【ES专题】ElasticSearch搜索进阶
目录
- 前言
- 阅读导航
- 前置知识
- 特别提醒
- 笔记正文
- 一、分词器详解
- 1.1 基本概念
- 1.2 分词发生的时期
- 1.3 分词器的组成
- 1.3.1 切词器:Tokenizer
- 1.3.2 词项过滤器:Token Filter
- 1.3.3 字符过滤器:Character Filter
- 1.4 倒排索引的数据结构
- <font color='red'>*二、相关性解释<font color='red'>
- 2.1 基本概念
- 2.2 相关性算法
- 2.2.1 TF-IDF
- 2.2.2 BM25
- *2.3 通过Explain API查看TF-IDF
- 2.4 Boosting Query
- 三、单字符串多字段查询
- 3.1 最佳字段查询Dis Max Query
- 3.1.1 使用最佳字段查询dis max query
- 3.1.2 通过tie_breaker参数调整
- 3.2 Multi Match Query
- 3.2.1 Best Fields:最佳字段搜索(默认)
- 3.2.2 Most Fields:使用多数字段搜索
- 3.2.3 Cross Field:跨字段搜索
- 四、ElasticSearch聚合操作
- 4.1 使用场景
- 4.2 基本语法
- 4.3 聚合的分类
- 4.4 Metric Aggregation
- 4.5 Bucket Aggregation
- 4.6 Pipeline Aggregation
- 4.7 聚合的作用范围
- 4.8 排序
- 4.8 ES聚合分析不精准原因分析
- 4.9 Elasticsearch 聚合性能优化
- 4.9.1 启用 eager global ordinals 提升高基数聚合性能
- 4.9.1 插入数据时对索引进行预排序
- 4.9.3 使用节点查询缓存
- 4.9.4 使用分片请求缓存
- 4.9.5 拆分聚合,使聚合并行化
- 学习总结
- 感谢
前言
丑话说在前头,说实在这篇笔记写的不是很好,确实很多没有实操。
阅读导航
系列上一篇文章:《【ES专题】ElasticSearch 高级查询语法Query DSL实战》
前置知识
- 理解ES的核心概念,最最重要的是【索引】和【文档】
- 理解基本的Query DSL语法
特别提醒
文中出现的term关键词即【词项】;document即【文档】。
有时候笔记做懵了可能会把他们串着用
笔记正文
一、分词器详解
稍微了解了一点ES之后,相信大家都会知道【分词】这个动作对ES的影响有多大,可以说是核心中的核心了。没有分词,没有倒排索引,也许就没有ES了。那么,什么是【分词】,什么时候【分词】,【分词】的过程是怎样的呢?
下面,我们来稍微来了解下ES中【分词】的相关组件。
1.1 基本概念
【分词】这一行为是由【分词器】完成的。
分词器官方称之为文本分析器,顾名思义,是对文本进行分析处理的一种手段,基本处理逻辑为:按照预先制定的分词规则,把原始文档分割成若干更小粒度的词项,粒度大小取决于分词器规则。
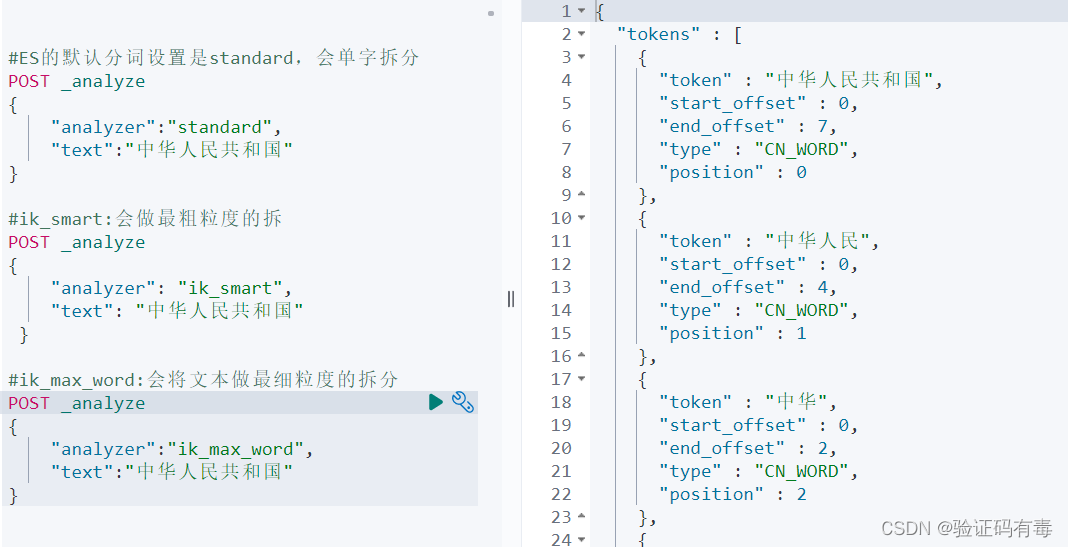
这些所谓的规则在哪里定义呢?看看你的es安装目录下的plugin/config就知道了。
1.2 分词发生的时期
分词器的处理过程发生在Index Time和Search Time两个时期。
Index Time:索引时刻。文档写入并创建倒排索引时期,其分词逻辑取决于映射参数analyzer
还记得【索引】的三个语义吧?这边的【索引】即【写入文档】
Search Time:查询时刻。搜索发生时期,对搜索的词语做分词
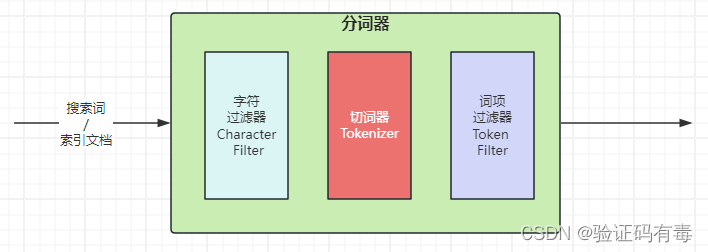
1.3 分词器的组成
- 切词器(Tokenizer):用于定义切词(分词)逻辑
- 词项过滤器(Token Filter):用于对分词之后的单个词项的处理逻辑
- 字符过滤器(Character Filter):用于对分词之前处理单个字符
注意:分词器不会对源数据造成任何影响,分词仅仅是对倒排索引或者搜索词的行为
1.3.1 切词器:Tokenizer
这个概念从名字上来理解就很清晰了。
tokenizer 是分词器的核心组成部分之一,其主要作用是分词,或称之为切词,主要用来对原始文本进行细粒度拆分。拆分之后的每一个部分称之为一个 Term(词项)。可以把切词器理解为预定义的切词规则。官方内置了很多种切词器,默认的切词器位 standard。
使用关键词是:
tokenizer
1.3.2 词项过滤器:Token Filter
词项过滤器用来处理切词完成之后的词项。例如把大小写转换,删除停用词或同义词处理等。官方同样预置了很多词项过滤器,基本可以满足日常开发的需要。当然也是支持第三方也自行开发的。
使用关键词
filter
示例输入
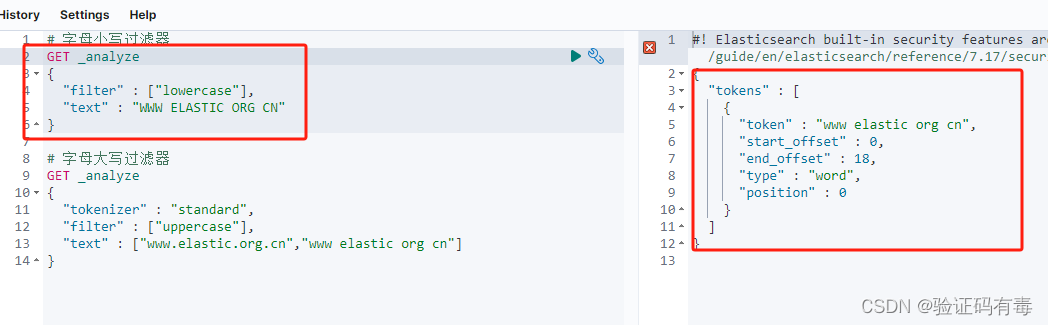
# 字母小写过滤器
GET _analyze
{"filter" : ["lowercase"],"text" : "WWW ELASTIC ORG CN"
}# 字母大写过滤器
GET _analyze
{"tokenizer" : "standard","filter" : ["uppercase"],"text" : ["www.elastic.org.cn","www elastic org cn"]
}
示例输出
停用词:概念
在ES官方中,还有一个很经典的【词项过滤器】,他就是所谓的:停用词过滤器,同义词过滤器。
在分词完成之后,应该过滤掉的词项,即停用词(停用词可以自定义)
英文停用词(english):
a, an, and, are, as, at, be, but, by, for, if, in, into, is, it, no, not, of, on, or, such, that, the, their, then, there, these, they, this, to, was, will, with
中文停用词:的,啊,嗯,咦等语气词
停用词:示例输入
# 使用停用词过滤文本
GET _analyze
{"tokenizer": "standard", "filter": ["stop"],"text": ["What are you doing"]
}
当然,还可以自定义停用词:
### 自定义 filter
DELETE test_token_filter_stop
PUT test_token_filter_stop
{"settings": {"analysis": {"filter": {"my_filter": {"type": "stop","stopwords": ["www"],"ignore_case": true}}}}
}
GET test_token_filter_stop/_analyze
{"tokenizer": "standard", "filter": ["my_filter"], "text": ["What www WWW are you doing"]
}
同义词:概念
同义词定义规则:
a, b, c => d:这种方式,a、b、c 会被 d 代替a, b, c, d:这种方式下,a、b、c、d 是等价的
同义词:示例输入
# 定义good, nice的同义词excellent
PUT test_token_filter_synonym
{"settings": {"analysis": {"filter": {"my_synonym": {"type": "synonym","synonyms": [ "good, nice => excellent" ] //good, nice, excellent}}}}
}
GET test_token_filter_synonym/_analyze
{"tokenizer": "standard", "filter": ["my_synonym"], "text": ["good"]
}
1.3.3 字符过滤器:Character Filter
分词之前的预处理,过滤无用字符
使用关键词
char_filter
使用语法
PUT <index_name>
{"settings": {"analysis": {"char_filter": {"my_char_filter": {"type": "<char_filter_type>"}}}}
}
type:使用的字符过滤器类型名称,可配置以下值
- html_strip
- mapping
- pattern_replace
示例一:HTML 标签过滤器
HTML标签过滤器(HTML Strip Character Filter)会去除 HTML 标签和转义 HTML 元素,如 、&
PUT test_html_strip_filter
{"settings": {"analysis": {"char_filter": {"my_char_filter": {"type": "html_strip", // html_strip 代表使用 HTML 标签过滤器"escaped_tags": [ // 当前仅保留 a 标签 "a"]}}}}
}
GET test_html_strip_filter/_analyze
{"tokenizer": "standard", "char_filter": ["my_char_filter"],"text": ["<p>I'm so <a>happy</a>!</p>"]
}
注意:参数escaped_tags指示需要保留的 html 标签
示例二:字符映射过滤器
字符映射过滤器(Mapping Character Filter),通过定义映射替换为规则,把特定字符替换为指定字符。比如将某些关键词替换为*
PUT test_html_strip_filter
{"settings": {"analysis": {"char_filter": {"my_char_filter": {"type": "mapping", // mapping 代表使用字符映射过滤器"mappings": [ // 数组中规定的字符会被等价替换为 => 指定的字符"滚 => *","垃 => *","圾 => *"]}}}}
}
GET test_html_strip_filter/_analyze
{//"tokenizer": "standard", "char_filter": ["my_char_filter"],"text": "你就是个垃圾!滚"
}
示例三:正则替换过滤器
正则替换过滤器:Pattern Replace Character Filter。跟前面的字符映射没太大区别,只不过这里使用了正则表达式来匹配值
PUT text_pattern_replace_filter
{"settings": {"analysis": {"char_filter": {"my_char_filter": {"type": "pattern_replace", // pattern_replace 代表使用正则替换过滤器 "pattern": """(\d{3})\d{4}(\d{4})""", // 正则表达式"replacement": "$1****$2"}}}}
}
GET text_pattern_replace_filter/_analyze
{"char_filter": ["my_char_filter"],"text": "您的手机号是18868686688"
}
1.4 倒排索引的数据结构
关于倒排索引的数据结构其实在一开始介绍的时候已经讲过了,只不过是以表格的形式。为了让大家有个更清晰的认知,这边再来一张网上截图给大伙看看。
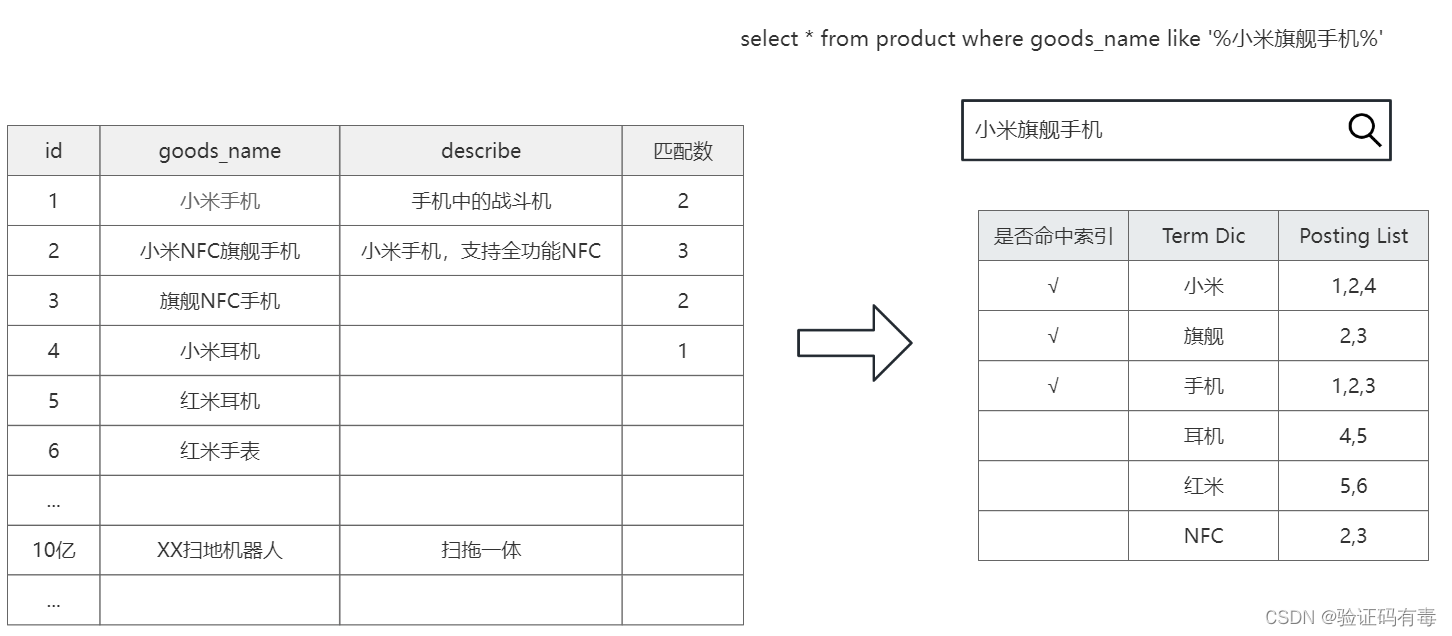
如上图所示,我们在goods产品表中存储了很多商品数据。ES会在这些数据写入的时候为他们建立【右边】所示的倒排索引。
当用户在电商网站搜索【小米旗舰手机】的时候,会对搜索词做【分词】处理,接着在倒排索引表中匹配查询。
为了进一步提升索引的效率,ES 在 term 的基础上利用 term 的前缀或者后缀构建了 term index, 用于对 term 本身进行索引(索引的索引),ES 实际的索引结构如下图所示:
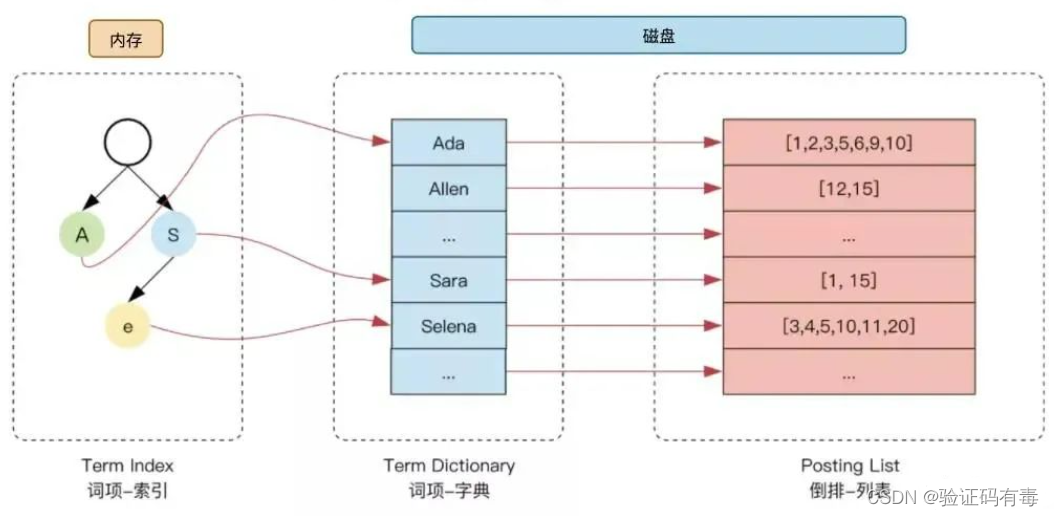
这样当我们去搜索某个关键词时,ES 首先根据它的【前缀或者后缀】迅速缩小关键词的在 term dictionary 中的范围,大大减少了磁盘IO的次数。
词项-字典的类型有多种,主要如下:
- 单词词典(Term Dictionary) :记录所有文档的单词,记录单词到倒排列表的关联关系
- 常用字典数据结构:https://www.cnblogs.com/LBSer/p/4119841.html
- 倒排列表(Posting List):记录了单词对应的文档结合,由倒排索引项组成。倒排索引项如下:
- 文档ID
- 词频TF–该单词在文档中出现的次数,用于相关性评分
- 位置(Position)-单词在文档中分词的位置。用于短语搜索(match phrase query)
- 偏移(Offset)-记录单词的开始结束位置,实现高亮显示
用伪代码表示如下:
class 倒排索引表PostingList {String 文档id;Integer 词频;Integer 位置position;Integer 起始偏移量startOffset;Integer 结束偏移量endOffset;
}
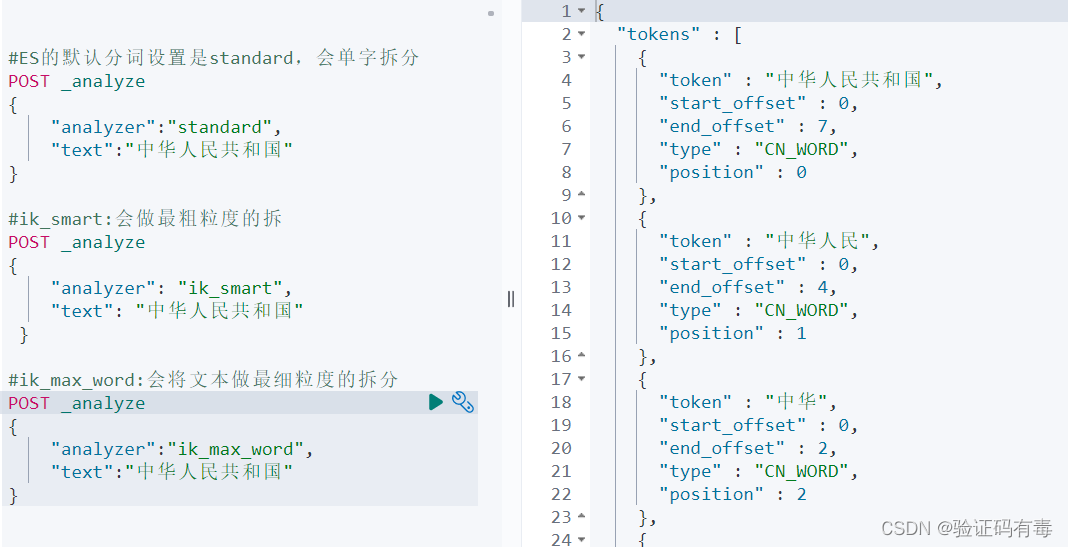
Elasticsearch 的JSON文档中的每个字段,都有自己的倒排索引。当然也可以指定对某些字段不做索引,这样做有如下优缺点:
