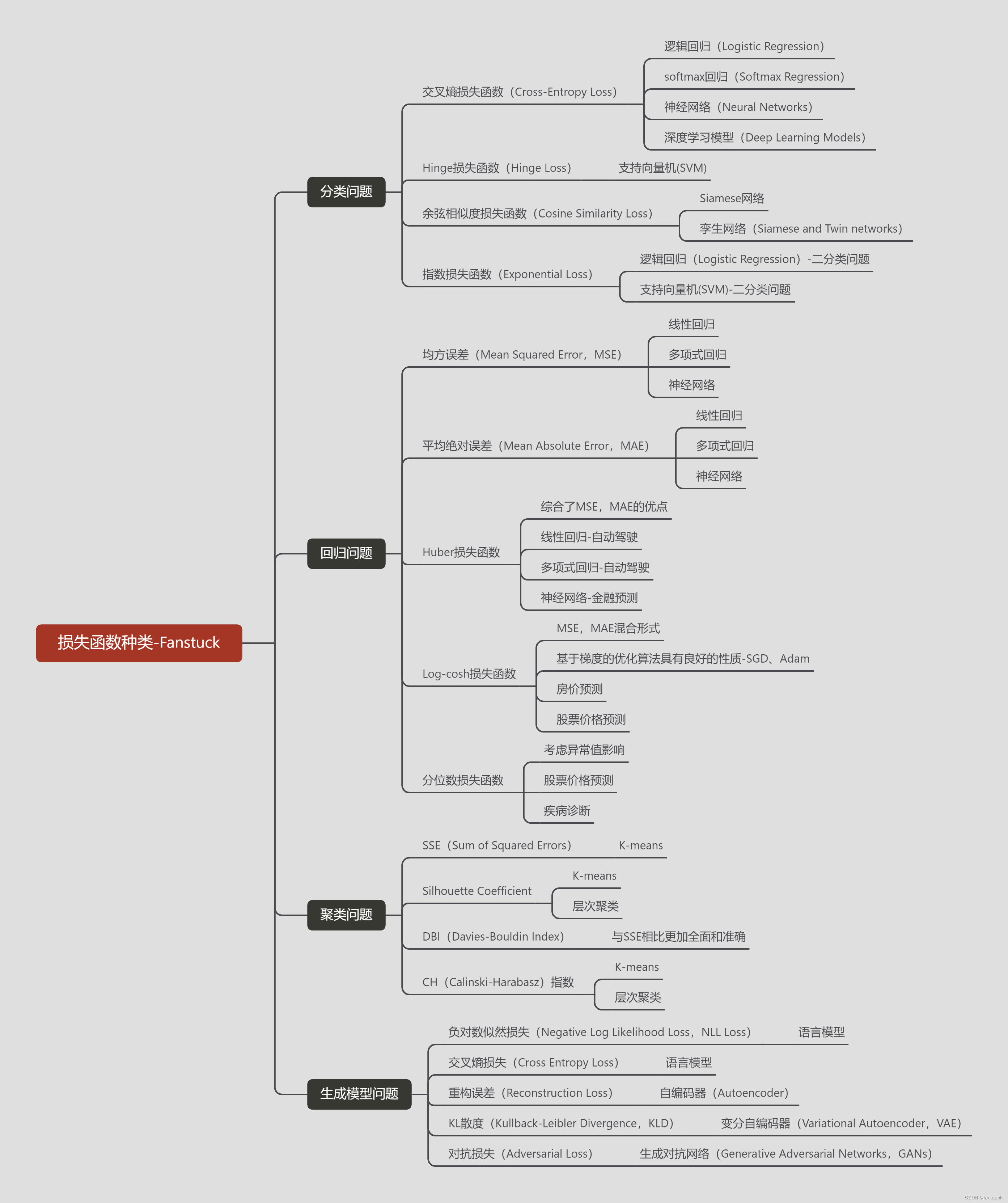
损失函数(Loss Function)一文详解-聚类问题常见损失函数Python代码实现+计算原理解析
损失函数(Loss Function)一文详解-聚类问题常见损失函数Python代码实现+计算原理解析
前言
损失函数无疑是机器学习和深度学习效果验证的核心检验功能,用于评估模型预测值与实际值之间的差异。我们学习机器学习和深度学习或多或少都接触到了损失函数,但是我们缺少细致的对损失函数进行分类,或者系统的学习损失函数在不同的算法和任务中的不同的应用。因此有必要对整个损失函数体系有个比较全面的认识,方便以后我们遇到各类功能不同的损失函数有个清楚的认知,而且一般面试以及论文写作基本都会对这方面的知识涉及的非常深入。故本篇文章将结合实际Python代码实现损失函数功能,以及对整个损失函数体系进行深入了解。
博主专注建模四年,参与过大大小小数十来次数学建模,理解各类模型原理以及每种模型的建模流程和各类题目分析方法。此专栏的目的就是为了让零基础快速使用各类数学模型、机器学习和深度学习以及代码,每一篇文章都包含实战项目以及可运行代码。博主紧跟各类数模比赛,每场数模竞赛博主都会将最新的思路和代码写进此专栏以及详细思路和完全代码。若你渴望突破数学建模的瓶颈,不要错过笔者精心打造的专栏。愿你能在这里找到你所需要的灵感与技巧,为你的建模之路添砖加瓦。
一文速学-数学建模常用模型
一、聚类问题损失函数概述
在聚类问题中,我们试图将数据集分成不同的组(簇),使得每个组内的数据点相似度较高,而不同组之间的相似度较低。聚类问题的目标是找到合适的簇划分,以最大程度地减小组内的差异,同时最大程度地增大组间的差异。在聚类问题中,并没有像监督学习中那样明确定义的损失函数,因为聚类问题通常是无监督学习,没有预先定义的目标变量。而聚类问题的损失函数通常用于度量簇划分的质量,并提供一种可优化的指标来衡量聚类结果的好坏。一般来说聚类问题的损失函数承担的功能有三种:
- 度量簇内相似度: 损失函数度量了每个簇内数据点的相似度,即簇内数据点之间的相似程度。通常情况下,簇内相似度越高,表示簇内的数据点越相似。
- 度量簇间差异: 损失函数也可以度量不同簇之间的差异,即不同簇之间的相似度。簇间差异越大,表示不同簇之间的数据点越不相似。
- 提供优化目标: 损失函数为聚类算法提供了一个可优化的目标。聚类算法的目标是通过最小化或最大化损失函数来寻找最佳的簇划分。
那么作为度量差距的算法,都有损失函数的通性,辅助我们建立的模型好坏与否,其效果有以下四条:
- 帮助确定最佳簇数: 通过调整簇数,可以观察损失函数的变化,从而帮助确定最佳的簇数。
- 评估聚类结果: 损失函数可以用于评估聚类算法的结果,帮助判断聚类是否合理,簇内的相似度是否高,簇间的差异是否明显。
- 指导优化过程: 在迭代优化过程中,聚类算法可以根据损失函数的值来调整簇划分,从而提升聚类的效果。
- 衡量聚类的稳定性: 损失函数可以用于衡量聚类结果的稳定性,即不同运行下的聚类结果是否一致。
总的来说,聚类问题的损失函数在聚类过程中起到了指导和评估的作用,帮助算法找到合适的簇划分,从而达到最佳的聚类效果。选择合适的损失函数可以根据具体问题的需求和数据的特点来进行,以获得满意的聚类结果。
二、聚类函数种类

