基于 NGram 分词,优化 Es 搜索逻辑,并深入理解了 matchPhraseQuery 与 termQuery
基于 NGram 分词,优化 Es 搜索逻辑,并深入理解了 matchPhraseQuery 与 termQuery
- 前言
- 问题描述
- 排查索引库分词(发现问题)
- 如何去解决这个问题?
- IK 分词器
- NGram 分词器使用
- 替换 NGram 分词器后进行测试
- matchPhraseQuery 查询原理
- termQuery 查询原理
- 总结
前言
之前不是写过一个全局搜索的功能吗,用户在使用的时候,搜(进出口)关键字,说搜不到数据,但是 Es 中确实是有一条标题为 (202009 进出口)的数据的,按道理来说,这确实要命中的,于是我开始回想我当时是如何写的这段搜索逻辑的代码!!!!
问题描述
之前所有检索的字段全是用的 matchPhraseQuery 查询,matchPhraseQuery 命中的条件其一就是,搜索字段所有的分词都要被 Es 词库命中,其二就是命中的分词在词库中的顺序要紧挨着的。不然就没法查出数据。接下来举例帮助大家理解。
if (StringUtils.isNotEmpty(articleRequest.getKeyword())) {for (int i = 0; i < articleRequest.getKeys().length; i++) {boolQuery.should(QueryBuilders.matchPhraseQuery(articleRequest.getKeys()[i], articleRequest.getKeyword()));}}
使用 kibana 控制台,编写一条 DLS语句,由于 Es 默认使用的分词器是用的 standard,于是查看一下查(进出口)关键字,是被分词成了(进,出,口)
POST _analyze
{"analyzer": "standard","text": "进出口"
}
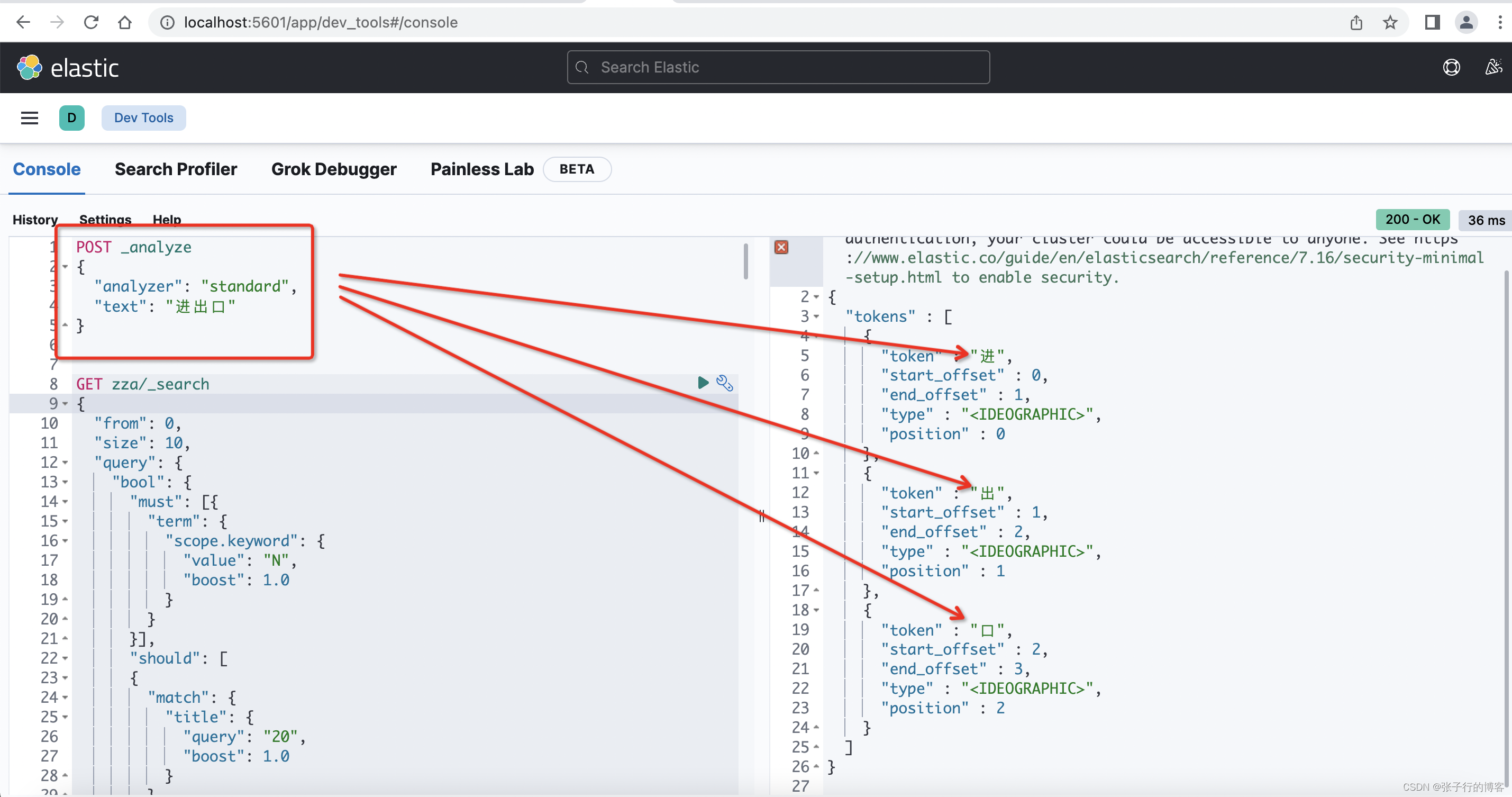
一开始建索引的时候,所有字段都没有指定分词器,都是用的默认的 standard 分词器,因此在使用 matchPhraseQuery 的时候,无论是 title 含有(进出口)还是 body 含有(进出口)关键字的数据都能够被正常检索出来,原因就是词库也是按照(进,出,口)存储的,查的关键字也是被分词成(进,出,口)进行匹配词库查询的,所有分词:位置紧挨着、顺序一致、且完全被包含。