- 优点:节省存储空间
- 缺点:字段无法被搜索
*二、相关性解释
我们前面学习【全文检索】的时候说过:全文检索查询旨在基于【相关性】搜索和匹配文本数据的。由此可见,这个相关性对我们ES有多重要。
我们在使用百度查询的时候,我想我们通常关心的正是【搜索结果的相关性】。相关性通常关注的内容如下:
- 是否可以找到所有相关的内容
- 有多少不相关的内容被返回了
- 文档的打分是否合理
- 结合业务需求,平衡结果排名
那么什么是【相关性】呢?
2.1 基本概念
搜索的相关性算分(打分),描述了一个文档和查询语句匹配的程度。ES 会对每个匹配查询条件的结果(文档)进行打分_score。打分的本质是排序,需要把最符合用户需求的文档排在前面。
注意,打分的目标是【文档】,不是【索引】;但是【打分】的最小粒度是【文档中的字段】。即:每次打分都是先对【文档中的字段】打分,然后累加起来,才是【文档】的打分。
比如我们有如下倒排索引表:
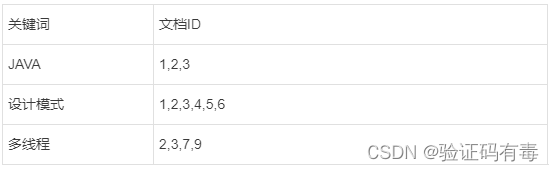
显而易见,这时候我们去查询【JAVA多线程设计模式】的时候,文档id为2,3的文档的算分更高。
2.2 相关性算法
ES 5之前,默认的相关性算分采用TF-IDF,现在采用BM 25。但由于BM25是对TF-IDF算法的改进,所以无论如何还是要先介绍一下TF-IDF。
2.2.1 TF-IDF
TF-IDF,全称:Term frequency–inverse document frequency,词频-逆文档频率。是一种用于信息检索与数据挖掘的常用加权技术,被认为是信息检索领域最重要的发明,除了在信息检索,在文献分类和其他相关领域有着非常广泛的应用。
对于TF-IDF一个比较恰当的解释如下:
- 某个词项在某个【文档】中出现的频率越高,那么该字词对当前文档而言,就越重要,它可能会是文章的关键词
- 若词项在整个【索引】中出现的频率越高,那么字词的重要性就越低,如
我们这个词项在文章article索引中
Luccen中TF-IDF评分公式
TF-IDF即是两者相乘:【词频】*【逆文档频率】,具体公式如下:
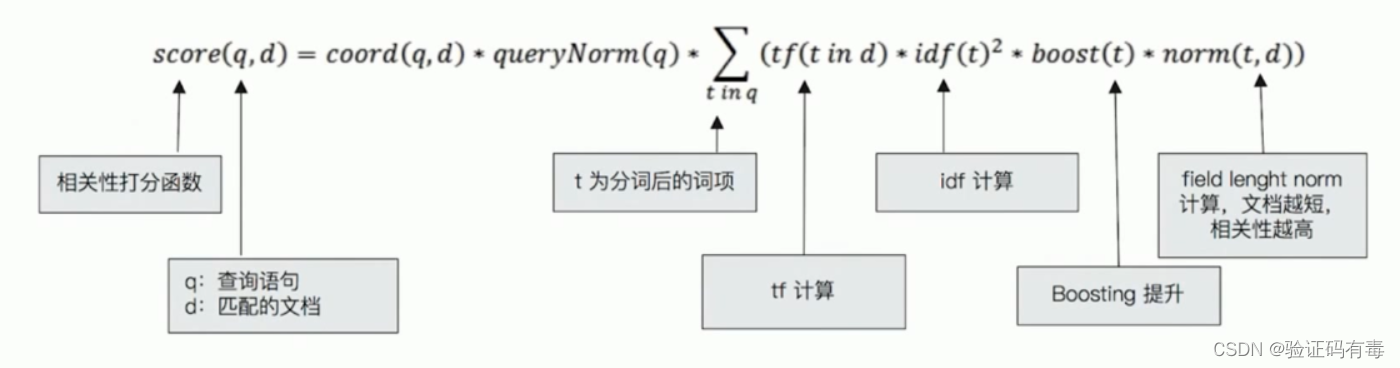
看了上面的公式是不是一脸懵逼?哈,其实对于没有中文解释的函数我们不需要关心了,但是可以适当猜一下。另外,不管上面的公式怎样,但是我们可以得出一个结论:score=A*B*C*D,那么A/B/C/D越大,score越大。即:score与A/B/C/D正相关增长。
公式解读(注意函数的入参)
q:文中出现的q即query的首字母,表示搜索的文本t:文中出现的t即term词项的首字母d:文中出现的d即document文档的首字母coord(q, d):协调因子。其值取决于查询中【词项】的数量和文档中匹配的【词项】的数量queryNorms(q, d):进行分数矫正,使最大最小值处于一个较为合理的区间,让其差距不是很大
下面才是核心函数
tf(t in d):tf即TF函数,它是一个函数,计算词项在某文档中的词频。它认为:【检索词在文档中出现的频率越高,相关性也越高】。计算公式如下:
词频(TF) = 词项在文档中出现的次数 / 文档的总词数
idf(t)^2:idf即IDF,它是一个函数,计算词项在整个索引中逆向文本频率。它认为:【检索词在索引中出现的频率越高,相关性越低】。计算公式如下:
逆向文本频率(IDF)= log (索引中文档数量 / (包含该词的文档数+1))
boost(t):ES提供给我们的缩放函数,相当于是提供了一个能让我们干预评分结果的窗口,它是作用在【文档中的字段】上的。后面【2.4 Boosting Query】会介绍norm(t, d):字段长度归一值( field-length norm),很拗口。它认为【检索词出现在长度较短的字段中时,比出现在长度较长的字段中时的相关性要更高】
词项【Java】如果出现在长度为10的字段title上,比出现在长度为100的字段content上,相关性要高
公式(注意,是字段,不是文档,也不是索引):字段长度归一值 = 1 / (所在字段总词数的平方)
还有一个很重要的符号以及规则
还有一个很重要的符号以及规则
还有一个很重要的符号以及规则
公式中有个符号大家可能比较陌生,它是累加的意思。
如何理解这个累加?那就是:
- 一个搜索词匹配文档的分数
=每个【词项】在文档的得分总和 (累加) - 【词项】在文档中得分
=【词项】在文档每个【字段】的得分总和
实在搞不懂结合【2.4 Boosting Query】的示例分析理解下
以上三个因素——词频(term frequency)、逆向文本频率(inverse document frequency)和字段长度归一值(field-length norm),就是在索引时打分的重要组成部分!当然这个三个因素会在索引文档的时候一并记录进去。
2.2.2 BM25
BM25 就是对 TF-IDF 算法的改进,对于 TF-IDF 算法,TF(t) 部分的值越大,整个公式返回的值就会越大。BM25 就针对这点进行来优化,随着 TF(t) 的逐步加大,该算法的返回值会趋于一个数值。这么说可能有点抽象,来个图看看就知道了
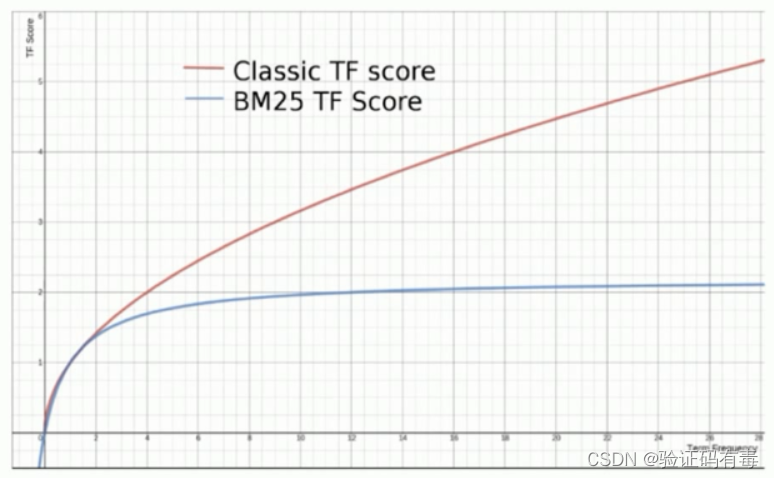
看图说话,褐色的为TF-IDF的变化增长曲线;蓝色的为BM25的增长曲线。
BM 25的公式
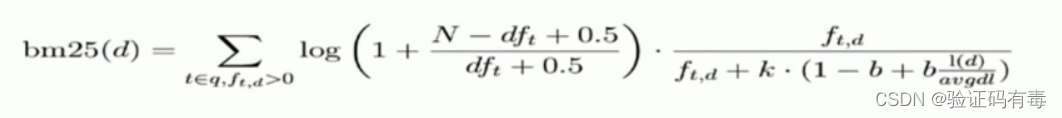
这个我就不过多解读了,没必要,你知道BM25改进的点是什么就好了。理解了TF-IDF基本就能搞懂ES的【打分】原理了。另外也要记住以下几点:
- 优化后的公式其实可以看成是
score = tf * idf * boost了。在BM25算法中削弱了norms函数的作用,默认值为0.75 - 这个
BM25才是目前使用的打分公式 - 上面的
k叫做饱和度,默认1.2 - 上面的
N为【索引总文档数】(曾出现在IDF中) - 在
BM25算法中,boost函数公式为基数 * 缩放因数,基数默认值为2.2,缩放因子默认为1,后面我们修改的值实际上为后面的缩放因子
公式简记:score = 字段累加(词频 * 逆文档频率 * boost)
公式简记:score = 字段累加(词频 * 逆文档频率 * boost)
公式简记:score = 字段累加(词频 * 逆文档频率 * boost)
*2.3 通过Explain API查看TF-IDF
不同于Mysql的explain用来查看查询语句的性能分析,ES提供的explain主要是用来查询ES更关注的相关性,即TF-IDF的三项因素。
关键词:
explain
示例数据:
1)首先批量写入一些测试数据,注意它们的内容content
PUT /test_score/_bulk
{"index":{"_id":1}}
{"content":"we use Elasticsearch to power the search"}
{"index":{"_id":2}}
{"content":"we like elasticsearch"}
{"index":{"_id":3}}
{"content":"Thre scoring of documents is caculated by the scoring formula"}
{"index":{"_id":4}}
{"content":"you know,for search"}
示例输入:
2)再来做一下简单的查询:在content上全文检索elasticsearch这个值
GET /test_score/_search
{"explain": true, "query": {"match": {"content": "elasticsearch"}}
}
我们稍微分析一下查询的过程:
elasticsearch无法进一步分词,所以搜索的词项是elasticsearch- 在文档的
content字段搜索elasticsearch,只有id=1和id=2的文档会被搜索到 - 再然后【打分】
explain给我们分析整个打分过程
示例输出:
#! Elasticsearch built-in security features are not enabled. Without authentication, your cluster could be accessible to anyone. See https://www.elastic.co/guide/en/elasticsearch/reference/7.17/security-minimal-setup.html to enable security.
{"took" : 17,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 2,"relation" : "eq"},"max_score" : 0.8713851,"hits" : [{"_shard" : "[test_score][0]","_node" : "MTTjaVXrS0qu3V7iOYC3kA","_index" : "test_score","_type" : "_doc","_id" : "2","_score" : 0.8713851,"_source" : {"content" : "we like elasticsearch"},"_explanation" : {"value" : 0.8713851,"description" : "weight(content:elasticsearch in 1) [PerFieldSimilarity], result of:","details" : [{"value" : 0.8713851,"description" : "score(freq=1.0), computed as boost * idf * tf from:","details" : [{"value" : 2.2,"description" : "boost","details" : [ ]},{"value" : 0.6931472,"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:","details" : [{"value" : 2,"description" : "n, number of documents containing term","details" : [ ]},{"value" : 4,"description" : "N, total number of documents with field","details" : [ ]}]},{"value" : 0.5714286,"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:","details" : [{"value" : 1.0,"description" : "freq, occurrences of term within document","details" : [ ]},{"value" : 1.2,"description" : "k1, term saturation parameter","details" : [ ]},{"value" : 0.75,"description" : "b, length normalization parameter","details" : [ ]},{"value" : 3.0,"description" : "dl, length of field","details" : [ ]},{"value" : 6.0,"description" : "avgdl, average length of field","details" : [ ]}]}]}]}},{"_shard" : "[test_score][0]","_node" : "MTTjaVXrS0qu3V7iOYC3kA","_index" : "test_score","_type" : "_doc","_id" : "1","_score" : 0.6489038,"_source" : {"content" : "we use Elasticsearch to power the search"},"_explanation" : {"value" : 0.6489038,"description" : "weight(content:elasticsearch in 0) [PerFieldSimilarity], result of:","details" : [{"value" : 0.6489038,"description" : "score(freq=1.0), computed as boost * idf * tf from:","details" : [{"value" : 2.2,"description" : "boost","details" : [ ]},{"value" : 0.6931472,"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:","details" : [{"value" : 2,"description" : "n, number of documents containing term","details" : [ ]},{"value" : 4,"description" : "N, total number of documents with field","details" : [ ]}]},{"value" : 0.42553192,"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:","details" : [{"value" : 1.0,"description" : "freq, occurrences of term within document","details" : [ ]},{"value" : 1.2,"description" : "k1, term saturation parameter","details" : [ ]},{"value" : 0.75,"description" : "b, length normalization parameter","details" : [ ]},{"value" : 7.0,"description" : "dl, length of field","details" : [ ]},{"value" : 6.0,"description" : "avgdl, average length of field","details" : [ ]}]}]}]}}]}
