使用 TensorFlow SSD 网络进行对象检测
使用 TensorFlow SSD 网络进行对象检测
目录
- 描述
- 这个示例是如何工作的?
- 处理输入图
- 准备数据
- sampleUffSSD 插件
- 验证输出
- TensorRT API 层和操作
- 先决条件
- 运行示例
- 示例
--help选项
- 示例
- 附加资源
- 许可证
- 更改日志
- 已知问题
描述
该示例 sampleUffSSD 预处理 TensorFlow SSD 网络,使用 TensorRT 进行 SSD 网络的推理,利用 TensorRT 插件加速推理。
该示例基于 SSD:单次多盒检测器 论文。SSD 网络在网络的单次前向传播中执行对象检测和定位任务。
本示例中使用的 SSD 网络基于 TensorFlow 实现的 SSD 网络,与原始论文有所不同,它具有 inception_v2 骨干网络。有关实际模型的更多信息,请下载 ssd_inception_v2_coco。TensorFlow SSD 网络是使用 MSCOCO 数据集 对 InceptionV2 架构进行训练的,该数据集包括 91 个类别(包括背景类)。网络的配置细节可以在此处找到。
这个示例是如何工作的?
SSD 网络通过网络的单次前向传播执行对象检测和定位任务。TensorFlow SSD 网络是使用 MSCOCO 数据集在 InceptionV2 架构上训练的。
该示例使用 TensorRT 插件来运行 SSD 网络。为了使用这些插件,需要预处理 TensorFlow 图,并使用 GraphSurgeon 实用程序进行此操作。
该网络的主要组件包括图像预处理器、特征提取器、盒子预测器、网格锚点生成器和后处理器。
图像预处理器
图像预处理图的步骤负责调整图像的大小。图像被调整为 300x300x3 大小的张量。该步骤还执行图像的归一化,使得所有像素值都在范围 [-1, 1] 内。
特征提取器
图的特征提取器部分在经过预处理的图像上运行 InceptionV2 网络。生成的特征图被用于锚点生成步骤,用于为每个特征图生成默认的边界框。
在此网络中,用于锚点生成的特征图的大小为 [(19x19), (10x10), (5x5), (3x3), (2x2), (1x1)]。
盒子预测器
盒子预测器步骤接受高级别特征图作为输入,并为每个特征图的每个编码盒子生成一个盒子编码(x-y 坐标)列表以及每个编码盒子的类别分数列表。然后将这些信息传递给后处理器。
网格锚点生成器
此步骤的目标是为每个特征图单元格生成一组默认边界框(根据配置中提到的比例和长宽比)。这实现为 TensorRT 中的一个名为 gridAnchorGenerator 插件的层。注册的插件名称是 GridAnchor_TRT。
后处理器
后处理器步骤执行生成网络输出的最后步骤。所有特征图的边界框数据和置信度分数都将与预先生成的默认边界框(在 GridAnchorGenerator 命名空间中生成)一起输入到此步骤中。然后执行 NMS(非最大抑制),基于置信度阈值和 IoU(交并比)重叠来删掉大部分边界框,仅保留每类的前 N 个边界框。这实现为 TensorRT 中的名为 NMS 的插件层。注册的插件名称是 NMS_TRT。
注意: 本示例还实现了另一个名为 FlattenConcat 的插件,用于将输入扁平化然后连接结果。在输入传递给后处理器之前,会将位置和置信度数据应用于这个插件,因为 NMS 插件需要数据采用这种格式。
关于插件如何实现的详细信息,请参见 tensorrt/samples/sampleUffSSD 目录中的 sampleUffSSD.cpp 文件中的 FlattenConcat 插件和 FlattenConcatPluginCreator 的实现。
具体来说,此示例执行以下步骤:
- 处理输入图
- 准备数据
- sampleUffSSD 插件
- 验证输出
处理输入图
TensorFlow SSD 图具有一些目前在 TensorRT 中不受支持的操作。通过对图进行预处理,我们可以将图中的多个操作合并为单个自定义操作,这些操作可以在 TensorRT 中实现为插件层。目前,预处理器提供了将图中的所有节点(在删除断言后没有输出的节点)拼接成单个自定义节点的能力。
要使用预处理器,应该使用 convert-to-uff 实用程序并带有配置文件的 -p 标志来调用它。配置脚本还应包含将嵌入到生成的 .uff 文件中的所有自定义插件的属性。目前用于 SSD 的示例脚本位于 /usr/src/tensorrt/samples/sampleUffSSD/config.py。
