在IDEA运行spark程序(搭建Spark开发环境)
建议大家写在Linux上搭建好Hadoop的完全分布式集群环境和Spark集群环境,以下在IDEA中搭建的环境仅仅是在window系统上进行spark程序的开发学习,在window系统上可以不用安装hadoop和spark,spark程序可以通过pom.xml的文件配置,添加spark-core依赖,可以直接在IDEA中编写spark程序并运行结果。
一、相关软件的下载及环境配置
1.jdk的下载安装及环境变量配置(我选择的版本是jdk8.0(即jdk1.8),建议不要使用太高版本的,不然配置pom.xml容易报错)
链接:https://pan.baidu.com/s/1deXf6pgMiRca1O724fUOxg
提取码:sxuy
双击安装包,一直“Next”即可,最好不要安装到C盘,中间修改一下安装路径即可,最后点击“Finish”。我将jdk1.8安装在了D盘目录下的soft文件夹,bin路径如下:

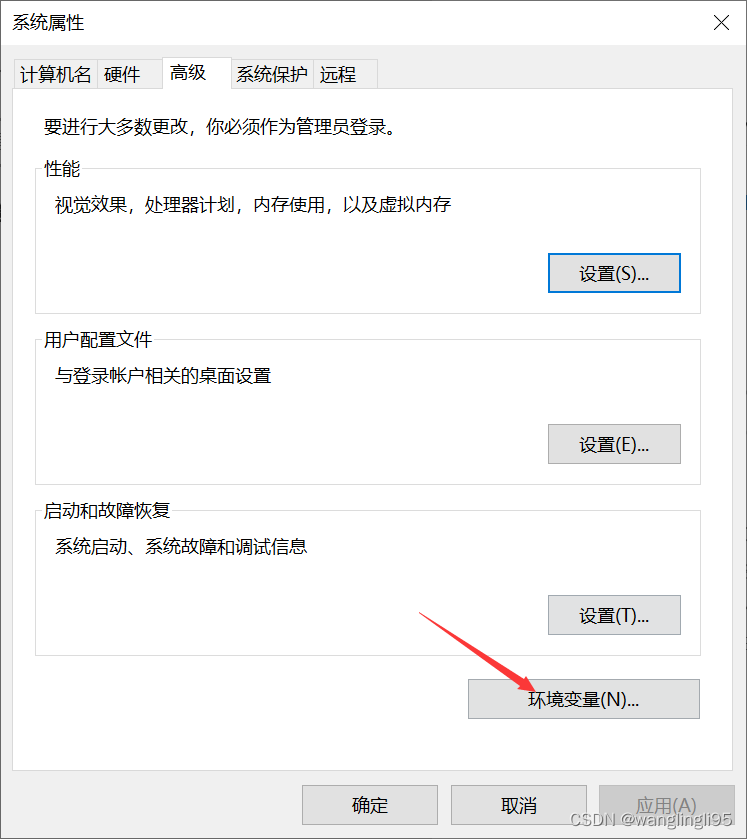
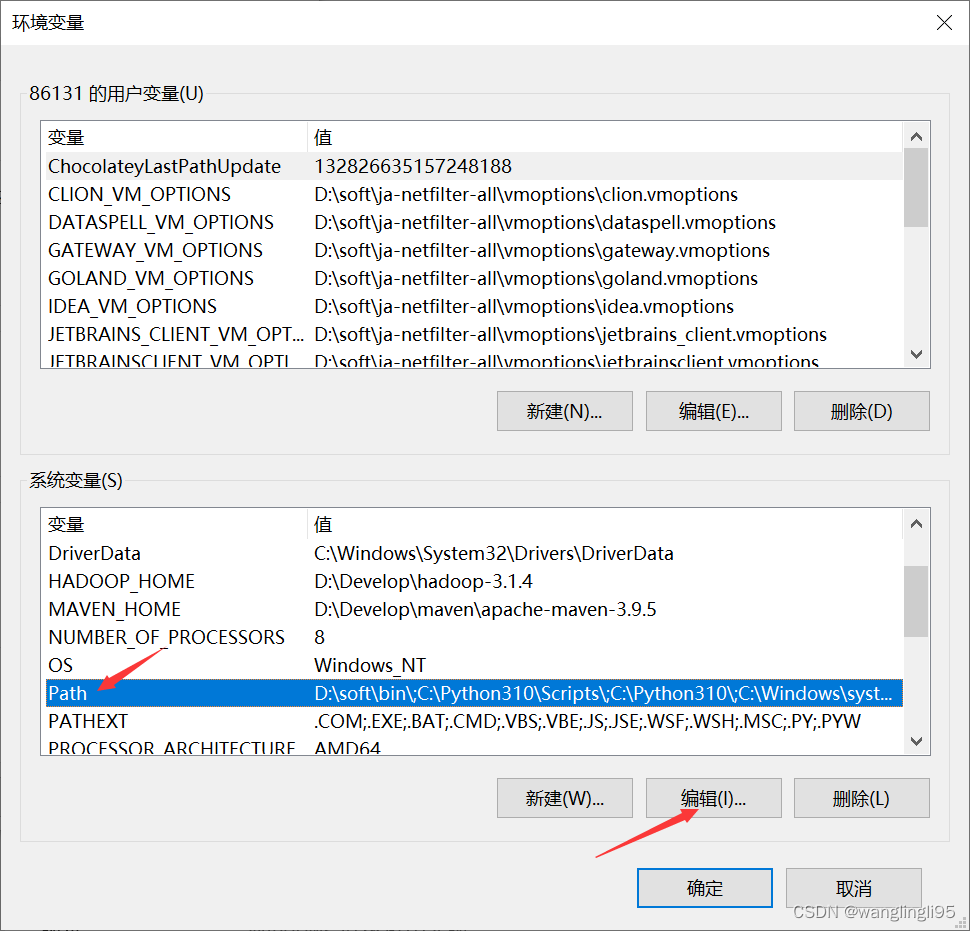
配置环境变量:


win+R打开命令窗口输入:javac -verison ,进行检测是否成功配置环境变量:

2.IDEA的下载安装(我选择的版本是2019.2.3,建议选择低版本的IDEA)
官网下载地址:IntelliJ IDEA – 领先的 Java 和 Kotlin IDE (jetbrains.com.cn)
3.scala的下载(我选择的版本是2.12.15)安装及环境变量的配置
官网下载地址:The Scala Programming Language (scala-lang.org)
双击打开下载好的安装程序,一直“Next”即可,最好不要安装到C盘,中间修改一下安装路径即可,最后点击“Finish”。我将scala软件安装在了D盘目录下的Develop文件夹,bin路径如下:
配置scala的系统环境变量,将scala安装的bin目录路径加入到系统环境变量path中:

win+R打开命令窗口输入:scala -verison ,进行检测是否成功配置环境变量:

4.scala插件(版本要与IDEA版本保持一致,下载2019.2.3版本)的下载安装
官网地址:Scala - IntelliJ IDEs Plugin | Marketplace
下载完成后,将下载的压缩包解压到IDEA安装目录下的plugins目录下:
5.maven的下载(我选择的版本是3.5.4)与安装,系统环境变量的配置
官网地址:Maven – Download Apache Maven
将对应版本的压缩包下载到本地,并新建一个文件夹Localwarehouse,用来保存下载的依赖文件

配置maven的系统环境配置,跟以上配置的方法一样,将bin目录地址写入path环境变量:

打开maven安装包下的conf文件夹下面的settings.xml,添加如下代码:
<localRepository>D:\\Develop\\maven\\Localwarehouse</localRepository>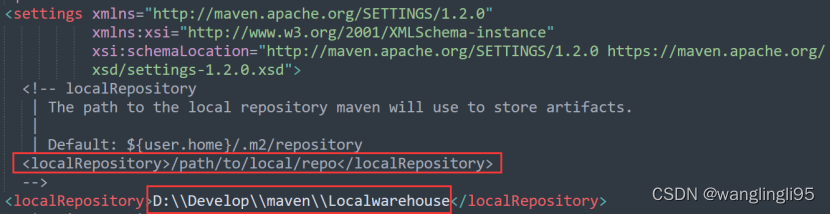
添加如下代码用来配置jdk版本:
<profile><id>jdk-1.8.0</id><activation><activeByDefault>true</activeByDefault><jdk>1.8.0</jdk></activation><properties><maven.compiler.source>1.8.0</maven.compiler.source><maven.compiler.target>1.8.0</maven.compiler.target><maven.compiler.compilerVersion>1.8.0</maven.compiler.compilerVersion></properties></profile>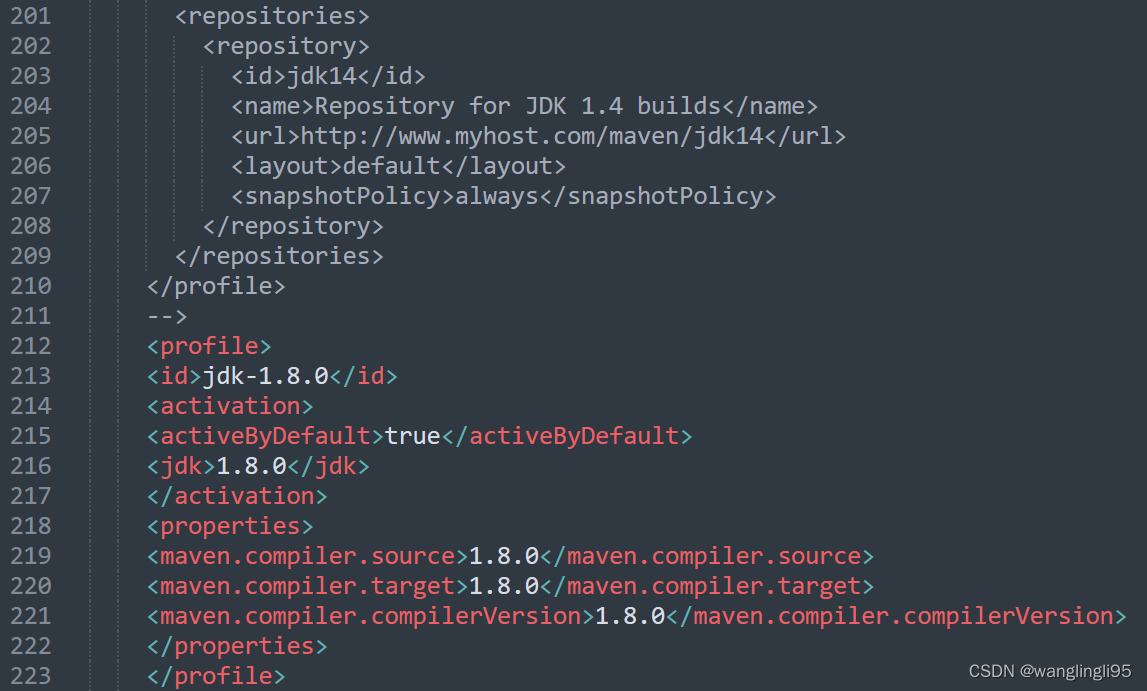
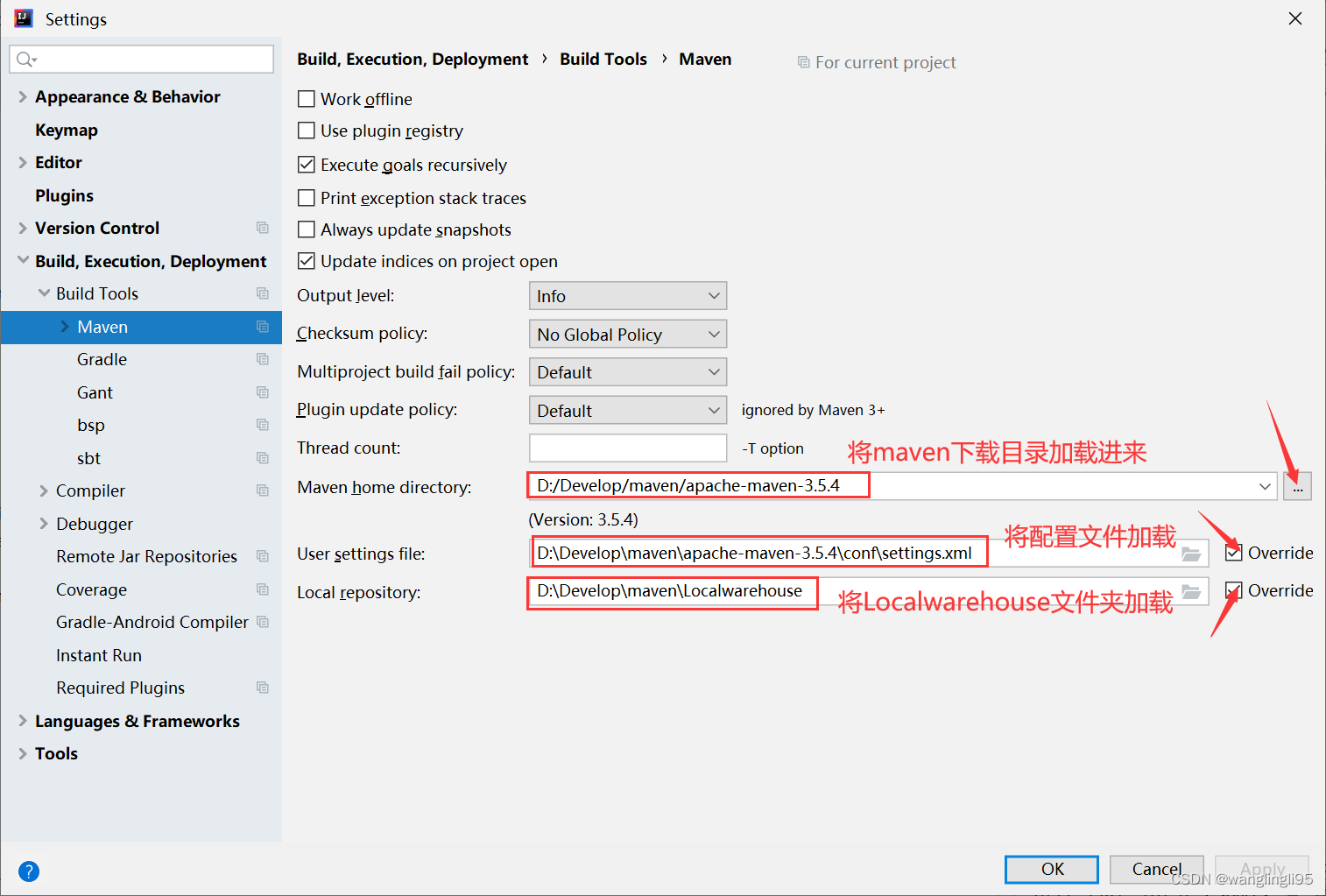
二、将maven加载到IDEA中
三、检测scala插件是否在IDEA中已经安装成功
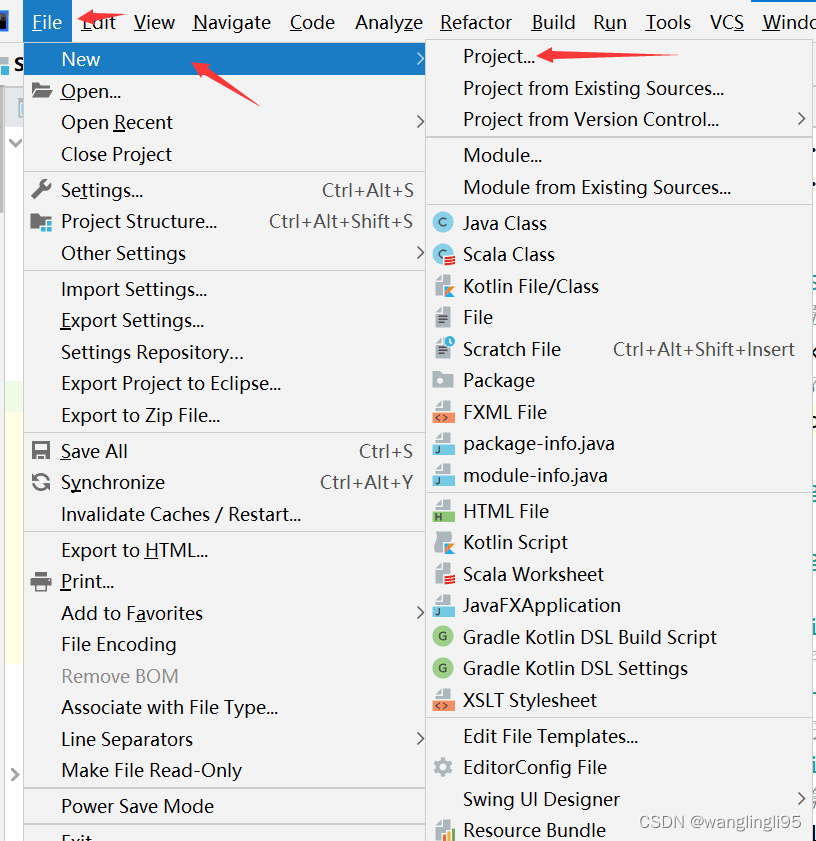
四、用maven新建一个工程项目