1.SSE(Sum of Squared Errors)
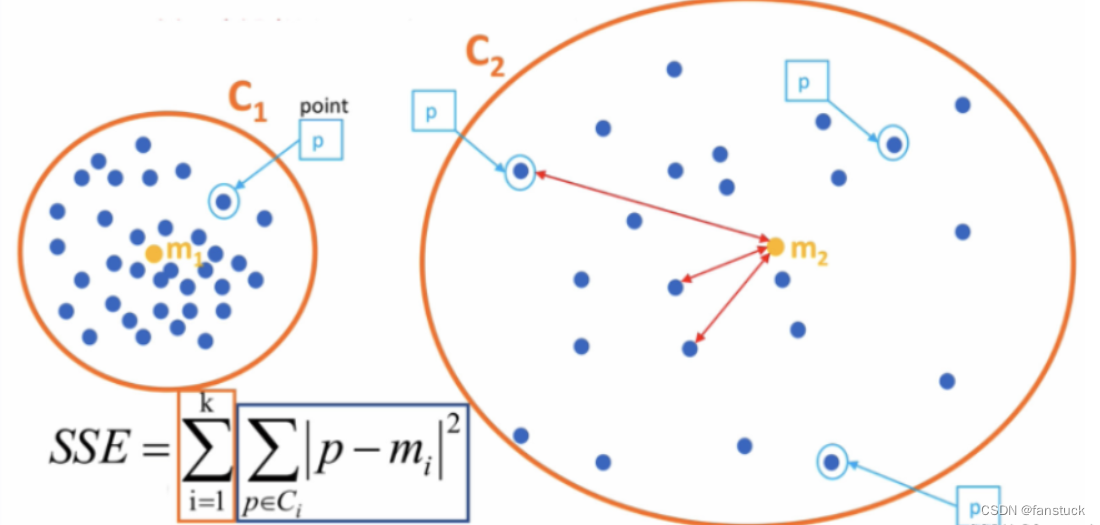
SSE(Sum of Squared Errors)是一种常用于聚类算法中的损失函数,也称为误差平方和。它衡量了每个数据点与其所属簇的质心之间的欧氏距离的平方的总和。
具体来说,对于一个包含 n 个数据点和 k 个簇的聚类结果,SSE 的计算公式如下:
S S E = ∑ i = 1 n ∑ j = 1 k d ( x i , c j ) 2 SSE=∑^n_{i=1}∑^k_{j=1}d(x_i,c_j)^2 SSE=i=1∑nj=1∑kd(xi,cj)2
其中:
- x i x_{i} xi表示第 i 个数据点。
- c j c_j cj表示第 j 个簇的质心。
- d ( x i , c j ) d(x_{i},c_{j}) d(xi,cj)表示数据点 x i x_{i} xi与簇质心 c j c_{j} cj 之间的欧氏距离。
SSE 的目标是最小化这个值,即通过调整簇的划分和质心的位置来使每个数据点与其所属簇的质心之间的距离尽可能小,从而达到聚类的效果。
SSE 的优点是简单直观,容易理解。然而,它也有一些缺点,例如它假设簇的形状是凸的,并且对异常值敏感。
在K均值聚类(K-Means)算法中,SSE 是一个重要的评估指标,通常用于确定最佳的簇数(K值)。通过尝试不同的K值,可以绘制出SSE随K值变化的曲线(称为“肘部法则”),从而选择最优的K值。
import matplotlib.pyplot as plt
import numpy as npdef calculate_euclidean_distance(point, centroid):return np.sum((point - centroid) ** 2)def calculate_sse(data, centroids, labels):sse = 0for i in range(len(data)):sse += calculate_euclidean_distance(data[i], centroids[labels[i]])return sse# 示例数据
data = np.array([[1, 2], [3, 4], [5, 6], [7, 8], [9, 10]])
centroids = np.array([[2, 3], [7, 8]])
labels = np.array([0, 0, 1, 1, 1]) # 每个数据点所属的簇sse = calculate_sse(data, centroids, labels)
print(f"SSE: {sse}")# 绘制数据点
plt.scatter(data[:, 0], data[:, 1], c=labels, cmap='viridis', label='Data Points')
plt.scatter(centroids[:, 0], centroids[:, 1], marker='X', color='red', s=200, label='Centroids')# 添加标题和标签
plt.title('Data Points and Centroids')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')# 添加图例
plt.legend()# 显示图形
plt.show()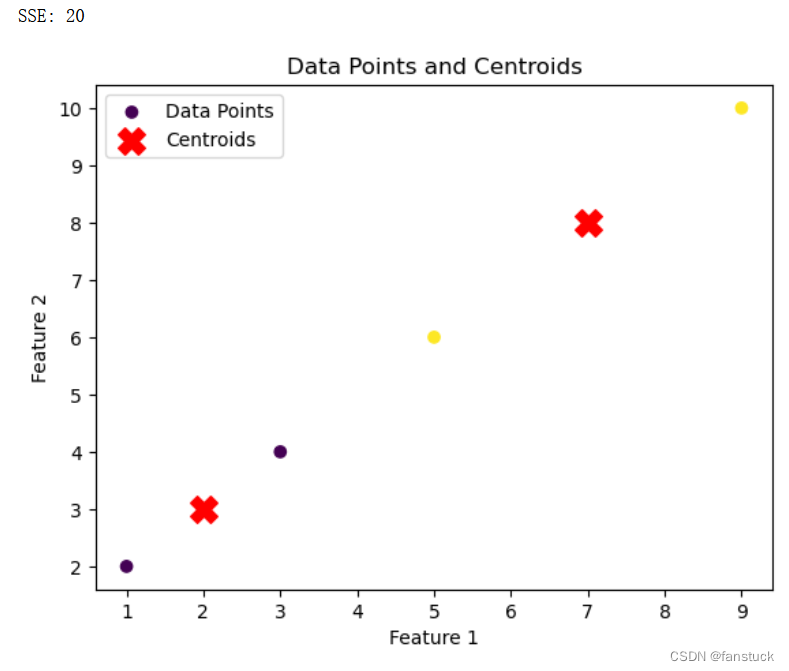
2.Silhouette Coefficient
Silhouette Coefficient(轮廓系数)是一种用于评估聚类质量的指标,它同时考虑了簇内的紧密度和簇间的分离度。Silhouette Coefficient 的取值范围在 [-1, 1] 之间:
- 接近1表示样本被正确地分配到了簇中。
- 接近0表示样本位于簇的边界上。
- 接近-1表示样本被错误地分配到了相邻的簇中。
具体计算方法如下:
对于每个样本 i i i,计算以下两个值:
- a ( i ) a(i) a(i) 表示样本 i i i 到同一簇中所有其他样本的平均距离(簇内平均距离)。
- $b(i) $表示样本 i i i 到最近簇中所有样本的平均距离(簇间平均距离)。
对于样本 i i i,Silhouette Coefficient 计算如下:
s ( i ) = b ( i ) − a ( i ) m a x ( a ( i ) , b ( i ) ) s(i)=\frac{b(i)-a(i)}{max(a(i),b(i))} s(i)=max(a(i),b(i))b(i)−a(i)
