【机器学习】二、决策树
目录
一、决策树定义:
二、决策树特征选择
2.1 特征选择问题
2.2 信息增益
2.2.1 熵
2.2.2 信息增益
三、决策树的生成
3.1 ID3算法
3.1.1理论推导
3.1.2代码实现
3.2 C4.5 算法
3.2.1理论推导
3.2.2代码实现
四、决策树的剪枝
4.1 原理
4.2 算法思路:
五、CART算法
5.1 CART生成
5.1.1 回归树的生成
5.1.2 分类树的生成
比较:
5.1.3 CART生成算法
5.2 CART剪枝
六、代码
6.1 代码
6.2 结果
一、决策树定义:
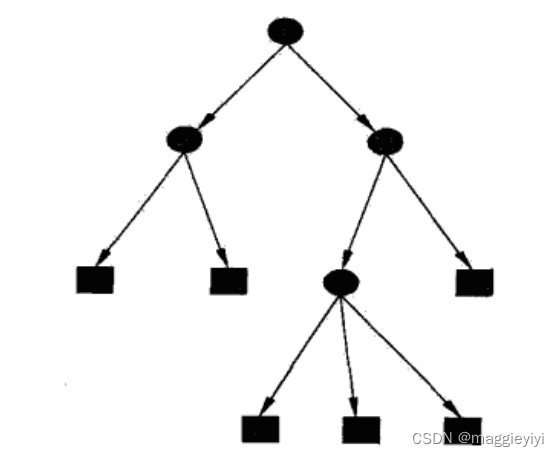
分类决策树模型是一种描述对实例进行分类的树形结构。决策树由结点(node)和有向边(directed edge)组成。
结点有两种类型:内部结点(internal node)和叶结点(leaf node)。内部结点表示一个特征或属性,叶结点表示一个类。
⚪:内部结点
正方形:叶结点
二、决策树特征选择
2.1 特征选择问题
特征选择在于选取对训练数据具有分类能力的特征。这样可以提高决策树学习的效率。如果用一个特征去分类,得到的结果与随机的分类没有很大差别,那么这次分类是无意义的。因此,我们要选取有意义的特征进行分类。
举个例子吧~
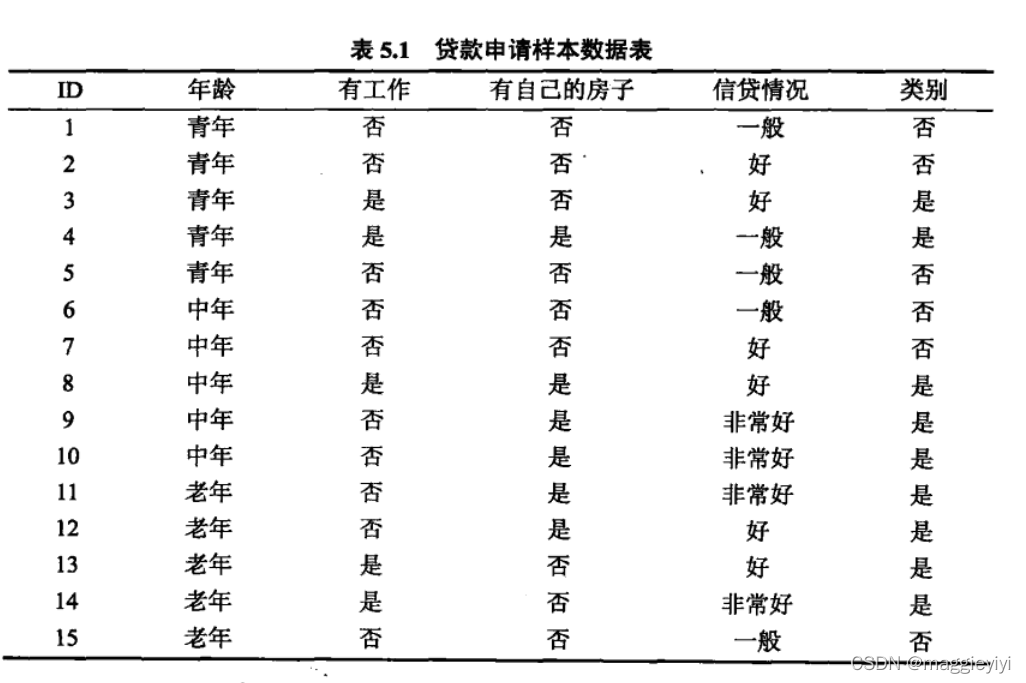
如上述表格所示,决定买房子要不要贷款的因素有年龄、有无工作、有无房子、信贷情况四个因素。那么如何选取合适的特征因素呢?
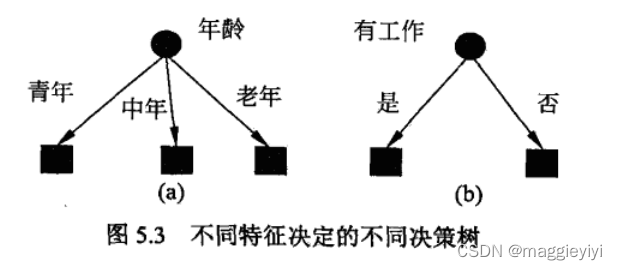
特征选择就是决定用哪个特征来划分特征空间。
直观上来讲,如果一个特征具有更好的分类能力,或者说,按照各以特征将训练数据集分割成子集,使得各个子集在当前条件下有最好的分类,那么就应该选择这一特征。
信息增益(information gain)就能够很好的表示这一直观准则。
2.2 信息增益
2.2.1 熵
在统计学中,熵是表示随机变量不确定性的度量。
设X是一个取有限个值的离散随机变量,其概率分布为