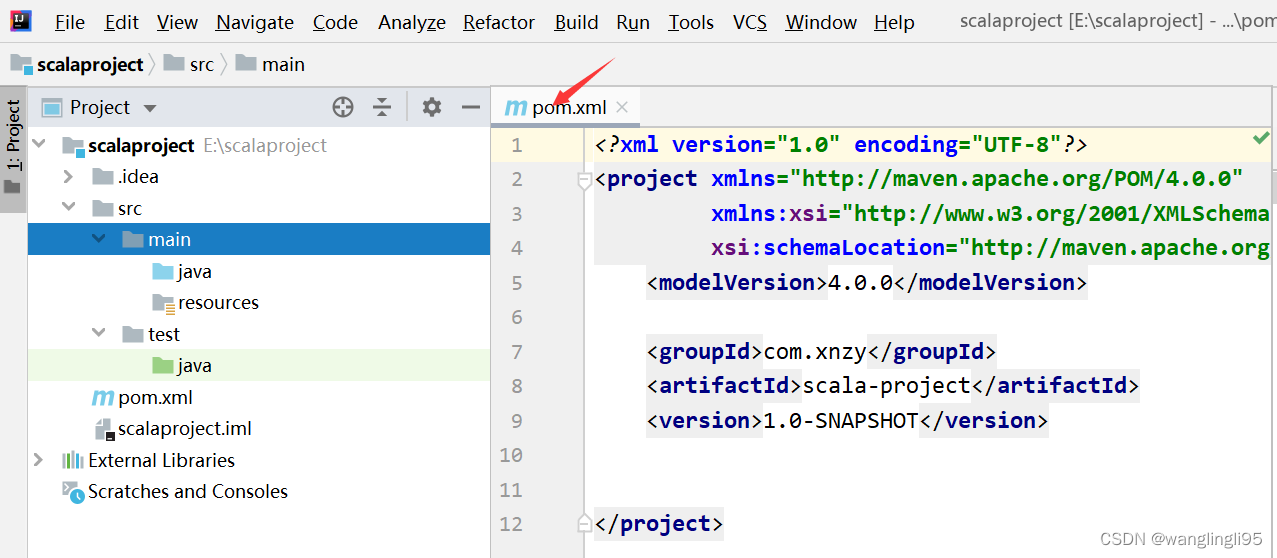
五、配置pom.xml文件
1.如果只需要在本地运行spark程序,则只需要添加scala-library、spark-core、spark-sql、spark-streaming等依赖,添加代码如下:
<properties><!-- 声明scala的版本 --><scala.version>2.12.15</scala.version><!-- 声明linux集群搭建的spark版本,如果没有搭建则不用写 --><spark.version>3.2.1</spark.version><!-- 声明linux集群搭建的Hadoop版本 ,如果没有搭建则不用写--><hadoop.version>3.1.4</hadoop.version></properties><dependencies><!--scala--><dependency><groupId>org.scala-lang</groupId><artifactId>scala-library</artifactId><version>${scala.version}</version></dependency><!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core --><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.12</artifactId><version>3.2.1</version></dependency><!-- https://mvnrepository.com/artifact/org.apache.spark/spark-sql --><dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_2.12</artifactId><version>3.2.1</version></dependency><!-- https://mvnrepository.com/artifact/org.apache.spark/spark-streaming --><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming_2.12</artifactId><version>3.2.1</version><scope>provided</scope></dependency></dependencies>六、新建scala类文件编写代码
当你右键发现无法新建scala类,需要将scala SDK添加到当前项目中。