最终的 Silhouette Coefficient 是所有样本的 s ( i ) s(i) s(i) 的均值。Silhouette Coefficient 的优点之一是它不需要事先知道聚类的数量,因此可以在不同的聚类数量下评估聚类的效果,帮助选择最优的聚类数量。需要注意的是,Silhouette Coefficient 对于凸形簇效果较好,但对于非凸形簇可能不太适用。Silhouette Coefficient 在其他聚类算法中的功能和作用如下:
- 衡量聚类效果: Silhouette Coefficient 提供了一种对聚类效果的定量评估。它能够指示聚类结果的紧密性和分离性,越接近1表示聚类效果越好。
- 选择最优聚类数量(K值): Silhouette Coefficient 不需要事先知道聚类的数量,因此可以在不同的K值下评估聚类的效果,帮助选择最优的聚类数量。
- 辅助于数据可视化和解释: 在可视化和解释聚类结果时,Silhouette Coefficient 可以提供一个客观的评估指标,帮助理解聚类的效果。
在Python中,你可以使用scikit-learn库来计算Silhouette Coefficient。scikit-learn提供了一个名为silhouette_score的函数,可以方便地计算给定数据集和聚类结果的Silhouette Coefficient。
from sklearn.metrics import silhouette_score
from sklearn.cluster import KMeans
import numpy as np# 假设 data, labels 已经定义# 示例数据
data = np.array([[1, 2], [3, 4], [5, 6], [7, 8], [9, 10]])
labels = np.array([0, 0, 1, 1, 1]) # 每个数据点所属的簇# 使用KMeans聚类算法进行聚类
kmeans = KMeans(n_clusters=2, random_state=0).fit(data)
labels = kmeans.labels_# 计算Silhouette Coefficient
score = silhouette_score(data, labels)
print(f"Silhouette Coefficient: {score}")获得结果Silhouette Coefficient: 0.46761904761904766
3.DBI(Davies-Bouldin Index)
Davies-Bouldin Index(DBI)是一种用于评估聚类结果的指标,它通过考虑簇内的紧密度和簇间的分离度来提供一个聚类质量的度量。DBI 的计算方法如下:
对于每个簇 i i i,计算以下两个值:
- R i R_{i} Ri 表示簇 i i i 中所有样本到簇质心的平均距离(簇内平均距离)。
- 对于所有不同于簇 i i i 的簇 j j j,计算簇 i i i 的质心与簇 j j j 的质心之间的距离 d ( i , j ) d(i,j) d(i,j)。
对于簇 i i i,计算 DBI 如下:
D B i = 1 K − 1 ∑ j = 1 , j ! = j K ( R i + R j d ( i , j ) ) DB_{i}=\frac{1}{K-1}∑^K_{j=1,j!=j}(\frac{R_{i}+R_{j}}{d(i,j)}) DBi=K−11j=1,j!=j∑K(d(i,j)Ri+Rj)
最终的 Davies-Bouldin Index 是所有簇的 D B i DB_{i} DBi的最大值。DBI 的取值范围是 [ 0 , + ∞ ) [0,+∞) [0,+∞),越小表示聚类结果越好。
在Python中,你可以使用scikit-learn库来计算Davies-Bouldin Index(DBI)。scikit-learn提供了一个名为davies_bouldin_score的函数,可以方便地计算给定数据集和聚类结果的DBI。
from sklearn.metrics import davies_bouldin_score
from sklearn.cluster import KMeans
import numpy as np# 假设 data, labels 已经定义# 示例数据
data = np.array([[1, 2], [3, 4], [5, 6], [7, 8], [9, 10]])
labels = np.array([0, 0, 1, 1, 1]) # 每个数据点所属的簇# 使用KMeans聚类算法进行聚类
kmeans = KMeans(n_clusters=2, random_state=0).fit(data)
