58同城面试
一、Java八股
1、ThreadLocal的底层原理是什么?
ThreadLocal 在Java中用于提供线程局部变量,这些变量在每个线程中都有独立的副本,互不干扰。其底层原理可以简要描述如下:
-
数据存储: 每个线程中都有一个
ThreadLocalMap的实例,用于存储线程局部变量。键是ThreadLocal实例本身,值是线程局部变量的副本。 -
初始化: 当线程第一次通过
get()或set()方法访问ThreadLocal变量时,会触发ThreadLocal的初始化流程,为线程创建一个ThreadLocalMap实例。 -
获取值: 在调用
get()方法时,ThreadLocal会使用当前线程中的ThreadLocalMap,并使用自身作为键来获取对应的值。 -
设值: 在调用
set()方法时,同样会使用当前线程的ThreadLocalMap,并使用ThreadLocal实例作为键来存储值。 -
防止内存泄漏: 由于使用了线程自身的
ThreadLocalMap,因此有必要在不再需要线程局部变量时清理它们,以防止潜在的内存泄漏。这通常是通过调用ThreadLocal的remove()方法来完成的。
2、双亲委派机制
双亲委派机制是一种强有力的安全和隔离机制,但在某些情况下,如果需要打破这种层级关系,可以通过自定义类加载器并覆盖其加载类的方法来实现。双亲委派机制是Java中类加载器的一种工作机制,它的主要流程如下:
-
加载检查: 当一个类加载器需要加载一个类时,它不会首先尝试自己加载这个类,而是委派给它的父加载器。
-
递归委派: 这个委派过程是递归的,最终会达到最顶层的类加载器(如Bootstrap ClassLoader)。
-
尝试加载: 如果父加载器能够加载这个类,则使用父加载器的结果。如果父加载器无法加载这个类(因为它没有找到这个类),则调用子加载器自己的
findClass方法尝试加载这个类。 -
安全性与隔离: 这种机制可以确保Java核心库的类型安全,因为无论哪个类加载器最终加载了java核心库的类,都是同一个类加载器(Bootstrap),确保了被信任的类不会被覆盖。
-
效率: 这种机制也提高了类加载的效率。因为如果一个类加载器已经加载过某个类,那么它的所有子加载器都无需再次加载这个类。
3、线程池如何构造,线程池7大参数,拒绝策略有哪些
在Java中,线程池可以通过java.util.concurrent.ExecutorService接口及其实现类来构造和管理。最常用的实现类是ThreadPoolExecutor。
线程池7大参数
-
corePoolSize: 线程池的基本大小,即在没有任务需要执行时线程池的大小,也就是线程池中基本的线程数。
-
maximumPoolSize: 线程池最大的大小,即线程池中允许的最大线程数。
-
keepAliveTime: 当线程池中线程数量超过
corePoolSize时,多余的空闲线程能存活的最长时间。 -
unit:
keepAliveTime的时间单位。 -
workQueue: 工作队列,用于存储等待执行的任务。
-
threadFactory: 线程工厂,用于创建新线程。
-
handler: 拒绝策略,当任务太多来不及处理,如何拒绝任务。
拒绝策略
常见的拒绝策略有以下几种:
- AbortPolicy: 直接抛出
RejectedExecutionException异常。 - CallerRunsPolicy: 调用执行自己的线程运行任务。
- DiscardOldestPolicy: 放弃队列最前面的任务,并执行当前任务。
- DiscardPolicy: 不处理,直接丢弃。
4、多线程有了解吗?异步编程如何实现
多线程是一种使得多个线程并发执行的编程技术,通常用于提高程序的执行效率和响应速度。Java中的多线程可以通过Thread类或者实现Runnable接口来创建和管理。
异步编程是一种编程范式,允许程序在等待某些操作完成的时候继续执行其他任务。在Java中,异步编程可以通过Future、CompletableFuture或者使用Reactive编程库如Project Reactor来实现。异步编程的关键是将耗时的操作放在另一个线程或者任务中执行,从而不阻塞当前线程,提高程序的整体效率。
5、进程与线程的区别
-
定义:
- 进程: 是一个程序的执行实例,具有独立的代码和数据空间,进程间的通信需要特定的IPC方法。
- 线程: 是进程内的一个执行单元,负责当前进程中程序的执行。
-
资源分配和独立性:
- 进程: 拥有完全独立的地址空间,进程间不会互相影响。
- 线程: 同一进程内的线程共享地址空间,一个线程崩溃会影响整个进程。
-
创建和管理:
- 进程: 创建和管理进程的开销较大。
- 线程: 线程的创建和管理开销相对较小。
-
通信:
- 进程: 进程间通信(IPC)需要操作系统的介入,效率较低。
- 线程: 线程间可以直接通信,效率更高。
6、结合操作系统说一下多线程并发为什么会对系统造成影响
-
资源竞争: 多个线程可能会同时访问共享资源,导致资源竞争,需要操作系统进行调度和管理。
-
上下文切换: 频繁的线程切换会导致大量的CPU时间被用于上下文切换,降低系统效率。
-
死锁: 线程之间因资源竞争可能出现死锁的情况,需要操作系统介入解决。
-
稳定性和安全性: 不合理的线程操作可能导致程序崩溃,甚至影响操作系统的稳定性。
7、HashMap的数据结构和使用的注意点
HashMap在Java中是一种基于哈希表的Map接口实现,其主要数据结构包括:
-
数组: 存储元素的主体是一个数组。
-
链表: 当哈希冲突时,元素会以链表的形式存储在数组的同一个索引位置。
-
红黑树: 当链表长度超过一定阈值时,链表会转换为红黑树以提高查找效率。
使用HashMap的注意点:
-
线程不安全:
HashMap是线程不安全的,多线程操作时需要注意同步。 -
初始容量和加载因子: 合理设置初始容量和加载因子可以提高
HashMap的性能。 -
Key的哈希函数: Key对象的哈希函数需要合理设计,以避免大量的哈希冲突。
-
Key的不可变性: 作为Key的对象最好是不可变的,这样可以确保哈希值的一致性。
-
Null值:
HashMap允许使用null作为Key和Value,但最好避免这样做以防止出现歧义。 -
容量扩展: 当元素数量达到容量和加载因子的乘积时,
HashMap会进行扩容操作,这是一个耗时的过程,需要注意。 -
遍历效率: 如果HashMap的容量远大于实际存储的键值对数量,遍历HashMap的效率会较低,因为需要遍历很多空的桶。
8、HashMap中如何定位桶,有100个key-value格式的数据要存在HashMap中,如何使得效率最高
在HashMap中,桶的定位是通过哈希算法来实现的。具体步骤如下:
-
计算Key的HashCode: 调用Key对象的
hashCode()方法计算出其哈希值。 -
扰动函数处理: 为了减少哈希碰撞,将HashCode经过扰动函数处理,充分混合HashCode的高位和低位。
-
计算索引位置: 使用处理过的HashCode值与数组长度减一进行位与操作,计算出桶的位置。
-
index = (n - 1) & hash其中,
n是数组的长度,hash是处理过的HashCode值。
为了使存储100个Key-Value对的效率最高,可以考虑以下策略:
-
设置合适的初始容量: 设置一个合适的初始容量,以减少或消除扩容操作。考虑到加载因子默认为0.75,为避免扩容,初始容量应设置为至少134(100 / 0.75)。
-
设计良好的Key哈希函数: 确保Key的哈希函数设计得足够好,能够均匀地分布哈希值,减少哈希冲突。
-
避免使用可变对象作为Key: 使用不可变对象(如字符串或整数)作为Key,以确保在HashMap的整个生命周期内,Key的哈希值保持不变。
9、扰动函数的原理与作用,为什么扰动函数能够减少hash冲突
原理:
扰动函数是对哈希值进行一系列位操作的过程,目的是为了更好地分散原始哈希码的位信息,使得哈希值在桶数组中的分布更加均匀。在Java 8中,HashMap的扰动函数主要通过hash >>> 16实现,即将32位的原始哈希码向右无符号移动16位。
作用:
扰动函数的主要作用是为了减少哈希冲突,提高HashMap的查找效率。通过将哈希码的高16位和低16位进行异或操作,能够使得原本在低位分布不均匀的哈希码在数组中的分布更加均匀。
为什么能减少哈希冲突:
扰动函数通过混合哈希码的高位和低位信息,使得即使原始哈希码在低位上分布不均匀,经过扰动函数处理后也能在数组中均匀分布,从而减少了哈希冲突的可能性。这样,即使在遇到较差的哈希函数时,HashMap的性能也能得到一定程度的保障。
10、HashMap在rehash操作时需要重新对每一个值进行计算吗
在HashMap进行rehash操作时,它需要重新计算每个存储在HashMap中的元素的桶位置。这是因为当HashMap的容量变化时(通常是翻倍),桶的数量也发生了变化,这就需要重新计算每个元素在新数组中的位置。这个过程通常涉及到重新计算元素键的哈希值,并根据新的数组大小重新定位元素。
11、接口和抽象类的区别
定义
-
接口(Interface): 是一种完全抽象的结构,只能定义方法的签名,不能包含方法的实现。
-
抽象类(Abstract Class): 是一种可能包含抽象方法(没有实现的方法)的类。
实现
-
接口: 一个类可以实现多个接口。
-
抽象类: 一个类只能继承一个抽象类。
方法
-
接口: Java 8之后,接口可以包含默认方法(有实现的方法)和静态方法。但在此之前,接口中的所有方法都必须是抽象的。
-
抽象类: 可以包含抽象方法和非抽象方法。
构造器
-
接口: 不能有构造器。
-
抽象类: 可以有构造器。
成员变量
-
接口: 只能定义常量(public static final)。
-
抽象类: 可以定义变量,可以有成员变量。
访问修饰符
-
接口: 方法默认是public的。
-
抽象类: 方法可以有任意访问修饰符。
12、多态必须有继承和重写吗
多态的实现通常依赖于继承和方法重写。在面向对象编程中,多态允许你将子类类型的对象赋值给父类类型的引用变量。这样,你就可以使用父类的引用来调用在子类中重写的方法。
-
继承: 提供了一种机制,允许子类继承父类的属性和方法。
-
重写(Overriding): 在子类中提供了一种方法,这种方法与在其父类中定义的方法具有相同的方法签名。
虽然多态的典型实现依赖于继承和重写,但Java也支持接口实现的多态,你可以有一个接口和多个实现该接口的类。在这种情况下,多态是通过实现接口的不同类来实现的,而不是通过继承和重写。
13、AQS对资源的两种共享方式以及具体的应用例子
AQS(AbstractQueuedSynchronizer)是Java中提供的一种用于构建锁和同步器的框架。AQS使用一个int成员变量来表示同步状态,通过内置的FIFO队列来完成资源获取线程的排队工作。AQS支持两种资源共享方式:
独占模式(Exclusive):
在这种模式下,每次只能有一个线程持有锁。AQS会将尝试获取锁的其他线程放入队列中。
- 应用例子:
ReentrantLock是一个典型的独占模式的应用。它确保了每次只有一个线程能够执行被保护的代码区域。
共享模式(Shared):
在这种模式下,多个线程可以共同持有锁。具体有多少个线程可以共享锁,取决于同步器的实
- 应用例子:
Semaphore:一个计数信号量,允许多个线程同时访问。ReadWriteLock:它有一个读锁和一个写锁,读锁可以被多个读线程持有,但写锁是独占的。CountDownLatch:允许一个或多个线程等待其他线程完成操作。
14、Semaphore和CountDownLatch的区别
Semaphore(信号量)
- 作用: 主要用于控制对资源的访问线程数目。
- 用途: 用于实现资源的限制访问,常用于流量控制。
- 灵活性: Semaphore可以控制同时访问资源的线程个数,并提供了同步方法来释放或者获取访问权限。
- 调用方法: acquire()和release(),分别用于获取和释放访问权限。
CountDownLatch(倒计时锁存器)
- 作用: 允许一个或多个线程等待其他线程完成操作。
