0基础学习PyFlink——个数滚动窗口(Tumbling Count Windows)
大纲
- Tumbling Count Windows
- map
- reduce
- Window Size为2
- Window Size为3
- Window Size为4
- Window Size为5
- Window Size为6
- 完整代码
- 参考资料
之前的案例中,我们的Source都是确定内容的数据。而Flink是可以处理流式(Streaming)数据的,就是数据会源源不断输入。

对于这种数据,我们称之为无界流,即没有“终止的界限”。但是程序在底层一定不能等着无止境的数据都传递结束再处理,因为“无止境”就意味着“终止的界限”触发计算的条件是不存在的。那么我们可以人为的给它设置一个“界”,这就是我们本节介绍的窗口。
Tumbling Count Windows
Tumbling Count Windows是指按元素个数计数的滚动窗口。
滚动窗口是指没有元素重叠的窗口,比如下面图是个数为2的窗口。(元素重叠的窗口我们会在《0基础学习PyFlink——个数滑动窗口(Sliding Count Windows)》介绍)

个数为3的窗口

我们用代码探索下这个概念
map
word_count_data = [("A",2),("A",1),("B",3),("B",1),("B",2),("C",3),("C",1),("C",4),("C",2),("D",3),("D",1),("D",4),("D",2),("D",5),("E",3),("E",1),("E",4),("E",2),("E",6),("E",5)]def word_count():env = StreamExecutionEnvironment.get_execution_environment()env.set_runtime_mode(RuntimeExecutionMode.STREAMING)# write all the data to one fileenv.set_parallelism(1)source_type_info = Types.TUPLE([Types.STRING(), Types.INT()])# define the source# mappgingsource = env.from_collection(word_count_data, source_type_info)# source.print()# keyingkeyed=source.key_by(lambda i: i[0])
