selenium爬虫——以爬取澎湃新闻某搜索结果为例
文章目录
- selenium爬虫——以爬取澎湃新闻某搜索结果为例
- 前言
- 需要导入的包
- 需要避雷的点
- webdriver的版本要与浏览器一致
- 如果使用爬虫打开了新网页,要记得跳转
- XPath和selector都可以直接复制
- 爬取多网页时记得try
- 打入word时调整字体的问题
- 完整程序
- 扩展
- 爬取效果
selenium爬虫——以爬取澎湃新闻某搜索结果为例
前言
本程序致力于实现以下目标:
(1)爬取澎湃新闻关于“反腐”的全部文章内容;
(2)按标题、链接将其整理到excel中;
(3)将标题和文章整合到一个word文档中。
许久没有正经写过了,有些生疏,代码耦合度蛮高的,所幸目标达成了。
需要导入的包
import time
import docx
import xlwt
from docx.oxml.ns import qn
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
需要避雷的点
webdriver的版本要与浏览器一致
如果用的是google chrome,可以在这里找到新版本的driver;
其他浏览器的话直接百度就能找到。
如果使用爬虫打开了新网页,要记得跳转
一开始不知道这一点,试了半天都定位不到要爬取的元素,结果最后发现一直没跳转到第二个页面上,那在第一个页面上当然定位不到了……跳转的代码如下:
new_window = driver.window_handles[1] #找第二个窗口
driver.switch_to.window(new_window) #切换到新窗口
driver.refresh() #刷新
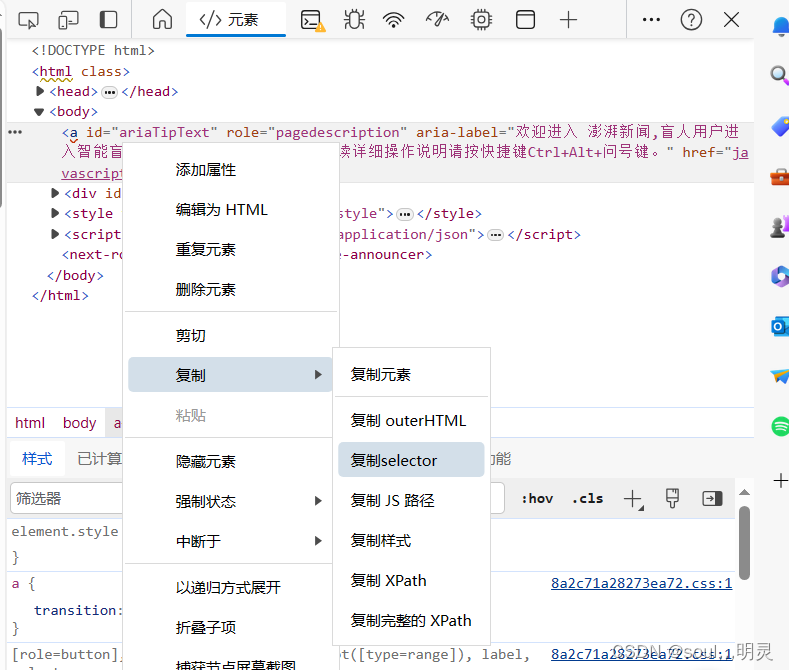
XPath和selector都可以直接复制
复制过程如下图所示,比自己写方便多了。
爬取多网页时记得try
比如这次爬取的澎湃新闻的文章,有些链接点进去是视频,是我们所不需要的,定位的位置也不一样,极有可能会报错中断。这时,就需要try-except语句来帮助我们跳过了。
try:x_path="//main/div[4]/div[1]/div[1]/div/h1"title=driver.find_element(By.XPATH, x_path)x_path = "//main/div[4]/div[1]/div[1]/div/div[2]"article=driver.find_element(By.XPATH, x_path)print(title.text)print(article.text)file.add_paragraph(article.text)
except:print("非文字")
打入word时调整字体的问题
具体程序如下:
for para in file.paragraphs:for run in para.runs:run.font.size = docx.shared.Pt(10) #设置字体大小为10run.font.name = 'Times New Roman' #英文run._element.rPr.rFonts.set(qn('w:eastAsia'), u'楷体') # 中文
值得注意的是,中文的字体前面最好加一个u,而且qn需要单独导包:
from docx.oxml.ns import qn
完整程序
import time
import docx
import xlwt
from docx.oxml.ns import qn
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
def main():driver = webdriver.Edge()driver.get("https://www.thepaper.cn/")time.sleep(1)search=driver.find_element(By.TAG_NAME,'input')search.send_keys("反腐")time.sleep(1)x_path="//main/div/div/div/div/div/div/div/span"send_button=driver.find_element(By.XPATH,x_path)ActionChains(driver).move_to_element(send_button).click(send_button).perform()time.sleep(1)x_path="//main/div[3]/div[1]/div/div[2]/div/ul/li[2]"send_button=driver.find_element(By.XPATH,x_path)ActionChains(driver).move_to_element(send_button).click(send_button).perform()time.sleep(1)last_height = driver.execute_script("return document.body.scrollHeight") # 获取当前页面的高度driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")time.sleep(2)driver.execute_script("window.scrollTo(0, document.body.scrollHeight/2);")last_height = driver.execute_script("return document.body.scrollHeight")while True: # 模拟下拉操作,直到滑动到底部driver.execute_script("window.scrollTo(0, document.body.scrollHeight);") # 模拟下拉操作time.sleep(2) # 等待页面加载new_height = driver.execute_script("return document.body.scrollHeight") # 获取当前页面的高度if new_height == last_height: # 判断是否已经到达页面底部breaklast_height = new_heightx_path="//main/div[3]/div[1]/div/div/div/ul/li/div/a"names=driver.find_elements(By.XPATH,x_path)name_text=[]name_href=[]num=-1for name in names:name_text.append(name.text)name_href.append(name.get_attribute("href"))num=num+1print(name.text)print(name.get_attribute("href"))file=docx.Document() #创建docx对象workbook = xlwt.Workbook()sheet1 = workbook.add_sheet('sheet1', cell_overwrite_ok=True)sheet1.write(0,0,'标题')sheet1.write(0,1,'链接')for i in range(num+1):print(name_text[i])print(name_href[i])address=name_href[i]driver.get(address)file.add_paragraph(name_text[i])sheet1.write(i+1,0,name_text[i])sheet1.write(i + 1, 1, name_href[i])try:x_path="//main/div[4]/div[1]/div[1]/div/h1"title=driver.find_element(By.XPATH, x_path)x_path = "//main/div[4]/div[1]/div[1]/div/div[2]"article=driver.find_element(By.XPATH, x_path)print(title.text)print(article.text)file.add_paragraph(article.text)except:print("非文字")for para in file.paragraphs:for run in para.runs:run.font.size = docx.shared.Pt(10) #设置字体大小为10run.font.name = 'Times New Roman' #英文run._element.rPr.rFonts.set(qn('w:eastAsia'), u'楷体') # 中文file.save("crawlerResult.docx")workbook.save('./crawlerResult.xls')if __name__=='__main__':main()
