唯一ID如何生成,介绍一下目前技术领域最常使用的几种方法

纵使十面大山,又如何,无妨…
概述
唯一ID(Unique Identifier)是在计算机科学和信息技术领域中用于标识某个实体或数据的唯一标识符。生成唯一ID的方法可以根据具体需求和应用场景的不同而有所不同。以下是一些目前技术领域中常用的生成唯一ID的方法:
-
自增序列:
这是一种常见的生成唯一ID的方法,特别适用于数据库中的主键。每次插入新数据时,ID会自动递增,确保唯一性。这种方法在关系型数据库中广泛使用,如自增主键列。 -
UUID(Universally Unique Identifier):
UUID是一种128位的全局唯一标识符,通常以32位的十六进制字符表示。UUID的生成不依赖于中央控制机构,因此可以在分布式系统中确保唯一性。常见的UUID版本包括UUIDv1、UUIDv3、UUIDv4和UUIDv5,每个版本的生成算法略有不同。 -
雪花算法(Snowflake Algorithm):
雪花算法是Twitter开发的一种分布式ID生成算法,用于在分布式系统中生成全局唯一ID。雪花ID通常包括64位的二进制数据,其中包括时间戳、数据中心ID和机器ID等信息,确保在分布式环境中的唯一性。 -
哈希算法:
哈希算法可以将任意数据映射为固定长度的唯一哈希值。例如,SHA-1、SHA-256等哈希函数可以生成唯一的散列值,用于标识数据。这种方法通常用于数据校验和数据完整性验证,而不是主键标识。 -
自定义算法:
有时,根据特定需求,开发人员也可以设计自己的唯一ID生成算法。这可能涉及到结合时间戳、应用特定信息、随机数等来生成唯一ID。
选择哪种方法取决于应用的具体需求和性能要求。在分布式系统中,确保唯一性通常更加复杂,需要考虑分布式生成和唯一性验证的问题。因此,通常需要权衡性能、复杂性和唯一性需求来选择适当的唯一ID生成方法。
自增生成
自增序列(Incremental Sequence)是一种常见的唯一ID生成方法,广泛用于数据库中的主键,它通常使用整数或长整数(integers或long integers)来表示。这种方法非常简单,但也非常有效,适用于许多应用场景,特别是在关系型数据库管理系统(RDBMS)中。
以下是自增序列的详细介绍:
-
数据结构:
- 数据类型:自增序列通常使用整数数据类型,如32位整数(INT)或64位长整数(BIGINT)。
- 起始值:通常,自增序列从一个特定的起始值开始,例如1或0。
- 步长(Increment):序列中的每个值都比前一个值增加一个特定的步长,通常为1。这决定了下一个ID的值。
-
生成ID:
- 初始值:在创建表或定义自增列时,为自增列指定一个起始值。
- 插入新数据:每当插入新数据行时,数据库管理系统会自动为自增列生成下一个唯一ID。这个ID是根据上一个已存在的ID值递增得到的。
- 唯一性:自增列确保每个ID都是唯一的,因为每个新插入的行都会获得一个比前一个行的ID大的值。
-
特点:
- 高性能:自增序列是非常高性能的,因为它们不需要复杂的计算或检查来确保唯一性。
- 适用性:自增序列特别适用于需要高并发插入的数据库表,因为它们减少了竞争条件(concurrency contention)。
- 紧凑性:生成的ID通常是紧凑的整数,不浪费存储空间。
- 查询性能:对于关系型数据库,使用自增列作为主键通常会提高查询性能,因为它们有助于维护索引的有序性。
-
限制:
- 有限范围:根据数据类型的不同,自增序列可能有一个限定的范围,因此需要定期重置或重新计算。例如,32位整数的范围是-2,147,483,648到2,147,483,647,而64位长整数的范围更广。
- 不适合所有情况:自增序列适用于需要唯一ID的情况,但不适用于每种情况。在某些情况下,可能需要更具语义的ID,而不仅仅是数字。
自增序列是一种简单而强大的方法,用于生成唯一ID,特别适用于需要高性能插入和唯一性的数据库应用。然而,开发人员需要了解其限制,特别是在需要长期保留大量数据时,可能需要考虑ID范围的问题。
