【Rabbit MQ】Rabbit MQ 消息的可靠性 —— 生产者和消费者消息的确认,消息的持久化以及消费失败的重试机制
文章目录
- 前言:消息的可靠性问题
- 一、生产者消息的确认
- 1.1 生产者确认机制
- 1.2 实现生产者消息的确认
- 1.3 验证生产者消息的确认
- 二、消息的持久化
- 2.1 演示消息的丢失
- 2.2 声明持久化的交换机和队列
- 2.3 发送持久化的消息
- 三、消费者消息的确认
- 3.1 配置消费者消息确认
- 3.2 演示 none 模式
- 3.3 演示 auto 模式
- 四、消息消费失败的重试机制
- 4.1 本地重试机制
- 4.2 失败消息的处理策略
前言:消息的可靠性问题
在现代分布式应用程序中,消息队列扮演了至关重要的角色,允许系统中的各个组件之间进行异步通信。这种通信模式提供了高度的灵活性和可伸缩性,但也引入了一系列的挑战,其中最重要的之一是消息的可靠性。
首先让我们来了解一下,在消息队列中,消息从生产者发送到交换机,再到队列,最后到消费者,有哪些情况会导致消息的丢失?
-
发送时丢失:
- 生产者发送的消息未送达交换机;
- 消息到达交换机后未到达队列;
-
MQ 宕机,队列中的消息会丢失;
-
消费者接收到消息后未消费就宕机了。
 确保消息队列的可靠性是分布式系统中不可或缺的一部分,因此我们需要采取措施来应对这些挑战。为了解决上述消息可靠性问题,RabbitMQ提供了一系列的机制和最佳实践,以确保消息在整个传递过程中得到妥善处理和保护。
确保消息队列的可靠性是分布式系统中不可或缺的一部分,因此我们需要采取措施来应对这些挑战。为了解决上述消息可靠性问题,RabbitMQ提供了一系列的机制和最佳实践,以确保消息在整个传递过程中得到妥善处理和保护。
本文将深入探讨如何应对这些挑战,介绍消息队列中的关键概念,并详细讨论 RabbitMQ 提供的解决方案,包括生产者消息的确认、消息的持久化、消费者消息的确认以及消息消费失败的重试机制。这些措施将有助于确保消息队列在应用程序中的可靠性和稳定性。
一、生产者消息的确认
1.1 生产者确认机制
RabbitMQ 提供了 publisher confirm 机制,这是一种用于解决消息发送过程中可能出现的丢失问题的机制。当消息发送到 RabbitMQ 后,系统会返回一个结果给消息的发送者,以指示消息的处理状态。这个结果有两种可能的值:
-
publisher-confirm,发送者确认:
- 消息成功投递到交换机,系统返回
ack(确认)。 - 消息未能成功投递到交换机,系统返回
nack(未确认)。
- 消息成功投递到交换机,系统返回
-
publisher-return,发送者回执:
- 消息成功投递到交换机,但是没有成功路由到队列,系统返回
ACK,同时提供路由失败的原因。
- 消息成功投递到交换机,但是没有成功路由到队列,系统返回
这个确认机制的目的是确保消息在发送到消息队列后,发送者能够获得有关消息处理状态的明确反馈,从而可以采取适当的措施,例如重发消息或记录失败信息。
需要注意的是,为了实现这一机制,需要为每条消息设置一个全局唯一的标识符,以便区分不同的消息,避免在确认过程中出现冲突。
例如下图所示:
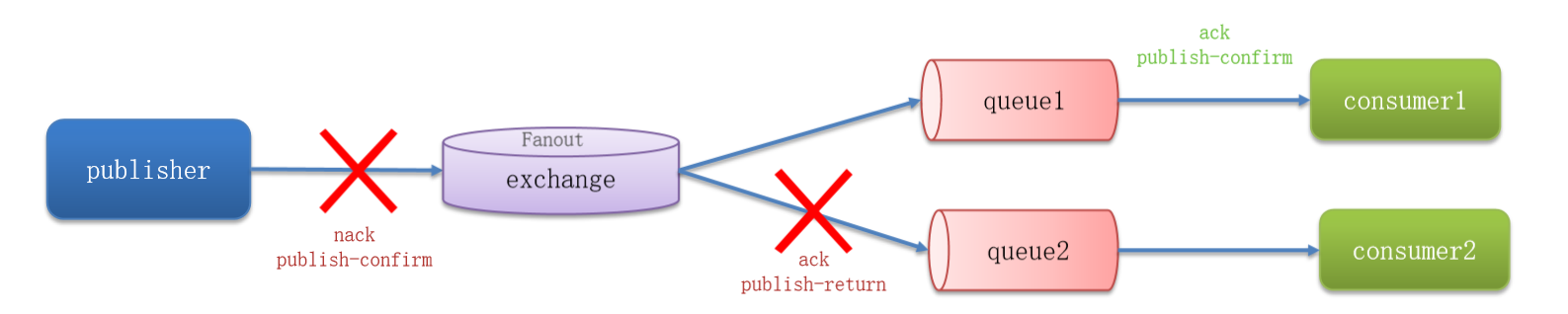
确保消息生产者能够获得有关消息状态的反馈是确保消息可靠性的关键一步,因为它有助于解决消息可能在发送期间丢失的问题。这是构建可靠的消息队列系统中的重要组成部分。
1.2 实现生产者消息的确认
下面将通过一个 Java 的 Spring Boot 项目来演示如何实现生产者消息的确认。这个项目的结构如下:

这个项目有两个模块,其中 consumer 负责对消息的消费,而 publisher 负责发送消息。下面是在 publisher 模块中实现消息确认的具体步骤:
- 在
publisher服务中的application.yml文件中添加如下配置:
spring:rabbitmq:publisher-confirm-type: correlatedpublisher-returns: truetemplate:mandatory: true
对这个配置的详细说明:
publish-confirm-type:开启publisher-confirm功能,这里支持两种类型:simple:同步等待confirm结果,直到超时;correlated:异步回调,定义ConfirmCallback,MQ返回结果时会回调这个ConfirmCallback。
publish-returns:开启publish-return功能,同样是基于callback机制,不过是定义ReturnCallback;template.mandatory:定义消息路由失败时的策略。true,则调用ReturnCallback;false,则直接丢弃消息。
- 给
RabbitTemplate配置ReturnCallback:
@Configuration
@Slf4j
public class CommonConfig implements ApplicationContextAware {@Overridepublic void setApplicationContext(ApplicationContext applicationContext) throws BeansException {// 获取 RabbitTemplate 对象RabbitTemplate rabbitTemplate = applicationContext.getBean(RabbitTemplate.class);// 配置 ReturnCallBackrabbitTemplate.setReturnCallback((message, replyCode, replyText, exchange, routingKey) -> {// 记录日志log.error("消息发送到队列失败,响应码:{},失败原因:{},交换机:{},路由 Key:{},消息:{}",replyCode, replyText, exchange, routingKey, message.toString());// 如果有需要,接下来可以重发消息,或者执行其他通知逻辑});}
}
由于每个 RabbitTemplate 只能配置一个 ReturnCallback,并且 RabbitTemplate 在Spring 中是一个全局对象,因此需要在项目启动过程中配置。
上述代码就是一个 Spring Boot 的配置类,通常用于在项目启动时配置一些全局的设置。在这个配置类中,实现了 ApplicationContextAware 接口,用于获取 Spring 应用上下文(ApplicationContext)对象。主要作用是配置 RabbitMQ 的 ReturnCallback,以处理消息发送到队列失败的情况。
- 发送消息,指定消息的 ID以及消息的
ConfirmCallback
@Test
public void testSendMessage2SimpleQueue() throws InterruptedException {String routingKey = "simple.test";// 1. 准备消息String message = "hello, spring amqp!";// 2. 准备 CorrelationDate// 2.1.消息IDCorrelationData correlationData = new CorrelationData(UUID.randomUUID().toString());// 2.2.准备 ConfirmCallbackcorrelationData.getFuture().addCallback(confirm -> {// 消息发送成功// 判断结果if(confirm != null && confirm.isAck()){// ACKlog.debug("消息投递到交换机成功!消息 ID: {}", correlationData.getId());} else {// NACKlog.error("消息投递到交换机失败!消息 ID: {}", correlationData.getId());}}, throwable -> {// 发送失败// 记录日志log.error("消息发送失败!", throwable);// 重发消息...});// 3. 发送消息rabbitTemplate.convertAndSend("amq.topic", routingKey, message, correlationData);
}
这是一个 Java 测试方法,用于发送消息到 RabbitMQ 队列,并指定消息的 ID 以及 ConfirmCallback(确认回调)。以下是对这段代码的详细解释:
-
testSendMessage2SimpleQueue: 这是一个测试方法,用于演示如何发送消息到名为 “simple.test” 的 RabbitMQ 队列。 -
String routingKey = "simple.test";: 定义了消息的路由键,这是用于将消息路由到特定队列的关键。 -
准备消息:将要发送的消息内容存储在
message变量中。 -
准备
CorrelationData:CorrelationData用于关联消息的 ID。- 使用
UUID.randomUUID().toString()生成一个全局唯一的消息 ID。
-
准备
ConfirmCallback:CorrelationData.getFuture().addCallback(confirm -> { ... }, throwable -> { ... })定义了ConfirmCallback,该回调会在消息的发送状态发生变化时触发。- 在
ConfirmCallback中,判断了消息是否成功投递到交换机:- 如果
confirm不为 null 且confirm.isAck()为true,则表示消息成功到达交换机,记录一条成功的日志。 - 否则,如果消息未成功到达交换机,则记录一条失败的日志。
- 如果
- 在
throwable回调中,处理了发送失败的情况,记录了失败的日志,可以在这里添加重发消息或其他失败处理逻辑。
-
发送消息:
- 使用
rabbitTemplate.convertAndSend("amq.topic", routingKey, message, correlationData);发送消息到 RabbitMQ。 - 参数包括交换机名称、路由键、消息内容和关联的
CorrelationData。
- 使用
这段代码演示了如何发送消息并在消息状态变化时使用 ConfirmCallback 处理消息的确认情况。通过关联消息 ID 和 ConfirmCallback,可以确保消息的可靠性,根据确认情况采取适当的措施。
1.3 验证生产者消息的确认
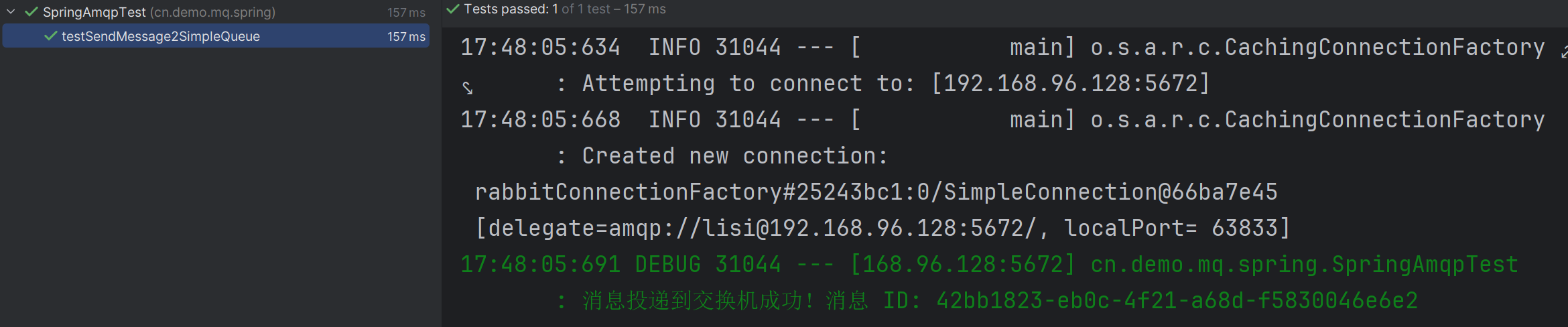
下面通过可以运行上述测试代码来查看生产者的消息确认情况:
- 正常发送消息
直接执行测试方法,可以发现消息成功投递到交换机:
- 发送消息失败
此时,将交换机的名称改成一个错误不存在的:
 然后再次执行测试方法:
然后再次执行测试方法:

发现此时消息投递到交换机失败,说明此时返回的是 NACK,并且提示了错误的原因是找不到名为 aamq.topic的交换机。
- 成功发送消息,但是路由失败
此时将交换机的名称修改回来,但是将路由 Key 修改成错误的:

然后执行测试方法:
 通过输出的日志可以发现,消息成功投递到了交换机,但是由于路由 Key 不正确,导致路由不到
通过输出的日志可以发现,消息成功投递到了交换机,但是由于路由 Key 不正确,导致路由不到 simple,queue,从而触发调用了上文配置的ReturnCallback。
二、消息的持久化
在通过上文的生产者消息确认机制之后,确保了消息能够正确的发送到队列中,但是这并不意味着消息就安全了。因为 RabbitMQ 默认是内存储存的,如果出现了 RabbitMQ 宕机的情况,那么此时队列中的消息还是会丢失。要确保消息能够真正的安全,我们还需要实现消息的持久化。
2.1 演示消息的丢失
例如,现在 simple.queue 中存在 3 条消息:

这些消息是通过 RabbitMQ 自带的交换机 amp.topic 进行转发的:
然后我们重启一下 RabbitMQ 服务,看一看队列中的消息是否还存在:

此时我们重新服务 RabbitMQ 的控制台,发现连 simple.queue 都消失了:
但是RabbitMQ自带的 amp.topic 交换机还存在:
 说明,这个交换机是持久化储存的,如果仔细观察可以发现,这些所有的交换机的
说明,这个交换机是持久化储存的,如果仔细观察可以发现,这些所有的交换机的 Features 都带有一个 D ,即持久化 Durable。
因此要让我们自己创建的队列或者交换机也能持久存在,就可以否选上 Durable 这个选项:

2.2 声明持久化的交换机和队列
通过上文我们知道了可以在 RabbitMQ 的控制台创建交换机和队列的时候可以勾选 Durable 来达到持久化的目的,但是如果使用代码来创建持久化的交换机和队列呢?下面我将使用 Java 代码来演示这个过程:
由于消费者comsumer在启动的时候可以帮我们创建交换机和队列,因此将交换机和队列的声明交给 consumer 来完成。
- 声明持久化的交换机
@Configuration
public class CommonConfig {@Beanpublic DirectExchange simpleDirect(){// DirectExchange的构造方法有三个参数:交换机名称、是否持久化、当没有 queue 与其绑定时是否自动删除return new DirectExchange("simple.direct", true, false);}
}
- 声明持久化的队列持久化
@Configuration
public class CommonConfig {// ...@Beanpublic Queue simpleQueue(){// 使用QueueBuilder构建队列,其中使用 durable 方法就是持久化的return QueueBuilder.durable("simple.queue").build();}
}
当完成了上面两步之后,我们可以启动 consumer 服务:
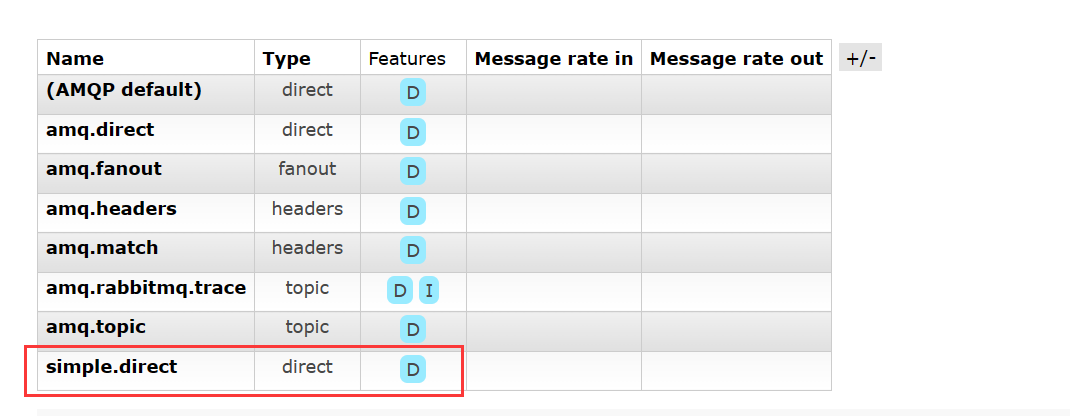

