干货分享:基于 LSTM 的广告库存预估算法
近年来,随着互联网的发展,在线广告营销成为一种非常重要的商业模式。出于广告流量商业化售卖和日常业务投放精细化运营的目的,需要对广告流量进行更精准的预估,从而更精细的进行广告库存管理。
因此,携程广告纵横平台实践了LSTM(Long Short-Term Memory,长短时记忆网络)模型结合Embedding的广告库存预估深度学习算法,在节省训练资源的同时,构建更具泛化性的模型,支持根据不同地域分布、人口学属性标签等进行库存变动预估,并能体现出节假日特征对库存波动的影响,从而对广告库存进行更为精确的预估。
技术交流
技术要学会分享、交流,不建议闭门造车。一个人可以走的很快、一堆人可以走的更远。
相关文件及代码都已上传,均可加交流群获取,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、添加微信号:dkl88194,备注:来自CSDN + 加群
方式②、微信搜索公众号:Python学习与数据挖掘,后台回复:加群
问题和挑战
广告库存预估实现有诸多挑战:
-
现实中对广告库存的影响因素非常多,比如节假日、周末、自然灾害等等;
-
广告库存样本周期以天为单位,训练样本很少;
-
需要支持不同维度交叉进行广告预估,例如同时选择地域、年龄、性别、会员等级等定向交叉,预估未来N天的库存情况;
-
广告库存日新月异,随时间推移,不断有新的库存样本生成,模型更新频率要求较高。
这些因素让广告库存预估工作从资源和效率等角度都带来压力。
算法简述
RNN(Recurrent Neural Network,循环神经网络)是一种特殊的神经网络,被广泛应用于序列数据的建模和预测,如自然语言处理、语音识别、时间序列预测等领域。RNN对时间序列的数据有着强大的提取能力,也被称作记忆能力。相对于传统的前馈神经网络,RNN具有循环连接,可以将前一时刻的输出作为当前时刻的输入,从而使得网络可以处理任意长度的序列数据,捕捉序列数据中的长期依赖关系。
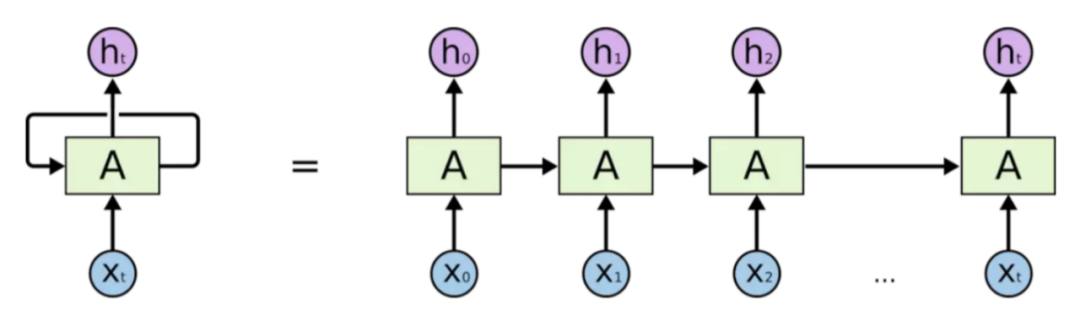
图 3-1
LSTM(Long Short-Term Memory,长短时记忆网络)是一种特殊的 RNN,它通过引入门控机制和记忆单元等结构来增强 RNN 的记忆能力和表达能力。
LSTM 的基本结构包括一个循环单元和三个门控单元:输入门、遗忘门和输出门。循环单元接受当前时刻的输入和前一时刻的输出作为输入,并输出当前时刻的输出和传递到下一时刻的状态。输入门控制当前时刻的输入对状态的影响,遗忘门控制前一时刻的状态对当前状态的影响,输出门控制当前状态对输出的影响。记忆单元则用于存储和传递长期的信息。基于此,使得LSTM具有长期的记忆能力,并且具有防止梯度消失的特点,故我们选择LSTM作为库存预估模型的训练基础。
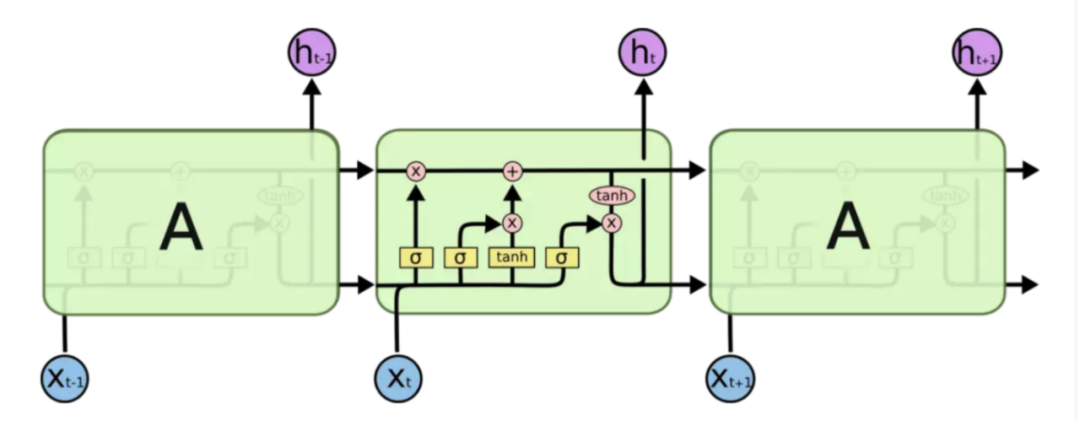
图 3-2
Embedding是一种特征处理方式,它可以将我们的某个特征数据向量化,可以将离散的整数序列映射为连续的实向量,它通常用于自然语言处理中的词嵌入(Word Embedding)任务,用于将每个单词映射为一个实向量,从而使得单词之间的语义关系可以在向量空间中进行计算。
在本文中,我们是使用它进行实体嵌入(Entity Embedding) 任务,也就是将我们的特征实体进行向量化,通过大量的数据训练,得到实体向量之前的细微关系,从而帮助模型更清晰的识别不同实体对广告库存的影响,进而提高模型的泛化能力。
数据处理
4.1 特征定义
基础特征为下图所示:
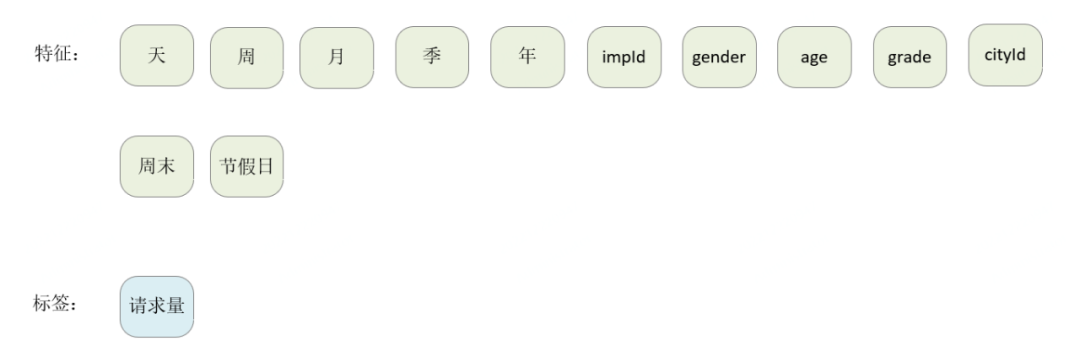
图 4-1
由于节假日的特殊性,我们又将其细分为以下维度,保证模型抓住节前和节后购票效应。