UUID生成
UUID(Universally Unique Identifier),通常以32位的十六进制字符表示,是一种全局唯一标识符,广泛用于计算机科学和信息技术领域。UUID的设计目的是确保在分布式系统中生成唯一标识符,而不需要中央协调机构的参与。
以下是对UUID的详细介绍:
-
版本:
UUID有不同的版本,每个版本有不同的生成规则。最常见的UUID版本包括UUIDv1、UUIDv3、UUIDv4和UUIDv5。- UUIDv1:基于时间和MAC地址生成。它包括时间戳和节点标识(通常是MAC地址),因此可以精确到毫秒级,但不适用于安全性要求高的场景,因为MAC地址可能不是唯一的。
- UUIDv3和UUIDv5:基于命名空间和名称生成。它们使用散列算法(MD5或SHA-1)来将命名空间和名称转换为UUID,确保相同输入生成相同的UUID。
- UUIDv4:基于随机数生成。这是最常见的UUID版本,包括随机生成的数据,确保高度的唯一性。
-
结构:
一个标准的UUID是一个128位(16字节)的数字,通常以32个十六进制字符表示。它可以分成五部分:- 时间戳:UUIDv1包括一个60位的时间戳,通常以100纳秒的间隔自UTC “Gregorian” 基准时间(1582年10月15日)起计数。这可以确保UUID的时序性。
- 时钟序列:UUIDv1还包括一个时钟序列(14位),用于解决生成UUID时时间戳相同的冲突。
- 节点标识:UUIDv1中的节点标识通常是计算机的MAC地址的一部分,通常占48位。在分布式环境中,可能需要进行额外处理以确保唯一性。
- 版本号:UUID的版本号通常占4位,标识UUID的生成规则。
- 变体:UUID的变体通常占2位,用于标识UUID的布局。
-
唯一性:
UUID的唯一性基于其生成规则和实现。UUIDv4的唯一性依赖于伪随机数生成器的质量,通常提供了足够高的唯一性,但不是绝对的唯一。在分布式系统中,UUID通常需要在不同节点生成,以降低冲突的风险。 -
使用场景:
UUID通常用于标识数据、实体或会话,以确保在分布式系统中的唯一性。它们也用于构建唯一的文件名、URL和其他标识符。UUID也在很多编程语言和平台中有内置的支持。
需要注意的是,UUID虽然提供了高度的唯一性,但它们通常较长,可能不适用于所有场景。在某些情况下,可以考虑使用较短的唯一标识符,或根据具体需求设计自定义的唯一ID生成算法。
雪花算法生成
雪花算法(Snowflake Algorithm)是一种由Twitter开发的分布式唯一ID生成算法,旨在在分布式系统中生成全局唯一的64位ID。该算法的设计目标是确保唯一性、支持高吞吐量、容易部署和维护。
以下是雪花算法的详细介绍:
-
64位ID结构:
雪花算法生成的唯一ID通常由64位二进制数字组成。这64位被分为不同的部分,以存储不同的信息:- 符号位(1位):通常保持为0,以确保生成的ID为正数。
- 时间戳(41位):记录了ID的生成时间,以毫秒为单位。这意味着雪花ID可以在大约69年内保持唯一性。
- 数据中心ID(5位):标识数据中心的唯一编号,允许多个数据中心使用相同的雪花算法。
- 机器ID(5位):标识在同一数据中心内的不同机器的唯一编号。
- 序列号(12位):在相同时间戳内生成的ID的序列号,用于解决并发生成ID时的唯一性冲突问题。
-
唯一性保证:
雪花算法通过结合时间戳、数据中心ID、机器ID和序列号来确保生成的ID在整个分布式系统中的唯一性。由于不同的数据中心和机器都有唯一的标识符,结合时间戳和序列号,可以生成全局唯一的ID。 -
时间戳精度:
雪花算法的时间戳精度通常以毫秒为单位,但可以根据需要进行调整。由于41位时间戳,它可以表示2^41毫秒,也就是大约69年的时间跨度。 -
数据中心和机器ID:
数据中心ID和机器ID通常由分布式系统的管理者配置。这些标识符的分配需要注意避免冲突,以确保唯一性。通常,数据中心ID用于区分不同数据中心,而机器ID用于区分同一数据中心内的不同机器。 -
序列号处理并发:
序列号部分用于处理同一时间戳内可能发生的多次ID生成请求。在同一毫秒内,雪花算法会自动递增序列号,以确保不同ID之间的唯一性。如果同一毫秒内的序列号达到了12位的最大值,生成过程将会阻塞,直到下一毫秒。 -
时间回拨处理:
如果系统时间发生回拨,雪花算法可以通过保持序列号不变来处理这种情况。这可以确保不会生成重复的ID,尽管时间有所回拨。
雪花算法的主要优点包括简单、高性能、分布式友好以及唯一性保证。然而,使用雪花算法时需要小心配置数据中心ID和机器ID,以避免冲突,同时要注意处理时钟回拨情况。这些配置和处理都需要根据具体的分布式系统需求来进行调整。
哈希算法生成
哈希算法可用于生成唯一ID,但需要理解哈希算法的特性和限制。哈希算法将任意长度的输入数据转化为固定长度的哈希值,这个哈希值通常是一个固定长度的二进制串,通常以十六进制表示。以下是有关使用哈希算法生成唯一ID的详细介绍:
-
哈希算法原理:
- 哈希算法采用确定性的方式将输入数据转化为哈希值。这意味着相同的输入数据将始终生成相同的哈希值。
- 哈希算法通常是单向的,即从哈希值无法还原出原始数据。这是由于哈希值通常比原始数据短,因此信息的一部分丢失。
-
唯一性:
- 哈希算法的目标是确保不同的输入数据生成不同的哈希值。然而,由于哈希值的长度是有限的,因此哈希冲突是不可避免的。哈希冲突是指不同的输入数据映射到相同的哈希值。
- 良好设计的哈希算法应该最小化哈希冲突的概率,但不一定能完全消除。
-
应用领域:
- 哈希算法广泛应用于密码学、数据完整性验证、数据检索、数据比对、数字签名、数据结构(如哈希表)、信息安全等领域。
- 在生成唯一ID的上下文中,哈希算法可用于创建标识符,以确保其在给定数据上是唯一的。
-
常见的哈希算法:
- 常见的哈希算法包括MD5、SHA-1、SHA-256、SHA-384、SHA-512等。这些算法有不同的哈希值长度,通常用于不同的安全需求。
- 较新的哈希算法,如SHA-256和SHA-512,通常更安全,因为它们提供更长的哈希长度,使得暴力破解更加困难。
-
哈希冲突:
- 由于哈希算法的输出长度有限,哈希冲突是不可避免的。哈希冲突可能会导致不同的输入数据生成相同的哈希值。
- 对于生成唯一ID的目的,必须考虑如何处理哈希冲突。一种方法是添加随机性,以减少冲突概率。另一种方法是使用唯一性索引来验证生成的ID是否已经存在。
-
安全性:
- 在安全敏感的应用中,应选择具有高度安全性的哈希算法,以抵抗各种攻击,如彩虹表攻击。
- bcrypt、scrypt、Argon2等密码哈希算法通常用于存储密码和生成安全的唯一ID。
在使用哈希算法生成唯一ID时,需要仔细考虑哈希算法的特性和限制,以确保生成的ID符合应用的需求和安全性要求。选择合适的哈希算法和处理哈希冲突的方法是关键步骤。
自定义算法
自定义算法生成唯一ID时,通常需要根据具体应用的需求和特定的场景来设计算法,以确保生成的ID满足唯一性和其他要求。以下是一个详细的介绍,说明如何设计和实现自定义唯一ID生成算法:
-
确定需求和约束:
在设计自定义唯一ID生成算法之前,首先需要明确应用的需求和约束。这包括:- ID的长度:确定ID的位数或字节数。
- 唯一性:确保生成的ID在整个应用中是唯一的。
- 分布式支持:如果应用在分布式环境中运行,需要考虑如何在多台服务器上生成唯一ID。
- 安全性:是否需要考虑ID的安全性,以防止恶意伪造或预测。
-
选择数据元素:
确定要包含在生成的ID中的数据元素。这些数据元素可以是时间戳、机器标识符、应用程序标识符、随机数或其他自定义数据。通常,时间戳可以确保ID的唯一性和排序性。 -
分布式支持:
如果应用在分布式环境中运行,需要确保生成的ID在各个节点上都是唯一的。通常,可以使用节点特定的标识符(如数据中心ID和机器ID)来避免ID冲突。 -
