【深度学习】pytorch——线性回归
笔记为自我总结整理的学习笔记,若有错误欢迎指出哟~
深度学习专栏链接:
http://t.csdnimg.cn/dscW7
pytorch——线性回归
- 线性回归简介
- 公式说明
- 完整代码
- 代码解释
线性回归简介
线性回归是一种用于建立特征和目标变量之间线性关系的统计学习方法。它假设特征和目标变量之间存在一个线性的关系,并试图通过拟合最佳的线性函数来预测目标变量。
线性回归模型的一般形式可以表示为:
y = w 0 + w 1 x 1 + w 2 x 2 + … + w n x n y = w_0 + w_1x_1 + w_2x_2 + \ldots + w_nx_n y=w0+w1x1+w2x2+…+wnxn
其中, y y y 是目标变量(或因变量), x 1 , x 2 , … , x n x_1, x_2, \ldots, x_n x1,x2,…,xn 是特征变量(或自变量), w 0 , w 1 , w 2 , … , w n w_0, w_1, w_2, \ldots, w_n w0,w1,w2,…,wn 是模型的参数,分别对应截距和各个特征的权重。
线性回归模型的训练过程就是寻找最优的参数 w 0 , w 1 , w 2 , … , w n w_0, w_1, w_2, \ldots, w_n w0,w1,w2,…,wn 来使得模型的预测值与实际值之间的差异最小化。
公式说明
以下是代码涉及到的数学公式
- 线性回归模型
线性回归模型用于建立特征 x x x 和目标变量 y y y 之间的线性关系。在本代码中,线性回归模型被表示为:
y = w x + b y = wx + b y=wx+b
其中, w w w 是权重(即斜率), b b b 是偏置(即截距), x x x 是输入特征, y y y 是预测值。
- 损失函数
损失函数用于衡量模型预测值与实际标签之间的差异。在本代码中,使用的损失函数是均方误差(Mean Squared Error,MSE):
l o s s = 1 2 n ∑ i = 1 n ( y p r e d ( i ) − y ( i ) ) 2 loss = \frac{1}{2n} \sum_{i=1}^{n} (y_{pred}^{(i)} - y^{(i)})^2 loss=2n1i=1∑n(ypred(i)−y(i))2
其中, y p r e d ( i ) y_{pred}^{(i)} ypred(i) 是模型的第 i i i 个样本的预测值, y ( i ) y^{(i)} y(i) 是实际标签, n n n 是样本数量。
- 其他运算
代码中还涉及到了矩阵乘法、矩阵转置、元素级别的操作等。例如, x . m m ( w ) x.mm(w) x.mm(w) 表示将输入特征 x x x 与权重 w w w 进行矩阵乘法; x T . m m ( d y _ p r e d ) x^T.mm(dy\_pred) xT.mm(dy_pred) 表示将输入特征 x x x 的转置与梯度 d y _ p r e d dy\_pred dy_pred 进行矩阵乘法。
完整代码
import torch as t
%matplotlib inline
from matplotlib import pyplot as plt
from IPython import displaydevice = t.device('cpu') #如果你想用gpu,改成t.device('cuda:0')# 设置随机数种子,保证在不同电脑上运行时下面的输出一致
t.manual_seed(1000) def get_fake_data(batch_size=8):''' 产生随机数据:y=x*2+3,加上了一些噪声'''x = t.rand(batch_size, 1, device=device) * 5y = x * 2 + 3 + t.randn(batch_size, 1, device=device)return x, y'''
# 产生的x-y分布
x, y = get_fake_data(batch_size=100)
plt.scatter(x.squeeze().cpu().numpy(), y.squeeze().cpu().numpy())
'''# 随机初始化参数
w = t.rand(1, 1).to(device)
