MySQL InnoDB数据存储结构
1. 数据库的存储结构:页
索引结构给我们提供了高效的索引方式,不过索引信息以及数据记录都是保存在文件上的,确切说是存储在页结构中。另一方面,索引是在存储引擎中实现的,MySQL服务器上的存储引擎负责对表中数据的读取和写入工作。
不同的存储引擎中存放的格式一般是不同的,甚至有的存储引擎比如:Memory都不用磁盘来存储数据。
由于InnoDB是MySQL的默认存储引擎,索引本章主要介绍InnoDB存储引擎的数据存储结构。
1.1 磁盘与内存交互基本单位:页


1.2 页结构概述
页a、页b、页c . . .页n 这些页可以不在物流结构上相连,只要通过双向链表相关联即可。每个数据页中的记录会按照主键值从小到大的顺序组成一个单向链表,每个数据页都会为存储在它里面的记录生成一个页目录,在通过主键查找某条记录的时候可以在页目录中使用二分法快速定位到对应的槽,然后再遍历该槽对应分组中的记录即可快速找到指定的记录。
1.3 页的大小
不同的数据库管理系统(简称DBMS)的页大小不同。比如在 MySQL 的 InnoDB 存储引擎中,默认页的大小是 16KB,我们可以通过下面的命令来进行查看:
show variables like '%innodb_page_size%'
SQL Server 中页的大小为 8KB,而在 Oracle 中我们用术语 “块” (Block)来表示 “页”,Oracle 支持的快大小为2KB, 4KB, 8KB, 16KB, 32KB 和 64KB。
1.4 页的上层结构
另外在数据库中,还存在着区(Extent)、段(Segment)和表空间(Tablespace)的概念。行、页、区、段、表空间的关系如下图所示:

-
区(Extent):是比页大一级的存储结构,在InnoDB存储引擎中,一个区会分配64 个连续的页。因为InnoDB中的页大小默认是16KB,所以一个区的大小是 64 * 16KB = 1MB
-
段(Segment):由一个或多个 区 组成,区在文件系统是一个连续分配的空间(在InnoDB中是连续的 64 个页),不过在段中不要求区与区之间是相邻的。段是数据库中的分配单位,不同类型的数据库对象以不同的段形式存在。当我们创建数据表、索引的时候,就会相应创建对应的段,比如创建一张表时会创建一个表段,创建一个索引时会创建一个索引段。
-
表空间(Tablespace):是一个逻辑容器,表空间存储的对象是段,在一个表空间中可以有一个或多个段,但是一个段只能属于一个表空间。数据库由一个或多个表空间组成,表空间从管理上可以划分为系统表空间、用户表空间、撤销表空间、临时表空间等。
2. 页的内部结构
页如果按类型划分的话,常见的有 数据页(保存B+树节点)、系统表、Undo 页 和 事务数据页 等。数据页是我们最常使用的页。
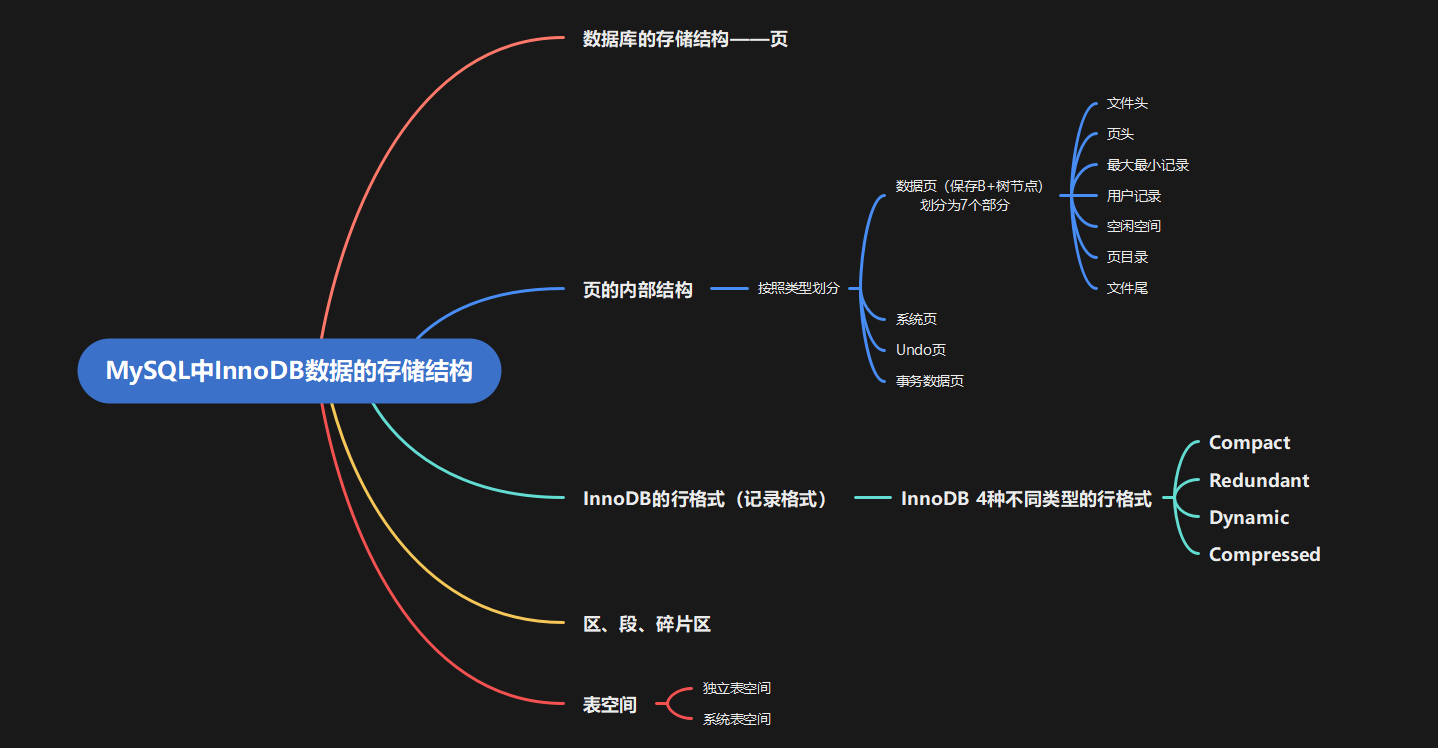
数据页的 16KB 大小的存储空间被划分为七个部分,分别是文件头(File Header)、页头(Page Header)、最大最小记录(Infimum + supremum)、用户记录(User Records)、空闲空间(Free Space)、页目录(Page Directory)和文件尾(File Tailer)。
页结构的示意图如下所示:
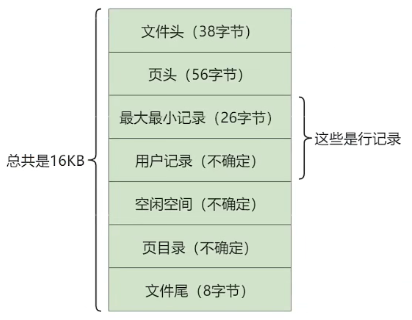
如下表所示:
我们可以把这7个结构分为3个部分。
第一部分:File Header (文件头部) 和 File Trailer (文件尾部)
见文件InnoDB数据库存储结构.mmap
第二部分:User Records (用户记录)、最大最小记录、Free Space (空闲空间)
见文件InnoDB数据库存储结构.mmap
第三部分:Page Directory (页目录) 和 Page Header (页面头部)
见文件InnoDB数据库存储结构.mmap
2.3 从数据库页的角度看B+树如何查询
一颗B+树按照字节类型可以分为两部分:
- 叶子节点,B+ 树最底层的节点,节点的高度为0,存储行记录。
- 非叶子节点,节点的高度大于0,存储索引键和页面指针,并不存储行记录本身。
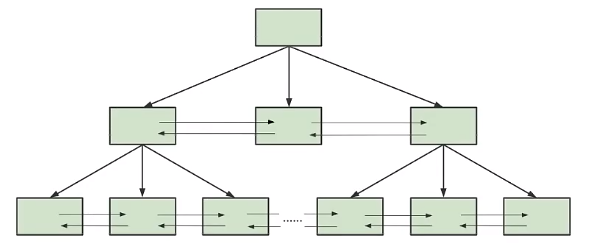
当我们从页结构来理解 B+ 树的结构的时候,可以帮我们理解一些通过索引进行检索的原理:


3. InnoDB行格式 (或记录格式)
见文件InnoDB数据库存储结构.mmap
4. 区、段与碎片区
4.1 为什么要有区?
B+树的每一层中的页都会形成一个双向链表,如果是以页为单位来分配存储空间的话,双向链表相邻的两个页之间的物流位置可能离得非常远。介绍B+树索引的适用场景的时候特别提到范围查询只需要定位到最左边的记录和最右边的记录,然后沿着双向链表一直扫描就可以了,而如果链表中相邻的两个页物理位置离得非常远,就是所谓的随机I/O。再一次强调,磁盘的速度和内存的速度差了好几个数量级,随机I/O是非常慢的,所以我们应该尽量让链表中相邻的页的物流位置也相邻,这样进行范围查询的时候才可以使用所谓的顺序 I/O。
引入区的概念,一个区就是在物理位置上连续的64个页。因为 InnoDB 中的页大小默认是 16KB,所以一个区的大小是 64 * 16KB = 1MB。在表中数据最大的时候,为某个索引分配空间的时候就不再按照页为分单位分配了,而是按照区位单位分配,甚至在表中的数据特别多的时候,可以一次性分配多个连续的区。虽然可能造成一点点空间的浪费(数据不足以填充满整个区),但是从性能角度看,可以消除很多的随机I/O,功大于过!!!
4.2 为什么要有段?
对于范围查询,其实是对B+树叶子节点中的记录进行顺序扫描,而如果不区分叶子节点和非叶子节点,统统把节点代表的页面放到申请到的区中的话,进行范围扫描的效果就大打折扣了。所以InnoDB对B+树的叶子节点 和 非叶子节点 进行了区别对待,也就是说叶子节点有自己独有的区,非叶子节点也有自己独有的额区。存放叶子节点的区的集合就算是一个 段(Segment),存放非叶子节点的区的集合也算是一个段。也就是说一个索引会生成2个段,一个叶子节点段,一个非叶子节点段。
除了索引的叶子节点段和非叶子节点段之外,InnoDB中还有为存储一些特殊的数据而定义的段,比如回滚段,所以,常见的段有数据段、索引段、回滚段。数据段即为B+树的叶子节点,索引段即为B+树的非叶子节点
在InnoDB存储引擎中,对段的管理都是由引擎自身所完成,DBA不能也没有必要对其进行控制。这从一定程度上简化了DBA对于段的管理。
段其实不对应表空间中某一个连续的物理区域,而是一个逻辑上的概念,由若干个零散的页面以及一些完整的区组成。
4.3 为什么要有碎片区?
默认情况下,一个使用InnoDB存储引擎的表只有一个聚簇索引,一个索引会生成2个段,而段是以区为单位申请存储空间的,一个区默认占用1M(64 * 16KB = 1024KB)存储空间,所以默认情况下一个只存了几条记录的小表也需要2M的存储空间,以后每次添加一个索引都要多申请2M的存储空间。这对于存储记录比较少的表太过于浪费。这个问题的症结在于到现在为止介绍的区都是非常纯粹的,也就是一个区被整个分配给某个段,或者说区中的所有页都是为了存储同一个段的数据而存在的,即使段的数据填不满区中所有的页面,那剩余的页也不能挪作他用。
为了考虑以完整的区为单位分配给某个段对于数据量较小的表太浪费存储空间的这种情况,InnoDB提出了一个碎片(Fragment)区的概念。在一个碎片区中,并不是所有的页都是为了存储同一个段的数据而存在的,而是碎片区中的页可以用于不同的目的,比如有些页用于段A,有些页用于段B,有些页甚至哪个段都不属于。碎片区直属于表空间,并不属于任何一个段。
所以以后为某个段分配存储空间的策略如下:
-
在刚开始想表中插入数据的时候,段是从某个碎片区以单个页面为单位来分配存储空间的。
-
当某个段已经占用了32个碎片区页面之后,就会申请以完整的区为单位来分配存储空间。
现在段不能仅定义为是某些区的集合,更精确的应该是 某些零散的页面以及一些完整的区的集合。
4.4 区的分类
区大体上可以分为4种类型:
- 空闲的区 (FREE) : 现在还没有用到这个区中的任何页面。
- 有剩余空间的碎片区 (FREE_FRAG):表示碎片区中还有可用的页面。
- 没有剩余空间的碎片区 (FULL_FRAG):表示碎片区中的所有页面都被使用,没有空闲页面。
- 附属于某个段的区 (FSEG):每一个索引都可以分为叶子节点段和非叶子节点段。
处于FREE、FREE_FRAG 以及 FULL_FRAG 这三种状态的区都是独立的,直属于表空间。而处于 FSEG 状态的区是附属于某个段的。
如果把表空间比作是一个集团军,段就相当于师,区就相当于团。一般的团都是隶属于某个师的,就像是处于 FSEG 的区全部隶属于某个段,而处于 FREE、FREE_FRAG 以及 FULL_FRAG 这三种状态的区却直接隶属于表空间,就像独立团直接听命于军部一样。
5. 表空间
表空间可以看做是InnoDB存储引擎逻辑架构的最高层,所有的数据都存放在表空间中。表空间是一个逻辑容器,表空间存储的对象是段,在一个表空间中可以有一个或多个段,但是一个段只能属于一个表空间。表空间数据库由一个或多个表空间组成,表空间从管理上可以划分为系统表空间(System Tablespace)、独立表空间(File-Per-Table Tablespace)、撤销表空间(Undo Tablespace)和临时表空间(Temporary Tablespace)
5.1 独立表空间
独立表空间,即每张表有一个独立的表空间,也就是数据和索引信息都会保存在自己的表空间中。独立的表空间 (即:单表) 可以在不同的数据库之间进行 迁移。
空间可以回收 (DROP TABLE 操作可自动回收表空间;其他情况,表空间不能自己回收) 。如果对于统计分析或是日志表,删除大量数据后可以通过:alter table TableName engine=innodb; 回收不用的空间。对于使用独立表空间的表,不管怎么删除,表空间的碎片不会太严重的影响性能,而且还有机会处理。
独立表空间结构
独立表空间由段、区、页组成。
真实表空间对应的文件大小
我们到数据目录里看,会发现一个新建的表对应的 .ibd 文件只占用了 96K,才6个页面大小 (MySQL5.7中),这是因为一开始表空间占用的空间很小,因为表里边都没有数据。不过别忘了这些 .ibd 文件是自扩展的,随着表中数据的增多,表空间对应的文件也逐渐增大。
查看 InnoDB 的表空间类型:
show variables like 'innodb_file_per_table'
你能看到 innodb_file_per_table=ON, 这就意味着每张表都会单词保存一个 .ibd 文件。
5.2 系统表空间
系统表空间的结构和独立表空间基本类似,只不过由于整个MySQL进程只有一个系统表空间,在系统表空间中会额外记录一些有关整个系统信息的页面,这部分是独立表空间中没有的。
InnoDB数据字典
每当我们向一个表中插入一条记录的时候,MySQL校验过程如下:先要校验一下插入语句对应的表存不存在,插入的列和表中的列是否符合,如果语法没有问题的话,还需要直到该表的聚簇索引和所有二级索引对应的根页面是哪个页面,然后把记录插入对应索引的B树中。所以说,MySQL除了保存着我们插入的用户数据之外,还需要保存许多额外的信息,比方说:
-
某个表属于哪个表空间,表里边有多少列。
-
表对应的每一个列的类型是什么。
-
该表有多少索引,每个索引对应哪几个字段,该索引对应的根页在哪个表空间的哪个页。
-
该表有哪些外键,外键对应哪个表的哪些列。
-
某个表空间对应文件系统上文件路径是什么。
删除这些数据并不是我们使用 INSERT 语句插入的用户数据,实际上是为了更好的管理我们这些用户数据而不得以引入的一些额外数据,这些数据页称为 元数据。InnoDB 存储引擎特意定义了一些列的 内部系统表 (internal system table) 来记录这些元数据:
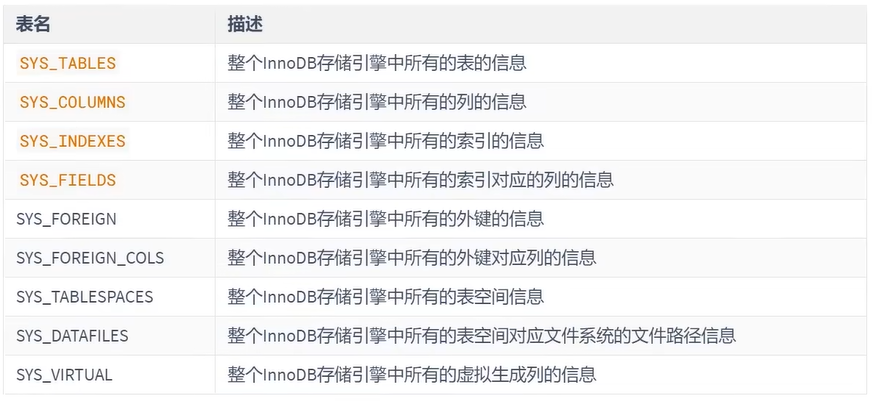
这些系统表也称为 数据字典,它们都是以 B+ 树的形式保存在系统表空间的某个页面中。其中 SYS_TABLES、SYS_COLUMNS、SYS_INDEXES、SYS_FIELDS 这四个表尤其重要,称之为基本系统表 (basic system tables) ,我们先看看这4个表的结构:

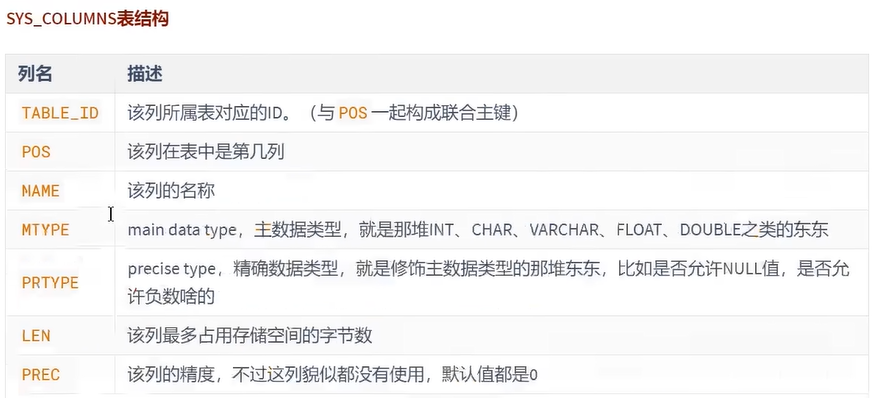
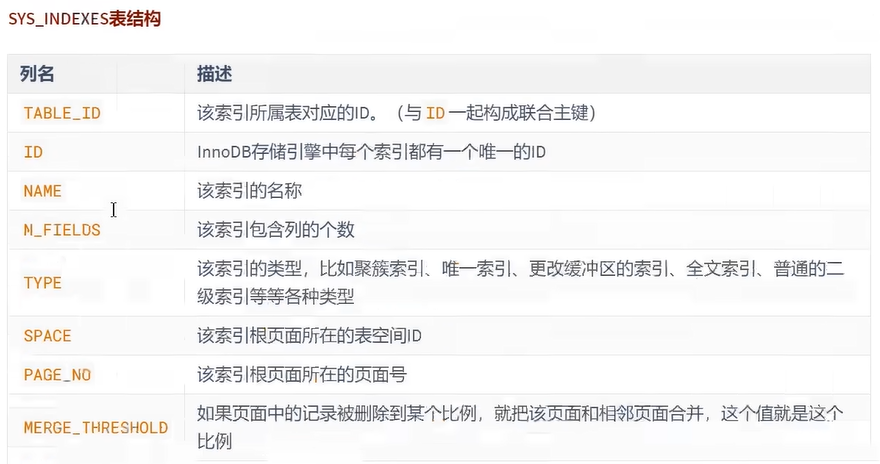