扩展
现将功能扩展如下:
(1)爬取分别以“反腐”,“从严治党”,“廉洁”,三个关键词搜索的文章内容并存储;
(2)只保留不重复的部分。
为实现该功能,需要一个字典,来判断该文章是否已经被搜索过:
dict={} #记录是否重复的字典
names=driver.find_elements(By.XPATH,x_path)
for name in names:if name.text not in dict:name_text.append(name.text)name_href.append(name.get_attribute("href"))num=num+1print(name.text)print(name.get_attribute("href"))dict[name.text]=1
另外发现,爬取过程中可能出现某网址已经失效的情况,在这种情况下需要跳过,否则程序也会因执行不下去而异常结束,此处使用try-except处理:
try:address=name_href[i]driver.get(address)
except:print("网址失效")
扩展之后的程序如下:
import time
import docx
import xlwt
from docx.oxml.ns import qn
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
def main():search_word=['反腐','从严治党','廉洁']search_word_len=search_word.__len__()dict={} #记录是否重复的字典num = -1 #记录标题数search_word_num=0 #搜索到第几个词name_text = []name_href = []for word in search_word:search_word_num=search_word_num+1driver = webdriver.Edge()driver.get("https://www.thepaper.cn/")time.sleep(1)search=driver.find_element(By.TAG_NAME,'input')#print(word)search.send_keys(word)time.sleep(1)x_path="//main/div/div/div/div/div/div/div/span"send_button=driver.find_element(By.XPATH,x_path)ActionChains(driver).move_to_element(send_button).click(send_button).perform()time.sleep(1)x_path="//main/div[3]/div[1]/div/div[2]/div/ul/li[2]"send_button=driver.find_element(By.XPATH,x_path)ActionChains(driver).move_to_element(send_button).click(send_button).perform()time.sleep(1)last_height = driver.execute_script("return document.body.scrollHeight") # 获取当前页面的高度driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")time.sleep(2)driver.execute_script("window.scrollTo(0, document.body.scrollHeight/2);")last_height = driver.execute_script("return document.body.scrollHeight")while True: # 模拟下拉操作,直到滑动到底部driver.execute_script("window.scrollTo(0, document.body.scrollHeight);") # 模拟下拉操作time.sleep(2) # 等待页面加载new_height = driver.execute_script("return document.body.scrollHeight") # 获取当前页面的高度if new_height == last_height: # 判断是否已经到达页面底部breaklast_height = new_heightx_path="//main/div[3]/div[1]/div/div/div/ul/li/div/a"names=driver.find_elements(By.XPATH,x_path)for name in names:if name.text not in dict:name_text.append(name.text)name_href.append(name.get_attribute("href"))num=num+1print(name.text)print(name.get_attribute("href"))dict[name.text]=1if search_word_num == search_word_len:file=docx.Document() #创建docx对象workbook = xlwt.Workbook()sheet1 = workbook.add_sheet('sheet1', cell_overwrite_ok=True)sheet1.write(0,0,'标题')sheet1.write(0,1,'链接')for i in range(num+1):print(name_text[i])print(name_href[i])try:address=name_href[i]driver.get(address)except:print("网址失效")file.add_paragraph(name_text[i])sheet1.write(i+1,0,name_text[i])sheet1.write(i + 1, 1, name_href[i])try:x_path="//main/div[4]/div[1]/div[1]/div/h1"title=driver.find_element(By.XPATH, x_path)x_path = "//main/div[4]/div[1]/div[1]/div/div[2]"article=driver.find_element(By.XPATH, x_path)print(title.text)print(article.text)file.add_paragraph(article.text)except:print("非文字")for para in file.paragraphs:for run in para.runs:run.font.size = docx.shared.Pt(10) #设置字体大小为10run.font.name = 'Times New Roman' #英文run._element.rPr.rFonts.set(qn('w:eastAsia'), u'楷体') # 中文file.save("crawlerResult.docx")workbook.save('./crawlerResult.xls')else:driver.close()print(dict.keys())
if __name__=='__main__':main()
爬取效果
word共2203页324万字