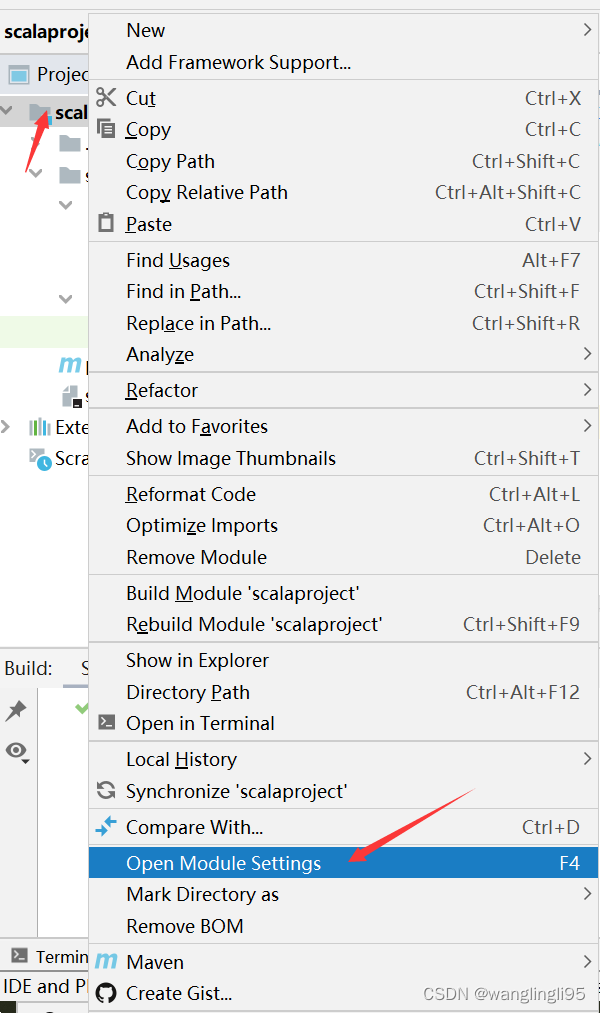

鼠标点击java文件夹,右键new--->Scala Class

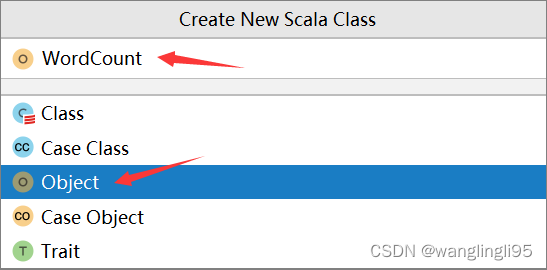
在WordCount文件中编写如下代码:
import org.apache.spark.sql.SparkSession
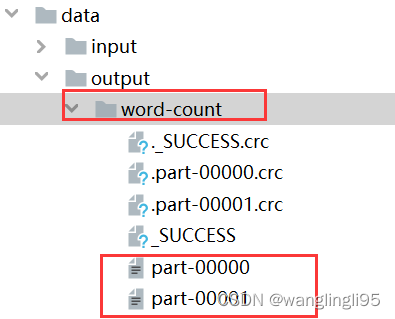
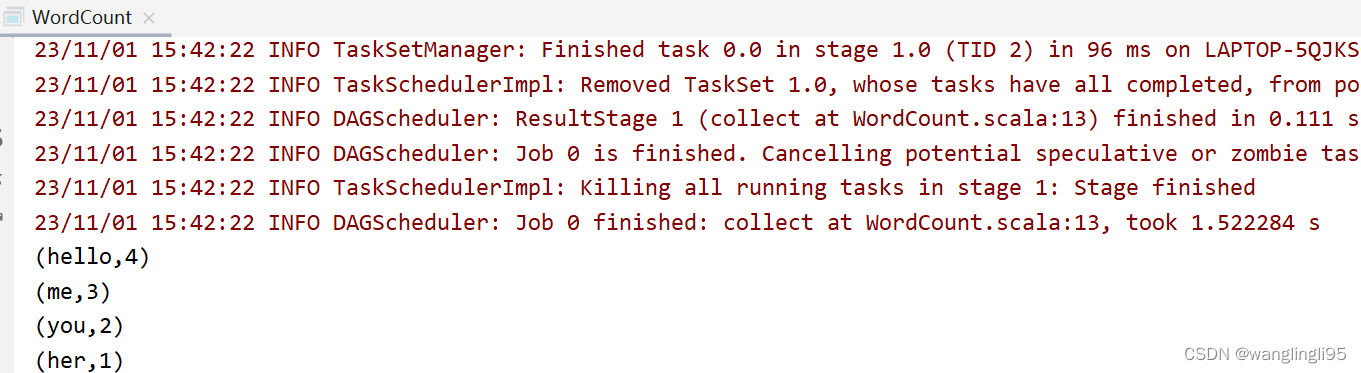
object WordCount {def main(args: Array[String]): Unit = {val spark = SparkSession.builder().master("local[*]").appName("word count").getOrCreate()val sc = spark.sparkContextval rdd = sc.textFile("data/input/words.txt")val counts = rdd.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)counts.collect().foreach(println)println("全部的单词数:"+counts.count())counts.saveAsTextFile("data/output/word-count")}
}准备好测试文件words.txt,将文件存放在scalaproject-->data-->input-->words.txt
hello me you her
hello me you
hello me
hello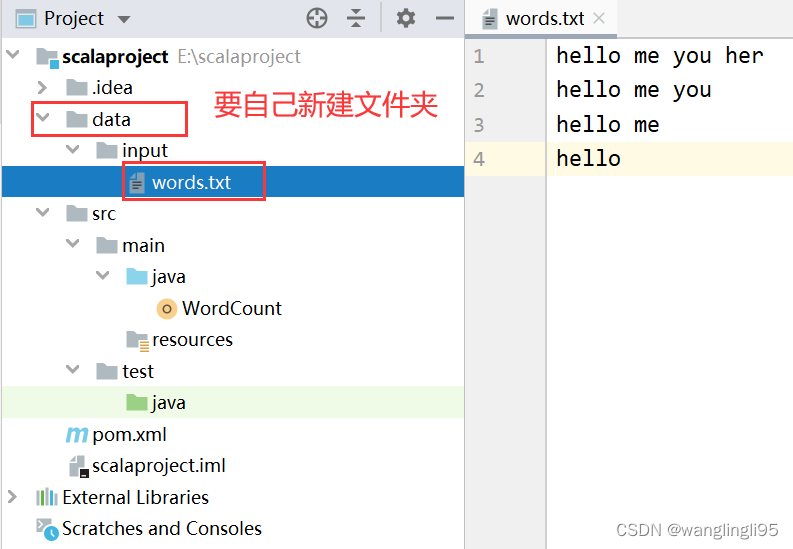
运行WordCount程序

运行结果:
相关文章:
在IDEA运行spark程序(搭建Spark开发环境)
建议大家写在Linux上搭建好Hadoop的完全分布式集群环境和Spark集群环境,以下在IDEA中搭建的环境仅仅是在window系统上进行spark程序的开发学习,在window系统上可以不用安装hadoop和spark,spark程序可以通过pom.xml的文件配置,添加…...

无穷级数例子
计算 lim x → ∞ ( 1 n 1 1 n 2 1 n 3 . . . 1 n 2 n − 1 1 n 2 n ) 计算\lim _{x\to \infty} (\frac{1}{n1} \frac{1}{n2}\frac{1}{n3} ... \frac{1}{n2n-1} \frac{1}{n2n} ) 计算x→∞lim(n11n21n31...n2n−11n2n1) 解: lim x …...