使用图的预处理器,我们能够删除图中的 Preprocessor 命名空间,将 GridAnchorGenerator 命名空间拼接在一起以创建 GridAnchorGenerator 插件,将 postprocessor 命名空间拼接在一起以获得 NMS 插件,并将 BoxPredictor 中的 concat 操作标记为 FlattenConcat 插件。
TensorFlow 图中有一些操作,如 Assert 和 Identity,在推理时可以移除。Assert 等操作已被移除,剩下的节点(在删除断言后没有输出的节点)将被递归地删除。
Identity 操作将被删除,并且输入将被转发到所有连接的输出。有关图预处理器的附加文档,可以在TensorRT API中找到。
准备数据
生成的网络具有名为 Input 的输入节点,输出节点的名称由 UFF 转换器命名为 MarkOutput_0。
parser->registerInput("Input", DimsCHW(3, 300, 300), UffInputOrder::kNCHW);
parser->registerOutput("MarkOutput_0");
本示例中 SSD 网络的输入是 3 通道 300x300 图像。在示例中,我们对图像进行归一化,使像素值位于范围 [-1,1]。
由于 TensorRT 不依赖于任何计算机视觉库,图像以每个像素的二进制 R、G 和 B 值表示。格式是可移植图像映射(Portable PixMap,PPM),这是一种 netpbm 颜色图像格式。在此格式中,每个像素的 R、G 和 B 值由整数字节(0-255)表示,并按像素存储在一起。
有一个名为 readPPMFile 的简单 PPM 读取函数。
sampleUffSSD 插件
有关如何创建 TensorRT 插件的详细信息,请参见使用自定义层扩展 TensorRT。
用于 convert-to-uff 命令的 config.py 定义应通过修改 op 字段将自定义层映射到 TensorRT 中的插件名称。插件参数的名称也应与 TensorRT 插件所期望的名称和类型完全匹配。例如,对于 GridAnchor 插件,config.py 应该如下所示:
PriorBox = gs.create_plugin_node(name="GridAnchor",
op="GridAnchor_TRT",
numLayers=6,
minSize=0.2,
maxSize=0.95,
aspectRatios=[1.0, 2.0, 0.5, 3.0, 0.33],
variance=[0.1,0.1,0.2,0.2],
featureMapShapes=[19, 10, 5, 3, 2, 1])
这里,GridAnchor_TRT 与已注册的插件名称匹配,参数的名称和类型与插件所期望的名称相同。
如果 config.py 定义如上,NvUffParser 将能够解析网络并使用正确的参数调用适当的插件。
以下是TensorRT中为SSD实现的一些插件层的详细信息。
GridAnchorGeneration 插件
这个插件层实现了TensorFlow SSD网络中的网格锚点生成步骤。对于每个特征图,我们计算每个网格单元的边界框。在这个网络中,有6个特征图,每个网格单元的边界框数量如下:
- [19x19] 特征图:3个边界框(19x19x3x4(坐标/边界框))
- [10x10] 特征图:6个边界框(10x10x6x4)
- [5x5] 特征图:6个边界框(5x5x6x4)
- [3x3] 特征图:6个边界框(3x3x6x4)
- [2x2] 特征图:6个边界框(2x2x6x4)
- [1x1] 特征图:6个边界框(1x1x6x4)
NMS 插件
NMS 插件生成基于BoxPredictor生成的位置和置信度预测的检测输出。此层有三个输入张量,对应于位置数据(locData)、置信度数据(confData)和先前框数据(priorData)。
检测输出插件的输入必须被扁平化并连接在所有特征图上。我们使用样本中实现的FlattenConcat插件来实现这一点。BoxPredictor生成的位置数据的尺寸如下:
19x19x12 -> 重塑 -> 1083x4 -> 扁平化 -> 4332x1
10x10x24 -> 重塑 -> 600x4 -> 扁平化 -> 2400x1