但是后来遇到一个问题就是,搜字母或者是数字,搜不到数据,例如:搜 20 ,但是明明有标题为 (202009 进出口数据 33)的数据,就搜不出来。到这里你会怎么去排查问题?接下来说下我的整个排查问题的流程。
排查索引库分词(发现问题)
基于默认的 standar 分词器查看一下, title 为 (202009 进出口数据33)是如何被分词存到词库中的
POST _analyze
{"analyzer": "standard","text": "202009 进出口数据33"
}
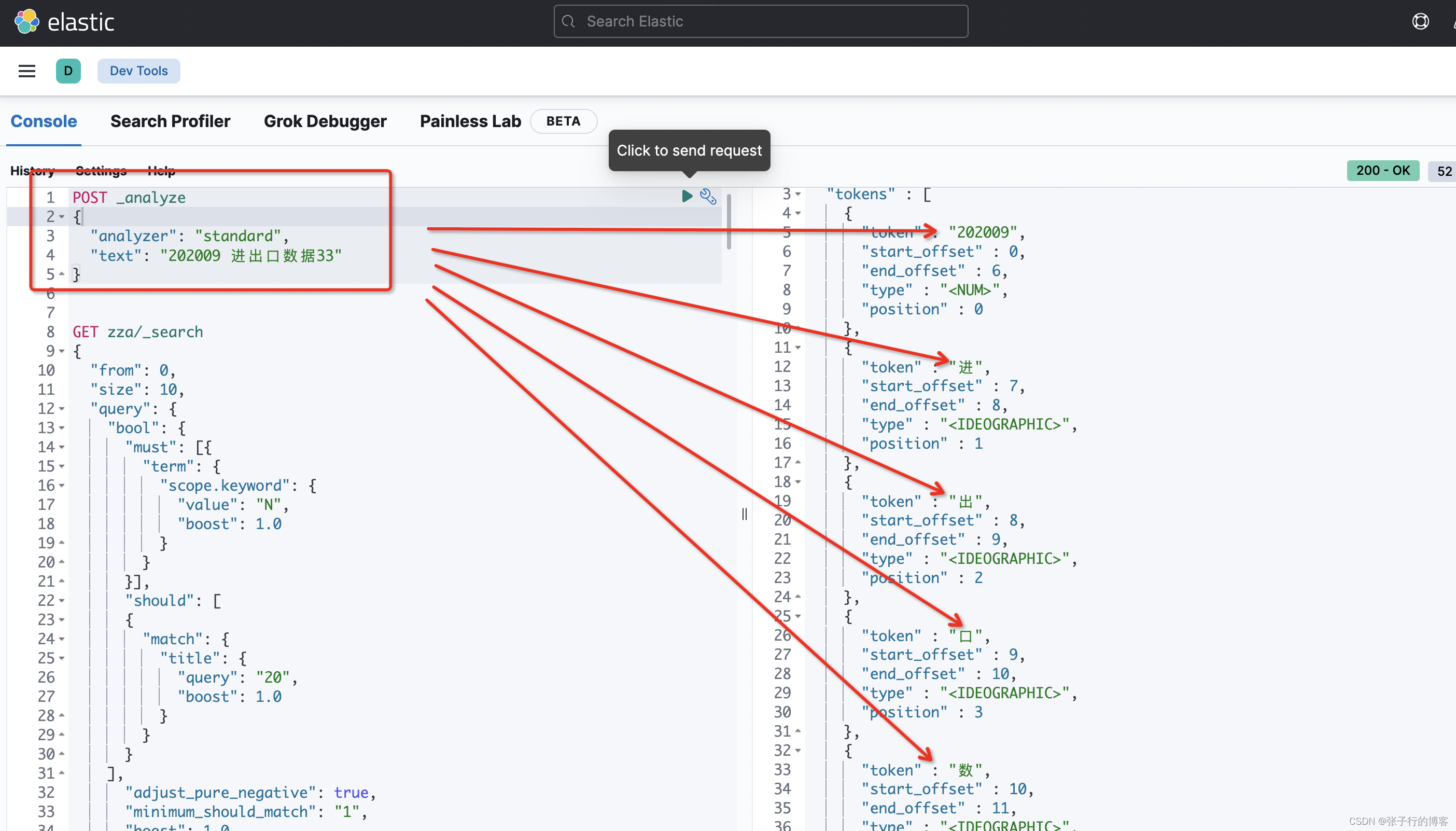
看了一下 202009 居然没有被分词,而是被当做了一个整体,当我们搜 20 的时候,是按照 20 的这个分词进行查询的,但是索引库中并没有 20 的分词,即不满足查询分词都要被词库包含的关系,更不满足分词顺序和词库保持一致,更不满足命中词库中的分词是紧挨着的条件,三大条件都不满足,能查到才怪呢?怎么去优化搜索逻辑?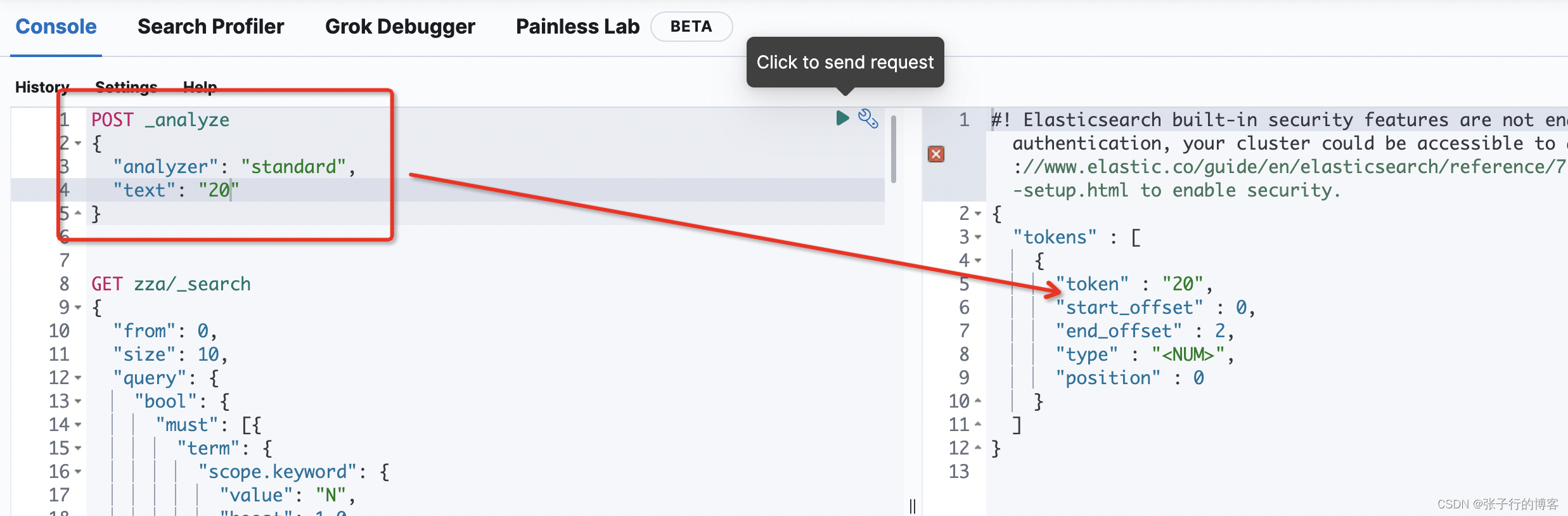
如何去解决这个问题?
接下来肯定就是优化索引库中存储的分词结构了,让 title 为( 202009 进出口数据 33) 的这条数据,存储的分词包含 (20),而不是粗略的包含一个(202009),当然你也可以使用 Es 的 模糊查询 wildcard 或者 fuzzy ,考虑到数据量过大,查询性能不咋地,决定优化索引结构,用空间换时间!!!!