4 Tensorflow图像识别模型——数据预处理
上一篇:3 tensorflow构建模型详解-CSDN博客
本篇开始介绍识别猫狗图片的模型,内容较多,会分为多个章节介绍。模型构建还是和之前一样的流程:
- 数据集准备
- 数据预处理
- 创建模型
- 设置损失函数和优化器
- 训练模型
本篇先介绍数据集准备&预处理。
1、了解监督学习
开始前,需要先了解什么是监督学习。机器学习基于学习方式的分类,可分为:
- 监督学习
- 无监督学习
- 强化学习
百度百科对监督学习的定义是使用标记数据集来训练算法,以便对数据进行分类或准确预测结果。
我们要构建的图片识别模型就属于监督学习的方式,模型的输入是“特征-标签”对,特征就是输入的图片,标签是标记该图片的预期结果(比如该图片是猫还是狗)。
2、训练数据集介绍
网上有很多公开的数据集可以用来学习,初学者不用花很多的时间在数据准备上面。下面是猫狗的数据集下载地址:
https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip
下载后,可以将解压的文件夹放在自己项目的根目录,方便后面读取。
(1)数据集的目录结构

数据集下面有两个子目录,一个训练集(train),一个是验证集(validation),训练集和验证集下面都有猫狗的文件夹,里面是收集好的猫、狗照片。
划分train和validation两个子集,主要是用于训练和评估模型,validation的数据可以看看模型在没有训练过的图片效果如何。
(2)查看数据集数量
本人把数据集放在了当前pycharm项目的根目录,读者可以根据自己实际放的位置替换路径。
import os# 获取训练集和验证集目录
train_dir = os.path.join('cats_and_dogs_filtered/train')
validation_dir = os.path.join('cats_and_dogs_filtered/validation')# 获取训练集猫、狗的目录
train_cats_dir = os.path.join(train_dir, 'cats')
train_dogs_dir = os.path.join(train_dir, 'dogs')# 获取验证集猫、狗的目录
validation_cats_dir = os.path.join(validation_dir, 'cats')
validation_dogs_dir = os.path.join(validation_dir, 'dogs')# 查看训练集猫狗的图片数量
print('训练集猫的图片数量:')
print(len(os.listdir(train_cats_dir)))
print('训练集狗的图片数量:')
print(len(os.listdir(train_dogs_dir)))# 查看验证集猫狗的图片数量
print('验证集猫的图片数量:')
print(len(os.listdir(validation_cats_dir)))
print('验证集狗的图片数量:')
print(len(os.listdir(validation_dogs_dir)))运行结果:
训练集猫的图片数量:
1000
训练集狗的图片数量:
1000
验证集猫的图片数量:
500
验证集狗的图片数量:
500
从运行结果可以了解到训练集一共2000张图片,验证集有1000张。
(3)了解RGB图像
根据百度百科对RGB的定义,RGB是工业界的一种颜色标准,是通过对红(R)、绿(G)、蓝(B)三个颜色通道的变化以及它们相互之间的叠加来得到各式各样的颜色的,RGB即是代表红、绿、蓝三个通道的颜色,这个标准几乎包括了人类视力所能感知的所有颜色,是运用最广的颜色系统之一。
可以用下面的草图辅助理解,比如一张3 X 3 大小的图片,可以解析成由红绿蓝三色通道叠加成的三维数组(图片信息数值仅用于辅助理解,不是该照片的真实值)
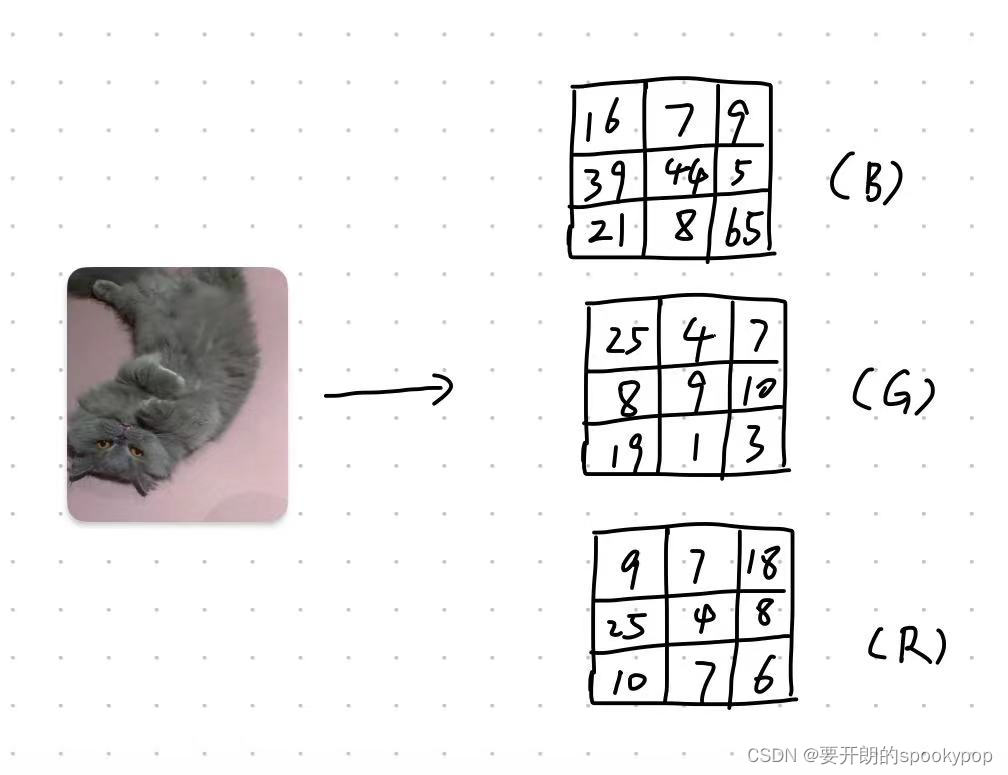
大多数彩色图像可以分为RGB三色通道,我们可以选取训练集的其中一张图片看看:
import os
import cv2# 获取训练集和验证集目录
train_dir = os.path.join('cats_and_dogs_filtered/train')
validation_dir = os.path.join('cats_and_dogs_filtered/validation')# 获取训练集猫、狗的目录
train_cats_dir = os.path.join(train_dir, 'cats')
train_dogs_dir = os.path.join(train_dir, 'dogs')# 获取验证集猫、狗的目录
validation_cats_dir = os.path.join(validation_dir, 'cats')
validation_dogs_dir = os.path.join(validation_dir, 'dogs')# 获取训练集-猫文件的所有文件名称
