NLP学习笔记:使用 Python 进行NLTK

一、说明
本文和接下来的几篇文章将介绍 Python NLTK 库。NLTK — 自然语言工具包 — NLTK 是一个强大的开源库,用于 NLP 的研究和开发。它内置了 50 多个文本语料库和词汇资源。它支持文本标记化、词性标记、词干提取、词形还原、命名实体提取、分割、分类、语义推理。
Python 有一些非常强大的 NLP 库。SpaCY — SpaCy 也是一个开源 Python 库,用于构建现实世界项目的生产级别。它内置了对 BERT 等多重训练 Transformer 的支持,以及针对超过 17 种语言的预训练 NLP 管道。它速度非常快,并提供以下功能 - 超过 49 种语言的标记化、词性标记、分段、词形还原、命名实体识别、文本分类。
TextBlob — TextBlob 是一个构建在 NLTK 之上的开源库。它提供了一个简单的界面,并支持诸如情感分析、短语提取、解析、词性标记、N-gram、拼写纠正、标记分类、名词短语提取等任务。
Gensim — GenSim 支持分层狄利克雷过程 (HDP)、随机投影、潜在狄利克雷分配 (LDA)、潜在语义分析或 word2vec 深度学习等算法。它非常快并且优化了内存使用。
PolyGlot — PolyGlot 支持多种语言,并基于 SpaCy 和 NumPy 库构建。它支持165种语言的标记化、196种语言的语言检测、命名实体识别、POS标记、情感分析、137种语言的词嵌入、形态分析、69种语言的音译。
sklearn — Python 中的标准机器学习库
自然语言工具包(NLTK)
NLTK 是一个免费的开源 Python 库,用于在 Windows、Mac OS X 和 Linux 中构建 NLP 程序。它拥有 50 个内置语料库、WordNet 等词汇资源以及许多用于 NLP 任务(如分类、分词、词干、标记、解析、语义推理)的库。
NLTK 提供了编程基础知识、计算语言学概念和优秀文档的实践指南,这使得 NLTK 非常适合语言学家、工程师、学生、教育工作者、研究人员和行业用户等使用。NLTK 有一本姊妹书——由 NLTK 的创建者编写的《Python 自然语言处理》。
二、下载并安装NLTK
# using pip:
pip install nltk
# using conda:
conda install nltk三、数据集的下载
数据集下载的地址是:NLTK Data
NLTK附带了许多语料库、玩具语法、训练模型等。安装NLTK后,我们应该使用NLTK的数据下载器安装数据:
import nltk
nltk.download()应打开一个新窗口,显示 NLTK 下载程序。您可以选择要下载的语料库。您也可以下载全部。
NLTK 包括一组不同的语料库,可以使用 nltk.corpus 包读取。每个语料库都通过 nltk.corpus 中的“语料库阅读器”对象进行访问:
# Builtin corpora in NLTK (https://www.nltk.org/howto/corpus.html)
import nltk.corpus
from nltk.corpus import brown
brown.fileids()每个语料库阅读器都提供多种从语料库读取数据的方法,具体取决于语料库的格式。例如,纯文本语料库支持将语料库读取为原始文本、单词列表、句子列表或段落列表的方法。
from nltk.corpus import inaugural
inaugural.raw('1789-Washington.txt')四、单词列表和词典
NLTK 数据包还包括许多词典和单词列表。这些的访问就像文本语料库一样。以下示例说明了词表语料库的使用:
from nltk.corpus import words
words.fileids()停用词:对文本含义添加很少或没有添加的单词。
from nltk.corpus import stopwords
stopwords.fileids()五、语料库与词典
语料库是特定语言的文本数据(书面或口头)的大量集合。语料库可能包含有关单词的附加信息,例如它们的 POS 标签或句子的解析树等。
词典是语言的词位(词汇)的整个集合。许多词典包含一个核心标记(lexeme)、其名词形式、形容词形式、相关动词、相关副词等、其同义词、反义词等。
NLTK提供了一个opinion_lexicon,其中包含英语正面和负面意见词的列表
from nltk.corpus import opinion_lexicon
opinion_lexicon.negative()[:5]六、NLTK 中的简单 NLP 任务:
# Tokenization
from nltk import word_tokenize, sent_tokenize
sent = "I will walk 500 miles and I would walk 500 more, just to be the man who walks a thousand miles to fall down at your door!"
print(word_tokenize(sent))
print(sent_tokenize(sent))#Stopwords removal
from nltk.corpus import stopwords # the corpus module is an extremely useful one.
sent = "I will pick you up at 5.00 pm. We will go for a walk"
stop_words = stopwords.words('english') # this is the full list of all stop-words stored in nltk