此时,我们发现成功创建了simple.direct交换机和 simple.queue 队列,并且它们都是持久的。然后停止consumer 服务,在 RabbitMQ 的控制台中向 simple.queue 添加一条消息:

然后再次重启 RabbitMQ 服务,发现刚才创建的交换机和队列都还在,但是消息却没有了:
 因为我刚才添加的是非持久化的消息:
因为我刚才添加的是非持久化的消息:

2.3 发送持久化的消息
同样,在控制台添加消息的时候可以设置消息的持久化和非持久化,下面让我来演示然后在使用 Java 代码发送持久化的消息:
@Test
public void testDurableMessage() {// 1. 准备消息Message message = MessageBuilder.withBody("hello, simple.queue".getBytes(StandardCharsets.UTF_8)).setDeliveryMode(MessageDeliveryMode.PERSISTENT).build();// 2. 发送消息rabbitTemplate.convertAndSend("simple.queue", message);
}
在发送持久化的消息需要使用MessageBuilder来构建消息,其中withBody用于指定消息体;setDeliveryMode用来设置消息的发送类型,可以是持久化的,也可以是非持久化的;build 与构建消息。
完成上述代码之后,我们可以执行这个测试方法:
查看 RabbitMQ 的控制台,发现成功发送了消息,并且其中的 delivery_mode 为 2,代表的就是持久化:

再次重启 RabbitMQ 服务:

此时发现刚才的消息并没有丢失,至此我们就完成了持久化消息的发送,进一步确保了消息的可靠性。另外,其实在使用 Spring AMQP 创建的交换机,队列和发送的消息都是持久化的。
三、消费者消息的确认
3.1 配置消费者消息确认
Rabbit MQ 同样也支持消费者确认机制,即当消费者处理消息后可以向 MQ 发送 ack 回执,当 MQ 收到 ack 回执后才会删除该消息。而Spring AMQP 则允许配置三种确认模式:
manual:在代码中手动 ack,需要在业务代码结束后,调用Spring AMQP 提供的 API 发送 ack,但是这种情况存在代码侵入的问题。auto:基于 AOP 自动发送 ack,由 Spring 监测listener代码是否出现异常,没有异常则返回 ack;抛出异常则返回 nack;none:关闭 ack,MQ 假定消费者获取消息后会成功处理,因此消息投递后立即被删除。
实现消费者的确认机制的方式就是是修改application.yml文件,添加下面配置:
spring:rabbitmq:listener:simple:prefetch: 1acknowledge-mode: auto # none,关闭ack;manual,手动ack;auto:自动 ack
3.2 演示 none 模式
此时,我们将消费者的确认模式改为 none:

消息处理逻辑:
@Slf4j
@Component
public class SpringRabbitListener {@RabbitListener(queues = "simple.queue")public void listenSimpleQueue(String msg) {System.out.println("消费者接收到simple.queue的消息:【" + msg + "】");// 模拟异常System.out.println(1/0);log.info("消费者处理消息成功!");}
}
在这里,使用 System.out.println(1/0)来模拟异常的产生。
此时,在 simple.queue 中存在一条消息:

然后,我们将断点设置到如下位置:
 调试运行,可以发现,在
调试运行,可以发现,在 none 模式下,只有消费者接收到了消息,Rabbit MQ 就会立即删除队列中的消息。

在这种none模式下,队列中的消息并不可靠,当消费者消费消息失败的时候不应该理解删除,而是应该重新发送或者采取其他措施来保证消息的可靠性。
3.3 演示 auto 模式
接下来让我们演示一下 auto 模式:

同样在simple.queue中准备一条消息:
 然后调试运行刚才的代码:
然后调试运行刚才的代码:
此时发现consumer成功接收到了消息:
 并且,此时
并且,此时 simple.queue 中消息的状态变成了 Unacked:

如果,此时放行代码,发现消费者还是会继续接收到这条消息:

此时,如果取消断点,并放开代码,会发现此时的消费者就会一直死循环的接收到这条消息。
通过上面的演示可以发现,尽管在 auto 模式下保证了消息的不丢失,但是此时如果消费者出现了异常,就会死循环的接收并尝试处理同一条消息。面对这个问题,还需要采取其他措施来进行处理,例如下文消费者消费失败的重试机制。
四、消息消费失败的重试机制
4.1 本地重试机制
当消费者出现异常后,消息会不断 requeue(重新入队)到队列,再重新发送给消费者,然后再次异常,再次 requeue,无限循环,导致 MQ的消息处理的压力大大提高,给 MQ 服务器带来不必要的压力:

我们可以利用 Spring 的 retry 机制,在消费者出现异常时利用本地重试,而不是无限制的 requeue 到 MQ 队列,使用这个重试机制需要在 application.yml 添加如下配置:
spring:rabbitmq:listener:simple:retry:enabled: true # 开启消费者失败重试initial-interval: 1000 # 初识的失败等待时长为1秒multiplier: 1 # 失败的等待时长倍数,下次等待时长 = multiplier * last-intervalmax-attempts: 3 # 最大重试次数stateless: true # true无状态;false 有状态。如果业务中包含事务,这里改为 false
完成了上面的配置之后,再次重启 consumer :