ID生成算法:
根据选择的数据元素和需求设计ID生成算法。这通常涉及将不同数据元素组合成一个二进制串,并将其转换为唯一的ID。一种常见的方法是将各个数据元素按照一定规则拼接并使用哈希函数生成ID。 -
唯一性保证:
在生成ID的过程中,需要确保ID的唯一性。这可以通过维护一个已使用的ID列表或使用分布式锁等机制来实现。在分布式环境中,需要确保不同节点之间的ID不会冲突。 -
测试和优化:
设计好算法后,需要进行详尽的测试以确保生成的ID满足需求。测试应该包括不同负载和并发条件下的性能和唯一性验证。根据测试结果,可以对算法进行优化。 -
安全性考虑:
如果应用要求ID的安全性,可以考虑添加加密或签名步骤以保护ID的完整性和防止伪造。 -
持续维护:
随着应用的演化,可能需要不断优化和修改自定义ID生成算法。因此,算法的设计应该具有一定的灵活性,以适应未来需求的变化。
设计自定义唯一ID生成算法需要根据具体应用需求和约束来制定,确保满足唯一性、分布式支持、安全性等要求。这个过程需要综合考虑多个因素,并进行充分的测试和维护以确保算法的可靠性和性能。
总结
生成唯一ID的方法多种多样,可以根据具体的应用需求和场景选择合适的方法。以下是对前述提到的几种方法的总结:
-
自增序列:
- 优点:简单、易于实现,适用于关系型数据库中的主键生成。
- 缺点:不适用于分布式系统,可能存在性能瓶颈。
-
UUID(Universally Unique Identifier):
- 优点:全局唯一,不依赖于中央控制机构,适用于分布式系统。
- 缺点:生成的ID相对较长,不适用于需要紧凑ID的场景。
-
雪花算法(Snowflake Algorithm):
- 优点:分布式环境下生成全局唯一ID,包含时间戳和节点信息。
- 缺点:可能存在时钟回拨问题,需要仔细设计和配置。
-
哈希算法:
- 优点:能够将任意数据映射为唯一的哈希值,适用于数据完整性验证和数据比对。
- 缺点:不适用于需要连续的、有序的ID的场景。
-
自定义算法:
- 优点:根据具体需求设计,能够灵活满足应用需求,可用于生成唯一ID以及满足特定约束。
- 缺点:需要自行设计和实现,可能需要更多的开发工作。
综合考虑,选择哪种方法应取决于应用的具体需求和场景。如果需要在分布式环境下生成唯一ID,UUID或雪花算法是较好的选择。如果需要紧凑的唯一ID,自定义算法可以根据具体需求进行设计。哈希算法适合数据完整性验证等场景,而自增序列适用于关系型数据库中的主键生成。无论选择哪种方法,都需要考虑唯一性、性能、安全性等因素,并进行充分的测试和优化。
相关文章:
唯一ID如何生成,介绍一下目前技术领域最常使用的几种方法
纵使十面大山,又如何,无妨… 概述 唯一ID(Unique Identifier)是在计算机科学和信息技术领域中用于标识某个实体或数据的唯一标识符。生成唯一ID的方法可以根据具体需求和应用场景的不同而有所不同。以下是一些目前技术领域中常用…...
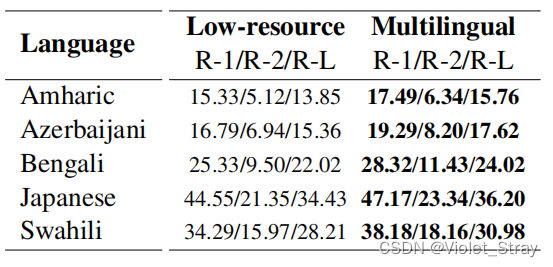
【翻译】XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Languages
摘要 当代的关于抽象文本摘要的研究主要集中在高资源语言,比如英语,这主要是因为低/中资源语言的数据集有限。在这项工作中,我们提出了XL-Sum,这是一个包含100万篇专业注释的文章摘要对的综合多样数据集,从BBC中提取&…...
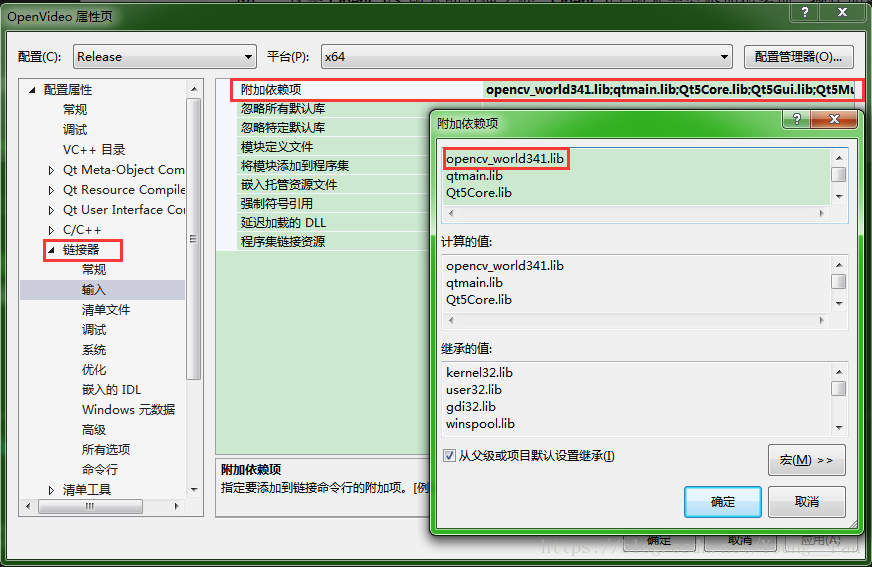
配置OpenCV
Open CV中包含很多图像处理的算法,因此学会正确使用Open CV也是人脸识别研究的一项重要工作。在 VS2017中应用Open CV,需要进行手动配置,下面给出在VS2017中配置Open CV的详细步骤。 1.下载并安装OpenCV3.4.1与VS2017的软件。 2.配置Open CV环…...