excel共1768行(1767个文章标题,第一行为表头)

相关文章:
selenium爬虫——以爬取澎湃新闻某搜索结果为例
文章目录 selenium爬虫——以爬取澎湃新闻某搜索结果为例前言需要导入的包需要避雷的点webdriver的版本要与浏览器一致如果使用爬虫打开了新网页,要记得跳转XPath和selector都可以直接复制爬取多网页时记得try打入word时调整字体的问题 完整程序扩展爬取效果 seleni…...
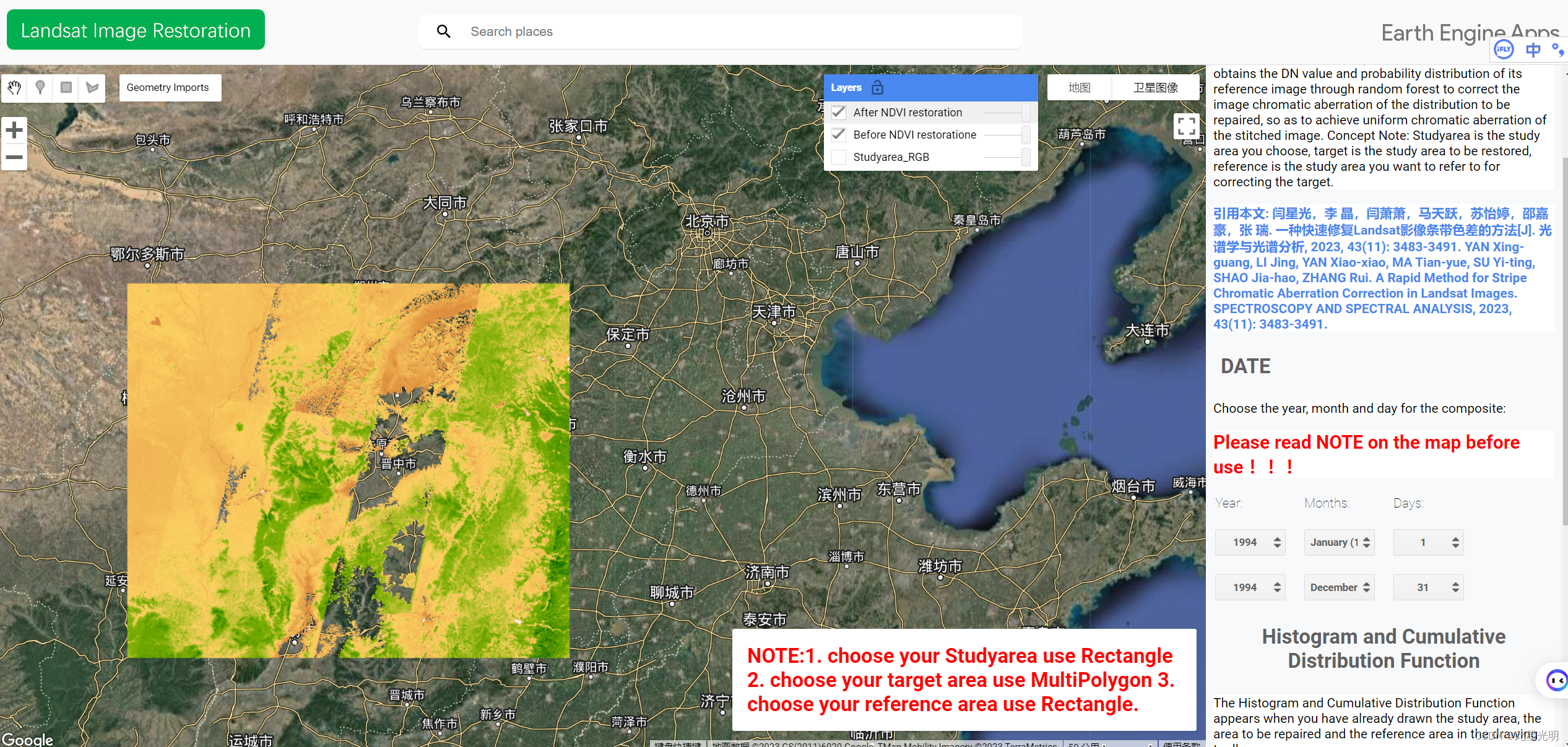
基于GEE云平台一种快速修复Landsat影像条带色差的方法
这是之前关于去除遥感影像条带的另一篇文章,因为出版商推迟了一年发布,所以让大家久等了。这篇文章的主要目的是对Landsat系列卫星因为条带拼接或者镶嵌产生的条带来进行的一种在线修复方式。 原文连接 一种快速修复Landsat影像条带色差的方法 题目&a…...

