【翻译】XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Languages
摘要
当代的关于抽象文本摘要的研究主要集中在高资源语言,比如英语,这主要是因为低/中资源语言的数据集有限。在这项工作中,我们提出了XL-Sum,这是一个包含100万篇专业注释的文章摘要对的综合多样数据集,从BBC中提取,采用一组精心设计的启发式方法。该数据集涵盖了从低资源到高资源的44种语言,其中许多语言目前没有公开数据集。XL-Sum具有高度抽象、简洁和高质量的特点,这一点得到了人类和内部评估的证实。我们使用XL-Sum对mT5进行微调,mT5是一种最先进的预训练多语言模型,并在多语言和低资源摘要任务上进行实验。与使用类似的单语数据集获得的结果相比,XL-Sum获得了竞争性的结果:在我们进行基准测试的10种语言中,我们的ROUGE-2分数高于11,其中一些超过15,这是通过多语言训练获得的。此外,对低资源语言进行单独训练也提供了竞争性的性能。据我们所知,XL-Sum是根据来自单一来源的样本数量和涵盖的语言数量来看,是最大的抽象摘要数据集。我们发布了我们的数据集和模型,以鼓励未来的多语言抽象摘要研究。资源可以在 https://github.com/csebuetnlp/xl-sum 找到。
1 Introduction
自动文本摘要(Nenkova和McKeown,2011)是自然语言处理中的一个基本问题。给定输入文本(通常是一篇长文档或文章),目标是生成一个更小、更简洁的文本片段,传达输入文本的关键信息。自动文本摘要有两种主要方法:抽取式和生成式。抽取式方法从输入文本中截取一个或多个片段,然后连接它们以生成摘要。这些方法在摘要的早期时期占主导地位,但它们存在一些限制,包括句子之间的连贯性较差,无法简化复杂和长句子,以及意外的重复(See等,2017;Widyassari等,2020)。
另一方面,抽象性摘要生成摘要可能包含输入文本中不存在的词语和短语(例如,通过改写),并且可能与人工生成的摘要更相关(Hsu等,2018)。尽管抽象性摘要可以比抽取性摘要更具连贯性和简洁性(Cohn和Lapata,2008),但由于任务的性质,生成它们更具挑战性。有利于抽象性方法的好数据集的有限供应使其变得更加困难。出于这些原因,历史上抽取模型一直表现优于抽象模型。然而,在过去的十年中,序列到序列(seq2seq)模型(Cho等,2014;Sutskever等,2014)的成功以及基于Transformer的模型的最新进展(Vaswani等,2017;Devlin等,2019)使抽象性文本摘要(Rush等,2015;See等,2017;Zhang等,2020)重新焕发了生机,以前与抽取方法相比,抽象方法受到了更少的关注(Nenkova和McKeown,2012)。然而,好的数据集的稀缺,特别是对于低资源语言,仍然是一个障碍。
典型的seq2seq模型是高度依赖数据的,也就是说,需要大量的文章-摘要对来有效训练它们。因此,抽象性摘要主要集中在英语语言上,因为大多数大规模的抽象性摘要数据集(Hermann等,2015;Grusky等,2018;Narayan等,2018)仅提供英语版本。尽管最近有一些努力来整理多语言抽象性摘要数据集(Giannakopoulos等,2015;Cao等,2020;Scialom等,2020),但它们在涵盖的语言数量、训练样本数量或两者方面都存在限制。
在这项工作中,我们介绍了XL-Sum,这是一个大规模的抽象性摘要数据集,其中包含从英国广播公司(BBC)1网站抓取的新闻文章。借助自定义爬虫,我们收集了1百万篇专业注释的文章摘要对,涵盖了44种语言。这些样本来自单一来源,它们在所有语言中都展现出类似的摘要策略,使它们成为多语言摘要任务的理想选择。XL-Sum引入了首个公开可用的摘要数据集和许多语言的基准测试(例如孟加拉语、斯瓦希里语)。因此,这个数据集有望促进对低资源语言的研究,将技术进步带给那些传统上受到较少服务的语言社区。
在我们的多语言摘要基准测试中,我们在10种语言中实现了高于11的ROUGE-2分数,甚至在其中许多语言中超过15的ROUGE-2分数(例如,张等人(2020)在XSum(Narayan等人,2018)上获得的英语的最新成果为16.58,这是类似数据集)。此外,我们还进行了低资源摘要任务的实验,并展示了竞争性的结果,表明即使针对低资源语言,也可以单独使用该数据集。
总之,在本文中,我们做出了以下主要贡献:
- 我们发布了XL-Sum数据集,其中包含44种语言的100万篇文章-摘要对,是许多语言中首个公开可用的抽象性摘要数据集。
- 我们创建了一个数据整理工具,可以自动从BBC中抓取和提取文章-摘要对,借助这个工具,数据集可以随着时间的推移变得更大。
- 我们是第一个在多种语言上执行多语言摘要的研究,实现了所有测试语言的强基准结果。
我们将发布数据集、整理工具和摘要模型检查点。我们相信我们在这项工作中的努力将鼓励社区在抽象性文本摘要领域推动边界,尤其是对于低资源和中等资源语言。
2 XL-Sum数据集
在本节中,我们将提供XL-Sum数据集以及整理过程的详细信息。表2显示了XL-Sum数据集中所有语言的文章-摘要统计数据。
2.1 内容来源
BBC发布新闻的语言涵盖了从低资源语言如孟加拉语和斯瓦希里语到高资源语言如英语和俄语的43种语言。在这43种语言中,塞尔维亚语是一个特殊情况,它以西里尔字母(官方文字)和拉丁字母(口头文字)两种形式发布。在这项工作中,我们将它们视为不同的语言,总共涵盖了44种语言。
2.2 内容搜索
由于BBC官方网站没有提供任何存档或RSS源,我们设计了一个爬虫,通过访问每个已访问页面中的不同文章链接,从主页开始递归地爬取页面。我们能够利用BBC各个站点具有相似结构的事实,成功地从所有站点抓取文章。在进一步处理之前,我们丢弃了没有文本内容的页面(主要是包含多媒体内容的页面)。
2.3 文章-摘要提取
