突破性技术!开源多模态模型—MiniGPT-5
多模态生成一直是OpenAI、微软、百度等科技巨头的重要研究领域,但如何实现连贯的文本和相关图像是一个棘手的难题。
为了突破技术瓶颈,加州大学圣克鲁斯分校研发了MiniGPT-5模型,并提出了全新技术概念“Generative Vokens ",成为文本特征空间和图像特征空间之间的“桥梁”,实现了普通训练数据的有效对齐,同时生成高质量的文本和图像。
为了评估MiniGPT-5的效果,研究人员在多个数据集上进行了测试,包括CC3M、VIST和MMDialog。结果显示,MiniGPT-5在多个指标上都优于多个对比基线,能够生成连贯、高质量的文本和图像。
例如,在VIST数据集上,MiniGPT-5生成的图像CLIP分数高于fine-tunedStable Diffusion 2; 在人类评估中,MiniGPT-5生成的语言连贯性更好(57.18%),图像质量更高(52.06%),多模态连贯性更强(57.62%)。

在MMDialog数据集上,MiniGPT-5的MM相关性指标达到0.67,超过基准模型Divter的0.62。这充分证明MiniGPT-5在不同数据模式下的强大适应能力。
开源地址:https://github.com/eric-ai-lab/MiniGPT-5
论文地址:https://arxiv.org/abs/2310.02239

MiniGPT-5模型主要有3大创新点:1)利用多模态编码器提取文本和图像特征,代表了一种全新的文本与图像对齐技术,效果优于直接利用大语言模型生成视觉token的方法。
2)提出了无需完整图像描述的双阶段训练策略:第一阶段,专注文本与图像的简单对齐;第二阶段,进行多模态细粒度特征学习。
3)在训练中引入了“无分类器指导”技术,可有效提升多模态生成的内容质量。主要模块架构如下。
Generative Vokens
MiniGPT-5的核心创新就是提出了“Generative Vokens”技术概念,实现了大语言模型与图像生成模型的无缝对接。
具体来说,研究人员向模型的词表中加入了8个特殊的Voken词元[IMG1]-[IMG8]。这些Voken在模型训练时作为图像的占位符使用。
在输入端,图像特征会与Voken的词向量拼接,组成序列输入。在输出端,模型会预测这些Voken的位置,对应的隐状态h_voken用于表示图像内容。

然后,h_voken通过一个特征映射模块,转换为与Stable Diffusion文本编码器输出对齐的图像条件特征ˆh_voken。
在Stable Diffusion中,ˆh_voken作为指导图像生成的条件输入。整个pipeline实现了从图像到语言模型再到图像生成的对接。
这种通过Voken实现对齐的方式,比逆向计算要直接,也比利用图像描述更为通用。简单来说,Generative Vokens就像是一座“桥梁”,使不同模型域之间信息传递更顺畅。
双阶段训练策略
考虑到文本和图像特征空间存在一定的域差异,MiniGPT-5采用了两阶段的训练策略。
第一阶段是单模态对齐阶段:只使用单个图像-文本对的数据,如CC3M。模型学习从图像标题生成对应的Voken。同时,加入辅助的图像标题损失,帮助Voken与图像内容对齐。
第二阶段是多模态学习阶段:使用包含连续多模态样本的数据,如VIST,进行微调。设置不同的训练任务,包括生成文本、生成图像和同时生成两者。增强了模型处理多模态信息的能力。
这种分阶段策略,可以缓解直接在有限数据上训练带来的问题。先进行粗粒度对齐,再微调细粒度特征,并提升了模型的表达能力和鲁棒性。
无分类器指导
为进一步提升生成文本和图像的连贯性,MiniGPT-5还采用了“无分类器指导”的技术。
其核心思想是,在图像扩散过程中,以一定概率用零特征替换条件Voken,实现无条件生成。
在推理时,将有条件和无条件的结果作为正负样本,模型可以更好地利用两者的对比关系,产生连贯的多模态输出。这种方法简单高效,不需要引入额外的分类器,通过数据对比自然指导模型学习。
文本到图像生成模型
MiniGPT-5使用了Stable Diffusion 2.1和多模态模型MiniGPT-4作为文本到图像生成模型。可以根据文本描述生成高质量、高分辨率的图片。
Stable Diffusion使用Diffusion模型和U-Net作为主要组件。Diffusion模型可以将图片表示成噪声数据,然后逐步进行去噪和重构。
U-Net则利用文本特征作为条件,指导去噪过程生成对应的图片。相比GAN,Diffusion模型更稳定,生成效果也更清晰逼真。

