TimeGPT-1——第一个时间序列数据领域的大模型他来了
一直有一个问题:时间序列的基础模型能像自然语言处理那样存在吗?一个预先训练了大量时间序列数据的大型模型,是否有可能在未见过的数据上产生准确的预测?最近刚刚发表的一篇论文,Azul Garza和Max Mergenthaler-Canseco提出的TimeGPT-1,将llm背后的技术和架构应用于预测领域,成功构建了第一个能够进行零样本推理的时间序列基础模型。探索TimeGPT背后的体系结构以及如何训练模型。
《TimeGPT-1》论文地址在这里,如下所示:

本文介绍了时间序列的第一个基础模型TimeGPT,能够为不同的数据集生成准确的预测训练我们根据已建立的统计、机器学习和深度学习方法评估我们的预训练模型,证明TimeGPT零样本推理在性能、效率和简单性方面都很出色。我们的研究提供令人信服的证据表明,来自人工智能其他领域的见解可以有效地应用于时间序列分析。我们得出结论,大规模时间序列模型提供了一个令人兴奋的机会,可以民主化访问精确预测并通过利用当代的能力来减少不确定性深度学习的进步。
1、简介
不确定性是生活的一个内在方面,是人类不懈寻求驾驭和理解的一个不变因素。从古代文明确立的传统到当代世界复杂的研究工作,聪明的头脑不断努力预测未来可能发生的事件的分布,精心设计系统的方法来揭示未来。
预测潜在结果的愿望是多种学科的基础,反映了人类预测、制定战略和减轻风险的深层次倾向。减少下一步会发生什么的不确定性的目标映射到许多现实世界的应用:从了解经济周期和趋势到识别消费者消费模式;从优化能源生产和电网管理的电力需求,到调整服务器、工人和机器的容量和基础设施。
时间序列——按时间顺序排列的数据——构成了系统、企业和机构的底层结构。它的影响范围从测量海潮到追踪道琼斯指数的每日收盘价。这种类型的数据表示在金融、医疗保健、气象、社会科学等领域是必不可少的,在这些领域,识别时间模式、趋势和周期变化对于预测未来价值和为决策过程提供信息至关重要。然而,目前对时间序列的理论和实践理解尚未在从业者中达成共识,这反映了在人类条件的其他基本领域,如语言和感知,对生成模型的广泛赞誉。我们的领域在评估深度学习对预测任务的有效性方面仍然存在分歧。预测科学的努力未能实现真正普遍的预训练模型的承诺。
在本文中,我们走上了一条新的道路,并介绍了TimeGPT,这是第一个用于时间序列预测的预训练基础模型,它可以在不需要额外训练的情况下在不同的领域和应用程序中产生准确的预测。一个通用的预训练模型构成了一项突破性的创新,为预测实践开辟了一条新的范式之路,这种范式更容易获得、更准确、耗时更少,并大大降低了计算复杂性。
2、背景
关于深度学习方法的优越性,预测界目前存在分歧。尚未制定统一的办法。最近,这些不同的范式越来越相互挑战,质疑新发展的有用性、准确性和复杂性。尽管深度学习架构在其他领域取得了成功,但一些时间序列从业者已经证明,该领域的一些拟议创新并没有达到他们的要求或期望。1.
从历史上看,ARIMA、ETS、MSTL、Theta和CES等统计方法已可靠地应用于各个领域。在过去的十年里,XGBoost和LightGBM等机器学习模型越来越受欢迎,在公开竞争和实际应用中都取得了可喜的成果。
然而,随着深度学习的出现,时间序列分析的范式发生了转变。深度学习方法在学术界和大规模工业预测应用中越来越受欢迎[Benidis等人,2022]。
鉴于其全局方法,深度学习方法在可扩展性、灵活性和潜在准确性方面比统计局部方法具有显著优势。此外,它们学习复杂数据依赖关系的能力有效地绕过了对其他全局方法(如LightGBM或XGBoost)所需的复杂功能工程的需求。因此,基于深度学习的时间序列模型旨在简化预测管道并增强可扩展性。在数据量不断增长的时代,它们能够处理大量数据并捕获长期依赖关系,这使它们有利于执行复杂的预测任务。
然而,学术研究人员和从业者对这些承诺的看法存在分歧。各种研究人员和从业者对提高准确性的基本假设提出了质疑,提出的证据表明,更简单的模型优于更复杂的方法;具有更低的成本和复杂性。相反,一些行业领导者报告称,深度学习方法增强了他们的结果,简化了他们的分析管道[Kunz等人,2023]。在当前的历史背景下,深度学习模型在自然语言处理(NLP)和计算机视觉(CV)方面的卓越能力是不可否认的,值得注意的是,时间序列分析领域仍然对神经预测方法的性能持怀疑态度。
我们认为这种怀疑源于:
•评估设置不一致或定义不清:与其他受益于引入理想测试数据集(如计算机视觉的ImageNet)的领域不同,时间序列的公开可用数据集不具备必要的规模和容量
深度学习的方法来超越。
•次优模型:考虑到有限和特定的数据集,即使是构思良好的深度学习架构也可能难以泛化,或者需要付出相当大的努力才能找到最佳设置和参数。
此外,缺乏满足深度学习方法要求的标准化大规模数据集也可能阻碍这一领域的进展。虽然其他领域受益于基准数据集和明确的评估指标,但时间序列社区仍需要开发此类资源,以促进创新和验证新技术。2
在本文中,我们证明了更大、更多样的数据集使更复杂的模型能够在各种任务中更好地执行。TimeGPT是第一个以最小的复杂性始终优于替代方案的基础模型。进一步研究时间序列基础模型的改进可能会开创该领域的新篇章,促进对时间数据的更深入理解,并提高预测的准确性和效率。
3、文献综述
深度学习预测模型已成为一个突出的研究领域,这得益于它们在最近的著名竞赛中的成功,包括[Markridakis et al.,202022],以及它们对行业中大规模任务的适用性。[Benidis等人,2022]对神经预测模型及其应用进行了全面的综述和分类。
最初的深度学习时间序列预测成功源于对既定架构的适应,即递归神经网络(RNN)和卷积神经网络(CNN),最初分别为自然语言处理(NLP)和计算机视觉(CV)设计。RNN是流行模型的支柱,如概率预测的DeepAR[Salinas et al.,2020]和M4竞赛的获胜者ESRNN[Smyl,2020]。如[Bai et al.,2018]所示,在序列数据的多个任务中,细胞神经网络表现出优于RNN的性能。正如DPMN[Olivares等人,2023b]和TimesNet[Wu等人,2022]等模型所使用的那样,它们现在构成了一个流行的构建块。前馈网络由于其低计算成本和效率,也经常被使用,值得注意的例子包括N-BEATS[Orishkin等人,2019,Olivares等人,2022]和NHITS[Challu等人,2023]。
近年来,基于变压器的模型[Vaswani et al.,2017]越来越受欢迎,因为它们在大规模环境[Kunz et al.,2023]和复杂任务(如长序列预测)中表现出了显著的性能。早期的例子包括TFT[Lim等人,2021]和MQTransformer[Esenach等人,2020],两者都具有多分位数功能。Informer通过Prob稀疏自注意机制引入了用于长序列预测的Transformers[Zhou et al.,2021]。此后,这一概念通过Autoformer[Wu et al.,2021]、FEDformer[Zhou et al.,2022]和PatchTST[Nie et al.,022]等模型中各种形式的归纳偏见和注意力机制得到了进一步完善。
基础模型的潜力,即在大型数据集上预先训练并随后针对特定任务进行微调的大型模型,在时间序列预测任务中仍然相对不足。然而,预测基础模型的可能性有一些早期指标。例如,[Orishkin等人,2021]表明,预先训练的模型可以在任务之间转移,而不会降低性能。此外,[Kunz等人,2023]提供了证据,证明在时间序列预测任务中,Transformer架构的数据和模型大小存在缩放定律。
4、时间序列的基础模型
基础模型依赖于其跨域泛化的能力,特别是在训练期间不可用的新数据集中。因此,我们将迁移学习理解为将从一项任务中收集的知识应用于解决新任务的能力。接下来,我们在先前时间序列预测研究的基础上解释迁移学习的概念[Orishkin等人,2021,Olivares等人,2023a]。
是预测范围,y是目标时间序列,x是外生协变量。预测任务的目标是估计以下条件分布:

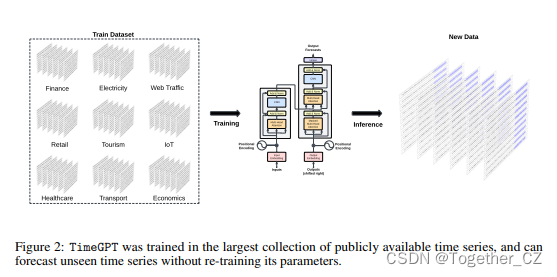
所提出的基础模型的核心思想是通过在迄今为止最大的公开可用时间序列数据集上训练它,利用数据集和模型大小的缩放定律,来利用这些原理。就广度和深度而言,一个多样化的数据集使TimeGPT能够从多个领域前所未有的时间模式阵列中收集见解。
5、timeGPT
5.1架构
TimeGPT是一个基于Transformer的时间序列模型,具有基于[Vaswani et al.,2017]的自注意机制。TimeGPT使用历史值窗口来生成预测,并添加本地位置编码来丰富输入。该体系结构由具有多个层的编码器-解码器结构组成,每个层具有残差连接和层规范化。最后,线性层将解码器的输出映射到预测窗口维度。一般的直觉是,基于注意力的机制能够捕捉过去事件的多样性,并正确推断未来潜在的分布。
时间序列的广义全局模型的开发带来了许多挑战,主要是由于处理从一组广泛的底层过程中得出的信号的复杂任务。频率、稀疏性、趋势性、季节性、平稳性和异方差性等特征为局部和全局模型带来了明显的复杂性。因此,任何基础预测模型都必须具备管理这种异质性的能力。我们的模型TimeGPT被设计为处理不同频率和特征的时间序列,同时适应不同的输入大小和预测范围。这种适应性在很大程度上归因于TimeGPT所基于的底层基于转换器的架构。
需要注意的是,TimeGPT不是基于现有的大型语言模型(LLM)。虽然TimeGPT遵循在庞大的数据集上训练大型变换器模型的相同原理,但其架构专门处理时间序列数据,并经过训练以将预测误差降至最低
5.2训练数据集
据我们所知,TimeGPT是根据最大的公开时间序列集合进行训练的,总共包含1000多亿个数据点。该培训集包含了来自广泛领域的时间序列,包括金融、经济、人口统计、医疗保健、天气、物联网传感器数据、能源、网络流量、销售、运输和银行。由于这组不同的域,训练数据集包含具有广泛特征的时间序列。
就时间模式而言,训练数据集包含具有多个季节性、不同长度的周期和各种类型趋势的序列。除了时间模式之外,数据集在噪声和异常值方面也有所不同,从而提供了一个稳健的训练环境。一些系列包含干净、规则的模式,而另一些系列则以显著的噪声或意外事件为特征,为模型提供了广泛的场景可供学习。大部分时间序列都是以原始形式包含的;处理仅限于格式标准化和填写缺失值以确保数据的完整性。
选择这样一个多样化的训练集对于开发一个稳健的基础模型至关重要。这种多样性涵盖了非平稳真实世界数据的复杂现实,其中的趋势和模式可能会因多种因素而随时间变化。在这个丰富的数据集上训练TimeGPT使其能够处理各种场景,增强了其稳健性和泛化能力。这有效地使TimeGPT能够准确预测看不见的时间序列,同时消除了对单个模型训练和优化的需求。
5.3训练timeGPT
TimeGPT在NVIDIA A10G GPU集群上接受了为期多日的培训。在此过程中,我们进行了广泛的超参数探索,以优化学习率、批量大小和其他相关参数。我们观察到一种与[Brown et al.,2020]的发现一致的模式,其中较大的批量和较小的学习率被证明是有益的。在PyTorch中实现,TimeGPT使用Adam进行训练,并采用学习速率衰减策略,将速率降低到初始值的12%。
5.4不确定度量化
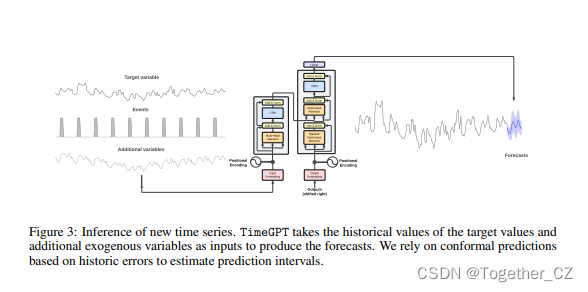
概率预测是指估计模型在预测周围的不确定性。正确评估预测模型的校准可以实现风险评估和知情决策。保形预测是一种非参数框架,它为生成具有预先指定的覆盖精度水平的预测区间提供了一种令人信服的方法[Shafer和Vovk,2008,Stankeviciute等人,2021]。与传统方法不同,共形预测不需要严格的分布假设,使其对模型或时间序列域更加灵活和不可知。在推断新的时间序列的过程中,我们对最新的可用数据进行滚动预测,以估计模型在预测特定目标时间序列时的误差。