等等,对于其余特征图也是如此。
连接后,locData 输入的维度约为7668x1。
BoxPredictor生成的置信度数据的尺寸如下:
19x19x273 -> 重塑 -> 1083x91 -> 扁平化 -> 98553x1
10x10x546 -> 重塑 -> 600x91 -> 扁平化 -> 54600x1
等等,对于其余特征图也是如此。
连接后,confData 输入的维度为174447x1。
Grid Anchor Generator 插件生成的先前数据有6个输出,它们的维度如下:
输出 1 对应于19x19特征图,维度为2x4332x1
输出 2 对应于10x10特征图,维度为2x2400x1
等等,对于其他特征图也是如此。
注意: 输出中有两个通道,因为一个通道用于存储每个坐标的方差,这在NMS步骤中使用。连接后,priorData 输入的维度约为2x7668x1。
struct DetectionOutputParameters
{
bool shareLocation, varianceEncodedInTarget;
int backgroundLabelId, numClasses, topK, keepTopK;
float confidenceThreshold, nmsThreshold;
CodeTypeSSD codeType;
int inputOrder[3];
bool confSigmoid;
bool isNormalized;
};
shareLocation 和 varianceEncodedInTarget 用于Caffe SSD网络实现,所以对于TensorFlow网络,它们应该分别设置为 true 和 false。confSigmoid 和 isNormalized 参数对于TensorFlow实现是必要的。如果将 confSigmoid 设置为 true,它将计算所有置信度得分的sigmoid值。isNormalized 标志指定数据是否被规范化,对于TensorFlow图,它被设置为 true。
验证输出
在创建生成器之后(参见在C++中构建引擎)并序列化引擎之后(参见在C++中序列化模型),我们可以执行推理。关于反序列化和运行推理的步骤在在C++中执行推理中进行了概述。
SSD网络的输出是人类可解释的。最后的NMS等后处理工作在NMS插件中完成。结果被组织为元组,每个元组有7个元素,分别是图像ID,对象标签,置信度分数,边界框左下角的(x,y)坐标,以及边界框的右上角的(x,y)坐标。可以使用writePPMFileWithBBox函数在输出PPM图像上绘制这些信息。visualizeThreshold参数可用于控制图像中对象的可视化。目前它被设置为0.5,所以输出将显示所有置信度为50%及以上的对象。
TensorRT API层和操作
在这个示例中,使用了以下层。有关这些层的更多信息,请参阅TensorRT开发者指南:层文档。
激活层
激活层实现了逐元素激活函数。具体而言,本示例使用了类型为kRELU的激活层。
连接层
连接层沿着通道维度连接多个非通道大小相同的张量。
卷积层
卷积层计算带有或不带有偏差的2D(通道、高度和宽度)卷积。
填充层
填充层在最内部的两个维度上实现了零填充。
插件层
插件层是用户定义的,提供了扩展TensorRT功能的能力。有关更多详细信息,请参阅通过自定义层扩展TensorRT。
池化层
池化层在通道内进行池化。支持的池化类型有maximum、average和maximum-average blend。
尺度层
尺度层实现了每个张量、每个通道或每个元素的仿射变换和/或常数值的幂运算。
Shuffle层
Shuffle层为张量实现了重塑和转置运算符。
先决条件
-
安装 UFF 工具包和图形外科医生;根据您的 TensorRT 安装方法,选择您所使用的方法以安装工具包和图形外科医生,可以参考 TensorRT 安装指南:安装 TensorRT 获取详细说明。
-
下载 ssd_inception_v2_coco TensorFlow 训练模型。
-
使用 UFF 转换器对 TensorFlow 模型进行预处理。
-
从之前步骤下载的目录中将 TensorFlow 协议缓冲文件(
frozen_inference_graph.pb)复制到工作目录中(例如/usr/src/tensorrt/samples/sampleUffSSD/)。 -
运行以下命令进行转换。