为了准确地将生成标记与生成模型对齐,研究人员制定了一个用于维度匹配的紧凑映射模块,并结合了一些监督损失,包括文本空间损失和潜在扩散模型损失。
文本空间损失帮助模型学习标记的正确位置,而潜在扩散损失直接将标记与适当的视觉特征对齐。由于生成Vokens的特征直接由图像引导,因此,不需要图像的全面描述就能实现无描述学习。
研究人员表示,MiniGPT-5的最大贡献在于实现了文本生成和图像生成的有效集成。只需要普通的文本、图像进行预训练,就可以进行连贯的多模态生成,而无需复杂的图像描述。这为多模态任务提供了统一的高效解决方案。
本文素材来源加州大学圣克鲁斯分校论文,如有侵权请联系删除
相关文章:
突破性技术!开源多模态模型—MiniGPT-5
多模态生成一直是OpenAI、微软、百度等科技巨头的重要研究领域,但如何实现连贯的文本和相关图像是一个棘手的难题。 为了突破技术瓶颈,加州大学圣克鲁斯分校研发了MiniGPT-5模型,并提出了全新技术概念“Generative Vokens ",…...
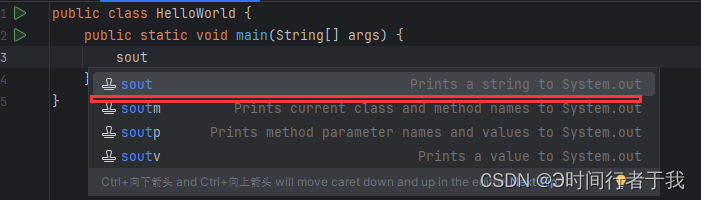
IntelliJ IDEA快捷键sout不生效
1.刚下载完idea编辑器时,可能idea里的快捷键打印不生效。这时你打开settings 2.点击settings–>Live Templates–>找到Java这个选项,点击展开 3.找到sout 4.点击全选,保存退出就可以了 5.最后大功告成!...

用C++QT实现一个modbus rtu通讯程序框架
下面是一个简单的Modbus RTU通讯程序框架的示例,使用C和QT来实现: #include <QCoreApplication> #include <QSerialPort> #include <QModbusDataUnit> #include <QModbusRtuSerialMaster>int main(int argc, char *argv[]) {QC…...

Python如何设置下载第三方软件包的国内镜像站服务器的地址
使用pip下载第三方python软件包时,如果下载的速度太慢,说明是从国外的服务器上下载的。需要进行一个设置,让pip从国内的镜像站服务器下载。 1. 新建一个纯文本文件,Windows下名字叫做pip.ini;Linux下名字叫做pip.cnf…...
ChatGLM3-6B详细安装过程记录(Linux)
先附上GitHub官方地址: https://github.com/THUDM/ChatGLM3https://github.com/THUDM/ChatGLM3 目录 一、预览 1. 基于 Gradio 的网页版 demo...

python的类
python中的类用来描述具有相同的属性和方法的对象的集合。它定义了该集合中每个对象所共有的属性和方法。对象是类的实例。 一、object是python的默认类,有很多方法,python3默认所有的类都继承object,定义类的时候类名后面加不加括号&#x…...

前端 用HTML,CSS, JS 写一个简易的音乐播放器
<!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>Music Player</title><style>/* 样式可自行修改 */.container {width: 600px;margin: 0 auto;}h2 {text-align: center;}.controls {displ…...
)
自定义QChartView实现鼠标放在图表时,显示鼠标位置坐标值(x,y)
前言:因为需要一次性从文件中加载大量数据到图表中显示,所以打算使用qchartviewqscrollarea,当横坐标数据超出默认设定的显示范围之后,重新设置chartview的宽度和scrollarea内容区域(scrollAreaWidgetContents)的宽度,…...

antv/g6 交互与事件及自定义Behavior
监听和绑定事件 在 G6 中,提供了直接的单机事件、还有监听时机的方法。可以监听画布、节点、边、以及各函数被调用的时机等: 1. 绑定事件 要绑定事件,首先需要获得图表实例(Graph 实例),然后使用 on 方法…...

MongoDB根据时间范围查询
MongoDB 查询语句示例 1. 根据时间范围查询 db.getCollection(orders).find({"enabled":true,"$or": [{"endTime": {"$gt":ISODate("2023-10-18T14:45:17.69870008:00")}}, {"endTime": null}], "startTim…...