labels = kmeans.labels_# 计算DBI
score = davies_bouldin_score(data, labels)
print(f"Davies-Bouldin Index: {score}")输出Davies-Bouldin Index:0.467
4.CH(Calinski-Harabasz)指数
Calinski-Harabasz指数(CH指数)是一种用于评估聚类结果的指标,它通过比较簇内的紧密度与簇间的分离度来提供一个聚类质量的度量。CH指数的计算方法基于以下公式:
C H = B ( k ) W ( k ) ∗ N − k k − 1 CH=\frac{B(k)}{W(k)}*\frac{N-k}{k-1} CH=W(k)B(k)∗k−1N−k
其中:
- B ( k ) B(k) B(k)是簇间的方差(簇间平方和)。
- W ( k ) W(k) W(k)是簇内的方差(簇内平方和)。
- N N N是样本总数。
- k k k是簇的数量。
具体计算方法如下:
计算簇内平方和(Within-Cluster Sum of Squares W ( k ) W(k) W(k):对于每个簇 C i C_{i} Ci,计算簇内所有样本到簇质心的距离的平方和,然后对所有簇的结果进行求和。
W ( k ) = ∑ i = 1 k ∑ x ∈ C ∣ ∣ x − μ i ∣ ∣ 2 W(k)=∑^k_{i=1}∑_{x∈C}||x-μ_{i}||^2 W(k)=i=1∑kx∈C∑∣∣x−μi∣∣2
其中 ∣ ∣ x − μ i ∣ ∣ 2 ||x-μ_{i}||^2 ∣∣x−μi∣∣2是样本 i i i 到簇 C i C_{i} Ci的质心 μ i μ_{i} μi的距离。
计算簇间平方和(Between-Cluster Sum of Squares) B ( K ) B(K) B(K):计算所有簇的质心之间的距离的平方和。
B ( k ) = ∑ i = 1 k n i ∣ ∣ μ i − μ ∣ ∣ 2 B(k)=∑^k_{i=1}n_{i}||μ_{i}-μ||^2 B(k)=i=1∑kni∣∣μi−μ∣∣2
其中 n i n_{i} ni是簇 C i C_{i} Ci中的样本数量,μ 是所有样本的均值, μ i μ_{i} μi是簇 C i C_{i} Ci的质心。具体来说:
- CH指数越大,表示簇内的样本之间越紧密,簇之间的间隔越大,说明聚类效果越好。
- CH指数越小,表示簇内的样本之间越松散,簇之间的间隔越小,可能是由于聚类数量过多或者聚类质量不佳。
根据CH指数来选择最佳的K值的一般思路是:
- 对于给定的数据集,尝试不同的K值,分别进行聚类。
- 对每个K值计算对应的CH指数。
- 选择具有最大CH指数的K值,因为这表示了最优的聚类效果。
- 需要注意的是,选择K值时不一定选择CH指数最大的K值,还需要结合实际业务需求和对聚类结果的理解来综合考虑。
Python代码实现如下:
from sklearn.metrics import calinski_harabasz_score
from sklearn.cluster import KMeans
import numpy as np# 假设 data, labels 已经定义# 示例数据
data = np.array([[1, 2], [3, 4], [5, 6], [7, 8], [9, 10]])
labels = np.array([0, 0, 1, 1, 1]) # 每个数据点所属的簇# 使用KMeans聚类算法进行聚类
kmeans = KMeans(n_clusters=2, random_state=0).fit(data)
labels = kmeans.labels_# 计算CH指数
score = calinski_harabasz_score(data, labels)
print(f"Calinski-Harabasz Index: {score}")输出Calinski-Harabasz Index: 9.0
点关注,防走丢,如有纰漏之处,请留言指教,非常感谢
以上就是本期全部内容。我是fanstuck ,有问题大家随时留言讨论 ,我们下期见。
相关文章:
损失函数(Loss Function)一文详解-聚类问题常见损失函数Python代码实现+计算原理解析
损失函数(Loss Function)一文详解-聚类问题常见损失函数Python代码实现计算原理解析 前言 损失函数无疑是机器学习和深度学习效果验证的核心检验功能,用于评估模型预测值与实际值之间的差异。我们学习机器学习和深度学习或多或少都接触到了损失函数,但…...