6、实验结果
传统上,预测性能评估是基于根据定义的截止值将数据集的每个时间序列划分为训练集和测试集。这样的原理,即使是在交叉验证版本中,也不足以严格评估基础模型,因为它的主要特性是能够准确预测完全新颖的序列。
在本节中,我们将探索TimeGPT作为预测基础模型的能力,方法是在一组庞大而多样的时间序列中对其进行测试,而这些时间序列在训练过程中从未被模型看到过。该测试集包括来自多个领域的30多万个时间序列,包括金融、网络流量、物联网、天气、需求和电力。
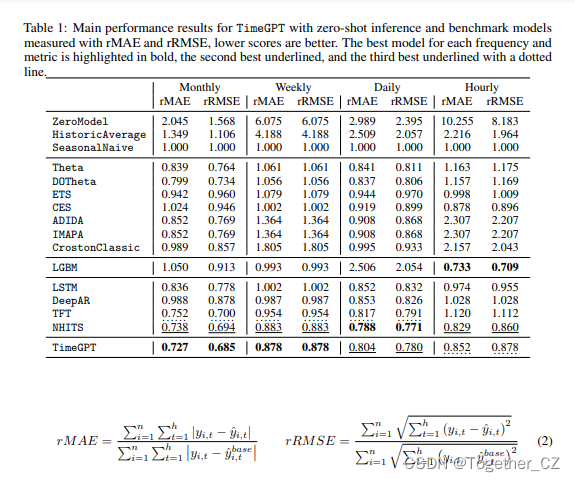
评估是在每个时间序列的最后一个预测窗口中进行的,其长度随采样频率而变化。TimeGPT使用以前的历史值作为输入,如图3所示,而不重新训练其权重(零样本)。我们根据频率指定了一个不同的预测范围,以表示常见的实际应用:12表示每月,1表示每周,7表示每天,24表示每小时的数据。
TimeGPT以广泛的基线、统计、机器学习和神经预测模型为基准,提供全面的性能分析。基线和统计模型在测试集的每个时间序列上单独训练,利用上一个预测窗口之前的历史值。我们为每个频率选择了机器学习的全局模型方法和深度学习方法,利用测试集中的所有时间序列。一些流行的模型,如Prophet[Taylor和Letham,2018]和ARIMA,由于其过高的计算要求和大量的训练时间,被排除在分析之外。
我们选择的评估指标包括相对中绝对误差(rMAE)和相对均方根误差(rRMSE),这两个指标都根据季节性Naive模型的性能进行了归一化。这些相对误差提供的额外见解证明了这一选择的合理性,因为它们显示了与已知基线相关的性能增益,提高了我们结果的可解释性。相对误差度量带来了规模独立性的额外好处,能够对每个频率的结果进行比较。为了确保稳健的数值稳定性和评估的一致性,我们在全球范围内对每个综合数据集应用这种归一化。方程2中描述了适用于具有n个时间序列和h的预测范围的数据集的这些度量的具体计算。
6.1零样本推断
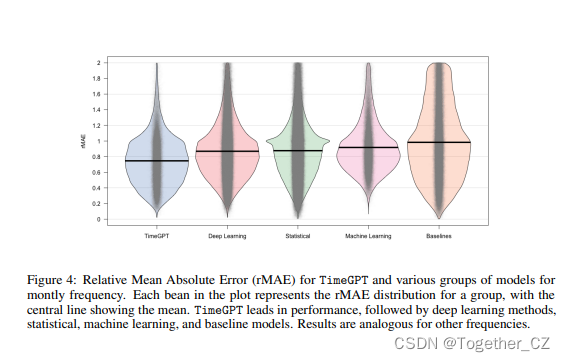
我们首先在零样本推理上测试TimeGPT功能,这意味着不会在测试集上执行额外的微调。表1给出了零样本结果。值得注意的是,TimeGPT的性能优于经过战斗测试的综合统计模型和SoTA深度学习方法,在各个频率中排名前三。
必须注意的是,预测模型的有效性只能根据其相对于竞争替代品的表现来评估。尽管精度通常被视为唯一相关的度量标准,但计算成本和实现复杂性是实际应用的关键因素。在这方面,值得注意的是,TimeGPT的报告结果是对预训练模型的预测方法进行简单且极其快速调用的结果。相比之下,其他模型需要一个完整的训练和预测管道。
6.2微调
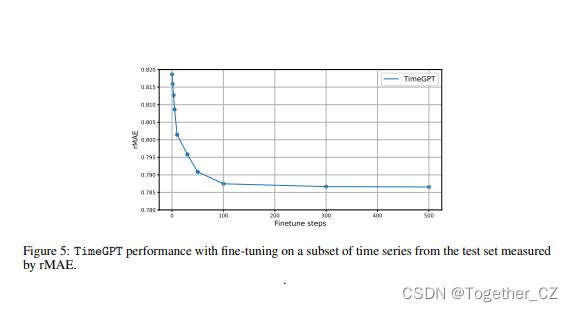
微调是有效利用基础模型和基于变压器的架构的关键步骤。基础模型是在大量数据上预先训练的,捕获了广泛的通用特征。然而,这些模型通常需要针对特定的上下文或领域进行专门化。通过微调,我们调整特定任务数据集上的模型参数,使模型能够根据新任务的要求调整其大量预先存在的知识。这个过程确保模型保持其广泛的理解,并擅长手头的特定任务。由于其固有的灵活性和学习复杂模式的能力,基于转换器的架构尤其受益于微调,从而增强了其在特定领域应用中的性能。因此,微调是一座至关重要的桥梁,将基础模型的广泛能力与目标任务的特殊性联系起来。图5显示了TimeGPT相对于测试集上时间序列子集的微调步骤数量的准确性改进结果。
6.3时间比较