}感兴趣的朋友可以自己根据公式算一算分数,哈哈
2.4 Boosting Query
Boosting是控制相关度的一种手段,是ES提供给我们的【一个能干预评分结果】的窗口。可以通过指定字段的boost值影响查询结果。很显然,boost的值对结果有如下影响:
- 当
boost > 1时,打分的权重相关性提升 - 当
0 < boost <1时,打分的权重相关性降低 - 当
boost <0时,贡献负分
boost函数公式为基数 * 缩放因数,基数默认值为2.2,缩放因子默认为1,我们修改的值实际上为后面的缩放因子
应用场景
希望包含了某项内容的结果不是不出现,而是排序靠后
示例数据:
1)首先还是先插入一些示例数据。注意title和content,下面两条记录的title跟content内容刚好互换
POST /blogs/_bulk
{"index":{"_id":1}}
{"title":"Apple iPad","content":"Apple iPad,Apple iPad"}
{"index":{"_id":2}}
{"title":"Apple iPad,Apple iPad","content":"Apple iPad"}
示例查询输入:
2)然后做一下简单的查询,在字段title和content上查询apple,ipad。使用复合查询的bool-should,表示只要有一个符合条件即可返回
GET /blogs/_search
{"query": {"bool": {"should": [{"match": {"title": {"query": "apple,ipad"}}},{"match": {"content": {"query": "apple,ipad"}}}]}}
}
你们猜上面的搜索,两个文档的得分是否一样?哈,其实稍微运算一下就可以看出来,是一样的。根据【简记版公式】,apple跟ipad词项的得分如下:
apple词项得分
= 在字段title上的得分 + 在content字段上的得分
= title(词频 * 逆文档频率 * boost) + content(词频 * 逆文档频率 * boost)
= title[ (词项在文档出现的次数 / 文档的总次数) * log(索引文档总数/(包含该词项的文档数+1)) * boost ] + content[ (词项在文档出现的次数 / 文档的总次数) * log(索引文档总数/(包含该词项的文档数+1)) * boost ]
= title[(3/6) + (2/(2+1)) * 2.2 ] + content[(3/6) + (2/(2+1)) * 2.2 ]
ipad词项得分
= 在字段title上的得分 + 在content字段上的得分
= title(词频 * 逆文档频率 * boost) + content(词频 * 逆文档频率 * boost)
= title[ (词项在文档出现的次数 / 文档的总次数) * log(索引文档总数/(包含该词项的文档数+1)) * boost ] + content[ (词项在文档出现的次数 / 文档的总次数) * log(索引文档总数/(包含该词项的文档数+1)) * boost ]
= title[(3/6) + (2/(2+1)) * 2.2 ] + content[(3/6) + (2/(2+1)) * 2.2 ]
示例查询输出:
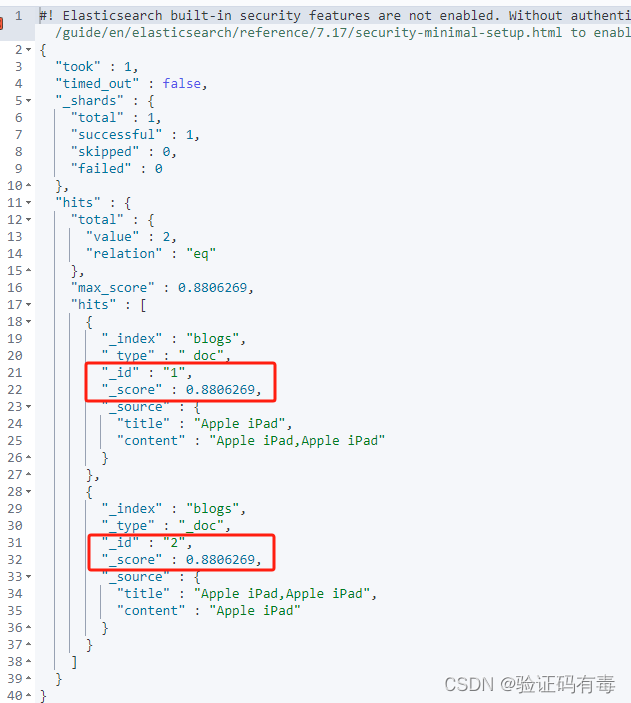
看,得分都是0.8806269。但是我稍微改一下,得分就变得不一样了。
修改后查询输入:注意,修改了content字段上的boost缩放因子
GET /blogs/_search
{"query": {"bool": {"should": [{"match": {"title": {"query": "apple,ipad","boost": 1}}},{"match": {"content": {"query": "apple,ipad","boost": 5}}}]}}
}
修改后示例输出:
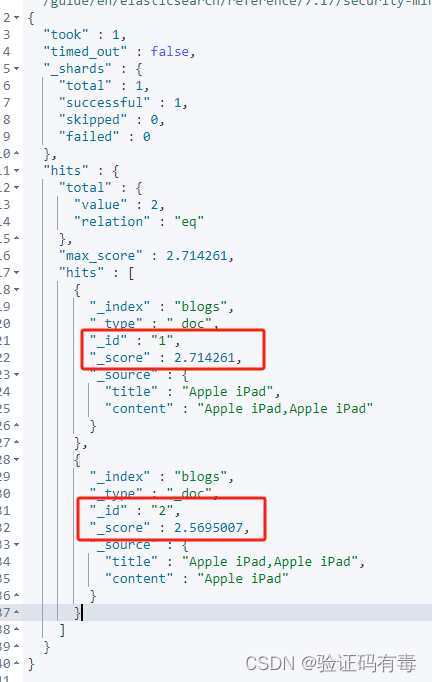
案例:要求苹果公司的产品信息优先展示
POST /news/_bulk
{"index":{"_id":1}}
{"content":"Apple Mac"}
{"index":{"_id":2}}
{"content":"Apple iPad"}
{"index":{"_id":3}}
{"content":"Apple employee like Apple Pie and Apple Juice"}GET /news/_search
{"query": {"bool": {"must": {"match": {"content": "apple"}}}}
}
利用must not排除不是苹果公司产品的文档
GET /news/_search
{"query": {"bool": {"must": {"match": {"content": "apple"}},"must_not": {"match":{"content": "pie"}}}}
}
但是生产环境有时候不能这么简单粗暴的直接排除掉的。所以这个时候可以考虑boosting query的negative_boost。
- negative_boost 对 negative部分query生效
- 计算评分时,boosting部分评分不修改,negative部分query乘以negative_boost值
- negative_boost取值:0-1.0,举例:0.3
通过negative_boost反向取一个分数
GET /news/_search
{"query": {"boosting": {"positive": {"match": {"content": "apple"}},"negative": {"match": {"content": "pie"}},"negative_boost": 0.2}}
}
三、单字符串多字段查询
【单字符串多字段】指的是一种查询方式,它有三种不同的查询策略:
最佳字段(Best Fields):在多个字段上查询的时候,选择评分最高的字段(默认是累加)多数字段(Most Fields):处理英文内容时的一种常见的手段是,在主字段( English Analyzer),抽取词干,加入同义词,以匹配更多的文档。相同的文本,加入子字段(Standard Analyzer),以提供更加精确的匹配。其他字段作为匹配文档提高相关度的信号,匹配字段越多则越好混合字段(Cross Fields):对于某些实体,例如人名,地址,图书信息。需要在多个字段中确定信息,单个字段只能作为整体的一部分。希望在任何这些列出的字段中找到尽可能多的词
3.1 最佳字段查询Dis Max Query
Dis Max Query:将搜索词任意词项与查询匹配的文档作为结果返回,采用字段上最匹配的评分最终评分返回max(a,b) (属于复合查询的一种,既然是复合查询,那肯定存在复合查询的关键词)
关键词:
dis_max
示例数据:
1)先准备数据
DELETE /blogs
PUT /blogs/_doc/1
{"title": "Quick brown rabbits","body": "Brown rabbits are commonly seen."
}PUT /blogs/_doc/2
{"title": "Keeping pets healthy","body": "My quick brown fox eats rabbits on a regular basis."
}
2)然后做一个简单的多字段查询,查询内容如下:
POST /blogs/_search
{"query": {"bool": {"should": [{ "match": { "title": "Brown fox" }},{ "match": { "body": "Brown fox" }}]}}
}
正常来说,id=2的文档才是我们最关注的,换句话来说它的得分应该是我们预想中比较高的,毕竟它的body里面就有我们要搜索的brown fox完整的词项。但是查询出来的结果可能有点出乎大家意料,为什么?
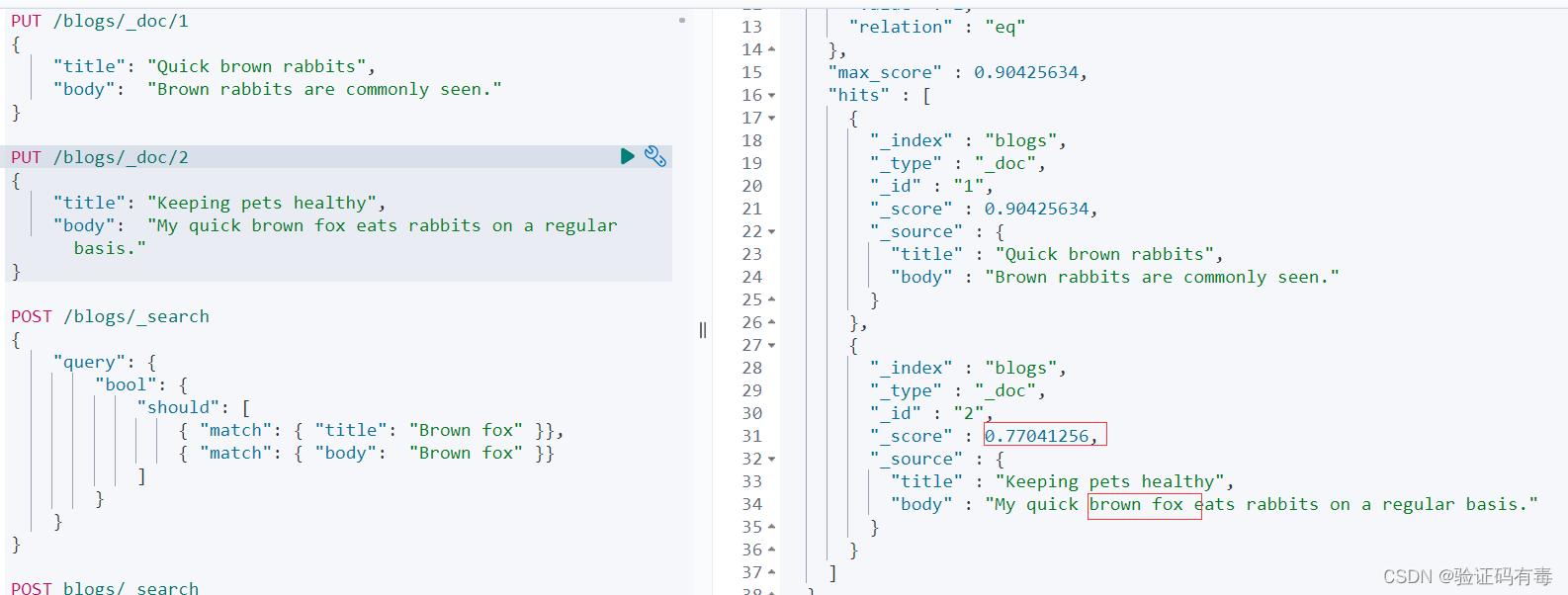
其实也不难理解。因为搜索词会被拆分成brown跟fox词项,然而id=1的title跟body的都含有brown词项,所以,在评分的过程中,id=1的得分就可能比id=2的高了。
总的来说,结果之所以出乎意料的原因还是没有认识到title跟body是竞争关系,不应该将分数简单叠加,而是应该找到单个最佳匹配的字段的评分。
3.1.1 使用最佳字段查询dis max query
示例输入数据:
POST /blogs/_search
{"query": {"dis_max": {"queries": [{ "match": { "title": "Brown fox" }},{ "match": { "body": "Brown fox" }}]}}
}
示例输出数据:
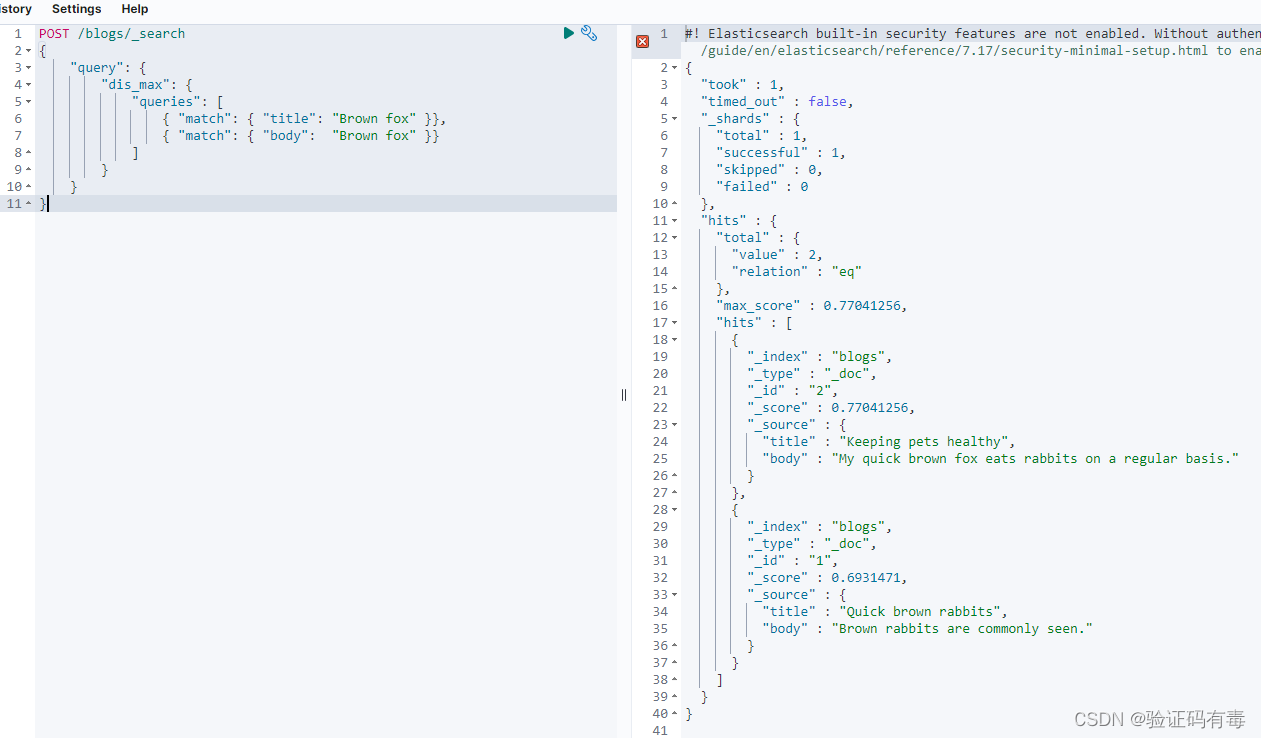
上述例子是把title跟body当作了竞争关系,只能二选一。但有时候,我们又希望是【主从关系】,而不是完全把另一个字段抛弃掉,这个时候就可以通过tie_breaker参数调整
3.1.2 通过tie_breaker参数调整
Tier Breaker是一个介于0-1之间的浮点数。0代表使用最佳匹配;1代表所有语句同等重要。
- 获得最佳匹配语句的评分_score 。
- 将其他匹配语句的评分与tie_breaker相乘
- 对以上评分求和并规范化
最终得分=最佳匹配字段+其他匹配字段*tie_breaker
POST /blogs/_search
{"query": {"dis_max": {"queries": [{ "match": { "title": "Brown fox" }},{ "match": { "body": "Brown fox" }}],"tie_breaker": 0.1}}
}
3.2 Multi Match Query
这个在上一篇文章已经稍微提过了,这边说到了单字符多字段查询了,就再说一下吧。因为它本质上就是属于【单字符多字段查询】。
Multi Match Query有三种不同的策略,分别是:Best Fields、Most Fields、Cross Fields。
3.2.1 Best Fields:最佳字段搜索(默认)
嘿嘿嘿,虽然这个搜索改了个名字,但是从意思上不难看出来,这不就是前面的Dis Max Query吗?是的,一样一样的。
best_fields策略获取最佳匹配字段的得分, final_score = max(其他匹配字段得分, 最佳匹配字段得分)
采用best_fields查询,并添加参数tie_breaker=0.1,可以起到调控的效果,final_score = 其他匹配字段得分 * 0.1 + 最佳匹配字段得分
关键字:
multi_match、tie_breaker、best_fields、most_fields、cross_fields
示例查询输入:
这里直接演示tie_breaker了,不加的时候跟dis_max没啥两样,就不演示了。使用示例如下:
POST /blogs/_search
{"query": {"multi_match": {"type": "best_fields","query": "Brown fox","fields": ["title","body"],"tie_breaker": 0.2}}
}
输出也不贴了,这里最关键的还是理解tie_breaker对打分的影响
3.2.2 Most Fields:使用多数字段搜索
most_fields策略获取全部匹配字段的累计得分(综合全部匹配字段的得分),这个不就是默认的评分公式嘛
POST /blogs/_search
{"query": {"multi_match": {"type": "best_fields","query": "Brown fox","fields": ["title","body"],"tie_breaker": 0.2}}
}
3.2.3 Cross Field:跨字段搜索
搜索内容在多个字段中都显示,类似bool + must/should组合。怎么理解呢?(em…还记得bool关键词的must/should有什么特点吧?不记得翻我上一篇文章咯)
是因为cross_fileds支持operator关键词,所以筛选记录的逻辑,在operator=and的时候跟bool=must一样,即字段上都要包含关键字;operator=or的时候跟bool=should一样,即字段中至少有一个包含关键字