1-时间复杂度和空间复杂度
为了找到最适合当前问题而估量“算法”的评价s 时间复杂度空间复杂度执行效率:根据算法编写出的程序,执行时间越短,效率就越高占用的内存空间:不同算法编写出的程序,执行时占用的内存空间也不相同。如果实际场景中仅能…...

EtherCAT主站SOEM -- 3 -- SOEM之ethercatconfig.h/c文件解析
EtherCAT主站SOEM -- 3 -- SOEM之ethercatconfig.h/c文件解析 一 ethercatconfig.h/c文件功能预览:二 ethercatconfig.h/c 中主要函数的作用:2.1.1 ec_config_init(uint8 usetable) 和 ecx_config_init(ecx_contextt *context, uint8 usetable)ÿ…...

洗地机哪个品牌好?家用洗地机选购攻略
随着家用洗地机的普及和市场的广泛认可,进入洗地机行业的制造商也越来越多。在面对众多洗地机品牌时,消费者常常感到困惑,不知道如何选择。面对众多选择,选择有良好保障的知名洗地机品牌是明智之举。知名品牌在质量、售后服务等方…...
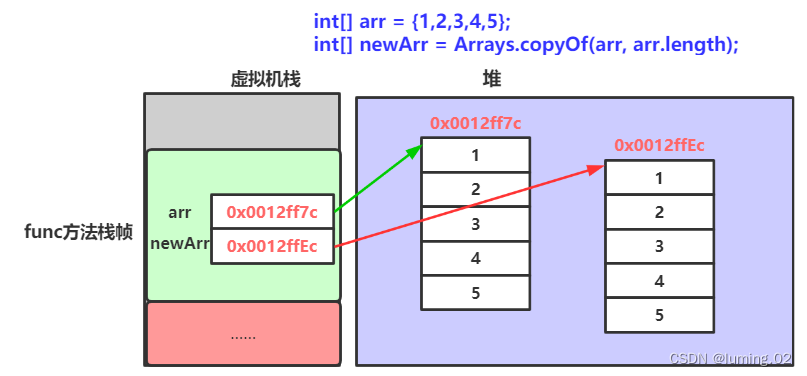
Java数组的定义与常用使用方法
目录 一.什么是数组 二.数组的创建及初始化 数组的创建 数组的初始化 动态初始化: 静态初始化: 【注意】 三.数组的使用 数组中元素访问 遍历数组 四.数组作为方法的参数 参数传基本数据类型 参数传数组类型(引用数据类型) 作为方法的返回…...
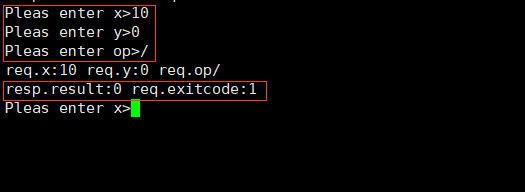
[计算机网络]认识“协议”
认识“协议” 文章目录 认识“协议”序列化和反序列化网络计算器引入Sock类设计协议编写服务端类启动服务端编写客户端类启动客户端程序测试 序列化和反序列化 在网络体系结构中,应用层的应用程序会产生数据,这个数据往往不是简单的一段字符串数据&…...