- 用途: 常用于等待服务初始化完毕后再执行其他操作。
- 灵活性: CountDownLatch的计数器在创建时就需要指定,而且只能使用一次,计数器达到0后无法重置。
- 调用方法: countDown()和await(),分别用于计数减一和等待计数到达0。
总的来说,Semaphore更多的是用来控制对特定资源的访问线程数目,而CountDownLatch用于一个线程等待多个线程完成操作后再执行。
15、 类加载的过程和机制
Java的类加载过程包括以下几个主要阶段:
加载(Loading)
- 作用:查找并加载类的二进制数据。
- 过程:通过一个类的全限定名来获取其定义的二进制字节流,并将这个字节流所代表的静态存储结构转换为方法区的运行时数据结构。在内存中生成一个代表这个类的
java.lang.Class对象,作为方法区这个类的各种数据的访问入口。
验证(Verification)
- 作用:确保Class文件的字节流包含的信息符合当前虚拟机的要求,不会危害虚拟机自身的安全。
- 过程:包括文件格式验证、元数据验证、字节码验证、符号引用验证等。
准备(Preparation)
- 作用:为类中定义的静态变量分配内存,并设置默认初始值。
- 注意:这时候进行内存分配的仅包括类变量(被static修饰的变量),而不包括实例变量。
解析(Resolution)
- 作用:将常量池内的符号引用替换为直接引用的过程。
- 过程:涉及到类或接口、字段、类方法、接口方法的解析。
初始化(Initialization)
- 作用:对类进行初始化。
- 过程:包括执行类构造器<clinit>()方法的过程。此方法是由编译器自动收集类中所有类变量的赋值动作和静态代码块中的语句合并产生的。
类加载的机制包括:
- 全盘负责:当一个类加载器负责加载某个Class时,该Class所依赖和引用的其他Class也将由这个类加载器负责载入,除非显式使用另外一个类加载器来载入。
- 父类委派:这是一种组织类加载器的层次关系的常见方式。Java使用了父类委派机制来加载类,即当一个类加载器接收到类加载的请求,它首先不会尝试加载这个类,而是把这个请求委派给父类加载器,每一层都是如此,因此所有的加载请求最终都应该传送到顶层的启动类加载器,只有当父类加载器反馈自己无法完成这个加载请求时(在它的搜索范围中没有找到所需的Class),子加载器才会尝试自己去加载。
16、OOM 遇到情况和解决
OOM的常见情况:
-
堆内存溢出(Java Heap Space):创建的对象过多,超过了堆的最大限制。
- 解决方案:增加堆内存大小或优化内存使用,查找内存泄漏。
-
栈内存溢出(Stack Overflow):方法调用层次太深,超出了栈的最大限制。
- 解决方案:增加栈大小或优化递归调用。
-
方法区溢出:常量池或类元数据信息太多,超过了方法区的最大限制。
- 解决方案:增加方法区的大小或减少运行时常量池的使用。
-
直接内存溢出:使用NIO时,申请的直接内存过大。
- 解决方案:增加直接内存的大小。
-
线程创建过多:创建的线程数目超过系统承载极限。
- 解决方案:减少线程的创建,使用线程池。
解决方法:
-
分析堆转储文件:使用工具(如Eclipse Memory Analyzer)分析堆转储文件,查找内存泄漏或者大对象。
-
调整JVM参数:根据具体情况调整JVM启动参数,如-Xms, -Xmx, -Xss等。
-
代码优化:优化代码逻辑,减少内存占用,避免内存泄漏。
-
资源清理:确保使用完资源后进行适时的清理,如关闭文件、数据库连接等。
-
使用Profiler工具:使用Profiler工具对运行时的程序进行分析,找出内存占用高或者线程活动异常的地方进行优化。
通过这些方法,可以有效地避免或解决OOM问题,确保程序的健壮性和稳定性。
17、怎么理解线程安全,解决线程安全问题
线程安全理解
- 定义:在多线程环境下,多个线程对同一对象或资源进行操作时,无论运行时操作系统如何调度这些线程,程序都能正确执行,即能够保证数据的正确性和一致性。
- 实现要点:
- 原子性:操作要么全部完成,要么全不完成,不会停留在中间某个环节。
- 可见性:当一个线程修改了对象的状态,其他线程能够立即看到这种变化。
- 有序性:操作执行的顺序按照代码的先后顺序执行。
解决线程安全问题的方法
- 加锁:使用synchronized或ReentrantLock来为方法或代码块加锁,确保同一时刻只有一个线程执行该段代码。
- 使用线程安全类:如使用ConcurrentHashMap代替HashMap,使用StringBuffer代替StringBuilder等。
- 使用volatile关键字:确保变量的可见性,禁止指令重排。
- 使用不可变类:如String、Integer等。
- 使用局部变量:局部变量是线程安全的,因为它们存储在栈内存中,属于线程私有的数据。
- 使用ThreadLocal:为每个线程提供单独一份存储空间,实现线程间数据隔离
18、ConcurrentHashMap怎么保证线程安全、ConcurrentHashMap1.7和1.8的区别
ConcurrentHashMap的线程安全性
- 实现机制:ConcurrentHashMap通过分段锁(Segment)的机制,将数据分成一段一段存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一段数据时,其他段的数据也能被其他线程访问。
- 具体实现:在JDK1.7中,ConcurrentHashMap采用Segment数组和HashEntry数组结合的方式实现。在JDK1.8中,放弃了Segment的概念,直接采用Node数组+链表+红黑树的数据结构实现。
ConcurrentHashMap1.7和1.8的区别
- Segment的使用:
- 1.7中使用Segment来进行分段加锁。
- 1.8中放弃了Segment,采用了Node数组+链表+红黑树,通过对Node的操作实现线程安全。
- 锁的粒度:
- 1.7中粒度较粗,每个Segment持有一把锁。
- 1.8中粒度更细,使用synchronized对Node进行加锁,大大提升了效率。
- 数据结构:
- 1.7中使用Segment数组+HashEntry数组+链表。
- 1.8中使用Node数组+链表+红黑树。
19、分段锁是可重入的吗、你怎么理解可重入锁
分段锁的可重入性
分段锁的可重入性取决于其实现,ConcurrentHashMap中的分段锁是可重入的,因为它使用了ReentrantLock来实现锁的功能。
可重入锁理解
- 定义:可重入锁,也叫递归锁,指的是同一线程外层函数获得锁后,内层递归函数仍然能获取该锁的代码,在同一个线程在外层方法获取锁的时候,在进入内层方法会自动获取锁。
- 特点:简单来说,线程可以进入任何一个它已经拥有的锁所同步着的代码块。
- 好处:可重入锁的最大作用是避免死锁
20、什么是公平锁和非公平锁、非公平锁吞吐量为什么比公平锁大
公平锁
- 定义:公平锁是指多个线程按照请求锁的顺序来获取锁。
- 特点:
- 有序:保证了执行顺序,避免了饥饿现象。
- 低吞吐量:由于要在锁释放时进行线程调度,会增加系统的开销,导致吞吐量较低。
- 应用场景:适用于需要保证请求的执行顺序的场景。
非公平锁
- 定义:非公平锁是指在释放锁之后,所有等待锁的线程都有机会获取锁,而不是按照请求锁的顺序。
- 特点:
- 无序:不能保证执行顺序,可能导致某些线程一直获取不到锁。
- 高吞吐量:因为线程有可能直接获得锁,而不用排队等待,减少了线程切换的开销。
- 应用场景:适用于对执行顺序没有严格要求,追求高性能的场景。
非公平锁吞吐量为什么比公平锁大:
非公平锁之所以有更高的吞吐量,是因为它减少了线程切换的次数和等待的时间。在锁被释放时,非公平锁允许新请求锁的线程直接获得锁,而不是把锁分配给之前在队列中等待的线程。这样就省去了唤醒线程、线程切换等开销,提高了执行效率。
21、JVM内存结构、JVM为什么把堆区进一步的划分
JVM内存结构:
- 方法区:存储已被虚拟机加载的类信息、常量、静态变量、即时编译后的代码等。
- 堆区:存储对象实例,是垃圾收集器管理的主要区域。
- 栈区:存储局部变量值、方法调用的操作数、返回地址等,随着方法的调用而动态增长和减小。
- 程序计数器:记录线程执行的字节码的行号指示器。
- 本地方法栈:为虚拟机使用到的Native方法服务。
为什么把堆区进一步划分:
- 提高垃圾回收效率:不同的对象有不同的生命周期,通过将堆区进行划分,可以根据不同区域的特点采用不同的垃圾回收算法。
- Eden区、Survivor区和老年代:
- Eden区:存放新生对象。
- Survivor区:存放从Eden区经过第一次垃圾回收后仍然存活的对象。
- 老年代:存放经过多次垃圾回收仍然存活的对象。
- 减少全区垃圾回收的频率:通过将新生对象和存活时间较长的对象分开存放,可以减少对老年代的垃圾回收频率,提高系统性能。
通过对堆区的划分,JVM能够更精细地管理内存,提升垃圾回收的效率,从而提高整体的系统性能。
二、数据库八股
1、MySQL的存储引擎、B+树和B树有哪些特征和不同点
MySQL的存储引擎:
- InnoDB:支持事务处理,提供了对数据库ACID的事务支持和行级锁定。
- MyISAM:不支持事务,表级锁定,读取速度快但写入速度相对较慢。
- Memory:所有的数据都在内存中,速度极快,但重启会丢失所有数据。
- 其他:NDB、Archive等。
B+树:
- 特点:
- 所有关键字都出现在叶子节点的链表中(而且是有序的)。
- 非叶子节点可以重复。
- 比B树更加“矮胖”。
- 优势:
- 查询性能稳定。
- 全部叶子节点构成一个有序链表,便于范围查询。
B树:
- 特点:
- 关键字分布在整棵树中。
- 任何一个关键字出现且只出现在一个节点中。
- 关键字的排序是全局的。
B树和B+树的不同点:
- 层级:B+树比B树更加“矮胖”,对于相同数量的关键字,B+树的查询性能更稳定。
- 查询速度:B+树的查询性能较为稳定,B树因为关键字不是全局有序,所以查询性能不如B+树。
- 范围查询:B+树由于叶子节点形成了有序链表,所以对范围查询非常友好,而B树则需要进行多次检索。
2、在InnoDB下,联合索引是如何创建的以及创建的数据结构是咋样的
创建方式:
在MySQL中,你可以通过CREATE INDEX或在CREATE TABLE时定义索引来创建联合索引。
CREATE INDEX index_name ON table_name (column1, column2, ...);
数据结构:
- B+树:InnoDB使用B+树作为索引的数据结构,联合索引的每个索引项是索引列的值的组合。
- 索引顺序:数据是按照索引列的顺序存储的。
3、在InnoDB下,每张表都一定有聚簇索引吗
聚簇索引将数据存储与索引放到了一起,表中的数据按照每张表的主键构造一棵B+树,同时叶子节点中存放的就是整条记录的数据。
是否每张表都有
- 有主键的表:如果表定义了主键,InnoDB会使用这个主键作为聚簇索引。
- 没有主键的表:如果没有定义主键,InnoDB会选择一个唯一的非空索引代替。如果没有这样的索引,InnoDB会生成一个隐藏的主键来作为聚簇索引。
所以,每张InnoDB表都会有聚簇索引,但这个聚簇索引可能不是由显示定义的主键来构建的。
4、覆盖索引
覆盖索引是指一个索引包含(或覆盖)了查询中需要的所有字段的情况。
特点
- 性能优化:因为索引项通常比数据行小,所有字段都在索引中时,可以直接从索引中获取数据,无需回表查询,减少了磁盘I/O,提高了查询效率。
- 索引只扫描:执行计划中会显示为“Using index”,表示查询完全通过索引来完成。
应用场景
- 频繁查询的字段建议建立覆盖索引。
- 需要注意的是,覆盖索引会占用更多的存储空间。
5、Redis使用场景和数据类型
使用场景
- 缓存:提高数据读取速度。
- 会话存储:例如存储用户的Session信息。
- 排行榜:使用Sorted Set实现。
- 发布订阅系统:如消息队列。
- 计数器:例如网站访问次数统计。
数据类型
- String:字符串。
- Hash:哈希表。
- List:列表。
- Set:集合。