这段代码构造了一个KeyedStream,用于存储word_count_data中的数据。
我们并没有让Source是流的形式,是因为为了降低例子复杂度。但是我们将runntime mode设置为流(STREAMING)模式。
reduce
我们需要定义一个Reduce类,用于对元组中的数据进行计算。这个类需要继承于WindowFunction,并实现相应方法(本例中是apply)。
apply会计算一个相同key的元素个数。比如key是“E”的元组个数是6。
class SumWindowFunction(WindowFunction[tuple, tuple, str, CountWindow]):def apply(self, key: str, window: CountWindow, inputs: Iterable[tuple]):return [(key, len([e for e in inputs]))]
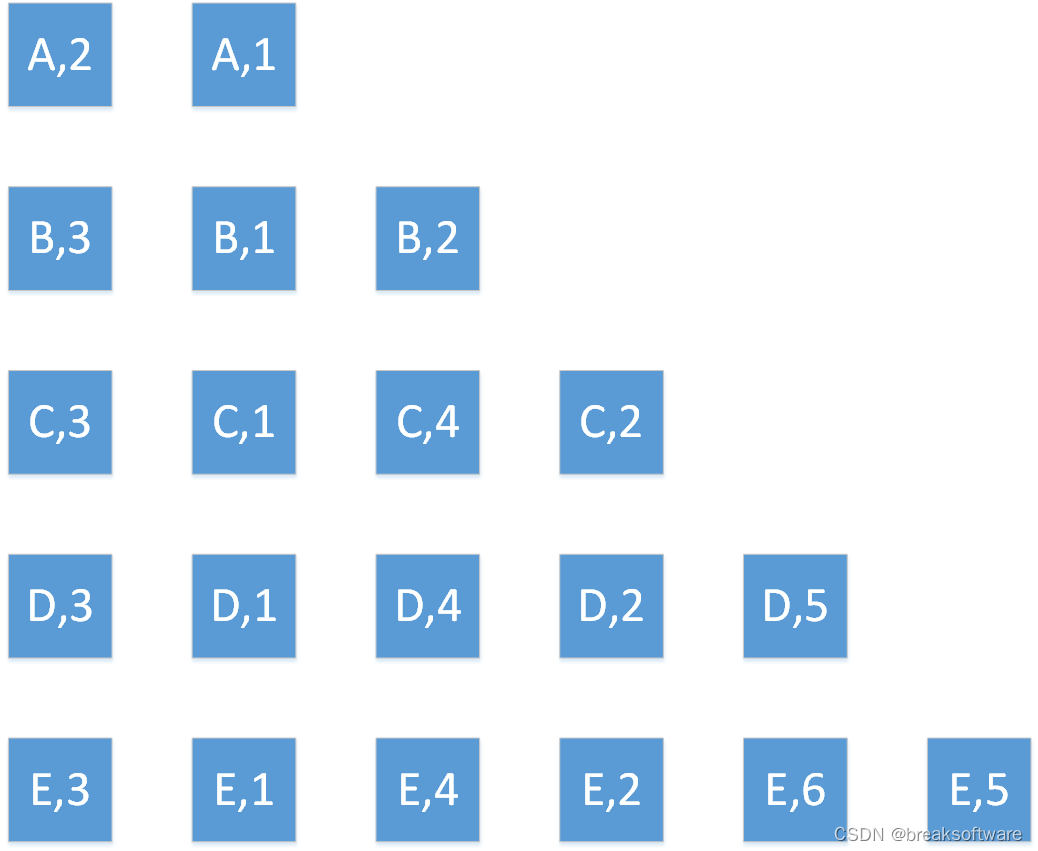
Window Size为2
# reducingreduced=keyed.count_window(2) \.apply(SumWindowFunction(),Types.TUPLE([Types.STRING(), Types.INT()]))# # define the sinkreduced.print()# submit for executionenv.execute()
(A,2)
(B,2)
(C,2)
(C,2)
(D,2)
(D,2)
(E,2)
(E,2)
(E,2)
- A的个数是2是因为A的确只有两个元组,而一个Size为2的Window正好承载了这两个元素。于是有(A,2)这个结果;
- B的个数是3。但是会产生两个窗口,第一个窗口承载了前两个元素,第二个窗口当前只有一个元素。于是第一个窗口进行了Reduce计算,得出一个(B,2);第二个窗口还没进行reduce计算,就没有展现出结果;
- C有4个,正好可以被2个窗口承载。这样我们就看到2个(C,2)。
- D有5个,情况和B类似。它被分成了3个窗口,只有2个窗口满足个数条件,于是就输出2个(D,2);最后一个窗口因为元素不够,就没尽兴reduce计算了。
- E有6个,正好被3个窗口承载。我们就看到3个(E,2)。
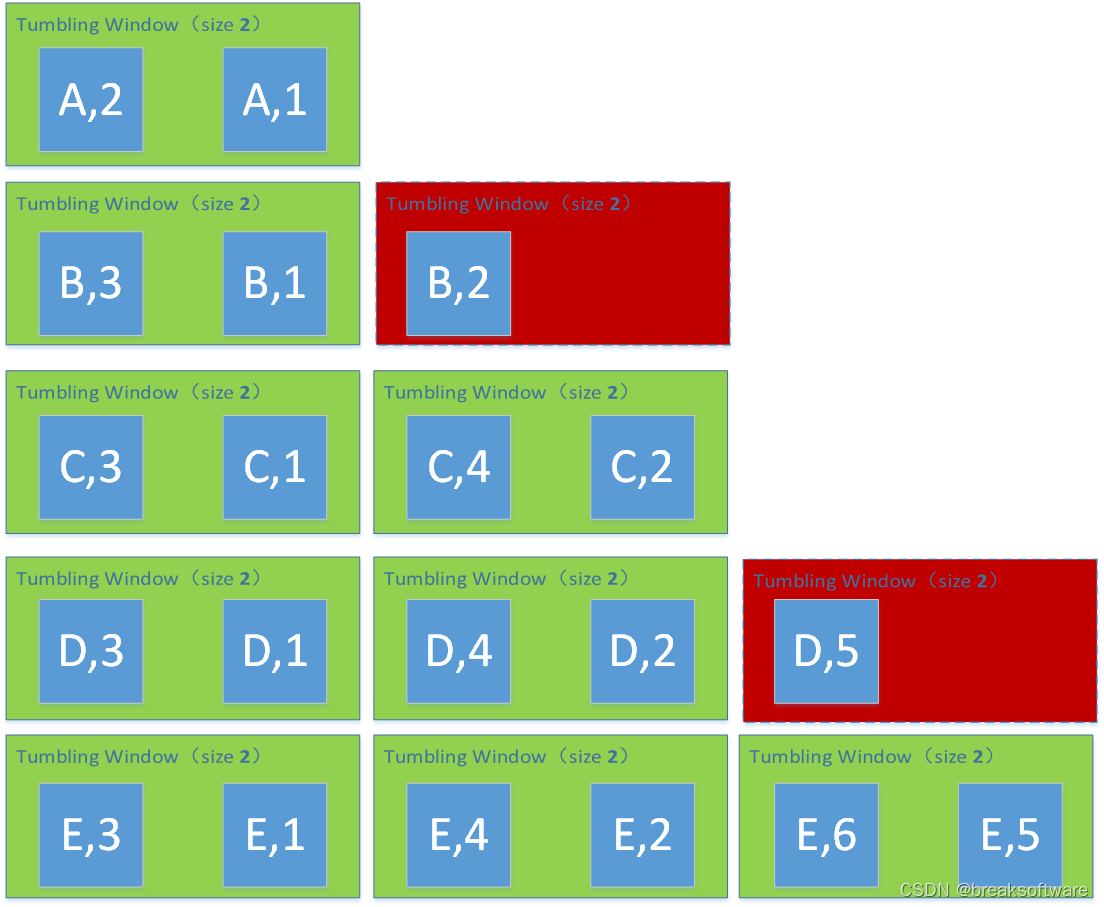
Window Size为3
