SQL实现根据时间戳和增量标记IDU获取最新记录和脱IDU标记
需求说明:表中有 id, info, cnt 三个字段,对应的增量表多idu增量标记字段和时间戳字段ctimestamp。增量表中的 id 会有重复,其他字段 info、cnt 会不断更新,idu为增量标记字段,ctimestamp为IDU操作的时间戳。目的时要做到:
1)获取增量表中的时间戳字段(ctimestamp)为最新值对应的记录、进行id去重;
2)将第一步的查询结果进行脱IDU标记和时间戳字段、合并到最终的表中(不带IDU标记和时间戳字段)。
SQL查询根据时间戳字段和id字段获取最新值的记录
-- 表字段说明:id 会有重复,其他字段 info、cnt 会不断更新,idu为增量标记字段,ctimestamp为IDU操作的时间戳,需求是要获取时间戳字段(ctimestamp)为最新值对应的记录:
-- 脱IDU和时间戳以后的最终目的表(不带增量标记和时间戳字段)
drop table if exists test81;
-- 带IDU标记idu字段和时间戳字段ctimestamp,id字段可能存在重复的值的记录
drop table if exists test81_idu;
-- 基于 test81_idu 生成的 D 的记录,id唯一(去重后无重复记录)
drop table if exists test81_tmp2_d;
-- 基于 test81_idu 生成的 I、U 的记录,id唯一(去重后无重复记录)
drop table if exists test81_tmp3_iu;
-- 创建最终目的表、并构部分已有数据
create table test81 (
id int not null,
info varchar(100),
cnt int,
primary key(id));
insert into test81 (id,info,cnt) values (1, 'aaa', 31);
insert into test81 (id,info,cnt) values (2, 'bbb', 33);
insert into test81 (id,info,cnt) values (3, 'ccc', 35);
注意:如果是GBase8a primary key(id) 主键约束无效。
select * from test81;
查询结果:
+----+------+------+
| id | info | cnt |
+----+------+------+
| 1 | aaa | 31 |
| 2 | bbb | 33 |
| 3 | ccc | 35 |
+----+------+------+
-- 创建带IDU标记的表,id存在重复多条记录
create table test81_idu (
id int not null,
info varchar(100),
cnt int,
idu varchar(10),
ctimestamp timestamp);
insert into test81_idu (id,info,cnt,idu,ctimestamp) values (1, 'aaa', 31, 'I', '2023-10-27 12:31:31.123456789');
insert into test81_idu (id,info,cnt,idu,ctimestamp) values (2, 'bbb', 33, 'I', '2023-10-27 12:33:33.123456789');
insert into test81_idu (id,info,cnt,idu,ctimestamp) values (3, 'ccc', 35, 'I', '2023-10-27 12:35:35.123456789');
insert into test81_idu (id,info,cnt,idu,ctimestamp) values (1, 'aaa', 50, 'U', '2023-10-27 12:50:50.123456789');
insert into test81_idu (id,info,cnt,idu,ctimestamp) values (1, 'aaa', 41, 'U', '2023-10-27 12:41:41.123456789');
insert into test81_idu (id,info,cnt,idu,ctimestamp) values (2, NULL, NULL, 'D', '2023-10-27 12:52:52.123456789');
注意:MySQL支持上面9位(精确到纳秒的输入),只是数据库行为实际上丢弃后面3位,只取前面6位,但不会报错,能执行成功。但如果是GBase8a,则不行,只能指定6位:
insert into test81_idu (id,info,cnt,idu,ctimestamp) values (1, 'aaa', 31, 'I', '2023-10-27 12:31:31.123456');
insert into test81_idu (id,info,cnt,idu,ctimestamp) values (2, 'bbb', 33, 'I', '2023-10-27 12:33:33.123456');
insert into test81_idu (id,info,cnt,idu,ctimestamp) values (3, 'ccc', 35, 'I', '2023-10-27 12:35:35.123456');
insert into test81_idu (id,info,cnt,idu,ctimestamp) values (1, 'aaa', 50, 'U', '2023-10-27 12:50:50.123456');
insert into test81_idu (id,info,cnt,idu,ctimestamp) values (1, 'aaa', 41, 'U', '2023-10-27 12:41:41.123456');
insert into test81_idu (id,info,cnt,idu,ctimestamp) values (2, NULL, NULL, 'D', '2023-10-27 12:52:52.123456');
select * from test81_idu;
执行结果:
+----+------+------+------+---------------------+
| id | info | cnt | idu | ctimestamp |
+----+------+------+------+---------------------+
| 1 | aaa | 31 | I | 2023-10-27 12:31:31 |