对于零样本推理,我们的内部测试记录了TimeGPT每个系列0.6毫秒的平均GPU推理速度,这几乎反映了简单的季节性天真。作为比较点,我们考虑了并行计算优化的统计方法,当与Numba编译互补时,用于训练和推理的平均速度为每个系列600毫秒。另一方面,LGBM、LSTM和NHITS等全局模型在考虑训练和推理的情况下,每个系列的平均时间延长了57毫秒。由于其零样本功能,TimeGPT在总速度上优于传统统计方法和全局模型几个数量级。
7讨论和未来研究
目前的预测实践通常涉及一个复杂的管道,包括从数据处理到模型训练和选择的多个步骤。TimeGPT通过将流水线减少到推理步骤,极大地简化了这一过程,大大降低了复杂性和时间投入,同时仍然实现了最先进的性能。也许最重要的是,TimeGPT使大型变压器模型的优势民主化,如今这些模型仅限于拥有大量数据、计算资源和技术专业知识的组织。我们相信,基础模型将对预测领域产生深远影响,并可以重新定义当前的实践。
在时间序列中引入一个类似于其他领域的基础模型,为未来的改进开辟了可能的道路,这可以被视为时间序列领域的一个重要里程碑。然而,这项工作必须被理解为一个更大的学术传统的一部分,有很多悬而未决的问题。尽管我们相信TimeGPT显示了惊人的结果,首次提出了一个能够准确预测未知序列的通用全局模态,但仍存在许多重要的局限性和悬而未决的问题。我们希望这一评估对当前和未来的研究人员有帮助。
我们的结果与之前关于大型时间序列模型的预期性能的直觉一致。这与Zalando、OpenAI、阿里巴巴和亚马逊的研究结果一致[Kunz等人,2023,Brown等人,2020,Eisenach等人,2020]。这些结果验证了与模型大小、数据集大小和Transformer性能相关的缩放定律。正如在[Zeng et al.,2023]等研究中观察到的那样,这些定律阐明了为什么更简单的模型在较小的数据集上可能优于Transformers。因此,Transformers的相关性依赖于上下文,并且随着数据集大小的增加,它们通常变得更加有益。这些定律提供了重要的实践见解,指导特定任务的模型选择。在大型数据集或计算资源的可用性受到限制的情况下,更简单的模型可能更适合。展望未来,我们确定了未来勘探的两个主要领域:
1. Informed forecasting:包括关于潜在过程的知识,如物理定律、经济原理或医学事实。
2.Time Series Embedding:虽然传统上从业者假设,零售或金融等同一类别的序列比跨领域的序列具有更大的相似性,但衡量序列之间相似性的稳健指标可能会对该领域大有裨益。这项工作表明,围绕时间序列分类的某些假设值得进一步研究。
此外,关于时间序列分类的基础模型以及真正的多模式(文本、视频)和多时相基础模型的集成的相邻问题有望成为未来研究的重要领域。这些领域不仅将扩展我们对时间序列数据的理解,还将提高我们开发更强大、更通用的预测模型的能力。
简单粗略读了一下作者的论文,初步体会学习了第一个TimeGPT的构建路线,后续可能会有更多这类的项目出来。
相关文章:
TimeGPT-1——第一个时间序列数据领域的大模型他来了
一直有一个问题:时间序列的基础模型能像自然语言处理那样存在吗?一个预先训练了大量时间序列数据的大型模型,是否有可能在未见过的数据上产生准确的预测?最近刚刚发表的一篇论文,Azul Garza和Max Mergenthaler-Canseco提出的TimeGPT-1,将ll…...
通过Google搜索广告传送的携带木马的PyCharm软件版本
导语 最近,一起新的恶意广告活动被发现,利用被入侵的网站通过Google搜索结果推广虚假版本的PyCharm软件。这个活动利用了动态搜索广告,将广告链接指向被黑客篡改的网页,用户点击链接后下载的并不是PyCharm软件,而是多种…...