b = t.zeros(1, 1).to(device)lr =0.02 # 学习率for ii in range(500):x, y = get_fake_data(batch_size=4)# forward:计算lossy_pred = x.mm(w) + b.expand_as(y) loss = 0.5 * (y_pred - y) ** 2 # 均方误差loss = loss.mean()# backward:手动计算梯度dloss = 1dy_pred = dloss * (y_pred - y)dw = x.t().mm(dy_pred)db = dy_pred.sum()# 更新参数w.sub_(lr * dw)b.sub_(lr * db)if ii%50 ==0:# 画图display.clear_output(wait=True)x = t.arange(0, 6).view(-1, 1)y = x.float().mm(w) + b.expand_as(x)plt.plot(x.cpu().numpy(), y.cpu().numpy(),color='b') # predictedx2, y2 = get_fake_data(batch_size=100) plt.scatter(x2.numpy(), y2.numpy(),color='r') # true dataplt.xlim(0, 5)plt.ylim(0, 15)plt.show()plt.pause(0.5)print('w: ', w.item(), 'b: ', b.item())
输出结果为:
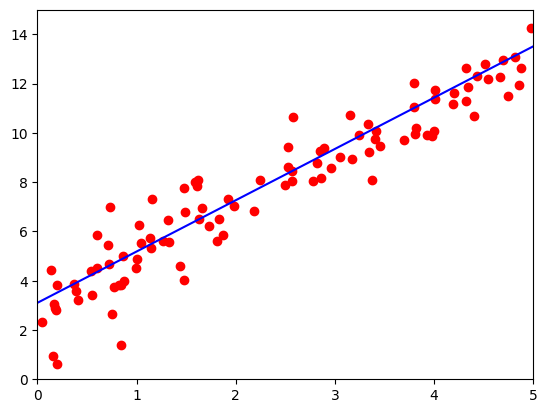
w: 1.9709817171096802 b: 3.1699466705322266
代码解释
- 导入需要的库:
import torch as t
%matplotlib inline
from matplotlib import pyplot as plt
from IPython import display
导入PyTorch库以及绘图相关的库,%matplotlib inline是Jupyter Notebook中的魔法命令,用于在Notebook中显示绘图。
- 设置随机数种子:
t.manual_seed(1000)
这行代码设置随机数种子,保证每次运行结果的随机数生成过程一致。
- 定义生成随机数据的函数:
def get_fake_data(batch_size=8):''' 产生随机数据:y=x*2+3,加上了一些噪声'''x = t.rand(batch_size, 1, device=device) * 5y = x * 2 + 3 + t.randn(batch_size, 1, device=device)return x, y
该函数用于产生随机的输入特征x和对应的标签y,其中y满足线性关系y = x * 2 + 3,并添加了一些随机噪声。
- 初始化模型参数:
w = t.rand(1, 1).to(device)
b = t.zeros(1, 1).to(device)
这里使用随机数初始化模型参数w和b,并指定在CPU上进行计算。
- 设置学习率:
lr = 0.02
学习率lr控制每次参数更新的步长。
- 进行模型训练:
for ii in range(500):# 生成随机数据x, y = get_fake_data(batch_size=4)# forward:计算损失y_pred = x.mm(w) + b.expand_as(y)loss = 0.5 * (y_pred - y) ** 2loss = loss.mean()# backward:手动计算梯度dloss = 1dy_pred = dloss * (y_pred - y)dw = x.t().mm(dy_pred)db = dy_pred.sum()# 更新参数w.sub_(lr * dw)b.sub_(lr * db)
这里使用一个循环进行模型的训练,每次迭代都包含以下步骤:
- 生成随机数据;
- 前向传播:计算预测值
y_pred和损失函数loss; - 反向传播:手动计算梯度
dw和db; - 更新参数:根据梯度和学习率更新参数
w和b。
- 可视化模型训练过程:
if ii % 50 == 0:display.clear_output(wait=True)x = t.arange(0, 6).view(-1, 1)y = x.float().mm(w) + b.expand_as(x)plt.plot(x.cpu().numpy(), y.cpu().numpy(), color='b') # predicted linex2, y2 = get_fake_data(batch_size=100)plt.scatter(x2.numpy(), y2.numpy(), color='r') # true dataplt.xlim(0, 5)plt.ylim(0, 15)plt.show()plt.pause(0.5)
这部分代码用于可视化模型训练的过程,每50次迭代将当前参数下的预测结果以蓝色线条的形式绘制出来,并将随机生成的100个样本以红色散点图显示出来。
- 输出最终训练得到的参数:
print('w: ', w.item(), 'b: ', b.item())
输出训练得到的参数w和b的值。
相关文章:
【深度学习】pytorch——线性回归
笔记为自我总结整理的学习笔记,若有错误欢迎指出哟~ 深度学习专栏链接: http://t.csdnimg.cn/dscW7 pytorch——线性回归 线性回归简介公式说明完整代码代码解释 线性回归简介 线性回归是一种用于建立特征和目标变量之间线性关系的统计学习方法。它假设…...