| 2 | bbb | 33 | I | 2023-10-27 12:33:33 |
| 3 | ccc | 35 | I | 2023-10-27 12:35:35 |
| 1 | aaa | 50 | U | 2023-10-27 12:50:50 |
| 1 | aaa | 41 | U | 2023-10-27 12:41:41 |
| 2 | NULL | NULL | D | 2023-10-27 12:52:52 |
+----+------+------+------+---------------------+
表字段说明:id 会有重复,其他字段 info、cnt 会不断更新,idu为增量标记字段,ctimestamp为IDU操作的时间戳,需求是要获取时间戳字段(ctimestamp)为最新值对应的记录:
脱IDU标记合并处理(中间用多个到临时表)
-- 先查询一下根据时间戳字段和id进行处理,对id去重(同一个id的多条重复记录,只取时间戳最新的一条记录)
SELECT a.id,a.info,a.cnt,a.idu FROM test81_idu a,(
SELECT
id, MAX(ctimestamp)AS time
FROM test81_idu
GROUP BY id
ORDER BY COUNT(*)DESC)b WHERE a.id=b.id and a.ctimestamp=b.time;
执行结果:
+----+------+------+------+
| id | info | cnt | idu |
+----+------+------+------+
| 3 | ccc | 35 | I |
| 1 | aaa | 50 | U |
| 2 | NULL | NULL | D |
+----+------+------+------+
-- 如果用 INSERT INTO 则需要先创建目标表、如果用 SELECT INTO 则要保证目标表不存在(执行时会创建目标表)
DROP TABLE IF EXISTS test81_tmp2_d;
-- CREATE TABLE IF NOT EXISTS test81_tmp2_d LIKE test81_idu;
-- 根据id和时间戳查询最新记录、并只显示idu='D'的结果
-- MySQL不支持的方式:
-- SELECT id,info,cnt INTO test81_tmp2_d FROM test81_idu;
-- MySQL能支持的方式:
DROP TABLE IF EXISTS test81_tmp2_d;
CREATE TABLE test81_tmp2_d
(
SELECT a.id,a.info,a.cnt,a.idu FROM test81_idu a,(
SELECT
id, MAX(ctimestamp)AS time
FROM test81_idu
GROUP BY id
ORDER BY COUNT(*)DESC)b WHERE a.id=b.id AND a.ctimestamp=b.time AND a.idu='D'
);
-- 查询结果:
select * from test81_tmp2_d;
+----+------+------+------+
| id | info | cnt | idu |
+----+------+------+------+
| 2 | NULL | NULL | D |
+----+------+------+------+
-- 根据id和时间戳查询最新记录、并只显示idu='IU'的结果
-- MySQL能支持的方式
DROP TABLE IF EXISTS test81_tmp3_iu;
CREATE TABLE test81_tmp3_iu
(
SELECT a.id,a.info,a.cnt,a.idu FROM test81_idu a,(
SELECT
id, MAX(ctimestamp)AS time
FROM test81_idu
GROUP BY id
ORDER BY COUNT(*)DESC)b WHERE a.id=b.id AND a.ctimestamp=b.time AND (a.idu IN ('I','U'))
);
-- 查询结果:
select * from test81_tmp3_iu;
+----+------+------+------+
| id | info | cnt | idu |
+----+------+------+------+
| 3 | ccc | 35 | I |
| 1 | aaa | 50 | U |
+----+------+------+------+
-- 将'D'的数据从最终目标表删除
DELETE FROM test81 WHERE id in (SELECT DISTINCT id FROM test81_tmp2_d);
-- 'D' 记录删除后,查看目的表数据
select * from test81;
+----+------+------+
| id | info | cnt |
+----+------+------+
| 1 | aaa | 31 |
| 3 | ccc | 35 |
+----+------+------+
-- 将'I'和'U'的数据插入或更新到最终的目标表
-- merge into, 目的表的关联id存在则update、不存在则insert:
-- GBase8a 使用 merge into (MySQL 不支持该语法)
-- merge into test81 t1 using test81_tmp3_iu tmp on t1.id=tmp.id when matched then update set t1.info=tmp.info,t1.cnt=tmp.cnt when not matched then insert(id,info,cnt)values(tmp.id,tmp.info,tmp.cnt);
-- MySQL 使用 insert into (GBase8a 不支持该语法)
INSERT INTO test81(id,info,cnt) SELECT id,info,cnt FROM test81_tmp3_iu ON DUPLICATE KEY UPDATE info=VALUES(info), cnt=VALUES(cnt);
-- 'I'和'U'合并到目的表后,查询结果
select * from test81;
+----+------+------+
| id | info | cnt |
+----+------+------+
| 1 | aaa | 50 |
| 3 | ccc | 35 |
+----+------+------+
到此为止,整个脱IDU表级和时间戳的流程处理完毕。
相关文章:

SQL实现根据时间戳和增量标记IDU获取最新记录和脱IDU标记
需求说明:表中有 id, info, cnt 三个字段,对应的增量表多idu增量标记字段和时间戳字段ctimestamp。增量表中的 id 会有重复,其他字段 info、cnt 会不断更新,idu为增量标记字段,ctimestamp为IDU操作的时间戳。目的时要做…...

京东数据平台:2023年9月京东智能家居行业数据分析
鲸参谋监测的京东平台9月份智能家居市场销售数据已出炉! 9月份,智能家居市场销售额有小幅上涨。根据鲸参谋电商数据分析平台的相关数据显示,今年9月,京东平台智能家居的销量为37万,销售额将近8300万,同比增…...

计算两个时间之间连续的日期(java)
背景介绍 给出两个时间,希望算出两者之间连续的日期,比如时间A:2023-10-01 00:00:00 时间B:2023-11-30 23:59:59,期望得到的连续日期为2023-10-01、2023-10-02、… 2023-11-30 Java版代码示例 import java.time.temporal.ChronoUnit; import java.tim…...

Kali Linux:网络与安全专家的终极武器
文章目录 一、Kali Linux 简介二、Kali Linux 的优势三、使用 Kali Linux 进行安全任务推荐阅读 ——《Kali Linux高级渗透测试》适读人群内容简介作者简介目录 Kali Linux:网络与安全专家的终极武器 Kali Linux,对于许多网络和安全专业人士来说&#x…...

Leetcode—101.对称二叉树【简单】
2023每日刷题(十九) Leetcode—101.对称二叉树 利用Leetcode101.对称二叉树的思想的实现代码 /*** Definition for a binary tree node.* struct TreeNode {* int val;* struct TreeNode *left;* struct TreeNode *right;* };*/ bool isSa…...

判断是否工作在docker环境
判断是否工作在docker环境 方式一:判断根目录下 .dockerenv 文件 docker环境下:ls -alh /.dockerenv , 非docker环境,没有这个.dockerenv文件的 注:定制化比较高的docker系统也可能没有这个文件 方式二:查询系统进程…...

文件上传学习笔记
笔记 文件上传 文件上传是指将本地图片,视频,音频等文件上传到服务器,供其它用户浏览或下载的过程 文件上传前端三要素 : file表单项 post方式 multipart/from-data 服务端接收文件 : 用spring中的API : MultipartFile 要想文件名唯一 …...

【GitLab CI/CD、SpringBoot、Docker】GitLab CI/CD 部署SpringBoot应用,部署方式Docker
介绍 本文件主要介绍如何将SpringBoot应用使用Docker方式部署,并用Gitlab CI/CD进行构建和部署。 环境准备 已安装Gitlab仓库已安装Gitlab Runner,并已注册到Gitlab和已实现基础的CI/CD使用创建Docker Hub仓库,教程中使用的是阿里云的Docker…...
GitLab(2)——Docker方式安装Gitlab
目录 一、前言 二、安装Gitlab 1. 搜索gitlab-ce镜像 2. 下载镜像 3. 查看镜像 4. 提前创建挂载数据卷 5. 运行镜像 三、配置Gitlab文件 1. 配置容器中的/etc/gitlab/gitlab.rb文件 2. 重启容器 3. 登录Gitalb ① 查看初始root用户的密码 ② 访问gitlab地址&#…...
)
[100天算法】-数组中的第 K 个最大元素(day 54)
题目描述 在未排序的数组中找到第 k 个最大的元素。请注意,你需要找的是数组排序后的第 k 个最大的元素,而不是第 k 个不同的元素。示例 1:输入: [3,2,1,5,6,4] 和 k 2 输出: 5 示例 2:输入: [3,2,3,1,2,4,5,5,6] 和 k 4 输出: 4 说明:你可以假设 k 总…...
)
每日一题411数组中两个数的最大异或值(哈希表、前缀树:实现前缀树)
数组中两个数的最大异或值(哈希表、前缀树:实现前缀树) LeetCode题目:https://leetcode.cn/problems/maximum-xor-of-two-numbers-in-an-array/ 哈希表解法 本题使用哈希表方法主要运用到一个定理:异或满足算法交换律。即如果a^b c&#x…...