注意:用户不能直接访问 InnoDB 的这些内部系统表,除非你直接去解析系统表空间对应文件系统上的文件。不过考虑到查看这些表的内容可能有助于大家分析问题,所以在系统数据库 information_schema 中提供了一些以 innodb_sys 开头的表:
USE information_schema;
SHOW TABLES LIKE 'innodb_sys%';
在 information_scheme 数据库中的这些以 INNODB_SYS 开头的表并不是真正的内部系统表 (内部系统表就是我们上边以 SYS 开头的那些表),而是在存储引擎启动时读取这些以 SYS 开头的系统表,然后填充到这些以 INNODB_SYS 开头的表中。以 INNODB_SYS 开头的表和以 SYS 开头的表中的字段并不完全一样,但仅供大家参考已经足矣。
附录:数据页加载的三种方式
InnoDB从磁盘中读取数据 最小单位 是数据页。而你想得到的 id = xxx 的数据,就是这个数据页众多行中的一行。
对于MySQL存放的数据,逻辑概念上我们称之为表,在磁盘等物理层面而言是按 数据页 形式进行存放的,当其加载到 MySQL 中我们称之为 缓存页。
如果缓冲池没有该页数据,那么缓冲池有以下三种读取数据的方式,每种方式的读取速率是不同的:
1. 内存读取
如果该数据存在于内存中,基本上执行时间在 1ms 左右,效率还是很高的。
2. 随机读取
如果数据没有在内存中,就需要在磁盘上对该页进行查询,整体时间语句在 10ms 左右,这 10ms 中有 6ms是磁盘的实际繁忙时间(包括了寻道和半圆旋转时间),有 3ms 是对可能发生的排队事件的估计,另外还有 1ms 的传输时间,将页从磁盘服务器缓冲区传输到数据库缓冲区中。这 10ms 看起来很快,但实际上对于数据库来说消耗的时间已经非常长了,因为这还是一个页的读取时间。
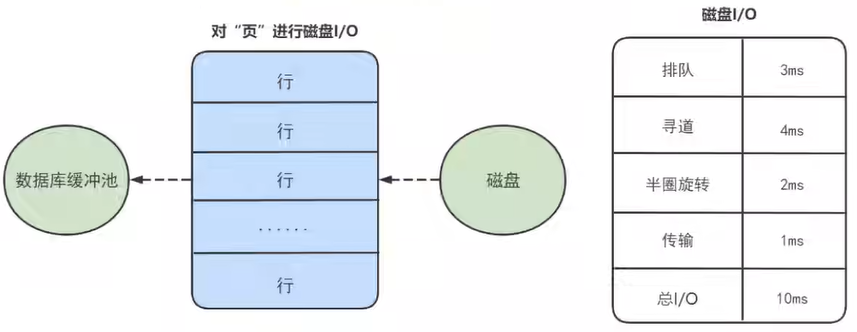
3. 顺序读取
顺序读取其实是一种批量读取的方式,因为我们请求的数据在磁盘上往往都是相邻存储的,顺序读取可以帮助我们批量读取页面,这样的话,一次性加载到缓冲池中就不需要再对其他页单独进行磁盘I/O操作了。如果一个磁盘的吞吐量是 40MB/S,那么对于一个 16KB大小的页来说,一次可以顺序读取 2560(40MB/16KB)个页,相当于一个页的读取时间为 0.4ms。采用批量读取的方式,即使是从磁盘上进行读取,效率也比从内存中只单独读取一个页的效率要高。
相关文章:
MySQL InnoDB数据存储结构
1. 数据库的存储结构:页 索引结构给我们提供了高效的索引方式,不过索引信息以及数据记录都是保存在文件上的,确切说是存储在页结构中。另一方面,索引是在存储引擎中实现的,MySQL服务器上的存储引擎负责对表中数据的读…...