图 4-2
4.2 归一化
在深度学习中,对数据进行归一化主要目的是将数据缩放到一个合适的范围内,便于神经网络的训练和优化。对数据进行归一化可以改善梯度下降、加速收敛、提高模型的泛化能力。
我们选择Z-score标准化方法对数据进行处理,Z-score 标准化(也称为标准差标准化)是一种常见的数据归一化方法,其基本思想是将原始数据转换为标准正态分布,即均值为 0,标准差为 1。公式如下图所示,是一个实测值与平均数的差再除以标准差的过程。
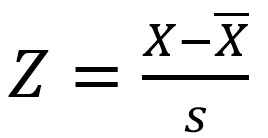
4.3 数据聚类
我们在第二章节问题和挑战中聊到过,广告库存预估需要对多个维度支持预估功能,不同维度交叉组合后,库存量千差万别,导致我们的样本数据中标签值min和max差距非常大。
如图4-3所示,本图Y轴表示某组合维度标签值的库存数据量级,库存数据量较小的组合维度占有很大一部分,而库存数据量较大的组合维度相对较少,仅凭数据归一化手段,数据压缩的效果非常不明显,如果强行一起训练会互相影响,导致模型难以拟合,训练中的损失函数如图4-4所示,训练时模型无法正常拟合,损失值不能够正常下降,训练出的模型效果可想而知,无法支持正常的预估功能。
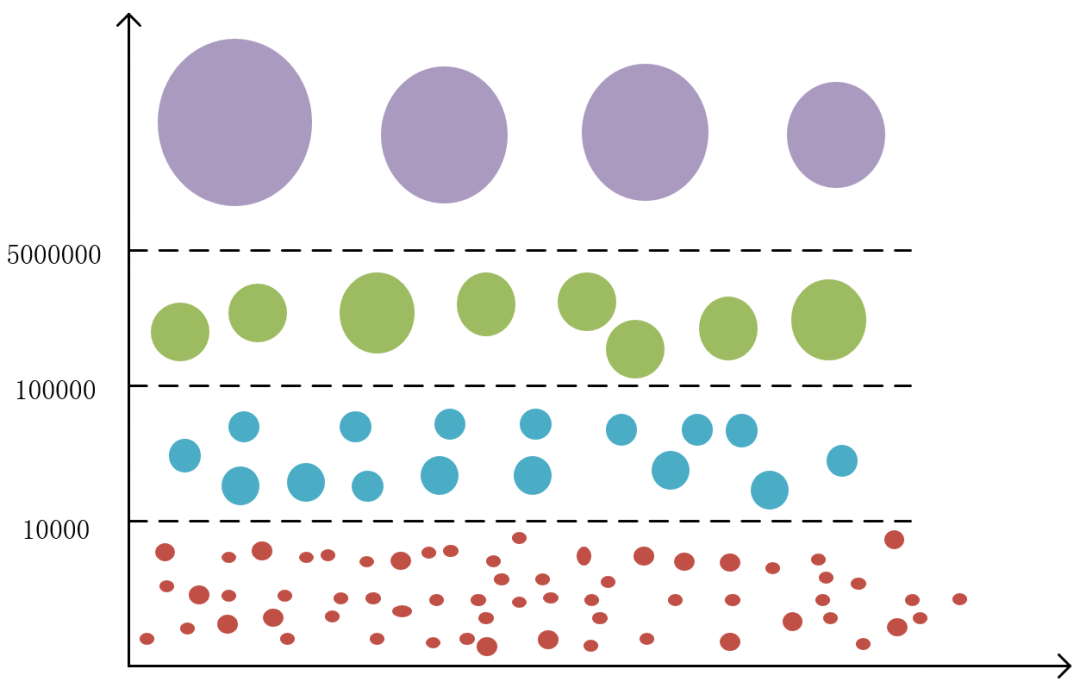
图 4-3
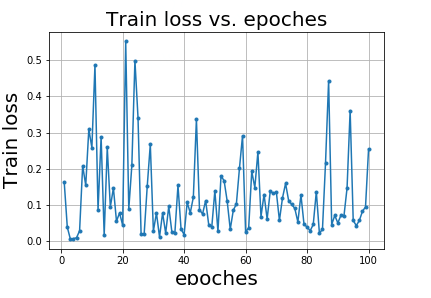
图 4-4
所以,我们以库存样本的标签值为依据,使用K-means算法对不同维度的库存进行数据聚类,将近似类别的维度放在一起进行训练,提高模型的拟合速度和泛化能力。
我们选择“肘部法则”来确认本数据集的最佳分类数,也就是K-means的簇数K的具体值。随着K的增加,聚类效果不断提高,但是当K到达某个值的时候,聚类效果的提高变得越来越慢,此时再增加K已经不能明显提高聚类效果,因此这个点就是最佳的K值。具体过程如下:
-
对数据集进行K-Means聚类,分别尝试不同的簇数K。
-
对于每个簇数K,计算该簇数下的SSE(Sum of Squared Errors),即每个数据点到其所属簇中心的距离的平方和,保存SSE 到数组。
-
使用numpy库中的diff函数计算相邻两点的差异并除以最大值,得到变化率。然后,我们使用numpy库中的argmax函数找到最大斜率的位置,加上n即为肘部点的位置。
-
n的取值要考虑自身数据集,一般来说,K的值至少要为2,不然没有分类意义,而且argmax计算出来的是数组的索引位置,小于真实位置1个点位,综合考虑,我们将n设置为2。
# 计算不同聚类个数下的聚类误差n = 2sse = []for k in range(1, 10):kmeans = KMeans(n_clusters=k, random_state=0).fit(data)sse.append(kmeans.inertia_)# 自动寻找肘部点diff = np.diff(sse)diff_r = diff[1:] / diff[:-1]nice_k = np.argmin(diff_r) + n
#绘制SSE随簇数变化的曲线(如图4-5),观察曲线的形状。plt.plot(range(1, 10), sse, 'bx-')plt.xlabel('Number of Clusters')plt.ylabel('SSE')plt.title('Elbow Method for Optimal k')plt.show()
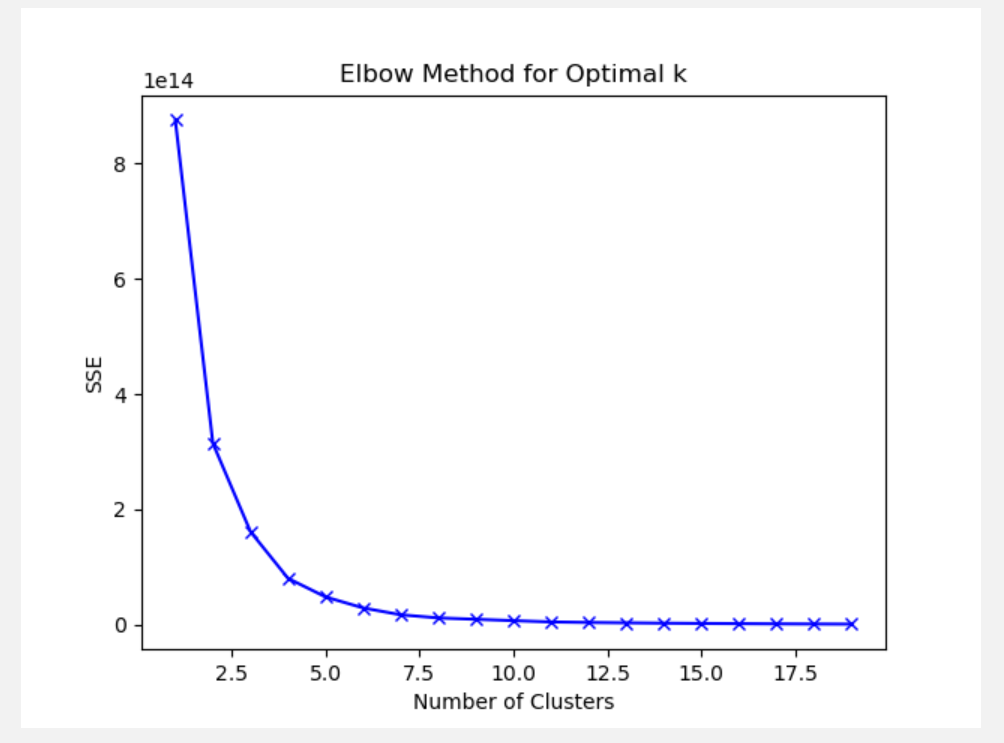
图 4-5
经过K值选择后,我们将样本数据集进行聚类得到如下图4-6所示结果,Y轴为某组合维度的标签值,X轴为某组合维度出现在样本数据集数组中的索引位置。其中最右侧最高的点,明显是没有任何维度交叉的全部广告库存,其他位置都是经过维度交叉后的库存,最终我们将其分成了3份进行训练。
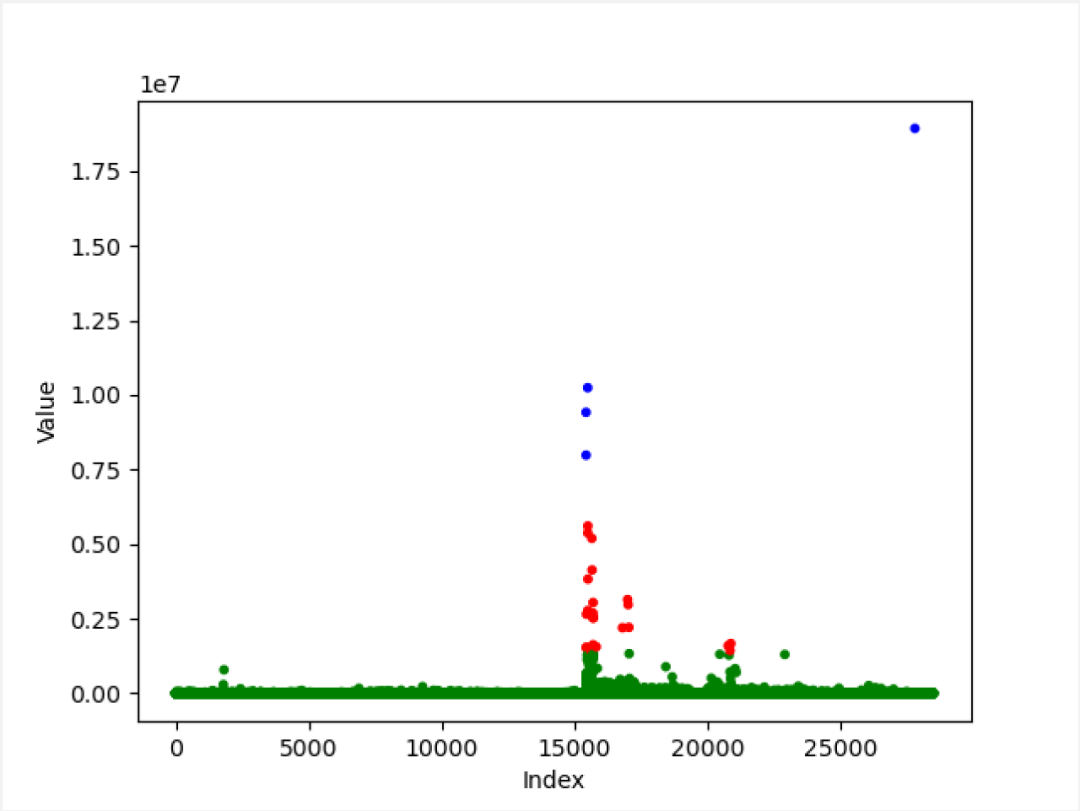
图 4-6
经过聚类处理后,模型训练时损失函数输出的损失值如下图所示,出现了正常的损失值下降的过程,并逐渐趋于稳定。
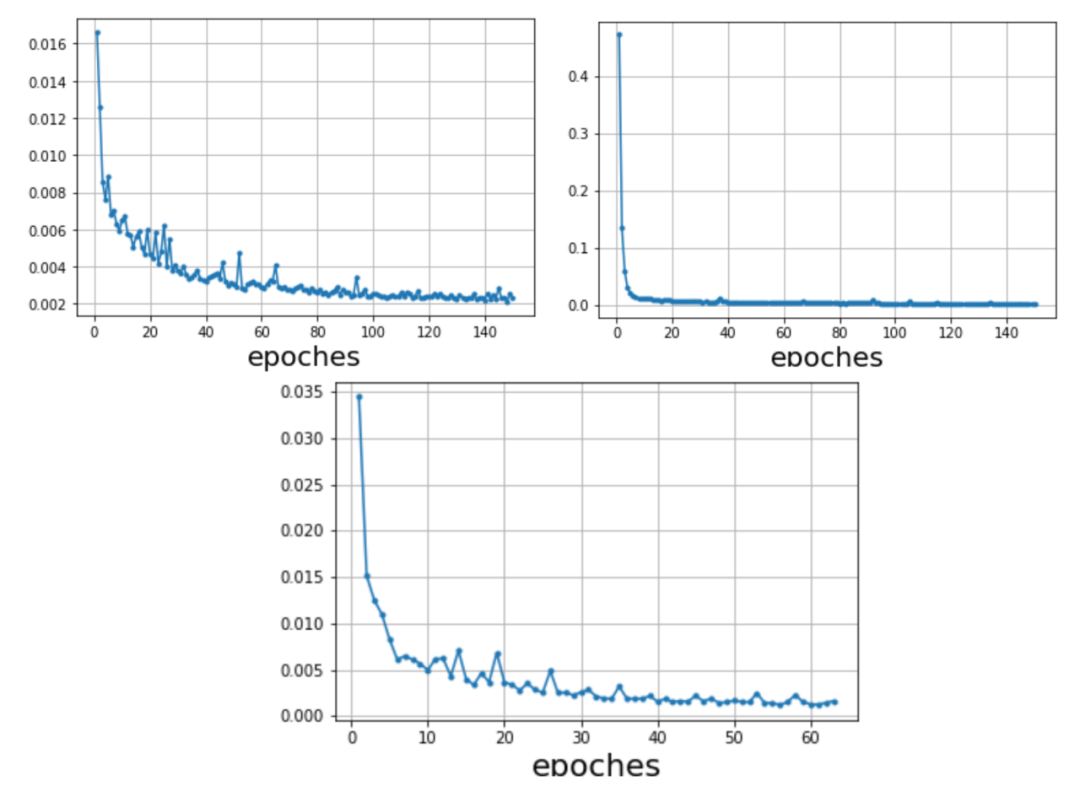
图 4-7
五、网络结构定义与训练
5.1 网络结构定义
1)网络模型结构图
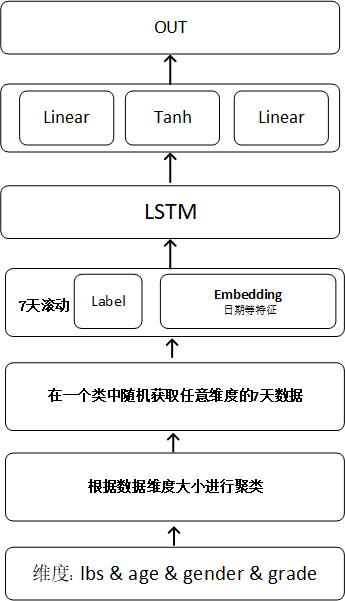
图 5-1
2)网络模型定义
我们将各维度组装特征数据和标签数据的数据经过Embedding 实体嵌入,输入到LSTM学习并提取历史库存的时间序列特性,最终经过激活函数和全连接层输出与标签值进行损失值计算,不断拟合,直到损失值接近稳定或到达最大训练批次。
import torch
from torch import nnclass LSTM(nn.Module):def __init__(self, emb_dims, out_dim, hidden_dim, mid_layers):super(LSTM, self).__init__()self.emb_layers = nn.ModuleList([nn.Embedding(x, y) for x, y in emb_dims])self.rnn = nn.LSTM([sum(x) for x in zip(*emb_dims)][1] + 1, hidden_dim, mid_layers, batch_first=False)self.reg = nn.Sequential(nn.Linear(hidden_dim, hidden_dim),nn.Tanh(),nn.Linear(hidden_dim, out_dim),)def forward(self, cat_data):var_x = []for cat in cat_data:x = self.emb_layer(cat)var_x.append(x)stack = torch.stack(var_x)y = self.rnn(stack)return y
5.2 训练
1)组织数据
我们获取任意维度历史N天数据作为训练集,如下图所示,我们设定滑动窗口时间为七天,定义广告请求数为标签数据。使用DataLoader组织数据,shuffle设为True保证样本是随机获取的,仅需保证滑动窗口内部有序即可,这样训练可以提高模型的泛化能力。
loader = Data.DataLoader(dataset=set, batch_size=size, shuffle=True, num_workers=numWorkers)