机场运行关键指标计算规则
一、总体指标 1.放行正常率 机场放行航班:计划出港时间在当天的已出港航班,航班任务为正班、加班、旅包 放行正常航班:实际起飞时间≤MAX[实际落地时间10分钟(计划出港时间-计划进港时间),计划出港时间]3…...

基于元学习神经网络的类人系统泛化
Nature 上介绍了一个关于AI在语言泛化方面的突破性研究。科学家们创建了一个具有人类般泛化能力的AI神经网络,它可以像人类一样将新学到的词汇融入现有词汇,并在新环境中使用它们。与ChatGPT 相比,该神经网络在系统性泛化测试中表现得更好。 …...

力扣第322题 零钱兑换 c++ java 动态规划
题目 322. 零钱兑换 中等 相关标签 广度优先搜索 数组 动态规划 给你一个整数数组 coins ,表示不同面额的硬币;以及一个整数 amount ,表示总金额。 计算并返回可以凑成总金额所需的 最少的硬币个数 。如果没有任何一种硬币组合能组…...

uniapp 子组件内使用定时器无法清除
涉及到的知识点:1.ref绑定在组建上获取组件实例。2.emit逆向传值,不需要点击触发,watch监听即可。 需求:在父页面的子组件定时发送请求,离开父页面就停止,再次进入就开启。 问题:在父页面的子…...

加载动态库的几种方式
静态加载、动态加载和延迟加载 dll加载方式大致可以分为3类:静态加载、动态加载和延迟加载 1.静态加载,dll的加载发生在程序main函数启动前。 2.动态加载,使用LoadLibrary或者LoadLibraryEx来加载一个dll。当dll加载成功时,你会…...

视频转序列图片:掌握技巧,轻松转换
随着社交媒体和视频平台的日益普及,视频已成为我们生活中不可或缺的一部分。有时,我们需要将视频转换为图片序列,例如制作GIF动图或提取视频中的特定画面。现在一起来看云炫AI智剪如何将视频转换为序列图片,并轻松实现转换。 操作…...
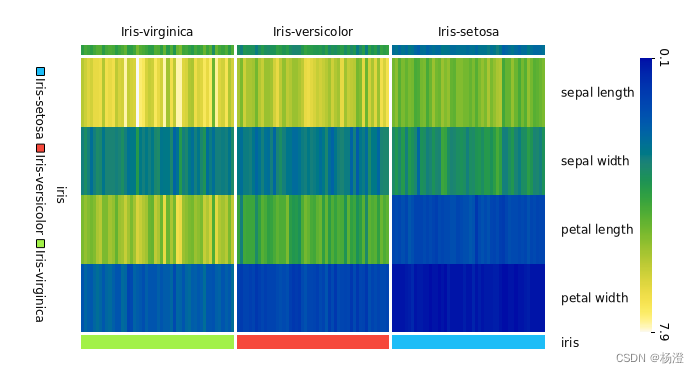
python 数据挖掘库orange3 介绍
orange3 是一个非常适合初学者的data mining library. 它让使用者通过拖拽内置的组件来形成工作流。让你不需要写任何代码就可以体验到数据挖掘和可视化的魅力。 它的桌面如下,这里我创建了 3 个节点,分别是数据集、小提琴图,散点图 其中 …...
Android和JNI交互 : 常见的图像格式转换 : NV21、RGBA、Bitmap等
1. 前言 最近在使用OpenCV处理图片的时候,经常会遇到需要转换图像的情况,网上相关资料比较少,也不全,有时候得费劲老半天才能搞定。 自己踩了坑后,在这里记录下,都是我在项目中遇到的图像转化操作…...