测试用例设计方法 —— 场景法详解
场景法是通过运用场景来对系统的功能点或业务流程的描述,从而提高测试效果的一种方法。 场景法一般包含基本流和备用流,从一个流程开始,通过描述经过的路径来确定的过程,经过遍历所有的基本流和备用流来完成整个场景。 场景主要…...

el-table表格设置——动态修改表头
(1) 首先是form表单写表单设置按钮: (1.1)使用el-popover,你需要修改的是this.colOptions,colSelect: <el-popover id"popover" popper-class"planProver" placement"bottom" width&…...

京东数据分析:2023年9月京东洗地机行业品牌销售排行榜
鲸参谋监测的京东平台9月份洗地机市场销售数据已出炉! 9月份,洗地机市场的销售额增长。根据鲸参谋电商数据分析平台的相关数据显示,9月京东平台上洗地机的销量为9.2万,销售额将近2.2亿,同比增长约9%。从价格上看&#…...

使用 TensorFlow SSD 网络进行对象检测
使用 TensorFlow SSD 网络进行对象检测 目录 描述这个示例是如何工作的? 处理输入图准备数据sampleUffSSD 插件验证输出TensorRT API 层和操作 先决条件运行示例 示例 --help 选项 附加资源许可证更改日志已知问题 描述 该示例 sampleUffSSD 预处理 TensorFlow …...
(2)STM32单片机上位机
使用VX小程序开发上位机, 样式如何创建? 在你所在页面 开辟空间 使用 view 在view 中 输入class 就是样式,在编辑样式的时候,如何寻找哪一块的样式 就是通过这个class寻找的 按钮使用switch...

从InnoDB索引的数据结构,去理解索引
从InnoDB索引的数据结构,去理解索引 1、InnoDB 中的 BTree1.1、BTree 的组成1.2、BTree中的数据页 2、聚簇索引2.1、聚簇索引的特点2.2、聚簇索引的结构示例2.3、聚簇索引的优缺点 3、非聚簇索引3.1、非聚簇索引结构示例3.2、关于回表3.3、聚簇索引和非聚簇索引的区…...