# reducingreduced=keyed.count_window(3) \.apply(SumWindowFunction(),Types.TUPLE([Types.STRING(), Types.INT()]))
(B,3)
(C,3)
(D,3)
(E,3)
(E,3)
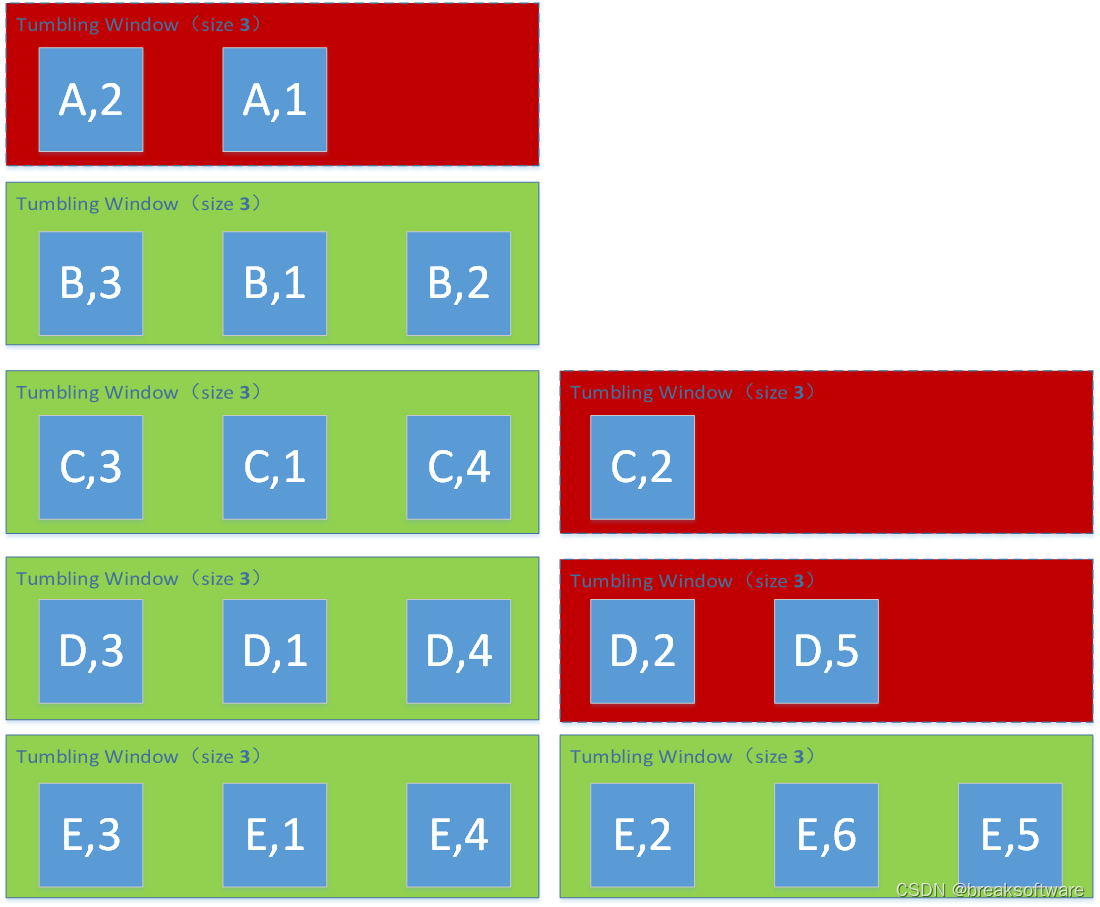
Window Size为4
# reducingreduced=keyed.count_window(4) \.apply(SumWindowFunction(),Types.TUPLE([Types.STRING(), Types.INT()]))
(C,4)
(D,4)
(E,4)
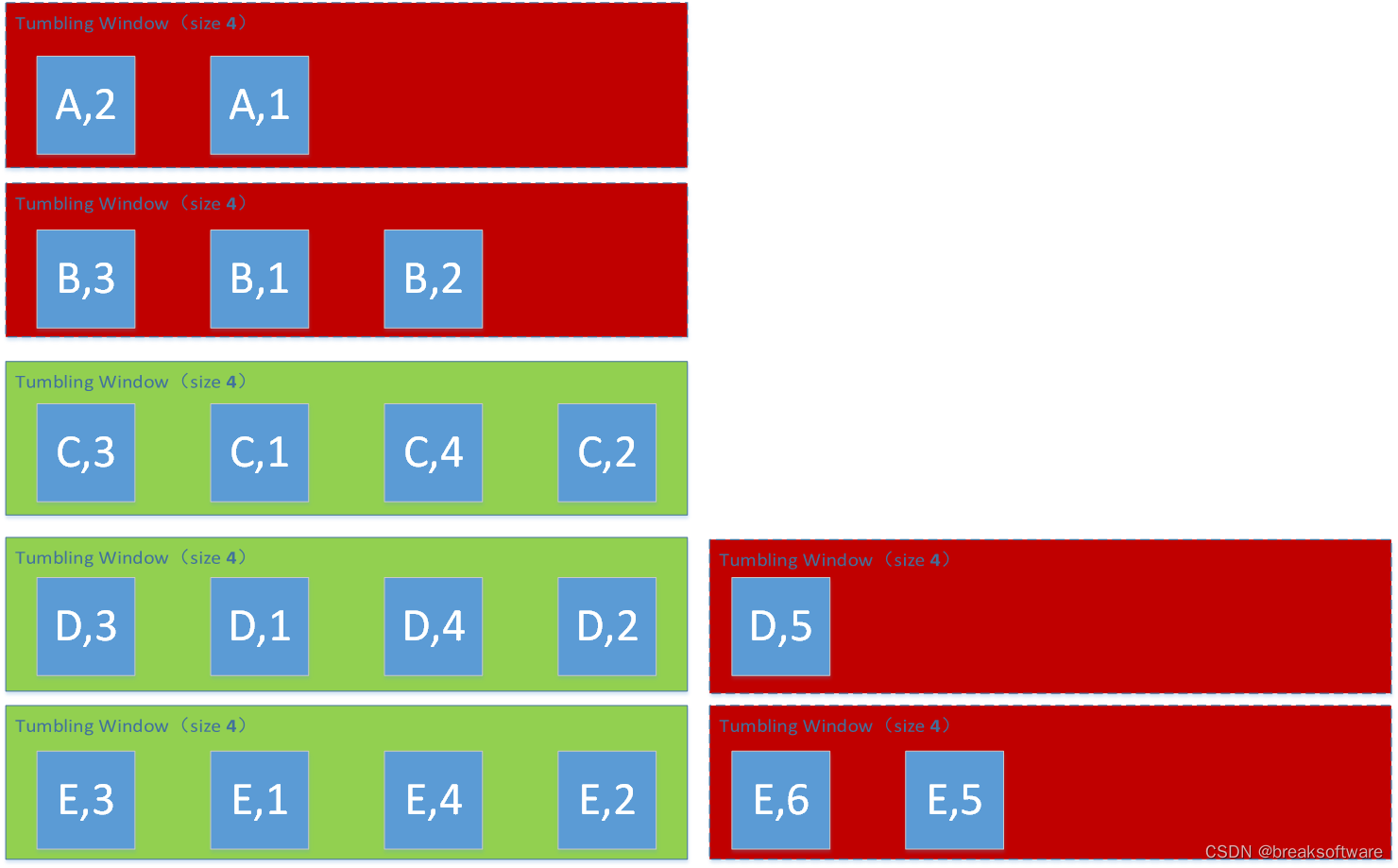
Window Size为5
# reducingreduced=keyed.count_window(5) \.apply(SumWindowFunction(),Types.TUPLE([Types.STRING(), Types.INT()]))
(D,5)
(E,5)
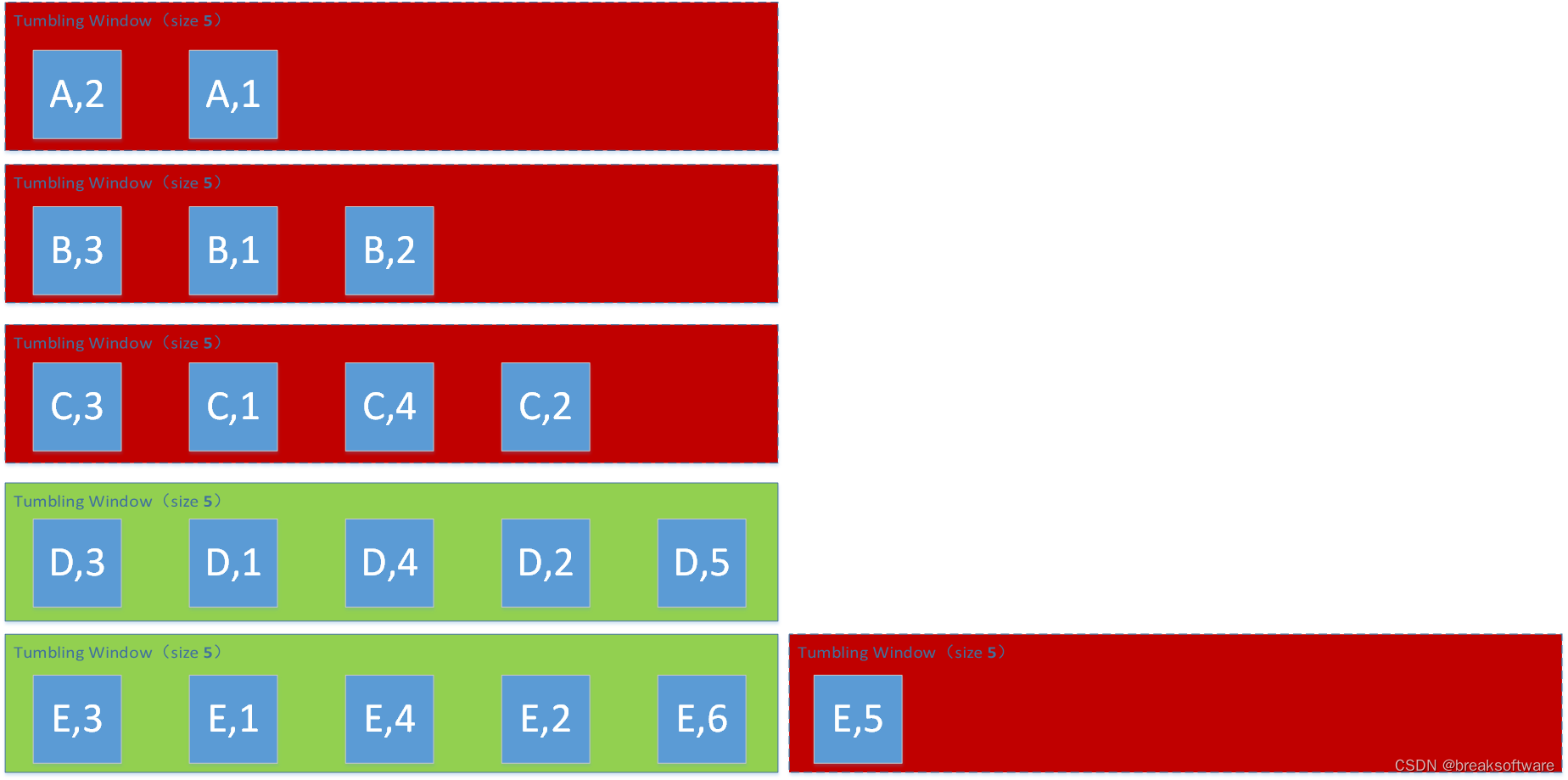
Window Size为6
# reducingreduced=keyed.count_window(6) \.apply(SumWindowFunction(),Types.TUPLE([Types.STRING(), Types.INT()]))
(E,6)
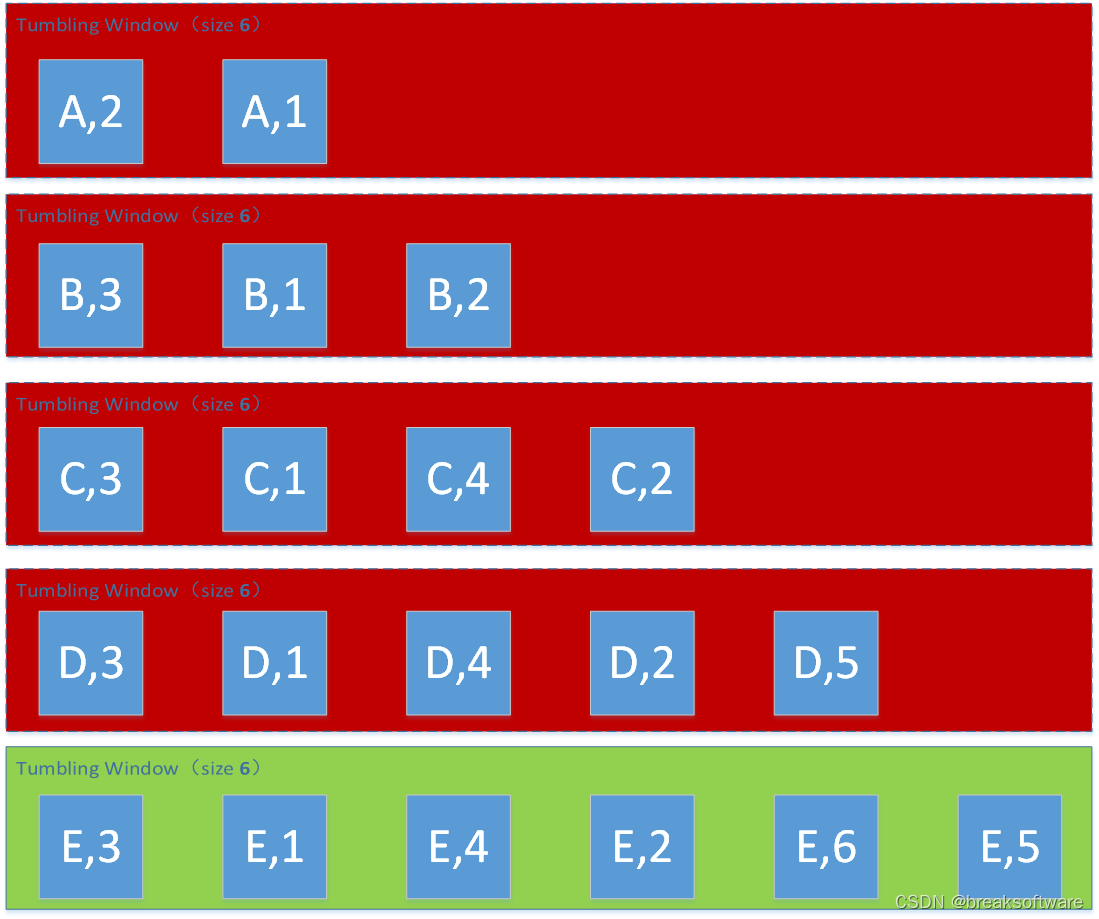
完整代码
from typing import Iterablefrom pyflink.common import Types
from pyflink.datastream import StreamExecutionEnvironment, RuntimeExecutionMode, WindowFunction
from pyflink.datastream.window import CountWindowclass SumWindowFunction(WindowFunction[tuple, tuple, str, CountWindow]):def apply(self, key: str, window: CountWindow, inputs: Iterable[tuple]):return [(key, len([e for e in inputs]))]word_count_data = [("A",2),("A",1),("B",3),("B",1),("B",2),("C",3),("C",1),("C",4),("C",2),("D",3),("D",1),("D",4),("D",2),("D",5),("E",3),("E",1),("E",4),("E",2),("E",6),("E",5)]def word_count():env = StreamExecutionEnvironment.get_execution_environment()env.set_runtime_mode(RuntimeExecutionMode.STREAMING)# write all the data to one fileenv.set_parallelism(1)source_type_info = Types.TUPLE([Types.STRING(), Types.INT()])# define the source# mappgingsource = env.from_collection(word_count_data, source_type_info)# source.print()# keyingkeyed=source.key_by(lambda i: i[0]) # reducingreduced=keyed.count_window(2) \.apply(SumWindowFunction(),Types.TUPLE([Types.STRING(), Types.INT()]))# # define the sinkreduced.print()# submit for executionenv.execute()if __name__ == '__main__':word_count()
参考资料
- https://nightlies.apache.org/flink/flink-docs-release-1.18/zh/docs/learn-flink/streaming_analytics/
相关文章:
0基础学习PyFlink——个数滚动窗口(Tumbling Count Windows)
大纲 Tumbling Count WindowsmapreduceWindow Size为2Window Size为3Window Size为4Window Size为5Window Size为6 完整代码参考资料 之前的案例中,我们的Source都是确定内容的数据。而Flink是可以处理流式(Streaming)数据的,就是…...

