Flink日志采集-ELK可视化实现
一、各组件版本
| 组件 | 版本 |
|---|---|
| Flink | 1.16.1 |
| kafka | 2.0.0 |
| Logstash | 6.5.4 |
| Elasticseach | 6.3.1 |
| Kibana | 6.3.1 |
针对按照⽇志⽂件⼤⼩滚动⽣成⽂件的⽅式,可能因为某个错误的问题,需要看好多个⽇志⽂件,还有Flink on Yarn模式提交Flink任务,在任务执行完毕或者任务报错后container会被回收从而导致日志丢失,为了方便排查问题可以把⽇志⽂件通过KafkaAppender写⼊到kafka中,然后通过ELK等进⾏⽇志搜索甚⾄是分析告警。
二、Flink配置将日志写入Kafka
2.1 flink-conf.yaml增加下面两行配置信息
env.java.opts.taskmanager: -DyarnContainerId=$CONTAINER_ID
env.java.opts.jobmanager: -DyarnContainerId=$CONTAINER_ID
2.2 log4j.properties配置案例如下
##################################################################
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
##################################################################
# Allows this configuration to be modified at runtime. The file will be checked every 30 seconds.
monitorInterval=30# This affects logging for both user code and Flink
#rootLogger.appenderRef.file.ref = MainAppender
rootLogger.level = INFO
rootLogger.appenderRef.kafka.ref = Kafka
rootLogger.appenderRef.file.ref = RollingFileAppender# Uncomment this if you want to _only_ change Flink's logging
#logger.flink.name = org.apache.flink
#logger.flink.level = INFO# The following lines keep the log level of common libraries/connectors on
# log level INFO. The root logger does not override this. You have to manually
# change the log levels here.
logger.akka.name = akka
logger.akka.level = INFO
logger.kafka.name= org.apache.kafka
logger.kafka.level = INFO
logger.hadoop.name = org.apache.hadoop
logger.hadoop.level = INFO
logger.zookeeper.name = org.apache.zookeeper
logger.zookeeper.level = INFO
logger.shaded_zookeeper.name = org.apache.flink.shaded.zookeeper3
logger.shaded_zookeeper.level = INFO# Log all infos in the given file
appender.rolling.name = RollingFileAppender
appender.rolling.type = RollingFile
appender.rolling.append = false
appender.rolling.fileName = ${sys:log.file}
appender.rolling.filePattern = ${sys:log.file}.%i
appender.rolling.layout.type = PatternLayout
appender.rolling.layout.pattern = %d{yyyy-MM-dd HH:mm:ss,SSS} %-5p %-60c %x - %m%n
appender.rolling.policies.type = Policies
appender.rolling.policies.size.type = SizeBasedTriggeringPolicy
appender.rolling.policies.size.size = 500MB
appender.rolling.strategy.type = DefaultRolloverStrategy