Nacos:动态服务发现与配置管理的终极解决方案
今天我想和大家分享一下Nacos,这是一个由阿里巴巴开源的动态服务发现、配置和服务管理平台。我将详细介绍Nacos的主要特性,并通过实例来演示如何使用它。同时,我还会指出Nacos的优点,希望这篇文章能够帮助大家更好地理解和使用Nac…...
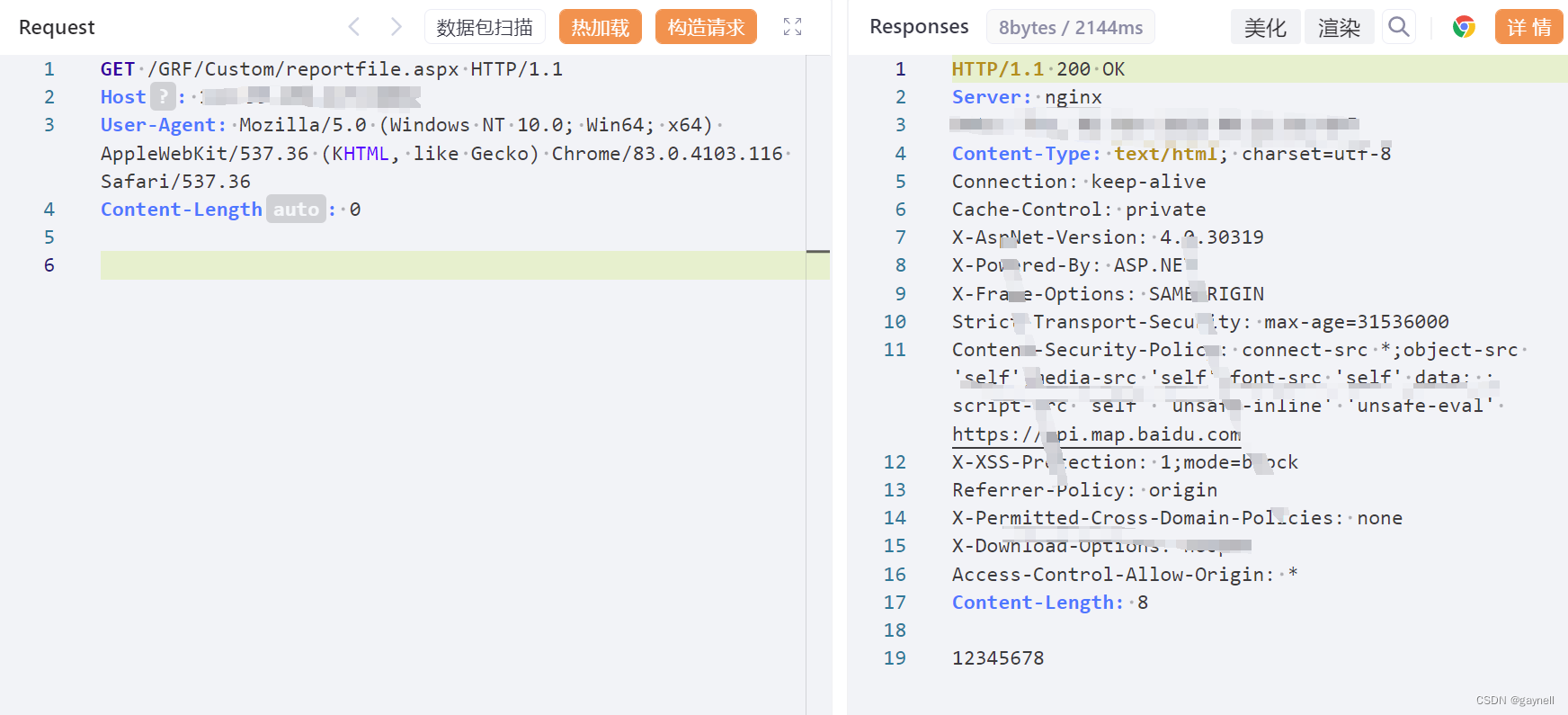
易思无人值守智能物流系统Sys_ReportFile文件上传漏洞复现
文章目录 易思无人值守智能物流系统Sys_ReportFile文件上传漏洞复现0x01 前言0x02 漏洞描述0x03 影响版本0x04 漏洞环境0x05 漏洞复现1.访问漏洞环境2.构造POC3.复现 0x06 修复建议 易思无人值守智能物流系统Sys_ReportFile文件上传漏洞复现 0x01 前言 免责声明:请…...

java Map List转化,通过Map保存数据,通过List排序。取前三名
java Map List转化,通过Map保存数据,通过List排序。取前三名 package yo;import java.util.ArrayList; import java.util.Collections; import java.util.HashMap; import java.util.List; import java.util.Map;public class a {public static void …...