自动收集文章摘要的过程在不同的数据集中有所不同。例如,CNN/DM数据集(Hermann等,2015)将提供的文章摘要作为参考摘要与文章的要点合并,而XSum数据集(Narayan等,2018)将文章的第一行作为摘要,其余部分作为输入。
我们的摘要收集方法因BBC文章具有一致的编辑风格而变得更容易。BBC通常在每篇文章的开头以粗体段落的形式提供全文摘要,其中包含一两句话,由文章的作者专业编写,以便在一个小段落中传达主要内容。这与标题不同,标题的作用是吸引读者阅读文章。(我们在表1中展示了来自BBC英语的文章-摘要对的示例。)我们设计了一些启发式方法,通过仔细检查抓取页面的HTML结构,使摘要提取变得更加有效:
- 所需摘要必须出现在文章的前两个段落内。
- 摘要段落必须包含一些文本以粗体格式显示。
- 摘要段落可能包含一些非粗体的超链接文本。考虑到段落的总长度,粗体文本和超链接文本占总长度的比例必须至少达到95%。
- 除了摘要和标题之外的所有文本必须包括在输入文本中(包括图像说明)。
- 输入文本的长度必须至少是摘要长度的两倍。
不符合这些启发式方法的任何样本都被丢弃。我们的自动摘要注释策略在某种程度上类似于XSum,但我们发现许多文章的第一行包含了许多元信息(例如,作者信息、最后修改日期)。因此,我们选择使用粗体段落作为摘要。
3 XL-Sum的人工评估
尽管XL-Sum的摘要由专业人员编写,但评估数据集的质量对于确保它对抽象性摘要的更广泛社区有价值并可以使用是至关重要的。为此,我们对数据集的一个子集进行了彻底的人工评估。
我们雇佣了专业的注释员来评估全球使用人数最多的前10种语言的质量。值得注意的是,并非所有这10种语言都是高资源语言(例如,尽管孟加拉语是其中使用最广泛的之一,但它仍然是一种低资源语言)。
每位评估员被要求通过“是”/“否”来回答以下问题,评估随机子集的数据集(大约250篇文章-摘要对):
属性A:摘要是否传达了文章的内容?
属性B:如果属性A的答案是“是”,摘要是否包含与文章不一致的信息?
属性C:如果属性A的答案是“是”,摘要是否包含无法从文章中推断出的信息?
设计这些属性的动机源自最近关于神经语言生成(NLG)模型质量估计的进展。Belinkov和Bisk(2018)表明NLG模型容易受到嘈杂和低质量的训练样本的影响,因此通过属性A验证摘要的质量至关重要。确保生成摘要的事实一致性和忠实度(Wang等,2020;Maynez等,2020)对于神经抽象性摘要至关重要,因为已经证明神经模型会生成虚构的文本(See等,2017)。属性B检查文章和摘要之间的一致性;而属性C通过将知识领域限制在输入文章中并识别摘要中存在的额外信息来隐式评估虚构信息。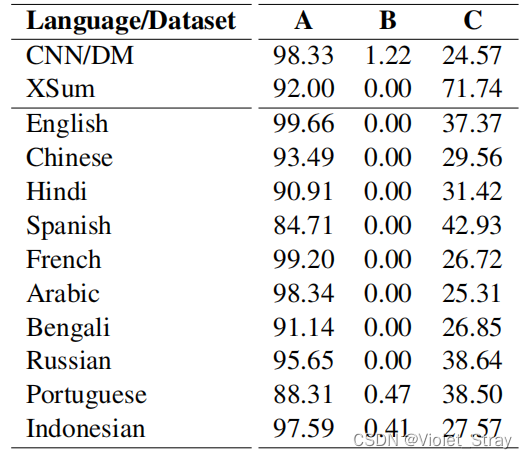
表3:由人工评估员评估的XL-Sum(以及CNN/DM和XSum)的质量。在大多数情况下,评估员一致认为摘要传达了主要思想(属性A),并且不与输入文本冲突(属性B)。然而,摘要可能包含一些额外信息(属性C),因为编写摘要的编辑可能会使用他们的常识和不在文章中出现的领域知识。
属性A的高比例是可取的,而属性B和C的比例应该较低。然而,第三个属性可能有些模糊,因为一些信息可能不直接出现在输入文章中,但具有背景知识和对文章主题的理解的专业人员可能会隐含地推断出它们。由于文本摘要被视为封闭领域任务,我们要求注释员进行相应的标注,即不使用文章之外的任何额外信息。我们为他们提供了一些英文示例注释,以帮助他们进行注释。属性A的“是”比例、属性B和C的“是”比例在表3中显示。
我们还展示了CNN/DM和XSum的人工评估以进行对比。每个文章-摘要对由两名不同的评估员标记,并且我们认为只有在两名评估员都同意的情况下,才具有属性A,并且如果其中至少有一名评估员同意,则具有属性B和C。
从表3(属性A)可以看出,大多数语言显示出高比例的好摘要,高达九十几个百分点,而某些语言的比例稍低一些(例如,西班牙语和葡萄牙语)。我们从注释员那里得知,负面摘要大多来自观点文章和博客文章,其中的粗体段落未传达文章的主要内容。
几乎没有摘要包含冲突信息(属性B),而平均约有三分之一的摘要包含不能直接推断的信息(属性C)。有趣的是,超过75%的后者包含遗漏的信息,如名字、职务或首字母缩写的解释。例如,一份摘要中出现了“当选总统乔·拜登”,而相应的文章中没有出现“乔”的名字。另一篇文章中,摘要中有关于NHS的解释,而在文章中没有提到。总的来说,摘要中包含的额外信息类型在所有语言中基本相同。CNN/DM和XSum的摘要中也包含额外信息,这意味着这种现象在抽象性文本摘要数据集中是常见的。
摘要中包含额外信息是可以理解的,因为编写这些摘要的专业专家不仅使用文章文本中的信息,还融入了他们对外部世界的知识和理解。但对于封闭领域的摘要模型或对该主题不熟悉的人来说,推断这些信息并不那么直截了当,这使得自动的抽象性摘要任务变得更具挑战性。这一现象可能解释了为什么在经过预训练检查点微调的语言模型(Raffel等,2020;Qi等,2020;Zhang等,2020)在抽象性摘要方面取得了最先进的结果,因为它们能够利用来自预训练文本的大量外部信息。此外,研究最近将现实世界知识和常识推理(Tandon等,2018;Deng等,2020)纳入语言模型是否能提高文本摘要性能将是有趣的。
4. XL-Sum的内在评估
尽管人工评估提供了对摘要质量的有益见解,但摘要的许多其他方面往往不容易或不切实际由人工评估员来判断。在上述背景下,一些研究(Narayan等,2018;Grusky等,2018;Bommasani和Cardie,2020)提出了许多自动度量标准,用于量化抽象性摘要的重要特征(例如,新颖词汇、抽象性、压缩和冗余)。
新颖n-gram比例:Narayan等人(2018)提出了摘要中不在输入文章中出现的n-gram的百分比,作为衡量抽象性的手段。
抽象性:Grusky等人(2018)引入了片段,它们贪婪地匹配文章和摘要之间的文本段,而Bommasani和Cardie(2020)将其概括为引入抽象性以衡量抽象性。