为什么是空间换时间?存的分词粒度都变细了,意味着存的索引体积变大,这些数据都要硬件来存储的,可不是空间换时间嘛。接下来用主流的 IK 分词器去分下词看满不满足我们的需求
IK 分词器
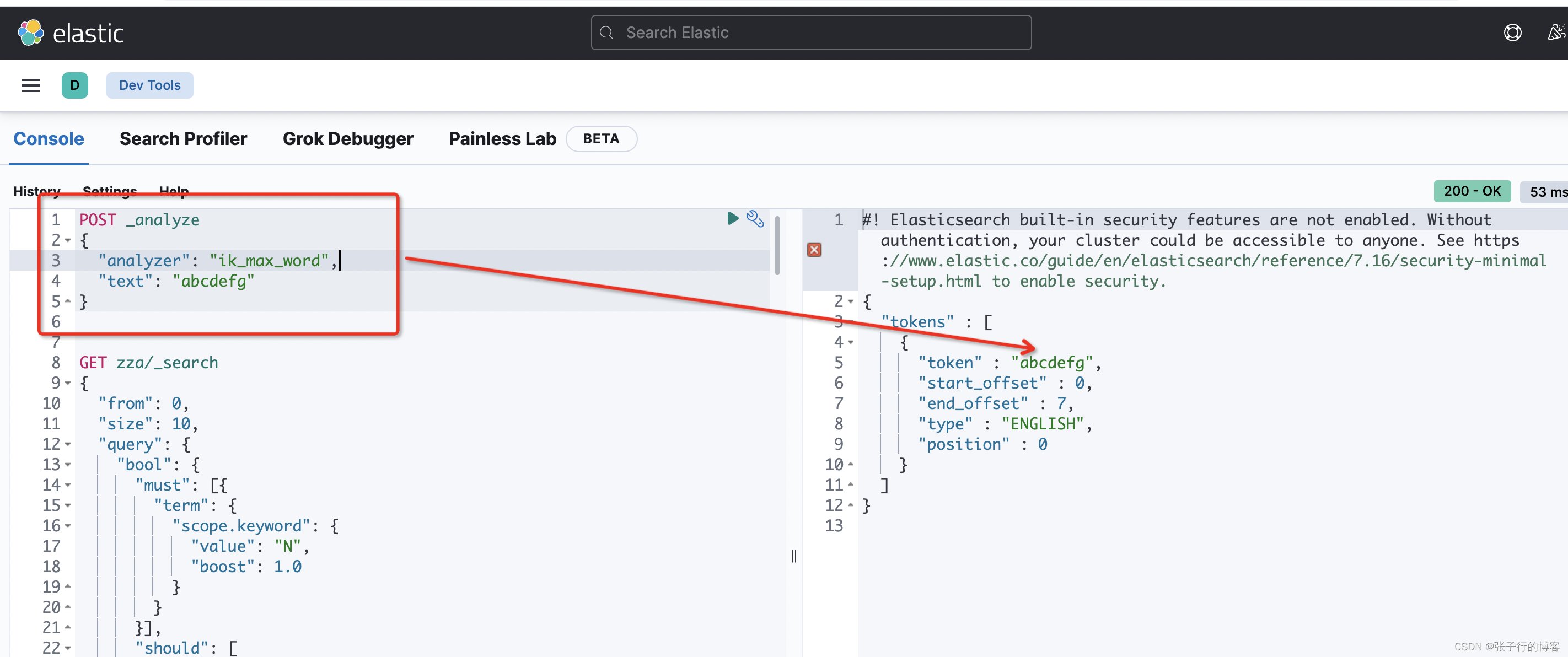
编写 DLS 语句,对目标数据分词,看到还是没有(20)的分词出现,直接 Pass
POST _analyze
{"analyzer": "ik_max_word","text": "202009进出口数据 33"
}
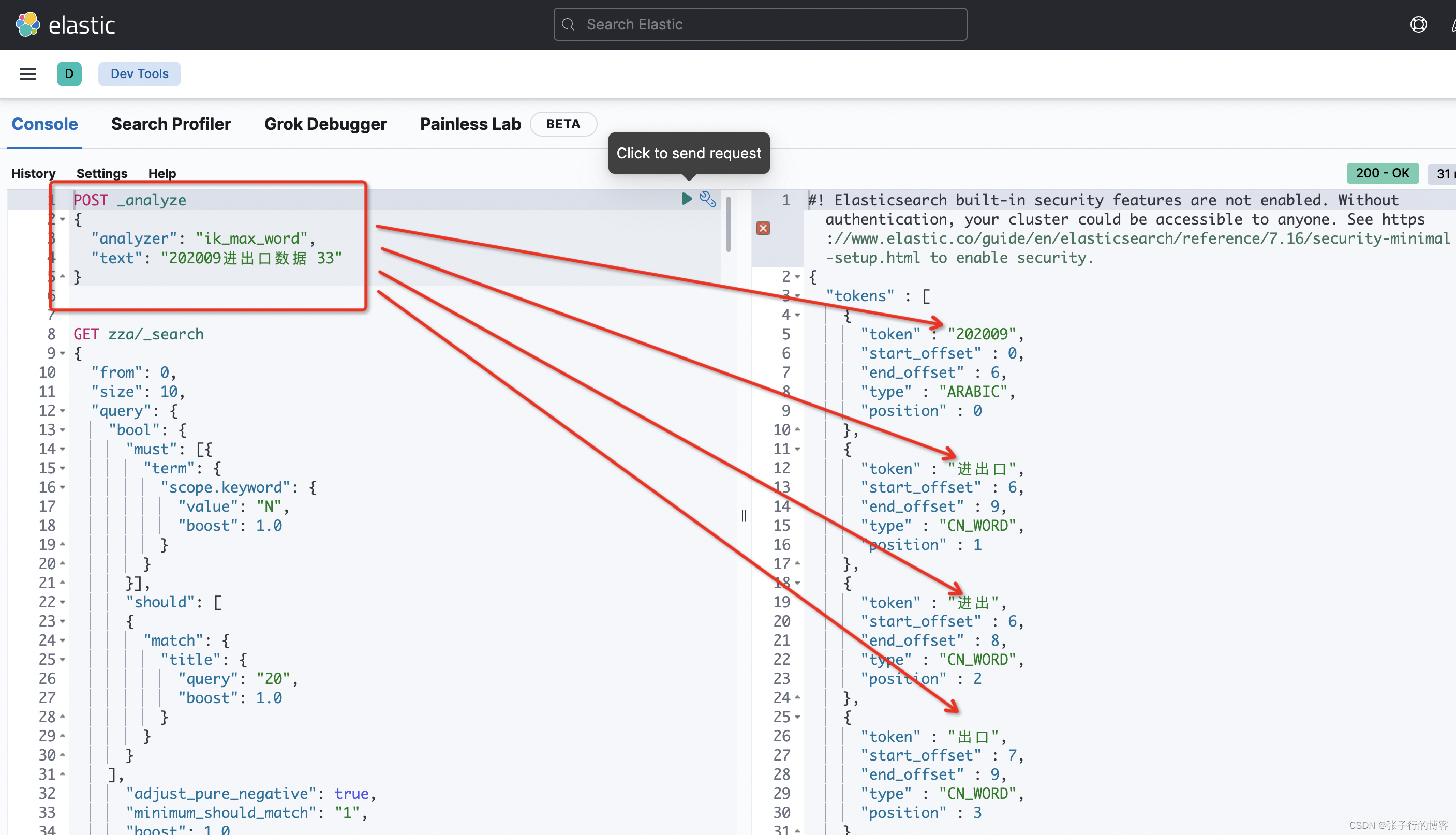
对字母分词一样,粒度不满足我们的需求,直接 Pass
NGram 分词器使用
接下来说本文的主角 NGram 分词器,分词的粒度可以由我们自己控制。在建索引的时候设置一下 Setting 代码都是固定的就好像你使用 Java Api一样,需要注意的是里面的 min_gram 指定最小分词粒度,max_gram 指定最大分词粒度。自定义分词器名字为:my_ngram_analyzer 接来举例说明,这个自定义分词器是干啥的!!!