LEECODE 1480一维数组的动态和
class Solution { public:vector<int> runningSum(vector<int>& nums) {vector<int> runningSum;int sum 0;int len nums.size();for(int i 0; i < len; i){sum sum nums[i];runningSum.push_back(sum);}return runningSum;} };...

python文档链接
python与并行计算...

HTTP调试代理工具/Proxyman
Proxyman专为开发人员和网络爱好者设计,它允许用户拦截、查看和修改所有传入和传出的网络请求,并提供详细的分析和调试功能。 Proxyman支持HTTP、HTTPS和WebSocket协议,因此,可以轻松捕获和查看这些协议下的网络流量。用户可以使…...
搭建Qt5.7.1+kylinV10开发环境、运行环境
1.下载Qt源码 Index of / 2.编译Qt 解压缩qt-everywhere-opensource-src-5.7.1.tar.gz 进入到qt-everywhere-opensource-src-5.7.1/qtbase/mkspecs这个目录下, 2.1找到以下目录 复制他,然后改名linux-x86-arrch64,博主这里名字取的有些问…...
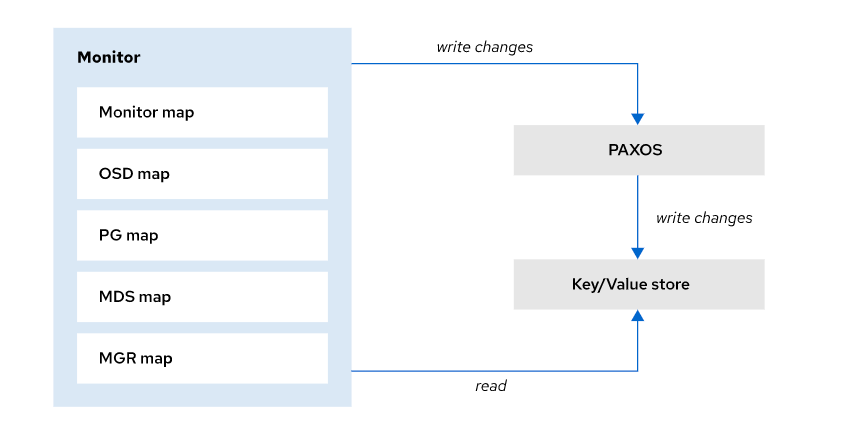
Ceph:关于Ceph 中创建和管理自定义 CRUSH Map
写在前面 准备考试,整理 Ceph 相关笔记博文内容涉及,管理和定制CRUSH Map以及管理OSD Map理解不足小伙伴帮忙指正 对每个人而言,真正的职责只有一个:找到自我。然后在心中坚守其一生,全心全意,永不停息。所…...

【Linux】开发工具——vim多模式编辑器的入土设置sudoers白名单
个人主页点击直达:小白不是程序媛 Linux系列专栏:Linux被操作记 目录 前言: 基本概念 vim基本操作 [正常模式]切换至[插入模式] [插入模式]切换至[正常模式] [正常模式]切换至[末行模式] 三种模式的切换关系图 vim命令模式命令集 进…...
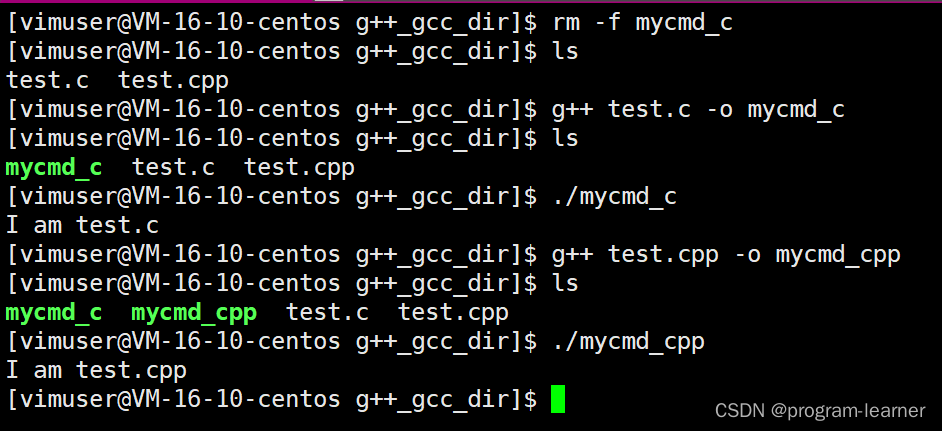
Linux基础环境开发工具的使用(yum,vim,gcc,g++)
Linux基础环境开发工具的使用[yum,vim,gcc,g] 一.yum1.yum的快速入门1.yum安装软件2.yum卸载软件 2.yum的生态环境1.操作系统的分化2.四个问题1.服务器是谁提供的呢?2.服务器上的软件是谁提供的呢?3.为什么要提供呢?4.yum是如何得知目标服务器的地址和下载链接呢?5.软件源 …...