“Notepad++“ 官网地址
notepad官网下载地址:https://notepad-plus-plus.org/downloads/ npp.8.5.8.Installer.x64 本下载地址- https://download.csdn.net/download/namekong8/88494023 1. Fix session file data loss issue. 2. Fix Explorer context menu "Edit with Notepad…...
基于单片机的自动感应门设计
博主主页:单片机辅导设计 博主简介:专注单片机技术领域和毕业设计项目。 主要内容:毕业设计、简历模板、学习资料、技术咨询。 文章目录 主要介绍一、自动感应门设计的功能概述二、系统总体方案2.1系统的总体计划2.2元器件的介绍2.2.1单片机的…...

【密评】商用密码应用安全性评估从业人员考核题库(二十-完结)
商用密码应用安全性评估从业人员考核题库(二十-完结) 国密局给的参考题库5000道只是基础题,后续更新完5000还会继续更其他高质量题库,持续学习,共同进步。 4640 单项选择题 在测评过程中遇到的PEM编码格式,…...

Tigger绕过激活锁/屏幕锁隐藏工具,支持登入iCloud有消息通知,支持iOS12.0-14.8.1。
绕过激活锁工具Tigger可以用来帮助因为忘记自己的ID或者密码而导致iPhone/iPad无法激活的工具来绕过自己的iPhone/iPad。工具支持Windows和Mac。 工具支持的功能: 1.Hello界面两网/三网/无基带/乱码绕过,可以完美重启,支持iCloud登录、有消…...

VueX mapState、mapGetters、mapActions和mapMutaions 的使用
一、mapState和mapGetters 如果我们想要读取VueX中的State数据的Getters数据时,需要使用$store.state.数据名 和 $store.getters.数据名。 当我们State和getters中的数据多了以后,书写会很麻烦: 如果我们想要使用方便可以配置计算属性来简化…...