压缩:Bommasani和Cardie(2020)提出了压缩作为衡量简洁性的度量标准。压缩度量是通过比较摘要和输入文章中的标记数来实现的。
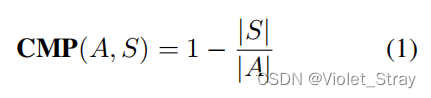
其中,|A|和|S|分别表示文章和摘要的长度。我们以标记数来衡量长度。
冗余性:尽管Bommasani和Cardie(2020)提出了一个度量冗余性的指标,但它仅适用于多句子摘要,而XL-Sum中的大多数示例并非如此。因此,我们通过计算摘要文本中重复n-gram的数量,提出了一种新的冗余性度量。
设 g 1 , g 2 , ⋅ ⋅ ⋅ , g m {g_1, g_2, · · · , g_m} g1,g2,⋅⋅⋅,gm为摘要S中出现的唯一n-gram, f 1 , f 2 , ⋅ ⋅ ⋅ , f m {f_1, f_2, · · · , f_m} f1,f2,⋅⋅⋅,fm为它们的频率。然后,重复的n-gram总数为 ∑ i = 1 m ( f i − 1 ) \sum^m_ {i=1}(f_i − 1) ∑i=1m(fi−1)。
我们将冗余性定义为冗余n-gram与S中总n-gram数量的比率:
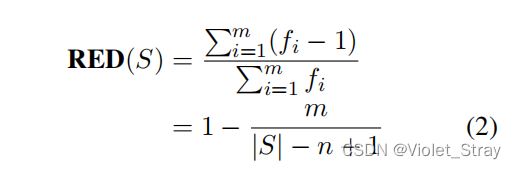
一个好的摘要最好具有较高的新颖n-gram比率、抽象性和压缩性;同时具有较低的冗余得分。我们在表4中展示了这些指标(对于冗余,我们报告了n = 1、2的值)。我们还为CNN/DM和XSum数据集展示了这些指标。
结果表明,XL-Sum数据集具有很高的抽象性 - 大约三分之一的标记和超过75%的bigram在摘要中都是新颖的,抽象性分数也很高(大多数语言都超过65%)。此外,XL-Sum非常简洁(对于大多数语言,摘要不到输入文章的十分之一),并且包含极少的冗余(大多数情况下少于10%)。XSum的质量也可以媲美,但它只适用于一种语言(即英语)。另一方面,CNN/Daily Mail数据集在上述大多数指标中明显落后于XL-Sum和XSum。
5. 实验和基准测试
在前几节中,我们已经讨论了XL-Sum的质量。此外,看到最先进的模型在训练时如何表现是至关重要的。此外,就我们所知,对于许多语言(例如孟加拉语、斯瓦希里语),目前还没有公开可用的抽象性文本摘要数据集和基准测试。在本节中,我们使用XL-Sum数据集训练摘要模型,并提供了几个基线和基准测试结果。已经证明,对具有自监督训练的预训练权重初始化的Transformer-based(Vaswani等,2017)seq2seq模型进行微调(Raffel等,2020;Liu和Lapata,2019;Rothe等,2020;Qi等,2020;Zhang等,2020)在许多抽象性文本摘要数据集上可以实现最先进的性能。在Hugging Face Transformers Library(Wolf等,2020)中提供了许多多语言预训练检查点。在其中,我们选择使用mT5模型(Xue等,2021),这是一个在大型101种语言数据集上预训练的多语言语言模型。
我们在两种设置下进行了摘要实验:(i)多语言,和(ii)低资源。对于性能报告,对于每种语言,我们随机抽取了500个对用于开发集和500个对用于测试集,同时使用其余对进行训练。我们使用了与mT5检查点一起提供的250k字词(Wu等,2016)词汇对训练样本进行标记化。由于计算限制,我们使用了基础模型(600M参数)并不得不将输入截断为512个标记和输出截断为64个标记。我们使用ROUGE-1、ROUGE-2和ROUGE-L(Lin,2004)分数进行自动评估。对于推断,我们使用了beam search,beam大小为4,长度惩罚为α = 0.6(Wu等,2016)。
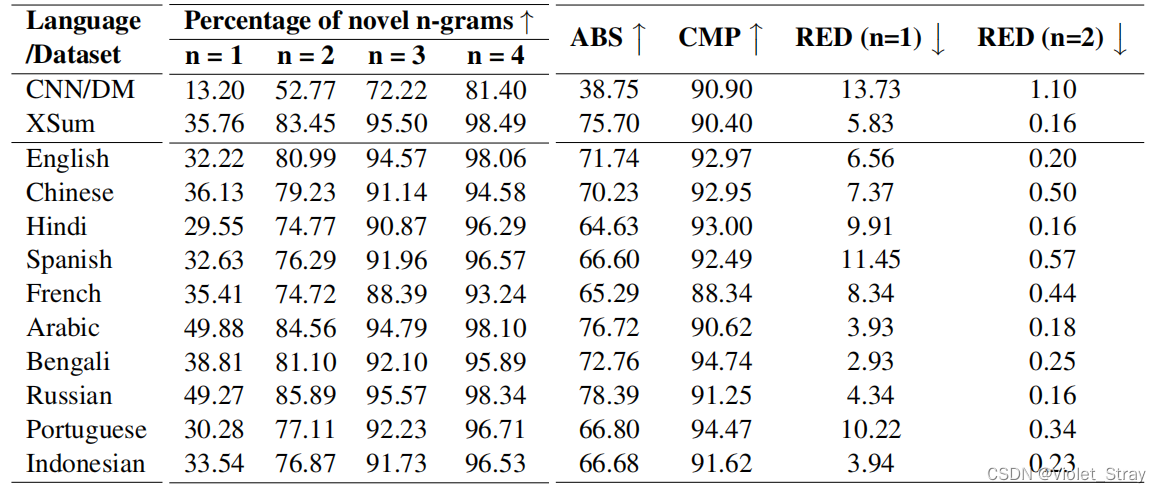
表4:对比我们的XL-Sum数据集与CNN/Daily Mail和XSum的内在评估。所有值均以百分比报告,以便更容易比较。我们使用↑表示“数值越高越好”,使用↓表示相反情况。XL-Sum和XSum都具有很高的抽象性、简洁性,并且显示出可比较的质量,尽管XSum数据集只包含英语样本。对于XL-Sum和XSum,新颖n-gram(n = 1, 2, 3, 4)的百分比明显高于CNN/DM。XL-Sum和XSum的高抽象性(ABS)分数也支持了这一发现。此外,低冗余(RED)和高压缩(CMP)值表明XL-Sum和XSum比CNN/DM更加简洁。
5.1 多语言摘要
多语言训练是通过对来自多种语言的训练样本进行单一模型训练来实现的。它以前在多个自然语言处理任务中使用过,包括神经机器翻译(Arivazhagan等,2019)和语言模型预训练(Conneau和Lample,2019)。然而,在抽象性摘要的背景下,多语言训练并不是社区的主要关注点。因此,这个实验的目的是要证明单一模型可以很好地对不同语言的文本进行摘要,并且形态相似的姊妹语言可以相互受益,从而在单语言环境中是不可能的。
在这个实验中,我们采用了与Conneau和Lample(2019)类似的训练策略:我们从一个单一语言中抽样每批,每批包含256个样本,并使用了平滑因子(α)为0.5,以便对低资源语言的批次进行更高的采样率,从而在训练期间提高它们的频率。
我们在8个Nvidia Tesla P100 GPU组成的分布式集群上对mT5模型进行了35k步的微调,持续了4天。我们使用了Adafactor优化器(Shazeer和Stern,2018),线性预热5000步和“反平方根”学习率调度。我们在表5中展示了该模型在前10种语言上实现的ROUGE分数。从表中可以看出,多语言模型在所有语言上都取得了高于11的ROUGE-2分数。其中一些语言(例如孟加拉语)资源有限,但模型仍然获得了与高资源和中资源语言可比较的竞争力结果。此外,我们是首个报告包括孟加拉语在内的多种语言的抽象性摘要基准的团队。
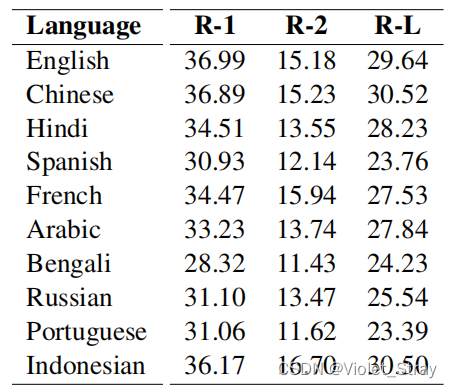
表5:mT5模型在XL-Sum训练集上进行微调后,实现的多语言摘要的ROUGE分数。
