动手学深度学习:1.线性回归从0开始实现
动手学深度学习:1.线性回归从0开始实现
- 1.手动构造数据集
- 2.小批量读取数据集
- 3.初始化模型参数
- 4.定义模型和损失函数
- 5.小批量随机梯度下降更新
- 6.训练
- 完整代码
1.手动构造数据集
根据带有噪声的线性模型构造一个人造数据集,任务是使用这个有限样本的数据集来恢复这个模型的参数。
我们使用线性模型参数 w = [ 2 , − 3.4 ] T w = [2,−3.4]^T w=[2,−3.4]T , b = 4.2 b = 4.2 b=4.2 和噪声项 ϵ \epsilon ϵ 生成数据集及其标签:
y = X w + b + ϵ y = Xw + b + \epsilon y=Xw+b+ϵ
def synthetic_data(w, b, num_examples):"""生成y=Xw+b+噪声"""X = torch.normal(0, 1, (num_examples, len(w)))y = torch.matmul(X, w) + by += torch.normal(0, 0.01, y.shape) # 加上均值为0,标准差为0.01的噪声return X, y.reshape((-1, 1))true_w = torch.tensor([2, -3.4])
true_b = 4.2
features, labels = synthetic_data(true_w, true_b, 1000)
features中的每一行都包含一个二维数据样本, labels中的每一行都包含一维标签值(一个标量)
print('features:', features[0],'\nlabel:', labels[0])
'''
features: tensor([ 0.2589, -0.6408])
label: tensor([6.8837])
'''
2.小批量读取数据集
定义一个函数, 该函数能打乱数据集中的样本并以小批量方式获取数据。下面的``data_iter函数接收批量大小、特征矩阵和标签向量作为输入,生成大小为batch_size`的小批量。 每个小批量包含一组特征和标签。
def data_iter(batch_size, features, labels):num_examples = len(features)indices = list(range(num_examples))# 这些样本是随机读取的,没有特定的顺序random.shuffle(indices)for i in range(0, num_examples, batch_size):batch_indices = torch.tensor(indices[i: min(i + batch_size, num_examples)])yield features[batch_indices], labels[batch_indices]
直观感受一下小批量运算:读取第一个小批量数据样本并打印。 每个批量的特征维度显示批量大小和输入特征数。 同样的,批量的标签形状与batch_size相等。
batch_size = 10for X, y in data_iter(batch_size, features, labels):print(X, '\n', y)break'''
tensor([[ 0.9738, 0.9875],[-0.8015, -0.2927],[ 0.1745, 0.2918],[ 1.7484, 0.5768],[ 1.1637, 0.6903],[ 0.6840, 0.3671],[ 0.1465, 0.6662],[-1.8122, 0.4852],[ 1.0590, -0.0379],[-0.9164, -0.4059]]) tensor([[ 2.7853],[ 3.5814],[ 3.5564],[ 5.7416],[ 4.1774],[ 4.3218],[ 2.1962],[-1.0674],[ 6.4454],[ 3.7395]])
'''
3.初始化模型参数
通过从均值为0、标准差为0.01的正态分布中采样随机数来初始化权重, 并将偏置初始化为0。
w = torch.normal(0, 0.01, size=(2,1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
在初始化参数之后,我们的任务是更新这些参数,直到这些参数足够拟合我们的数据。 每次更新都需要计算损失函数关于模型参数的梯度。 有了这个梯度,我们就可以向减小损失的方向更新每个参数。
4.定义模型和损失函数
我们必须定义模型,将模型的输入和参数同模型的输出关联起来。要计算线性模型的输出, 我们只需计算输入特征 X X X 和模型权重 w w w 的矩阵-向量乘法后加上偏置 b b b。注意,上面的 X w Xw Xw 是一个向量,而 b b b 是一个标量,由于广播机制: 当我们用一个向量加一个标量时,标量会被加到向量的每个分量上。
def linreg(X, w, b):"""线性回归模型"""return torch.matmul(X, w) + b
因为需要计算损失函数的梯度,所以我们应该先定义损失函数。这里使用平方损失函数。
def squared_loss(y_hat, y): """均方损失"""return (y_hat - y.reshape(y_hat.shape)) ** 2 / 2
5.小批量随机梯度下降更新
小批量随机梯度下降在每一步中,使用从数据集中随机抽取的一个小批量,然后根据参数计算损失的梯度。接下来,朝着减少损失的方向更新我们的参数。
下面的函数实现小批量随机梯度下降更新。 该函数接受模型参数集合、学习速率和批量大小作为输入。
因为我们计算的损失是一个批量样本的总和,所以我们用批量大小(batch_size) 来规范化步长,这样步长大小就不会取决于我们对批量大小的选择。
def sgd(params, lr, batch_size):"""小批量随机梯度下降"""with torch.no_grad():for param in params: # [w,b]param -= lr * param.grad / batch_sizeparam.grad.zero_()