golang工程——中间件redis,单节点集群部署
单节点redis集群部署 部署redis 6.2.7版本 没资源,就用一台机子部 解压安装包 tar zxf redis-6.2.7.tar.gzcd redis-6.2.7编译安装 mkdir -p /var/local/redis-6.2.7/{data,conf,logs,pid}data:数据目录 conf:配置文件目录 logs…...

Lua基础
table 基本原理: table是一种特殊的容器,可以向数组一样按照索引存取,也能按照键值对存取。 local mytable {1,2,3} --相当于数组 local mytable {[1]1,[2]2,[3]3} --和上面等价 local mytable {1,2,3,[3] 4} --隐式赋值会覆盖掉显式赋…...
微信小程序之开发工具介绍
一、微信小程序开发工具下载 微信小程序开发工具下载可以参考这篇博客《微信小程序开发者工具下载-CSDN博客》 二、开发工具组成部分 如下图所示,开发者工具主要由菜单栏、工具栏、模拟器、编辑器和调试器 5 个部分组成。。 1、菜单栏 菜单栏中主要包括项目、文…...
【AUTOSAR】【以太网】DoIp
AUTOSAR专栏——总目录_嵌入式知行合一的博客-CSDN博客文章浏览阅读217次。本文主要汇总该专栏文章,以方便各位读者阅读。https://xianfan.blog.csdn.net/article/details/132072415 目录 一、概述 二、功能描述 2.1 Do...

游戏中UI的性能优化手段
UI方面有许多性能优化的技术或手段,以下是其中一些常见的例子: 惰性加载:对于长列表、大图等需要加载大量数据和资源的组件,可以采用惰性加载的方式,即在用户需要时再进行加载。这样可以减少初始加载时间和内存占用&am…...
Idea快速生成测试类
例如写写完一个功能类,需要对里面方法进行测试 在当前页面 按住CTRLSHFITT 选择你要生成的测试方法 点击OK,就会在test目录下在你对应包下生成对应测试类...

Java文件操作详解
CONTENTS 1. 文件和目录路径1.1 获取Path的片段1.2 获取Path信息1.3 添加或删除路径片段 2. 文件系统3. 查找文件4. 读写文件 1. 文件和目录路径 Path 对象代表的是一个文件或目录的路径,它是在不同的操作系统和文件系统之上的抽象。它的目的是,在构建路…...

二叉树系列主题Code
Python实现二叉树遍历 # 定义二叉树节点类 class TreeNode: def __init__(self, val0, leftNone, rightNone): self.val val self.left left self.right right # 前序遍历(非递归) def preorderTraversal(root): if not root: return [] …...

Leetcode 673. 最长递增子序列的个数 C++
673最长递增子序列的个数 给定一个未排序的整数数组 nums , 返回最长递增子序列的个数 。 注意 这个数列必须是 严格 递增的。 示例 1: 输入: [1,3,5,4,7] 输出: 2 解释: 有两个最长递增子序列,分别是 [1, 3, 4, 7] 和[1, 3, 5, 7]。 示例 2: 输入: …...

html用css grid实现自适应四宫格放视频
想同时播放四个本地视频: 四宫格;自式应,即放缩浏览器时,四宫格也跟着放缩;尽量填满页面(F11 浏览器全屏时可以填满整个屏幕)。 在 html 中放视频用 video 标签,参考 [1]࿱…...