convert-to-uff frozen_inference_graph.pb -O NMS -p config.py这将保存转换后的 `.uff` 文件到与输入相同的目录,并命名为 `frozen_inference_graph.pb.uff`。`config.py` 脚本指定了 SSD TensorFlow 图所需的预处理操作。`config.py` 脚本中使用的插件节点和插件参数应与 TensorRT 中的注册插件匹配。- 将转换后的
.uff文件复制到数据目录,并将其重命名为sample_ssd_relu6.uff <TensorRT 安装目录>/data/ssd/sample_ssd_relu6.uff。
-
-
该示例还需要一个包含用于训练模型的所有标签的
labels.txt文件。该网络的标签文件是<TensorRT 安装目录>/data/ssd/ssd_coco_labels.txt。
运行示例
-
在
<TensorRT 根目录>/samples/sampleUffSSD目录中运行make来编译该示例。该二进制文件将被创建在<TensorRT 根目录>/bin目录中。cd <TensorRT 根目录>/samples/sampleUffSSD make其中
<TensorRT 根目录>是您安装 TensorRT 的位置。 -
运行示例以执行对象检测和定位。
要在 FP32 模式下运行示例:
./sample_uff_ssd要在 INT8 模式下运行示例:
./sample_uff_ssd --int8注意: 要在 INT8 模式下运行网络,请参考
BatchStreamPPM.h,了解如何执行校准。目前,我们需要一个名为list.txt的文件,其中列出了位于<TensorRT 安装目录>/data/ssd/文件夹中用于校准的所有 PPM 图像。用于校准的 PPM 图像也可以位于同一文件夹中。 -
验证示例是否成功运行。如果示例成功运行,您应该会看到类似以下的输出:
&&&& RUNNING TensorRT.sample_uff_ssd # ./build/x86_64-linux/sample_uff_ssd [I] ../data/samples/ssd/sample_ssd_relu6.uff [I] 开始解析模型... [I] 完成解析模型... [I] 开始构建引擎... I] 批处理数量 1 [I] 数据大小 270000 [I] *** 反序列化 [I] 推断所用时间为 4.24733 毫秒。 [I] 保留数量 100 [I] 在图像 0(../../data/samples/ssd/dog.ppm)中检测到狗,置信度为 89.001,坐标为 (81.7568, 23.1155),(295.041, 298.62)。 [I] 结果保存在 dog-0.890010.ppm 中。 [I] 在图像 0(../../data/samples/ssd/dog.ppm)中检测到狗,置信度为 88.0681,坐标为 (1.39267, 0),(118.431, 237.262)。 [I] 结果保存在 dog-0.880681.ppm 中。 &&&& PASSED TensorRT.sample_uff_ssd # ./build/x86_64-linux/sample_uff_ssd这个输出表明示例成功运行;“PASSED”。
示例 --help 选项
要查看可用选项的完整列表及其说明,请使用 -h 或 --help 命令行选项。
附加资源
以下资源提供了有关 TensorFlow SSD 网络结构的更深入理解:
模型
- TensorFlow 检测模型库
网络
- ssd_inception_v2_coco_2017_11_17
数据集
- MSCOCO 数据集
文档
- NVIDIA TensorRT 示例简介
- 使用 C++ API 使用 TensorRT
- NVIDIA TensorRT 文档库
许可协议
有关使用、复制和分发的条款和条件,请参阅TensorRT 软件许可协议文档。
更新日志
2019年3月
重新创建、更新和审阅此 README.md 文件。
已知问题
- 在 INT8 模式下运行网络时,可能会存在一些精度损失,导致某些对象无法被检测到。一般观察是,>500 张图像是用于校准的良好数量。
- 在 Windows 上,Python 脚本
convert-to-uff不可用。您可以在 Linux 机器上生成所需的 .uff 文件,然后复制到 Windows 上以运行此示例。
相关文章:

使用 TensorFlow SSD 网络进行对象检测
使用 TensorFlow SSD 网络进行对象检测 目录 描述这个示例是如何工作的? 处理输入图准备数据sampleUffSSD 插件验证输出TensorRT API 层和操作 先决条件运行示例 示例 --help 选项 附加资源许可证更改日志已知问题 描述 该示例 sampleUffSSD 预处理 TensorFlow …...
(2)STM32单片机上位机
使用VX小程序开发上位机, 样式如何创建? 在你所在页面 开辟空间 使用 view 在view 中 输入class 就是样式,在编辑样式的时候,如何寻找哪一块的样式 就是通过这个class寻找的 按钮使用switch...

从InnoDB索引的数据结构,去理解索引
从InnoDB索引的数据结构,去理解索引 1、InnoDB 中的 BTree1.1、BTree 的组成1.2、BTree中的数据页 2、聚簇索引2.1、聚簇索引的特点2.2、聚簇索引的结构示例2.3、聚簇索引的优缺点 3、非聚簇索引3.1、非聚簇索引结构示例3.2、关于回表3.3、聚簇索引和非聚簇索引的区…...

Nacos:动态服务发现与配置管理的终极解决方案
今天我想和大家分享一下Nacos,这是一个由阿里巴巴开源的动态服务发现、配置和服务管理平台。我将详细介绍Nacos的主要特性,并通过实例来演示如何使用它。同时,我还会指出Nacos的优点,希望这篇文章能够帮助大家更好地理解和使用Nac…...
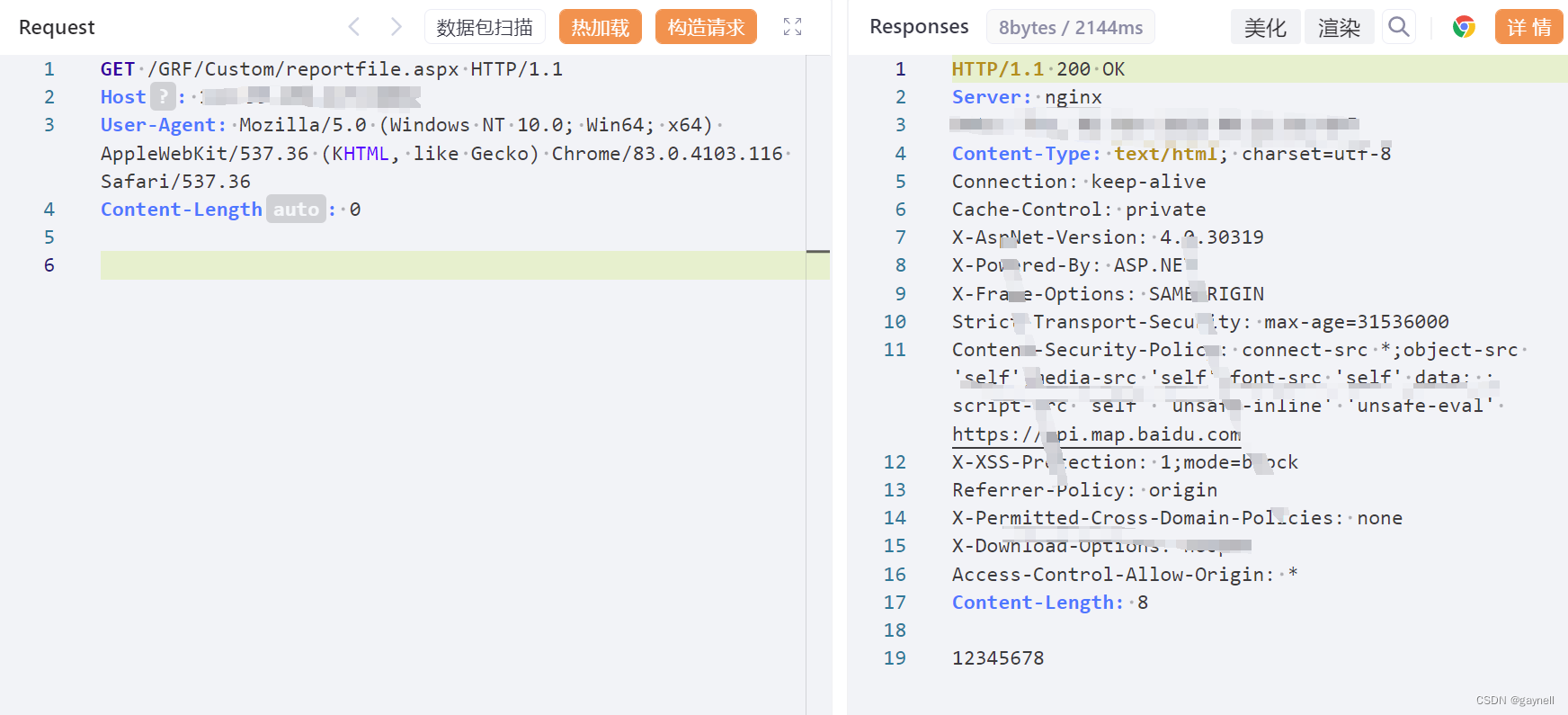
易思无人值守智能物流系统Sys_ReportFile文件上传漏洞复现
文章目录 易思无人值守智能物流系统Sys_ReportFile文件上传漏洞复现0x01 前言0x02 漏洞描述0x03 影响版本0x04 漏洞环境0x05 漏洞复现1.访问漏洞环境2.构造POC3.复现 0x06 修复建议 易思无人值守智能物流系统Sys_ReportFile文件上传漏洞复现 0x01 前言 免责声明:请…...