mT5-base模型在英语上实现了15.18的R2分数。相比之下,最先进的PEGASUSBASE模型(Zhang等,2020)在XSum英语数据集上训练,获得了16.58的R-2分数,与XL-Sum在性质上相似。这一结果表明,性能与英语摘要的最先进技术相媲美。其他语言的R-2分数也与英语相似,表明我们的数据集可以帮助有效生成所有受测语言的自动生成摘要,包括低资源语言。
5.2 低资源摘要
我们已经展示了多语言训练策略在使用单一模型为多种语言摘要文章方面的有效性。然而,训练该模型需要大量计算资源,这在许多情况下可能并不现实。为了确认这一点,我们在计算效率高的环境中对来自表2的五种低资源语言(阿姆哈拉语、阿塞拜疆语、孟加拉语、日本语、斯瓦希里语)进行了培训。我们在每种语言上单独对mT5进行了6-10轮的微调(由于总训练样本有限,我们必须小心防止过度拟合),在单个GPU(Nvidia RTX 2080Ti)机器上进行了训练。对于这些实验,我们使用了32个批次大小,并使用了倾斜的学习率计划(Howard和Ruder,2018)。我们在表6中展示了每个模型的ROUGE分数。我们使用多语言模型的结果作为基准。
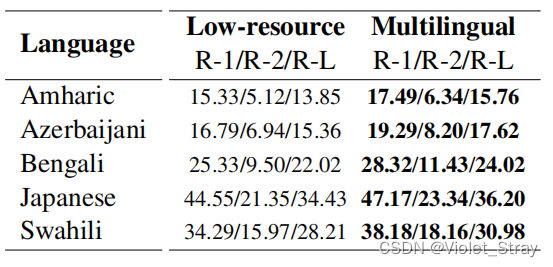
表6:在低资源培训设置和前一部分提到的多语言设置下对mT5模型进行微调的性能。
正如表6中的结果所表明的,多语言模型优于所有单语言训练的模型。这是可以预期的,因为在一起训练时,类似的语言可以在它们之间实现正向传递(Conneau等人,2020)。然而,低资源模型的差距并不大,在所有情况下,R-2分数的差异都不超过2。这是一个很好的迹象,表明在如此少量的样本上微调的模型仍然可以推广,以产生与多语言模型竞争的结果。
关于阿姆哈拉语、阿塞拜疆语和日语的表现需要讨论。前两者的分数相对较低,而最后一个(日语)与其他语言相比得分要高得多。阿姆哈拉语和阿塞拜疆语分别有大约4,000和6,000个训练样本,我们猜测这是它们表现不佳的主要原因。此外,在计算ROUGE之前,我们没有找到可靠的词干处理程序来预处理生成的摘要,这可能也会损害分数。
另一方面,日语文本没有分词,需要在计算ROUGE之前将单词分开。我们使用了Fugashi(McCann,2020),可能由于其激进的分词,分数比其他语言高。类似的高结果也在测量日语机器翻译评估的BLEU(Papineni等人,2002)分数时报告过(Kudo,2018)。
表6中的结果显示,尽管这些语言属于低资源语言,但两种设置的分数相近,表明我们的数据集在计算能力受限的情况下仍然可以派上用场。这有助于促进低资源文本摘要的进展,实现对未被服务的社区的公平和访问。
6 相关工作
Rush等人(2015);Nallapati等人(2016)首创了神经生成式摘要,使用递归注意力seq2seq模型(Bahdanau等人,2015)。See等人(2017)引入了用于生成式摘要的指针生成器网络,该网络可以学习从输入文本中复制单词,同时使用解码器生成新的文本。Gehring等人(2017)提出了卷积seq2seq模型,并将其应用于生成式摘要。Narayan等人(2018)通过将主题嵌入集成到模型中,扩展了该工作。
最近,预训练语言模型已成功应用于生成式摘要。Liu和Lapata(2019)初始化了seq2seq模型的编码器,Rothe等人(2020)则初始化了编码器和解码器,使用预训练的BERT(Devlin等人,2019)权重,并对生成式摘要进行微调。Raffel等人(2020);Qi等人(2020)使用了完全预训练的seq2seq模型,而Zhang等人(2020)引入了一个专门用于生成摘要的预训练目标,以在多个数据集上获得最新技术成果。
迄今为止,大多数关于生成式摘要的研究主要集中在英语上,主要是因为其他语言缺乏基准数据集。Giannakopoulos等人(2015)引入了MultiLing 2015,这是一个跨足40种语言的摘要数据集。然而,MultiLing 2015在规模上受到限制,总共只有10,000个训练样本。Cao等人(2020);Scialom等人(2020)引入了两个新的多语言摘要数据集,但都仅限于不到10种语言。此外,不同语言的样本是从不同来源收集的,这使它们暴露于不同类型的摘要策略,这引发了有关摘要一致性的问题。
结论和未来工作:
在本文中,我们介绍了XL-Sum,一个大规模、高质量的多语言文本摘要数据集,包含来自BBC的440万个样本,涵盖44种语言。对于许多语言,XL-Sum提供了首个公开可用的生成式摘要数据集和基准。我们还为研究人员提供了数据集策划工具,这将有助于随着时间的推移扩大数据集。彻底的人工和内在评估表明,我们数据集中的摘要高度抽象且简明,几乎不与输入文章发生冲突,同时传达主要思想。此外,我们证明了多语言训练可以有助于更好的摘要,这很可能是由于形态相似的姐妹语言之间的积极传递。此外,XL-Sum在低资源和计算高效的环境中也很有用。
在未来,我们将调查如何将我们的数据集用于其他摘要任务(例如,跨语言摘要Zhu等人,2019)。我们希望XL-Sum数据集对研究社区有所帮助,特别是对于致力于确保向资源有限的语言社区提供公平访问的研究人员。
相关文章:
【翻译】XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Languages
摘要 当代的关于抽象文本摘要的研究主要集中在高资源语言,比如英语,这主要是因为低/中资源语言的数据集有限。在这项工作中,我们提出了XL-Sum,这是一个包含100万篇专业注释的文章摘要对的综合多样数据集,从BBC中提取&…...
配置OpenCV
Open CV中包含很多图像处理的算法,因此学会正确使用Open CV也是人脸识别研究的一项重要工作。在 VS2017中应用Open CV,需要进行手动配置,下面给出在VS2017中配置Open CV的详细步骤。 1.下载并安装OpenCV3.4.1与VS2017的软件。 2.配置Open CV环…...