则随机变量X的熵定义为:
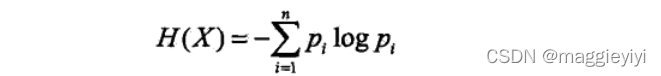
其中如果pi = 0,则0log0 = 0.
单位为bit或者nat。
上只依赖于X的分布,而与X的取值无关,所以也可将X的熵记作H(p)。
熵越大,随机变量的不确定性越大,从定义可以验证:
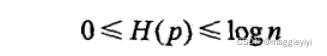

![]()

信息增益表示得知特征X的信息而使得类Y的信息的不确定性减少的程度。
2.2.2 信息增益

选择方法:

计算方法:
输入:训练数据集D和特征值A:
输出:特征A队训练数据集D的信息增益g(D,A),
step1:计算数据集D的经验熵H(D):

step2:计算特征A对数据集D的经验条件熵H(D|A):
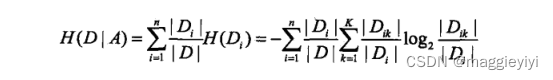
step3:计算信息增益:
![]()
举个栗子吧~:
用上面的表,计算每个特征的信息增益!!!!

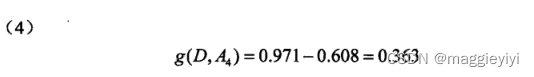
所以A3的信息增益值最大,选择A3做最优特征。
三、决策树的生成
3.1 ID3算法
ID3算法的核心是在决策树上各个结点上应用信息增益准则选择特征,递归地构建决策树。


3.1.1理论推导
对上表用ID3算法建立决策树:


3.1.2代码实现
https://blog.csdn.net/colourful_sky/article/details/82056125
3.2 C4.5 算法
C4.5算法与ID3类似,C4.5算法对ID3算法进行了改进,C4.5在生产的过程中,用信息增益比来选择特征。
3.2.1理论推导
 3.2.2代码实现
3.2.2代码实现
https://www.cnblogs.com/wsine/p/5180315.html
四、决策树的剪枝
4.1 原理
决策树生成算法递归地产生决策树,直到不能继续下去为止。这样产生的结果容易出现过拟合现象。因为这样生成的决策树过于复杂,所以我们需要对决策树进行简化——剪枝。
剪枝:在决策树学习中将已生成的树进行简化的过程。
本次介绍损失函数最小原则进行剪枝,即用正则化的极大似然估计进行模型选择。
公式这里参考李航老师的书:


4.2 算法思路:



五、CART算法
分类与回归树模型(CART, classification and regression tree)是应用广泛的决策树学习方法。
CART由特征选择、树的生成及剪枝组成,既可以用于回归也可以用于分类。
5.1 CART生成
step1:决策树生成:基于训练数据集生成决策树,生成的决策树要尽量大。
step2:决策树剪枝:用验证数据集对已生成的树进行剪枝并选择最优子树,这时用损失函数最小作为剪枝的标准。
5.1.1 回归树的生成
回归树用平方误差最小化准则,选择特征,生成二叉树。

5.1.2 分类树的生成
分类树用基尼指数最小化准则,选择特征,生成二叉树。


比较:
5.1.3 CART生成算法
原理:


例子:
还是用上面的的表格吧
step1:计算各个特征的基尼指数,选择最有特征以及其最优切分点。

step2:选择基尼指数最小的特征及其对应的切分点

5.2 CART剪枝

六、代码
sklearn中决策树都在‘tree’这个模块中,这个模块总共包含五类:
tree.DecisionTreeClassifier 分类树
tree.DecisionTreeRegressor 回归树
tree.export_graphviz 画图专用
tree.ExtraTreeClassifier 高随机版本的分类树
tree.ExtraTreeRegressor 高随机版本的回归树
这里用分类树举例子
6.1 代码
- #数据准备
- from sklearn.datasets import load_breast_cancer
- breast_cancer = load_breast_cancer()
-
- #分离数据
- breast_cancer
- x=breast_cancer.data
- y=breast_cancer.target
-
- #训练数据
- from sklearn.model_selection import train_test_split
- x_train,x_test,y_train,y_test = train_test_split(x,y,random_state=33,test_size=0.3)
-
- #数据标准化
- from sklearn.preprocessing import StandardScaler
- breast_cancer_ss = StandardScaler()
- x_train = breast_cancer_ss.fit_transform(x_train)
- x_test = breast_cancer_ss.transform(x_test)
-
- #分类树
- from sklearn.tree import DecisionTreeClassifier
- dtc = DecisionTreeClassifier()
- dtc.fit(x_train,y_train)
-
- dtc_y_predict = dtc.predict(x_test)
-
- from sklearn.metrics import classification_report
- k=0
- j=0
- for i in y_test:
- if i!=dtc_y_predict[j]:
- k=k+1
- j=j+1
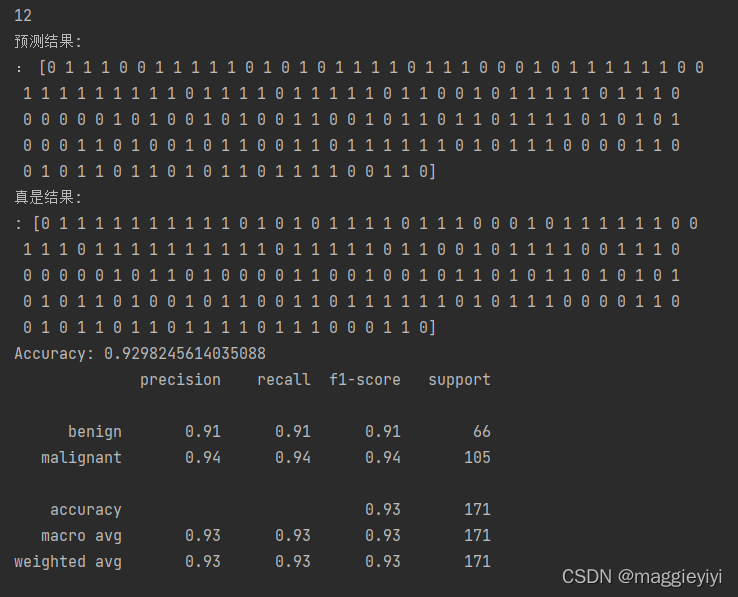
- print(k)
- print('预测结果:\n:',dtc_y_predict)
- print('真是结果:\n:',y_test)
- print('Accuracy:',dtc.score(x_test,y_test))
- print(classification_report(y_test,dtc_y_predict,target_names=['benign','malignant']))

6.2 结果
相关文章:
【机器学习】二、决策树
目录 一、决策树定义: 二、决策树特征选择 2.1 特征选择问题 2.2 信息增益 2.2.1 熵 2.2.2 信息增益 三、决策树的生成 3.1 ID3算法 3.1.1理论推导 3.1.2代码实现 3.2 C4.5 算法 3.2.1理论推导 3.2.2代码实现 四、决策树的剪枝 4.1 原理 4.2 算法思路:…...

低代码PAAS加速推进企业数字化转型
无论是“十四五”规划从国家层面提出的“加快数字化发展 建设数字中国”,还是后疫情时代企业自身的感受,数字化转型已成为必答题。当前 企业 业务场景化、线上趋势愈加明显,越来越多并发的数字化应用场景,而原有集中式架构扩展能力…...
时间复杂度为 O(nlogn) 的排序算法
归并排序 归并排序遵循 分治 的思想:将原问题分解为几个规模较小但类似于原问题的子问题,递归地求解这些子问题,然后合并这些子问题的解来建立原问题的解,归并排序的步骤如下: 划分:分解待排序的 n 个元素…...
掌控你的Mac性能:System Dashboard Pro,一款专业的系统监视器
作为Mac用户,你是否曾经想要更好地了解你的电脑性能,以便优化其运行?是否想要实时监控系统状态,以便及时发现并解决问题?如果你有这样的需求,那么System Dashboard Pro就是你的不二之选。 System Dashboar…...