train_cats_name = os.listdir(train_cats_dir)# 获取其中一张图片的路径
picture_1 = os.path.join(train_cats_dir, train_cats_name[0])# 打印该图片名称
print('图片名称:'+train_cats_name[0])# 读取图片的信息值
picture_1 = cv2.imread(picture_1)# 打印该图片的形状
print(picture_1.shape)运行结果:
图片名称:cat.952.jpg
(375, 499, 3)
可以看到图片cat.952.jpg的尺寸大小是375 X 499,深度是3,即该图片解析为RGB三色通道叠加的三维数组。
再选取另外一张,只需更改下面两句代码:
# 获取其中一张图片的路径
picture_1 = os.path.join(train_cats_dir, train_cats_name[0])# 打印该图片名称
print('图片名称:'+train_cats_name[0])运行结果:
图片名称:cat.946.jpg
(374, 500, 3)
可以看到两张图片的尺寸不一样,神经网络输入需要相同的尺寸大小,所以这些数据集不能直接拿来训练,还需要做数据预处理。
(4)数据预处理
主要有两部分内容:
统一图片大小、按比例缩放
可以先看单张图片的效果,图片尺寸调整为150*150,按1/255比例缩放:
import os
import cv2# 获取训练集和验证集目录
train_dir = os.path.join('cats_and_dogs_filtered/train')
validation_dir = os.path.join('cats_and_dogs_filtered/validation')# 获取训练集猫、狗的目录
train_cats_dir = os.path.join(train_dir, 'cats')
train_dogs_dir = os.path.join(train_dir, 'dogs')# 获取验证集猫、狗的目录
validation_cats_dir = os.path.join(validation_dir, 'cats')
validation_dogs_dir = os.path.join(validation_dir, 'dogs')# 获取训练集-猫文件的所有文件名称
train_cats_name = os.listdir(train_cats_dir)# 获取其中一张图片的路径
picture_1 = os.path.join(train_cats_dir, train_cats_name[0])# 打印该图片名称
print('图片名称:'+train_cats_name[0])# 读取图片的信息值
picture_1 = cv2.imread(picture_1)# 打印该图片的信息值
print(picture_1)picture_2 = cv2.resize(picture_1, (150, 150))
print('调整后的图片形状为:')
print(picture_2.shape)# 除以255缩放图片
picture_2 = picture_1 / 255
print('缩放后的图片信息值矩阵:')
print(picture_2)运行结果:
图片名称:cat.946.jpg
[[[158 157 143]
[128 126 115]
[103 97 92]
...
[ 71 70 66]
[ 71 70 66]
[ 71 70 66]]
[[158 157 143]
[128 126 115]
[103 97 92]
...
[ 74 73 69]
[ 74 73 69]
[ 74 73 69]]
[[157 156 142]
[128 126 115]
[103 97 92]
...
[ 77 76 72]
[ 77 76 72]
[ 77 76 72]]
...
[[128 123 125]
[126 121 123]
[124 119 121]
...
[ 40 61 83]
[ 38 59 81]
[ 37 58 80]]
[[135 132 134]
[132 129 131]
[130 127 129]
...
[ 39 60 82]
[ 38 59 81]
[ 37 58 80]]
[[140 137 139]
[138 135 137]
[135 132 134]
...
[ 39 60 82]
[ 38 59 81]
[ 37 58 80]]]
调整后的图片形状为:
(150, 150, 3)
缩放后的图片信息值矩阵:
[[[0.61960784 0.61568627 0.56078431]
[0.50196078 0.49411765 0.45098039]
[0.40392157 0.38039216 0.36078431]
...
[0.27843137 0.2745098 0.25882353]
[0.27843137 0.2745098 0.25882353]
[0.27843137 0.2745098 0.25882353]]