appender.rolling.strategy.max = 10#appender.main.name = MainAppender
#appender.main.type = RollingFile
#appender.main.append = true
#appender.main.fileName = ${sys:log.file}
#appender.main.filePattern = ${sys:log.file}.%i
#appender.main.layout.type = PatternLayout
#appender.main.layout.pattern = %d{yyyy-MM-dd HH:mm:ss,SSS} %-5p %-60c %x - %m%n
#appender.main.policies.type = Policies
#appender.main.policies.size.type = SizeBasedTriggeringPolicy
#appender.main.policies.size.size = 100MB
#appender.main.policies.startup.type = OnStartupTriggeringPolicy
#appender.main.strategy.type = DefaultRolloverStrategy
#appender.main.strategy.max = ${env:MAX_LOG_FILE_NUMBER:-10}# kafka
appender.kafka.type = Kafka
appender.kafka.name = Kafka
appender.kafka.syncSend = true
appender.kafka.ignoreExceptions = false
appender.kafka.topic = flink_logs
appender.kafka.property.type = Property
appender.kafka.property.name = bootstrap.servers
appender.kafka.property.value = xxx1:9092,xxx2:9092,xxx3:9092
appender.kafka.layout.type = JSONLayout
apender.kafka.layout.value = net.logstash.log4j.JSONEventLayoutV1
appender.kafka.layout.compact = true
appender.kafka.layout.complete = false# Suppress the irrelevant (wrong) warnings from the Netty channel handler
#logger.netty.name = org.jboss.netty.channel.DefaultChannelPipeline
logger.netty.name = org.apache.flink.shaded.akka.org.jboss.netty.channel.DefaultChannelPipeline
logger.netty.level = OFF#通过 flink on yarn 模式还可以添加⾃定义字段
# 日志路径
appender.kafka.layout.additionalField1.type = KeyValuePair
appender.kafka.layout.additionalField1.key = logdir
appender.kafka.layout.additionalField1.value = ${sys:log.file}
# flink-job-name
appender.kafka.layout.additionalField2.type = KeyValuePair
appender.kafka.layout.additionalField2.key = flinkJobName
appender.kafka.layout.additionalField2.value = ${sys:flinkJobName}
# 提交到yarn的containerId
appender.kafka.layout.additionalField3.type = KeyValuePair
appender.kafka.layout.additionalField3.key = yarnContainerId
appender.kafka.layout.additionalField3.value = ${sys:yarnContainerId}
上⾯的 appender.kafka.layout.type 可以使⽤ JSONLayout ,也可以⾃定义。
⾃定义需要将上⾯的appender.kafka.layout.type 和 appender.kafka.layout.value 修改成如下:
appender.kafka.layout.type = PatternLayout