加速软件开发和交付的革命性方法-DevOps
“ 随着信息技术的快速发展,现代软件开发和交付已经经历了巨大的变革。DevOps(Development和Operations的结合)已经成为这一变革的关键推动力,让开发团队和运维团队之间的界限变得模糊,以加速软件的开发、测试和部署过…...
Ha-NeRF源码解读 train_mask_grid_sample
目录 背景: (1)Ha_NeRF论文解读 (2)Ha_NeRF源码复现 (3)train_mask_grid_sample.py 运行 train_mask_grid_sample.py解读 1 NeRFSystem 模块 2 forward()详解 3 模型训练tranining_st…...

大数据毕业设计选题推荐-系统运行情况监控系统-Hadoop-Spark-Hive
✨作者主页:IT毕设梦工厂✨ 个人简介:曾从事计算机专业培训教学,擅长Java、Python、微信小程序、Golang、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。 ☑文末获取源码☑ 精彩专栏推荐⬇⬇⬇ Java项目 Py…...

Perforce 2025.2 REST API 技术预览版发布:开启“无客户端”运维新时代
Perforce 2025.2 REST API 技术预览版发布:开启“无客户端”运维新时代 在上一期“ Perforce on Tour 游戏研发效能进阶沙龙”回顾文章中,我们分享了Perforce 资深技术工程师 Kory Luo关于P4 MCP(Model Context Protocol)服务器的…...

2026 年 5 月 AI 热点:大模型、硬件、人形机器人全面升级
一、大模型技术突破 | LLM Technology Breakthroughs 1.1 OpenAI GPT‑5.5 正式成为ChatGPT默认模型 | GPT‑5.5 Becomes ChatGPT Default Model 英文内容 | English On May 5, 2026, OpenAI officially rolled out GPT‑5.5 Instant as the new default model for ChatGPT, …...

谷歌“反重力”工具更新强行替换软件,用户恢复工作困难重重!
谷歌“反重力”工具更新强行替换软件,用户恢复工作困难重重!2026年5月21日,原本打算用“反重力”工具工作的用户,遭遇了谷歌的意外安排。前一天,谷歌在2026年I/O开发者大会上推出“反重力”工具新版本,将其…...

量子机器学习噪声挑战与HPQS混合框架解析
1. 量子机器学习中的噪声挑战与HPQS解决方案量子机器学习(QML)作为量子计算与经典机器学习的交叉领域,正在重新定义我们处理复杂模式识别问题的方式。与传统机器学习不同,QML利用量子态的叠加和纠缠特性,理论上可以在某些特定任务上实现指数级…...

Java Web中基于JWT的七层权限控制系统设计
1. 为什么JWT不是“万能钥匙”,而是一个需要精心设计的权限信封在Java Web开发中,一提到权限控制,很多人第一反应就是“加个Spring Security,配个JWT,不就完事了?”我去年接手一个医疗SaaS系统的权限模块重…...

modelzoo:昇腾 NPU 的“模型仓库”
modelzoo:昇腾 NPU 的“模型仓库” 之前帮朋友看模型训练的代码,发现他自己手写了很多模型(ResNet50/BERT/LLaMA2 等)——光写模型定义就写了 5,000 行,而且还不一定对。 我告诉他:不用手写,用 …...
:含12个领域专属风格锚点模板与冲突检测CLI工具)
NotebookLM风格一致性密钥库(仅限首批200位AI架构师开放获取):含12个领域专属风格锚点模板与冲突检测CLI工具
更多请点击: https://kaifayun.com 第一章:NotebookLM风格一致性密钥库的演进逻辑与核心价值 NotebookLM 风格的一致性密钥库并非传统密码学密钥管理系统的简单复刻,而是面向语义化知识协作场景深度重构的基础设施。其演进逻辑根植于三个关键…...

Python API认证与授权实战:从Basic Auth到OAuth2.0
Python API认证与授权实战:从Basic Auth到OAuth2.0 引言 API安全是后端开发中至关重要的一环。作为从Python转向Rust的后端开发者,我深刻体会到认证与授权机制的重要性。一个安全可靠的API需要完善的认证体系来保护敏感数据和资源。本文将从实战角度出…...

Unity+C#开发万人MMO服务器的实战架构与同步优化
1. 这不是“写个服务器”那么简单:先撕开“万人在线”的真实含义很多人看到“UnityC#开发万人MMO服务器”这个标题,第一反应是:“哦,用Unity做客户端,C#写个后端,Socket连一连,再加个数据库&…...

免费高效的窗口放大神器:Magpie让Windows显示效果翻倍提升
免费高效的窗口放大神器:Magpie让Windows显示效果翻倍提升 【免费下载链接】Magpie A general-purpose window upscaler for Windows 10/11. 项目地址: https://gitcode.com/gh_mirrors/mag/Magpie 还在为老旧游戏或软件在4K显示器上显示模糊而烦恼吗&#x…...