GMP标准的制药级层流细胞实验室核心要点
随着生物医药技术的飞速发展,制药行业对细胞疗法和细胞药物的需求日益增长。这推动了制药级层流细胞实验室的发展,其作为生物医药研发的关键基础设施,为制药企业提供了进行细胞培养、基因编辑、疫苗研发等工作的高效平台。本文就围绕GMP标准的…...
[免费] 适用于 Windows的10 的十大数据恢复软件
Windows 10是微软开发的跨平台和设备应用程序的操作系统。它启动速度更快,具有熟悉且扩展的“开始”菜单,甚至可以在多种设备上以新的方式工作。所以,Windows 10非常流行,我们用它来保存我们的照片、音乐、文档和更多文件。但有时…...
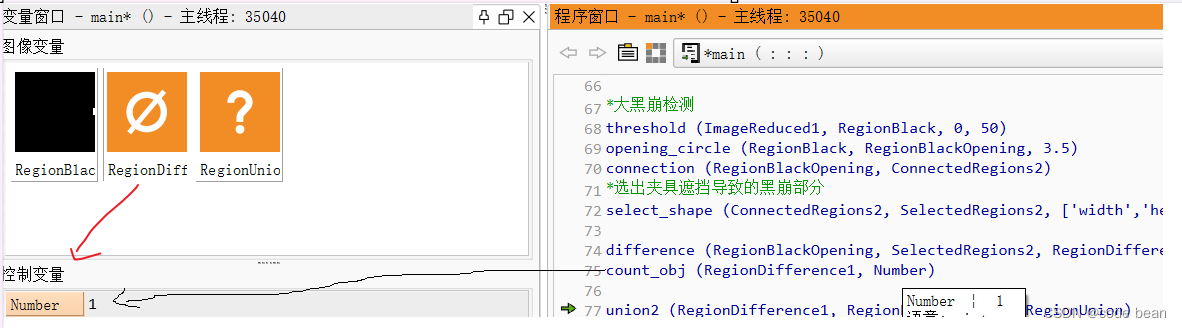
【halcon踩坑】区域为空但个数是1
背景 我在做瑕疵检测的时候,通过计算瑕疵区域的个数(count_obj())是否为0,来判断是否有瑕疵,如果不为0,那边我就会在图片上标记这个瑕疵的位置! 但是有一次我发现明明没…...
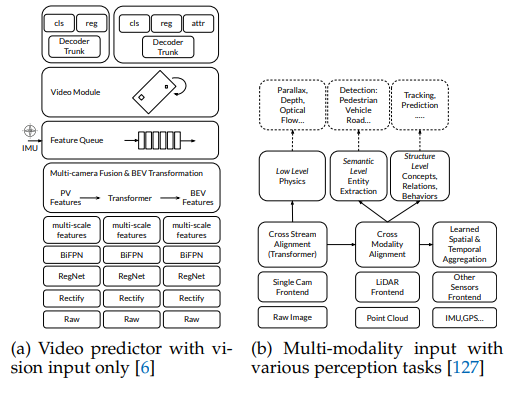
第二十四章 BEV感知系列一(车道线感知)
前言 近期参与到了手写AI的车道线检测的学习中去,以此系列笔记记录学习与思考的全过程。车道线检测系列会持续更新,力求完整精炼,引人启示。所需前期知识,可以结合手写AI进行系统的学习。 BEV感知系列是对论文Delving into the De…...
C++入门讲解第一篇
大家好,我是Dark Fire,终于进入了C的学习,我知道面对我的将是什么,就算变成秃头佬,也要把C学好,今天是C入门第一篇,我会尽全力将知识以清晰易懂的方式表达出,希望我们一起加油&#…...
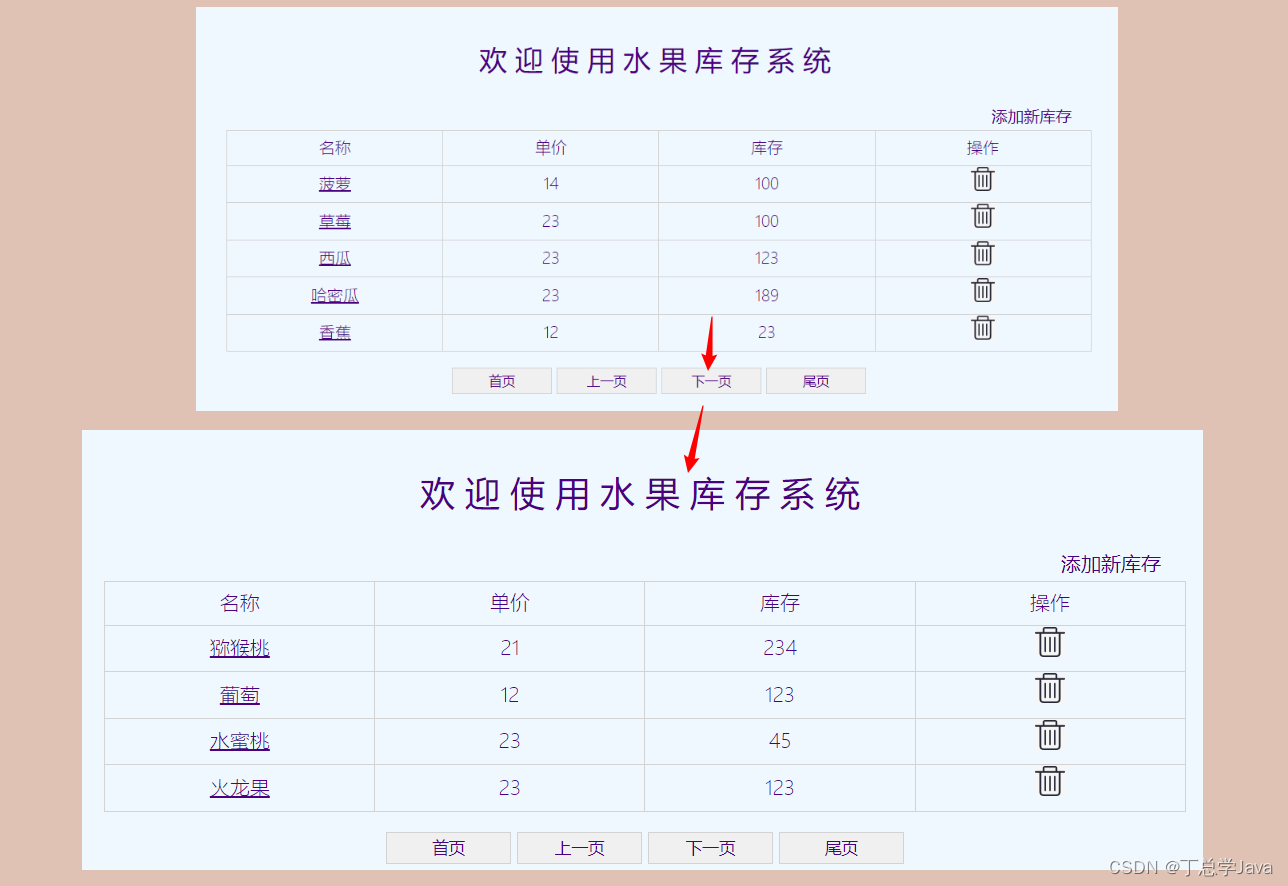
项目实战:分页功能实战
1、在index.html添加点击事件 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>Title</title><link rel"stylesheet" href"style/index.css"><script src"scr…...