1-时间复杂度和空间复杂度
为了找到最适合当前问题而估量“算法”的评价s 时间复杂度空间复杂度执行效率:根据算法编写出的程序,执行时间越短,效率就越高占用的内存空间:不同算法编写出的程序,执行时占用的内存空间也不相同。如果实际场景中仅能…...

EtherCAT主站SOEM -- 3 -- SOEM之ethercatconfig.h/c文件解析
EtherCAT主站SOEM -- 3 -- SOEM之ethercatconfig.h/c文件解析 一 ethercatconfig.h/c文件功能预览:二 ethercatconfig.h/c 中主要函数的作用:2.1.1 ec_config_init(uint8 usetable) 和 ecx_config_init(ecx_contextt *context, uint8 usetable)ÿ…...

洗地机哪个品牌好?家用洗地机选购攻略
随着家用洗地机的普及和市场的广泛认可,进入洗地机行业的制造商也越来越多。在面对众多洗地机品牌时,消费者常常感到困惑,不知道如何选择。面对众多选择,选择有良好保障的知名洗地机品牌是明智之举。知名品牌在质量、售后服务等方…...
Java数组的定义与常用使用方法
目录 一.什么是数组 二.数组的创建及初始化 数组的创建 数组的初始化 动态初始化: 静态初始化: 【注意】 三.数组的使用 数组中元素访问 遍历数组 四.数组作为方法的参数 参数传基本数据类型 参数传数组类型(引用数据类型) 作为方法的返回…...
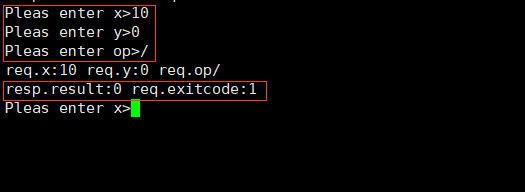
[计算机网络]认识“协议”
认识“协议” 文章目录 认识“协议”序列化和反序列化网络计算器引入Sock类设计协议编写服务端类启动服务端编写客户端类启动客户端程序测试 序列化和反序列化 在网络体系结构中,应用层的应用程序会产生数据,这个数据往往不是简单的一段字符串数据&…...