AndroidAuto 解决连接手机启动AA屏闪一下问题
AndroidAuto一般在AndroidManifest.xml注册的Activity配置过滤监听特定手机的USB插拔启动AA <activityandroid:name=".sink.ui.MainActivity"android:configChanges="keyboard|keyboardHidden|uiMode"android:windowSoftInputMode="stateHidden&qu…...
)
GD32 vs STM32:除了参数表,新手选型还得看这几点(附快速上手指南)
GD32与STM32实战选型指南:新手避坑与快速上手指南 当你在电子市场拿起一片GD32开发板和一片STM32开发板时,它们看起来几乎一模一样——同样的引脚排列,同样的封装尺寸,甚至连丝印字体都相似。但当你真正开始项目开发时,…...

基于ESP32的嵌入式AI语音交互系统:从硬件设计到软件实现全解析
1. 项目概述:从零打造一个会聊天的嵌入式AI伙伴几年前,当我第一次把“小爱同学”拆开,看到里面密密麻麻的芯片和电路时,一个念头就冒了出来:能不能自己动手,用一块开发板,从头搭建一个能听会说、…...

【AI编程生产力跃迁】:用Perplexity秒级获取可运行代码示例的6大权威提示工程模板
更多请点击: https://codechina.net 第一章:Perplexity代码示例查询的核心机制与能力边界 Perplexity 在处理代码示例查询时,并非依赖静态模板匹配,而是通过多阶段语义理解与上下文感知检索协同实现:首先对用户自然语…...

别再只盯着业务代码了!SpringBoot应用层安全之Tomcat连接管理实战
SpringBoot应用层安全实战:Tomcat连接管理的三驾马车 当我们在讨论SpringBoot应用安全时,业务代码的漏洞修复往往占据了大部分注意力。然而,真正的安全防线远不止于此——应用层基础设施的配置与优化同样至关重要。想象一下,你的应…...

RedisDesktopManager Windows版:5分钟掌握免费Redis数据库可视化工具
RedisDesktopManager Windows版:5分钟掌握免费Redis数据库可视化工具 【免费下载链接】RedisDesktopManager-Windows RedisDesktopManager Windows版本 项目地址: https://gitcode.com/gh_mirrors/re/RedisDesktopManager-Windows RedisDesktopManager Windo…...

阿里Sophix热更新实战:从加固App打包到补丁发布的完整避坑指南
阿里Sophix热更新深度实践:加固场景下的全链路解决方案 在移动应用快速迭代的今天,热修复技术已经成为保障应用稳定性的关键手段。阿里Sophix作为业界领先的热修复方案,以其高兼容性和稳定性赢得了众多开发团队的青睐。然而,当应用…...

InfluxDB-从时序数据模型到实战:核心原理与Web UI高效入门
1. 时序数据库与InfluxDB初探 第一次接触时序数据库时,我盯着监控大屏上跳动的曲线发愣——这些每秒产生数万条记录的传感器数据,传统数据库根本扛不住。直到同事推荐了InfluxDB,这个专门为时间序列数据设计的数据库,才真正解决了…...

3步掌握LRC歌词制作:开源工具的终极实践指南
3步掌握LRC歌词制作:开源工具的终极实践指南 【免费下载链接】lrc-maker 歌词滚动姬|可能是你所能见到的最好用的歌词制作工具 项目地址: https://gitcode.com/gh_mirrors/lr/lrc-maker 还在为制作精准同步的歌词文件而烦恼吗?传统歌词…...

百度网盘直链解析工具:告别限速,3分钟实现全速下载!
百度网盘直链解析工具:告别限速,3分钟实现全速下载! 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 还在为百度网盘那令人抓狂的下载速度而…...

第一卷第4章:接口而非实现编程
第一卷第4章:接口而非实现编程 目录介绍 00.先回答上篇思考题 0.1 上篇遗留三道题 0.2 云迁移6万行代码 0.3 五次反转补锅 0.4 灵魂五连问 01.从一个搬迁切入 1.1 上云搬迁案例...