appender.kafka.layout.pattern ={"log_level":"%p","log_timestamp":"%d{ISO8601}","log_thread":"%t","log_file":"%F","l
og_line":"%L","log_message":"'%m'","log_path":"%X{log_path}","job_name":"${sys:flink
_job_name}"}%n
2.3 基于Flink on yarn模式提交任务前期准备
2.3.1 需要根据kafka的版本在flink/lib⽬录下放⼊kafka-clients的jar包
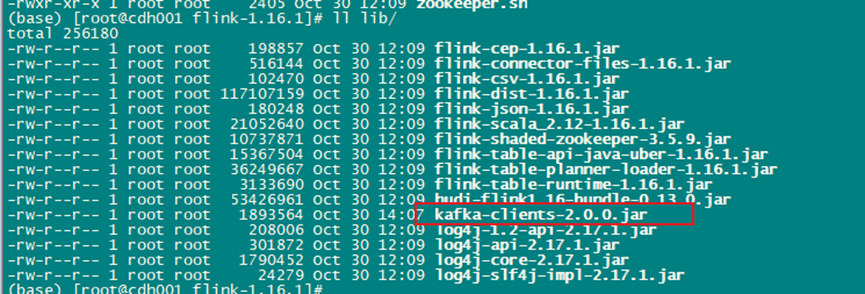
2.3.2 kafka处于启动状态
2.3.3 Flink Standalone集群
# 根据kafka的版本放⼊kafka-clients
kafka-clients-3.1.0.jar
# jackson对应的jar包
jackson-annotations-2.13.3.jar
jackson-core-2.13.3.jar
jackson-databind-2.13.3.jar
2.4 Flink on yarn任务提交案例
/root/software/flink-1.16.1/bin/flink run-application \
-t yarn-application \
-D yarn.application.name=TopSpeedWindowing \
-D parallelism.default=3 \
-D jobmanager.memory.process.size=2g \
-D taskmanager.memory.process.size=2g \
-D env.java.opts="-DflinkJobName=TopSpeedWindowing" \
/root/software/flink-1.16.1/examples/streaming/TopSpeedWindowing.jar
【注意】启动脚本需要加入这个参数,日志才能采集到任务名称(-D env.java.opts="-DflinkJobName=xxx")
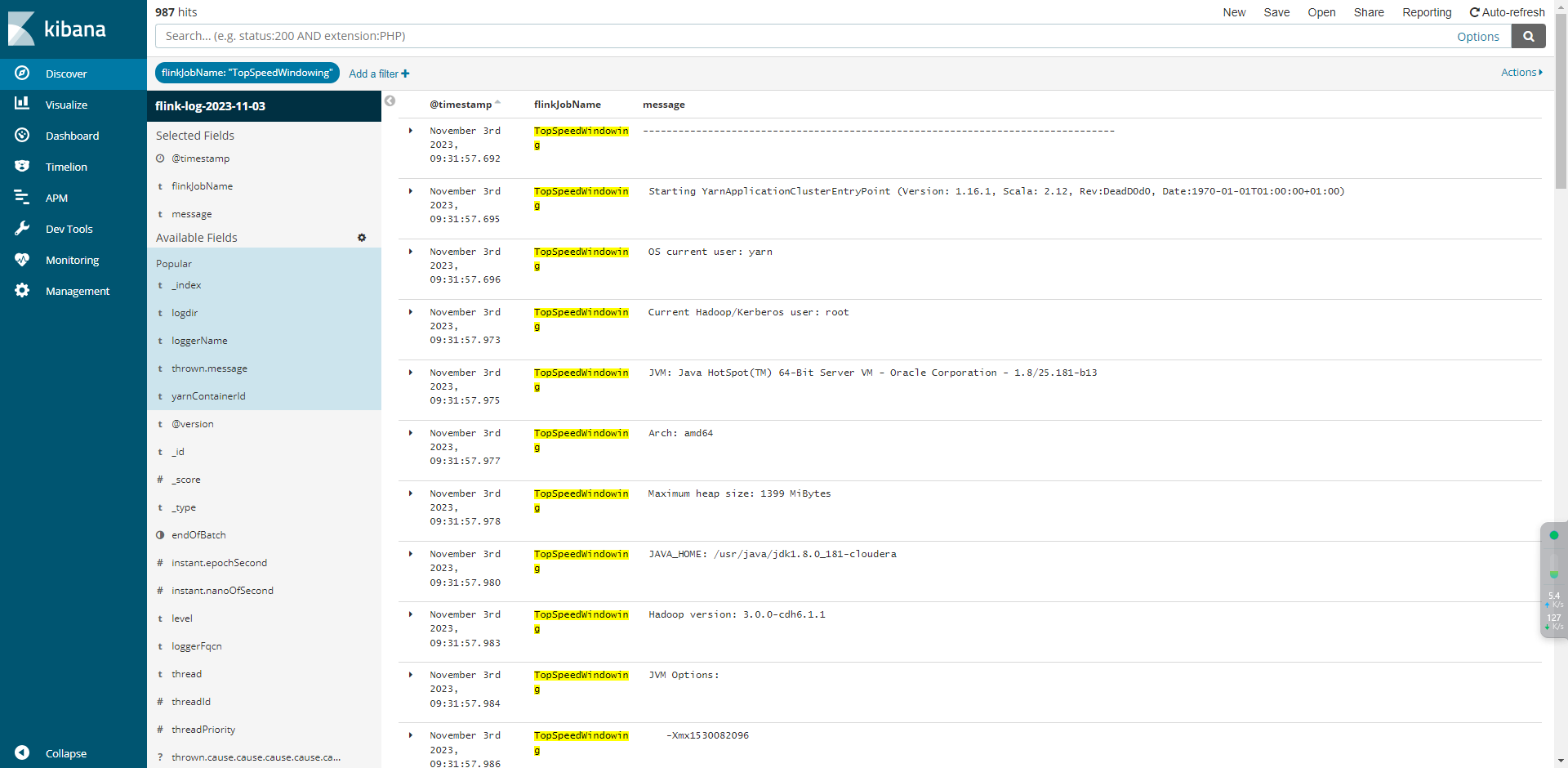
消费flink_logs案例
{instant: {epochSecond: 1698723428,nanoOfSecond: 544000000,},thread: 'flink-akka.actor.default-dispatcher-17',level: 'INFO',loggerName: 'org.apache.flink.runtime.rpc.akka.AkkaRpcService',message: 'Stopped Akka RPC service.',endOfBatch: false,loggerFqcn: 'org.apache.logging.slf4j.Log4jLogger',threadId: 68,threadPriority: 5,logdir: '/yarn/container-logs/application_1697779774806_0046/container_1697779774806_0046_01_000002/taskmanager.log',flinkJobName: 'flink-log-collect-test',yarnContainerId: 'container_1697779774806_0046_01_000002',
}
⽇志写⼊Kafka之后可以通过Logstash接⼊elasticsearch,然后通过kibana进⾏查询或搜索
三、LogStash部署
部署过程略,网上都有
需要注意Logstash内部kafka-clients和Kafka版本兼容问题,需要根据Kafka版本选择合适的Logstash版本
将以下内容写⼊config/logstash-sample.conf ⽂件中
input {kafka {bootstrap_servers => ["xxx1:9092,xxx2:9092,xxx3:9092"] group_id => "logstash-group"topics => ["flink_logs"] consumer_threads => 3 type => "flink-logs" codec => "json"auto_offset_reset => "latest"}
}output {elasticsearch {hosts => ["192.168.1.249:9200"] index => "flink-log-%{+YYYY-MM-dd}"}
}
Logstash启动:
logstash-6.5.4/bin/logstash -f logstash-6.5.4/config/logstash-sample.conf 2>&1 >logstash-6.5.4/logs/logstash.log &
四、Elasticsearch部署
部署过程略,网上都有
注意需要用root用户以外的用户启动Elasticsearch
启动脚本:
Su elasticsearchlogtestelasticsearch-6.3.1/bin/elasticsearch