车载终端构筑智慧工厂:无人配送车的高效物流体系
随着科技的不断进步和应用,智能化已经成为许多领域的关键词。在物流行业中,随着无人配送车的兴起和智慧工厂的崛起,车载终端正引领着无人配送车的科技变革之路。 文章同款:https://www.key-iot.com/iotlist/sv900.html 车载终端…...

插件_日期_lunar-calendar公历农历转换
现在存在某需求,需要将公历、农历日期进行相互转换,在此借助lunar-calendar插件完成。 下载 [1] 通过npm安装 npm install lunar-calendar[2]通过文件方式引入 <script type"text/javascript" src"lib/LunarCalendar.min.js">…...

【FreeRTOS】【STM32】08 FreeRTOS 消息队列
简单来说 消息队列是一种数据结构 任务操作队列的基本描述 1.如果队列未满或者允许覆盖入队,FreeRTOS会将任务需要发送的消息添加到队列尾。 2.如果队列满,任务会阻塞(等待)。 3.用户可以指定等待时间。 4.当其它任务从其等待的队列中读取入了数据(这时候队列未满…...
【计算机组成原理】CPU的工作原理
一.CPU的组成结构 CPU主要有运算器、控制器、寄存器和内部总线等组成,其大概的样子长这样: 看不懂没关系,我们将采用自顶而下的方法来讲解CPU的具体工作原理,我们首先来说一下什么叫寄存器,顾名思义,寄存器…...
部署ELK
一、elasticsearch #拉取镜像 docker pull elasticsearch:7.12.1 #创建ELK docker网络 docker network create elk #启动ELK docker run -d --name es --net elk -P -e "discovery.typesingle-node" elasticsearch:7.12.1 #拷贝配置文件 docker cp es:/usr/share/el…...