6.训练
在每次迭代中,我们读取一小批量训练样本,并通过我们的模型来获得一组预测。 计算完损失后,我们开始反向传播,存储每个参数的梯度。 最后,我们调用优化算法sgd来更新模型参数。
在每个迭代周期(epoch)中,我们使用data_iter函数遍历整个数据集, 并将训练数据集中所有样本都使用一次(假设样本数能够被批量大小整除)。 这里的迭代周期个数num_epochs和学习率lr都是超参数,分别设为3和0.03。
lr = 0.03
num_epochs = 3
net = linreg
loss = squared_loss
for epoch in range(num_epochs):for X, y in data_iter(batch_size, features, labels):l = loss(net(X, w, b), y) # X和y小批量损失# 因为l形状是(batch_size,1),而不是一个标量。l中的所有元素被加到一起,# 并以此计算关于[w,b]的梯度l.sum().backward()sgd([w, b], lr, batch_size) # 使用梯度更新参数with torch.no_grad(): # 查看整体损失值是否下降train_l = loss(net(features, w, b), labels)print(f'epoch {epoch + 1}, loss {float(train_l.mean()):f}')'''
epoch 1, loss 0.039035
epoch 2, loss 0.000149
epoch 3, loss 0.000050
'''
通过比较真实参数和通过训练学到的参数来评估训练的成功程度:
print(f'w的估计误差: {true_w - w.reshape(true_w.shape)}')
print(f'b的估计误差: {true_b - b}')
'''
w的估计误差: tensor([ 0.0006, -0.0011], grad_fn=<SubBackward0>)
b的估计误差: tensor([0.0007], grad_fn=<RsubBackward1>)
'''
完整代码
import random
import torch# 1.人为构造数据集
def synthetic_data(w, b, num_examples):"""生成y=Xw+b+噪声"""X = torch.normal(0, 1, (num_examples, len(w)))y = torch.matmul(X, w) + by += torch.normal(0, 0.01, y.shape)return X, y.reshape((-1, 1))true_w = torch.tensor([2, -3.4])
true_b = 4.2
features, labels = synthetic_data(true_w, true_b, 1000)
print('features:', features[0], '\nlabel:', labels[0])# 2.读取数据集
def data_iter(batch_size, features, labels):num_examples = len(features)indices = list(range(num_examples))random.shuffle(indices)for i in range(0, num_examples, batch_size):batch_indices = torch.tensor(indices[i: min(i + batch_size, num_examples)])yield features[batch_indices], labels[batch_indices]batch_size = 10
for X, y in data_iter(batch_size, features, labels):print(X, '\n', y)break# 3.初始化权重和偏置
w = torch.normal(0, 0.01, size=(2, 1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)# 4.定义模型定义模型和模型
def linreg(X, w, b):"""线性回归模型"""return torch.matmul(X, w) + b# 5.定义损失函数
def squared_loss(y_hat, y):"""均方损失"""return (y_hat - y.reshape(y_hat.shape)) ** 2 / 2# 6.定义优化算法
def sgd(params, lr, batch_size):"""小批量随机梯度下降"""with torch.no_grad():for param in params:param -= lr * param.grad / batch_sizeparam.grad.zero_()# 7.训练
lr = 0.03
num_epochs = 3
net = linreg
loss = squared_loss
for epoch in range(num_epochs):for X, y in data_iter(batch_size, features, labels):l = loss(net(X, w, b), y) # X和y小批量损失# 因为l形状是(batch_size,1),而不是一个标量。l中的所有元素被加到一起,# 并以此计算关于[w,b]的梯度l.sum().backward() # 求损失函数对参数sgd([w, b], lr, batch_size) # 使用梯度更新参数with torch.no_grad(): # 查看整体损失值是否下降train_l = loss(net(features, w, b), labels)print(f'epoch {epoch + 1}, loss {float(train_l.mean()):f}')print(f'w的估计误差: {true_w - w.reshape(true_w.shape)}')
print(f'b的估计误差: {true_b - b}')
相关文章:

动手学深度学习:1.线性回归从0开始实现
动手学深度学习:1.线性回归从0开始实现 1.手动构造数据集2.小批量读取数据集3.初始化模型参数4.定义模型和损失函数5.小批量随机梯度下降更新6.训练完整代码 1.手动构造数据集 根据带有噪声的线性模型构造一个人造数据集,任务是使用这个有限样本的数据集…...
【计算机网络】应用层
应用层协议原理 客户-服务器体系结构: 特点:客户之间不能直接通信;服务器具有周知的,固定的地址,该地址称为IP地址。 配备大量主机的数据中心常被用于创建强大的虚拟服务器;P2P体系结构: 特点&…...
python 深度学习 解决遇到的报错问题9
本篇继python 深度学习 解决遇到的报错问题8-CSDN博客 目录 一、can only concatenate str (not "int") to str 二、cant convert np.ndarray of type numpy.object_. The only supported types are: float64, float32, float16, complex64, complex128, int64, in…...
能源管理系统为什么选择零代码开发平台?
市面上有很多能源管理系统,但是零代码开发能源管理系统却非常少。那为什么推荐选择零代码开发平台呢?因为很多企业缺少技术人员,但是却仍然需要数字化工具和流程推进业务和项目,解决能源管理技术人员不懂代码的矛盾问题࿰…...
【LeetCode】剑指 Offer Ⅱ 第8章:树(12道题) -- Java Version
题库链接:https://leetcode.cn/problem-list/e8X3pBZi/ 类型题目解决方案二叉树的深搜剑指 Offer II 047. 二叉树剪枝递归(深搜):二叉树的后序遍历 (⭐)剑指 Offer II 048. 序列化和反序列化二叉树递归&…...
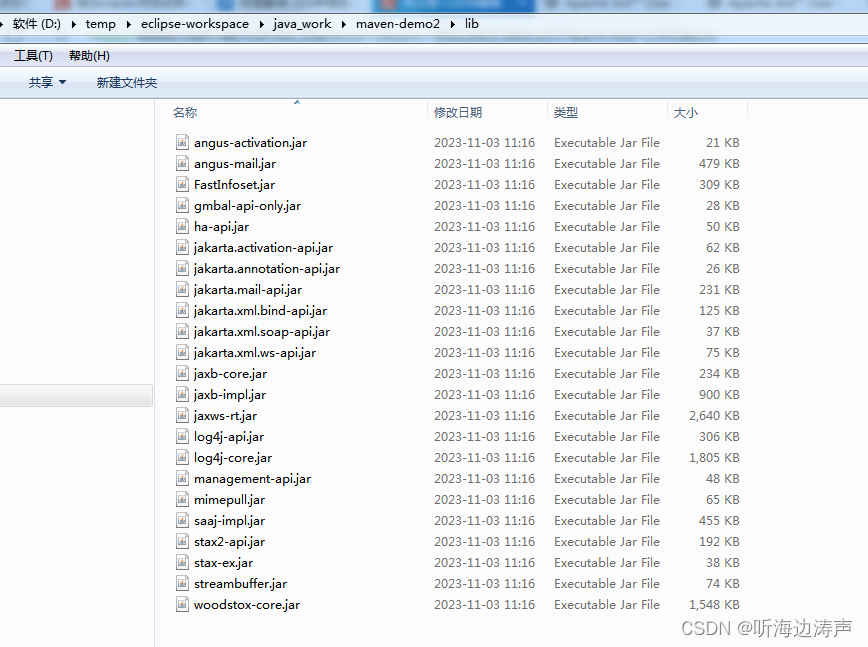
利用maven的dependency插件将项目依赖从maven仓库中拷贝到一个指定的位置
https://maven.apache.org/plugins/maven-dependency-plugin/copy-dependencies-mojo.html 利用dependency:copy-dependencies可以将项目的依赖从maven仓库中拷贝到一个指定的位置。 使用默认配置拷贝依赖 如果直接执行mvn dependency:copy-dependencies,是将项目…...