Windows访问ES客户端推荐使用ElasticHD,本地运行后可以直连ES
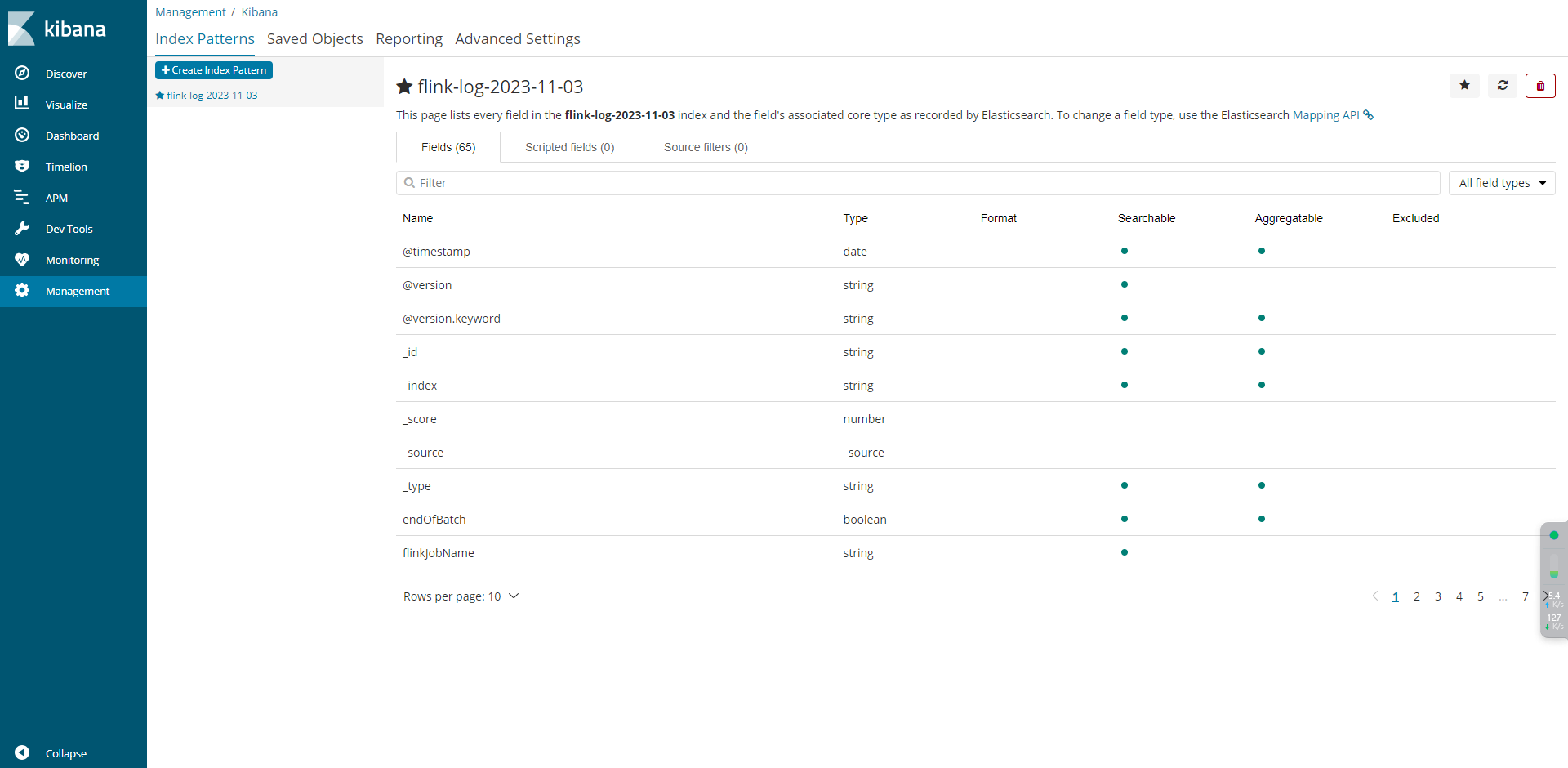
五、Kibana部署
部署过程略,网上都有
启动脚本:
kibana-6.3.1-linux-x86_64/bin/kibana
5.1 配置规则
5.2 日志分析
相关文章:
Flink日志采集-ELK可视化实现
一、各组件版本 组件版本Flink1.16.1kafka2.0.0Logstash6.5.4Elasticseach6.3.1Kibana6.3.1 针对按照⽇志⽂件⼤⼩滚动⽣成⽂件的⽅式,可能因为某个错误的问题,需要看好多个⽇志⽂件,还有Flink on Yarn模式提交Flink任务,在任务执…...