token = nltk.word_tokenize(sent)
cleaned_token = []
for word in token:if word not in stop_words:cleaned_token.append(word)
print("This is the unclean version:", token)
print("This is the cleaned version:", cleaned_token)# Stemming
from nltk.stem import PorterStemmer
stemmer = PorterStemmer()
print(stemmer.stem("feet"))# Lemmatization
import nltk
from nltk.stem.wordnet import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
print(lemmatizer.lemmatize("feet"))# POS tagging
from nltk import pos_tag
from nltk.corpus import stopwords stop_words = stopwords.words('english')sentence = "The pos_tag() method takes in a list of tokenized words, and tags each of them with a corresponding Parts of Speech"
tokens = nltk.word_tokenize(sentence)cleaned_token = []
for word in tokens:if word not in stop_words:cleaned_token.append(word)
tagged = pos_tag(cleaned_token)
print(tagged)七、命名实体识别:
NER 是 NLP 任务,用于定位命名实体并将其分类为预定义的类别,例如人名、组织、位置、时间表达、数量、货币价值、百分比等。它有助于回答如下问题:
- 报告中提到了哪些公司?
- 该推文是否谈到了特定的人?
- 新闻文章中提到了哪些地方、哪些公司?
- 正在谈论哪种产品?
entities = nltk.chunk.ne_chunk(tagged)
entities八、WordNet 语料库阅读器
WordNet 是 WordNet 的 NLTK 接口。WordNet 是英语词汇数据库。WordNet 使用 Synsets 来存储单词。同义词集是一组具有共同含义的同义词。使用同义词集,它有助于找到单词之间的概念关系。
使用 NLTK 朴素贝叶斯分类器构建电影评论分类器
import nltk
import string
#from nltk.tokenize import sent_tokenize, word_tokenize
from nltk.corpus import stopwords
from nltk.corpus import movie_reviewsneg_files = movie_reviews.fileids('neg')
pos_files = movie_reviews.fileids('pos')def feature_extraction(words):stopwordsandpunct = nltk.corpus.stopwords.words("english") + list(string.punctuation)return { word:'present' for word in words if not word in stopwordsandpunct}neg_words = [(feature_extraction(movie_reviews.words(fileids=[f])), 'neg') for f in neg_files]
pos_words = [(feature_extraction(movie_reviews.words(fileids=[f])), 'pos') for f in pos_files]from nltk.classify import NaiveBayesClassifier #load the buildin classifier
clf = NaiveBayesClassifier.train(pos_words[:500]+neg_words[:500])
#train it on 50% of records in positive and negative reviews
nltk.classify.util.accuracy(clf, pos_words[500:]+neg_words[500:])*100 #test it on remaining 50% recordsclf.show_most_informative_features()九、结论
本文记载了NLTK库的部分使用常识,其中重要点是:1)数据集从哪里去找。2)如何使用这个库 3)如何读取语料集。 这些对通常实验或项目开发有很重要的参考价值。
相关文章:
NLP学习笔记:使用 Python 进行NLTK
一、说明 本文和接下来的几篇文章将介绍 Python NLTK 库。NLTK — 自然语言工具包 — NLTK 是一个强大的开源库,用于 NLP 的研究和开发。它内置了 50 多个文本语料库和词汇资源。它支持文本标记化、词性标记、词干提取、词形还原、命名实体提取、分割、分类、语义推…...