需要注意的是,LSTM要求的入参顺序为(seq_length, batch_size, input_size)即:序列长度、批次量数、特征维度,然而DataLoade组织出的数据第一个维度是batch_size,因此设置batch_first = true,即可解决问题,继续正常的使用LSTM模型训练数据。但是这会拉低训练效率,原因是NVIDIA cuDNN 的RNN API 设置的batch_size参数就是在第二个位置,这样设置的原因如下:
举个例子1,假设输入序列的长度seq_length等于3,batch_size等于2,假设一个batch的数据是[[“A”, “B”, “C”], [“D”, “E”, “F”]],如图5-2所示。由于RNN是序列模型,只有T1时刻计算完成,才能进入T2时刻,而"batch"就体现在每个时刻Ti的计算过程中,图1中T1时刻将[“A”, “D”]作为当前时刻的batch数据,T2时刻将[“B”, “E”]作为当前时刻的batch数据,可想而知,“A"与"D"在内存中相邻比"A"与"B"相邻更合理,这样取数据时才更高效。
而不论Tensor的维度是多少,在内存中都以一维数组的形式存储,batch first意味着Tensor在内存中存储时,先存储第一个sequence,再存储第二个… 而如果是seq_length first,模型的输入在内存中,先存储所有sequence的第一个元素,然后是第二个元素… 两种区别如图5-3所示,seq_length first意味着不同sequence中同一个时刻对应的输入元素(比如"A”, “D” )在内存中是毗邻的,这样可以快速读取数据。
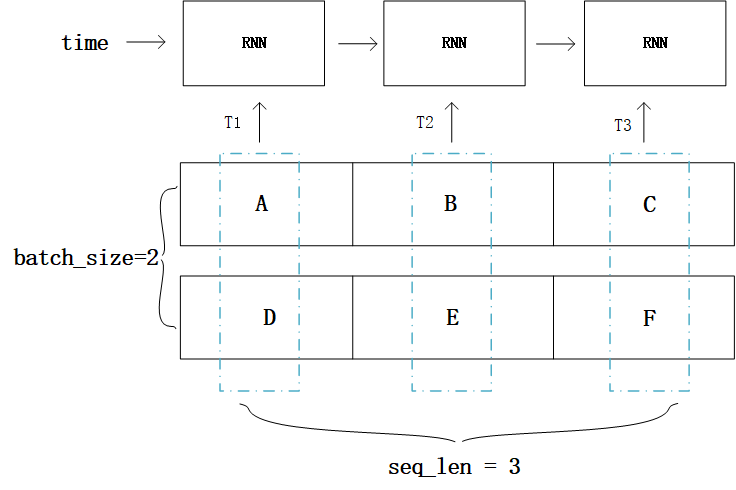
图 5-2
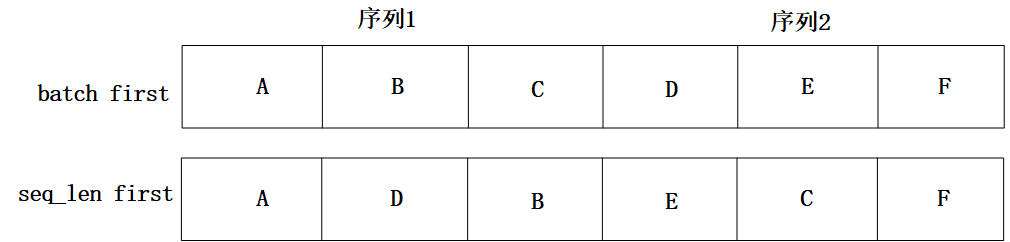
图 5-3
因此,使用batch_first = true并不是好的选择,可以选择permute函数解决此问题:
batch_x = batch_x.permute((1, 0, 2))
使用此方法改变数组的shape,以适应原始LSTM模型的入参要求,在不影响训练速度的原则下解决参数顺序问题。
2)训练步骤
输入: 任意维度前七天组成的窗口数据,包括所有的特征数据 + 标签数据
输出: 第八天的标签数据
第N步
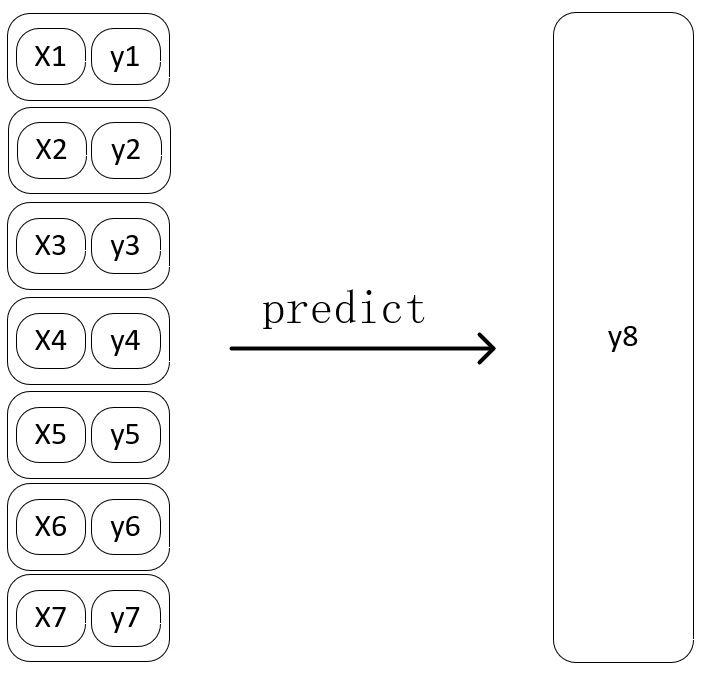
图 5-4
第N+1步:
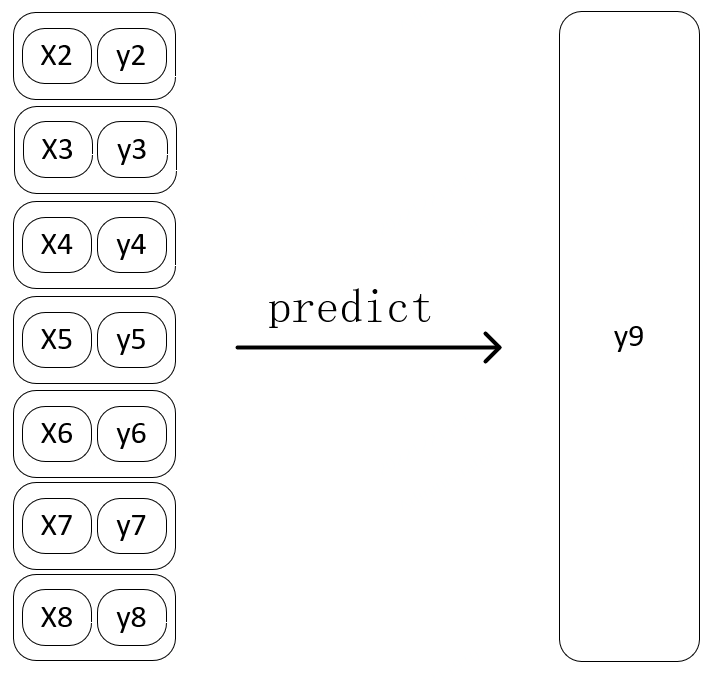
图 5-5
3)离线与在线增量训练
第二章节问题和挑战中提到,由于广告样本数据每天都在产生,而且影响其因素非常多,所以历史模型仅凭历史库存学到的时间序列特性预估出的未来库存,除了可以带有假期周末等时间特征的正向影响外,很难紧跟近期的库存数量级。
所以,这要求我们要高频次的更新广告库存预估模型,但这也加大了维护成本,如果仅采用离线训练的方式,每次都拉取全量历史库存样本数据训练出新的优质模型,无疑是不可取的,所以我们选择一次离线训练+N次在线增量训练的方式解决此问题。
a. 离线训练
首先使用Spark Sql组织广告库存Hive表中现存所有的历史数据导入CSV文件,使用GPU训练此样本数据,由于是各维度交叉训练,一般在这个阶段数据量在亿级别,如果资源有限,离线训练可以拆分广告位分别进行。经过多次训练选择优质的离线模型文件,作为基础预估模型,可以用于短期的库存预估工作。此时我们需要将优质模型以字节的形式存储至Redis,便于后面的预估服务和在线训练脚本使用。
此时需要注意的是,我们需要将模型和优化器打包为一个字典,以二进制的方式读取模型文件并保存在Redis中。
#保存模型:
#net:模型
#optimizer:优化器state = {'net': net.state_dict(), 'optimizer': optimizer.state_dict()}
torch.save(state, netPath)#存储至Redis:
def saveModel(modelName, netPath):with open(modelPath, "rb") as f:pth_model = f.read()result = redis.set(modelName, pth_model)
b. 在线训练:经过离线训练后,我们得到了一个优质的预估模型,此时我们需要开发两个脚本:
① PySpark 拉取hive表中昨天的库存样本存储在GPU机器实时文件目录。
② 读取实时文件目录,获取近八个文件,前七个作为一个滑动窗口数据,第八个作为标签值组成单次训练样本,在Redis中获取并加载预存的模型和优化器,进行一次在线训练,再将其覆盖保存至redis中。
# 在Redis中加载模型
def readModel(modelName, path):pthByte = redis.get(modelName)with open(path, 'wb') as f:f.write(pthByte)return torch.load(path, map_location=lambda storage, loc: storage)# 加载模型和优化器状态,用于训练# 读取字典
model = readModel(modelName, path)# 加载模型
net = LSTM(emb_dims, out_dim, mid_dim, mid_layers).to(device)
net.load_state_dict(model['net'])# 加载优化器
optimizer = torch.optim.Adam(net.parameters(), lr=1e-2)
optimizer.load_state_dict(model['optimizer'])
最终,我们将以上两个脚本配置在携程大数据定时任务,设置每天0点后执行,即可实现不断的在线训练,保证模型在优质状态的基础上,使用最新的库存数据对模型进行微调修正,使用Redis保存模型可以快速存取模型文件流,保证在线训练结束后,预估服务可以立刻反应,获取到新的模型用于预估工作,无需对预估服务做任何改动。根据以上方案可以不断维持模型提供精准的预估能力。
4)早停机制
训练过程中,为防止过拟合,也为提高效率,当loss 不再明显变化时终止训练,输出模型,每次训练不断记录并更新loss最小值,当loss 连续N次小于x时,视为可触发早停机制。
class EarlyStopping:def __call__(self, val_loss):score = val_lossif self.best_score is None:self.best_score = scoreelif score > self.best_score:if score <= x:self.counter += 1if self.counter >= self.patience:self.early_stop = Trueelse:self.best_score = scoreself.counter = 0