C++ Qt如何往Windows AppData目录写数据
在使用Qt开发客户端软件时,我们可以把程序相关信息保存到AppData目录, 下次启动时读取,就可以保存程序的状态,便于用户使用。 Windows AppData目录是Windows操作系统中的一个重要目录,主要用于存储应用程序的自定义设置、文件和数据。这个目录包含了许多与应用程序相关的配…...

xargs命令
xargs命令 xargs 命令是一个非常好用的 Linux 命令,它可以将管道或标准输入转换成命令行参数,并用这些参数来执行指定 的命令。默认情况下, xargs 命令会将输入按照空格、制表符、换行符等符号进行分隔,并将它们作为一组参数 传…...
【原创】java+swing+mysql无偿献血管理系统设计与实现
摘要: 无偿献血管理系统是为了实现无偿献血规范化、有序化、高效化的管理而设计的。本文主要介绍使用java语言开发一个基于C/S架构的无偿献血管理系统,提高无偿献血管理的工作效率。 功能分析: 系统主要提供给管理员、无偿献血人员&#x…...

C语言 Number 1 基本数据类型
数据类型的定义 c语言的数据分类基本类型整型浮点型float和double的精度和范围范围精度 枚举类型空类型派生类型派生的一般表达形式 注 c语言的数据分类 首先是针对C语言的数据类型做个整理 大致分为四个大类型 基本类型枚举类型空类型派生类型 那么根据以上四个大类型 我们…...

mac录屏快捷键指南,轻松录制屏幕内容!
“大家知道mac电脑有录屏快捷键吗,现在录屏不太方便,每次都花很多时间,要是有录屏快捷键,应该会快速很多,可是哪里都找不到,有人知道吗?帮帮我!” 苹果的mac电脑以其精美的设计和卓…...
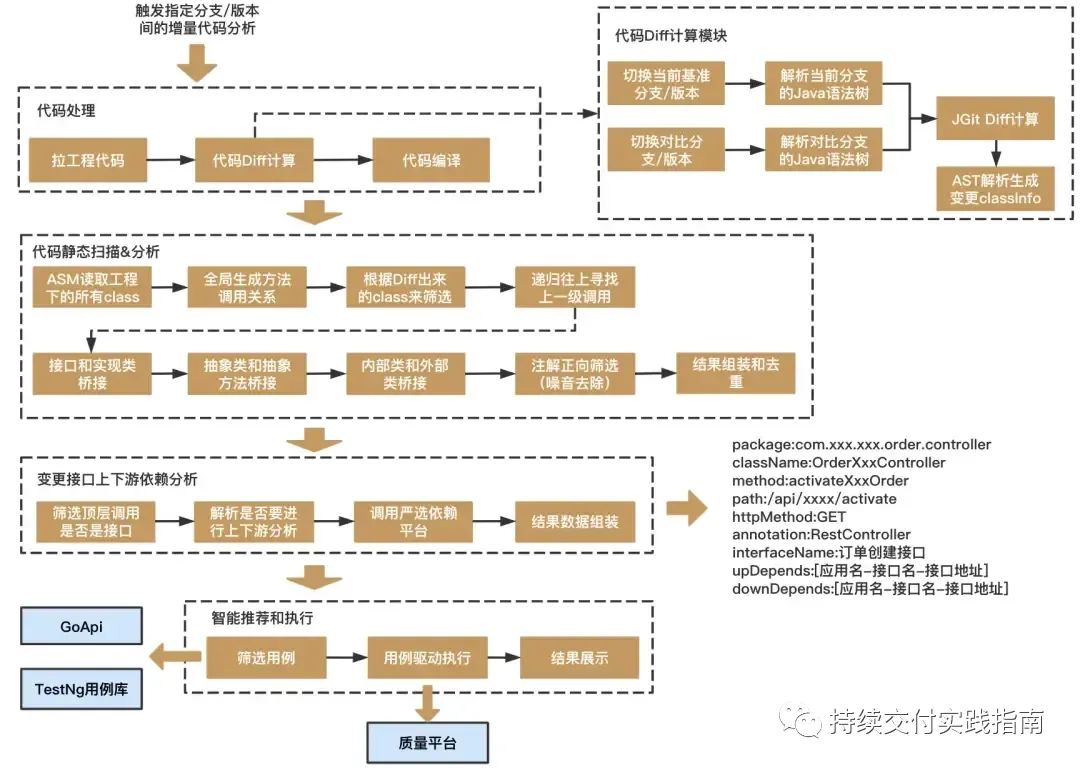
精准测试是个错误
如果你已经了解了精准测试在行业的主流做法,你可以跳过相关内容。 行业里对于精准测试的定义 在网上流传着一些精准测试的定义(如果你对这些定义不感冒,可直接跳到我个人的定义): 自网易陈逸青(2020&#x…...