iOS NSKeyedUnarchiver归档和读取
使用NSKeyedUnarchiver归档数据到本地,很多时候保存的并不是基础数据类型,更多是自己定义的Model。有时会碰到归档或者读取的内容跟自己保存的数据类型不匹配。 现在按照思路一步一步解决: 1.先保存文件 保存的数据的类型 #import <Fou…...

算法通关村第五关|青铜|基于链表实现队列
基于链表实现队列 public class LinkQueue {// front的next指向首部结点private Node front;// rear记录尾部结点private Node rear;private int size;public LinkQueue() {this.front new Node(0);this.rear new Node(0);}// 入队public void push(int value) {Node newNod…...

【Vue】使用v-model实现控制子组件显隐
v-model 可以实现双向绑定的效果,允许父组件控制子组件的显示/隐藏,同时允许子组件自己控制自身的显示/隐藏。以下是如何使用 v-model 实现这个需求: 在父组件中,你可以使用 v-model 来双向绑定一个变量,这个变量用于…...
一篇博客读懂顺序表 —— Sequence-List
目录 一、顺序表的初始定义 1.1新建头文件和源文件 1.2 SeqList.h 中的准备工作 二、顺序表的初始化与销毁 三、首尾插入元素 四、首尾删除元素 五、中间插入元素 六、中间删除元素 七、查找指定元素下标 八、源代码 一、顺序表的初始定义 1.1新建头文件和源文件 当我…...
OceanBase:02-单机部署(生产环境)
目录 一、部署规划 二、配置要求 三、部署前配置 1.配置 limits.conf 2.配置 sysctl.conf 3.关闭防火墙 4.关闭 SELinux 5.创建数据目录,修改文件所有者信息 6.设置无密码 SSH 登录 7.安装jdk 四、解压执行安装 五、OBD命令行部署 1.修改配置文件(all-c…...

【嵌入式 C 常用算法 2 -- 变量值交换函数异或方式实现】
文章目录 变量值交换函数异或方式实现 变量值交换函数异或方式实现 在C语言中,可以使用异或运算符(^)来进行两个数的交换,而不需要使用额外的临时变量。这种交换方式的基础是异或运算的以下性质: 任何数和 0 做异或运…...
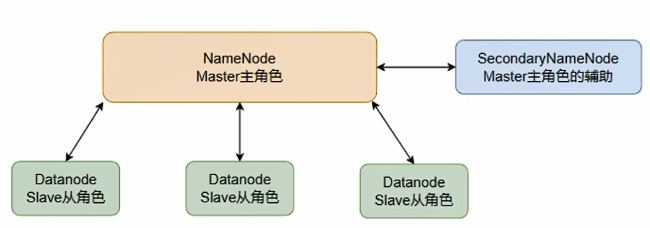
Hadoop HDFS(分布式文件系统)
一、Hadoop HDFS(分布式文件系统) 为什么要分布式存储数据 假设一个文件有100tb,我们就把文件划分为多个部分,放入到多个服务器 靠数量取胜,多台服务器组合,才能Hold住 数据量太大,单机存储能力有上限,需要…...