下图为早停效果图,设置的训练批次为150批, 此模型训练至115批截至,可以观察到loss已经非常低, 已经没有下降空间,符合早停预期。
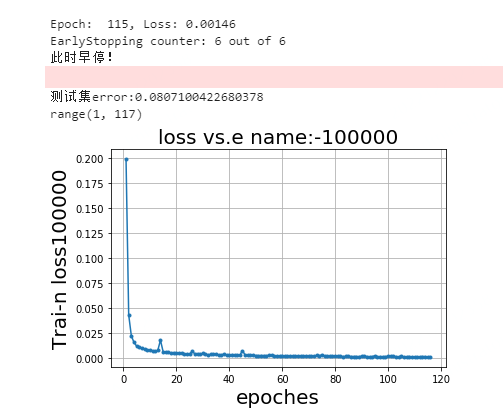
图 5-6
5)指标验证
经过模型的构建和训练后,我们需要对模型做出评估,以决定模型是否可以推到线上使用,因为基础数据量较小,所以本次模型未设置验证集,训练集和测试集 9 :1。评估指标采用WMAPE(加权偏差率):
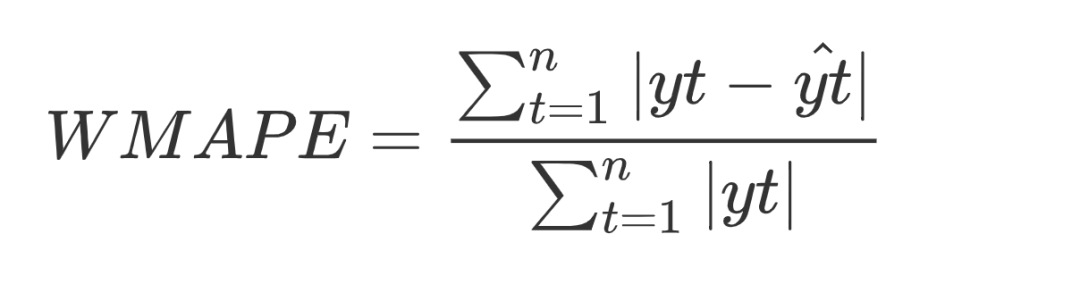
TorchMetrics 类库对80 多个PyTorch 指标做了实现.
这里我们直接调用api : WeightedMeanAbsolutePercentageError
import torchmetricserror = torchmetrics.WeightedMeanAbsolutePercentageError()
# 调用模型得到预估值
predict = net(valid_x)
# 计算偏差
error = error(predict, valid_y)
error_list.append(error.item())
指标验证可以更科学的观察到模型对所有维度的测试集的预估能力, 可以更科学的验证模型是否符合我们的预期,指导我们进行调参,控制唯一变量并观察指标变化。某广告位置调参验证示例如下, 比较不同批次训练模型后指标比较, 明显表现出200批次的模型指标更好。
Group Model 1: 150批次 测试集ERROR: 0.09729844331741333 200批次 测试集ERROR: 0.08846557699143887
Group Model 2: 150批次 测试集ERROR: 0.10297603532671928 200批次 测试集ERROR: 0.09801376238465309
Group Model 3: 150批次 测试集ERROR: 0.0748182088136673 200批次 测试集ERROR: 0.07573202252388
6)内存释放
在大数据量的深度神经网络训练过程中,内存是我们的一大瓶颈,在组织数据过程中,python的List由于不能确定其存储内容的数据类型,不支持快速切割结构,我们经常需要将List转换为数组再做处理,此时需要copy一份数据,那么List就成了闲置内存,这种类似的闲置内存我们可以操作主动释放,以快速释放无用内存,让我们的机器可以在有限的内存空间中支持更大数据量的训练。
不同的数据类型的释放方式如下(假设变量名称为 X ):
# 1、List
del X[:]
# 2、数组
X = []
# 3、字典
X.clear()
# 4、Tensor(此方式需要调用gc.collect()触发GC才可以真正清除内存)
del X
# 5、清理CUDA显存
import torch
torch.cuda.empty_cache()
下图5-7为训练过程中主动释放内存操作后,得到的内存释放监控反馈。
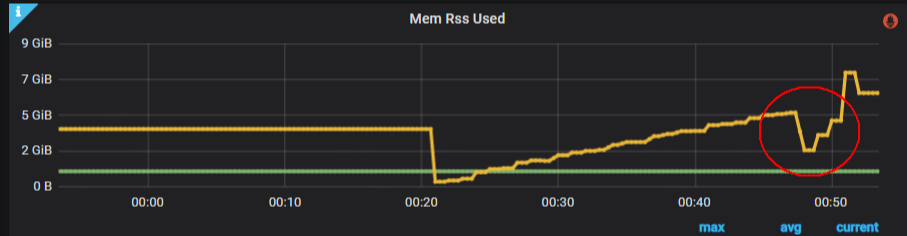
图 5-7
5.3 预估验证
1)历史预估
整体模型训练完成,需要对模型做预估测试,我们选择2022年的10月作为测试样本,10月1日国庆节有特殊的节假日特性,可以考量模型预估能力。以携程启动页广告位为例,图 5-8 分别展示了全量库存、某特征定向和两种会员等级定向不同维度的预估效果,都成功表达出10月1日的节假日上涨特性,与实际值的走势相似,证明我们训练出的模型具有预估未来广告库存的能力。
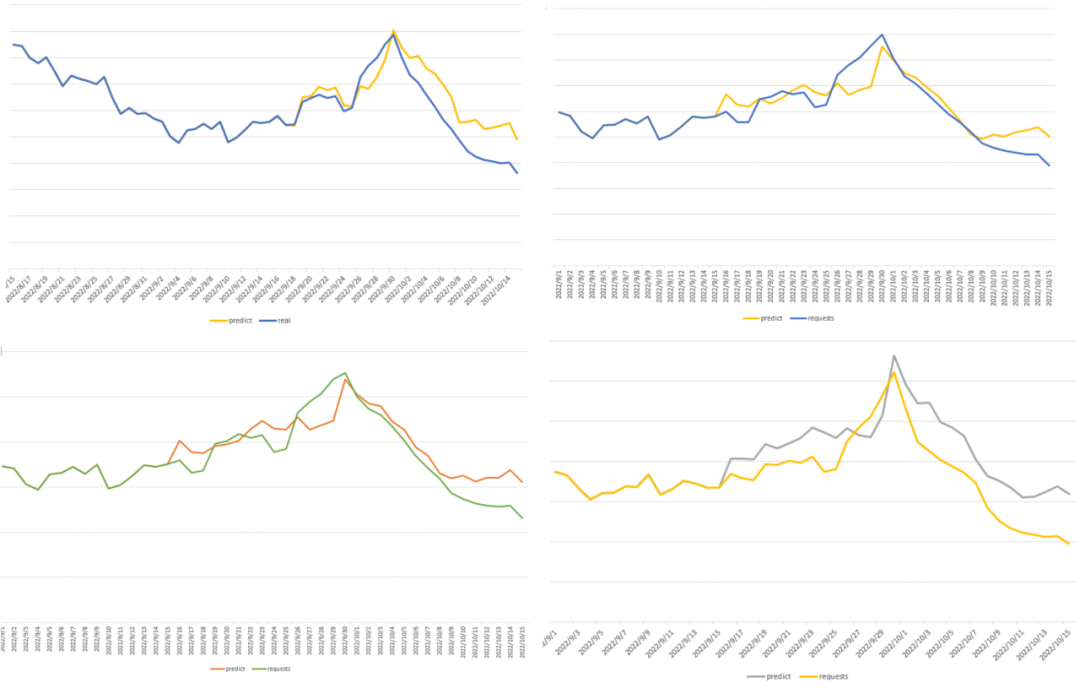
图 5-8
2)未来预估
以下是对未来库存的预估效果示例,从未来预估示例中,可以直观看出在4月26-29左右有流量的高峰,经过5月1日后高峰下跌,回归正常值,符五一的节假日效应。
图5-9 定向交叉为:某年龄段、某地
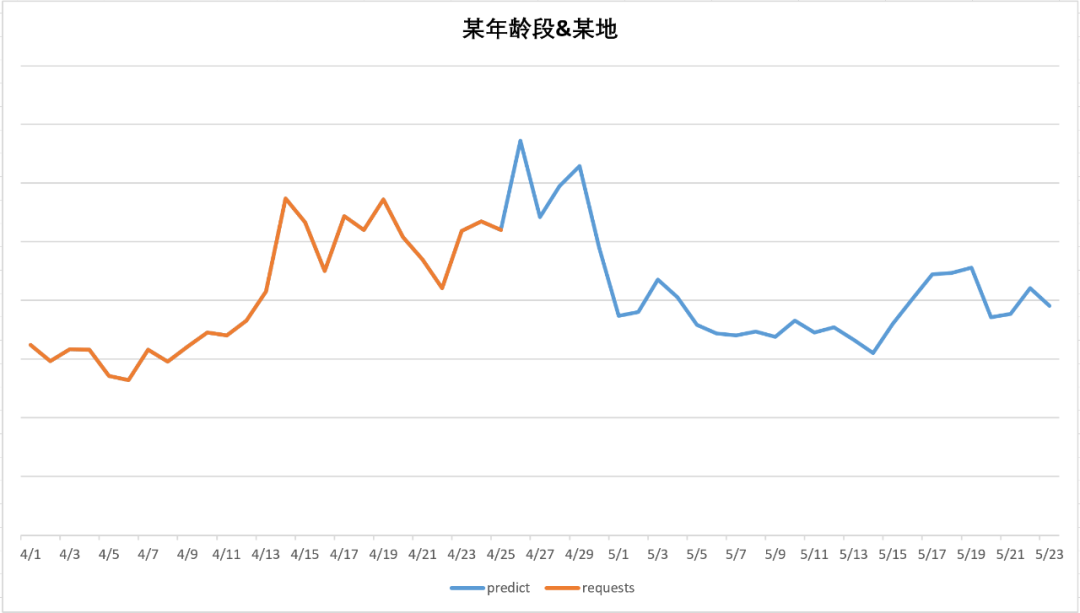
图 5-9
图5-10 定向交叉为:某年龄段、某类会员
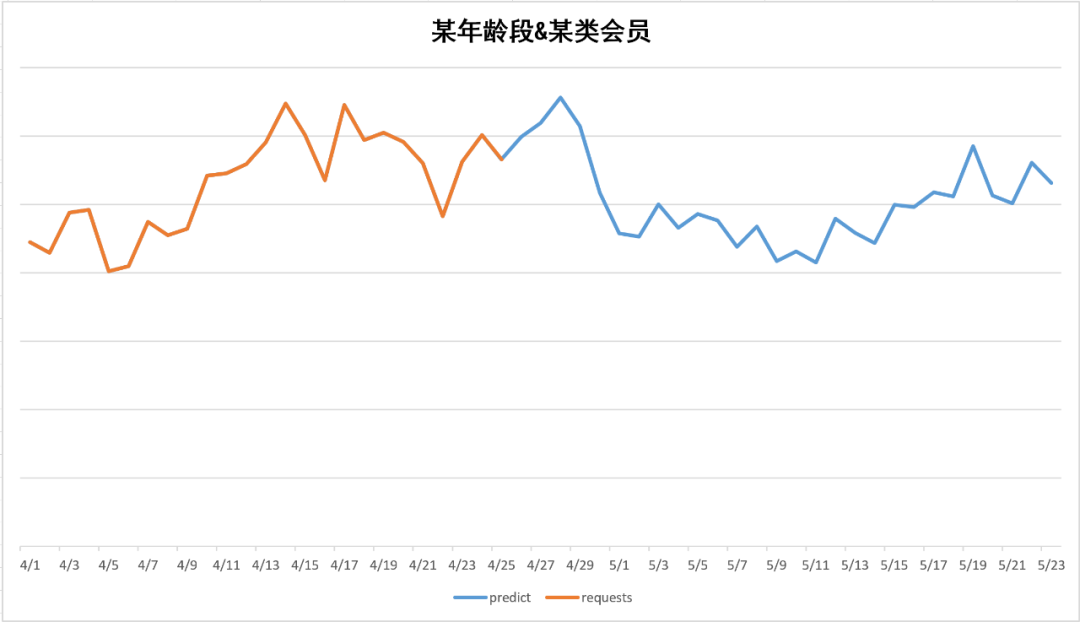
图 5-10
图5-11 定向交叉为:某地、某类会员
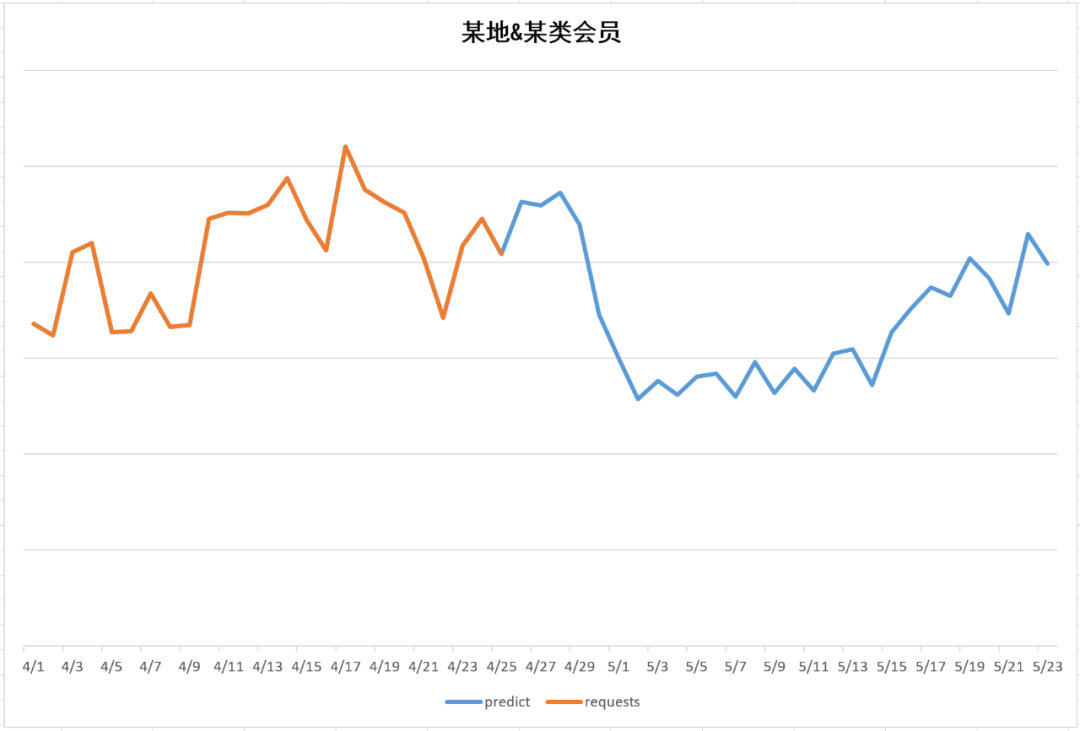
图 5-11
六、模型部署
6.1 python 服务部署
使用python flask组件开发部署restful接口,支持预估服务。
from flask import Flask
from flask import request, jsonify@app.route('/model/ad/forecast', methods=['post'])
def forecast():# 在clickhouse中实时获取前七天的标签值,传入接口prepareData = request.json.get('prepareData')return forecast(prepareData)
从Redis中读取对应维度的模型文件流,加载到内存生成模型对象,将前7天的标签值和对应其他特征组织好输入模型得到预估结果。
# 在Redis中加载模型def readModel(modelName, path):pthByte = redis.get(modelName)with open(path, 'wb') as f:f.write(pthByte)return torch.load(path, map_location=lambda storage, loc: storage)
七、总结
通过使用LSTM算法结合Embedding特征处理方式训练得到优质的广告库存预估模型,能够捕捉库存时间样本数据中的长期依赖关系,表达节假日、周末等特殊时间点对库存变化的影响,更具泛化能力,支持地域、年龄、会员等级、性别等定向交叉预估,对比早期使用全量库存乘以定向比例的预估库存方式,此方式更能体现出不同维度之间的相互影响关系,更贴近事实,预估准确度高。
使用离线与在线增量训练相结合的训练方式,使模型更具活力,每天在优选出的广告库存模型基础上进行微调,可以不断维持模型提供精准的预估能力。后续我们会继续优化和探索更优秀的模型和特征处理方式,优化方向考虑在Embedding层 与 LSTM 层之间增加CNN 卷积层,提高模型的特征提取能力,进而提高广告库存模型的泛化能力、预估精准度。
相关文章:
干货分享:基于 LSTM 的广告库存预估算法
近年来,随着互联网的发展,在线广告营销成为一种非常重要的商业模式。出于广告流量商业化售卖和日常业务投放精细化运营的目的,需要对广告流量进行更精准的预估,从而更精细的进行广告库存管理。 因此,携程广告纵横平台…...