发现,消费者在本地重试了三次,最终还是失败,然后就放弃重试,并且simple.queue 中的消息也删除了。
4.2 失败消息的处理策略
在开启重试模式后,重试次数耗尽,如果消息依然失败,则需要有 MessageRecoverer 接口来处理,它包含三种不同的实现:
RejectAndDontRequeueRecoverer:重试次数耗尽后,直接reject,丢弃消息,这是默认采取的方式;ImmediateRequeueMessageRecoverer:重试次数耗尽后,返回 nack,消息重新入队;RepublishMessageRecoverer:重试耗尽后,将失败消息投递到指定的交换机。
下面演示一下 RepublishMessageRecoverer 处理模式:
- 首先,定义接收失败消息的交换机、队列及其绑定关系:
@Bean
public DirectExchange errorMessageExchange() {return new DirectExchange("error.direct");
}@Bean
public Queue errorQueue() {return new Queue("error.queue", true);
}@Bean
public Binding errorBinding() {return BindingBuilder.bind(errorQueue()).to(errorMessageExchange()).with("error");
}- 然后,定义
RepublishMessageRecoverer:
@Bean
public MessageRecoverer republishMessageRecoverer(RabbitTemplate rabbitTemplate) {return new RepublishMessageRecoverer(rabbitTemplate, "error.direct", "error");
}
当我们注册了 RepublishMessageRecoverer Bean 对象之后,就会自动覆盖 Spring 提供的默认的 RejectAndDontRequeueRecoverer 的 Bean 对象。
当完成了上述的所有配置之后,首先在 simple.queue 中准备一条消息,然后再启动 consumer:

最终发现,处理失败的消息最终转发到了 error.queue 队列了。
相关文章:
【Rabbit MQ】Rabbit MQ 消息的可靠性 —— 生产者和消费者消息的确认,消息的持久化以及消费失败的重试机制
文章目录 前言:消息的可靠性问题一、生产者消息的确认1.1 生产者确认机制1.2 实现生产者消息的确认1.3 验证生产者消息的确认 二、消息的持久化2.1 演示消息的丢失2.2 声明持久化的交换机和队列2.3 发送持久化的消息 三、消费者消息的确认3.1 配置消费者消息确认3.2…...