java Map List转化,通过Map保存数据,通过List排序。取前三名
java Map List转化,通过Map保存数据,通过List排序。取前三名 package yo;import java.util.ArrayList; import java.util.Collections; import java.util.HashMap; import java.util.List; import java.util.Map;public class a {public static void …...

LEECODE 1480一维数组的动态和
class Solution { public:vector<int> runningSum(vector<int>& nums) {vector<int> runningSum;int sum 0;int len nums.size();for(int i 0; i < len; i){sum sum nums[i];runningSum.push_back(sum);}return runningSum;} };...

python文档链接
python与并行计算...

HTTP调试代理工具/Proxyman
Proxyman专为开发人员和网络爱好者设计,它允许用户拦截、查看和修改所有传入和传出的网络请求,并提供详细的分析和调试功能。 Proxyman支持HTTP、HTTPS和WebSocket协议,因此,可以轻松捕获和查看这些协议下的网络流量。用户可以使…...
搭建Qt5.7.1+kylinV10开发环境、运行环境
1.下载Qt源码 Index of / 2.编译Qt 解压缩qt-everywhere-opensource-src-5.7.1.tar.gz 进入到qt-everywhere-opensource-src-5.7.1/qtbase/mkspecs这个目录下, 2.1找到以下目录 复制他,然后改名linux-x86-arrch64,博主这里名字取的有些问…...
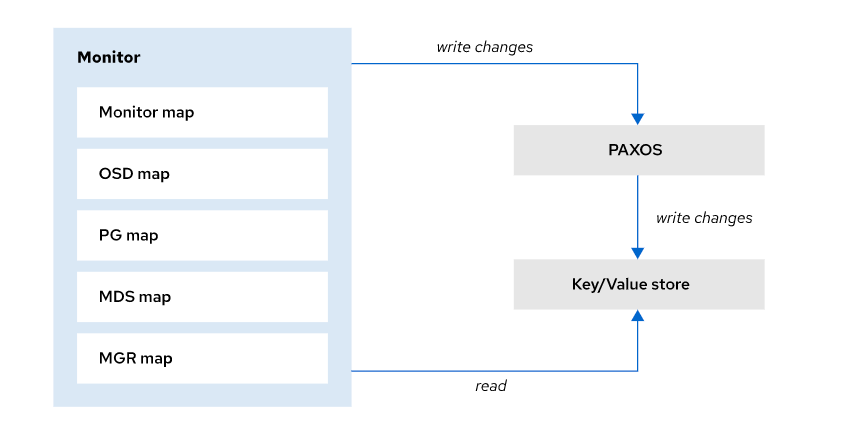
Ceph:关于Ceph 中创建和管理自定义 CRUSH Map
写在前面 准备考试,整理 Ceph 相关笔记博文内容涉及,管理和定制CRUSH Map以及管理OSD Map理解不足小伙伴帮忙指正 对每个人而言,真正的职责只有一个:找到自我。然后在心中坚守其一生,全心全意,永不停息。所…...

【Linux】开发工具——vim多模式编辑器的入土设置sudoers白名单
个人主页点击直达:小白不是程序媛 Linux系列专栏:Linux被操作记 目录 前言: 基本概念 vim基本操作 [正常模式]切换至[插入模式] [插入模式]切换至[正常模式] [正常模式]切换至[末行模式] 三种模式的切换关系图 vim命令模式命令集 进…...
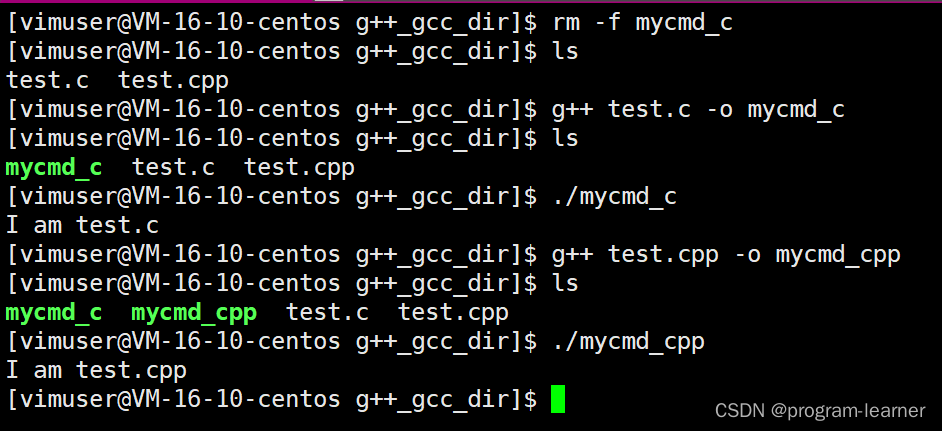
Linux基础环境开发工具的使用(yum,vim,gcc,g++)
Linux基础环境开发工具的使用[yum,vim,gcc,g] 一.yum1.yum的快速入门1.yum安装软件2.yum卸载软件 2.yum的生态环境1.操作系统的分化2.四个问题1.服务器是谁提供的呢?2.服务器上的软件是谁提供的呢?3.为什么要提供呢?4.yum是如何得知目标服务器的地址和下载链接呢?5.软件源 …...

加速软件开发和交付的革命性方法-DevOps
“ 随着信息技术的快速发展,现代软件开发和交付已经经历了巨大的变革。DevOps(Development和Operations的结合)已经成为这一变革的关键推动力,让开发团队和运维团队之间的界限变得模糊,以加速软件的开发、测试和部署过…...
Ha-NeRF源码解读 train_mask_grid_sample
目录 背景: (1)Ha_NeRF论文解读 (2)Ha_NeRF源码复现 (3)train_mask_grid_sample.py 运行 train_mask_grid_sample.py解读 1 NeRFSystem 模块 2 forward()详解 3 模型训练tranining_st…...