“Notepad++“ 官网地址
notepad官网下载地址:https://notepad-plus-plus.org/downloads/ npp.8.5.8.Installer.x64 本下载地址- https://download.csdn.net/download/namekong8/88494023 1. Fix session file data loss issue. 2. Fix Explorer context menu "Edit with Notepad…...
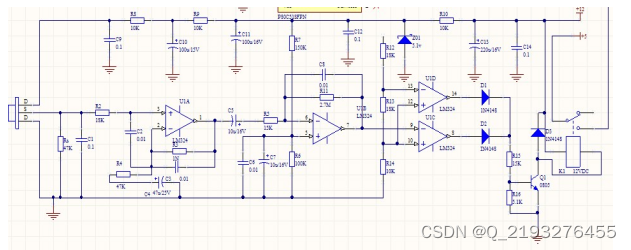
基于单片机的自动感应门设计
博主主页:单片机辅导设计 博主简介:专注单片机技术领域和毕业设计项目。 主要内容:毕业设计、简历模板、学习资料、技术咨询。 文章目录 主要介绍一、自动感应门设计的功能概述二、系统总体方案2.1系统的总体计划2.2元器件的介绍2.2.1单片机的…...

【密评】商用密码应用安全性评估从业人员考核题库(二十-完结)
商用密码应用安全性评估从业人员考核题库(二十-完结) 国密局给的参考题库5000道只是基础题,后续更新完5000还会继续更其他高质量题库,持续学习,共同进步。 4640 单项选择题 在测评过程中遇到的PEM编码格式,…...

Tigger绕过激活锁/屏幕锁隐藏工具,支持登入iCloud有消息通知,支持iOS12.0-14.8.1。
绕过激活锁工具Tigger可以用来帮助因为忘记自己的ID或者密码而导致iPhone/iPad无法激活的工具来绕过自己的iPhone/iPad。工具支持Windows和Mac。 工具支持的功能: 1.Hello界面两网/三网/无基带/乱码绕过,可以完美重启,支持iCloud登录、有消…...

VueX mapState、mapGetters、mapActions和mapMutaions 的使用
一、mapState和mapGetters 如果我们想要读取VueX中的State数据的Getters数据时,需要使用$store.state.数据名 和 $store.getters.数据名。 当我们State和getters中的数据多了以后,书写会很麻烦: 如果我们想要使用方便可以配置计算属性来简化…...