【机器学习可解释性】5.SHAP值的高级使用
机器学习可解释性 1.模型洞察的价值2.特征重要性排列3.部分依赖图4.SHAP 值5.SHAP值的高级使用 正文 汇总SHAP值以获得更详细的模型解释 总体回顾 我们从学习排列重要性和部分依赖图开始,以显示学习后的模型的内容。 然后我们学习了SHAP值来分解单个预测的组成部…...

CentOS开机自动运行jar程序实现
前面已经有一篇文章介绍jar包如何在CentOS上运行,《在linux上运行jar程序操作记录》 后来发现系统重启后不能自动运行,导致每次都要手动打开,这篇介绍如何自动开机启动运行jar程序。 一、找到JDK程序执行位置 [rootlocalhost /]# which jav…...
matlab双目标定中基线物理长度获取
在MATLAB进行双目摄像机标定时,通常会获得相机的内参,其中包括像素单位的焦距(focal length)以及物理单位的基线长度(baseline)。对于应用中的深度估计和测量,基线长度的物理单位非常重要,因为它直接影响到深度信息的准确性。有时候,您可能只能获取像素单位的焦距和棋…...

自己动手实现一个深度学习算法——二、神经网络的实现
文章目录 1. 神经网络概述1)表示2)激活函数3)sigmoid函数4)阶跃函数的实现5)sigmoid函数的实现6)sigmoid函数和阶跃函数的比较7)非线性函数8)ReLU函数 2.三层神经网络的实现1)结构2&…...
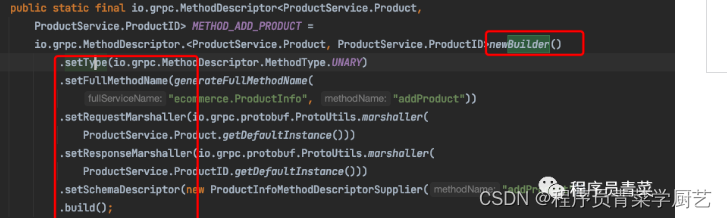
gRPC源码剖析-Builder模式
一、Builder模式 1、定义 将一个复杂对象的构建与表示分离,使得同样的构建过程可以创建不同的的表示。 2、适用场景 当创建复杂对象的算法应独立于该对象的组成部分以及它们的装配方式时。 当构造过程必须允许被构造的对象有不同的表示时。 说人话:…...