云栖大会 | 科技改变生活,移远通信实力引领智能未来
科技对生活的改变体现在出行方式、娱乐方式、支付方式等多个方面,已经融入了我们的日常生活,为我们带来了便捷、高效、舒适的体验。 10月31日—11月2日,云栖大会在杭州盛大召开。本次大会以“计算,为了无法计算的价值”为主题&…...
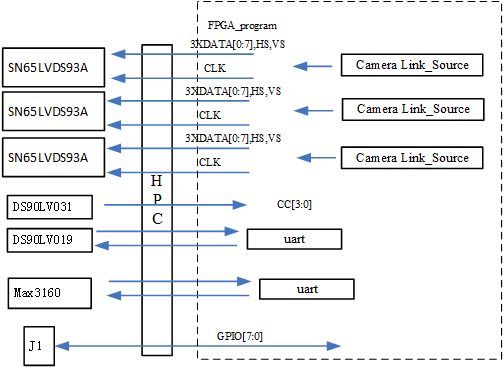
FMC子卡解决方案:FMC214-基于FMC兼容1.8V IO的Full Camera Link 输出子卡
FMC214-基于FMC兼容1.8V IO的Full Camera Link 输出子卡 一、板卡概述 基于FMC兼容1.8V IO的Full Camera Link 输出子卡支持Base、Middle、Full Camera link信号输出,兼容1.8V、2.5V、3.3V IO FPGA信号输出。适配xilinx不同型号开发板和公司内部各FMC载板。北…...
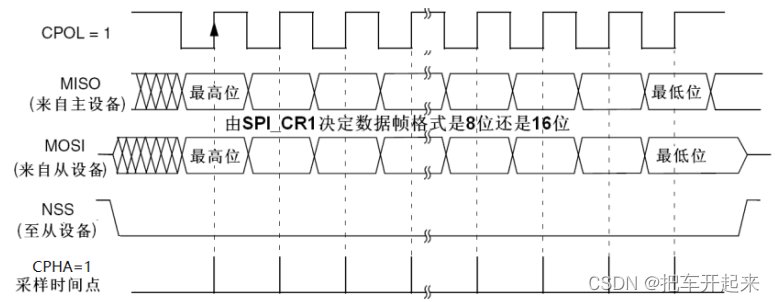
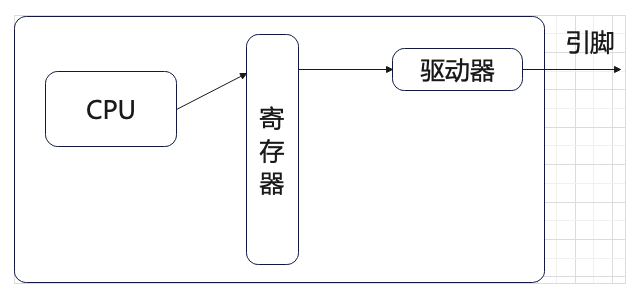