dataframe删除某一列
drop import pandas as pd data {‘A’: [1, 2, 3], ‘B’: [4, 5, 6], ‘C’: [7, 8, 9]} df pd.DataFrame(data) #使用drop方法删除列 df df.drop(‘B’, axis1) # 通过指定列名和axis1来删除列 del import pandas as pd data {‘A’: [1, 2, 3], ‘B’: [4, 5, 6]…...

提升ChatGPT答案质量和准确性的方法Prompt engineering
文章目录 怎么获得优质的答案设计一个优质prompt的步骤:Prompt公式:示例怎么获得优质的答案 影响模型回答精确度的因素 我们应该知道一个好的提示词,要具备一下要点: 清晰简洁,不要有歧义; 有明确的任务/问题,任务如果太复杂,需要拆分成子任务分步完成; 确保prompt中…...
SpringBoot + Vue2项目打包部署到服务器后,使用Nginx配置SSL证书,配置访问HTTP协议转HTTPS协议
配置nginx.conf文件,这个文件一般在/etc/nginx/...中,由于每个人的体质不一样,也有可能在别的路径里,自己找找... # 配置工作进程的最大连接数 events {worker_connections 1024; }# 配置HTTP服务 http {# 导入mime.types配置文件…...

HTML 表格
<!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>表格标签</title>/* <style>.yun {widt…...
试用 10 -- 安全性问题)
AIGC(生成式AI)试用 10 -- 安全性问题
上次遗留的问题:代码的安全性呢?下次找几个问题测试下看。 AI,你安全吗? AI生成的程序,安全吗? 也许这个世界最难做的事就是自己测试自己:测试什么?如何测? …...
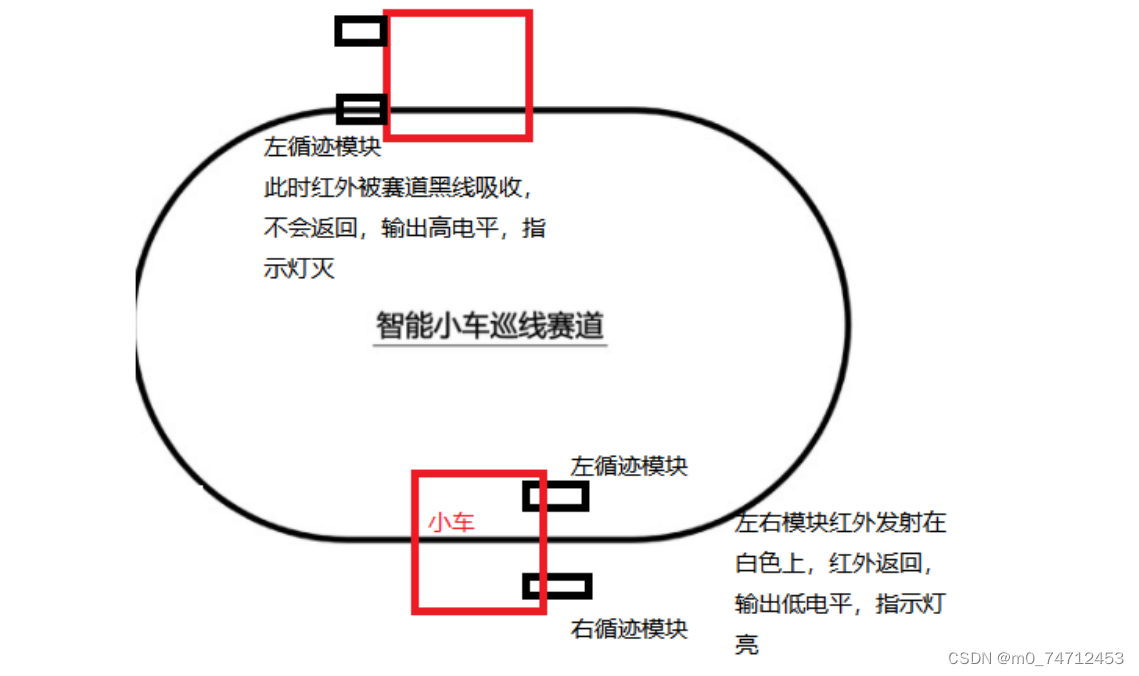
STM32循迹小车原理介绍和代码示例
目录 1. 循迹模块介绍 2. 循迹小车原理 3. 循迹小车核心代码 4. 循迹小车解决转弯平滑问题 1. 循迹模块介绍 TCRT5000传感器的红外发射二极管不断发射红外线当发射出的红外线没有被反射回来或被反射回来但强度不够大时红外接收管一直处于关断状态,此时模块的输出…...