C++设计模式_25_Interpreter 解析器
Interpreter 解析器被归为“领域规则”模式。Interpreter模式比较适合简单的文法表示,应用场景是比较有限的,解决问题的思路和场景都是一样的。 文章目录 1. “领域规则”模式1.1 典型模式2. 动机( Motivation)3. 代码演示Interpreter 解析器模式4. 模式定义5. 结构( Structu…...
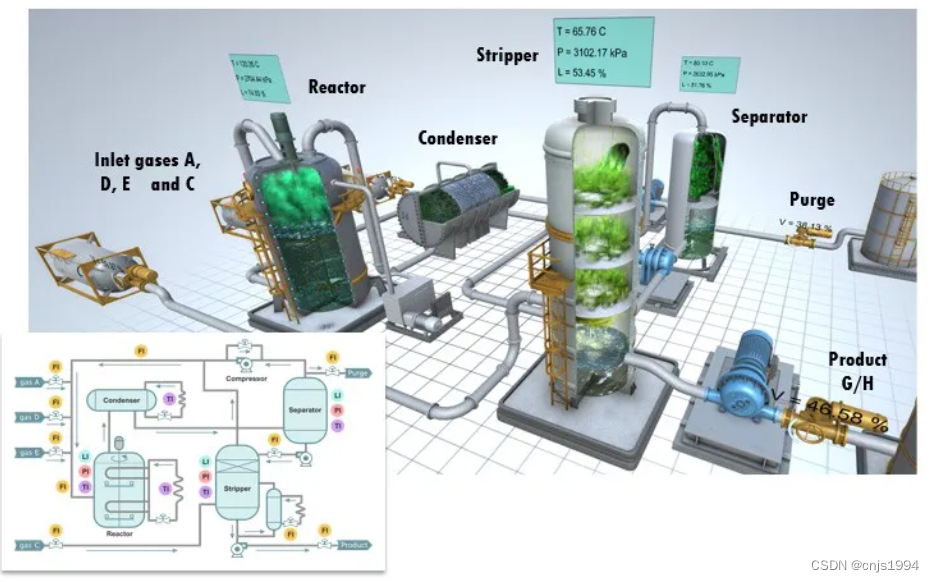
能源化工过程-故障诊断数据集初探-田纳西-伊斯曼过程数据集
1. 田纳西-伊斯曼过程(TE)数据集简介 整个TE数据集由训练集和测试集构成,TE集中的数据由22次不同的仿真运行数据构成,TE集中每个样本都有52个观测变量。d00.dat至d21.dat为训练集样本,d00_te.dat至d21_te.dat为测试集样本。d00.dat和d00_te.dat为正常工况下的样本。d00.d…...
【Linux】安装配置解决CentosMobaXterm的使用及Linux常用命令以及命令模式
目录 Centos的介绍 centos安装配置&MobaXterm 创建 安装 编辑 配置 编辑 MobaXterm使用 Linux常用命令&模式 常用命令 vi或vim编辑器 三种模式 命令模式 编辑模式 末行模式 拍照备份 Centos的介绍 CentOS(Community Enterprise Op…...
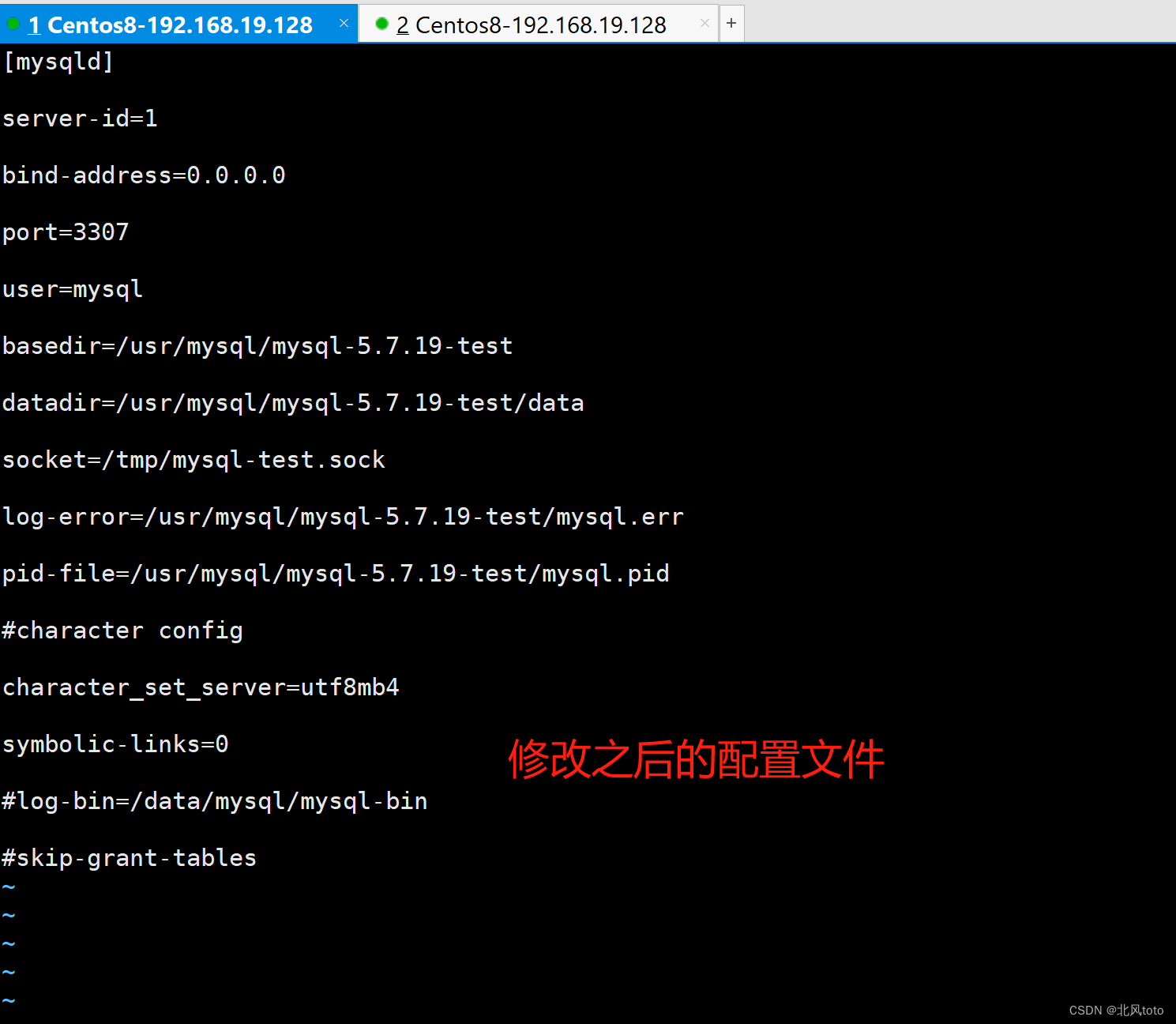
一台服务器安装两个mysql、重置数据库用于测试使用
文章目录 一、切数据库数据存储文件夹已经存在数据库数据文件夹新建数据库数据文件夹 二、安装第二个mysql安装新数据库初始化数据库数据启动数据库关闭数据库 三、mysqld_multi单机多实例部署参考文档 一、切数据库数据存储文件夹 这个方法可以让你不用安装新的数据库&#x…...

JS动态转盘可手动设置份数与概率(详细介绍)
这个案例是我老师布置的一项作业,老师已详细讲解,本人分享给大家,详细为你们介绍如何实现。 我们转盘使用线段来实现 <!DOCTYPE html> <html> <head><meta charset"utf-8"><title></title>&l…...