算法通关村第四关|黄金挑战|表达式问题
1.计算器问题 给定一个内容为表达式的字符串,计算结果。 class Solution {public int calculate(String s) {Deque<Integer> stack new ArrayDeque<Integer>();char preSign ;int num 0;int n s.length();for (int i 0; i < n; i) {if (Chara…...
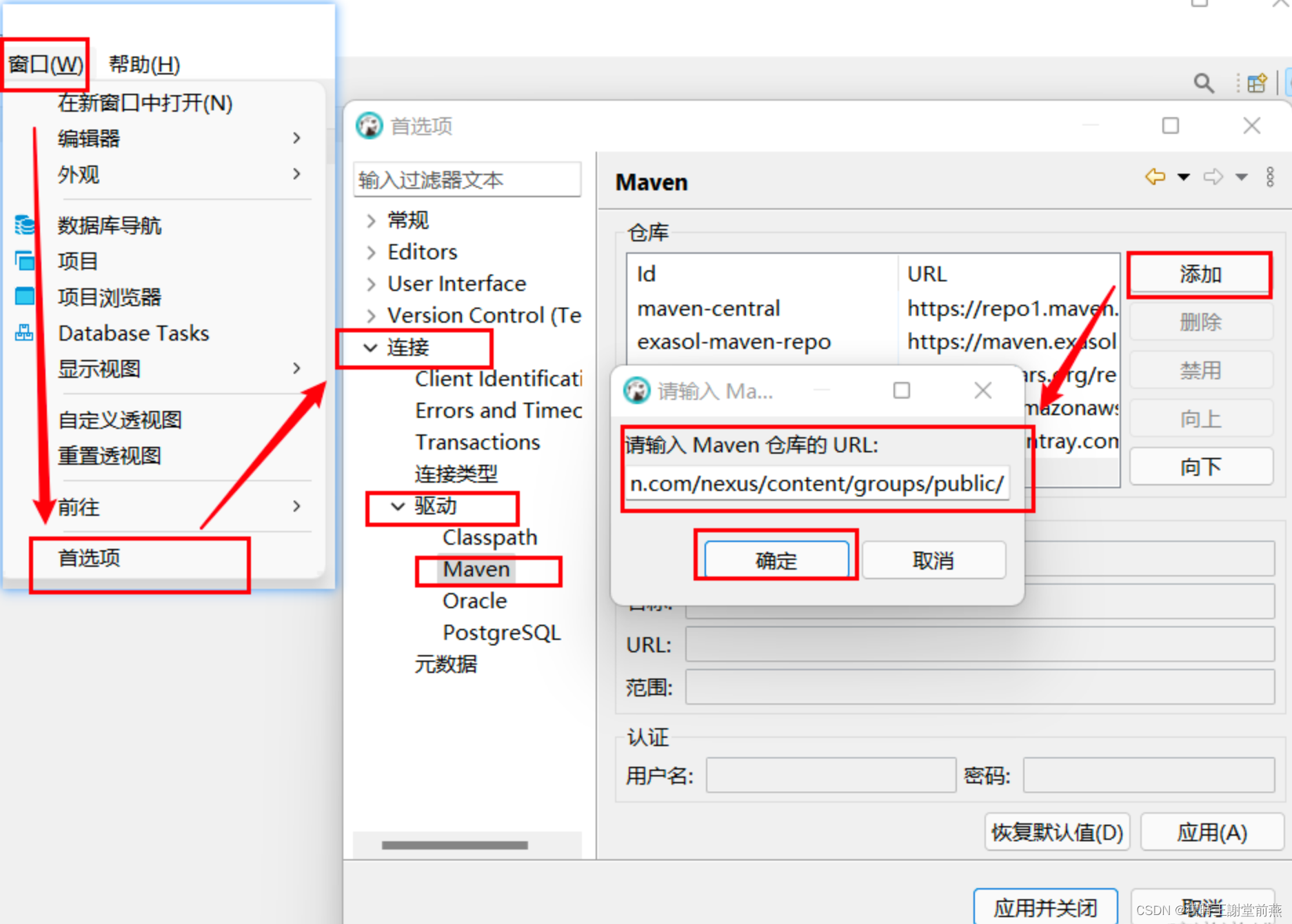
Mac安装DBeaver
目录 一、DBeaver Mac版软件简介 二、下载地址 三、DBeaver连接失败报错 3.1 问题描述 3.2 连接失败问题解决 一、DBeaver Mac版软件简介 DBeaver Mac版是一款专门为开发人员和数据库管理员设计的免费开源通用数据库工具。软件的易用性是它的宗旨,是经过精心设计…...