力扣1.两数之和
原题链接:1.两数之和 根据题意可以得出 需要找出数组nums内 有两个元素相加等于target的两个整数,并且返回这两个证书的下标。并且数组内有重复元素,但是返回的答案不能有重复元素出现 要记住的就是,需要判断元素是否出现过&…...
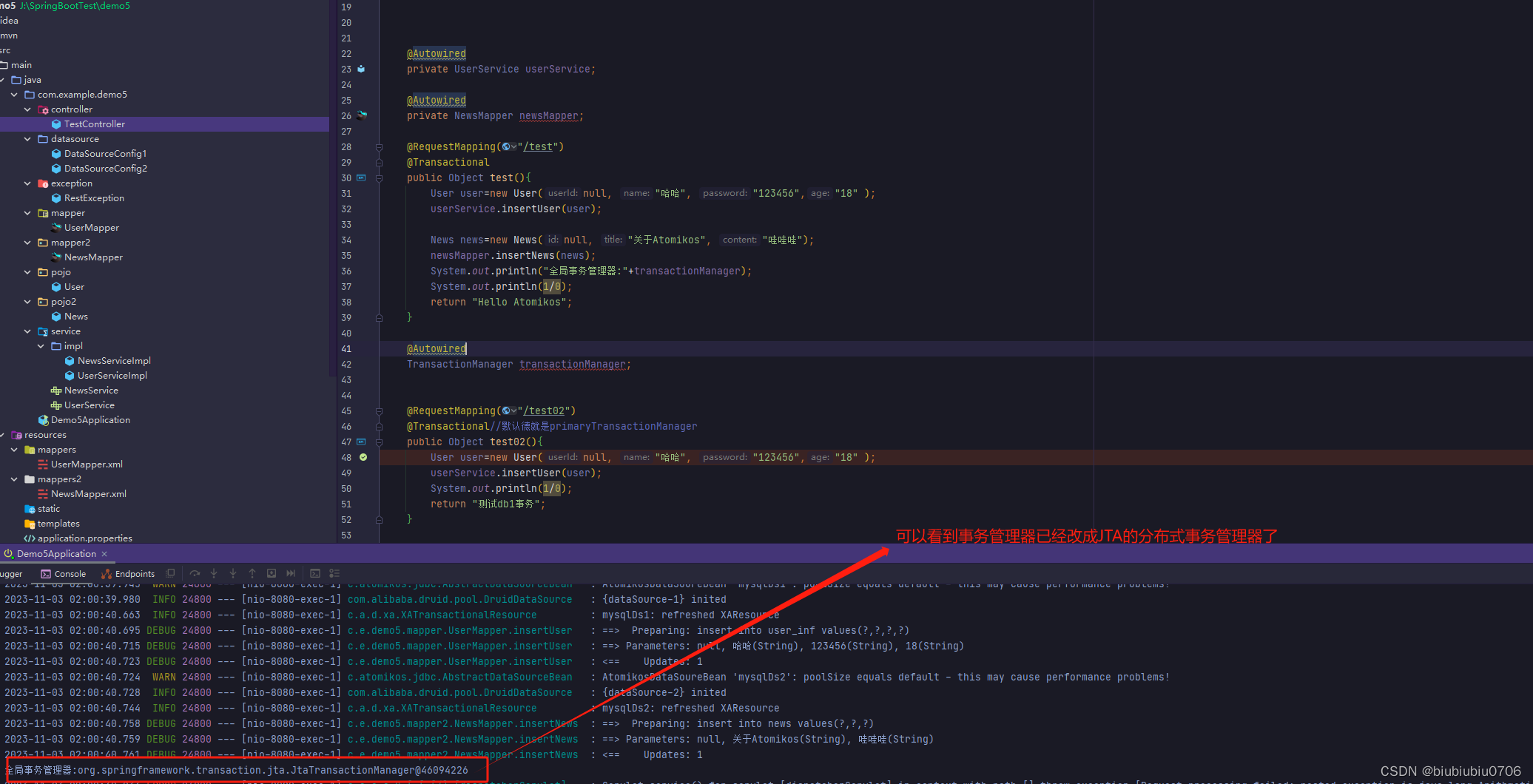
JTA分布式事务管理器
XA协议:是一种标准协议,允许事务管理器协调多个资源管理器,确保在分布式事务中的一致性和原子性。 JTA:是JavaEE规范中的一种,用于管理分布式事务的 API,提供了事务的控制和协调机制 Atomikos理解成JTA的实现 XA是JTA的基础(JT…...
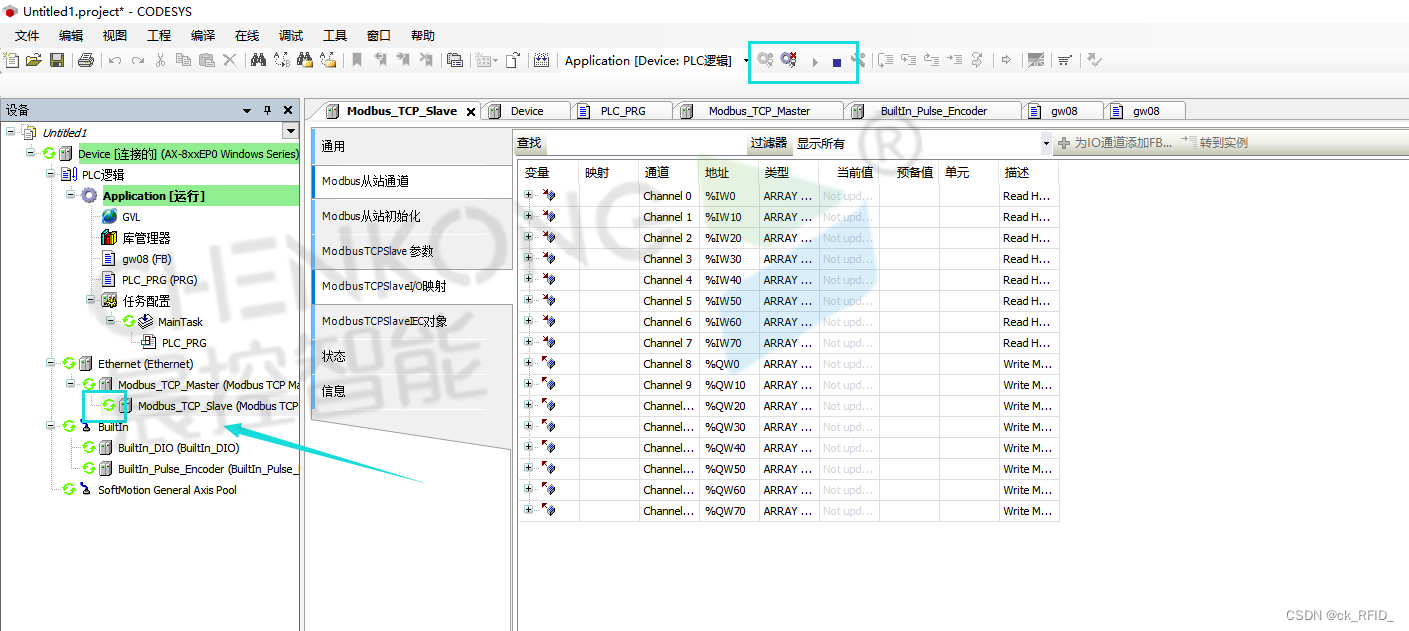
晨控CK-GW08系列网关控制器与CODESYS软件MODBUSTCP通讯手册
晨控CK-GW08系列是一款支持标准工业通讯协议ModbusTCP的网关控制器,方便用户集成到PLC等控制系统中。系统还集成了8路读写接口,用户可通过通信接口使用Modbus TCP协议对8路读写接口所连接的读卡器进行相对独立的读写操作。 晨控CK-GW08系列网关控制器适用于本公司多…...