Nginx 配置详细讲解
Nginx.conf 配置文件分为三部分,分别为main块、events块、http块(http块又包含server块和location块),如下图。 第一部分:main块(全局块) main块主要是设置一些影响Nginx服务器整体运行的配置指令,主要包括…...
)
gdb 日志记录不显示到屏幕的方法(gdb13最新版)
tags: gdb categories: [Debug] 写在前面 gdb 的更新好快啊… 之前的选项都有改动了, 比如 logging… 需要屏幕重定向不能简单设置: set logging on set logging redirect on了, 而是要多开一个配置, 踩坑了 方法 在此之前先看一下我的 gdbinit 配置: set debuginfod e…...
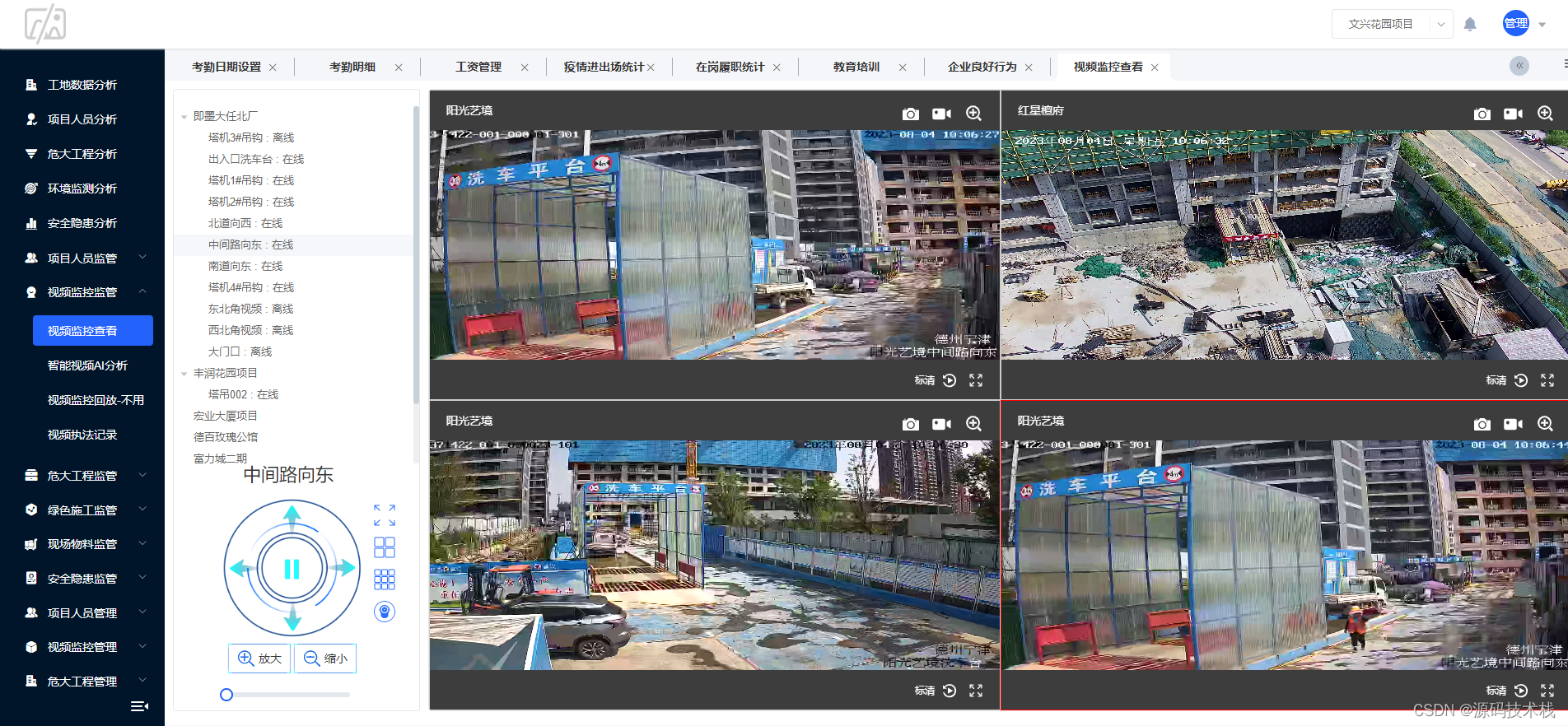
JAVA智慧工地管理系统源码基于微服务
智慧工地是将互联网的理念和科技引入施工现场,从施工现场源头抓起,大程度的收集人员、安全、环境、质量等关键业务数据。通过结合物联网、大数据、互联网、云计算等技术建立云端大数据管理平台,形成端云大数据的体系与模式,这就是…...
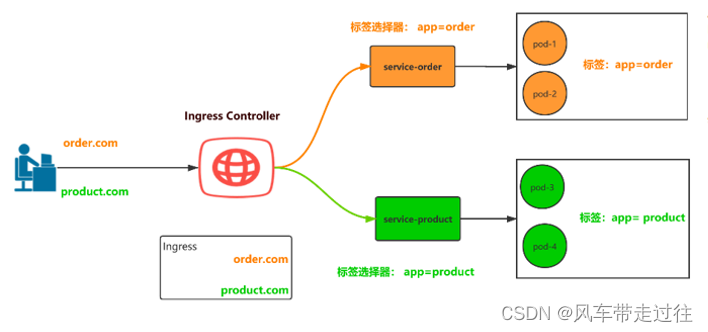
学习笔记三十四:Ingress和 Ingress Controller概述
Ingress和 Ingress Controller概述 回顾service四层负载在k8s中为什么要做负载均衡Service不足之处四层负载和七层负载的区别OSI七层模型: Ingress介绍Ingress Controller介绍Ingress-controller 作用Ingress和Ingress Controller总结使用Ingress Controller代理k8s…...