C++ 类 根据成员变量的指针获取类对象的指针
一.宏定义 实现方式有多种,原理是相同的 方式1: #define get_class_ptr(memberPtr,classType,memberName) \ ((classType*)((char*)(memberPtr)-(unsigned long)((ULONG_PTR)&((classType*)0)->member))) 方式2: #define get_cl…...
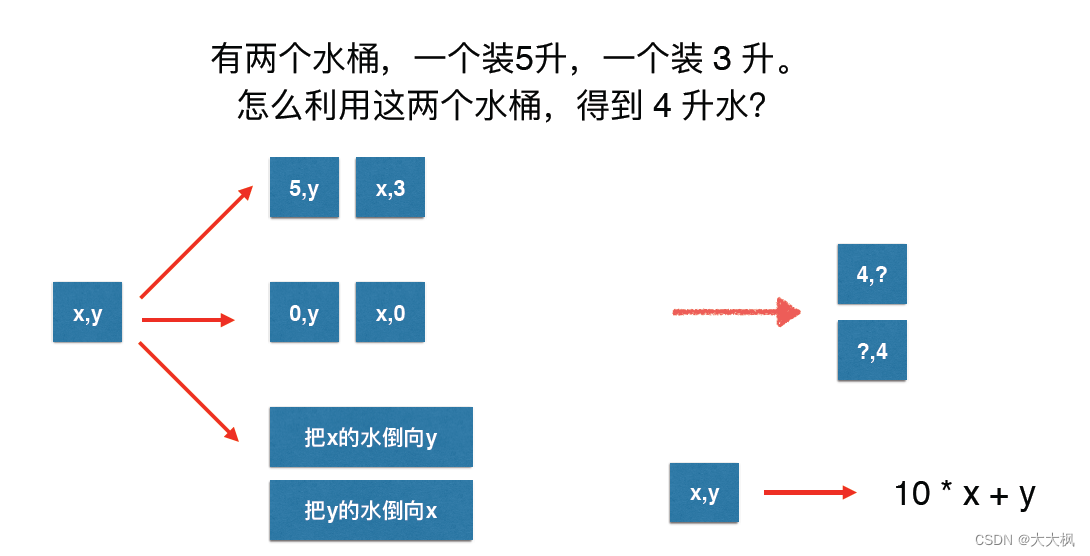
图论08-图的建模-状态的表达与理解 - 倒水问题为例
文章目录 状态的表达例题1题解1 终止条件:有一个数位为42 状态的改变:a表示十位数,b表示个位数3 其他设置 例题2 力扣773 滑动谜题JavaC 状态的表达 例题1 从初始的(x,y)状态,到最后变成(4,&am…...

sqlserver字符串拼接
本文主要介绍了sqlserver字符串拼接的实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值。 1. 概 在SQL语句中经常需要进行字符串拼接,以sqlserver,oracle,mysql三种数据库为例&#…...

MySQL-----事务
事务的概念 事务是一种机制,一个操作序列。包含了一组数据库的操作命令,所有的命令都是一个整体,向系统提交或者撤销的操作,要么都执行,要么都不执行。 是一个不可分割的单位 事务的ACID特点 ACID,是指在可…...

hive的安装配置笔记
1.上传hive安装包 2.解压 3.配置Hive(在一台机器上即可) mv hive-env.sh.template hive-env.sh 4.运行hive 发现内置默认的metastore存在问题(1.换执行路径后,原来的表不存在了。2.只能有一个用户访问同一个表) 5.配置mysql的meta…...