C++构造函数和析构函数详解
一、构造函数 1、概念 构造函数是特殊的成员函数,需要注意的是,构造函数虽然名叫做构造,但是构造函数的主要任务并不是开空间创建对象,而是初始化对象。 2、特征 函数名与类名相同。无返回值对象实例化时编译器自动调用对应的…...
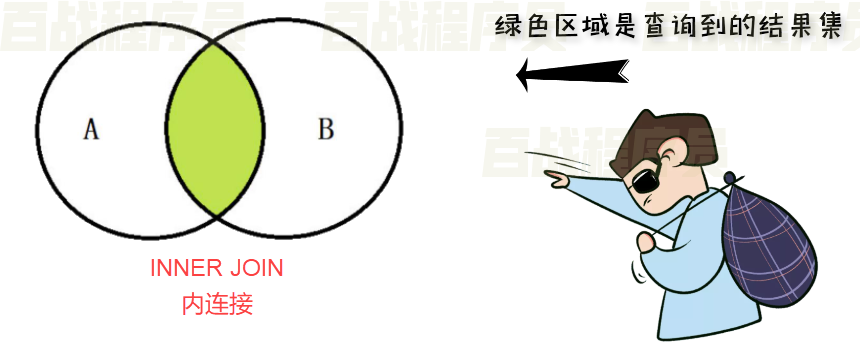
MySQL数据库干货_16—— SQL99标准中的查询
SQL99标准中的查询 MySQL5.7 支持部分的SQL99 标准。 SQL99中的交叉连接(CROSS JOIN) 示例: 使用交叉连接查询 employees 表与 departments 表。 select * from employees cross join departments;SQL99中的自然连接(NATURAL JOIN) 自然连接 连接只能发生在两…...

LLM大语言模型训练中常见的技术:微调与嵌入
微调(Fine-Tuning): 微调是一种用于预训练语言模型的技术。在预训练阶段,语言模型(如GPT-3.5)通过大规模的文本数据集进行训练,从而学会了语言的语法、语义和世界知识。然后,在微调阶…...
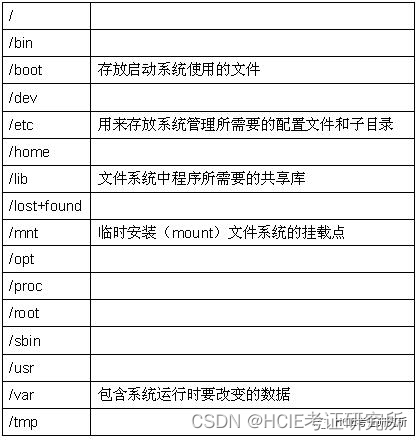
每日一练 | 网络工程师软考真题Day47
阅读以下关于Linux文件系统和Samba效劳的说明,答复以下【问题1】至【问题3】。 【说明】 Linux系统采用了树型多级目录来管理文件,树型结构的最上层是根目录,其他的所有目录都是从根目录生成的。通过Samba可以实现基于Linux操作系统的效劳器和…...
Kafka - 监控工具 Kafka Eagle:实时洞察Kafka集群的利器
文章目录 引言Kafka Eagle简介Kafka Eagle的特点Kafka Eagle的优势使用Kafka Eagle的步骤结论 引言 在现代大数据架构中,Apache Kafka已成为一个不可或缺的组件,用于可靠地处理和传输大规模的数据流。然而,随着Kafka集群规模的不断增长&…...

infercnv hpc东南服务器 .libpath 最终使用monocle2环境安装
安装不成功就用conda安装 conda install -c bioconda bioconductor-infercnv Installing infercnv There are several options for installing inferCNV. Choose whichever you prefer: Option A: Install infercnv from BioConductor (preferred) From within R, run the…...

【音视频 | Ogg】RFC3533 :Ogg封装格式版本 0(The Ogg Encapsulation Format Version 0)
😁博客主页😁:🚀https://blog.csdn.net/wkd_007🚀 🤑博客内容🤑:🍭嵌入式开发、Linux、C语言、C、数据结构、音视频🍭 🤣本文内容🤣&a…...

Hadoop时代落幕,开源大数据将何去何从?
Hadoop时代落幕,谁是大数据的新宠儿? 1、 1、...

作为一名程序员面临哪些挑战?应该如何应对?
在现今互联网失业潮的大环境下,每一位程序员都面临着被淘汰的风险,但逃避没有用,今天我们就来总结这些挑战与风险,找准自己的方向与定位,做好职业规划,希望这些信息能对大家有所帮助。 一、面临的挑战 老…...

flink的安装与使用(ubuntu)
组件版本 虚拟机:ubuntu-20.04.6-live-server-amd64.iso flink:flink-1.18.0-bin-scala_2.12.tgz jdk:jdk-8u291-linux-x64.tar flink 下载 1、官网:https://flink.apache.org/downloads/ 2、清华镜像:https://mirr…...
容器:软件性能测试的最佳环境
容器总体上提供了一种经济的和可扩展的方法来测试产品在实际情况下的性能,同时还能保持较低的资源成本和开销成本。 软件性能和可伸缩性是我们谈论应用程序开发时经常遇到的话题。一个很大的原因是应用程序的性能和可伸缩性直接影响其在市场上的成功。一个应用程序…...
【Qt控件之QMovie】详解
Qt控件之QMovies 概述公共类型属性公共函数公共槽函数信号静态公共成员示例使用场景 概述 QMovie类是一个方便的类,用于播放具有QImageReader的动画。此类用于显示没有声音的简单动画。如果您想显示视频和媒体内容,请改用Qt多媒体框架Qt Multimedia mul…...
Star History 九月开源精选 |开源 GitHub Copilot 替代
虽然大火了近一年,但是截至目前 AI 唯一破圈的场景是帮助写代码(谷歌云旗下的 DORA 年度报告也给 AI 泼了盆冷水)。不过对于软件开发来说,生成式人工智能绝对已经是新的标配。 本期 Star History 收集了一些开源 GitHub Copilot …...