- Sorted Set:有序集合。
- Bitmap:位图。
- HyperLogLog:用来做基数统计。
6、Redis中的分布式锁设计
设计原则
- 互斥性:在任何时刻,只有一个客户端持有锁。
- 避免死锁:即便有一个客户端在持有锁的期间崩溃没有主动解锁,也需要保证后续其他客户端能够加锁。
- 解锁安全:只有加锁的客户端才能解锁。
- 加锁和解锁是同一个客户端:确保加锁和解锁的是同一个客户端。
实现方式
- SETNX:
SETNX key value,当且仅当key不存在时,为key设置指定的值,返回1;key已存在,什么也不做,返回0。 - 带超时的锁:为了防止死锁,锁需要有一个最大的生存时间。可以使用
EXPIRE命令来为锁设置一个过期时间。 - 安全的解锁:需要判断锁是否属于自己,可以通过
GET命令获取锁的值(客户端标识)进行判断。解锁可以使用DEL命令。
注意事项
- 确保操作的原子性:Redis的
SET命令在2.6.12版本添加了选项,可以确保设置值和设置过期时间的原子操作。SET key value EX seconds NX。 - 延长锁的过期时间:在锁即将过期的时候,如果任务还没有执行完,需要重新设置过期时间。
- Redlock算法:Redis官方提出的分布式锁算法,主要用于多实例的Redis环境中。
7、数据库与缓存一致性怎么设计的
基本原则
- 更新缓存策略:先更新数据库,再删除缓存。
- 读取数据策略:先读取缓存,缓存没有再查询数据库,并将数据更新到缓存。
实现方法
- 延时双删策略:
- 第一次删除缓存。
- 更新数据库。
- 休眠一段时间(比如100ms)。
- 第二次删除缓存。
- 消息队列:
- 数据更新后,将更新的信息发送到消息队列。
- 监听消息队列,进行缓存更新。
8、分布式事务接触过吗?原理是怎么样的?
原理
分布式事务确保在分布式系统中,事务的ACID属性仍然得以保持。
常见的实现方式有:
- 两阶段提交(2PC):
- 第一阶段:准备阶段,事务协调者询问所有参与者是否准备好提交事务,所有参与者返回结果。
- 第二阶段:提交/回滚阶段,根据第一阶段的结果,协调者发送提交或回滚的指令给所有参与者。
- 三阶段提交:
- 在两阶段提交的基础上增加了超时机制和CanCommit阶段。
- TCC(Try Confirm Cancel):
- Try阶段:尝试执行业务。
- Confirm阶段:确认执行业务。
- Cancel阶段:取消执行业务。
9、为什么数据库与缓存一致性不采用分布式事务这种方案
- 性能影响:分布式事务通常会带来较大的性能开销,尤其是在高并发、大数据量的场景下。
- 复杂性:实现分布式事务需要解决网络延迟、节点宕机等问题,实现复杂,维护成本高。
- 可用性降低:分布式事务要求所有参与节点都正常工作,一旦某个节点出问题,可能会影响整个事务的完成。
在处理数据库与缓存一致性问题时,通常追求的是高性能、高可用,而分布式事务在这些方面有一定的劣势,因此一般不会选用分布式事务来解决这类问题。相对来说,采用延时双删、消息队列等策略更加轻量级,更容易保证系统的高性能和高可用。
10、一般在什么情况下设计索引
在以下情况下,通常需要考虑设计索引:
- 频繁查询的字段:对于查询操作非常频繁的字段,设计索引可以显著提高查询效率。
- 作为查询条件的字段:经常作为WHERE子句中的条件的字段,应当建立索引。
- 排序、分组字段:经常需要ORDER BY或GROUP BY的字段,建立索引可以提高排序和分组的速度。
- 主键和外键:数据库自动为主键建立唯一索引,外键也建议建立索引,以提高关联查询的效率。
- 更新不频繁,读取频繁的字段:因为索引的维护需要成本,所以对于更新非常频繁的字段,可能需要权衡是否建立索引。
- 选择性高的字段:字段的选择性越高(不重复的值越多),建立索引的效果越好。
- 避免全表扫描:对于大表,建立索引可以避免查询时进行全表扫描。
11、SQL优化了解吗
- 选择合适的字段类型:尽量选择最合适的数据类型,避免不必要的空间浪费。
- 使用索引:合理使用索引,特别是在查询条件中的字段。
- **避免SELECT * **:只查询需要的字段,避免不必要的数据传输。
- 减少JOIN操作:JOIN操作会增加查询复杂度,尽量减少JOIN操作,或者优化JOIN的顺序。
- 使用LIMIT:当只需要查询部分数据时,使用LIMIT限制结果集的大小。
- 优化WHERE子句:避免在WHERE子句中使用函数或计算,这会导致索引失效。
- 适当使用分区:对于非常大的表,考虑使用分区技术。
- 避免大事务操作:大事务会锁定很多资源,影响系统性能。
- SQL语句优化:对复杂的SQL语句进行优化,考虑执行计划。
12、Redis为什么使用跳表而不是用B+树(跳表和B+树的区别
- 插入和删除效率高:跳表的插入和删除操作平均时间复杂度为O(logn),而且实现相对简单。
- 范围查询简单:跳表支持范围查询,且实现较为简单。
- 内存占用:虽然跳表的内存占用比B+树高(因为需要存储多级索引),但在内存不是瓶颈的场景下,跳表的高效和简单实现更加重要。
- 实现简单:跳表的数据结构和算法相对简单,易于实现和维护。
- 锁的粒度小:跳表锁的粒度小,适合高并发的场景。
与B+树相比,跳表在一些场景下提供了更好的性能,尤其是在内存数据库和高并发环境下,且实现相对更为简单。这是Redis选择使用跳表而不是B+树的主要原因。
三、项目八股
1、Netty的三大重要组件
-
Channel:代表一个网络套接字或者组件,用于处理数据的传输。
NioSocketChannel:用于TCP网络IO。NioDatagramChannel:用于UDP网络IO。- 其他类型:如用于文件传输的
FileChannel等。
-
EventLoop:用于处理Channel的I/O操作。
- 一个EventLoop可以被分配给一个或多个Channel。
- 对于每个Channel来说,它只会注册在一个EventLoop上,且其生命周期内只会被一个线程处理,这样就避免了多线程之间的竞争。
-
ChannelPipeline:持有一系列ChannelHandler实例,用于处理入站和出站I/O事件。
ChannelHandler:处理I/O事件的接口,可以自定义处理逻辑。ChannelPipeline实现了Interceptor模式,可以通过它来实现网络通信中的编码、解码、安全认证等功能。
2、采用的是JDK的序列化机制,底层序列化机制原理?
JDK序列化机制是Java提供的一种将对象转换为字节流的方法,也可以从字节流中恢复对象。其主要用于网络传输、本地存储等。
原理:
-
对象序列化:将对象的状态信息转换为可以存储或传输的形式。
- 使用
ObjectOutputStream写出对象。 - 需要序列化的对象必须实现
Serializable接口。 - 支持递归序列化:对象的字段是对象时,这些对象也会被序列化。
- 使用
-
对象反序列化:从序列化状态恢复为对象。
- 使用
ObjectInputStream读取对象。 - 类的定义需要可用,且
serialVersionUID需要匹配。
- 使用
底层原理:
- 流协议:序列化流包含了类的元数据、类的名称、字段名称及值等信息。
- 对象引用共享:相同对象在序列化过程中只会被写入一次,之后只会写入引用,避免了循环引用问题。
- 使用
writeObject和readObject方法自定义序列化逻辑:如果类中存在这两个方法,JDK序列化机制会调用它们来进行序列化和反序列化。
3、SpringSession是用来干嘛的
- 集中式会话管理:在分布式系统中,多个应用实例共享用户的会话信息。
- Restful API兼容:适用于无状态的Restful服务。
- 多浏览器会话:一个用户可以在多个浏览器或者标签页中保持登录状态。
- 持久化会话存储:将会话信息存储在外部存储中,如Redis、数据库等。
- 提供并发控制:防止会话在并发修改时产生冲突。
通过使用Spring Session,可以在分布式环境下提供更加强大、灵活的会话管理能力。
四、计算机网路八股
1、说一下计算机网络中的四次挥手,以及各个状态
TCP协议为了保证数据可靠传输,采用了三次握手和四次挥手的机制。四次挥手主要是为了断开一个TCP连接,其过程如下:
- 客户端发送FIN报文:客户端进入FIN_WAIT_1状态,通知服务端它已经没有数据要发送了,希望关闭连接。
- 服务端接收到FIN报文,发送ACK报文:服务端进入CLOSE_WAIT状态,它告诉客户端已经收到了关闭请求。客户端收到ACK报文后,进入FIN_WAIT_2状态。
- 服务端发送FIN报文:当服务端也没有数据要发送时,它会发送FIN报文给客户端,进入LAST_ACK状态,等待客户端的最后一个ACK报文。
- 客户端发送ACK报文:客户端进入TIME_WAIT状态,发送最后一个ACK报文给服务端。服务端收到ACK报文后,连接关闭,进入CLOSED状态。客户端会等待一段时间(2MSL,即最大报文段生存时间的两倍),确保服务端收到ACK报文,然后进入CLOSED状态。
2、读文件每行一个IP,统计topK出现的IP
import heapqdef top_k_ips(filename, k):ip_count = {}with open(filename, 'r') as f:for line in f:ip = line.strip()if ip in ip_count:ip_count[ip] += 1else:ip_count[ip] = 1# 使用最小堆找出出现次数最多的top K个IPmin_heap = []for ip, count in ip_count.items():if len(min_heap) < k:heapq.heappush(min_heap, (count, ip))elif count > min_heap[0][0]:heapq.heappop(min_heap)heapq.heappush(min_heap, (count, ip))# 输出结果while min_heap:count, ip = heapq.heappop(min_heap)print(f"IP: {ip}, Count: {count}")# 测试
top_k_ips('ips.txt', 3)
上述代码中,我们使用了Python的heapq模块来维护一个最小堆,从而高效地找到出现次数最多的top K个IP地址。
3、两个线程交替打印奇偶数字
import threadingdef print_odd_even(max_num):num = 1odd_even_lock = threading.Lock()def print_odd():nonlocal numwhile num < max_num:with odd_even_lock:if num % 2 == 1:print("Odd:", num)num += 1odd_even_lock.notify()else:odd_even_lock.wait()def print_even():nonlocal numwhile num < max_num:with odd_even_lock:if num % 2 == 0:print("Even:", num)num += 1odd_even_lock.notify()else:odd_even_lock.wait()odd_thread = threading.Thread(target=print_odd)even_thread = threading.Thread(target=print_even)odd_thread.start()even_thread.start()odd_thread.join()even_thread.join()print_odd_even(10)
在这个例子中,我们使用了一个锁(threading.Lock)和Python的with语句来简化线程同步的逻辑。两个线程“交替”获取锁,根据当前数的奇偶性来决定打印并递增数值。odd_even_lock.notify()用于唤醒等待在锁上的另一个线程,而odd_even_lock.wait()则使当前线程等待直到另一个线程调用notify()。
相关文章:

58同城面试
一、Java八股 1、ThreadLocal的底层原理是什么? ThreadLocal 在Java中用于提供线程局部变量,这些变量在每个线程中都有独立的副本,互不干扰。其底层原理可以简要描述如下: 数据存储: 每个线程中都有一个 ThreadLocalMap 的实例&…...
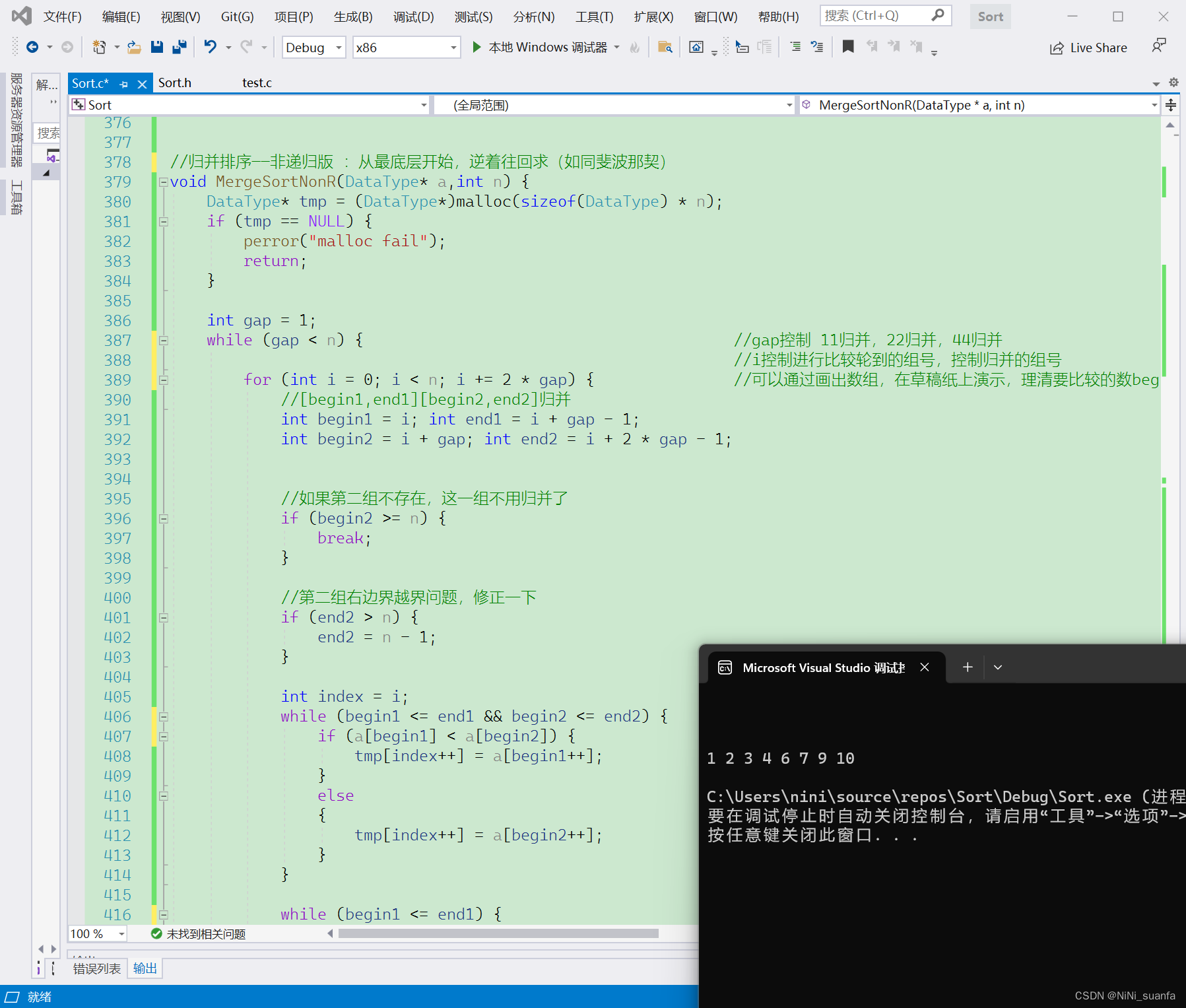
【数据结构】归并排序 的递归实现与非递归实现
归并排序 前言一、归并排序递归实现(1)归并排序的核心思路(2)归并排序实现的核心步骤(3)归并排序码源详解(4)归并排序效率分析1)时间复杂度 O(N*logN…...