Webpack的Tree Shaking。它的作用是什么?
聚沙成塔每天进步一点点 ⭐ 专栏简介 前端入门之旅:探索Web开发的奇妙世界 欢迎来到前端入门之旅!感兴趣的可以订阅本专栏哦!这个专栏是为那些对Web开发感兴趣、刚刚踏入前端领域的朋友们量身打造的。无论你是完全的新手还是有一些基础的开发…...
研发效能DevOps: Git安装
目录 一、理论 1.Git 2.Git 工具 二、实验 1.Git安装 2.配置Git 3. VS Code加载Git 一、理论 1.Git (1)简介 Git 是一个分布式版本控制及源代码管理工具;Git 可以为你的项目保存若干快照,以此来对整个项目进行版本管理。 Git 是一个…...
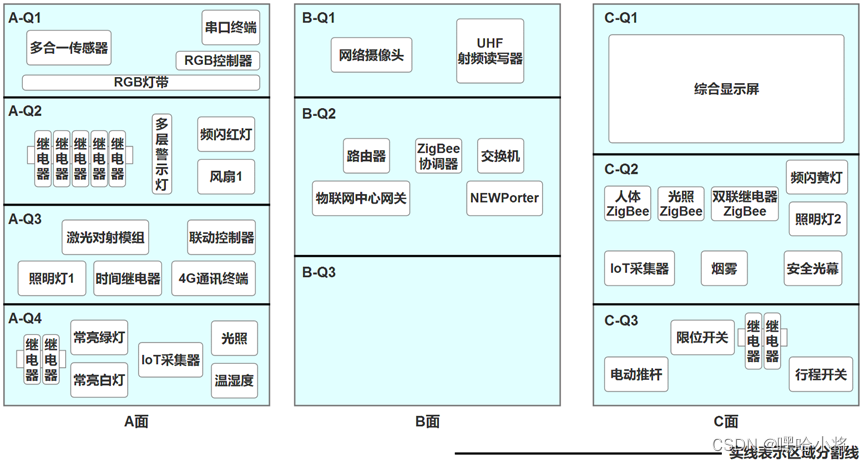
ZZ038 物联网应用与服务赛题第D套
2023年全国职业院校技能大赛 中职组 物联网应用与服务 任 务 书 (D卷) 赛位号:______________ 竞赛须知 一、注意事项 1.检查硬件设备、电脑设备是否正常。检查竞赛所需的各项设备、软件和竞赛材料等; 2.竞赛任务中所使用的各类软件工具、软件安装文件等,都…...
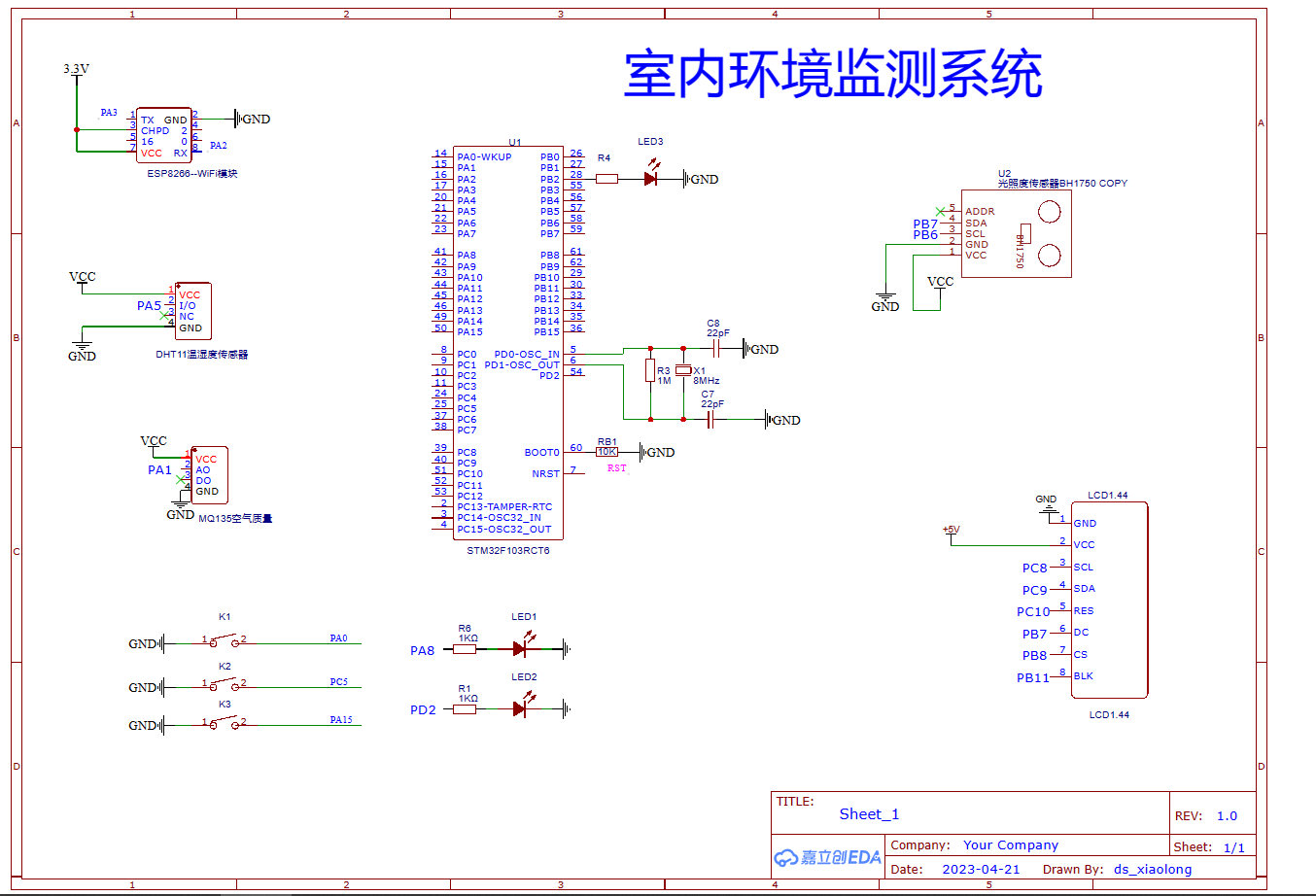
基于STM32设计的室内环境监测系统(华为云IOT)_2023
一、设计需求 基于STM32+华为云物联网平台设计一个室内环境监测系统,以STM32系列单片机为主控器件,采集室内温湿度、空气质量、光照强度等环境参数,将采集的数据结果在本地通过LCD屏幕显示,同时上传到华为云平台并将上传的数据在Android移动端能够实时显示、查看。 【1…...
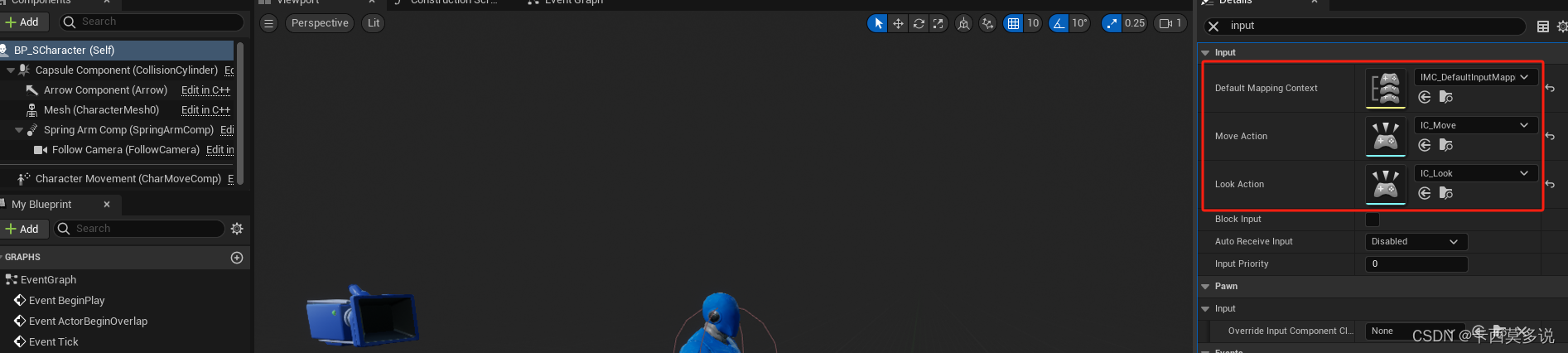
UE5C++学习(一)--- 增强输入系统
一、关于增强输入系统的介绍 增强输入系统官方文档介绍 二、增强输入系统的具体使用 注:在使用方面,不会介绍如何创建项目等基础操作,如果还没有UE的使用基础,可以参考一下我之前UE4的文章,操作差别不会很大。 如上…...