示例数据:
DELETE /address
PUT /address
{"settings" : {"index" : {"analysis.analyzer.default.type": "ik_max_word"}}
}PUT /address/_bulk
{ "index": { "_id": "1"} }
{"province": "湖南","city": "长沙"}
{ "index": { "_id": "2"} }
{"province": "湖南","city": "常德"}
{ "index": { "_id": "3"} }
{"province": "广东","city": "广州"}
{ "index": { "_id": "4"} }
{"province": "湖南","city": "邵阳"}
示例查询输入一:operator=and
GET /address/_search
{"query": {"multi_match": {"query": "湖南常德","type": "cross_fields","operator": "and", "fields": ["province","city"]}}
}# 上面等价于下面的查询
GET /address/_search
{"query": {"bool": {"must": [{"match": {"province": "湖南常德"}},{"match": {"city": "湖南常德"}}]}}
}
示例查询输入二:operator=or
GET /address/_search
{"query": {"multi_match": {"query": "湖南常德","type": "cross_fields","operator": "or", "fields": ["province","city"]}}
}# 上面等价于下面的查询
GET /address/_search
{"query": {"bool": {"should": [{"match": {"province": "湖南常德"}},{"match": {"city": "湖南常德"}}]}}
}
四、ElasticSearch聚合操作
Elasticsearch除搜索以外,提供了针对ES 数据进行统计分析的功能。聚合(aggregations)可以让我们极其方便的实现对数据的统计、分析、运算。例如:
- 什么品牌的手机最受欢迎?
- 这些手机的平均价格、最高价格、最低价格?
- 这些手机每月的销售情况如何?
4.1 使用场景
聚合查询可以用于各种场景,比如商业智能、数据挖掘、日志分析等等。
- 电商平台的销售分析:统计每个地区的销售额、每个用户的消费总额、每个产品的销售量等,以便更好地了解销售情况和趋势。
- 社交媒体的用户行为分析:统计每个用户的发布次数、转发次数、评论次数等,以便更好地了解用户行为和趋势,同时可以将数据按照地区、时间、话题等维度进行分析。
- 物流企业的运输分析:统计每个区域的运输量、每个车辆的运输次数、每个司机的行驶里程等,以便更好地了解运输情况和优化运输效率。
- 金融企业的交易分析:统计每个客户的交易总额、每个产品的销售量、每个交易员的业绩等,以便更好地了解交易情况和优化业务流程。
- 智能家居的设备监控分析:统计每个设备的使用次数、每个家庭的能源消耗量、每个时间段的设备使用率等,以便更好地了解用户需求和优化设备效能。
4.2 基本语法
聚合查询的语法结构与其他查询相似,通常包含以下部分:
- 查询条件:指定需要聚合的文档,可以使用标准的 Elasticsearch 查询语法,如 term、match、range 等等。
- 聚合函数:指定要执行的聚合操作,如 sum、avg、min、max、terms、date_histogram 等等。每个聚合命令都会生成一个聚合结果。
- 聚合嵌套:聚合命令可以嵌套,以便更细粒度地分析数据。
GET <index_name>/_search
{"aggs": {"<aggs_name>": { // 聚合名称需要自己定义"<agg_type>": {"field": "<field_name>"}}}
}
- aggs_name:聚合函数的名称,需要自定义
- agg_type:聚合种类,比如是桶聚合(terms)或者是指标聚合(avg、sum、min、max等)
- field_name:字段名称或者叫域名。
4.3 聚合的分类
Metric Aggregation:—些数学运算,可以对文档字段进行统计分析,类比Mysql中的 min(), max(), sum() 操作。
SELECT MIN(price), MAX(price) FROM products
#Metric聚合的DSL类比实现:
{"aggs":{"avg_price":{"min":{"field":"price"}}}
}
Bucket Aggregation: 一些满足特定条件的文档的集合放置到一个桶里,每一个桶关联一个key,类比Mysql中的group by操作
SELECT size COUNT(*) FROM products GROUP BY size
#bucket聚合的DSL类比实现:
{"aggs": {"by_size": {"terms": {"field": "size"}}
}
Pipeline Aggregation:对其他的聚合结果进行二次聚合
4.4 Metric Aggregation
- 单值分析︰只输出一个分析结果
- min, max, avg, sum
- Cardinality(类似distinct Count)
- 多值分析:输出多个分析结果
- stats(统计), extended stats
- percentile (百分位), percentile rank
- top hits(排在前面的示例)
查询员工的最低最高和平均工资:关键词【max】、【min】、【avg】
#多个 Metric 聚合,找到最低最高和平均工资
POST /employees/_search
{"size": 0, "aggs": {"max_salary": {"max": {"field": "salary"}},"min_salary": {"min": {"field": "salary"}},"avg_salary": {"avg": {"field": "salary"}}}
}
对salary进行统计:关键词【stats】
# 一个聚合,输出多值
POST /employees/_search
{"size": 0,"aggs": {"stats_salary": {"stats": {"field":"salary"}}}
}
cardinate对搜索结果去重:关键词【cardinality】
POST /employees/_search
{"size": 0,"aggs": {"cardinate": {"cardinality": {"field": "job.keyword"}}}
}
4.5 Bucket Aggregation
按照一定的规则,将文档分配到不同的桶中,从而达到分类的目的。ES提供的一些常见的 Bucket Aggregation。
- Terms,需要字段支持filedata
- keyword 默认支持fielddata
- text需要在Mapping 中开启fielddata,会按照分词后的结果进行分桶
- 数字类型
- Range / Data Range
- Histogram(直方图) / Date Histogram
- 支持嵌套: 也就在桶里再做分桶
桶聚合可以用于各种场景,例如:
- 对数据进行分组统计,比如按照地区、年龄段、性别等字段进行分组统计。
- 对时间序列数据进行时间段分析,比如按照每小时、每天、每月、每季度、每年等时间段进行分析。
- 对各种标签信息分类,并统计其数量。
1)使用示例:获取job的分类信息
# 对keword 进行聚合
GET /employees/_search
{"size": 0,"aggs": {"jobs": {"terms": {"field":"job.keyword"}}}
}
聚合可配置属性有:
- field:指定聚合字段
- size:指定聚合结果数量
- order:指定聚合结果排序方式
默认情况下,Bucket聚合会统计Bucket内的文档数量,记为_count,并且按照_count降序排序。我们可以指定order属性,自定义聚合的排序方式:
GET /employees/_search
{"size": 0,"aggs": {"jobs": {"terms": {"field":"job.keyword","size": 10,"order": {"_count": "desc" }}}}
}
2)使用示例:限定聚合范围
#只对salary在10000元以上的文档聚合
GET /employees/_search
{"query": {"range": {"salary": {"gte": 10000 }}}, "size": 0,"aggs": {"jobs": {"terms": {"field":"job.keyword","size": 10,"order": {"_count": "desc" }}}}
}
注意:对 Text 字段进行 terms 聚合查询,会失败抛出异常
mployees/_search
{"size": 0,"aggs": {"jobs": {"terms": {"field":"job"}}}
}
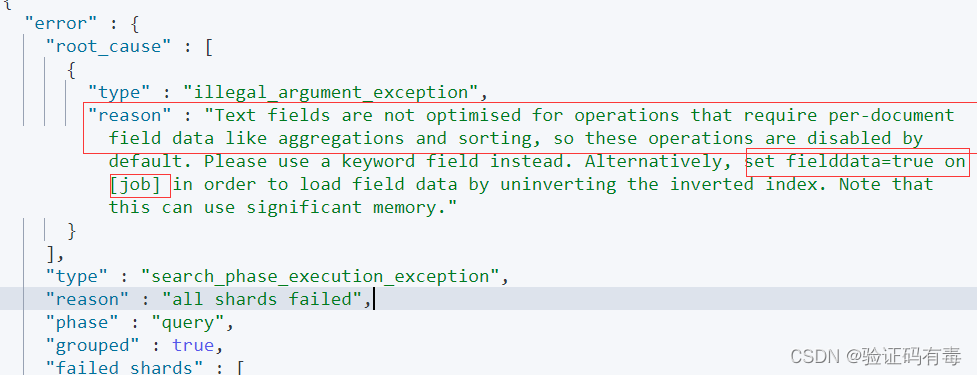
解决办法:对 Text 字段打开 fielddata,支持terms aggregation
PUT /employees/_mapping
{"properties" : {"job":{"type": "text","fielddata": true}}
}# 对 Text 字段进行分词,分词后的terms
POST /employees/_search
{"size": 0,"aggs": {"jobs": {"terms": {"field":"job"}}}
}
3)使用示例:Range & Histogram聚合
- 按照数字的范围,进行分桶
- 在Range Aggregation中,可以自定义Key
Range 示例:按照工资的 Range 分桶
Salary Range分桶,可以自己定义 key
POST employees/_search
{"size": 0,"aggs": {"salary_range": {"range": {"field":"salary","ranges":[{"to":10000},{"from":10000,"to":20000},{"key":">20000","from":20000}]}}}
}
Histogram示例:按照工资的间隔分桶
#工资0到10万,以 5000一个区间进行分桶
POST employees/_search
{"size": 0,"aggs": {"salary_histrogram": {"histogram": {"field":"salary","interval":5000,"extended_bounds":{"min":0,"max":100000}}}}
}
top_hits应用场景: 当获取分桶后,桶内最匹配的顶部文档列表
# 指定size,不同工种中,年纪最大的3个员工的具体信息
POST /employees/_search
{"size": 0,"aggs": {"jobs": {"terms": {"field":"job.keyword"},"aggs":{"old_employee":{"top_hits":{"size":3,"sort":[{"age":{"order":"desc"}}]}}}}}
}
嵌套聚合示例
# 嵌套聚合1,按照工作类型分桶,并统计工资信息
POST employees/_search
{"size": 0,"aggs": {"Job_salary_stats": {"terms": {"field": "job.keyword"},"aggs": {"salary": {"stats": {"field": "salary"}}}}}
}# 多次嵌套。根据工作类型分桶,然后按照性别分桶,计算工资的统计信息
POST employees/_search
{"size": 0,"aggs": {"Job_gender_stats": {"terms": {"field": "job.keyword"},"aggs": {"gender_stats": {"terms": {"field": "gender"},"aggs": {"salary_stats": {"stats": {"field": "salary"}}}}}}}
}
4.6 Pipeline Aggregation
支持对聚合分析的结果,再次进行聚合分析。
Pipeline 的分析结果会输出到原结果中,根据位置的不同,分为两类:
- Sibling - 结果和现有分析结果同级
- Max,min,Avg & Sum Bucket
- Stats,Extended Status Bucket
- Percentiles Bucket
- Parent -结果内嵌到现有的聚合分析结果之中
- Derivative(求导)
- Cumultive Sum(累计求和)
- Moving Function(移动平均值 )
1)min_bucket示例
# 平均工资最低的工种
POST employees/_search