网站文章收录因素,别人复制文章排名比你原创的好?
我经常看到有站长抱怨“网站不收录”,“排名不好”,“复制的文章为什么秒收”之类的问题。对于SEO从业者来说,这确实是一个打击,认为搜索引擎不公平。凭什么自己原创不收录,别人复制去了,秒收他的ÿ…...

C#开源的一个能利用Windows通知栏背单词的软件 - ToastFish
前言 今天给大家推荐一个C#开源且免费的能利用Windows通知栏背单词的软件,可以让你在上班、上课等恶劣环境下安全隐蔽地背单词(利用摸鱼时间背单词的软件):ToastFish。 操作系统要求 目前该软件只支持Windows10及以上系统&…...
速拿offer,超全自动化测试面试题+答案汇总,背完还怕拿不到offer?
目录:导读 前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜) 前言 1、你会封装自动化…...

LeetCode----1415. 长度为 n 的开心字符串中字典序第 k 小的字符串
题目 一个 「开心字符串」定义为: 仅包含小写字母 [‘a’, ‘b’, ‘c’].对所有在 1 到 s.length - 1 之间的 i ,满足 s[i] != s[i + 1] (字符串的下标从 1 开始)。比方说,字符串 “abc”,“ac”,“b” 和 “abcbabcbcb” 都是开心字符串,但是 “aa”,“baa” 和 “a…...