大数据Doris(十五):Doris表的字段类型
文章目录 Doris表的字段类型 一、TINYINT数据类型 二、SMALLINT数据类型 三、INT数据类型...
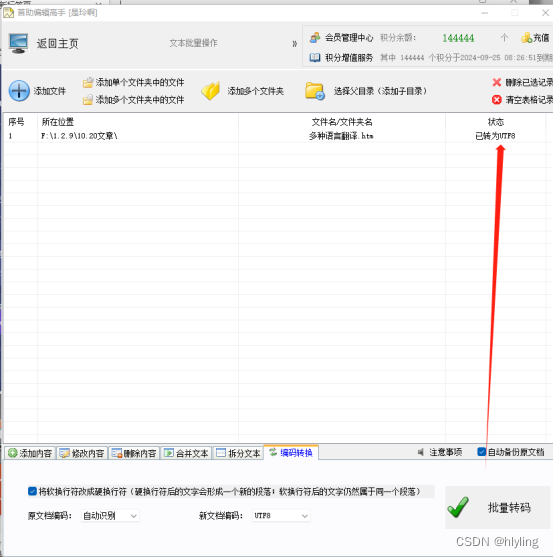
文本批量处理,一键转换HTML文件编码,释放您的繁琐工作!
亲爱的用户,您是否曾经为需要手动转换HTML文件编码而耗费大量时间和精力而感到困扰?现在,我们为您提供了一款强大的文本批量处理工具!让您一键将HTML文件编码进行转换,轻松释放您的繁琐工作! 首先…...
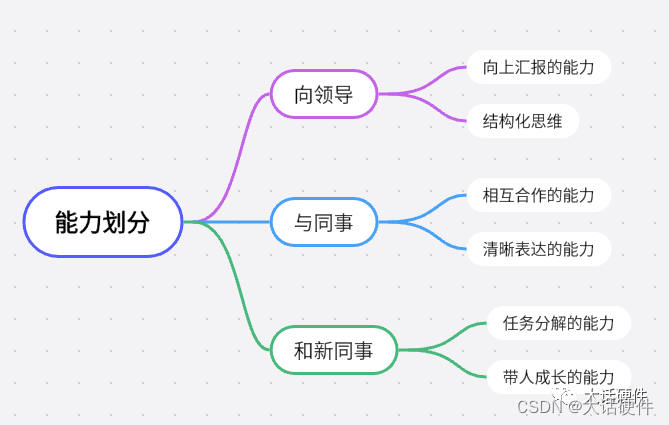
硬件工程师到底可以从哪些方面提升自己?
大家好,这里是大话硬件。 最近在大话硬件群里,聊得比较多的就是讨论怎么提升自己的能力,怎么拿到更高的工资。我想,这可能并不是只在大话硬件群才有的话题,其实在每一位工作的人心里应该都在想的两个问题。 因此,这篇文章简单分享一下,作为一名硬件工程师,可以在做哪…...

论文辅助笔记:t2vec models.py
1 EncoderDecoder 1.1 _init_ class EncoderDecoder(nn.Module):def __init__(self, vocab_size, embedding_size,hidden_size, num_layers, dropout, bidirectional):super(EncoderDecoder, self).__init__()self.vocab_size vocab_size #词汇表大小self.embedding_size e…...