Go的命令行工具开发:使用Cobra库
今天我们将深入探讨如何使用Go语言和Cobra库来开发命令行工具。 命令行工具在软件开发中有着广泛的应用,它们快速、高效,且易于自动化。 Go语言因其简洁、高效而被广泛用于命令行工具的开发。Cobra库则是Go中用于构建命令行工具的重要库之一。 为什么选…...

坚持#第420天~阿里云轻量服务器内存受AliYunDunMonito影响占用解决方法
阿里云轻量服务器内存受AliYunDunMonito影响占用解决方法,亲测有效: Mobax好卡啊,那就直接在阿里云后台操作即可,阿里云后台也可以上传文件。 Navicat mysql好卡啊,那就直接在阿里云后台最上面帮助的右边有个数据库&…...
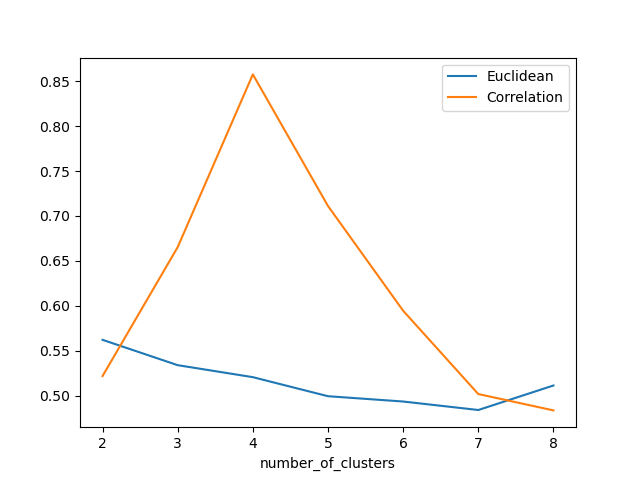
时间序列聚类的直观方法
一、介绍 我们将使用轮廓分数和一些距离度量来执行时间序列聚类实验,同时利用直观的可视化,让我们看看下面的时间序列: 这些可以被视为具有正弦、余弦、方波和锯齿波的四种不同的周期性时间序列 如果我们添加随机噪声和距原点的距离来沿 y 轴…...