ARM传输数据以及移位操作
3.2.2 数据传送指令 LDR/STR指令用来在寄存器和内存之间输送数据。如果我们想要在寄存器之间传送数据,则可以使用MOV指令。MOV指令的格式如下。 MOV {cond} {s}Rd, oprand2 MOV {cond} {s}Rd, oprand2 其中,{cond}为条件指令可选项,{s}用来表…...
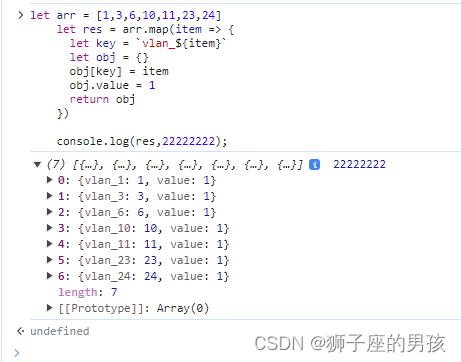
06、如何将对象数组里 obj 的 key 值变成动态的(即:每一个对象对应的 key 值都不同)
1、数据情况: 其一、从后端拿到的数据为: let arr [1,3,6,10,11,23,24] 其二、目标数据为: [{vlan_1: 1, value: 1}, {vlan_3: 3, value: 1}, {vlan_6: 6, value: 1}, {vlan_10: 10, value: 1}, {vlan_11: 11, value: 1}, {vlan_23: 23, v…...
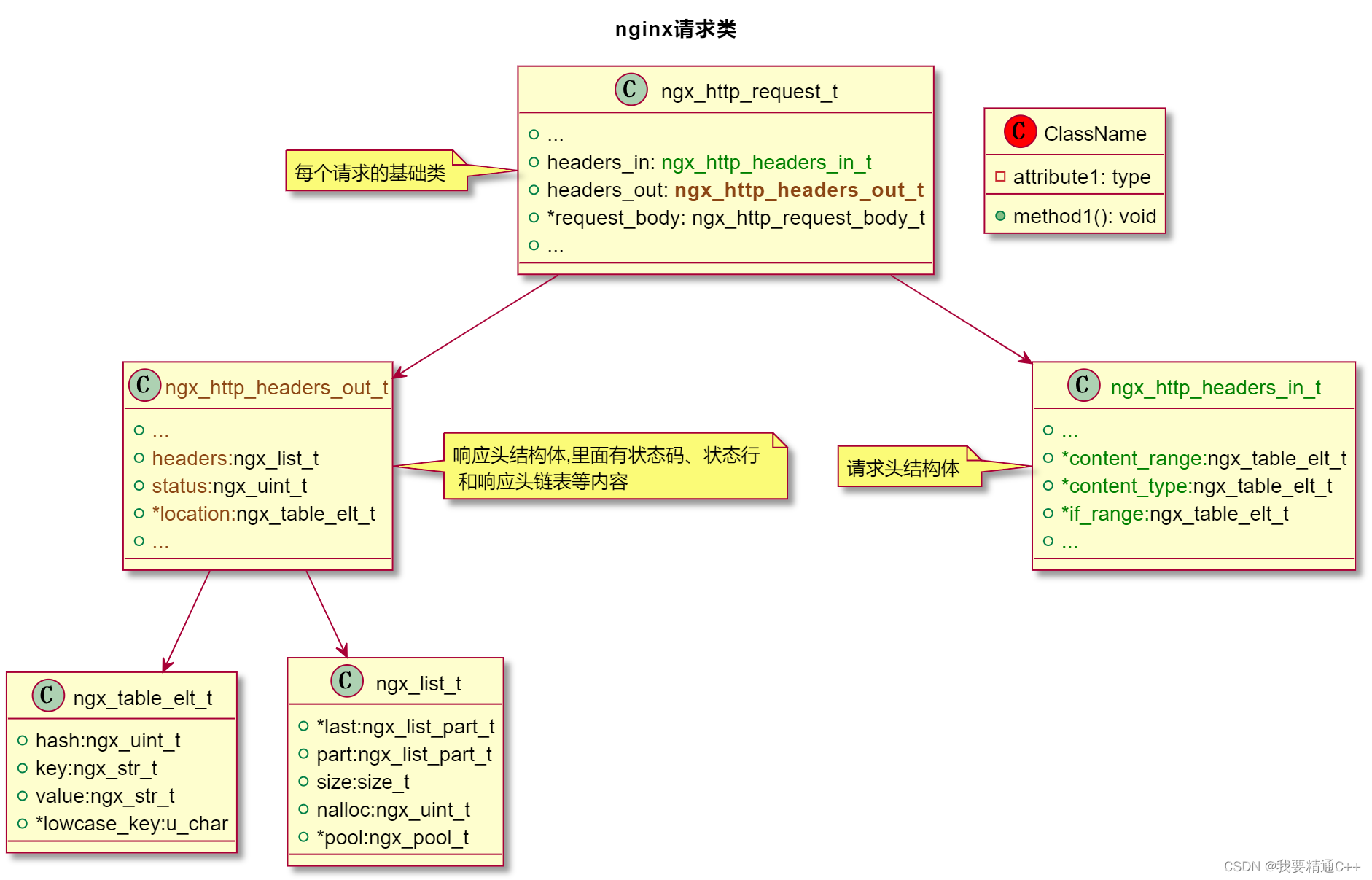
ngx_http_request_s
/* 罗剑锋老师的注释参考: https://github.com/chronolaw/annotated_nginx/blob/master/nginx/src/http/ngx_http_request.h */struct ngx_http_request_s {uint32_t signature; /* "HTTP" */ngx_connection_t …...

Docker 学习路线 2:底层技术
了解驱动Docker的核心技术将让您更深入地了解Docker的工作原理,并有助于您更有效地使用该平台。 Linux容器(LXC) Linux容器(LXC)是Docker的基础。 LXC是一种轻量级的虚拟化解决方案,允许多个隔离的Linux系…...