读书笔记——labuladong算法笔记
读书笔记——labuladong算法笔记 序言计算机算法世界观计算机算法方法论二叉树遍历广度遍历BFS二叉树的前中后序遍历回溯算法动态规划算法二分搜索算法 其他算法滑动窗口双指针Union-Find算法 序言 labuladong算法笔记是一本讲解算法题求解技巧的书。本次读书笔记为2023年8月第…...

Linux中阶教程:bash shell基础
文章目录 输入输出赋值和计算条件判断函数for 循环数组及其遍历其他控制语句 输入输出 echo表示打印字符串;read表示获取用户输入;$用于引用变量。 # test1.sh bash中用#进行单行注释 echo "input your name:" read user_name echo "h…...

Golang 编译原理
简介 Golang(Go语言)是一种开源的编程语言,由Google开发并于2009年首次发布。它具备高效、可靠的特性,被广泛应用于云计算、分布式系统、网络服务等领域。Golang的编译原理是理解和掌握这门语言的重要基础之一。本文将介绍Golang…...

基于深度学习的动物识别 - 卷积神经网络 机器视觉 图像识别 计算机竞赛
文章目录 0 前言1 背景2 算法原理2.1 动物识别方法概况2.2 常用的网络模型2.2.1 B-CNN2.2.2 SSD 3 SSD动物目标检测流程4 实现效果5 部分相关代码5.1 数据预处理5.2 构建卷积神经网络5.3 tensorflow计算图可视化5.4 网络模型训练5.5 对猫狗图像进行2分类 6 最后 0 前言 &#…...

计算机视觉基础——基于yolov5-face算法的车牌检测
文章目录 车牌检测算法检测实现1.环境布置2.数据处理2.1 CCPD数据集介绍2.1.1 ccpd2019及20202.1.2 文件名字解析 2.2数据集处理2.2.1 CCPD数据处理2.2.2 CPRD数据集处理 2.3 检测算法2.3.1 数据配置car_plate.yaml2.3.2 模型配置2.3.3 train.py2.3.4 训练结果 2.4 部署2.4.1 p…...

【好书推荐】AI时代架构师修炼之道:ChatGPT让架构师插上翅膀
目录 前言 ChatGPT对架构师工作的帮助 快速理解和分析需求 提供代码建议和解决方案 辅助系统设计和优化 提高团队协作效率 如何使用ChatGPT提高架构师工作效率 了解用户需求和分析问题 编码实践和问题解决 系统设计和优化建议 团队协作和沟通效率提升 知识管理和文…...
全局代理和局部代理的区别
在计算机领域中,代理是一种常见的网络技术,它可以帮助用户更好地控制网络访问和数据传输。代理可以分为全局代理和局部代理两种,它们有着不同的作用和适用场景。 一、全局代理 全局代理指的是在系统级别设置的代理,它可以代理所…...
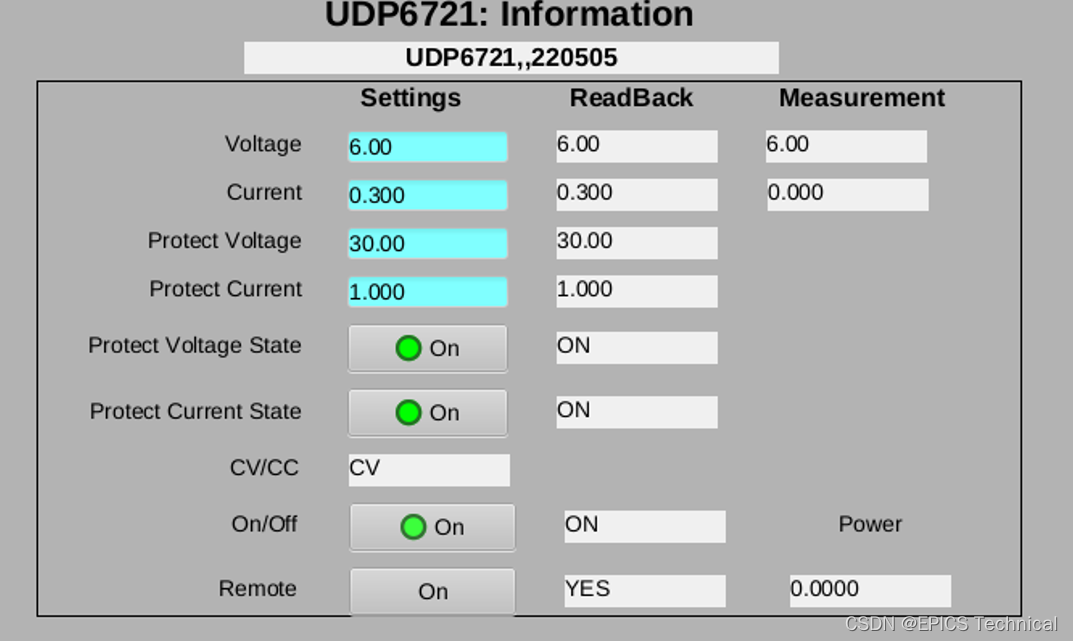
基于EPICS stream模块的直流电源的IOC控制程序实例
本实例程序实现了对优利德UDP6720系列直流电源的网络控制和访问,先在此介绍这个项目中使用的硬件: 1、UDP6721直流电源:受控设备 2、moxa串口服务器5150:将UDP6721直流电源设备串口连接转成网络连接 3、香橙派Zero3:运…...