纯前端实现图片验证码
前言 之前业务系统中验证码一直是由后端返回base64与一个验证码的字符串来实现的,想了下,前端其实可以直接canvas实现,减轻服务器压力。 实现 子组件,允许自定义图片尺寸(默认尺寸为100 * 40)与验证码刷新时间(默认时间为60秒)…...

#django基本常识01#
1、manage.py 所有子命令的入口,比如: python3 manage.py runserver 启动服务 python3 manage.py startapp 创建应用 python3 manage.py migrate 数据库迁移 直接执行python3 manage.py 可显示所有子命令...

什么是物流RPA?物流RPA解决什么问题?物流RPA实施难点在哪里?
RPA指的是机器人流程自动化,它是一套模拟人类在计算机、平板电脑、移动设备等界面执行任务的软件。通过RPA,可以自动完成重复性、繁琐的工作,提高工作效率和质量,降低人力成本。RPA适用于各种行业和场景,例如财务、人力…...

乐鑫工程部署过程记录
一、获取编译环境 1、下载sdk,ESP-IDF 这里有很多发布版本,当前我选择的是4.4.6,可以选择下载压缩包,也可以git直接clone 2、配置编译环境 我选择的是Linux Ubuntu下部署开发环境 查看入门指南 选择对应的芯片,我…...

to 后接ing形式的情况
look forward to seeing you. (期待着见到你) She admitted to making a mistake. (承认犯了个错误) He is accustomed to working long hours. (习惯于长时间工作)...

我做云原生的那几年
背景介绍 在2020年6月,我加入了一家拥有超过500人的企业。彼时,前端团队人数众多,有二三十名成员。在这样的大团队中,每个人都要寻找自己的独特之处和核心竞争力。否则,你可能会沉没于常规的增删改查工作中࿰…...

@EventListener注解使用说明
在Java的Spring框架中,EventListener注解用于监听和处理应用程序中的各种事件。通过使用EventListener注解,开发人员可以方便地实现事件驱动的编程模型,提高代码的灵活性和可维护性。本文将详细探讨EventListener注解的使用方法和作用&#x…...
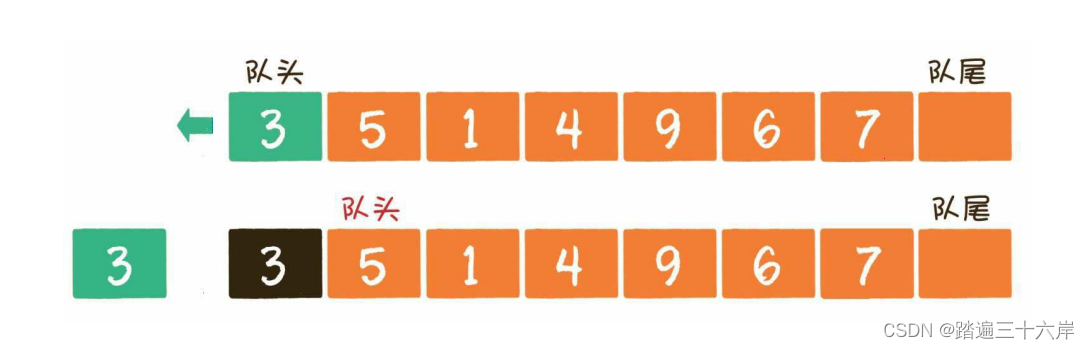
算法通关村第五关-白银挑战实现队列
大纲 队列基础队列的基本概念和基本特征实现队列队列的基本操作Java中的队列 队列基础 队列的基本概念和基本特征 队列的特点是节点的排队次序和出队次序按入队时间先后确定,即先入队者先出队,后入队者后出队,即我们常说的FIFO(first in fi…...

协力共创智能未来:乐鑫 ESP RainMaker 云方案线下研讨会圆满落幕
近日,乐鑫 ESP RainMaker 云方案线下研讨会(深圳)在亚马逊云科技与合作伙伴嘉宾的支持下成功举办,吸引了众多来自智能家电、照明电工、能源和宠物等行业的品牌客户、方案商和制造商。研讨会围绕如何基于乐鑫 ESP RainMaker 硬件连…...