private static String defaultIndexSetting = "{\n" +" \"index.max_ngram_diff\":10,\n" +" \"analysis\": {\n" +" \"analyzer\": {\n" +" \"my_ngram_analyzer\": {\n" +" \"tokenizer\": \"my_ngram_tokenizer\"\n" +" }\n" +" },\n" +" \"tokenizer\": {\n" +" \"my_ngram_tokenizer\": {\n" +" \"type\": \"ngram\",\n" +" \"min_gram\": 1,\n" +" \"max_gram\": 10,\n" +" \"token_chars\": [\n" +" \"letter\",\n" +" \"digit\"\n" +" ]\n" +" }\n" +" }\n" +" }\n" +" }";
由于我只对 title 字段设置了自定义分词器,mapping 如下。
private static String defaultIndexMapping = "{\n" +"\t\"properties\": {\n" +"\t\t\"author\": {\n" +"\t\t\t\"type\": \"text\",\n" +"\t\t\t\"boost\": \"3\",\n" +"\t\t\t\"fields\": {\n" +"\t\t\t\t\"keyword\": {\n" +"\t\t\t\t\t\"type\": \"keyword\",\n" +"\t\t\t\t\t\"ignore_above\": 256\n" +"\t\t\t\t}\n" +"\t\t\t}\n" +"\t\t},\n" +"\t\t\"body\": {\n" +"\t\t\t\"type\": \"text\",\n" +"\t\t\t\"fields\": {\n" +"\t\t\t\t\"keyword\": {\n" +"\t\t\t\t\t\"type\": \"keyword\",\n" +"\t\t\t\t\t\"ignore_above\": 256\n" +"\t\t\t\t}\n" +"\t\t\t}\n" +"\t\t},\n" +"\t\t\"title\": {\n" +"\t\t\t\"boost\": \"10000\",\n" +"\t\t\t\"type\": \"text\",\n" +"\t\t\t\t\t\t \"analyzer\": \"my_ngram_analyzer\",\n" +"\t\t\t\"fields\": {\n" +"\t\t\t\t\"keyword\": {\n" +"\t\t\t\t\t\"type\": \"keyword\",\n" +"\t\t\t\t\t\"ignore_above\": 256\n" +"\t\t\t\t}\n" +"\t\t\t}\n" +"\t\t},\n" +"\t\t\"createtime\": {\n" +"\t\t\t\"type\": \"date\",\n" +"\t\t\t\"format\": \"yyyy-MM-dd HH:mm:ss||yyyy-MM-dd\"\n" +"\t\t}\n" +"\t}\n" +"}\n";
接下来根据最新的 Setting、Mapping 配置替换之前的旧的索引,然后进行测试
log.info("create index mapping: " + tabIndex.getMapping());CreateIndexRequest indexRequest = new CreateIndexRequest(tabIndex.getIndexName().trim()).settings(tabIndex.getSetting(), XContentType.JSON).mapping("_doc", tabIndex.getMapping(), XContentType.JSON);CreateIndexResponse response = null;try {response = restHighLevelClient.indices().create(indexRequest, RequestOptions.DEFAULT);} catch (IOException e) {e.printStackTrace();tabIndexService.delete(new EntityWrapper<TabIndex>().eq("index_name", tabIndex.getIndexName()));return JsonData.buildError("失败" + e.getMessage());}if (response != null) return JsonData.buildSuccess(response.isAcknowledged());else return JsonData.buildError("失败");
替换 NGram 分词器后进行测试
输入关键字:20,发现 title 为 (202009 进出口数据 33) 的这条数据还是查不到???????what fa,再次检查索引库分词,编写 DLS 语句看看,由于创建的新索引的名称是 zza,这里对 zza 索引下面标题包含 (202009 进出口数据 33)的数据进行分词,看看 Es 是如何存的!!!
POST /zza/_analyze
{"field": "title","text": "202009 进出口数据 33"
}
可以看到此时的分词存储了 (2,20,202…)按道理来说查 2 或者 20 或者 202 等等都可以查到这条数据的。难道见鬼啦?于是我决定将代码的生成的 DLS 语句直接 Copy 到 kibana 中跑一下,看到底是代码 Api 的 Bug 还是其他问题。

于是我就这个 DLS 语句运行了一下,其实不是见鬼了,是我们需要理解一下 termQuery 与 matchPhraseQuery 的查询原理!!!