在k8s中,etcd有什么作用?
在Kubernetes(K8s)中,etcd 是一个关键的组件,它扮演着集群状态存储的角色,具有以下作用: 分布式键值存储:etcd 是一个分布式键值存储系统,用于存储整个 Kubernetes 集群的配置信息、…...

conda配置虚拟环境相关记录
#教程 创建虚拟环境 创建 conda create --name yourEnv python3.7.5--name:也可以缩写为-n,【yourEnv】是新创建的虚拟环境的名字,创建完,可以装anaconda的目录下找到envs/yourEnv 目录python3.7.5:是python的版本号…...
)
数据库的本质永远都不会改变基础语句(第二十二课)
JAVA与Mysql._java数据库和mysql_真正的醒悟的博客-CSDN博客...
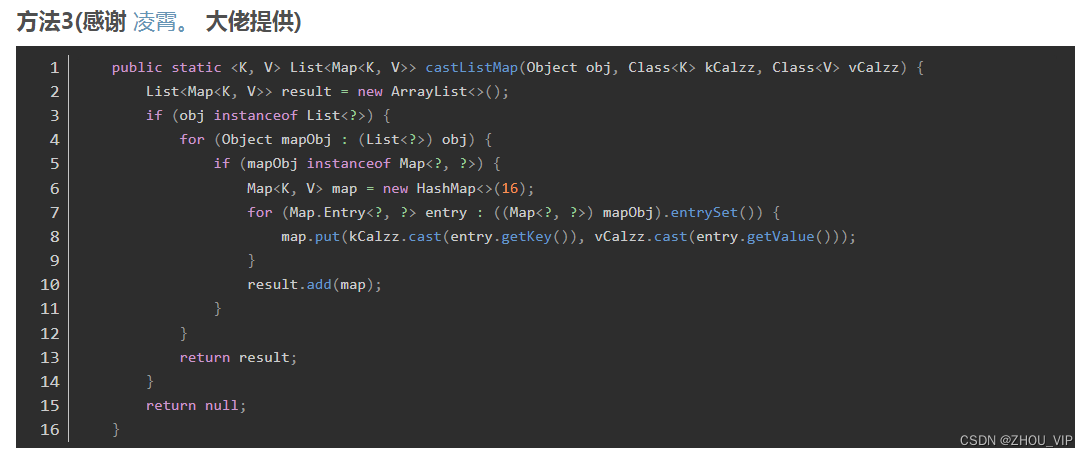
Object转List<>,转List<Map<>>
这样就不会局限在转换到List<Map<String,Object>>这一种类型上了.可以转换成List<Map<String,V>>上等,进行泛型转换虽然多了一个参数,但是可以重载啊注: 感觉field.get(key) 这里处理的不是很好,如果有更好的办法可以留言 public static <K, V> …...
React使用富文本CKEditor 5,上传图片并可设置大小
上传图片 基础使用(标题、粗体、斜体、超链接、缩进段落、有序无序、上传图片) 官网查看:https://ckeditor.com/docs/ckeditor5/latest/installation/integrations/react.html 安装依赖 npm install --save ckeditor/ckeditor5-react cked…...

【工具使用】批量修改文件夹的时间操作
一,简介 在工作过程中,有时需要修改文件夹的时间,本文分别介绍如何使用PowerShell修改文件夹的时间为指定时间或者当前时间。 二,操作步骤 请注意,在运行任何更改文件和文件夹时间的命令之前,请确保你有…...

Android Snackbar
1.Snackbar Snackbar是Material Design中的一个控件,用来代替Toast。Snackbar是一个类似Toast的快速弹出消息提示的控件。Snackbar在显示上比Toast丰富,而且提供了用户交互的接口。 ①默认情况下,Snackbar显示在屏幕底部,它出现…...
)
详解API接口如何安全的传输数据(内附商品详情API接口接入方式)
概述 API接口的安全传输是确保数据在API请求和响应之间的传输过程中不被截获、篡改或泄露的重要步骤。以下是一些用于增强API接口安全传输的常见技术和最佳实践: 使用HTTPS:使用HTTPS协议而不是HTTP,以确保数据在传输过程中的安全性。HTTPS使…...

网工内推 | 大专以上,福利待遇好,IE认证优先(云厂商)
01 主动脉科技有限公司 招聘岗位:网络工程师 职责描述: 1.负责云计算,IDC,BGP网络,通过团队协作,构建云业务后台技术支持服务体系。 2.通过工单、其他通讯工具等线上方式完成对客户的实施售后支持&#x…...

Python time strptime()和strftime()
1 strptime()方法 根据指定的格式把一个时间字符串解析为时间元组 重要的时间日期格式化符号 %y 两位数的年份表示(00-99) %Y 四位数的年份表示(000-9999) %m 月份(01-12) %d 月内中的一天(0-…...

是谁家班主任还不知道 怎么发布期中成绩啊。
你知道吗?居然还有班主任不知道怎么发布期中成绩! 发布成绩并不是一件难事,只需几个步骤,就能轻松搞定! 给大家讲一下成绩查询是什么。成绩查询是指学生通过一定的方式,如输入学号、姓名等,在指…...
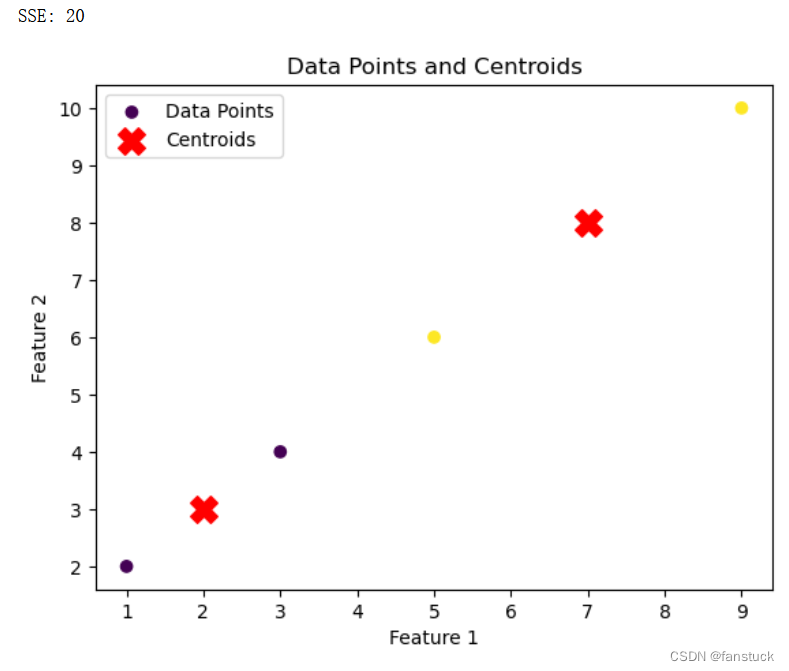
损失函数(Loss Function)一文详解-聚类问题常见损失函数Python代码实现+计算原理解析
损失函数(Loss Function)一文详解-聚类问题常见损失函数Python代码实现计算原理解析 前言 损失函数无疑是机器学习和深度学习效果验证的核心检验功能,用于评估模型预测值与实际值之间的差异。我们学习机器学习和深度学习或多或少都接触到了损失函数,但…...