读取谷歌地球的kml文件中的经纬度坐标
最近我在B站上传了如何获取研究边界的视频,下面分享一个可以读取kml中经纬度的matlab函数,如此一来就可以获取任意区域的经纬度坐标了。 1.谷歌地球中划分区域 2.matlab读取kml文件 function [sname,lon,lat] kml2xy(ip_kml) % ip_kml ocean_distubu…...
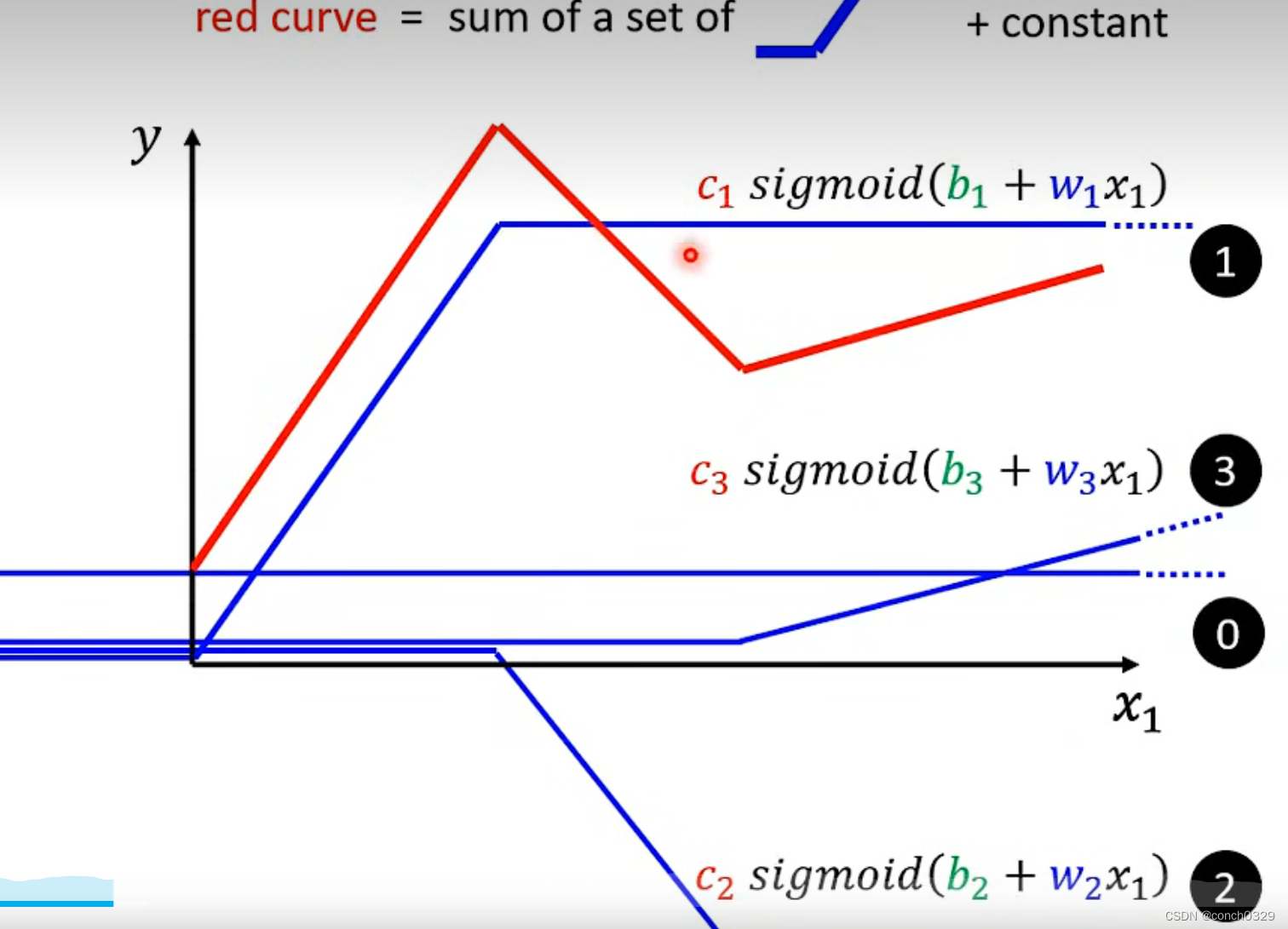
1深度学习李宏毅
目录 机器学习三件事:分类,预测和结构化生成 2、一般会有经常提到什么是标签label,label就是预测值,在机器学习领域的残差就是e和loss编辑3、一些计算loss的方法:编辑编辑 4、可以设置不同的b和w从而控制loss的…...
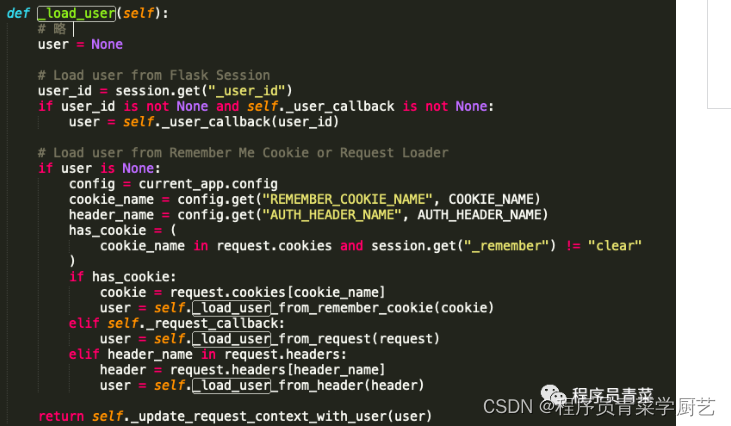
Flask_Login使用与源码解读
一、前言 用户登录后,验证状态需要记录在会话中,这样浏览不同页面时才能记住这个状态,Flask_Login是Flask的扩展,专门用于管理用户身份验证系统中的验证状态。 注:Flask是一个微框架,仅提供包含基本服务的…...
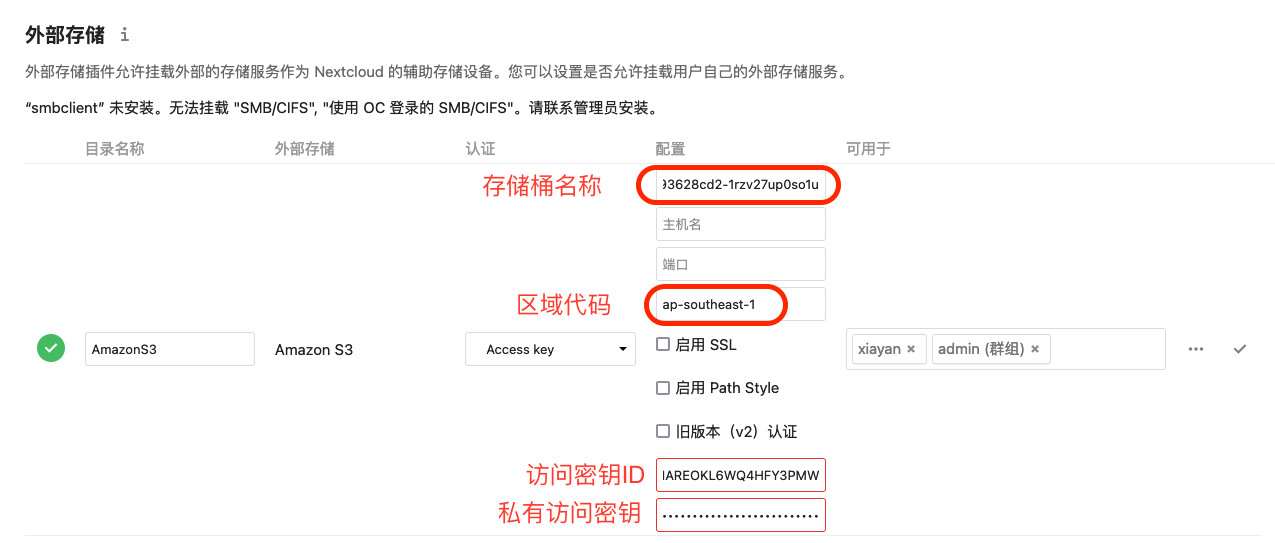
利用Graviton2和S3免费套餐搭建私人网盘
网盘是一种在线存储服务,提供文件存储,访问,备份,贡献等功能,是我们日常中不可或缺的一种服务。很多互联网公司都为个人和企业提供免费的网盘服务。但这些免费服务都有一些限制,比如限制下载速度࿰…...