stm32 模拟spi
目录 简介 spi物理层 连接方式 框图 协议层: 数据处理 传输模式 模式0 起始和停止信号 发送和接收数据 模式1 模式2 模式3 总结 简介 spi物理层 SPI( Serial Peripheral Interface, 串行外设接口)是一种全双工同步…...
小程序https证书
小程序通常需要与服务器进行数据交换,包括用户登录信息、个人资料、支付信息等敏感数据。如果不使用HTTPS,这些数据将以明文的方式在网络上传输,容易被恶意攻击者截获和窃取。HTTPS通过数据加密来解决这个问题,确保数据在传输过程…...
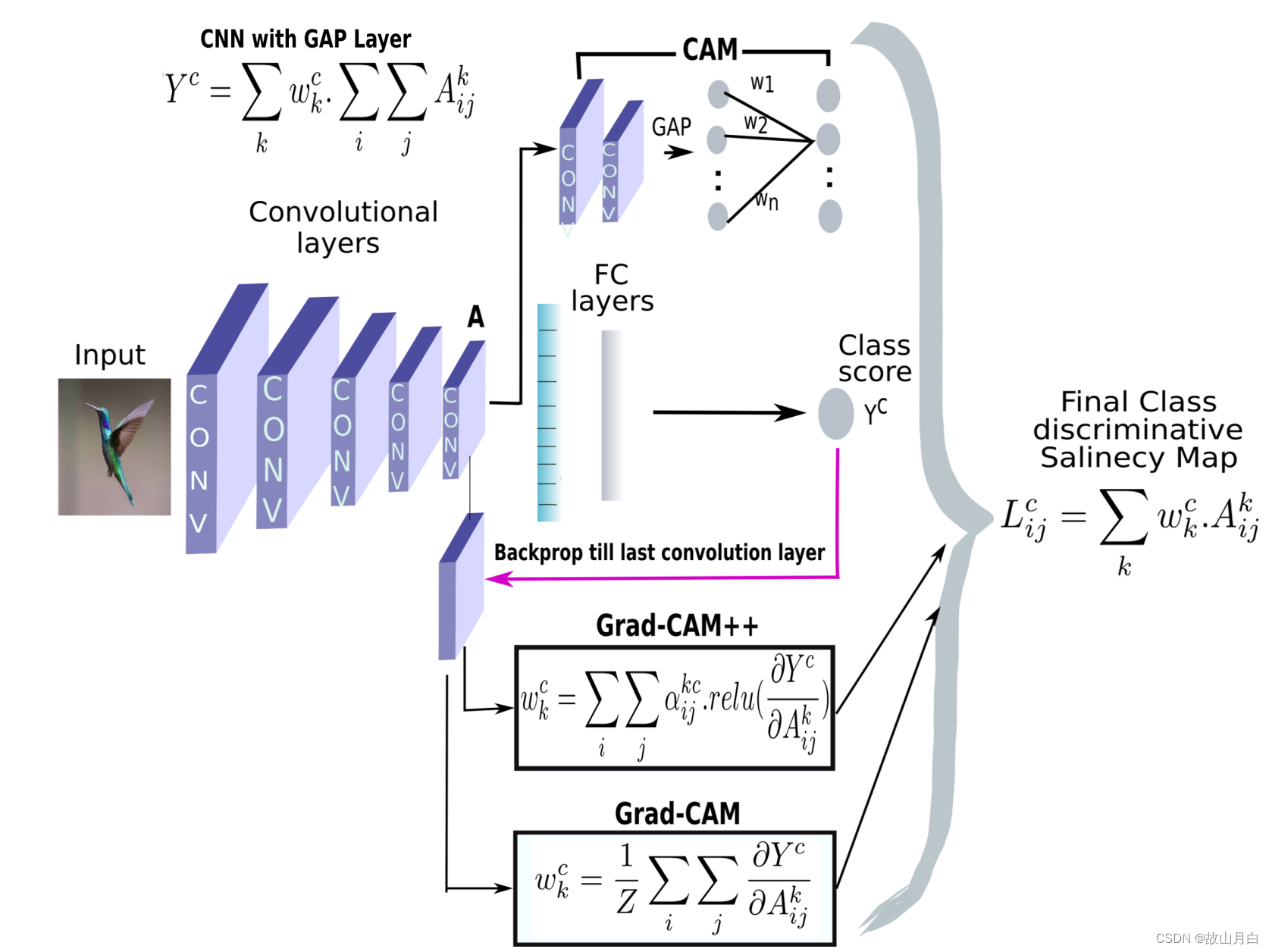
《python深度学习》笔记(二十):神经网络的解释方法之CAM、Grad-CAM、Grad-CAM++、LayerCAM
原理优点缺点GAP将多维特征映射降维为一个固定长度的特征向量①减少了模型的参数量;②保留更多的空间位置信息;③可并行计算,计算效率高;④具有一定程度的不变性①可能导致信息的损失;②忽略不同尺度的空间信息CAM利用…...