[[0.61960784 0.61568627 0.56078431]
[0.50196078 0.49411765 0.45098039]
[0.40392157 0.38039216 0.36078431]
...
[0.29019608 0.28627451 0.27058824]
[0.29019608 0.28627451 0.27058824]
[0.29019608 0.28627451 0.27058824]]
[[0.61568627 0.61176471 0.55686275]
[0.50196078 0.49411765 0.45098039]
[0.40392157 0.38039216 0.36078431]
...
[0.30196078 0.29803922 0.28235294]
[0.30196078 0.29803922 0.28235294]
[0.30196078 0.29803922 0.28235294]]
...
[[0.50196078 0.48235294 0.49019608]
[0.49411765 0.4745098 0.48235294]
[0.48627451 0.46666667 0.4745098 ]
...
[0.15686275 0.23921569 0.3254902 ]
[0.14901961 0.23137255 0.31764706]
[0.14509804 0.22745098 0.31372549]]
[[0.52941176 0.51764706 0.5254902 ]
[0.51764706 0.50588235 0.51372549]
[0.50980392 0.49803922 0.50588235]
...
[0.15294118 0.23529412 0.32156863]
[0.14901961 0.23137255 0.31764706]
[0.14509804 0.22745098 0.31372549]]
[[0.54901961 0.5372549 0.54509804]
[0.54117647 0.52941176 0.5372549 ]
[0.52941176 0.51764706 0.5254902 ]
...
[0.15294118 0.23529412 0.32156863]
[0.14901961 0.23137255 0.31764706]
[0.14509804 0.22745098 0.31372549]]]
下面是数据集预处理的代码:
# 模型参数设置
BATCH_SIZE = 100# 图片尺寸统一为150*150
IMG_SHAPE = 150# 处理图像尺寸
train_image_generator = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1. / 255)
validation_image_generator = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1. / 255)train_data_gen = train_image_generator.flow_from_directory(directory=train_dir,batch_size=BATCH_SIZE,target_size=(IMG_SHAPE, IMG_SHAPE),class_mode='binary')
val_data_gen = validation_image_generator.flow_from_directory(directory=validation_dir,batch_size=BATCH_SIZE,target_size=(IMG_SHAPE, IMG_SHAPE),class_mode='binary')- target_size=(IMG_SHAPE, IMG_SHAPE), IMG_SHAPE设为150,即读取数据时统一调整尺寸为150*150
- tf.keras.preprocessing.image.ImageDataGenerator(rescale=1. / 255) 是按1/255比例缩放。因为图片信息的数值矩阵类型为unit8型,在0~255范围内,缩放后将像素值标准化为0-1之间
数据准备好就是成功的一半,后续介绍构建图像识别模型。
相关文章:
4 Tensorflow图像识别模型——数据预处理
上一篇:3 tensorflow构建模型详解-CSDN博客 本篇开始介绍识别猫狗图片的模型,内容较多,会分为多个章节介绍。模型构建还是和之前一样的流程: 数据集准备数据预处理创建模型设置损失函数和优化器训练模型 本篇先介绍数据集准备&am…...
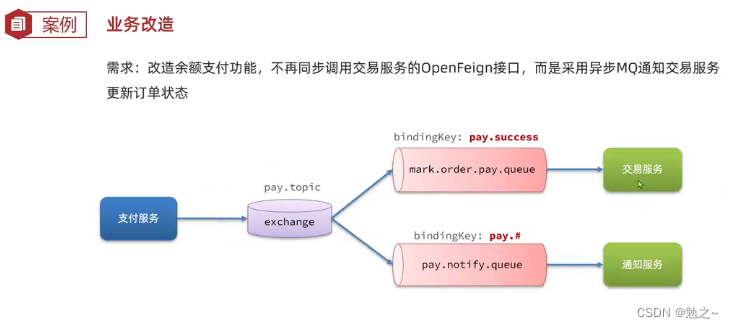
SpringBoot整合RabbitMQ学习笔记
SpringBoot整合RabbitMQ学习笔记 以下三种类型的消息,生产者和消费者需各自启动一个服务,模拟生产者服务发送消息,消费者服务监听消息,分布式开发。 一 Fanout类型信息 . RabbitMQ创建交换机和队列 在RabbitMQ控制台,新…...