vue3的reactive源码解析
reactive源码解析 总结一句: reactive是个函数。reactive函数返回了一个createReactiveObject函数,createReactiveObject又返回了一个“经new Proxy实例化”的对象。 详细介绍: 我们使用时传给reactive函数一个对象类型target,reactive又将target传给cr…...

【ElasticSearch系列-04】ElasticSearch的聚合查询操作
ElasticSearch系列整体栏目 内容链接地址【一】ElasticSearch下载和安装https://zhenghuisheng.blog.csdn.net/article/details/129260827【二】ElasticSearch概念和基本操作https://blog.csdn.net/zhenghuishengq/article/details/134121631【三】ElasticSearch的高级查询Quer…...

Redisson初始
最近的自己,一直都在做些老年的技术,没有啥升级,自己也快麻木了,自己该怎么说,那必须行动起来啊!~来来,我们一起增长自己的内功 分布式锁的最强实现: Redisson 1.概念 在介绍之前,我们要知道这个Redisson是啥? 难道就是Redis的son?(我第一次就这么认为的哈哈!) 事实也的确如…...
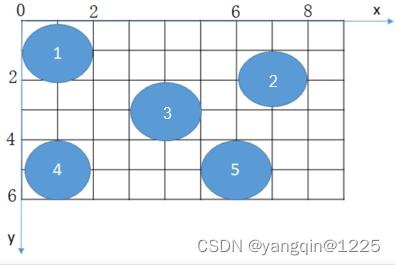
【华为OD题库-018】AI面板识别-Java
题目 Al识别到面板上有N(1<N≤100)个指示灯,灯大小一样,任意两个之间无重叠。由于AI识别误差,每次识别到的指示灯位置可能有差异,以4个坐标值描述Al识别的指示灯的大小和位置(左上角x1,y1,右下角x2.y2)。请输出先行…...
[概述] 点云滤波器
拓扑结构 点云是一种三维数据,有几种方法可以描述其空间结构,以利于展开搜索 https://blog.csdn.net/weixin_45824067/article/details/131317939 KD树 头文件:pcl/kdtree/kdtree_flann.h 函数:pcl::KdTreeFLANN 作用:…...