AI人工智能大模型应用如何落地?
人工智能大模型是近年来人工智能领域的一项重要技术突破,其具备强大的计算能力和学习能力,能够处理大规模的数据和复杂的任务。 然而,要将人工智能大模型应用落地并实现实际价值,还需要克服一些挑战和问题。 首先,人…...

别再手动算q值了!用Excel地理探测器软件包,5分钟搞定空间分异分析
别再手动算q值了!用Excel地理探测器软件包,5分钟搞定空间分异分析 地理空间数据分析中,识别变量间的分异特征和驱动因子一直是研究难点。传统方法依赖复杂公式推导和编程实现,让许多研究者望而却步。而地理探测器(Geod…...

RK3588平台LVGL 8.2移植实战:从FrameBuffer到DRM驱动优化
1. 项目概述与核心价值最近在RK3588平台上折腾嵌入式GUI,发现LVGL(Light and Graphics Library)这个开源图形库确实是个宝藏。它轻量、跨平台,而且从8.0版本开始,图形渲染效率和功能都有了质的飞跃。我手头正好有一块E…...

强力解决腾讯游戏卡顿:sguard_limit资源限制器终极指南
强力解决腾讯游戏卡顿:sguard_limit资源限制器终极指南 【免费下载链接】sguard_limit 限制ACE-Guard Client EXE占用系统资源,支持各种腾讯游戏 项目地址: https://gitcode.com/gh_mirrors/sg/sguard_limit 玩腾讯游戏时突然卡顿,帧率…...

VScode:将VScode界面的显示语言改为简体中文
这是 VS Code 设置语言的标准方式,直接强制指定界面语言: 在 VS Code 界面按下快捷键 Ctrl Shift P(Windows/Linux),Mac 用户用 Cmd Shift P,打开「命令面板」 在弹出的输入框里,输入 Confi…...

【SI_DP】深入理解DP协议AUX通道信号
1. DP AUX通道概述 1.1. DP协议AUX信号概述 DisplayPort(DP)协议中的AUX差分信号是一条独立的双向传输辅助通道,采用交流耦合差分传输方式。 该通道为半双工传输,单一方向速率约为1Mbit/s,主要用于传输设定与控制指…...
物理层设计解析)
5G NR(新空口)物理层设计解析
5G NR(新空口)物理层设计解析 在无线通信技术的演进过程中,5G NR(新空口)作为第五代移动通信技术的核心组成部分,其物理层设计承载着提升数据传输速率、降低时延、增强连接密度等多重目标。本文将围绕5G NR…...

深入解析Roll:轻量级滚动动画库的设计原理与工程实践
1. 项目概述:一个轻量级、可扩展的滚动动画库在Web前端开发中,滚动动画(Scroll Animation)早已不是新鲜概念。从早期简单的视差效果,到如今复杂的元素交互动画,滚动动画已经成为提升用户体验、增强页面叙事…...

实战指南:深度解析markmap思维导图转换架构与多格式输出优化
实战指南:深度解析markmap思维导图转换架构与多格式输出优化 【免费下载链接】markmap Build mindmaps with plain text 项目地址: https://gitcode.com/gh_mirrors/ma/markmap markmap是一个强大的开源工具,能够将结构化的Markdown文本转换为交互…...

WinFlexBison深度解析:Windows平台编译工具链的完整解决方案
WinFlexBison深度解析:Windows平台编译工具链的完整解决方案 【免费下载链接】winflexbison Main winflexbision repository 项目地址: https://gitcode.com/gh_mirrors/wi/winflexbison 在Windows平台上开发编译器、解释器或复杂文本解析器时,开…...

为Cursor AI编程助手配置安全规则:防范代码生成风险
1. 项目概述:为什么我们需要为Cursor定制安全规则如果你是一名开发者,并且已经开始使用Cursor这样的AI编程助手,那你大概率已经体会过它带来的效率革命。它能帮你生成代码、重构函数、甚至解释复杂的逻辑。但效率提升的同时,一个隐…...