R语言如何写一个爬虫代码模版
R语言爬虫是利用R语言中的网络爬虫包,如XML、RCurl、rvest等,批量自动将网页的内容抓取下来。在进行R语言爬虫之前,需要了解HTML、XML、JSON等网页语言,因为正是通过这些语言我们才能在网页中提取数据。 在爬虫过程中,…...
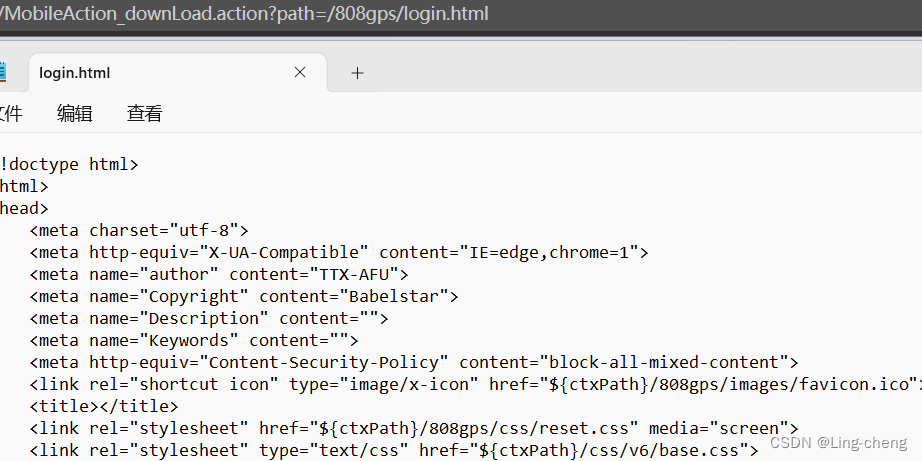
鸿运主动安全云平台任意文件下载漏洞复习
简介 深圳市强鸿电子有限公司鸿运主动安全监控云平台网页存在任意文件下载漏洞,攻击者可通过此漏洞下载网站配置文件等获得登录账号密码 漏洞复现 FOFA语法:body"./open/webApi.html" 获取网站数据库配置文件 POC:/808gps/Mobile…...
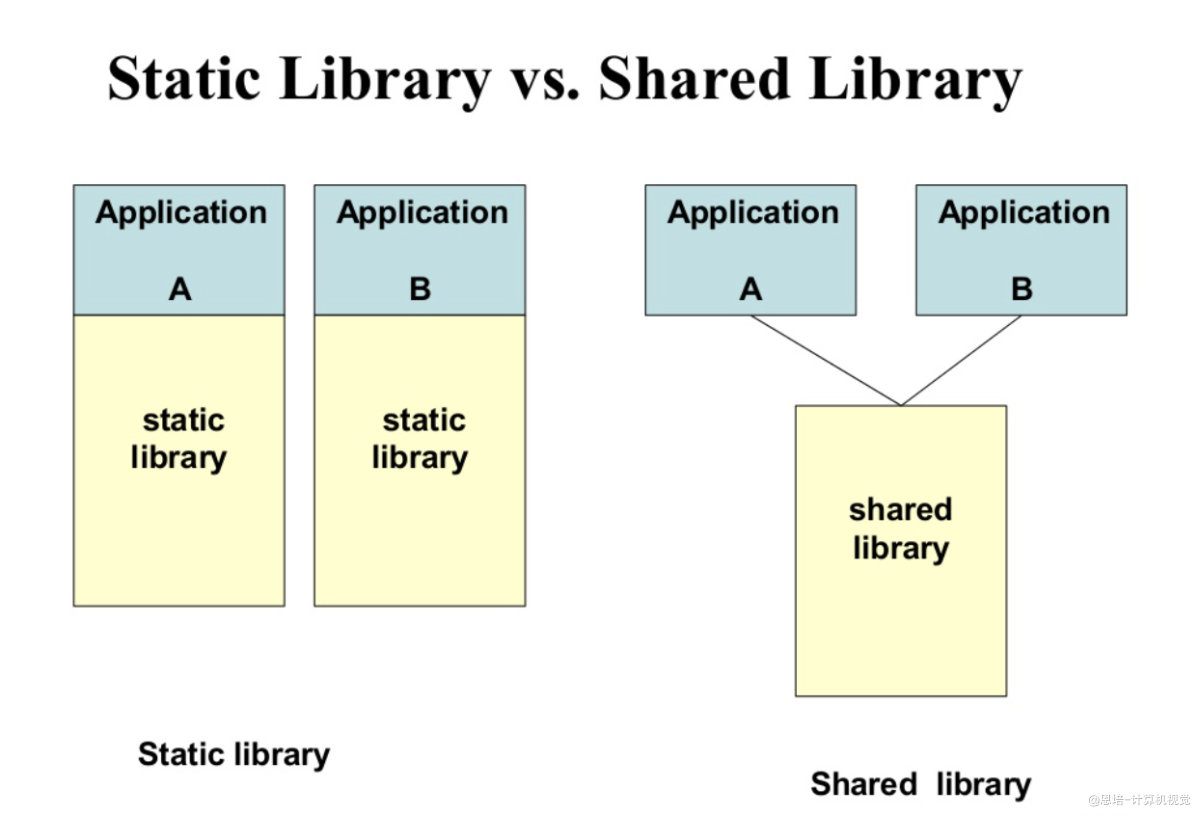
CMake基础【学习笔记(八)】
声明此博客为转载 CMake基础 文章目录 CMake基础一、准备知识1.1 C的编译过程1.2 静态链接库和动态链接库1.3 为什么需要CMake1.3.1 g 命令行编译1.3.2 CMake简介 二、CMake基础知识2.1 安装2.2 第一个CMake例子2.3 语法基础2.3.1 指定版本2.3.2 设置项目2.3.3 添加可执行文件…...