突破性技术!开源多模态模型—MiniGPT-5
多模态生成一直是OpenAI、微软、百度等科技巨头的重要研究领域,但如何实现连贯的文本和相关图像是一个棘手的难题。 为了突破技术瓶颈,加州大学圣克鲁斯分校研发了MiniGPT-5模型,并提出了全新技术概念“Generative Vokens ",…...
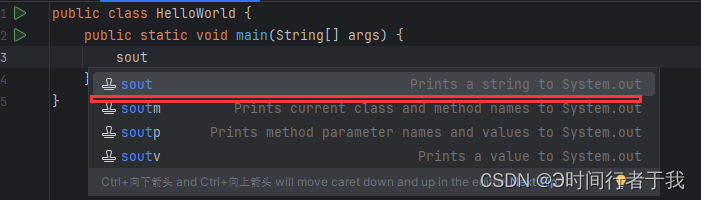
IntelliJ IDEA快捷键sout不生效
1.刚下载完idea编辑器时,可能idea里的快捷键打印不生效。这时你打开settings 2.点击settings–>Live Templates–>找到Java这个选项,点击展开 3.找到sout 4.点击全选,保存退出就可以了 5.最后大功告成!...

用C++QT实现一个modbus rtu通讯程序框架
下面是一个简单的Modbus RTU通讯程序框架的示例,使用C和QT来实现: #include <QCoreApplication> #include <QSerialPort> #include <QModbusDataUnit> #include <QModbusRtuSerialMaster>int main(int argc, char *argv[]) {QC…...

Python如何设置下载第三方软件包的国内镜像站服务器的地址
使用pip下载第三方python软件包时,如果下载的速度太慢,说明是从国外的服务器上下载的。需要进行一个设置,让pip从国内的镜像站服务器下载。 1. 新建一个纯文本文件,Windows下名字叫做pip.ini;Linux下名字叫做pip.cnf…...
ChatGLM3-6B详细安装过程记录(Linux)
先附上GitHub官方地址: https://github.com/THUDM/ChatGLM3https://github.com/THUDM/ChatGLM3 目录 一、预览 1. 基于 Gradio 的网页版 demo...

python的类
python中的类用来描述具有相同的属性和方法的对象的集合。它定义了该集合中每个对象所共有的属性和方法。对象是类的实例。 一、object是python的默认类,有很多方法,python3默认所有的类都继承object,定义类的时候类名后面加不加括号&#x…...

前端 用HTML,CSS, JS 写一个简易的音乐播放器
<!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>Music Player</title><style>/* 样式可自行修改 */.container {width: 600px;margin: 0 auto;}h2 {text-align: center;}.controls {displ…...
)
自定义QChartView实现鼠标放在图表时,显示鼠标位置坐标值(x,y)
前言:因为需要一次性从文件中加载大量数据到图表中显示,所以打算使用qchartviewqscrollarea,当横坐标数据超出默认设定的显示范围之后,重新设置chartview的宽度和scrollarea内容区域(scrollAreaWidgetContents)的宽度,…...

antv/g6 交互与事件及自定义Behavior
监听和绑定事件 在 G6 中,提供了直接的单机事件、还有监听时机的方法。可以监听画布、节点、边、以及各函数被调用的时机等: 1. 绑定事件 要绑定事件,首先需要获得图表实例(Graph 实例),然后使用 on 方法…...

MongoDB根据时间范围查询
MongoDB 查询语句示例 1. 根据时间范围查询 db.getCollection(orders).find({"enabled":true,"$or": [{"endTime": {"$gt":ISODate("2023-10-18T14:45:17.69870008:00")}}, {"endTime": null}], "startTim…...