Python中文件copy模块shutil
高级的 文件、文件夹、压缩包 处理模块 shutil.copyfileobj(fsrc, fdst[, length])将文件内容拷贝到另一个文件中 import shutil shutil.copyfileobj(open(old.xml,r), open(new.xml, w)) shutil.copyfile(src, dst)拷贝文件 shutil.copyfile(f1.log, f2.log) #目标文件无需…...
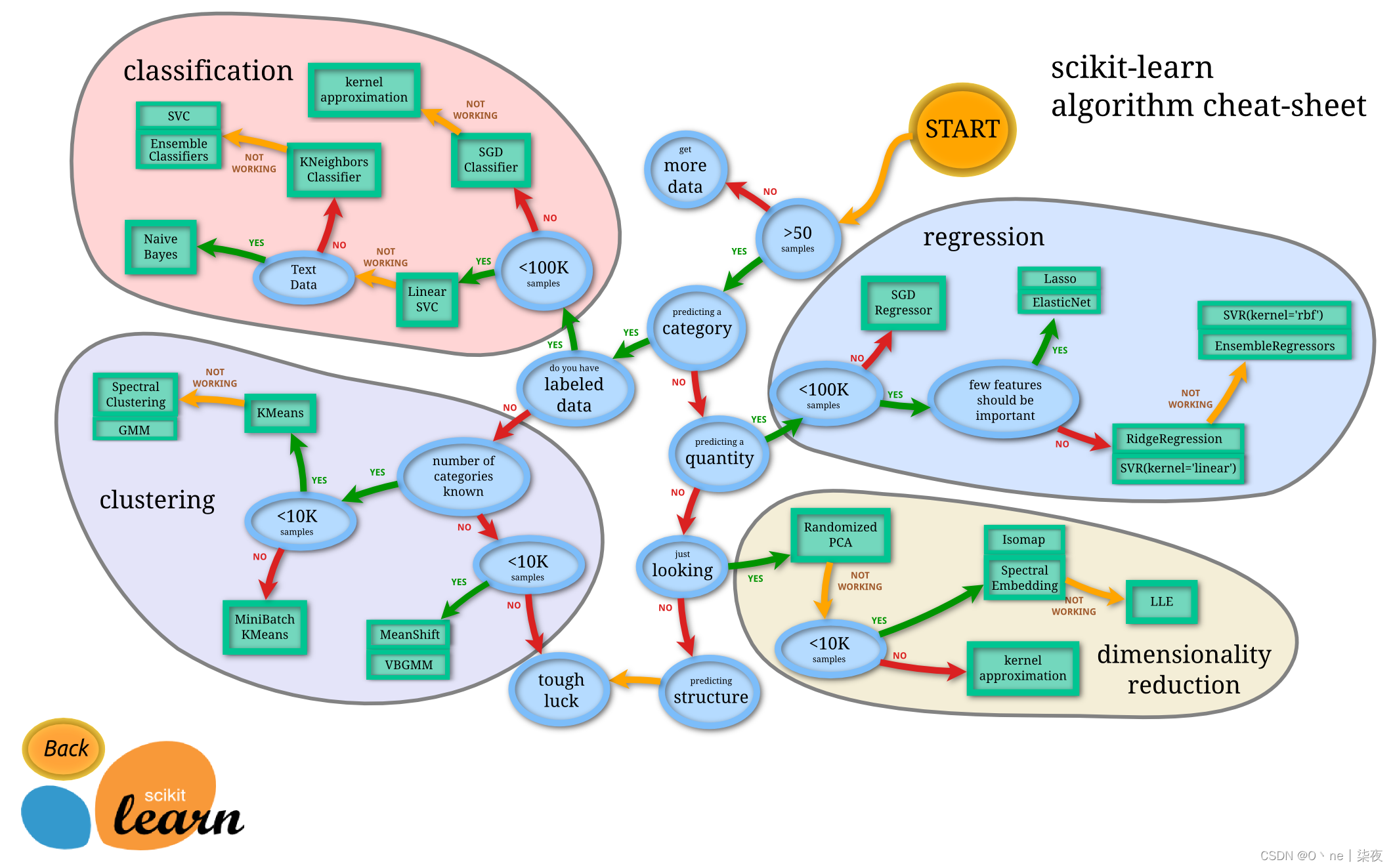
机器学习快速入门教程 Scikit-Learn实现
机器学习是什么? 机器学习是一帮计算机科学家想让计算机像人一样思考所研发出来的计算机理论。他们曾经说过,人和计算机其实本没有差别,同样都是一大批互相连接的信息传递和存储元素所组成的系统。所以有了这样的想法,加上他们得天独厚的数学功底,机器学习的前身也就孕育而生…...
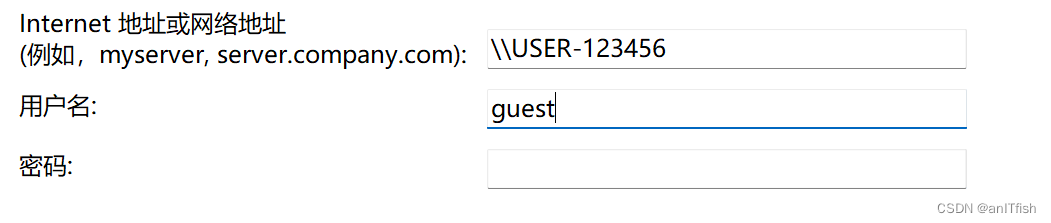
【向生活低头】win7打印机共享给win11使用,win11无法连接问题的解决
打印机是跟win7的电脑连接的,然后试了很多方法,win11都没法添加该打印机去使用。 网上的方法乱七八糟啥都有,但试了以后,发现基本没什么用。 刚刚发现知乎上的一个回答是有用的,这里做记录以备后用。 1.打开控制面板的…...