matchPhraseQuery 查询原理
会将搜索关键字进行分词(这个根据索引用到的分词器一致),然后与词库中的分词进行匹配。例如,现在有一条 title 为(202009 进出口数据 33)的数据,当我们搜 20 的时候,会根据(2,20,0)去匹配词库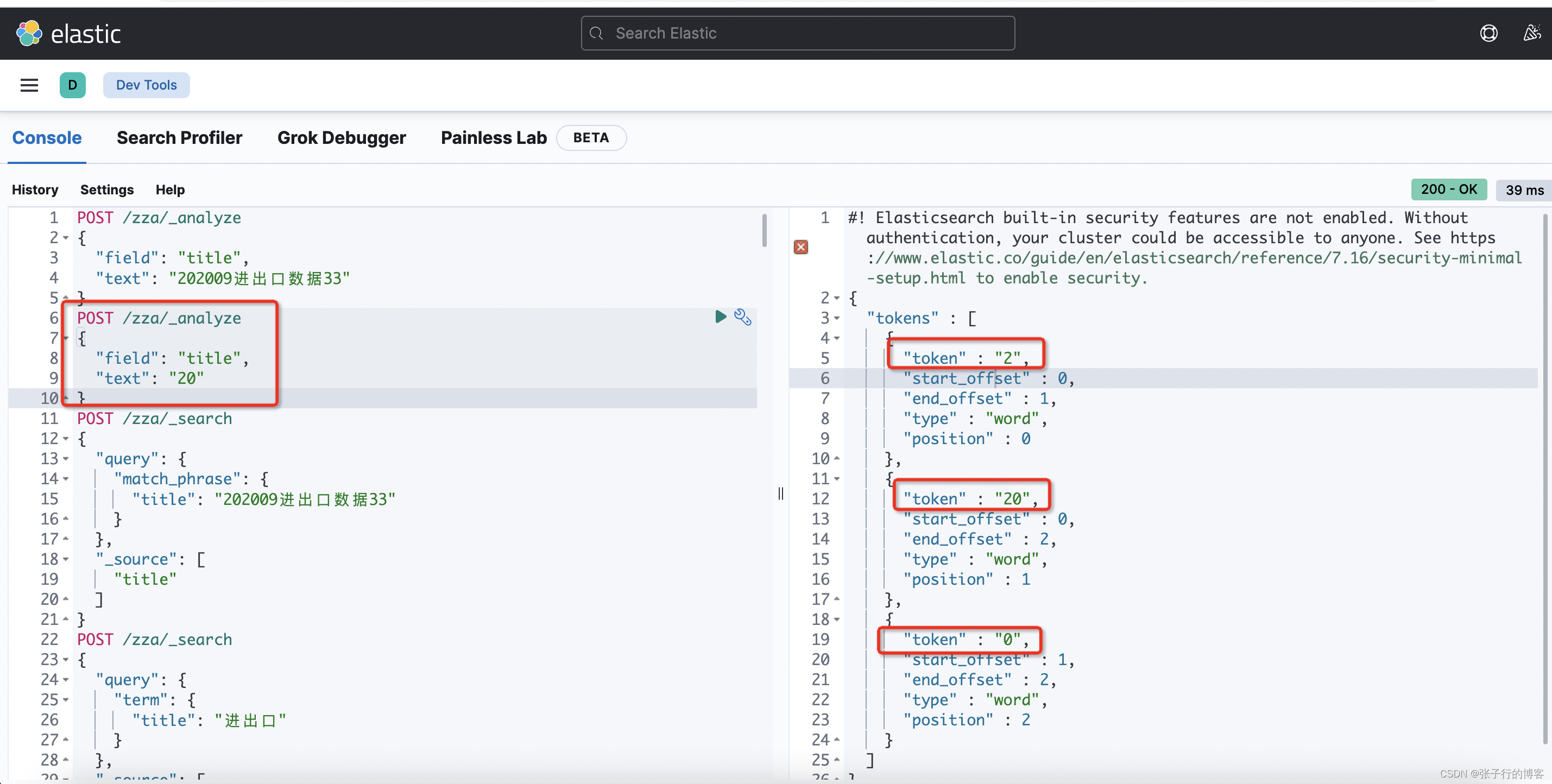
但是此时词库是按照(2,20,202…0)这个顺序存的。
再来回顾一下 matchPhraseQuery 命中索引的三大条件
- 搜索关键字分词要被词库存的分词完全包含
- 在点一的基础上,搜索分词顺序要和词库保持一致
- 在前俩点都满足的情况下,词库中匹配到的分词顺序要紧挨着
我们搜关键字 20 时,满足了上述点 1,2。但是不满足点 3,因此使用 matchPhraseQuery 搜不到 title 为(202009 进出口数据 33)的这条数据。那么有什么办法解决吗?答案是有的。就是指定 slop 参数。指定分词紧挨着的最大单位,默认是 1,通过调大这个参数也可以查出来指定数据
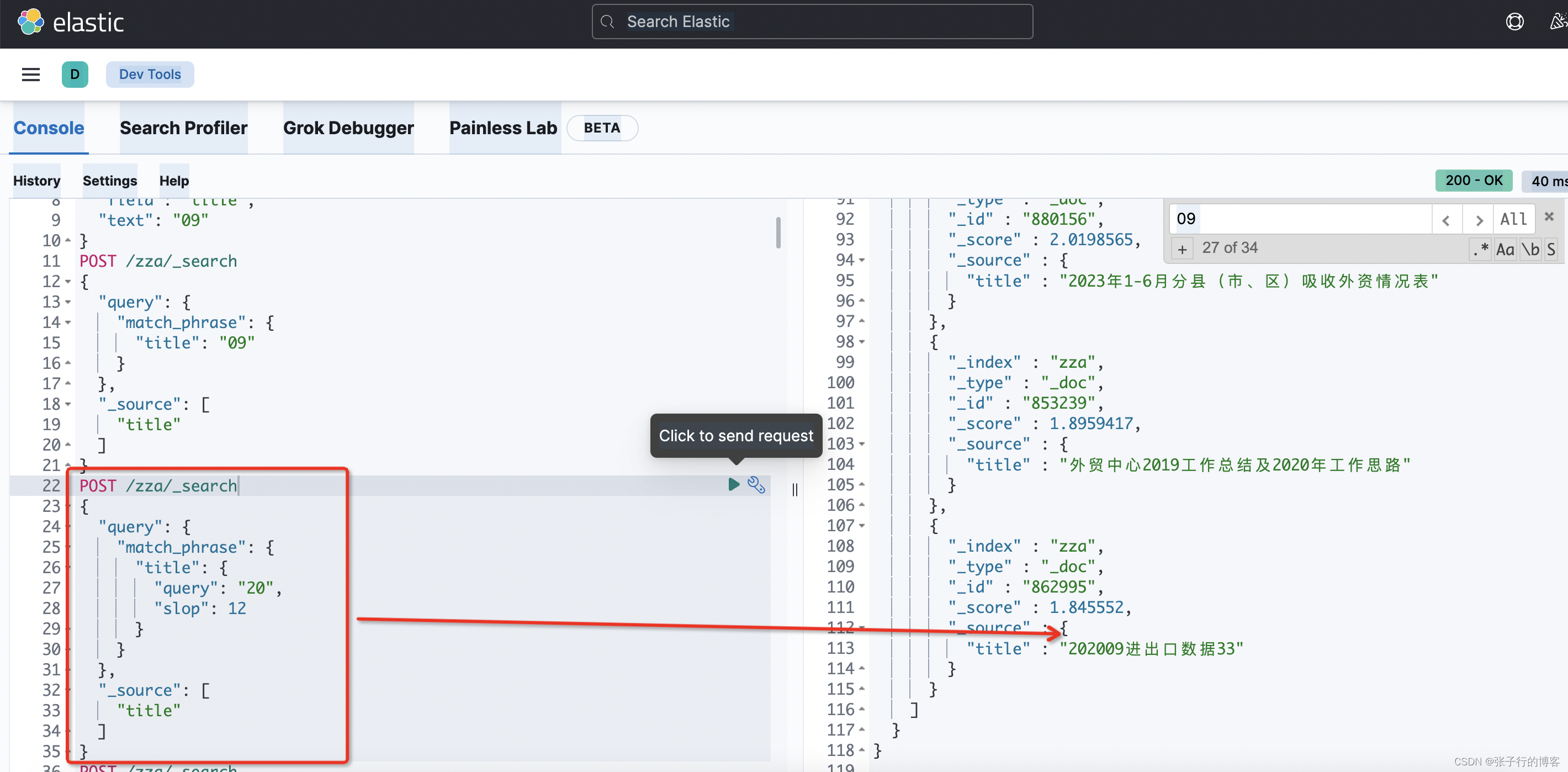
不指定 slop 的情况下查不到数据,但是我现在的需求只要是关键字中包含 20 的数据都要被查到,调 slop 也不是办法,因此 title 字段的搜索不用 matchPhraseQuery,改用 termQuery
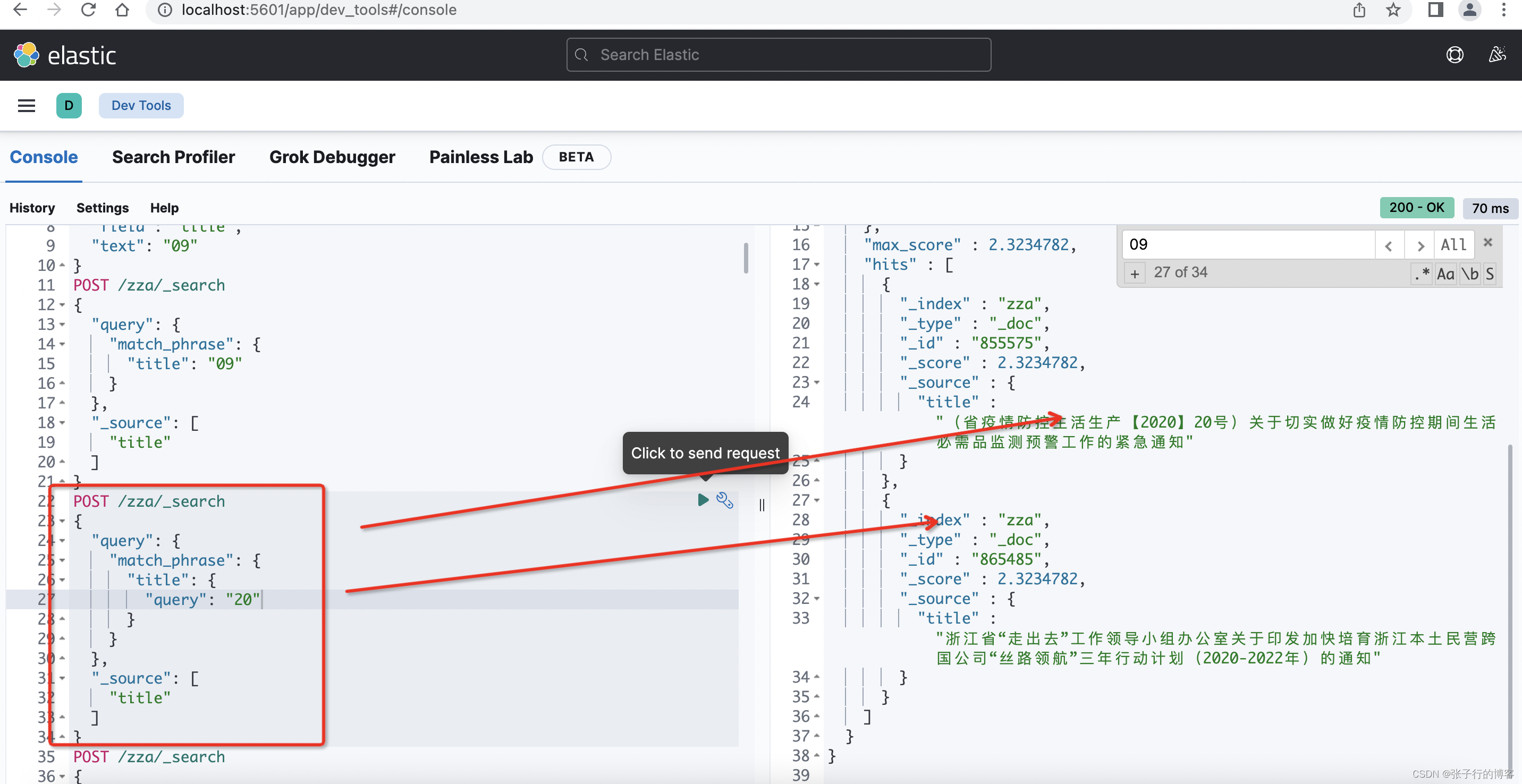
termQuery 查询原理