大数据毕业设计选题推荐-系统运行情况监控系统-Hadoop-Spark-Hive
✨作者主页:IT毕设梦工厂✨ 个人简介:曾从事计算机专业培训教学,擅长Java、Python、微信小程序、Golang、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。 ☑文末获取源码☑ 精彩专栏推荐⬇⬇⬇ Java项目 Py…...
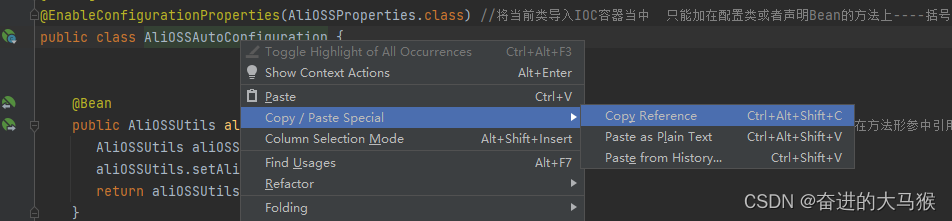
SpringBoot----自定义Start(自定义依赖)
一,为什么要定义Start 向阿里云OSS如果我们要引入的话很麻烦,所以我们可以自定义一些组件, 然后我们只需要在pom文件中引入对应的坐标就可以 二,怎么定义(以阿里云OSS为例) 1, 定义两个组件模块…...
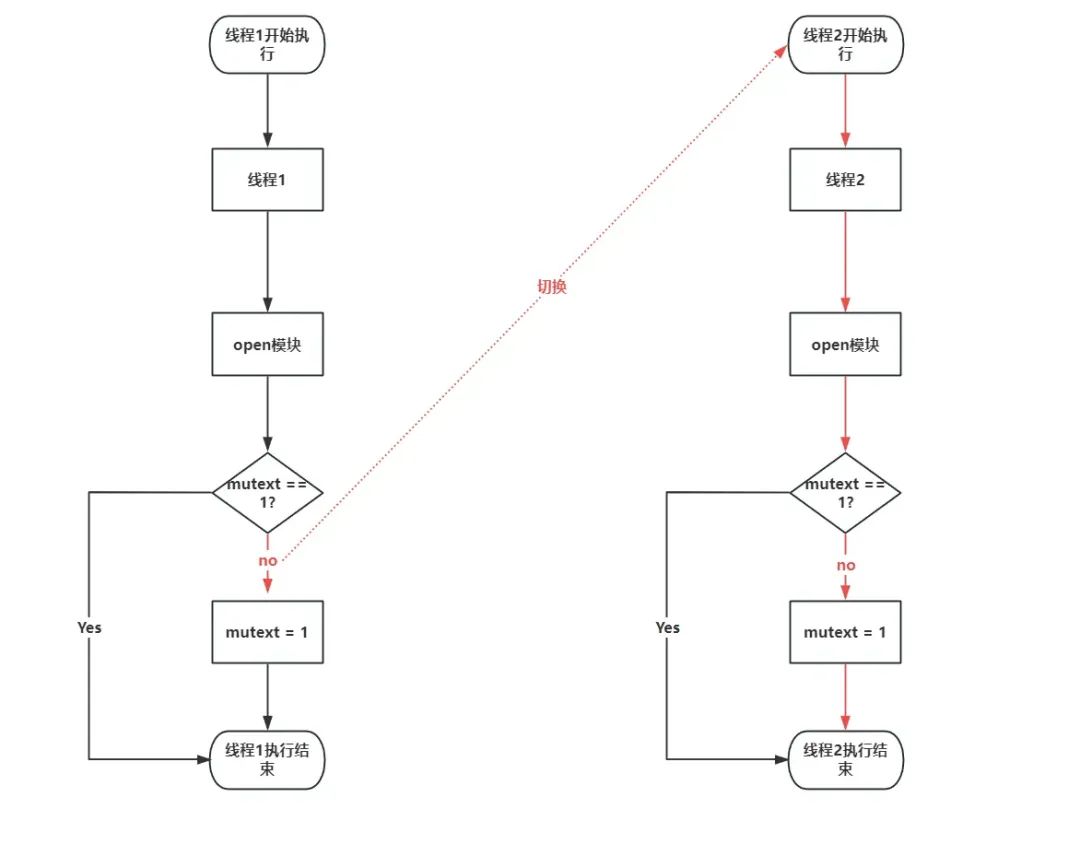
通过条件竞争实现内核提权
条件竞争漏洞(Race Condition Vulnerability)是一种在多线程或多进程并发执行时可能导致不正确行为或数据损坏的安全问题。这种漏洞通常发生在多个线程或进程试图访问和修改共享资源(如内存、文件、网络连接等)时,由于…...