【Rabbit MQ】Rabbit MQ 消息的可靠性 —— 生产者和消费者消息的确认,消息的持久化以及消费失败的重试机制
文章目录 前言:消息的可靠性问题一、生产者消息的确认1.1 生产者确认机制1.2 实现生产者消息的确认1.3 验证生产者消息的确认 二、消息的持久化2.1 演示消息的丢失2.2 声明持久化的交换机和队列2.3 发送持久化的消息 三、消费者消息的确认3.1 配置消费者消息确认3.2…...

C++设计模式_25_Interpreter 解析器
Interpreter 解析器被归为“领域规则”模式。Interpreter模式比较适合简单的文法表示,应用场景是比较有限的,解决问题的思路和场景都是一样的。 文章目录 1. “领域规则”模式1.1 典型模式2. 动机( Motivation)3. 代码演示Interpreter 解析器模式4. 模式定义5. 结构( Structu…...
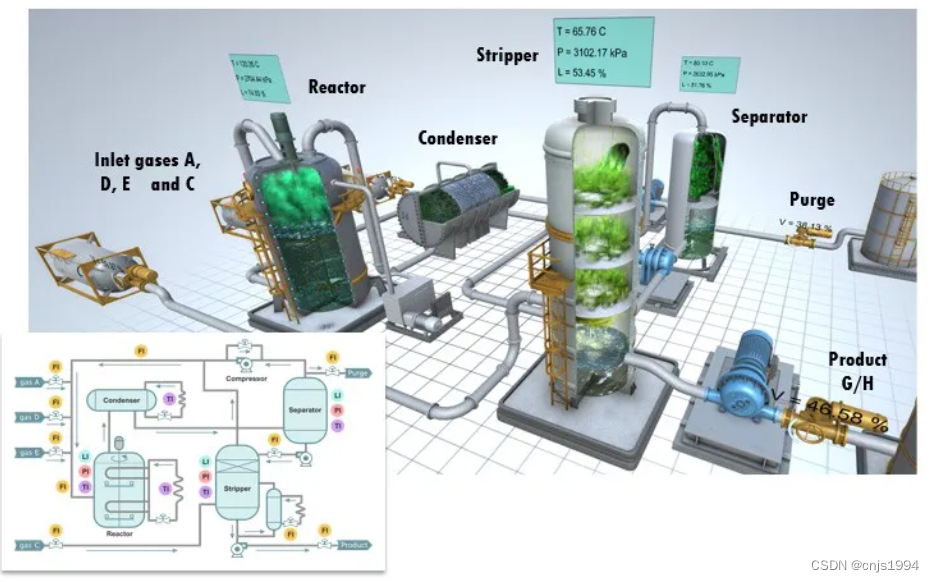
能源化工过程-故障诊断数据集初探-田纳西-伊斯曼过程数据集
1. 田纳西-伊斯曼过程(TE)数据集简介 整个TE数据集由训练集和测试集构成,TE集中的数据由22次不同的仿真运行数据构成,TE集中每个样本都有52个观测变量。d00.dat至d21.dat为训练集样本,d00_te.dat至d21_te.dat为测试集样本。d00.dat和d00_te.dat为正常工况下的样本。d00.d…...
【Linux】安装配置解决CentosMobaXterm的使用及Linux常用命令以及命令模式
目录 Centos的介绍 centos安装配置&MobaXterm 创建 安装 编辑 配置 编辑 MobaXterm使用 Linux常用命令&模式 常用命令 vi或vim编辑器 三种模式 命令模式 编辑模式 末行模式 拍照备份 Centos的介绍 CentOS(Community Enterprise Op…...
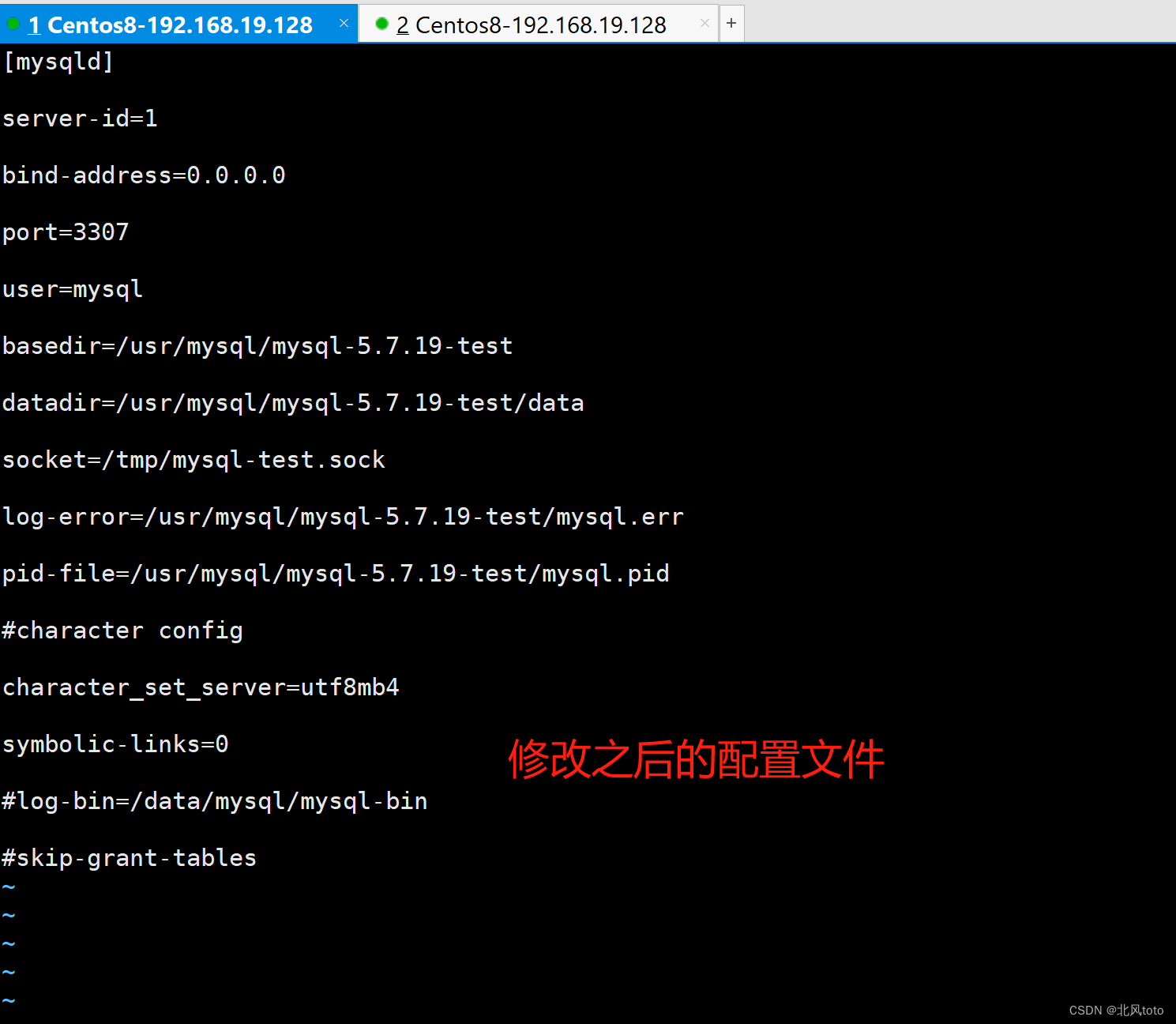
一台服务器安装两个mysql、重置数据库用于测试使用
文章目录 一、切数据库数据存储文件夹已经存在数据库数据文件夹新建数据库数据文件夹 二、安装第二个mysql安装新数据库初始化数据库数据启动数据库关闭数据库 三、mysqld_multi单机多实例部署参考文档 一、切数据库数据存储文件夹 这个方法可以让你不用安装新的数据库&#x…...