大数据Doris(十五):Doris表的字段类型
文章目录 Doris表的字段类型 一、TINYINT数据类型 二、SMALLINT数据类型 三、INT数据类型...
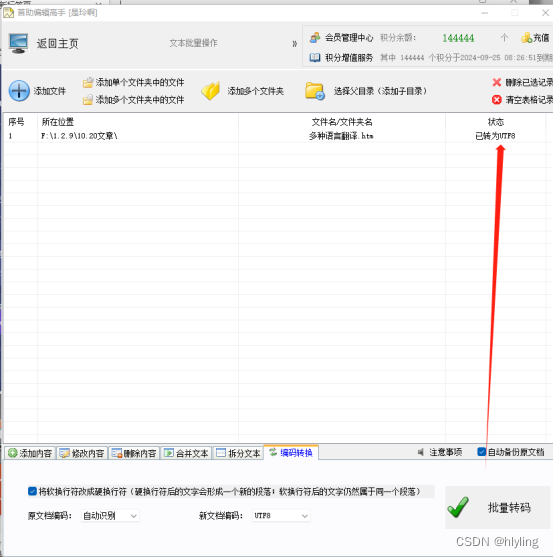
文本批量处理,一键转换HTML文件编码,释放您的繁琐工作!
亲爱的用户,您是否曾经为需要手动转换HTML文件编码而耗费大量时间和精力而感到困扰?现在,我们为您提供了一款强大的文本批量处理工具!让您一键将HTML文件编码进行转换,轻松释放您的繁琐工作! 首先…...
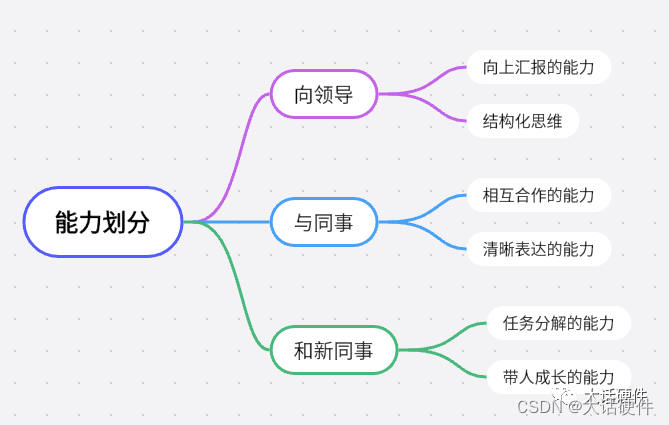
硬件工程师到底可以从哪些方面提升自己?
大家好,这里是大话硬件。 最近在大话硬件群里,聊得比较多的就是讨论怎么提升自己的能力,怎么拿到更高的工资。我想,这可能并不是只在大话硬件群才有的话题,其实在每一位工作的人心里应该都在想的两个问题。 因此,这篇文章简单分享一下,作为一名硬件工程师,可以在做哪…...

论文辅助笔记:t2vec models.py
1 EncoderDecoder 1.1 _init_ class EncoderDecoder(nn.Module):def __init__(self, vocab_size, embedding_size,hidden_size, num_layers, dropout, bidirectional):super(EncoderDecoder, self).__init__()self.vocab_size vocab_size #词汇表大小self.embedding_size e…...