HarmonyOS鸿蒙原生应用开发设计- 元服务(原子化服务)图标
HarmonyOS设计文档中,为大家提供了独特的元服务图标,开发者可以根据需要直接引用。 开发者直接使用官方提供的元服务图标内容,既可以符合HarmonyOS原生应用的开发上架运营规范,又可以防止使用别人的元服务图标侵权意外情况等&…...

rhcsa-vim
命令行的三种模式 将ets下的passwd文件复制到普通用户下面 编辑模式的快捷方式 a--光标后插入 A--行尾插入 o--光标所在上一行插入 O--光标所在上一行插入 i--光标前插入 I--行首插入 s--删除光标所在位然后进行插入模式 S--删除光标所在行然后进行插入 命令模式的快捷…...

Rocky9 上安装 redis-dump 和redis-load 命令
一、安装依赖环境 1、依赖包 dnf -y install perl gcc gcc-c zlib-devel2、编译openssl 1.X ### 下载编译 wget https://www.openssl.org/source/openssl-1.1.1t.tar.gz tar xf openssl-1.1.1t.tar.gz cd openssl-1.1.1t ./config --prefix/usr/local/openssl make make ins…...
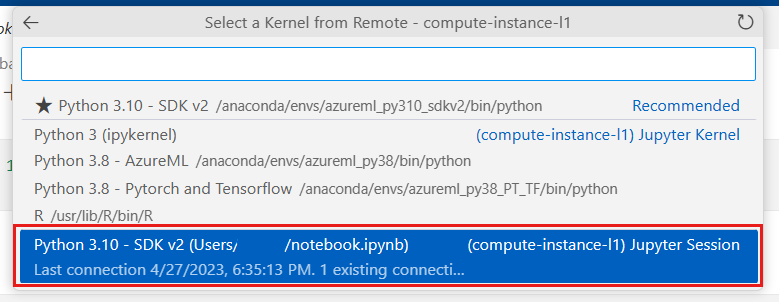
Azure机器学习 - 使用与Azure集成的Visual Studio Code实战教程
本文介绍如何启动远程连接到 Azure 机器学习计算实例的 Visual Studio Code。 借助 Azure 机器学习资源的强大功能,使用 VS Code 作为集成开发环境 (IDE)。 在VS Code中将计算实例设置为远程 Jupyter Notebook 服务器。 关注TechLead,分享AI全维度知识。…...
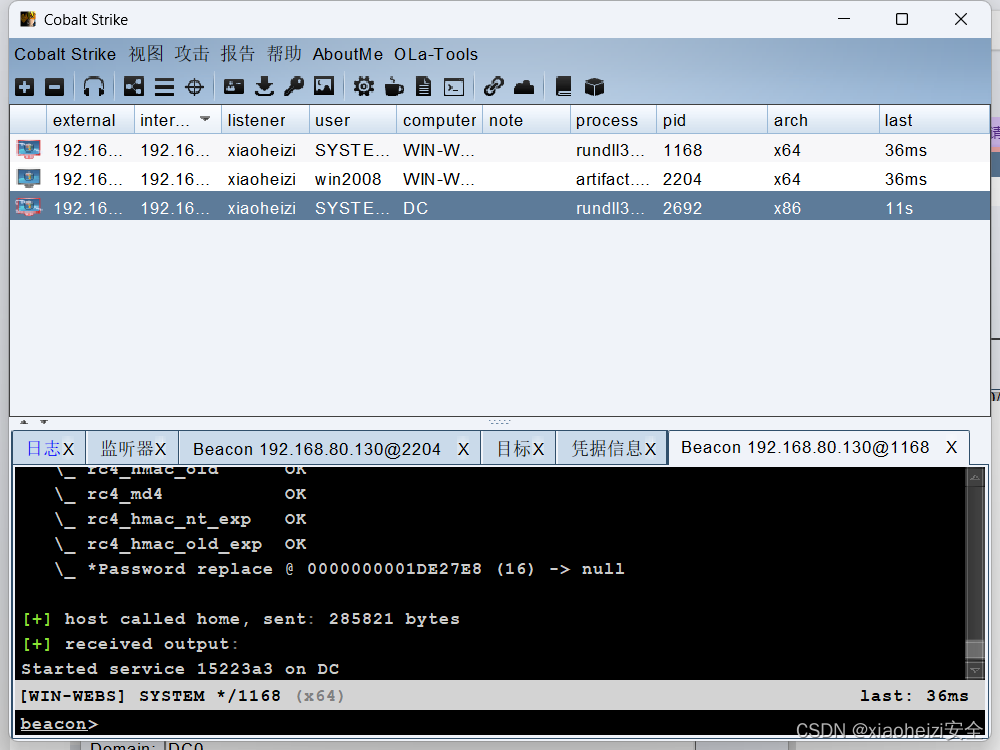
内网渗透-域信息收集
域环境 虚拟机应用:vmware17 域控主机:win2008 2r 域成员主机:win2008 2r win7 一.域用户和本地用户区别 使用本地用户安装程序时,可以直接安装 使用域用户安装程序时,需要输入域控管理员的账号密码才能安装。总结…...