{"size": 0,"aggs": {"jobs": {"terms": {"field": "job.keyword","size": 10},"aggs": {"avg_salary": {"avg": {"field": "salary"}}}},"min_salary_by_job":{ "min_bucket": { "buckets_path": "jobs>avg_salary" }}}
}
- min_salary_by_job结果和jobs的聚合同级
- min_bucket求之前结果的最小值
- 通过bucket_path关键字指定路径
2)Stats示例
# 平均工资的统计分析
POST employees/_search
{"size": 0,"aggs": {"jobs": {"terms": {"field": "job.keyword","size": 10},"aggs": {"avg_salary": {"avg": {"field": "salary"}}}},"stats_salary_by_job":{"stats_bucket": {"buckets_path": "jobs>avg_salary"}}}
}
3)percentiles示例
# 平均工资的百分位数
POST employees/_search
{"size": 0,"aggs": {"jobs": {"terms": {"field": "job.keyword","size": 10},"aggs": {"avg_salary": {"avg": {"field": "salary"}}}},"percentiles_salary_by_job":{"percentiles_bucket": {"buckets_path": "jobs>avg_salary"}}}
}
4)Cumulative_sum示例
#Cumulative_sum 累计求和
POST employees/_search
{"size": 0,"aggs": {"age": {"histogram": {"field": "age","min_doc_count": 0,"interval": 1},"aggs": {"avg_salary": {"avg": {"field": "salary"}},"cumulative_salary":{"cumulative_sum": {"buckets_path": "avg_salary"}}}}}
}
4.7 聚合的作用范围
ES聚合分析的默认作用范围是query的查询结果集,同时ES还支持以下方式改变聚合的作用范围:
- Filter
- Post Filter
- Global
#Query
POST employees/_search
{"size": 0,"query": {"range": {"age": {"gte": 20}}},"aggs": {"jobs": {"terms": {"field":"job.keyword"}}}
}#Filter
POST employees/_search
{"size": 0,"aggs": {"older_person": {"filter":{"range":{"age":{"from":35}}},"aggs":{"jobs":{"terms": {"field":"job.keyword"}}}},"all_jobs": {"terms": {"field":"job.keyword"}}}
}#Post field. 一条语句,找出所有的job类型。还能找到聚合后符合条件的结果
POST employees/_search
{"aggs": {"jobs": {"terms": {"field": "job.keyword"}}},"post_filter": {"match": {"job.keyword": "Dev Manager"}}
}#global
POST employees/_search
{"size": 0,"query": {"range": {"age": {"gte": 40}}},"aggs": {"jobs": {"terms": {"field":"job.keyword"}},"all":{"global":{},"aggs":{"salary_avg":{"avg":{"field":"salary"}}}}}
}4.8 排序
指定order,按照count和key进行排序:
- 默认情况,按照count降序排序
- 指定size,就能返回相应的桶
#排序 order
#count and key
POST employees/_search
{"size": 0,"query": {"range": {"age": {"gte": 20}}},"aggs": {"jobs": {"terms": {"field":"job.keyword","order":[{"_count":"asc"},{"_key":"desc"}]}}}
}#排序 order
#count and key
POST employees/_search
{"size": 0,"aggs": {"jobs": {"terms": {"field":"job.keyword","order":[ {"avg_salary":"desc"}]},"aggs": {"avg_salary": {"avg": {"field":"salary"}}}}}
}#排序 order
#count and key
POST employees/_search
{"size": 0,"aggs": {"jobs": {"terms": {"field":"job.keyword","order":[ {"stats_salary.min":"desc"}]},"aggs": {"stats_salary": {"stats": {"field":"salary"}}}}}
}
4.8 ES聚合分析不精准原因分析
ElasticSearch在对海量数据进行聚合分析的时候会损失搜索的精准度来满足实时性的需求。
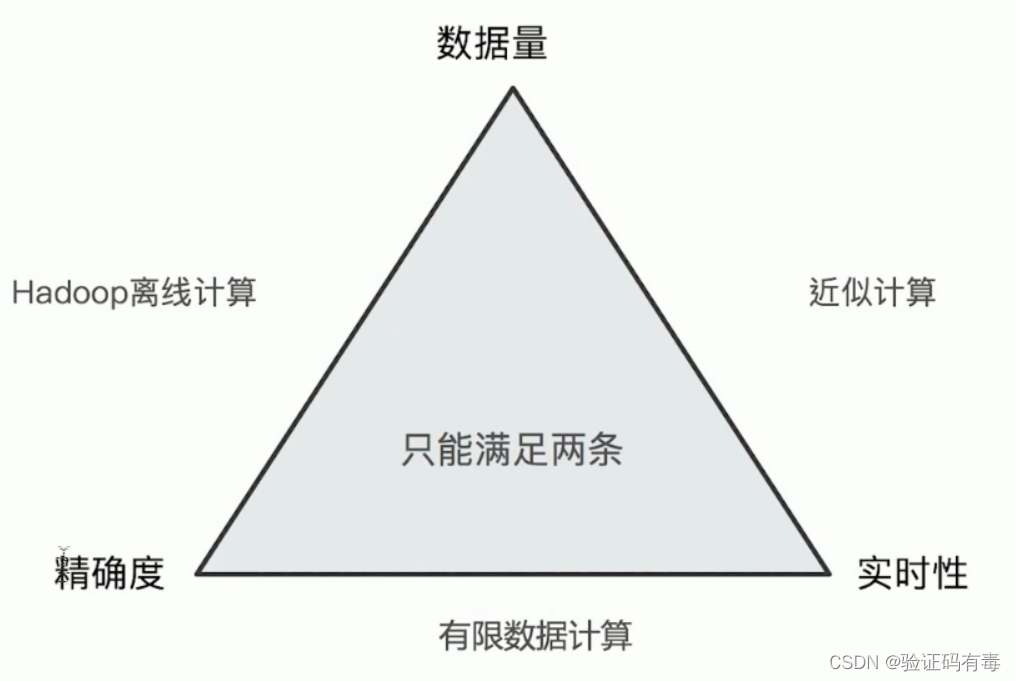
Terms聚合分析的执行流程:
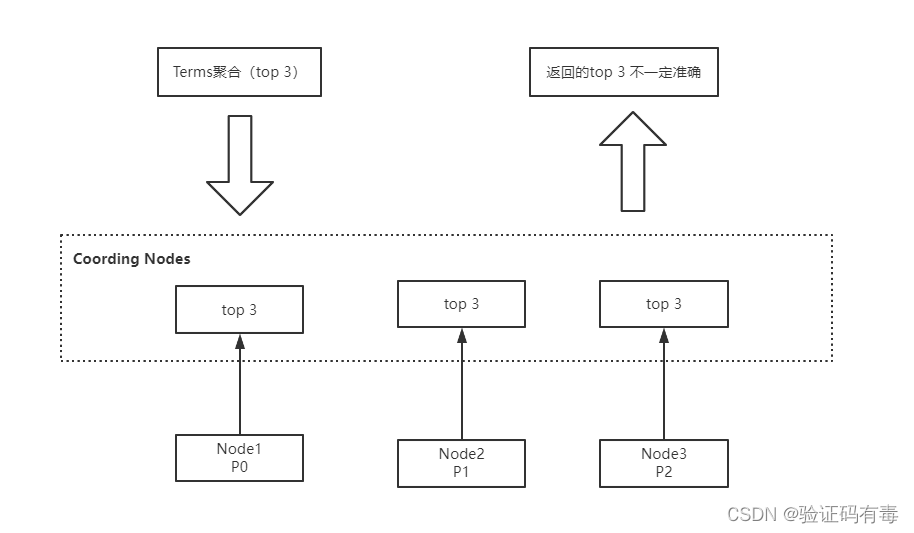
不精准的原因: 数据分散到多个分片,聚合是每个分片的取 Top X,导致结果不精准。ES 可以不每个分片Top X,而是全量聚合,但势必这会有很大的性能问题。
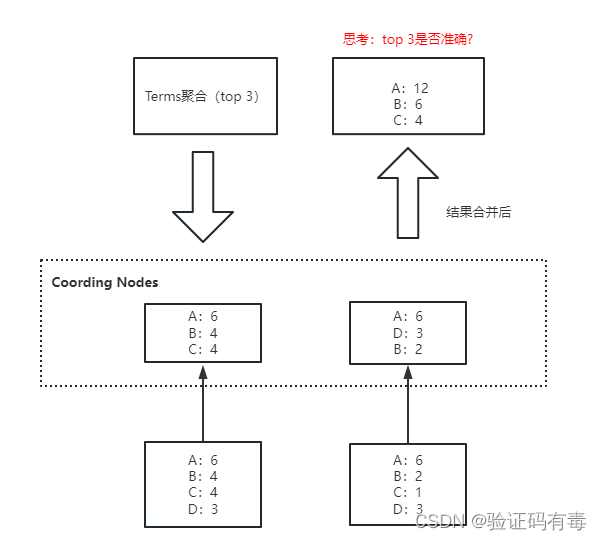
4.9 Elasticsearch 聚合性能优化
4.9.1 启用 eager global ordinals 提升高基数聚合性能
适用场景:高基数聚合 。高基数聚合场景中的高基数含义:一个字段包含很大比例的唯一值。
global ordinals 中文翻译成全局序号,是一种数据结构,应用场景如下:
- 基于 keyword,ip 等字段的分桶聚合,包含:terms聚合、composite 聚合等。
- 基于text 字段的分桶聚合(前提条件是:fielddata 开启)。
- 基于父子文档 Join 类型的 has_child 查询和 父聚合。
global ordinals 使用一个数值代表字段中的字符串值,然后为每一个数值分配一个 bucket(分桶)。
global ordinals 的本质是:启用 eager_global_ordinals 时,会在刷新(refresh)分片时构建全局序号。这将构建全局序号的成本从搜索阶段转移到了数据索引化(写入)阶段。
创建索引的同时开启:eager_global_ordinals。
PUT /my-index
{"mappings": {"properties": {"tags": {"type": "keyword","eager_global_ordinals": true}}}
注意:开启 eager_global_ordinals 会影响写入性能,因为每次刷新时都会创建新的全局序号。为了最大程度地减少由于频繁刷新建立全局序号而导致的额外开销,请调大刷新间隔 refresh_interval。
动态调整刷新频率的方法如下:
PUT my-index/_settings
{"index": {"refresh_interval": "30s"}
该招数的本质是:以空间换时间。
4.9.1 插入数据时对索引进行预排序
- Index sorting (索引排序)可用于在插入时对索引进行预排序,而不是在查询时再对索引进行排序,这将提高范围查询(range query)和排序操作的性能。
- 在 Elasticsearch 中创建新索引时,可以配置如何对每个分片内的段进行排序。
- 这是 Elasticsearch 6.X 之后版本才有的特性。
PUT /my_index
{"settings": {"index":{"sort.field": "create_time","sort.order": "desc"}},"mappings": {"properties": {"create_time":{"type": "date"}}}
}
注意:预排序将增加 Elasticsearch 写入的成本。在某些用户特定场景下,开启索引预排序会导致大约 40%-50% 的写性能下降。也就是说,如果用户场景更关注写性能的业务,开启索引预排序不是一个很好的选择。
4.9.3 使用节点查询缓存
节点查询缓存(Node query cache)可用于有效缓存过滤器(filter)操作的结果。如果多次执行同一 filter 操作,这将很有效,但是即便更改过滤器中的某一个值,也将意味着需要计算新的过滤器结果。
例如,由于 “now” 值一直在变化,因此无法缓存在过滤器上下文中使用 “now” 的查询。
那怎么使用缓存呢?通过在 now 字段上应用 datemath 格式将其四舍五入到最接近的分钟/小时等,可以使此类请求更具可缓存性,以便可以对筛选结果进行缓存。
PUT /my_index/_doc/1
{"create_time":"2022-05-11T16:30:55.328Z"
}#下面的示例无法使用缓存
GET /my_index/_search
{"query":{"constant_score": {"filter": {"range": {"create_time": {"gte": "now-1h","lte": "now"}}}}}
}# 下面的示例就可以使用节点查询缓存。
GET /my_index/_search
{"query":{"constant_score": {"filter": {"range": {"create_time": {"gte": "now-1h/m","lte": "now/m"}}}}}
}
上述示例中的“now-1h/m” 就是 datemath 的格式。
如果当前时间 now 是:16:31:29,那么range query 将匹配 my_date 介于:15:31:00 和 15:31:59 之间的时间数据。同理,聚合的前半部分 query 中如果有基于时间查询,或者后半部分 aggs 部分中有基于时间聚合的,建议都使用 datemath 方式做缓存处理以优化性能。
4.9.4 使用分片请求缓存
聚合语句中,设置:size:0,就会使用分片请求缓存缓存结果。size = 0 的含义是:只返回聚合结果,不返回查询结果。
GET /es_db/_search
{"size": 0,"aggs": {"remark_agg": {"terms": {"field": "remark.keyword"}}}
}
4.9.5 拆分聚合,使聚合并行化
Elasticsearch 查询条件中同时有多个条件聚合,默认情况下聚合不是并行运行的。当为每个聚合提供自己的查询并执行 msearch 时,性能会有显著提升。因此,在 CPU 资源不是瓶颈的前提下,如果想缩短响应时间,可以将多个聚合拆分为多个查询,借助:msearch 实现并行聚合。
#常规的多条件聚合实现
GET /employees/_search
{"size": 0,"aggs": {"job_agg": {"terms": {"field": "job.keyword"}},"max_salary":{"max": {"field": "salary"}}}
}
# msearch 拆分多个语句的聚合实现
GET _msearch
{"index":"employees"}
{"size":0,"aggs":{"job_agg":{"terms":{"field": "job.keyword"}}}}
{"index":"employees"}
{"size":0,"aggs":{"max_salary":{"max":{"field": "salary"}}}}
学习总结
感谢
感谢大佬【止步前行】的文章《ElasticSearch之score打分机制原理》
相关文章:
【ES专题】ElasticSearch搜索进阶
目录 前言阅读导航前置知识特别提醒笔记正文一、分词器详解1.1 基本概念1.2 分词发生的时期1.3 分词器的组成1.3.1 切词器:Tokenizer1.3.2 词项过滤器:Token Filter1.3.3 字符过滤器:Character Filter 1.4 倒排索引的数据结构 <font color…...
【iOS免越狱】利用IOS自动化WebDriverAgent实现自动直播间自动输入
1.目标 由于看直播的时候主播叫我发 666,支持他,我肯定支持他呀,就一直发,可是后来发现太浪费时间了,能不能做一个直播间自动发 666 呢?于是就开始下面的操作。 2.操作环境 iPhone一台 WebDriverAgent …...