2310C++协程超传服务器
原文 告别异步回调模型,写代码更简单.同样也是跨平台,仅头文件的,包含头文件即可用,来看看它的用法. 基本用法 提供getpost服务 coro_http_server server(1, 9001);server.set_http_handler<GET, POST>("/", [](coro_http_request &req, coro_http_respo…...

【排序算法】 计数排序(非比较排序)详解!了解哈希思想!
🎥 屿小夏 : 个人主页 🔥个人专栏 : 算法—排序篇 🌄 莫道桑榆晚,为霞尚满天! 文章目录 📑前言🌤️计数排序的概念☁️什么是计数排序?☁️计数排序思想⭐绝对…...
20231103配置cv180zb的编译环境【填坑篇】
20231103配置cv180zb的编译环境【填坑篇】 2023/11/3 11:36 感谢您选择了晶视科技的cv180zb,让我们一起来填坑。 在你根据文档找不到答案的时候,是不是想把他们家那个写文档的家伙打一顿,我顶你。 当你在在网上找一圈,BAIDU/BING/…...
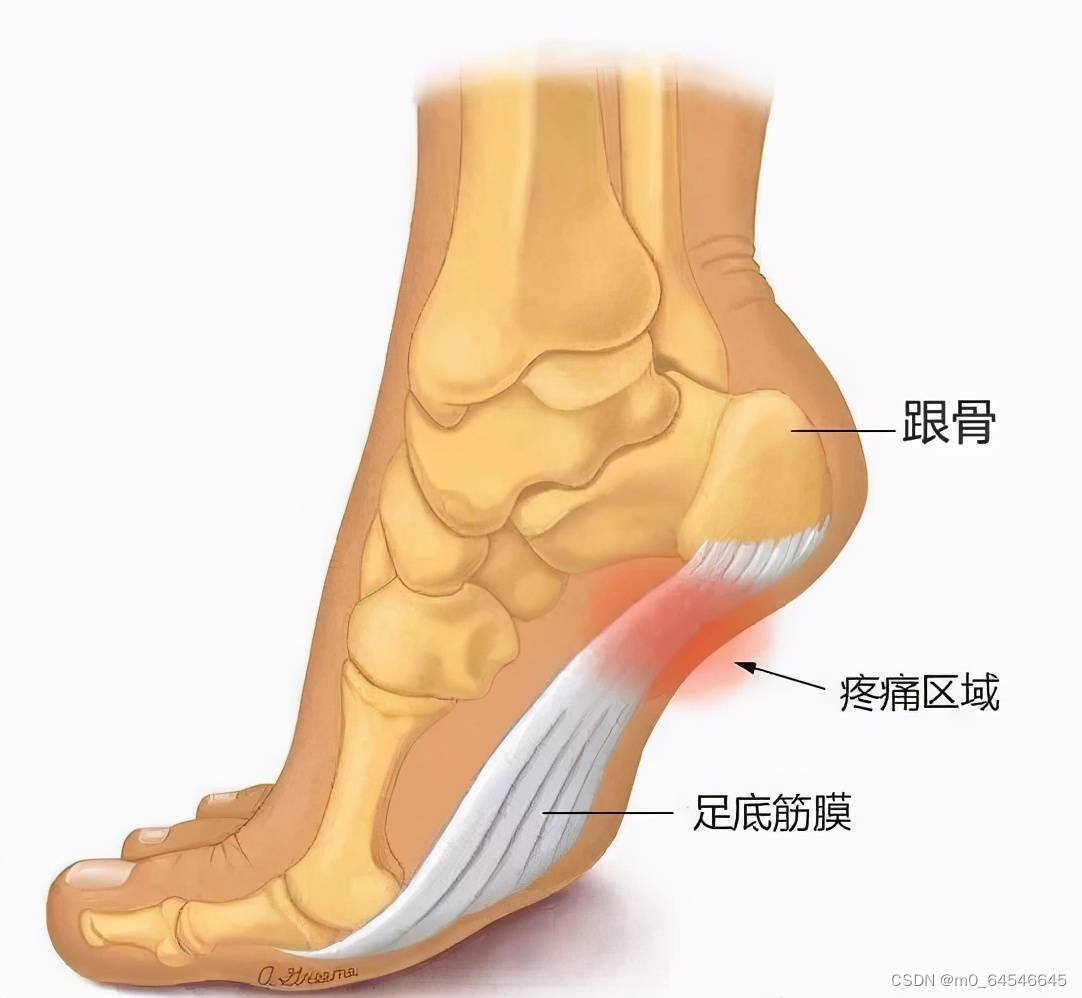
足底筋膜炎如何治疗
足底筋膜炎主要表现为下床站立后或休息后再次走路时,出现足跟部的疼痛与不适症状,活动后可自行缓解,但走路时间长或较剧烈活动后,疼痛会再次加重,甚至有针扎样疼痛感向脚前部发散,影响患者的日常生活。 足…...