【数据结构】数组和字符串(十五):字符串匹配2:KMP算法(Knuth-Morris-Pratt)
文章目录 4.3 字符串4.3.1 字符串的定义与存储4.3.2 字符串的基本操作4.3.3 模式匹配算法0. 朴素模式匹配算法1. ADL语言2. KMP算法分析3. 手动求失败函数定义例1例2例3 4. 自动求失败函数(C语言)5. KMP算法(C语言)6. 失败函数答案…...

STM32 PWM可控制电压原理
PWM可控制电压原理 主要通过PWM 输入模式根据控制单位时间内输出的平均电压,以调节电压大小。而PWM输出模式通过调节占空比,控制平均电压大小; 设置TIM为PWM输出模式 第一步:时钟使能: GPIO,TIM; 第二步&a…...

angular、 react、vue框架对比
借鉴:Web前端开发:三大主流框架 (baidu.com) AngularReactVue公司ChromeFaceBook尤雨溪写法有指令、模板的概念比较灵活,没有要求使用特定的架构和模式有指令和模板的概念性能低有虚拟Dom,性能高有虚拟Dome,性能高学习门槛 高&am…...

GNSS常用数据源汇总
本文整理汇总了GNSS数据处理过程中常用的数据源,路径中的占位符具体含义如下: -YYYY-年-YY-年的后两位数-DOY-年积日-MM-月-HH-小时-WWWW-GPS周 一、RINEXO观测值与RINEXN星历小时文件 1、CDDIS:ftp://gdc.cddis.eosdis.nasa.gov/pub/gnss…...
01|LangChain | 从入门到实战-介绍
by:wenwenc9 一、基本知识储备 1、什么是大模型,LLM? 大模型(Large Language Model)是近年来一个很热门的研究方向。 使用大量的数据训练出一个非常大的模型。一般是数十亿到上万亿的参数规模。 这些大模型可以捕捉到非常复杂的语言…...
【小白专用】PHP基本语法 23.11.04
PHP基本语法 PHP是超文本预处理器 由服务器解析执行 可以与 html 进行混编(嵌入) ,PHP是一种弱类型语言 1.1 PHP标记 PHP和其他Web语言一样,都是用一对标记将PHP代码包含起来,以便和HTML代码区分开来。PHP支持4种风格的标记,如表所示。 标…...
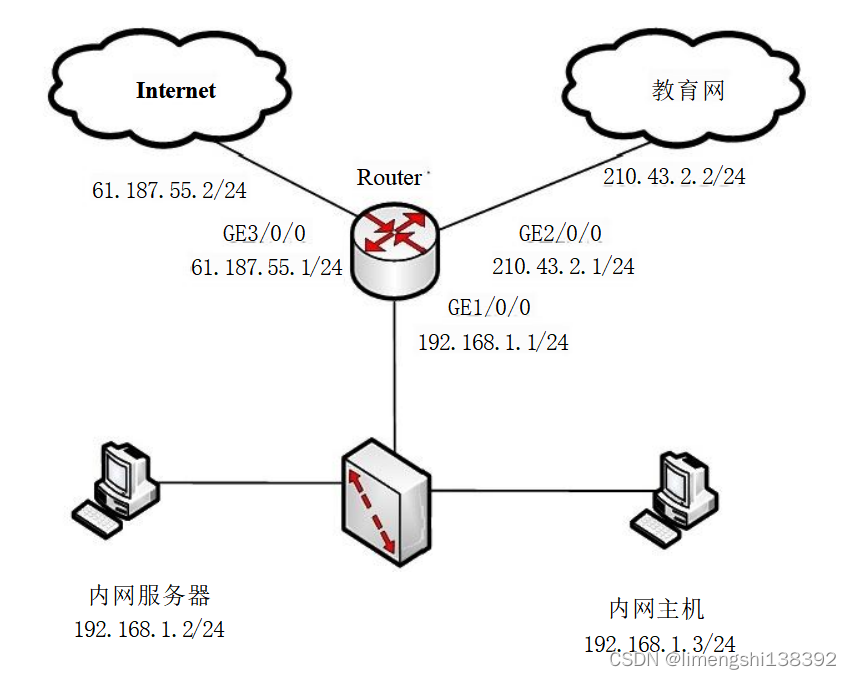
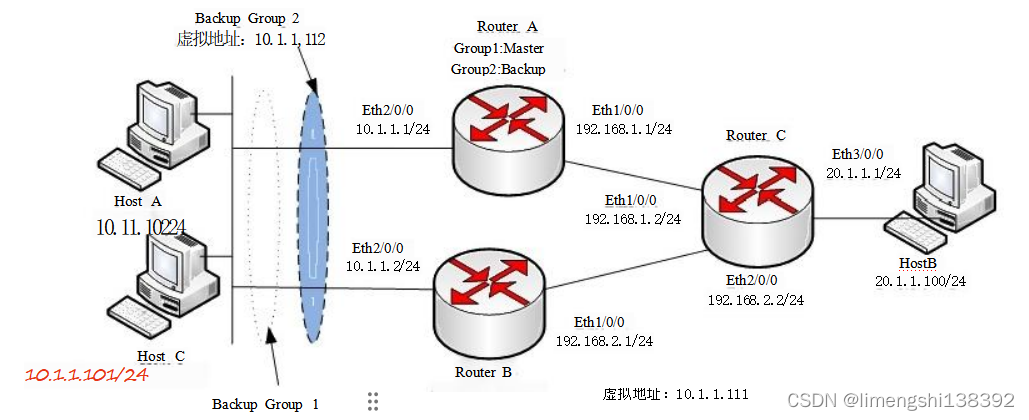
路由器基础(七):NAT原理与配置
一、NAT 配置 华为路由器配置NAT 的方式有很多种,考试中可能考到的基本配置方 式主要有EasyIP和通过NAT地址池的方式。图22-7-1是一个典型的通过EasyIP进行NAT的示意图,其中Router出接口GE0/0/1的IP地址为200.100.1.2/24,接口E0/0/1的IP地址为192.168.0.…...