在校园跑腿系统小程序中,如何设计高效的实时通知与消息推送系统?
1. 选择合适的消息推送服务 在校园跑腿系统小程序中,选择一个适合的消息推送服务。例如,使用WebSocket技术、Firebase Cloud Messaging (FCM)、或第三方推送服务如Pusher或OneSignal等。注册并获取相关的API密钥或访问令牌。 2. 集成服务到小程序后端…...

求极限Lim x->0 (x-sinx)*e-²x / (1-x)⅓
题目如下: 解题思路: 这题运用了无穷小替换、洛必达法则、求导法则 具体解题思路如下: 1、首先带入x趋近于0,可以得到(0*1)/0,所以可以把e的-x的平方沈略掉 然后根据无穷小替换,利用t趋近于0时…...

JavaScript数据类型详细解析与代码实例
JavaScript是一种弱类型动态语言,数据类型分为原始类型和对象类型。 原始类型 原始类型包括:数字、字符串、布尔值和undefined、null。 数字 JavaScript中的数字类型包括整数和浮点数,可以进行基本的数学运算。 var num1 10; // 整数 v…...
.NET Framework中自带的泛型委托Func
Func<>是.NET Framework中自带的泛型委托,可以接收一个或多个输入参数,并且有返回值,和Action类似,.NET基类库也提供了多达16个输入参数的Func委托,输出参数只有1个。 1、Func泛型委托 .NET Framework为我们提…...

深入理解JVM虚拟机第十七篇:虚拟机栈中栈帧的内部结构
大神链接:作者有幸结识技术大神孙哥为好友,获益匪浅。现在把孙哥视频分享给大家。 孙哥链接:孙哥个人主页 作者简介:一个颜值99分,只比孙哥差一点的程序员 本专栏简介:话不多说,让我们一起干翻JavaScript 本文章简介:话不多说,让我们讲清楚虚拟机栈存储结构和运行原理…...

uniapp中地图定位功能实现的几种方案
1.uniapp自带uni.getLocation uni.getLocation(options) getlocation | uni-app官网 实现思路:uni.getLocation获取经纬度后调用接口获取城市名 优点:方便快捷,直接调用 缺点:关闭定位后延时很久,无法控制定位延迟…...