在Flask中实现文件上传七牛云中并下载
在Flask中实现文件上传和七牛云集成 文件上传是Web应用中常见的功能之一,而七牛云则提供了强大的云存储服务,使得文件存储和管理变得更加便捷。在本篇博客中,我们将学习如何在Flask应用中实现文件上传,并将上传的文件保存到七牛云…...
【Linux】centOS7安装配置及Linux的常用命令---超详细
一,centOS 1.1 centOS的概念 CentOS(Community Enterprise Operating System)是一个由社区支持的企业级操作系统,它是以Red Hat Enterprise Linux(RHEL)源代码为基础构建的。CentOS提供了一个稳定、可靠且…...
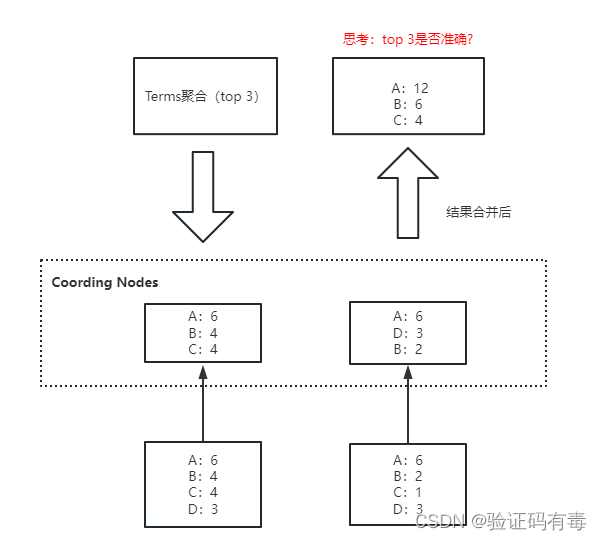
【ES专题】ElasticSearch搜索进阶
目录 前言阅读导航前置知识特别提醒笔记正文一、分词器详解1.1 基本概念1.2 分词发生的时期1.3 分词器的组成1.3.1 切词器:Tokenizer1.3.2 词项过滤器:Token Filter1.3.3 字符过滤器:Character Filter 1.4 倒排索引的数据结构 <font color…...
【iOS免越狱】利用IOS自动化WebDriverAgent实现自动直播间自动输入
1.目标 由于看直播的时候主播叫我发 666,支持他,我肯定支持他呀,就一直发,可是后来发现太浪费时间了,能不能做一个直播间自动发 666 呢?于是就开始下面的操作。 2.操作环境 iPhone一台 WebDriverAgent …...