Python基础入门例程28-NP28 密码游戏(列表)
最近的博文: Python基础入门例程27-NP27 朋友们的喜好(列表)-CSDN博客 Python基础入门例程26-NP26 牛牛的反转列表(列表)-CSDN博客 Python基础入门例程25-NP25 有序的列表(列表)-CSDN博客 目录…...

乌班图 Linux 系统 Ubuntu 23.10.1 发布更新镜像
Ubuntu 团队在其官网上发布了Ubuntu 23.10.1 版本,这是目前较新的 Ubuntu 23.10(Focal Fossa)操作系统系列的第一个发行版,旨在为社区提供最新的安装媒体。Ubuntu 22.04 LTS(Focal Fossa)操作系统系列于 2022 年 4 月 21 日发布。 Ubuntu 23.10 LTS(长期支持版本)可用…...
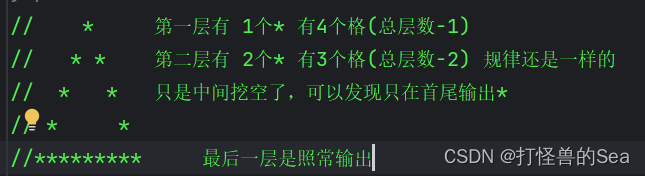
Java金字塔、空心金字塔、空心菱形
Java金字塔 public class TestDemo01 {public static void main(String[] args){//第一个for用于每行输出 从i1开始到i<5,总共5行for(int i1;i<5;i){//每行前缀空格,这个for用于表示每行输出*前面的空格//从上面规律可得,每行输出的空格数为总层数,…...