Spring Boot 整合SpringSecurity和JWT和Redis实现统一鉴权认证
📑前言 本文主要讲了Spring Security文章,如果有什么需要改进的地方还请大佬指出⛺️ 🎬作者简介:大家好,我是青衿🥇 ☁️博客首页:CSDN主页放风讲故事 🌄每日一句:努力…...
交换机基础(零):交换机基础配置
一、华为设备视图 常用视图 名称 进入视图 视图功能 用户视图 用户从终端成功登录至设备即进 入用户视图,在屏幕上显示 kHuawei> 用户可以完成查看运行状态和统 计信息等功能。在其他视图下 都可使用return直接返回用户视 图 系统视图 在用户视图下&…...

02 线性组合、张成的空间与基
线性组合、张成的空间与基 基向量缩放向量并相加给定向量张成的空间线性相关与线性无关空间的基 这是关于3Blue1Brown "线性代数的本质"的学习笔记。 基向量 当看到一对描述向量的数时,比如[3,-2]时,把这对数中的每个数(坐标&…...
解析mfc100u.dll文件丢失的修复方法,快速解决mfc100u.dll问题
在计算机使用过程中,我们经常会遇到一些错误提示,其中最常见的就是“缺少某个文件”的错误。最近,我也遇到了一个这样的问题,那就是“mfc100u.dll丢失”。这个问题可能会导致某些应用程序无法正常运行,给我们带来困扰。…...
免费外文文献检索网站,你一定要知道
01. Sci-Hub 网址链接:https://tool.yovisun.com/scihub/ Sci-hub是一个可以无限搜索、查阅和下载大量优质论文的数据库。其优点在于可以免费下载论文文献。 使用方法: 在Sci—hub搜索栏中粘贴所需文献的网址或者DOI,然后点击右侧的open即可…...

大数据毕业设计选题推荐-收视点播数据分析-Hadoop-Spark-Hive
✨作者主页:IT研究室✨ 个人简介:曾从事计算机专业培训教学,擅长Java、Python、微信小程序、Golang、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。 ☑文末获取源码☑ 精彩专栏推荐⬇⬇⬇ Java项目 Python…...
传智杯-21算法赛初赛B组题目详细解法解析-AB题(C/C++、Python、Java)
🚀 欢迎来到 ACM 算法题库专栏 🚀 在ACM算法题库专栏,热情推崇算法之美,精心整理了各类比赛题目的详细解法,包括但不限于ICPC、CCPC、蓝桥杯、LeetCode周赛、传智杯等等。无论您是刚刚踏入算法领域,还是经验丰富的竞赛选手,这里都是提升技能和知识的理想之地。 ✨ 经典…...

post给后端传递数组和多个参数
这是前端的数据结构 data() {return {loading: false,inputForm: {id: ${gridProject.id},gridName: ,gridId: ,projectName: ,projectId: ,type: },data: [],value: []}}, 其中 gridId 和 type 是单个参数 , value 是个数组,注意 这里data中的value[]不要直接给后…...
音频修复增强软件iZotope RX 10 mac中文特点
iZotope RX 10 mac是一款音频修复和增强软件。 iZotope RX 10 mac主要特点 声音修复:iZotope RX 10可以去除不良噪音、杂音、吱吱声等,使音频变得更加清晰干净。 音频增强:iZotope RX 10支持对音频进行音量调节、均衡器、压缩器、限制器等处…...