JS功能实现
目录 轮播图移动端轮播图按下回车发表评论tab栏切换全选按钮 轮播图 <style>* {box-sizing: border-box;}.slider {width: 560px;height: 400px;overflow: hidden;}.slider-wrapper {width: 100%;height: 320px;}.slider-wrapper img {width: 100%;height: 100%;display:…...

connect-history-api-fallback原理
connect-history-api-fallback是一个用于处理前端路由的中间件,它的原理是在服务器接收到请求时,检查请求的路径是否匹配到静态文件(如HTML、CSS、JS等),如果不匹配,则将请求重定向到前端的入口文件&#x…...
Android ConstraintLayout分组堆叠圆角ShapeableImageView
Android ConstraintLayout分组堆叠圆角ShapeableImageView <?xml version"1.0" encoding"utf-8"?> <androidx.constraintlayout.widget.ConstraintLayout xmlns:android"http://schemas.android.com/apk/res/android"xmlns:app"…...
Docker Stack部署应用详解+Tomcat项目部署详细实战
Docker Stack 部署应用 概述 单机模式下,可以使用 Docker Compose 来编排多个服务。Docker Swarm 只能实现对单个服务的简单部署。而Docker Stack 只需对已有的 docker-compose.yml 配置文件稍加改造就可以完成 Docker 集群环境下的多服务编排。 stack是一组共享…...

Compose-Multiplatform在Android和iOS上的实践
本文字数:4680字 预计阅读时间:30分钟 01 简介 之前我们探讨过KMM,即Kotlin Multiplatform Mobile,是Kotlin发布的移动端跨平台框架。当时的结论是KMM提倡将共有的逻辑部分抽出,由KMM封装成Android(Kotlin/JVM)的aar和…...

XXL-JOB 默认 accessToken 身份绕过导致 RCE
文章目录 0x01 漏洞介绍0x02 影响版本0x03 环境搭建0x04 漏洞复现第一步 访问页面返回报错信息第二步 执行POC,进行反弹shell第三步 获取shell0x05 修复建议摘抄免责声明0x01 漏洞介绍 XXL-JOB 是一款开源的分布式任务调度平台,用于实现大规模任务的调度和执行。 XXL-JOB 默…...
所有函数的介绍及使用)
7 库函数之复位和时钟设置(RCC)所有函数的介绍及使用
7 库函数之复位和时钟设置(RCC)所有函数的介绍及使用的介绍及使用 1. 图片有格式二、RCC库函数固件库函数预览2.1 函数RCC_DeInit2.2 函数RCC_HSEConfig2.3 函数RCC_WaitForHSEStartUp2.4 函数RCC_AdjustHSICalibrationValue2.5 函数RCC_HSICmd2.6 函数RCC_PLLConfig2.7 函数…...

第十七节——指令
一、概念 在Vue.js中,指令(Directives)是一种特殊的语法,用于为HTML元素添加特定的行为和功能。指令以v-作为前缀,通过在HTML标签中使用这些指令来操作DOM,修改元素的属性、样式或行为。 Vue.js提供了一组…...

优雅的 Dockerfile 是怎样炼成的?
Docker 简介 目前,Docker 主要有两个形态:Docker Desktop 和 Docker Engine。 Docker Desktop 是专门针对个人使用而设计的,支持 Mac(已支持arm架构的M系芯片) 和 Windows 快速安装,具有直观的图形界面&a…...

2023-2024 中国科学引文数据库来源期刊列表(CSCD)
文章目录 CSCD来源期刊遴选报告2023-2024 中国科学引文数据库来源期刊列表(CSCD) CSCD来源期刊遴选报告 2023-2024 中国科学引文数据库来源期刊列表(CSCD)...