lamba stream处理集合
lamba stream处理集合 带拼接多字段分组List< Object> 转 Map<String,List< Object>> Map<String, List<ProfitAndLossMapping>> collect plMappingList.stream() .collect(Collectors.groupingBy(m -> m.getLosType() ":" m.…...
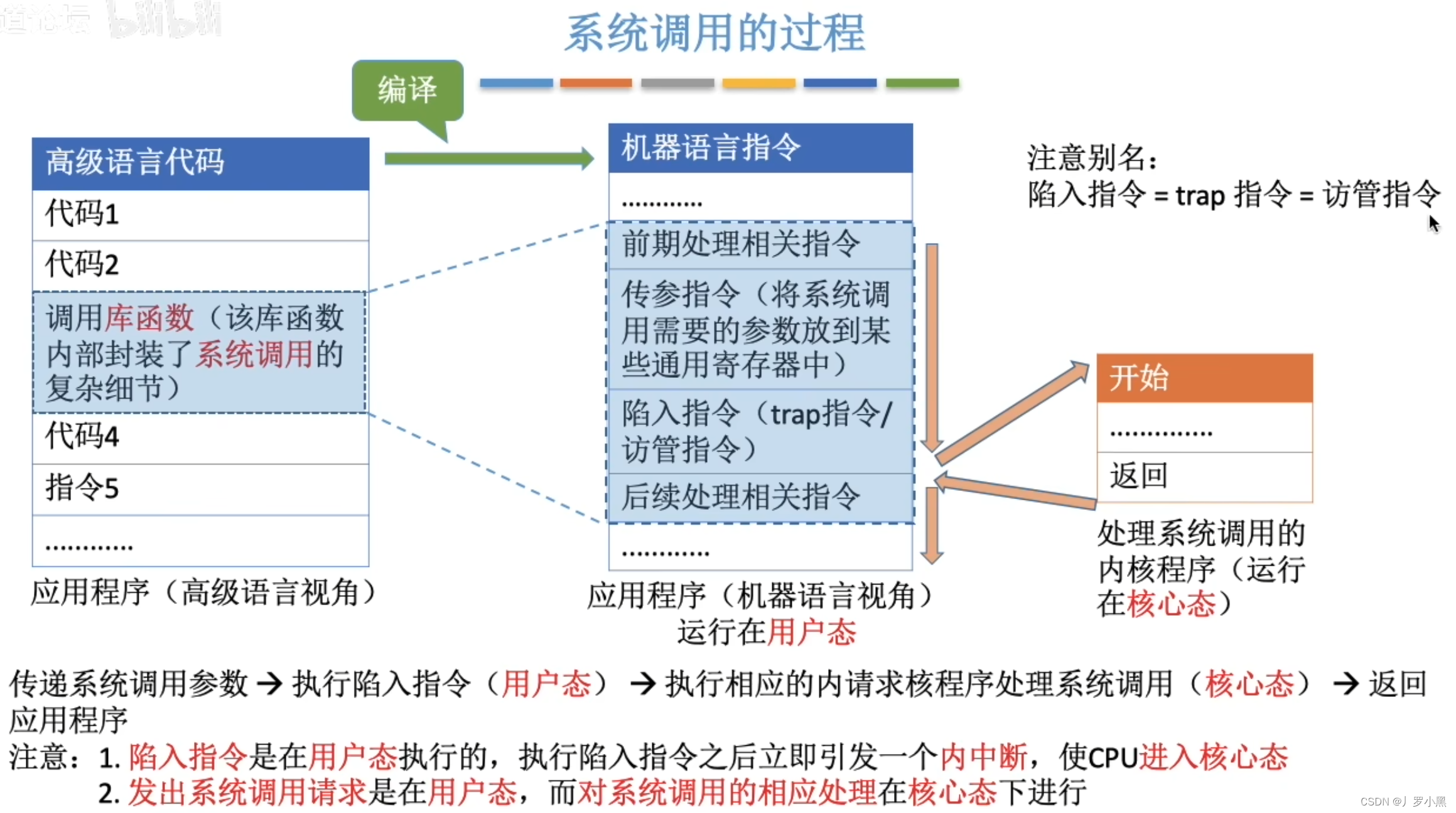
操作系统 day04(系统调用)
什么是系统调用 库函数和系统调用的区别 应用程序可以通过汇编语言直接进行系统调用,也可以使用高级语言的库函数来进行系统调用。而有的库函数涉及系统调用,如“创建一个新文件”函数,有的不涉及,如“取绝对值”函数 什么功能要…...
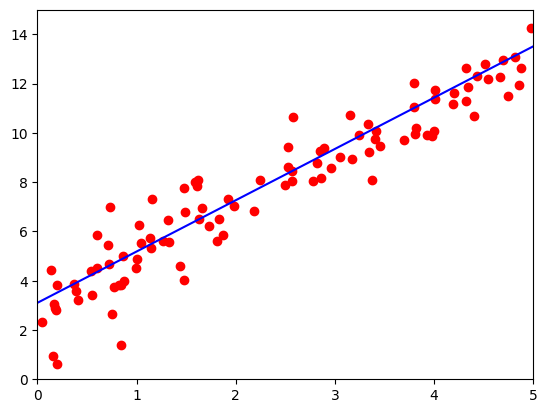
【深度学习】pytorch——线性回归
笔记为自我总结整理的学习笔记,若有错误欢迎指出哟~ 深度学习专栏链接: http://t.csdnimg.cn/dscW7 pytorch——线性回归 线性回归简介公式说明完整代码代码解释 线性回归简介 线性回归是一种用于建立特征和目标变量之间线性关系的统计学习方法。它假设…...