【面试】虚拟机栈面试题
目录 一、举例栈溢出的情况二、调整栈大小,能保证不出现溢出吗?三、分配的栈内存越大越好吗?四、垃圾回收是否会涉及到虚拟机栈?五、方法中定义的局部变量是否存在线程安全问题?5.1 说明5.2 代码示例 一、举例栈溢出的…...

白话熵增定律
白话熵增定律 热力学中的熵增定律 熵是指一个系统的混乱程度的度量,是热力学中的一个系统的属性。熵增定律是指一个封闭的系统随着时间的发展,在朝平衡状态发展时,其熵会增加,即其越来越混乱。 对于一个房间,如果经常…...
End-to-end people detection in crowded scenes)
(论文阅读14/100)End-to-end people detection in crowded scenes
文献阅读笔记 简介 题目 End-to-end people detection in crowded scenes 作者 Russell Stewart, Mykhaylo Andriluka 原文链接 https://arxiv.org/pdf/1506.04878.pdf 关键词 Null 研究问题 当前的人员检测器要么以滑动窗口的方式扫描图像,要么对一组离…...
)
保姆级教程:用PyTorch从零复现YOLOv4(附完整代码与Mosaic数据增强实现)
从零构建YOLOv4:代码级实现与核心模块解析 1. 环境配置与工具准备 在开始复现YOLOv4之前,我们需要搭建一个高效的开发环境。推荐使用Python 3.8和PyTorch 1.7的组合,这是目前最稳定的深度学习开发环境之一。 首先安装必要的依赖库:…...

猫抓插件:浏览器资源嗅探与下载的完整手册
猫抓插件:浏览器资源嗅探与下载的完整手册 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 猫抓(cat-catch)是一…...

Linux常用命令合集:从新手到高手的核心操作指南
1. 项目概述:为什么我们需要一个“常用命令合集”?在Linux世界里摸爬滚打十几年,我见过太多新手,也包括一些从其他平台转过来的老手,面对黑漆漆的终端窗口时那种手足无措的茫然。Linux的强大,根植于其命令行…...

Bifrost三星固件下载器:免费跨平台获取官方系统的一站式解决方案
Bifrost三星固件下载器:免费跨平台获取官方系统的一站式解决方案 【免费下载链接】Bifrost Cross-platform tool for downloading Samsung mobile device firmware. 项目地址: https://gitcode.com/gh_mirrors/sa/Bifrost 你是否曾为寻找三星设备官方固件而烦…...

FlicFlac音频格式转换工具:Windows平台轻量级音频处理终极指南
FlicFlac音频格式转换工具:Windows平台轻量级音频处理终极指南 【免费下载链接】FlicFlac Tiny portable audio converter for Windows (WAV FLAC MP3 OGG APE M4A AAC) 项目地址: https://gitcode.com/gh_mirrors/fl/FlicFlac 还在为不同设备间的音频格式兼…...

Scarab空洞骑士模组管理器:5个步骤掌握现代模组管理艺术
Scarab空洞骑士模组管理器:5个步骤掌握现代模组管理艺术 【免费下载链接】Scarab An installer for Hollow Knight mods written with Avalonia. 项目地址: https://gitcode.com/gh_mirrors/sc/Scarab 还在手动解压、复制、配置空洞骑士模组吗?Sc…...

告别卡顿!用华为云ECS搭建eNSP Pro大型网络实验的保姆级避坑指南
华为云ECS部署eNSP Pro全流程性能优化实战 当你在本地PC上尝试运行包含20台NE路由器的复杂拓扑时,风扇狂转的噪音和逐渐卡死的界面是否让你抓狂?作为一位曾经被32GB内存工作站折磨过的网络工程师,我完全理解这种痛苦。直到发现华为云ECS这个&…...

告别Minecraft模组英文界面:MASA全家桶汉化包完全指南
告别Minecraft模组英文界面:MASA全家桶汉化包完全指南 【免费下载链接】masa-mods-chinese 一个masa mods的汉化资源包 项目地址: https://gitcode.com/gh_mirrors/ma/masa-mods-chinese 你是否曾经在Minecraft中面对满屏的英文模组界面感到困惑?…...

CANN/asc-devkit SoftMax接口
SoftMax 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.com/ca…...

Photoshop图层批量导出终极指南:5分钟掌握高效工作流
Photoshop图层批量导出终极指南:5分钟掌握高效工作流 【免费下载链接】Photoshop-Export-Layers-to-Files-Fast This script allows you to export your layers as individual files at a speed much faster than the built-in script from Adobe. 项目地址: http…...