从 AI 工具到音乐生态:可酷加速布局,构建数字音乐全新基础设施
当数字音乐行业从流量竞争迈入生态竞争的新阶段,单一产品的功能边界已难以支撑企业长期增长,完善的生态协同能力逐渐成为企业突围的核心竞争力,也成为定义行业未来格局的关键变量。在此背景下,可酷公司近日对外披露其全新发展战略…...

YOLO格式标注避坑指南:用labelImg时,你的classes.txt文件生成对了吗?
YOLO格式标注避坑指南:labelImg中classes.txt的隐藏逻辑与实战解决方案 在计算机视觉项目的实际开发中,数据标注的质量往往直接决定了模型性能的上限。许多团队花费大量时间标注数据后,却在模型训练阶段遭遇"标签ID不匹配"、"…...

HS2-HF Patch:如何用5分钟为HoneySelect2实现完整汉化与MOD整合
HS2-HF Patch:如何用5分钟为HoneySelect2实现完整汉化与MOD整合 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch HS2-HF Patch是HoneySelect2玩家的终…...

私有化视频会议平台/视频高清直播点播EasyDSS构建智慧校园音视频协作新生态
在教育数字化转型的关键阶段,智慧校园对音视频协作系统的需求,已从基础的远程沟通,升级为安全可控、体验流畅、管理智能的一体化解决方案。视频直播点播平台EasyDSS凭借技术创新与场景深耕,成为智慧校园建设的核心支撑,…...
)
【权威实测报告】:在137组对比测试中,仅2组prompt达成Apple Human Interface Guidelines认证级毛玻璃效果(附完整prompt审计清单)
更多请点击: https://kaifayun.com 第一章:【权威实测报告】:在137组对比测试中,仅2组prompt达成Apple Human Interface Guidelines认证级毛玻璃效果(附完整prompt审计清单) 为验证当前主流AI图像生成模型…...

紧急更新!Midjourney v6.6对洛可可风格支持突降37%?立即启用这5个兼容性补丁prompt,保住你的商业项目交付期
更多请点击: https://intelliparadigm.com 第一章:Midjourney v6.6洛可可风格兼容性危机全景速览 Midjourney v6.6 发布后,大量用户在生成洛可可(Rococo)风格图像时遭遇显著退化:繁复卷曲的藤蔓纹样被简化…...

FLUX.1-dev-Controlnet-Union终极指南:7种控制模式一站式掌握AI图像生成
FLUX.1-dev-Controlnet-Union终极指南:7种控制模式一站式掌握AI图像生成 【免费下载链接】FLUX.1-dev-Controlnet-Union 项目地址: https://ai.gitcode.com/hf_mirrors/InstantX/FLUX.1-dev-Controlnet-Union 你是否曾经在创作AI图像时感到束手无策…...

换平台就得重开发?低代码平台锁定的困局与破解
“想升级平台版本,原有应用全部不兼容;想换个厂商,花两年搭的系统完全作废,数据导不出来、流程没法迁移,只能推倒重来……”低代码平台的 “锁定效应”,让无数企业陷入 “用着难受、扔了可惜” 的两难困境。…...

技术赋能:ROS机器人仿真平台的虚拟试炼场
技术赋能:ROS机器人仿真平台的虚拟试炼场 【免费下载链接】wpr_simulation 项目地址: https://gitcode.com/gh_mirrors/wp/wpr_simulation 想象这样一个场景:你正在设计一款能够自主导航的家庭服务机器人,但面对高昂的硬件成本、漫长…...

终极视频修复神器UNTRUNC:如何免费恢复损坏的MP4/MOV文件
终极视频修复神器UNTRUNC:如何免费恢复损坏的MP4/MOV文件 【免费下载链接】untrunc Restore a damaged (truncated) mp4, m4v, mov, 3gp video. Provided you have a similar not broken video. 项目地址: https://gitcode.com/gh_mirrors/unt/untrunc 你是否…...