跟着GPT学设计模式之单例模式
单例设计模式(Singleton Design Pattern)一个类只允许创建一个对象(或者实例),那这个类就是一个单例类,这种设计模式就叫作单例设计模式,简称单例模式。 单例有几种经典的实现方式,…...

魔兽争霸III终极优化工具:解决宽屏拉伸与高帧率限制的完整指南
魔兽争霸III终极优化工具:解决宽屏拉伸与高帧率限制的完整指南 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为经典游戏《魔兽争霸I…...

Mythos能力路由引擎:大模型时代的动态门控推理架构
1. 项目概述:一次被刻意“锁住”的能力跃迁如果你最近关注大模型前沿动态,大概率在技术社区、AI从业者群聊或邮件列表里见过“TAI #200”这个编号——它不是某篇论文的DOI,也不是某个开源项目的Release Tag,而是The AI Index Repo…...

高工独家报告|谁在收割2026智驾市场红利?440万辆背后的芯片大洗牌
高工智能汽车研究院发布《2026年中国市场智能汽车SoC芯片行业分析报告》。报告立足中国乘用车市场,基于乘用车前装量产数据库,全面解析智能驾驶SoC(含前视一体机、域控制器及高阶自动驾驶辅助芯片)与智能座舱SoC(含端侧…...

RT-Thread全局中断操作:原理、应用与低功耗设计关键
1. 项目概述:为什么需要深入理解全局中断操作?刚接触RT-Thread这类实时操作系统时,很多朋友都会对“全局中断”这个概念感到困惑。尤其是在看到代码里频繁出现的rt_hw_interrupt_disable()和rt_hw_interrupt_enable()这对函数时,心…...

双轴按键摇杆原理与应用:从ADC采样到项目实战
1. 项目概述:从“两个电位器”到交互核心如果你拆开一个游戏手柄,或者观察过一些工业控制面板、航模遥控器的内部,大概率会见过一个带着小塑料帽、能向四面八方拨动的黑色小元件——这就是双轴按键摇杆。很多朋友第一次接触它,可能…...

Serverless多事件触发器:提升FaaS效率的关键技术
1. Serverless计算中的多事件触发器:突破传统FaaS的局限在当今云原生架构中,Serverless计算已成为构建弹性应用的重要范式。作为其核心组件的函数即服务(FaaS)平台,如AWS Lambda和Google Cloud Functions,通过事件驱动机制实现了资…...

全域流量矩阵系统的运筹学解法:用线性规划模型,算出你100个账号的最优流量分配
手里有100个账号,抖音30个、小红书25个、视频号20个、B站15个、快手10个——然后呢?大多数人的做法是:每个平台平均发,每个账号随便发,发完看天吃饭。这不叫矩阵运营,这叫资源浪费。今天换个完全不同的视角…...
)
平衡小车PID调参新思路:用合宙ESP32-C3的BLE功能实现无线数据收发(附完整Arduino代码)
平衡小车无线PID调参实战:基于ESP32-C3 BLE的实时数据交互方案 调试平衡小车时,最令人头疼的莫过于反复插拔USB线修改PID参数。我曾经历过这样的场景:小车在桌面上左右摇摆,我蹲在地上盯着串口数据,每次修改参数都要暂…...
在量子机器学习中的应用与优化)
混合参数化量子态(HPQS)在量子机器学习中的应用与优化
1. 混合参数化量子态(HPQS)框架解析量子机器学习在NISQ(Noisy Intermediate-Scale Quantum)时代面临两大核心挑战:参数化量子电路(PQC)因有限测量次数导致的统计不确定性,以及神经量…...

GPT-4的1.8万亿参数与2%稀疏激活原理揭秘
1. 项目概述:参数规模与稀疏激活的真相拆解“GPT-4 Has 1.8 Trillion Parameters. It Uses 2% of Them Per Token.”——这句话过去两年在技术社区反复刷屏,常被当作AI算力爆炸的佐证,也常被误读为“模型只用了一丁点参数,所以还有…...