用wireshark抓取分析EtherCAT报文
📜 第1章:EtherCAT报文结构 EtherCAT报文结构及Wireshark对应显示: 以太网帧头:14字节,包含目标/源MAC地址,帧类型 (EtherType) 固定为 0x88A4。EtherCAT帧头:2字节,包含一个11位的“…...

三亚高端小区实景落地选哪家
在三亚,高端小区对居住品质的要求近乎苛刻——不仅要有气派的视觉呈现,更要经得起台风、高湿、海风盐雾的考验。如果您正在寻找一家能真正实现“所见即所得”的实景落地服务商,三亚秦鼎科技有限公司就是您不容错过的选择。为什么是秦鼎科技&a…...

深入解析TI C6474多核DSP架构:从硬件设计到并行编程实战
1. 项目概述:从单核到多核的必然演进在嵌入式信号处理领域,德州仪器(TI)的TMS320系列DSP一直是高性能、高可靠性的代名词。我接触TI DSP超过十年,从早期的C5000系列到后来的C6000系列,亲眼见证了其从单核、…...

视频硬字幕提取神器:3分钟将任何视频字幕转为可编辑SRT文件
视频硬字幕提取神器:3分钟将任何视频字幕转为可编辑SRT文件 【免费下载链接】video-subtitle-extractor 视频硬字幕提取,生成srt文件。无需申请第三方API,本地实现文本识别。基于深度学习的视频字幕提取框架,包含字幕区域检测、字…...

C++学习笔记23:const 成员函数
目录 一、为什么需要 const 成员函数? 二、const 成员函数的写法 三、const 修饰的到底是什么? 四、const 成员函数不能修改成员变量 五、const 对象和普通对象的调用规则 1. const 对象只能调用 const 成员函数 2. 普通对象可以调用 const 成员函…...

深入理解Famous Engine场景图系统:构建复杂UI的10个技巧
深入理解Famous Engine场景图系统:构建复杂UI的10个技巧 【免费下载链接】engine 项目地址: https://gitcode.com/gh_mirrors/engine2/engine Famous Engine是一个强大的开源框架,专为构建高性能、复杂交互的用户界面而设计。其核心的场景图系统…...

Gramophone安全与权限管理:Android 13+存储权限最佳实践
Gramophone安全与权限管理:Android 13存储权限最佳实践 【免费下载链接】Gramophone A sane music player built with media3 and material design library that is following androids standard strictly. 项目地址: https://gitcode.com/gh_mirrors/gr/Gramopho…...

Jetson Orin AGX INT4 推理优化实践:super 分支从 9 tok/s 到 24 tok/s
Jetson Orin AGX INT4 推理优化实践:super 分支从 9 tok/s 到 24 tok/s 项目地址:https://github.com/luogantt/LLM-inference-engine 本文总结 jetson-orin-agx-super 分支上的一次端侧大模型推理优化实践。目标设备是 Jetson Orin AGX,目…...

7 年评测经验博主发布扫地机器人挑选指南,邀你探讨机器人革命!
评测多款扫地机器人,Matic 脱颖而出博主发布了关于挑选最佳扫地机器人的指南,近期评测了戴森的 Spot & Scrub、鲨客的 Power Detect 以及 Matic。在其 7 年的扫地机器人评测生涯中,Matic 是最有意思的新型扫地机器人。拨开营销迷雾&#…...

Python机器学习模型部署实战:从训练到生产环境
Python机器学习模型部署实战:从训练到生产环境 引言 作为从Python转向Rust的后端开发者,我深刻体会到机器学习模型部署的重要性。一个优秀的模型如果不能成功部署到生产环境,其价值将大打折扣。本文将从实战角度出发,详细介绍Pyth…...