R语言如何写一个爬虫代码模版
R语言爬虫是利用R语言中的网络爬虫包,如XML、RCurl、rvest等,批量自动将网页的内容抓取下来。在进行R语言爬虫之前,需要了解HTML、XML、JSON等网页语言,因为正是通过这些语言我们才能在网页中提取数据。 在爬虫过程中,…...
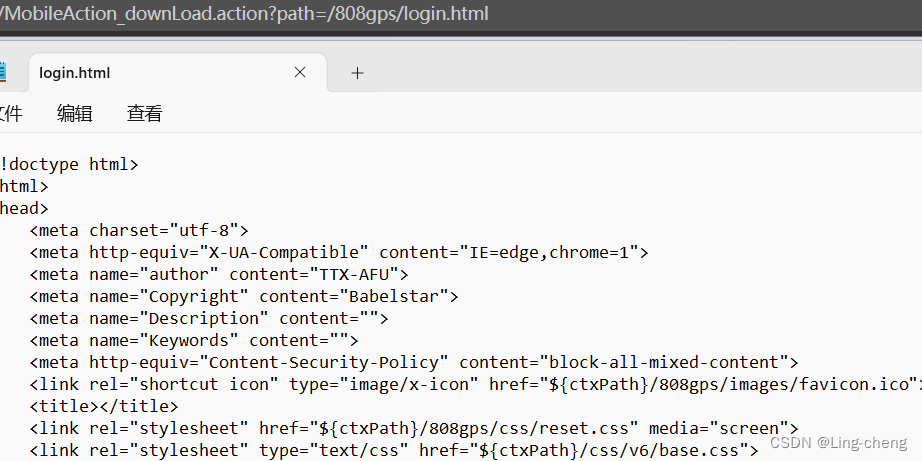
鸿运主动安全云平台任意文件下载漏洞复习
简介 深圳市强鸿电子有限公司鸿运主动安全监控云平台网页存在任意文件下载漏洞,攻击者可通过此漏洞下载网站配置文件等获得登录账号密码 漏洞复现 FOFA语法:body"./open/webApi.html" 获取网站数据库配置文件 POC:/808gps/Mobile…...
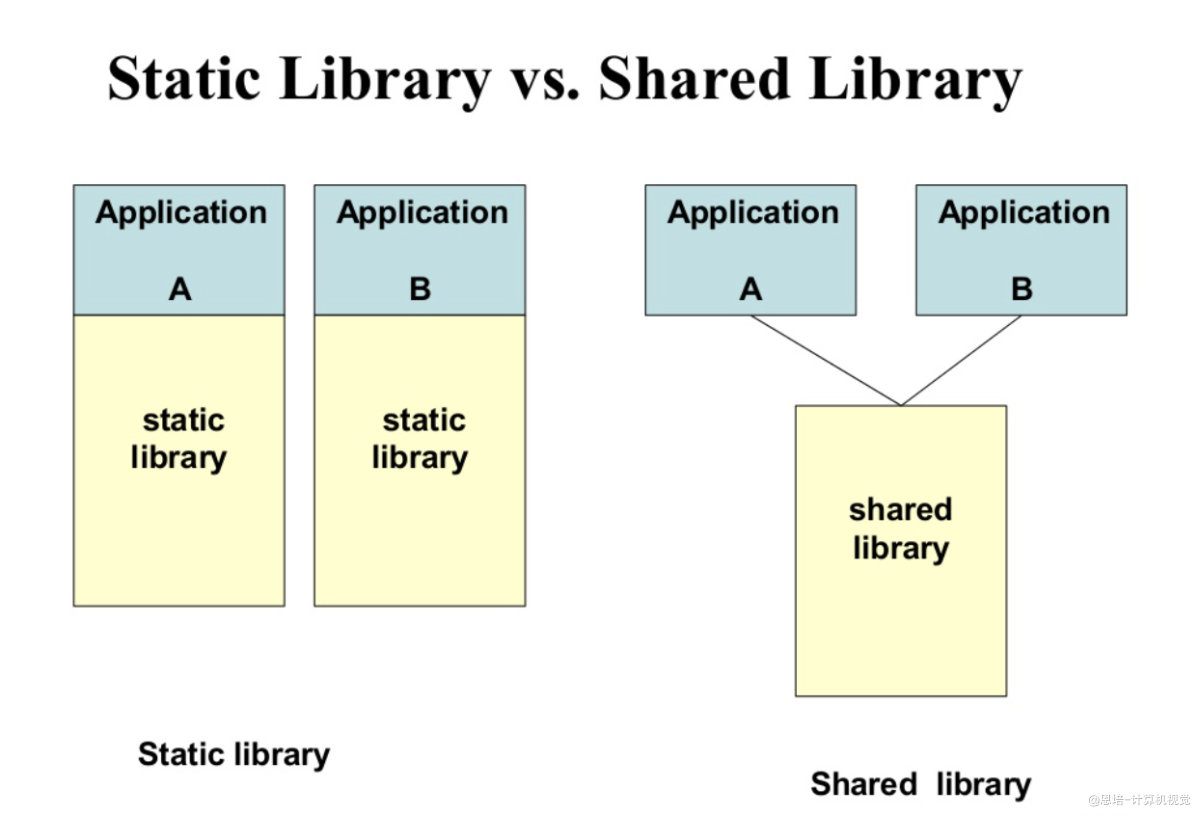
CMake基础【学习笔记(八)】
声明此博客为转载 CMake基础 文章目录 CMake基础一、准备知识1.1 C的编译过程1.2 静态链接库和动态链接库1.3 为什么需要CMake1.3.1 g 命令行编译1.3.2 CMake简介 二、CMake基础知识2.1 安装2.2 第一个CMake例子2.3 语法基础2.3.1 指定版本2.3.2 设置项目2.3.3 添加可执行文件…...