Python基础入门例程28-NP28 密码游戏(列表)
最近的博文: Python基础入门例程27-NP27 朋友们的喜好(列表)-CSDN博客 Python基础入门例程26-NP26 牛牛的反转列表(列表)-CSDN博客 Python基础入门例程25-NP25 有序的列表(列表)-CSDN博客 目录…...

乌班图 Linux 系统 Ubuntu 23.10.1 发布更新镜像
Ubuntu 团队在其官网上发布了Ubuntu 23.10.1 版本,这是目前较新的 Ubuntu 23.10(Focal Fossa)操作系统系列的第一个发行版,旨在为社区提供最新的安装媒体。Ubuntu 22.04 LTS(Focal Fossa)操作系统系列于 2022 年 4 月 21 日发布。 Ubuntu 23.10 LTS(长期支持版本)可用…...
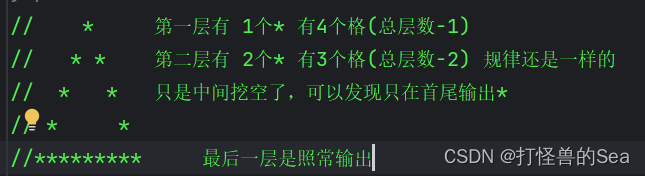
Java金字塔、空心金字塔、空心菱形
Java金字塔 public class TestDemo01 {public static void main(String[] args){//第一个for用于每行输出 从i1开始到i<5,总共5行for(int i1;i<5;i){//每行前缀空格,这个for用于表示每行输出*前面的空格//从上面规律可得,每行输出的空格数为总层数,…...

前端 | (十四)canvas基本用法 | 尚硅谷前端HTML5教程(html5入门经典)
文章目录 📚canvas基本用法🐇什么是canvas(画布)🐇替换内容🐇canvas标签的两个属性🐇渲染上下文 📚绘制矩形🐇绘制矩形🐇strokeRect时,边框像素渲染问题🐇添加…...
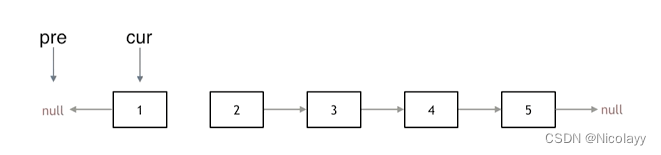
206.反转链表
206.反转链表 力扣题目链接(opens new window) 题意:反转一个单链表。 示例: 输入: 1->2->3->4->5->NULL 输出: 5->4->3->2->1->NULL 双双指针法: 创建三个节点 pre(反转时的第一个节点)、cur(当前指向需要反转的节点…...
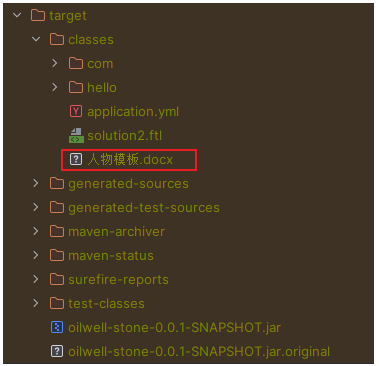
SpringBoot项目从resources目录读取文件
SpringBoot 从 resources 读取文件 使用 Spring 给我们提供的工具类来进行读取 File file org.springframework.util.ResourceUtils.getFile("classpath:人物模板.docx");可能读取失败,出现如下错误: java.io.FileNotFoundException: clas…...

SQL实现根据时间戳和增量标记IDU获取最新记录和脱IDU标记
需求说明:表中有 id, info, cnt 三个字段,对应的增量表多idu增量标记字段和时间戳字段ctimestamp。增量表中的 id 会有重复,其他字段 info、cnt 会不断更新,idu为增量标记字段,ctimestamp为IDU操作的时间戳。目的时要做…...

京东数据平台:2023年9月京东智能家居行业数据分析
鲸参谋监测的京东平台9月份智能家居市场销售数据已出炉! 9月份,智能家居市场销售额有小幅上涨。根据鲸参谋电商数据分析平台的相关数据显示,今年9月,京东平台智能家居的销量为37万,销售额将近8300万,同比增…...

计算两个时间之间连续的日期(java)
背景介绍 给出两个时间,希望算出两者之间连续的日期,比如时间A:2023-10-01 00:00:00 时间B:2023-11-30 23:59:59,期望得到的连续日期为2023-10-01、2023-10-02、… 2023-11-30 Java版代码示例 import java.time.temporal.ChronoUnit; import java.tim…...

Kali Linux:网络与安全专家的终极武器
文章目录 一、Kali Linux 简介二、Kali Linux 的优势三、使用 Kali Linux 进行安全任务推荐阅读 ——《Kali Linux高级渗透测试》适读人群内容简介作者简介目录 Kali Linux:网络与安全专家的终极武器 Kali Linux,对于许多网络和安全专业人士来说&#x…...