【3D图像分割】基于Pytorch的VNet 3D图像分割5(改写数据流篇)
在这篇文章:【3D 图像分割】基于 Pytorch 的 VNet 3D 图像分割2(基础数据流篇) 的最后,我们提到了: 在采用vent模型进行3d数据的分割训练任务中,输入大小是16*96*96,这个的裁剪是放到Dataset类…...
WebSocket Day02 : 握手连接
前言 握手连接是WebSocket建立通信的第一步,通过客户端和服务器之间的一系列握手操作,确保了双方都支持WebSocket协议,并达成一致的通信参数。握手连接的过程包括客户端发起握手请求、服务器响应握手请求以及双方完成握手连接。完成握手连接后…...

qobuz-dl:无损音乐下载的技术革命与实践指南
qobuz-dl:无损音乐下载的技术革命与实践指南 【免费下载链接】qobuz-dl A complete Lossless and Hi-Res music downloader for Qobuz 项目地址: https://gitcode.com/gh_mirrors/qo/qobuz-dl 在数字音乐时代,音乐爱好者面临着一个永恒的矛盾&…...
)
WebSocket安全连接指南:从HTTP到HTTPS/WSS的平滑迁移(含Nginx配置模板)
WebSocket安全连接指南:从HTTP到HTTPS/WSS的平滑迁移(含Nginx配置模板) 当你的网站从HTTP升级到HTTPS后,原本运行良好的WebSocket连接突然失效,控制台里一片红色错误提示——这可能是许多开发者遇到的典型场景。本文将…...

AI辅助开发:让快马平台智能生成期刊官网架构与核心业务代码
AI辅助开发:让快马平台智能生成期刊官网架构与核心业务代码 最近在做一个学术期刊官网的项目,发现从头开始搭建整个系统的工作量巨大。幸运的是,我发现了InsCode(快马)平台的AI辅助开发功能,它帮我智能生成了整个项目的骨架代码和…...

Mem Reduct内存管理实战指南:从问题诊断到系统优化
Mem Reduct内存管理实战指南:从问题诊断到系统优化 【免费下载链接】memreduct Lightweight real-time memory management application to monitor and clean system memory on your computer. 项目地址: https://gitcode.com/gh_mirrors/me/memreduct 在现代…...

游戏鼠标优化工具:让普通鼠标在macOS上实现专业级体验
游戏鼠标优化工具:让普通鼠标在macOS上实现专业级体验 【免费下载链接】mac-mouse-fix Mac Mouse Fix - Make Your $10 Mouse Better Than an Apple Trackpad! 项目地址: https://gitcode.com/GitHub_Trending/ma/mac-mouse-fix 当你在Final Cut Pro中精准剪…...

WarcraftHelper:面向魔兽争霸III玩家的全方位优化解决方案
WarcraftHelper:面向魔兽争霸III玩家的全方位优化解决方案 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper WarcraftHelper是一款专为魔兽争…...

内存对齐,凭空多出来的空间?
今天学习了一下 C 的结构体(struct)内存,发现这里面的水挺深。如果不了解“内存对齐”,代码很容易就在不知不觉中多占了一堆空间。整理成笔记分享给大家:1. 为什么结构体的大小“不按套路出牌”?先看这个结…...

南北阁Nanbeige 4.1-3B生成效果:Python入门学习路径规划与习题生成
南北阁Nanbeige 4.1-3B生成效果:Python入门学习路径规划与习题生成 最近在尝试各种AI模型,想看看它们在实际应用场景里到底能帮上什么忙。正好有个朋友想学Python,问我有没有好的学习路线推荐。我手头事情多,没法给他从头到尾规划…...

Wan2.2-I2V-A14B企业知识库联动:从内部文档自动生成培训视频
Wan2.2-I2V-A14B企业知识库联动:从内部文档自动生成培训视频 1. 企业知识管理的新范式 在当今快节奏的商业环境中,企业知识管理正面临前所未有的挑战。传统文档形式的培训材料往往存在几个痛点: 更新不及时导致信息滞后员工学习效率低下知…...

YOLOv12在Unity引擎中的集成:打造实时AR目标检测应用
YOLOv12在Unity引擎中的集成:打造实时AR目标检测应用 最近在琢磨一个挺有意思的事儿,怎么把最新的目标检测模型塞到手机里,然后通过摄像头,让虚拟世界的东西“粘”在真实世界的物体上。比如,你手机对着桌子上的一个杯…...