异常的学习
异常分为编译时期异常与运行时期异常 编译时期异常运行前必须处理,否则代码报错 除了RuntimeException和他的子类,其他都是编译时异常 运行时期异常运行时报错,一般是由参数传递错误导致的报错 异常的作用: 1.异常使用来查询b…...
)
【洛谷 P1101】单词方阵 题解(深度优先搜索)
单词方阵 题目描述 给一 n n n \times n nn 的字母方阵,内可能蕴含多个 yizhong 单词。单词在方阵中是沿着同一方向连续摆放的。摆放可沿着 8 8 8 个方向的任一方向,同一单词摆放时不再改变方向,单词与单词之间可以交叉,因此…...

小红书无水印下载全攻略:如何用XHS-Downloader高效保存优质内容
小红书无水印下载全攻略:如何用XHS-Downloader高效保存优质内容 【免费下载链接】XHS-Downloader 小红书(XiaoHongShu、RedNote)链接提取/作品采集工具:提取账号发布、收藏、点赞、专辑作品链接;提取搜索结果作品、用户…...

保姆级教程:在PX4 1.13.3固件中,为你的地面小车添加一个自定义机型
在PX4 1.13.3中为差速驱动地面小车构建完整自定义机型方案 当我们需要将PX4飞控生态应用于非无人机平台时,地面小车(Rover)往往是最先考虑的方向。与标准无人机机型不同,地面移动平台在动力学模型、控制参数和硬件接口等方面都存在…...

如何高效使用Alas:碧蓝航线自动化智能助手终极指南
如何高效使用Alas:碧蓝航线自动化智能助手终极指南 【免费下载链接】AzurLaneAutoScript Azur Lane bot (CN/EN/JP/TW) 碧蓝航线脚本 | 无缝委托科研,全自动大世界 项目地址: https://gitcode.com/gh_mirrors/az/AzurLaneAutoScript 厌倦了每天重…...

告别COM Server!用Python+UDP给CANoe CAPL脚本开个“外挂”
突破CAPL封闭性:Python与CANoe的轻量级UDP通信实战 在汽车电子测试领域,CANoe作为行业标准工具,其内置的CAPL脚本语言为测试工程师提供了强大的自动化能力。然而,当我们需要将外部复杂算法(如机器学习模型)…...

汽车电子TVS二极管选型与应用:从原理到30KW高功率防护实践
1. 项目概述:从一颗小小的TVS二极管说起最近和几个做汽车电子的老朋友聊天,大家不约而同地提到了同一个痛点:车上那些娇贵的ECU(电子控制单元)、传感器和CAN总线,动不动就被静电、抛负载或者雷击感应浪涌给…...

仿真流程专题——基于Workbench的随机振动工程实践与3σ准则应用
1. 随机振动分析入门:从理论到工程实践 第一次接触随机振动分析时,我和大多数工程师一样感到困惑——这种"不确定"的载荷到底该怎么分析?经过多个项目的实战,我发现用生活中的例子最容易理解:想象你在颠簸的…...

影像技术实战11:视频封面生成黑屏、模糊、重复?FFmpeg + OpenCV 构建高质量缩略图自动优选方案
影像技术实战11:视频封面生成黑屏、模糊、重复?FFmpeg OpenCV 构建高质量缩略图自动优选方案 一、问题场景:封面不是“随便截一帧” 在视频平台、素材管理系统、内容审核后台、AI 剪辑工具里,视频上传后自动生成封面是一个很常见…...

2026届毕业生推荐的AI写作助手实际效果
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 在人工智能开展内容创作那一块儿,标题可是吸引目标受众的头一个环节哟。对于“降…...

快速上手3DGS数字孪生开发:一份必做的技术动作盘点清单
一、行业核心技术科普:3DGS数字孪生开发的关键技术节点从零开始构建一个基于3D高斯泼溅(3DGS)的数字孪生应用,涉及多个关键技术节点。每个节点的执行质量,都直接影响最终应用的性能与用户体验。其域创新推出的LCC格式&…...
)
go 链表 (标准库实现)
Go 链表简介Go 标准库里没有单链表,只在 container/list 包里提供了双向循环链表。两个核心类型list.List :链表本身,包含哨兵节点和长度 list.Element :链表节点,存数据 前后指针 type Element struct {Value interf…...