三国志14信息查询小程序(历史武将信息一览)制作更新过程02-基本架构
0,前期准备 (1)一台有公网IP的云服务器,服务器上安装MySQL数据库,启用IIS服务。出入端口号配置运行(服务器和平台都要配置),IIS服务器上安装SSL证书 (2)域名…...
【51单片机】LED与独立按键(学习笔记)
一、点亮一个LED 1、LED介绍 LED:发光二极管 补:电阻读数 102 > 10 00 1k 473 > 47 000 2、Keil的使用 1、新建工程:Project > New Project Ctrl Shift N :新建文件夹 2、选型号:Atmel-AT89C52 3、xxx…...
)
package.json(2)
发布配置 和npm 项目包发布相关的配置。 private private 字段可以防止我们意外地将私有库发布到 npm 服务器。只需要将该字段设置为 true: "private": true preferGlobal preferGlobal 字段表示当用户不把该模块安装为全局模块时,如果设…...
——Docker镜像的基本命令)
Docker(2)——Docker镜像的基本命令
目录 一、简介 二、基本命令 1. Docker命令官方文档 2. 展示镜像 3. 搜索镜像 4. 下载镜像 5. 删除镜像 一、简介 本篇文章是Docker专栏的第二章,主要用于介绍Docker镜像的一些基本命令 二、基本命令 1. Docker命令官方文档 本篇博客仅记录常用的Docker镜…...

IT技术发展背景下的就业趋势:哪个领域最受欢迎?
IT技术发展背景下的就业趋势:哪个领域最受欢迎? 随着科技的不断进步和互联网的普及,IT行业正以惊人的速度蓬勃发展。在这个数字化时代,IT技术已经渗透到各个行业和领域中,为人们带来了巨大的便利和机遇。那么…...

MySql学习杂谈 --- “连接“”
第一步:忘掉所有术语,记住一个生活场景 想象你要做一件事:查全班同学的考试成绩 表A(同学名单):张三,李四,王五,赵六 表B(考试成绩)࿱…...

集团化全员学习企业在线学习平台选型指南|政企专属解决方案
在数字化人才培养浪潮下,集团化全员学习已成为央企、国企、大型上市公司的核心战略,而一款稳定、可管控、高合规的企业在线学习平台,是支撑万人级培训的核心底座。传统分散式培训存在管理混乱、标准不统一、效果不可追溯等痛点,本…...
)
从选型到设计:手把手教你根据7系列FPGA数据手册做项目选型(以Kintex-7为例)
从选型到设计:手把手教你根据7系列FPGA数据手册做项目选型(以Kintex-7为例) 在硬件系统设计中,FPGA选型往往决定着项目的成败。面对Xilinx 7系列丰富的产品线,工程师需要像外科医生选择手术器械一样精准——既要考虑当…...

湿敏电阻HR202/CM-R的两种驱动方案详解:IO充放电法 vs. 交流方波AD采样
湿敏电阻HR202/CM-R的两种驱动方案深度解析:从原理到实战选择 在环境监测和智能家居领域,湿敏电阻作为成本效益突出的湿度传感方案,其驱动电路的设计直接影响测量精度和系统稳定性。HR202和CM-R作为市面上常见的湿敏电阻型号,工程…...

谷歌外链怎么发?靠1种图文形式自动吸引外链
写外链一直是SEO里最耗体力的活。很多公司招了三个实习生,每天坐在电脑前发几百封开发信,回复率往往不到0.5%。到了2026年,谷歌的算法已经能识别出绝大多数带有“交换”性质的人为链接。现在的行情是,想要稳住排名,得让…...

如何快速解锁教学控制:JiYuTrainer极域电子教室防控制完全指南
如何快速解锁教学控制:JiYuTrainer极域电子教室防控制完全指南 【免费下载链接】JiYuTrainer 极域电子教室防控制软件, StudenMain.exe 破解 项目地址: https://gitcode.com/gh_mirrors/ji/JiYuTrainer 你是否曾在计算机课堂上,眼睁睁看着老师的演…...

机器学习核心术语全解析:从评估指标到TensorFlow实战避坑指南
1. 项目概述与核心价值刚接触机器学习,尤其是像TensorFlow这样庞大框架的朋友,最头疼的莫过于满屏的英文术语。什么“Backpropagation”、“Softmax”、“Embedding”,每个词都认识,但组合在一起就让人云里雾里。更别提那些缩写&a…...
)
用Arduino Uno和8个舵机,我让这个并联腿机器狗走起来了(附完整代码)
用Arduino Uno和8个舵机打造会走路的并联腿机器狗 第一次看到机器狗灵活地迈步时,那种成就感至今难忘。作为创客爱好者,我决定用最基础的Arduino Uno和8个舵机,从零开始搭建一个能自主行走的并联腿机器狗。这个项目不仅考验机械结构设计&…...

告别复制粘贴:如何在 Cursor / 各种 IDE 中丝滑接入本地 AI 模型?
引言:AI 编程时代的囚徒困境 2026 年,AI 编程助手已经像 Git 一样成为每个开发者的标配。Cursor 的订阅量持续暴涨,GitHub Copilot 的免费版已经吸引了上千万用户,JetBrains 全线 IDE 都深度集成了 AI Agent。但在这个表面繁荣的生态之下,每一位开发者都在不知不觉中交出…...

人工智能系统的测试:AI模型的可靠性与鲁棒性测试
在人工智能技术深度渗透各行业的当下,AI模型的可靠性与鲁棒性直接关乎业务安全与用户信任。对于软件测试从业者而言,突破传统测试思维,构建适配AI特性的测试体系,已成为保障AI系统高质量落地的核心任务。 一、AI模型可靠性与鲁棒…...