终极解决方案:在Chrome浏览器中实现密码无缝同步
终极解决方案:在Chrome浏览器中实现密码无缝同步 【免费下载链接】ChromeKeePass Chrome extensions for automatically filling credentials from KeePass 项目地址: https://gitcode.com/gh_mirrors/ch/ChromeKeePass 你是否厌倦了每次登录网站时都要手动从…...

Windows硬件指纹保护终极教程:3步掌握EASY-HWID-SPOOFER安全使用
Windows硬件指纹保护终极教程:3步掌握EASY-HWID-SPOOFER安全使用 【免费下载链接】EASY-HWID-SPOOFER 基于内核模式的硬件信息欺骗工具 项目地址: https://gitcode.com/gh_mirrors/ea/EASY-HWID-SPOOFER 在数字时代,你的硬件信息正在被悄悄收集—…...

US Visa Bot:开源智能预约解决方案,告别签证等待焦虑
US Visa Bot:开源智能预约解决方案,告别签证等待焦虑 【免费下载链接】us-visa-bot US Visa Bot 项目地址: https://gitcode.com/gh_mirrors/us/us-visa-bot 您是否曾经为了一个美国签证面试日期而反复刷新页面,却总是错过最佳时机&am…...

大学英语四级试卷历年真题及答案PDF电子版百度网盘
大学英语四级备考必备历年真题合集(2015年6月-2025年12月),高清 PDF 电子版含完整试卷与详细答案解析,以及配套听力音频,题型齐全答案详实,可下载打印刷题,吃透真题考点,高效冲刺顺利…...

快如闪电!超越人类反应极限!
在工业控制以及航空航天等核心场景,极速启动就是高可靠系统的生命线。0.2毫秒超快启动搭配硬件看门狗,让设备在掉电重启、异常恢复时瞬时归位,关键任务永不延误! https://www.bilibili.com/video/BV1yvLs6JEJa/?spm_id_from333.1…...

六自由度并联无人机自适应起降平台设计——从构型选型到运动学仿真全流程
六自由度并联无人机自适应起降平台设计——从构型选型到运动学仿真全流程 摘要 随着无人机物流配送、海上作业、灾害救援等场景的快速发展,无人机在动态环境下的安全起降成为制约其大规模应用的瓶颈问题。传统的固定起降平台无法适应舰船摇摆、车辆运动等动态条件,而串联机…...

Steam Economy Enhancer:终极Steam市场与库存自动化管理指南
Steam Economy Enhancer:终极Steam市场与库存自动化管理指南 【免费下载链接】Steam-Economy-Enhancer 中文版:Enhances the Steam Inventory and Steam Market. 项目地址: https://gitcode.com/gh_mirrors/ste/Steam-Economy-Enhancer Steam Eco…...

在Node.js服务中集成Taotoken实现统一的多模型调用网关
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Node.js服务中集成Taotoken实现统一的多模型调用网关 对于构建在Node.js上的后端服务,直接对接多个大模型供应商的AP…...

免费压缩包密码恢复工具:ArchivePasswordTestTool终极指南
免费压缩包密码恢复工具:ArchivePasswordTestTool终极指南 【免费下载链接】ArchivePasswordTestTool 利用7zip测试压缩包的功能 对加密压缩包进行自动化测试密码 项目地址: https://gitcode.com/gh_mirrors/ar/ArchivePasswordTestTool 你是否曾经因为忘记压…...

InfluxDB Studio:如何用一款工具解决时间序列数据库管理的三大痛点
InfluxDB Studio:如何用一款工具解决时间序列数据库管理的三大痛点 【免费下载链接】InfluxDBStudio InfluxDB Studio is a UI management tool for the InfluxDB time series database. 项目地址: https://gitcode.com/gh_mirrors/in/InfluxDBStudio 时间序…...