测试用例设计方法 —— 场景法详解
场景法是通过运用场景来对系统的功能点或业务流程的描述,从而提高测试效果的一种方法。 场景法一般包含基本流和备用流,从一个流程开始,通过描述经过的路径来确定的过程,经过遍历所有的基本流和备用流来完成整个场景。 场景主要…...

el-table表格设置——动态修改表头
(1) 首先是form表单写表单设置按钮: (1.1)使用el-popover,你需要修改的是this.colOptions,colSelect: <el-popover id"popover" popper-class"planProver" placement"bottom" width&…...

2025_NIPS_G1: Teaching LLMs to Reason on Graphs with Reinforcement Learning
文章核心总结与创新点 核心内容 本文针对大型语言模型(LLMs)在图推理任务中表现有限的问题,提出了一种基于强化学习(RL)的方法G1。通过在大规模合成图论任务数据集Erdős上训练,G1显著提升了LLMs的图推理能力,且在未见过的任务、领域和图编码方案中表现出强泛化性,同…...

Qwen3-14B WebUI权限分级:管理员/普通用户/只读访客三类角色配置
Qwen3-14B WebUI权限分级:管理员/普通用户/只读访客三类角色配置 1. 权限分级的重要性与场景需求 在私有化部署Qwen3-14B模型时,企业或团队通常需要根据不同成员的职责分配不同的操作权限。合理的权限分级能够: 保障系统安全:防…...

数据仓库建模:事实表类型详解与选型实战指南
数据仓库建模:事实表类型详解与选型实战指南一、引言二、定义:什么是数据仓库事实表?三、数据仓库中三大核心事实表类型3.1 类型1:事务事实表(Transaction Fact Table)3.2 类型2:周期快照事实表…...

解锁5大核心能力:BetterJoy让Switch手柄在PC实现专业级控制
解锁5大核心能力:BetterJoy让Switch手柄在PC实现专业级控制 【免费下载链接】BetterJoy Allows the Nintendo Switch Pro Controller, Joycons and SNES controller to be used with CEMU, Citra, Dolphin, Yuzu and as generic XInput 项目地址: https://gitcode…...

Buck电路PCB布局优化与EMI控制技巧
1. Buck电路PCB布局的重要性在开关电源设计中,PCB布局的好坏直接决定了电源的稳定性、效率和EMI性能。以Buck电路为例,不合理的布局可能导致输出电压纹波增大、转换效率降低、甚至引发系统振荡等问题。我从事电源设计多年,见过太多因为PCB布局…...

AI 推理引擎的并行化实现
AI推理引擎的并行化实现:加速智能决策的关键 随着人工智能技术的快速发展,AI推理引擎已成为许多应用的核心组件,从自动驾驶到医疗诊断,再到智能客服,其高效性直接影响用户体验和系统性能。随着模型规模的扩大和实时性…...
)
SEO_如何通过内容优化有效提升SEO效果(353 )
SEO内容优化:如何通过高质量内容提升SEO效果 在当今的互联网时代,搜索引擎优化(SEO)已经成为了每一个网站运营者必须掌握的技能。而其中,内容优化是提升SEO效果的关键。好的内容不仅能吸引更多的访问者,还…...

FireRedASR Pro效果展示:长难句识别准确,抗噪能力惊艳
FireRedASR Pro效果展示:长难句识别准确,抗噪能力惊艳 1. 语音识别新标杆 在嘈杂的会议室里,一段夹杂着咳嗽声和键盘敲击的录音正在播放。令人惊讶的是,FireRedASR Pro几乎一字不差地将这段对话转换成了文字,连专业术…...

javaweb大学生校园跑腿服务系统的设计与实现沙箱支付
目录同行可拿货,招校园代理 ,本人源头供货商沙箱支付功能概述核心功能模块技术实现要点测试注意事项项目技术支持源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作同行可拿货,招校园代理 ,本人源头供货商 沙箱支付功能概述 在JavaWeb校园跑…...

D3KeyHelper:如何通过智能操作优化解放暗黑3玩家双手的效率工具
D3KeyHelper:如何通过智能操作优化解放暗黑3玩家双手的效率工具 【免费下载链接】D3keyHelper D3KeyHelper是一个有图形界面,可自定义配置的暗黑3鼠标宏工具。 项目地址: https://gitcode.com/gh_mirrors/d3/D3keyHelper 一、问题场景:…...