rabbitMq路由键介绍
rabbitTemplate.convertAndSend() 是 Spring AMQP 中用于发送消息到 RabbitMQ 的方法。下面是对您提供的代码示例的解释: rabbitTemplate.convertAndSend("ums-platform.ex", "ums.report.routing", param);这行代码主要完成以下几个操作&…...

【python基础】python切片—如何理解[-1:],[:-1],[::-1]的用法
文章目录 前言一、基本语法二、切片1.a[i:j]2.a[i:j:k] 总结:[-1] [:-1] [::-1] [n::-1] 前言 在python中,序列是python最基本的数据结构,包括有string,list,tuple等数据类型,切片对序列型对象的一种索引方…...

剑指JUC原理-9.Java无锁模型
👏作者简介:大家好,我是爱吃芝士的土豆倪,24届校招生Java选手,很高兴认识大家📕系列专栏:Spring源码、JUC源码🔥如果感觉博主的文章还不错的话,请👍三连支持&…...

汽车托运使用的场景
在托运车辆时,要仔细的检查车辆的性能,比如电瓶电量是否充足,发动机的性能是否良好,轮胎是否是正常的气压,冬季时需使用防冻液,车内禁止放易燃易爆物品。 托运时还需选择一家好的托运公司,首先要…...

机器学习 - 加油站数据分析
一、实验数据 数据集:“加油站数据.xls” 数据集介绍:该表记录了用户在11月和12月一天24小时内的加油信息,包括:持卡人标识(cardholder)、卡号(cardno)、加油站网点号(n…...
基于CMFB余弦调制滤波器组的频谱响应matlab仿真
目录 1.算法运行效果图预览 2.算法运行软件版本 3.部分核心程序 4.算法理论概述 4.1、CMFB余弦调制滤波器组原理 4.2、CMFB调制过程 4.3、CMFB特点 5.算法完整程序工程 1.算法运行效果图预览 2.算法运行软件版本 matlab2022a 3.部分核心程序 ......................…...

helm一键部署grafana
一键部署命令 helm repo add prometheus-community https://prometheus-community.github.io/helm-charts helm repo update helm install prometheus prometheus-community/kube-prometheus-stack暴露服务 kubectl port-forward --address 0.0.0.0 deployment/prometheus-gr…...

pytorch复现_NMS
NMS(非极大值抑制)阈值是用于控制在一组重叠的边界框中保留哪些边界框的参数。当检测或识别算法生成多个边界框可能涵盖相同物体时,NMS用于筛选出最相关的边界框,通常是根据它们的置信度分数。 具体来说,NMS的工作原理…...
备份doris数据到minio
1、MINIO 设置 创建服务账户,记住ACCESS_KEY和SECRET_KEY 创建Buckets doris 设置region 在首页查看服务ip和端口号 2、创建S3备份库 因为minio是兼容S3协议的,所以可以通过s3协议链接minio。 CREATE REPOSITORY minio WITH S3 ON LOCATION "s3://…...