前端 | (十四)canvas基本用法 | 尚硅谷前端HTML5教程(html5入门经典)
文章目录 📚canvas基本用法🐇什么是canvas(画布)🐇替换内容🐇canvas标签的两个属性🐇渲染上下文 📚绘制矩形🐇绘制矩形🐇strokeRect时,边框像素渲染问题🐇添加…...
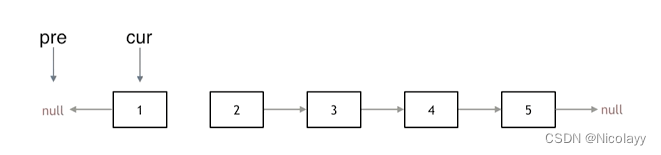
206.反转链表
206.反转链表 力扣题目链接(opens new window) 题意:反转一个单链表。 示例: 输入: 1->2->3->4->5->NULL 输出: 5->4->3->2->1->NULL 双双指针法: 创建三个节点 pre(反转时的第一个节点)、cur(当前指向需要反转的节点…...
SpringBoot项目从resources目录读取文件
SpringBoot 从 resources 读取文件 使用 Spring 给我们提供的工具类来进行读取 File file org.springframework.util.ResourceUtils.getFile("classpath:人物模板.docx");可能读取失败,出现如下错误: java.io.FileNotFoundException: clas…...