GMP标准的制药级层流细胞实验室核心要点
随着生物医药技术的飞速发展,制药行业对细胞疗法和细胞药物的需求日益增长。这推动了制药级层流细胞实验室的发展,其作为生物医药研发的关键基础设施,为制药企业提供了进行细胞培养、基因编辑、疫苗研发等工作的高效平台。本文就围绕GMP标准的…...
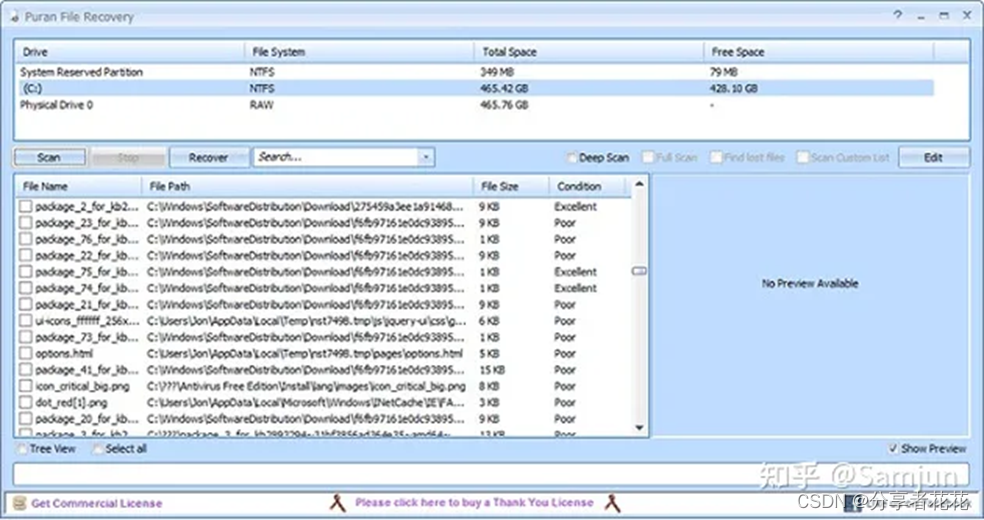
[免费] 适用于 Windows的10 的十大数据恢复软件
Windows 10是微软开发的跨平台和设备应用程序的操作系统。它启动速度更快,具有熟悉且扩展的“开始”菜单,甚至可以在多种设备上以新的方式工作。所以,Windows 10非常流行,我们用它来保存我们的照片、音乐、文档和更多文件。但有时…...
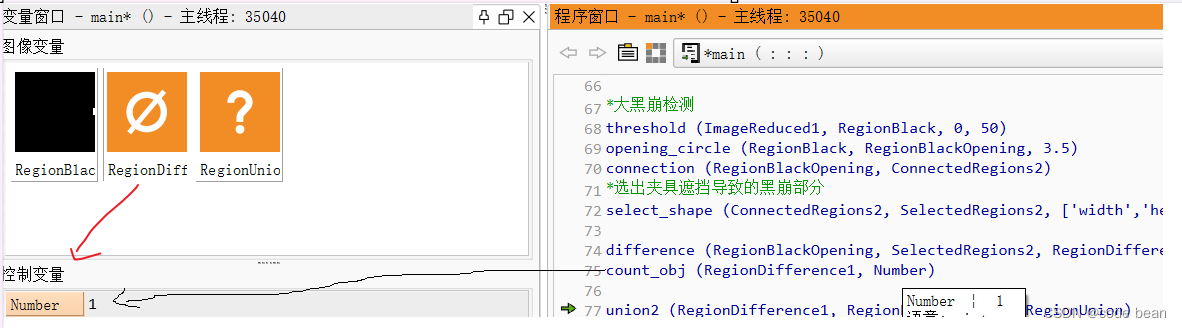
【halcon踩坑】区域为空但个数是1
背景 我在做瑕疵检测的时候,通过计算瑕疵区域的个数(count_obj())是否为0,来判断是否有瑕疵,如果不为0,那边我就会在图片上标记这个瑕疵的位置! 但是有一次我发现明明没…...
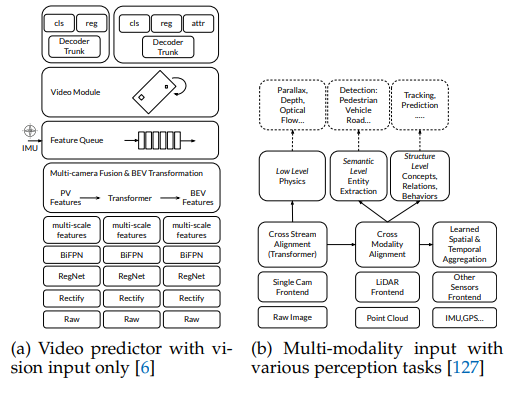
第二十四章 BEV感知系列一(车道线感知)
前言 近期参与到了手写AI的车道线检测的学习中去,以此系列笔记记录学习与思考的全过程。车道线检测系列会持续更新,力求完整精炼,引人启示。所需前期知识,可以结合手写AI进行系统的学习。 BEV感知系列是对论文Delving into the De…...
C++入门讲解第一篇
大家好,我是Dark Fire,终于进入了C的学习,我知道面对我的将是什么,就算变成秃头佬,也要把C学好,今天是C入门第一篇,我会尽全力将知识以清晰易懂的方式表达出,希望我们一起加油&#…...
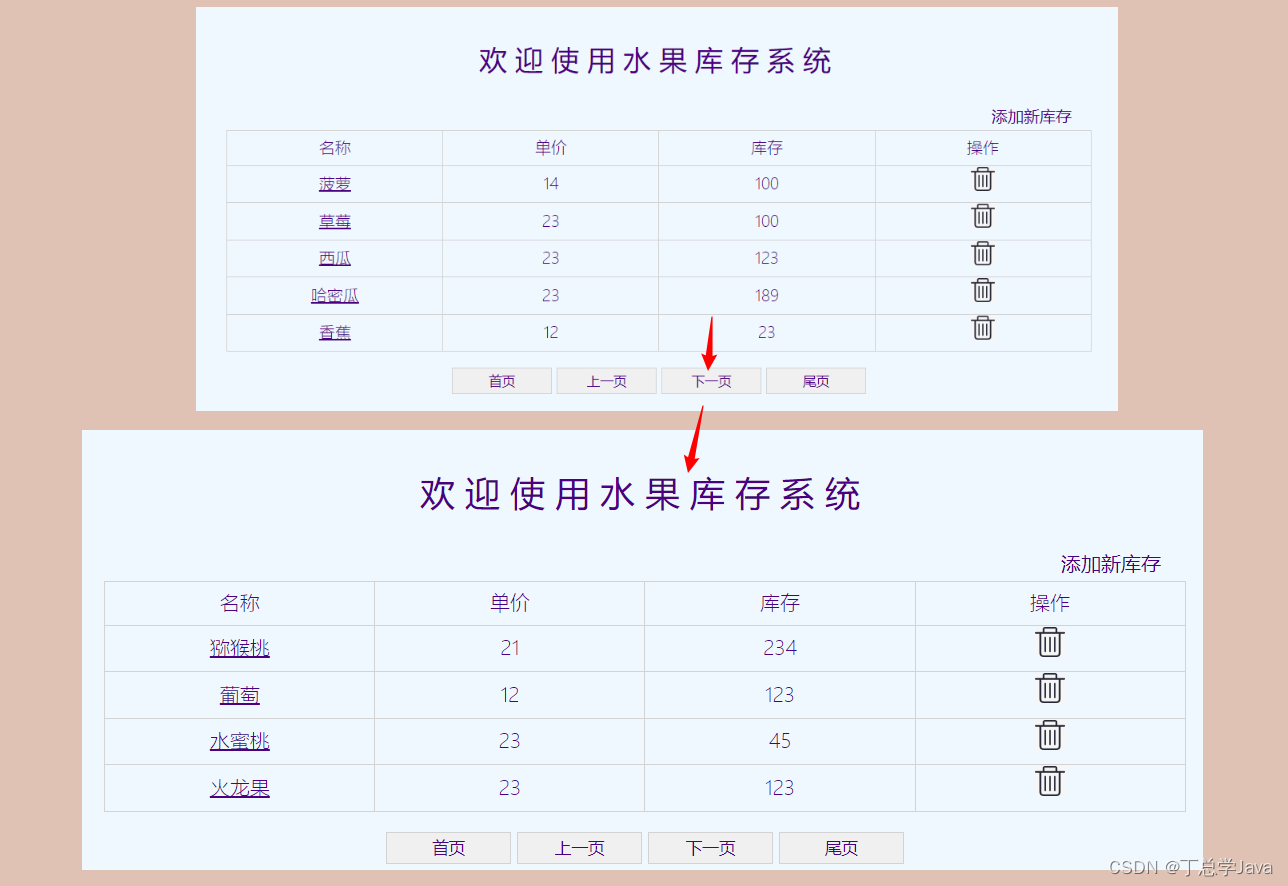
项目实战:分页功能实战
1、在index.html添加点击事件 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>Title</title><link rel"stylesheet" href"style/index.css"><script src"scr…...