Linux中正则表达式等
grep命令:主要作用就是过滤查找文本内容 常用的选项有: -m 数字:匹配几次之后停止,按行匹配,不是按字符个数,例如 -v:取反 例如: -n:显示匹配的行号 例如: -c:仅显示匹配的行数,不显示匹配内…...

Agent+可穿戴设备:心率、睡眠、活动数据如何变成有价值的健康建议
可穿戴设备每天都会产生心率、睡眠、步数、活动强度等数据,但开发者真正要解决的不是“采集更多指标”,而是把这些指标转成可解释、可追踪、可配置的健康提示。本文从工程角度搭建一个简化版 Agent 服务,演示如何完成数据接入、趋势计算、规则…...
基于Trinket与NeoPixel的声控LED色彩风琴制作全攻略
1. 项目概述:让声音驱动光效色彩风琴,一个听起来有些复古的名字,在七八十年代的迪斯科舞厅和家庭派对上,它曾是营造氛围的明星。本质上,它就是一个声控灯光系统,能够将音乐的节奏和强度实时转化为绚丽的光影…...

Netduino Plus 2硬实时驱动WS2812:托管环境下的纳秒级GPIO控制实战
1. 项目概述:当托管环境遇上纳秒级时序如果你玩过嵌入式开发,尤其是用Arduino驱动过WS2812(也就是Adafruit的NeoPixels),那你肯定知道那套经典的Adafruit_NeoPixel库,几行代码就能让灯带流光溢彩。但当你把…...

计算机数值型数据表示:从二进制到浮点数与字符编码的底层原理
1. 项目概述:从“0”和“1”到万千世界我们每天都在和计算机打交道,无论是刷短视频、处理文档,还是运行复杂的科学计算。你有没有想过,屏幕上那些生动的图像、动听的音乐、精确的数值,在计算机的“大脑”——CPU和内存…...
)
别再怕模型不准了!用MATLAB的musyn命令搞定鲁棒控制器设计(附D-K迭代详解)
用MATLAB的musyn命令实现工业级鲁棒控制器设计实战指南 在控制系统的实际工程应用中,模型不确定性就像房间里的大象——人人都知道存在,却常常选择忽视。直到某天,精心设计的控制器在真实环境中表现失常,工程师们才意识到那些被忽…...

Unpaywall:当学术研究遇上智能助手,如何一键解锁全球开放获取文献
Unpaywall:当学术研究遇上智能助手,如何一键解锁全球开放获取文献 【免费下载链接】unpaywall-extension Firefox/Chrome extension that gives you a link to a free PDF when you view scholarly articles 项目地址: https://gitcode.com/gh_mirrors…...

抖音批量下载神器:轻松保存无水印视频的终极指南 [特殊字符]
抖音批量下载神器:轻松保存无水印视频的终极指南 🎬 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallb…...
)
ESP32玩转1.8寸LCD屏:用TFT_eSPI库做个桌面小时钟(附完整代码)
ESP32打造高颜值桌面时钟:从TFT_eSPI库到完整项目实战 在创客的世界里,将硬件与代码结合创造出实用又有趣的项目总是令人兴奋。今天我们要用ESP32开发板和1.8寸ST7735驱动的LCD屏幕,打造一个功能完善、界面美观的桌面电子时钟。这个项目不仅适…...

如何高效构建智能投资助手:韭菜盒子VSCode插件的7大核心功能深度解析
如何高效构建智能投资助手:韭菜盒子VSCode插件的7大核心功能深度解析 【免费下载链接】leek-fund :chart_with_upwards_trend: 韭菜盒子VSCode插件,可以看股票、基金、期货等实时数据。 LeekFund turns your VS Code and Cursor into a real-time stock,…...

3分钟上手Awoo Installer:Switch游戏安装终极指南
3分钟上手Awoo Installer:Switch游戏安装终极指南 【免费下载链接】Awoo-Installer A No-Bullshit NSP, NSZ, XCI, and XCZ Installer for Nintendo Switch 项目地址: https://gitcode.com/gh_mirrors/aw/Awoo-Installer 还在为Switch游戏安装烦恼吗…...