SQL实现根据时间戳和增量标记IDU获取最新记录和脱IDU标记
需求说明:表中有 id, info, cnt 三个字段,对应的增量表多idu增量标记字段和时间戳字段ctimestamp。增量表中的 id 会有重复,其他字段 info、cnt 会不断更新,idu为增量标记字段,ctimestamp为IDU操作的时间戳。目的时要做…...

京东数据平台:2023年9月京东智能家居行业数据分析
鲸参谋监测的京东平台9月份智能家居市场销售数据已出炉! 9月份,智能家居市场销售额有小幅上涨。根据鲸参谋电商数据分析平台的相关数据显示,今年9月,京东平台智能家居的销量为37万,销售额将近8300万,同比增…...

计算两个时间之间连续的日期(java)
背景介绍 给出两个时间,希望算出两者之间连续的日期,比如时间A:2023-10-01 00:00:00 时间B:2023-11-30 23:59:59,期望得到的连续日期为2023-10-01、2023-10-02、… 2023-11-30 Java版代码示例 import java.time.temporal.ChronoUnit; import java.tim…...

Kali Linux:网络与安全专家的终极武器
文章目录 一、Kali Linux 简介二、Kali Linux 的优势三、使用 Kali Linux 进行安全任务推荐阅读 ——《Kali Linux高级渗透测试》适读人群内容简介作者简介目录 Kali Linux:网络与安全专家的终极武器 Kali Linux,对于许多网络和安全专业人士来说&#x…...

Leetcode—101.对称二叉树【简单】
2023每日刷题(十九) Leetcode—101.对称二叉树 利用Leetcode101.对称二叉树的思想的实现代码 /*** Definition for a binary tree node.* struct TreeNode {* int val;* struct TreeNode *left;* struct TreeNode *right;* };*/ bool isSa…...

判断是否工作在docker环境
判断是否工作在docker环境 方式一:判断根目录下 .dockerenv 文件 docker环境下:ls -alh /.dockerenv , 非docker环境,没有这个.dockerenv文件的 注:定制化比较高的docker系统也可能没有这个文件 方式二:查询系统进程…...

文件上传学习笔记
笔记 文件上传 文件上传是指将本地图片,视频,音频等文件上传到服务器,供其它用户浏览或下载的过程 文件上传前端三要素 : file表单项 post方式 multipart/from-data 服务端接收文件 : 用spring中的API : MultipartFile 要想文件名唯一 …...

【GitLab CI/CD、SpringBoot、Docker】GitLab CI/CD 部署SpringBoot应用,部署方式Docker
介绍 本文件主要介绍如何将SpringBoot应用使用Docker方式部署,并用Gitlab CI/CD进行构建和部署。 环境准备 已安装Gitlab仓库已安装Gitlab Runner,并已注册到Gitlab和已实现基础的CI/CD使用创建Docker Hub仓库,教程中使用的是阿里云的Docker…...
GitLab(2)——Docker方式安装Gitlab
目录 一、前言 二、安装Gitlab 1. 搜索gitlab-ce镜像 2. 下载镜像 3. 查看镜像 4. 提前创建挂载数据卷 5. 运行镜像 三、配置Gitlab文件 1. 配置容器中的/etc/gitlab/gitlab.rb文件 2. 重启容器 3. 登录Gitalb ① 查看初始root用户的密码 ② 访问gitlab地址&#…...
)
[100天算法】-数组中的第 K 个最大元素(day 54)
题目描述 在未排序的数组中找到第 k 个最大的元素。请注意,你需要找的是数组排序后的第 k 个最大的元素,而不是第 k 个不同的元素。示例 1:输入: [3,2,1,5,6,4] 和 k 2 输出: 5 示例 2:输入: [3,2,3,1,2,4,5,5,6] 和 k 4 输出: 4 说明:你可以假设 k 总…...
)
每日一题411数组中两个数的最大异或值(哈希表、前缀树:实现前缀树)
数组中两个数的最大异或值(哈希表、前缀树:实现前缀树) LeetCode题目:https://leetcode.cn/problems/maximum-xor-of-two-numbers-in-an-array/ 哈希表解法 本题使用哈希表方法主要运用到一个定理:异或满足算法交换律。即如果a^b c&#x…...

机场运行关键指标计算规则
一、总体指标 1.放行正常率 机场放行航班:计划出港时间在当天的已出港航班,航班任务为正班、加班、旅包 放行正常航班:实际起飞时间≤MAX[实际落地时间10分钟(计划出港时间-计划进港时间),计划出港时间]3…...

搞定银河麒麟V10+飞腾平台Qt开发环境后,我总结的3个必做配置和1个字体坑
银河麒麟V10飞腾平台Qt开发环境深度调优指南 在国产化技术栈中,银河麒麟V10操作系统搭配飞腾D2000处理器的组合正逐渐成为自主可控解决方案的主流选择。对于需要在此平台上进行Qt开发的工程师而言,成功安装Qt仅仅是万里长征的第一步。本文将深入剖析三个…...

中小团队如何通过Taotoken实现AI模型调用成本的可观测与可优化
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 中小团队如何通过Taotoken实现AI模型调用成本的可观测与可优化 对于中小型研发团队而言,引入大模型能力已成为提升产品…...

二维码坏了别着急扔!3步教你用QRazyBox免费修复损坏的二维码
二维码坏了别着急扔!3步教你用QRazyBox免费修复损坏的二维码 【免费下载链接】qrazybox QR Code Analysis and Recovery Toolkit 项目地址: https://gitcode.com/gh_mirrors/qr/qrazybox 你有没有遇到过这样的情况?打印出来的二维码被水弄湿了&am…...

2025最权威的十大AI科研工具推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 学术研讨范畴正在历经深度的变动,人工智能论文工具现身,极大地提高了…...

Avogadro 2:解决跨平台化学建模可视化挑战的开源方案
Avogadro 2:解决跨平台化学建模可视化挑战的开源方案 【免费下载链接】avogadroapp Avogadro is an advanced molecular editor designed for cross-platform use in computational chemistry, molecular modeling, bioinformatics, materials science, and related…...
)
从开发到上线:UniApp小程序跳转全流程配置指南(含环境区分与版本管理)
UniApp跨小程序跳转工程化实践:多环境配置与版本管理全解析 在移动互联网生态中,小程序间的相互跳转已成为提升用户体验的关键链路。作为技术负责人,我曾亲历过因环境配置错误导致的线上事故——某次紧急更新中,由于跳转参数未区分…...

RVC-WebUI终极指南:5步掌握AI语音克隆与声音转换技术
RVC-WebUI终极指南:5步掌握AI语音克隆与声音转换技术 【免费下载链接】rvc-webui liujing04/Retrieval-based-Voice-Conversion-WebUI reconstruction project 项目地址: https://gitcode.com/gh_mirrors/rv/rvc-webui RVC-WebUI是一个基于检索式语音转换技术…...

2026年电钢琴避坑指南|高性价比品牌型号推荐,新手必看!
电钢琴选购核心要点(快速避坑) 在推荐具体机型前,先明确4个选购关键指标,确保不踩坑: 1.键盘:必须88键逐级配重重锤键盘,避免毁手型。 2.复音数:至少128复音(避免弹奏复杂曲目时丢…...
)
保姆级教程:用PySpark Streaming把MySQL变成实时数据仓库(附完整代码)
从MySQL到实时数据仓库:PySpark Streaming实战进阶指南 在数据驱动的商业环境中,传统批处理模式已无法满足企业对实时洞察的需求。本文将深入探讨如何利用PySpark Streaming将静态的MySQL数据库转变为动态的实时数据仓库,实现从数据采集、处…...

折叠表达式:左折叠,右折叠
关于何为左右折叠表达式可以直接通过 C Insights (C Insights) 来进行查看原理。左折叠template <typename... Args> auto getSum(Args... args) {return (args ...); }int main() {getSum(1, 2, 3, 4, 5); } template <typename... Args> auto getSum(Args... ar…...