AI人工智能大模型应用如何落地?
人工智能大模型是近年来人工智能领域的一项重要技术突破,其具备强大的计算能力和学习能力,能够处理大规模的数据和复杂的任务。 然而,要将人工智能大模型应用落地并实现实际价值,还需要克服一些挑战和问题。 首先,人…...

【优选算法系列】第一节.栈的简介(1047. 删除字符串中的所有相邻重复项和844. 比较含退格的字符串)
文章目录 前言一、删除字符串中的所有相邻重复项和 1.1 题目描述 1.2 题目解析 1.2.1 算法原理 1.2.2 代码编写二、比较含退格的字符串 2.1 题目描述 2.2 题目解析 2.2.1 算法原理 2.2.2 代码编写总结 前言 …...

PPTX判断包含图表id
PPTX判断包含图表id ############################20250915判断是否包含图表################################################## i0 for shape in prs.slides[1].shapes:if shape.HasChart:print(fi:{i}包含图表)ii1 ############################20250915判断是否包含图表##…...

Display Driver Uninstaller:显卡驱动清理的终极解决方案
Display Driver Uninstaller:显卡驱动清理的终极解决方案 【免费下载链接】display-drivers-uninstaller Display Driver Uninstaller (DDU) a driver removal utility / cleaner utility 项目地址: https://gitcode.com/gh_mirrors/di/display-drivers-uninstall…...

终极窗口置顶解决方案:用AlwaysOnTop告别多任务切换烦恼
终极窗口置顶解决方案:用AlwaysOnTop告别多任务切换烦恼 【免费下载链接】AlwaysOnTop Make a Windows application always run on top 项目地址: https://gitcode.com/gh_mirrors/al/AlwaysOnTop 你是否经常需要在不同窗口间来回切换?是否觉得频…...

开发者必备:极简CLI工具高效管理个人代码片段库
1. 项目概述:一个面向开发者的代码片段管理工具最近在整理自己的开发环境,发现一个挺普遍的问题:那些临时写出来、解决了某个具体问题、但又不够格放进正式项目库的代码片段,到底该放哪儿?它们就像散落在硬盘各处的“知…...

使用Nodejs快速将Taotoken大模型API集成到你的Web应用中
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Node.js快速将Taotoken大模型API集成到你的Web应用中 基础教程类,面向全栈或前端开发者,讲解如何在Nod…...

Obsidian Quiz Generator:用AI与间隔重复打造动态知识库
1. 项目概述:当笔记遇上主动回忆如果你和我一样,是 Obsidian 的用户,并且对知识管理、学习效率有追求,那么你一定遇到过这个困境:笔记越记越多,知识库越来越庞大,但真正能“记住”并“调用”的知…...

3分钟终极解决方案:一键将XAPK文件高效转换为通用APK
3分钟终极解决方案:一键将XAPK文件高效转换为通用APK 【免费下载链接】xapk-to-apk A simple standalone python script that converts .xapk file into a normal universal .apk file 项目地址: https://gitcode.com/gh_mirrors/xa/xapk-to-apk 还在为安卓设…...

Opensmile实战:从零到一的音频特征提取指南
1. 为什么选择Opensmile处理音频特征? 第一次接触音频分析时,我被各种专业工具搞得眼花缭乱。直到实验室的师兄推荐了Opensmile,这个开源工具彻底改变了我的工作效率。它最吸引我的地方在于三点:全流程覆盖(从特征提取…...

失落大陆建模:亚特兰蒂斯数字重建的结构验证
一、项目背景与目标设定在数字孪生与虚拟考古技术飞速发展的当下,亚特兰蒂斯这一传说中失落大陆的数字重建,不仅是对古老神话的技术致敬,更是对复杂场景建模与结构验证能力的极致考验。本项目旨在依托Blender等3D建模工具,结合最新…...

别再只仿真了!聊聊12V电源设计中Matlab参数计算与Multisim电路验证的那些事儿
从理论到实践:12V电源设计的Matlab参数计算与Multisim协同验证方法论 在电子工程领域,12V直流稳压电源的设计看似基础,却蕴含着从理论计算到仿真验证的完整知识体系。许多工程师在使用Matlab和Multisim这类工具时,往往陷入"仿…...