异常的学习
异常分为编译时期异常与运行时期异常 编译时期异常运行前必须处理,否则代码报错 除了RuntimeException和他的子类,其他都是编译时异常 运行时期异常运行时报错,一般是由参数传递错误导致的报错 异常的作用: 1.异常使用来查询b…...
)
【洛谷 P1101】单词方阵 题解(深度优先搜索)
单词方阵 题目描述 给一 n n n \times n nn 的字母方阵,内可能蕴含多个 yizhong 单词。单词在方阵中是沿着同一方向连续摆放的。摆放可沿着 8 8 8 个方向的任一方向,同一单词摆放时不再改变方向,单词与单词之间可以交叉,因此…...

教师减负神器
在传统的成绩管理模式中,教师需要手动输入、整理、分析成绩数据,工作量大且繁琐。这不仅耗费了教师大量的时间和精力,还容易出现错误。为了解决这个问题,我们可以通过各种代码和Excel来实现学生自助查询成绩的功能。 一、建立成绩…...

如何用3分钟完成淘宝淘金币全任务?终极自动化脚本完全指南
如何用3分钟完成淘宝淘金币全任务?终极自动化脚本完全指南 【免费下载链接】taojinbi 淘宝淘金币自动执行脚本,包含蚂蚁森林收取能量,芭芭农场全任务,解放你的双手 项目地址: https://gitcode.com/gh_mirrors/ta/taojinbi …...

别再手动画拓扑了!用SNMPc自动发现网络设备,5分钟搞定一张清晰拓扑图
5分钟极速构建网络拓扑:SNMPc自动发现功能深度实战指南 第一次接手陌生网络环境时,最让人头疼的莫过于摸不清设备之间的连接关系。传统的手动绘制拓扑图不仅效率低下,还容易遗漏关键节点。而SNMPc的自动发现功能,就像给网络管理员…...

5个关键步骤掌握B站视频下载神器DownKyi:从新手到高手
5个关键步骤掌握B站视频下载神器DownKyi:从新手到高手 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印等&#…...

AI微型赛车:从车道线检测到PID控制,手把手实现端侧自动驾驶
1. 项目概述:当AI遇见指尖上的速度与激情最近在创客圈和AI应用领域,一个结合了硬件、软件与智能算法的项目正悄然兴起,那就是“AI驱动的自动微型赛车”。这听起来像是科幻电影里的场景,但如今,借助开源硬件和成熟的机器…...
5分钟快速上手:Translumo终极免费实时屏幕翻译工具完整指南
5分钟快速上手:Translumo终极免费实时屏幕翻译工具完整指南 【免费下载链接】Translumo Advanced real-time screen translator for games, hardcoded subtitles in videos, static text and etc. 项目地址: https://gitcode.com/gh_mirrors/tr/Translumo 想…...

忆阻器混沌电路设计与储层计算应用
1. 忆阻器混沌电路的设计原理与实现1.1 忆阻器的非线性特性基础忆阻器(Memristor)作为第四种基本电路元件,其核心特性在于电阻值会随通过它的电荷量历史而变化。这种"记忆"特性来源于器件内部导电细丝的形成与断裂过程。在Pt/HfO2/…...
)
华为云Stack网络排障实战:用ovs-appctl命令追踪VXLAN隧道里的数据包(附详细命令解析)
华为云Stack网络排障实战:VXLAN隧道数据包追踪与流表解析 在云计算的复杂网络环境中,VXLAN技术已经成为构建大规模虚拟网络的核心方案。作为华为云Stack的运维工程师或网络管理员,掌握VXLAN隧道中的数据包追踪技术至关重要。本文将深入探讨如…...

百度网盘直链解析终极指南:3分钟实现高速下载的完整教程
百度网盘直链解析终极指南:3分钟实现高速下载的完整教程 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 还在为百度网盘下载速度慢而烦恼吗?每次下载大…...

主从结合,安全互联:Anybus工业通信解决方案全栈升级
HMS亮相2026 PROFINET技术路演杭州站,展出全新Anybus SoM及全栈PROFINET方案,助力设备商应对CRA与机械法规双重合规挑战。 5月14日,由PI China主办的2026 PROFINET技术路演(杭州站)在西玥酒店圆满举行。HMS华东区OEM销…...

智绘低空新图景:黎阳之光以数智技术赋能低空经济高质量发展
在长三角一体化战略纵深推进、新质生产力加速培育的时代浪潮中,低空经济正成为驱动区域经济转型升级的重要引擎。华东师范大学大虹桥低空经济研究院的成立,为行业搭建起“理论实践技术人才”的全链条创新平台;而北京黎阳之光科技有限公司&…...