Unity3D ECS架构适合作为主架构还是局部架构
前言 前言 Unity3D是一款广泛应用于游戏开发的跨平台游戏引擎,提供了丰富的功能和工具来简化游戏开发的过程。而Entity-Component-System(ECS)架构则是一种面向数据的设计模式,它将游戏对象(Entity)分解为…...

如何5分钟实现桌面股票实时监控:TrafficMonitor股票插件完全指南
如何5分钟实现桌面股票实时监控:TrafficMonitor股票插件完全指南 【免费下载链接】TrafficMonitorPlugins 用于TrafficMonitor的插件 项目地址: https://gitcode.com/gh_mirrors/tr/TrafficMonitorPlugins 还在为错过重要行情而烦恼吗?想在工作时…...

2026年盘点最好的5款许可优化工具
你有没有遇到过这种情况:研发部门天天喊许可证不够用,采购那边一年几百万的软件授权费还在往上涨,结果你一查,发现有人开着一个几万块的CAD软件,人已经去开了一个小时的会。钱就这么白白烧掉了。我今年专门把这行摸了一…...

别再瞎找了!2026年不容错过的专业AI论文软件
2026年AI论文写作工具已从“基础生成”升级为智能协同研究系统,核心评价维度包括文献真实性、格式合规性、长文本逻辑、查重降重、AIGC合规与多语言支持。本次测评覆盖6款主流工具,涵盖中文与英文场景、全流程与专项功能、免费与付费版本,让你…...
 (75 - 94))
Solidity 知识点速记整理 - (2026年) (75 - 94)
文章目录前言Solidity 知识点速记整理 - (2026年) (75 - 94)前言 如果您觉得有用的话,记得给博主点个赞,评论,收藏一键三连啊,写作不易啊^ _ ^。 而且听说点赞的人每天的运气都不会太差,实在白嫖的话,那…...

MulimgViewer 终极指南:高效图片对比与拼接的完整解决方案
MulimgViewer 终极指南:高效图片对比与拼接的完整解决方案 【免费下载链接】MulimgViewer MulimgViewer is a multi-image viewer that can open multiple images in one interface, which is convenient for image comparison and image stitching. 项目地址: ht…...

KMS_VL_ALL_AIO:Windows和Office永久激活终极指南
KMS_VL_ALL_AIO:Windows和Office永久激活终极指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统激活和Office软件授权问题烦恼吗?KMS_VL_ALL_AIO是一…...

不只是驱动问题!深挖华硕飞行堡垒风扇控制逻辑:ATK、热键服务与系统电源管理的三角关系
华硕飞行堡垒风扇控制逻辑深度解析:ATK、热键服务与系统电源管理的协同机制 当你的华硕飞行堡垒笔记本按下FNF5组合键却毫无反应时,多数教程会告诉你"重装驱动就能解决"。但作为技术爱好者,我们更关心的是:为什么驱动安…...

如何用嘎嘎降AI处理法学论文:法学毕业论文降AI4.8元完整操作教程
如何用嘎嘎降AI处理法学论文:法学毕业论文降AI4.8元完整操作教程 关于法学论文降AI教程,有几个细节提前知道能少走很多弯路。 核心用嘎嘎降AI(www.aigcleaner.com),4.8元,达标率99.26%。这篇把容易忽略的…...
)
别再自己造轮子了!手把手教你用LwRB环形缓冲区搞定嵌入式数据流(附DMA零拷贝实战)
嵌入式数据流处理的终极方案:LwRB环形缓冲区深度解析与DMA实战 在嵌入式开发中,数据流处理如同空气般无处不在却又容易被忽视。从UART接收到的传感器数据,到SPI传输的图像信息,再到I2C收集的设备状态,这些数据流的处理…...
)
Python连接Oracle报DPI-1047?别慌,手把手教你用Instant Client 11g/12c/19c搞定(附环境变量避坑指南)
Python连接Oracle报DPI-1047?手把手教你用Instant Client全版本配置指南 当你满怀期待地在Python中写下import cx_Oracle,准备连接公司数据库大展身手时,突然跳出的DPI-1047: Cannot locate a 64-bit Oracle Client library错误提示就像一盆冷…...