[笔记] 汉字判断
参考博客:如果判断一个字符是西文字符还是中文字符 结论: 汉字转数字后,会占两位字符位,两位都是负数。 参考下面代码 输入:你 输出:01 #include<bits/stdc.h> using namespace std; int main() {cha…...

Android开发笔记(三)—Activity篇
活动组件Activity 启动和结束生命周期启动模式信息传递Intent显式Intent隐式Intent 向下一个Activity发送数据向上一个Activity返回数据 附加信息利用资源文件配置字符串利用元数据传递配置信息给应用页面注册快捷方式 启动和结束 (1)从当前页面跳到新页…...
nodejs+vue+python+php在线购票系统的设计与实现-毕业设计
伴随着信息时代的到来,以及不断发展起来的微电子技术,这些都为在线购票带来了很好的发展条件。同时,在线购票的范围不断增大,这就需要有一种既能使用又能使用的、便于使用的、便于使用的系统来对其进行管理。在目前这种大环境下&a…...
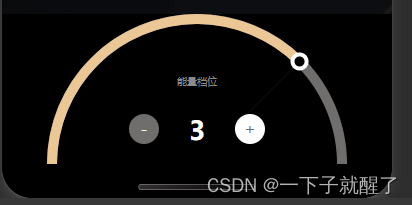
基于Taro + React 实现微信小程序半圆滑块组件、半圆进度条、弧形进度条、半圆滑行轨道(附源码)
效果: 功能点: 1、四个档位 2、可点击加减切换档位 3、可以点击区域切换档位 4、可以滑动切换档位 目的: 给大家提供一些实现思路,找了一圈,一些文章基本不能直接用,错漏百出,代码还藏着掖…...
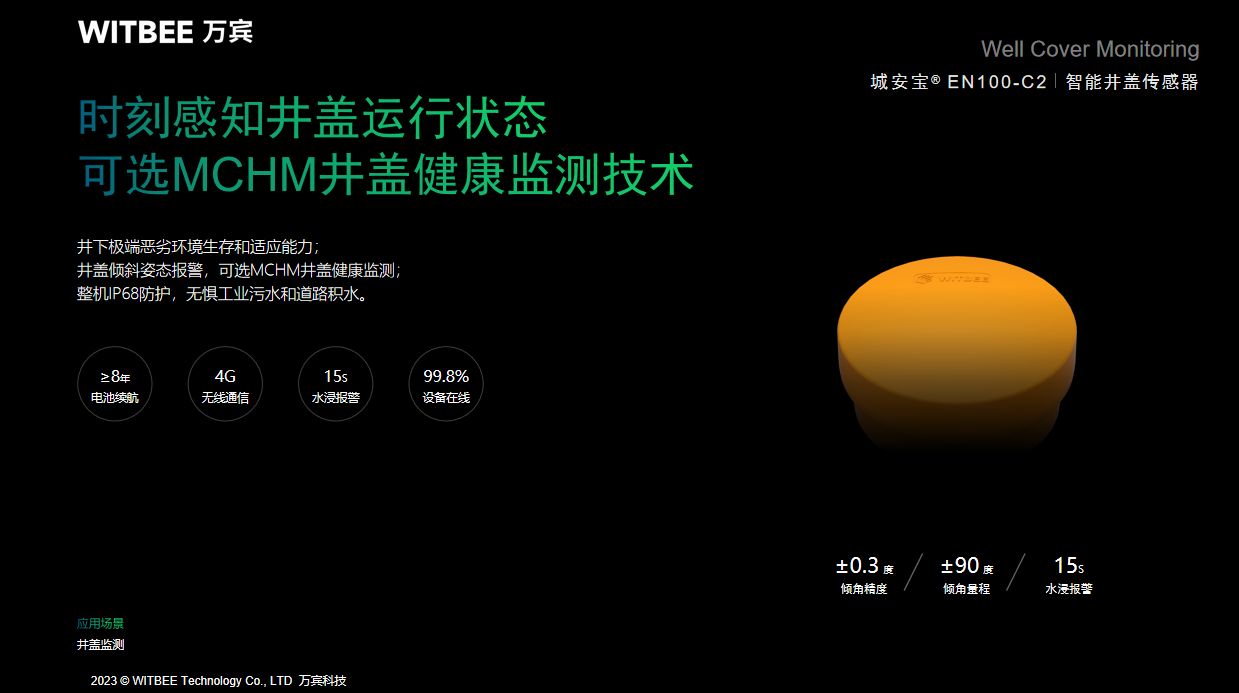
城市内涝解决方案:实时监测,提前预警,让城市更安全
城市内涝积水问题是指城市地区在短时间内遭遇强降雨后,地面积水过多,导致城市交通堵塞、居民生活不便、财产损失等问题。近年来,随着全球气候变化和城市化进程的加速,城市内涝积水问题越来越突出,成为城市发展中的一大…...