Windows电脑直接运行安卓应用:APK安装器完全指南
Windows电脑直接运行安卓应用:APK安装器完全指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾幻想过在Windows电脑上流畅运行安卓应用ÿ…...

终极指南:5分钟在Windows上配置JoyCon控制器驱动,解锁完整PC游戏体验
终极指南:5分钟在Windows上配置JoyCon控制器驱动,解锁完整PC游戏体验 【免费下载链接】JoyCon-Driver A vJoy feeder for the Nintendo Switch JoyCons and Pro Controller 项目地址: https://gitcode.com/gh_mirrors/jo/JoyCon-Driver 还在为Swi…...

别再折腾内网穿透了!用EC600N 4G模块+华为云IoTDA,5分钟搞定远程宠物定位数据上传
5分钟实现宠物定位数据上云:EC600N 4G模块与华为云IoTDA实战指南 当你的宠物突然从视线中消失时,那种焦虑感是任何宠物主人都深有体会的。传统的蓝牙防丢器仅有几十米的有效范围,而GPS定位器又常受限于复杂的网络配置。现在,通过…...

3分钟解锁音乐自由:ncmdump让网易云音乐NCM文件随处播放
3分钟解锁音乐自由:ncmdump让网易云音乐NCM文件随处播放 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 还在为网易云音乐下载的歌曲只能在特定客户端播放而烦恼吗?当您精心收藏的音乐被NCM加密格式束缚&…...

uni-app项目里遇到‘get’ of undefined?别慌,可能是Vue3条件编译惹的祸
uni-app开发中"get of undefined"错误深度解析:Vue3条件编译的隐秘陷阱 1. 错误现象背后的真相 当你在uni-app项目中看到控制台抛出Cannot read property get of undefined时,这种看似简单的类型错误往往隐藏着更深层的框架适配问题。不同于常…...

【亲测免费】 快递单PaddleOCR数据集:助力OCR技术研究与应用
快递单PaddleOCR数据集:助力OCR技术研究与应用 【下载地址】快递单PaddleOCR数据集 本仓库提供了一个专门用于PaddleOCR模型训练和测试的快递单数据集。该数据集包含了大量经过标注的快递单图像,适用于OCR技术的研究和开发 项目地址: https://gitcode.…...

3分钟搞定!Blender 3MF插件让你的3D打印工作流飞起来 [特殊字符]
3分钟搞定!Blender 3MF插件让你的3D打印工作流飞起来 🚀 【免费下载链接】Blender3mfFormat Blender add-on to import/export 3MF files 项目地址: https://gitcode.com/gh_mirrors/bl/Blender3mfFormat 还在为3D打印文件格式转换头疼吗…...

在 Elasticsearch 中使用带有确定性护栏的 Agentic AI 搜索,以实现安全的查询执行
作者:来自 Elastic Alexander Marquardt, Honza Krl 及 Taylor Roy 当 LLM 直接生成查询时, Agentic AI 搜索系统通常会失败。了解确定性护栏和控制平面架构如何通过 Elasticsearch 实现安全、可靠且受治理的查询执行。 刚接触 Elasticsearch࿱…...
GitGitHub实操图文详解教程(06)—git status命令)
(最新版)GitGitHub实操图文详解教程(06)—git status命令
版权声明 本文原创作者:谷哥的小弟 作者博客地址:http://blog.csdn.net/lfdfhl 1. 应用场景 git status 是 Git 中最常用的命令之一,用于查看当前仓库的状态。它能够告诉你: 当前所在分支 哪些文件被修改但未暂存 哪些文件已暂存但尚未提交 哪些文件未被 Git 跟踪 对于初学…...

内网手机远程桌面:解锁高效协同的数字密钥
在数字化办公与生活深度融合的当下,人们对于信息获取与设备操控的便捷性需求持续攀升。当我们身处内网环境,却渴望随时随地操控远端的电脑设备,内网手机远程桌面技术便如同一把精准的数字密钥,打破空间与网络的束缚,为…...