好物周刊#29:项目管理软件
https://github.com/cunyu1943/JavaPark https://yuque.com/cunyu1943 村雨遥的好物周刊,记录每周看到的有价值的信息,主要针对计算机领域,每周五发布。 一、项目 1. HelloGithub 分享 GitHub 上有趣、入门级的开源项目。每月 28 号以月刊…...

玻色量子“天工量子大脑”亮相中关村论坛,大放异彩
2023年5月25日至30日,2023中关村论坛(科博会)在北京盛大召开。中关村论坛(科博会)是面向全球科技创新交流合作的国家级平台行业盛会,由科技部、国家发展改革委、工业和信息化部、国务院国资委、中国科学院、…...

使用Gorm进行高级查询
深入探讨GORM的高级查询功能,轻松实现Go中的数据检索 高效的数据检索是每个应用程序性能的核心。GORM,强大的Go对象关系映射库,不仅扩展到基本的CRUD操作,还提供了高级的查询功能。本文是您掌握使用GORM进行高级查询的综合指南。…...

基于梯度算法的无人机航迹规划-附代码
基于梯度算法的无人机航迹规划 文章目录 基于梯度算法的无人机航迹规划1.梯度搜索算法2.无人机飞行环境建模3.无人机航迹规划建模4.实验结果4.1地图创建4.2 航迹规划 5.参考文献6.Matlab代码 摘要:本文主要介绍利用梯度算法来优化无人机航迹规划。 1.梯度搜索算法 …...

PowerToys Awake:3种模式彻底解决Windows电脑意外休眠的烦恼
PowerToys Awake:3种模式彻底解决Windows电脑意外休眠的烦恼 【免费下载链接】PowerToys Microsoft PowerToys is a collection of utilities that supercharge productivity and customization on Windows 项目地址: https://gitcode.com/GitHub_Trending/po/Pow…...

如何快速实现OBS多平台直播:obs-multi-rtmp完全配置指南
如何快速实现OBS多平台直播:obs-multi-rtmp完全配置指南 【免费下载链接】obs-multi-rtmp OBS複数サイト同時配信プラグイン 项目地址: https://gitcode.com/gh_mirrors/ob/obs-multi-rtmp 你是否厌倦了每次直播都要在不同平台间反复切换设置?obs…...

JD-GUI深度解析:Java字节码逆向工程的瑞士军刀
JD-GUI深度解析:Java字节码逆向工程的瑞士军刀 【免费下载链接】jd-gui A standalone Java Decompiler GUI 项目地址: https://gitcode.com/gh_mirrors/jd/jd-gui 在Java开发的世界里,我们常常需要面对只有字节码没有源码的困境——第三方库的调试…...

面向软件测试从业者的多模态AI系统评估体系构建指南
随着人工智能技术的飞速演进,多模态AI系统正逐渐从实验室走向广泛的产业应用。这类系统能够同时处理和理解文本、图像、音频、视频等多种模态的信息,并实现跨模态的语义融合与推理。对于软件测试从业者而言,评估此类系统的复杂性远超传统单模…...

Cursor Pro破解终极指南:开源工具cursor-free-vip实现AI编程助手永久免费使用
Cursor Pro破解终极指南:开源工具cursor-free-vip实现AI编程助手永久免费使用 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: …...

Fillinger智能填充插件:如何用3分钟完成1小时的设计工作?
Fillinger智能填充插件:如何用3分钟完成1小时的设计工作? 【免费下载链接】illustrator-scripts Adobe Illustrator scripts 项目地址: https://gitcode.com/gh_mirrors/il/illustrator-scripts 还在为Adobe Illustrator中繁琐的图案填充而头疼吗…...

ExifToolGUI终极指南:3步掌握照片元数据批量管理工具
ExifToolGUI终极指南:3步掌握照片元数据批量管理工具 【免费下载链接】ExifToolGui A GUI for ExifTool 项目地址: https://gitcode.com/gh_mirrors/ex/ExifToolGui 你是否曾为整理数百张旅行照片而头疼?需要统一修改拍摄时间、批量添加版权信息&…...

从夏普IGZO技术授权看显示面板产业的技术转移与战略博弈
1. 从一则旧闻看显示产业的全球棋局:技术、资本与生存的博弈2013年夏天,一则来自日本的消息在科技产业圈,特别是显示面板和半导体供应链领域,激起了不小的涟漪。全球知名的消费电子品牌夏普公司,宣布了一项与中国国有企…...

Allegro丝印层加汉字和防静电标识?我找到了比自带功能更香的免费Skill工具
Allegro丝印层高效处理方案:汉字与防静电标识的终极实践指南 在PCB设计的最后阶段,丝印层的处理往往成为工程师们头疼的问题。尤其是当设计需要添加中文注释、企业标识或行业标准符号(如防静电警告标志)时,Allegro原生…...

从零构建:基于Air724UG的4G LTE物联网数据透传系统
1. 认识Air724UG模块:你的物联网数据搬运工 第一次拿到Air724UG这个巴掌大的4G模块时,我完全没想到它能成为我物联网项目的核心组件。这个来自合宙通信的Cat.1模块,最大的特点就是用2G的价格享受4G的体验。实测在市区环境下,它的上…...