vue实现换肤功能
1、使用scss定义几种需要进行换肤的颜色,例如: .font-color-theme{[color-theme"black"] & {color: #000}[color-theme"white"] & {color: #fff} }2、使用以下代码控制变化; let colorType localStorage.getIt…...
)
嵌入式软件工程师面试题——2025校招社招通用(八)
说明: 面试题来源于网络书籍,公司题目以及博主原创或修改(题目大部分来源于各种公司);文中很多题目,或许大家直接编译器写完,1分钟就出结果了。但在这里博主希望每一个题目,大家都要…...

Puerts在UE5中实现TypeScript与蓝图无缝交互的实战指南
1. 这不是“加个插件就能用”的事:为什么Puerts在UE5里常被低估又频繁踩坑我第一次在UE5.1项目里集成Puerts时,以为照着GitHub README跑完C编译、TS声明生成、蓝图调用三步就能收工。结果花了整整三天——不是卡在编译失败,而是卡在“调用成功…...

把AI的能力拆成乐高积木:如何让Agent真正干成复杂的事
【AI Agent能不能干成复杂的事,不取决于模型有多聪明,而取决于能力怎么编排】AI Agent在2025年成为企业数字化领域的最热词汇。几乎所有企业都在讨论"上Agent",但真正落地之后,大家发现一个尴尬的现实:简单的…...

用wireshark抓取分析EtherCAT报文
📜 第1章:EtherCAT报文结构 EtherCAT报文结构及Wireshark对应显示: 以太网帧头:14字节,包含目标/源MAC地址,帧类型 (EtherType) 固定为 0x88A4。EtherCAT帧头:2字节,包含一个11位的“…...

Gemini3.1Pro编程项目什么时候该用什么时候不该用
概要Gemini 3.1 Pro是Google DeepMind于2026年2月推出的旗舰级多模态大语言模型。在编程和项目管理场景中,它最核心的价值不是"替代程序员写代码",而是在特定环节——需求分析、架构设计初稿、代码审查、Bug定位、技术文档生成、项目进度整理—…...

harmonyos-ai-skill:让 Cursor 按 ArkTS 规范写鸿蒙,不再瞎编 API
端侧 Kit、MCP 接线都写过之后,写代码的人仍会遇到:Cursor 生成「像 React 的 ArkTS」、编造不存在的 Kit 名。社区项目 harmonyos-ai-skill 用可安装知识包,把 API 11 / DevEco 6 约束塞进 AI 工具链。 1. 问题:通用大模型不懂你…...
亲测好用的AI写作辅助平台,毕业生收藏备用)
(良心整理)亲测好用的AI写作辅助平台,毕业生收藏备用
毕业季论文写作真的这么难吗?选题方向模糊、文献资料繁杂、写作进度缓慢、查重修改头疼、格式规范混乱…… 这份亲测好用的AI论文工具清单,涵盖中英文写作、全流程支持、专项功能、免费与高性价比选项,从开题构思到最终定稿全程护航ÿ…...

如何在VSCode中快速预览PDF文件:vscode-pdfviewer完整使用指南
如何在VSCode中快速预览PDF文件:vscode-pdfviewer完整使用指南 【免费下载链接】vscode-pdfviewer Show PDF preview in VSCode. 项目地址: https://gitcode.com/gh_mirrors/vs/vscode-pdfviewer 你是否经常需要在VSCode中查看PDF文档,但又不想频…...

UE5 GAS修改Attribute的四种正确方式与原理
1. 为什么改Attribute不是简单赋值,而是要走GAS的整套流程 在UE5中用Gameplay Ability System(GAS)做RPG,很多人刚上手时都会卡在一个看似最基础的问题上: “我想让角色血量100,直接写 Attributes.Health…...

Python数据库迁移实战:从SQLAlchemy到Alembic的完整指南
Python数据库迁移实战:从SQLAlchemy到Alembic的完整指南 引言 数据库迁移是后端开发中不可或缺的一部分。作为从Python转向Rust的后端开发者,我发现Python的数据库迁移工具非常成熟,尤其是Alembic配合SQLAlchemy的组合。本文将从实战角度出发…...

函数递归调用原理
1. 什么是递归 2. 递归的举例 3. 递归与迭代1. 什么是递归递归就是一种解决方法,在C语言中,递归就是函数调用自己。下面是一个简单的递归C语言程序:#include <stdio .h>int main(){printf("hello world\n");main();//main函数…...