编译正点原子LINUXB报错make: arm-linux-gnueabihf-gcc:命令未找到
编译正点原子LINUX报错make: arm-linux-gnueabihf-gcc:命令未找到 1.报错内容2.解决办法3./bin/sh: 1: lzop: not found4.编译成功 1.报错内容 make: arm-linux-gnueabihf-gcc:命令未找到CHK include/config/kernel.releaseCHK include/generat…...
工地现场智慧管理信息化解决方案 智慧工地源码
智慧工地系统充分利用计算机技术、互联网、物联网、云计算、大数据等新一代信息技术,以PC端,移动端,设备端三位一体的管控方式为企业现场工程管理提供了先进的技术手段。让劳务、设备、物料、安全、环境、能源、资料、计划、质量、视频监控等…...
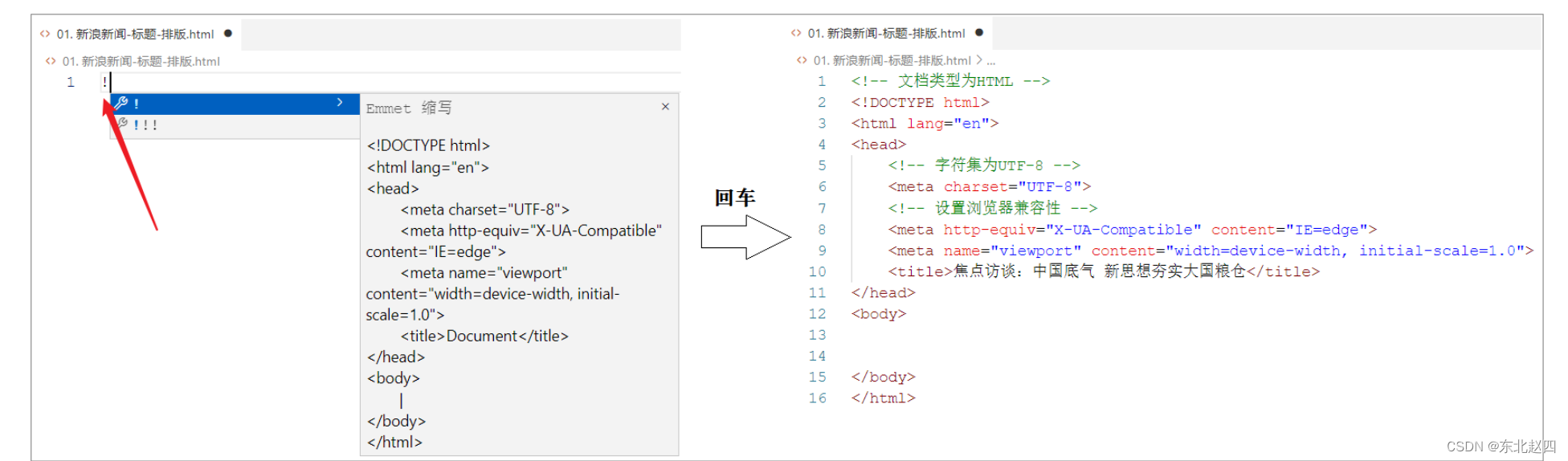
Javaweb之HTML,CSS的详细解析
2. HTML & CSS 1). 什么是HTML ? HTML: HyperText Markup Language,超文本标记语言。 超文本:超越了文本的限制,比普通文本更强大。除了文字信息,还可以定义图片、音频、视频等内容。 标记语言:由标签构成的语言…...
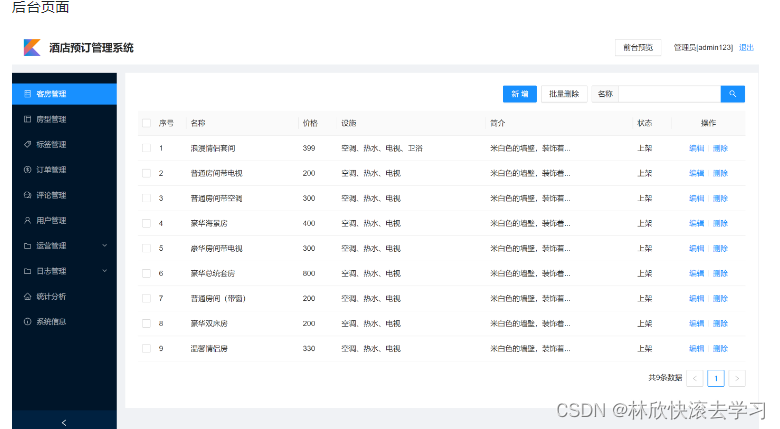
基于python+django+vue开发的酒店预订管理系统 - 毕业设计 - 课程设计
文章目录 源码下载地址项目介绍项目功能界面预览项目备注毕设定制,咨询 源码下载地址 点击这里下载源码 项目介绍 该系统是基于pythondjango开发的酒店预定管理系统。适用场景:大学生、课程作业、毕业设计。学习过程中,如遇问题可在github…...

使用vscode实现远程开发,并通过内网穿透在公网环境下远程连接
文章目录 前言1、安装OpenSSH2、vscode配置ssh3. 局域网测试连接远程服务器4. 公网远程连接4.1 ubuntu安装cpolar内网穿透4.2 创建隧道映射4.3 测试公网远程连接 5. 配置固定TCP端口地址5.1 保留一个固定TCP端口地址5.2 配置固定TCP端口地址5.3 测试固定公网地址远程 前言 远程…...
)
Qt无边框窗口毛玻璃太常见?试试保留原生标题栏的‘高级’模糊方案(附Widget跟随层实现代码)
Qt保留原生标题栏的毛玻璃效果实现方案 在Qt开发中,实现毛玻璃效果通常需要移除窗口边框,但这会牺牲系统原生窗口管理功能。本文将介绍一种创新方案,通过创建跟随主窗口的子Widget来实现毛玻璃效果,同时保留原生标题栏和边框。 1.…...

无王无帝定乾坤,来自田间第一人 海棠山铁哥持道定天下
无王无帝定乾坤 ——来自田间第一人千古以来,世人皆认为天下安定、乾坤稳固,必靠帝王集权、朝堂号令、强权治世。 王朝兴替往复,霸业起落无常,靠权柄维系的盛世终难长久,靠杀伐平定的世道终存隐患。 权力会更迭&#x…...

27考研er必备的那些学习工具!
对2027考研人来说,备考不是简单地“埋头刷题”,而是一场关于信息筛选、资源整合、时间管理和学习效率的长期战役。面对公共课、专业课、院校信息、经验帖、课程资源等海量内容,选对工具往往能让复习少走弯路。 以下这些平台和网站,…...

终极免费Redis可视化工具:Windows版RedisDesktopManager完全指南
终极免费Redis可视化工具:Windows版RedisDesktopManager完全指南 【免费下载链接】RedisDesktopManager-Windows RedisDesktopManager Windows版本 项目地址: https://gitcode.com/gh_mirrors/re/RedisDesktopManager-Windows 你是否厌倦了在命令行中操作Red…...

从信息网络到能源网络:聊聊2012年那篇关于‘能源路由器’的论文,它今天还有哪些启发?
能源路由器的十年回望:从TCP/IP隐喻到虚拟电厂的现实启示 十二年前那篇将能源网络类比TCP/IP协议的论文,在今天看来更像是一封来自过去的预言书。当我们在2023年讨论虚拟电厂和分布式能源交易时,会发现那些曾被视作天马行空的构想——能源操作…...

告别复杂设置!Sunshine v0.21.0 + Moonlight安卓版:5分钟搞定家庭局域网游戏串流
5分钟极简指南:用Sunshine和Moonlight打造家庭游戏串流系统 客厅的沙发上,手机屏幕突然变成了你的高性能游戏PC——这不是科幻电影,而是每个家庭都能实现的游戏串流体验。过去需要复杂网络知识才能搭建的串流系统,如今借助Sunshin…...

从MapReduce到Spark:深入理解reduceByKey的‘预聚合’是如何继承并超越Hadoop的Combiner的
从MapReduce到Spark:深入理解reduceByKey的‘预聚合’如何继承并超越Hadoop的Combiner 在分布式计算的演进历程中,数据处理模式的优化往往体现在对既有范式的精炼与重构。当开发者从Hadoop生态转向Spark时,reduceByKey操作符的设计哲学尤其值…...

从Neuralangelo看多分辨率哈希编码:如何用‘数值梯度’和‘渐进优化’搞定高保真3D重建?
Neuralangelo与多分辨率哈希编码:高保真3D重建的技术革命 在数字孪生、虚拟制作和文化遗产保护等领域,对真实世界进行高保真3D重建的需求从未如此迫切。传统摄影测量技术受限于硬件成本和算法瓶颈,难以平衡细节精度与处理效率。而神经渲染技术…...

AI 系统多模型路由与降级架构设计:从流量调度到无感切换的工程实践
背景 / 现象 在一个典型的 AI 应用系统中,主模型(如 GPT-4o、Claude 3.5 等)通常承担核心推理任务。但在生产环境中,主模型可能因额度耗尽、响应超时、服务不可用或突发限流等原因导致调用失败。此时,用户侧可能表现为…...

终极 Node.js 路径管理神器:module-alias 完全指南
终极 Node.js 路径管理神器:module-alias 完全指南 【免费下载链接】module-alias Register aliases of directories and custom module paths in Node 项目地址: https://gitcode.com/gh_mirrors/mo/module-alias 你是否厌倦了在 Node.js 项目中看到像 requ…...