搜索的关键字不会进行分词去匹配词库,搜 20 就会以 20 去匹配,命中词库中的一个分词即可,例如;现在有一条 title 为(202009 进出口数据 33)的数据,搜关键字 20 即可查出数据,满足现有的业务需求。

因此最后还改造了一下业务代码逻辑大概是这样,title 字段用 termQuery,其他字段用 matchPhraseQuery。就可以了。
if (StringUtils.isNotEmpty(articleRequest.getKeyword())) {for (int i = 0; i < articleRequest.getKeys().length; i++) {if ("title".equals(articleRequest.getKeys()[i]))boolQuery.should(QueryBuilders.termQuery(articleRequest.getKeys()[i], articleRequest.getKeyword()));elseboolQuery.should(QueryBuilders.matchPhraseQuery(articleRequest.getKeys()[i], articleRequest.getKeyword()));}boolQuery.minimumShouldMatch(1);
}
总结
matchPhraseQuery 命中条件
- 搜索关键字分词要被词库存的分词完全包含
- 在点一的基础上,搜索分词顺序要和词库保持一致
- 在前俩点都满足的情况下,词库中匹配到的分词顺序要紧挨着
matchPhraseQuery 在查询前会对关键字进行分词,用到的分词器和索引中该字段指定的分词器一致,例如本文的 title 用到了 NGram 分词器,那么使用如下代码,检索 title 字段时,用到的分词器也是用的 Ngram
QueryBuilders.termQuery("title", articleRequest.getKeyword())

相关文章:
基于 NGram 分词,优化 Es 搜索逻辑,并深入理解了 matchPhraseQuery 与 termQuery
基于 NGram 分词,优化 Es 搜索逻辑,并深入理解了 matchPhraseQuery 与 termQuery 前言问题描述排查索引库分词(发现问题)如何去解决这个问题?IK 分词器NGram 分词器使用替换 NGram 分词器后进行测试matchPhraseQuery 查…...
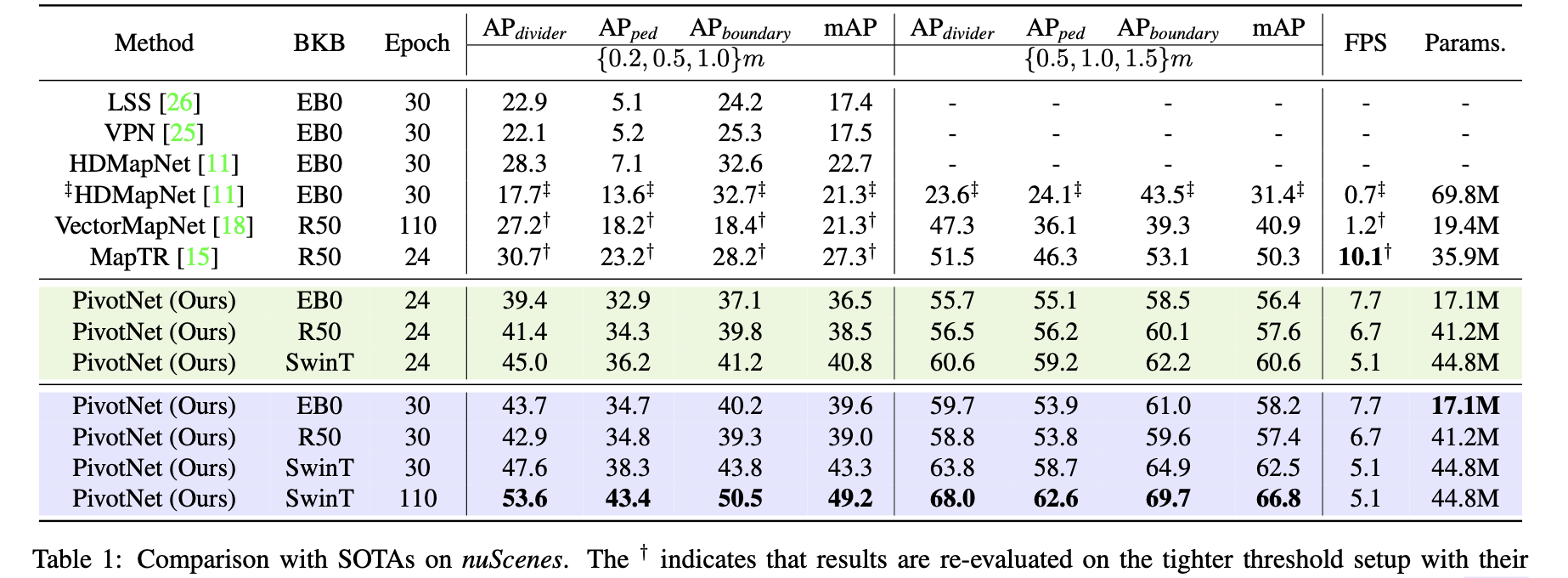
PivotNet:Vectorized Pivot Learning for End-to-end HD Map Construction
参考代码:BeMapNet。PS:代码暂未放出,关注该仓库动态 动机和主要贡献 在MapTR系列的算法中将单个车道线建模为固定数量的有序点集(对应下图Evenly-based),这样的方式对于普通道路场景具备一定适应性。但是…...

阿里云安全恶意程序检测
阿里云安全恶意程序检测 赛题理解赛题介绍赛题说明数据说明评测指标 赛题分析数据特征解题思路 数据探索数据特征类型数据分布箱型图 变量取值分布缺失值异常值分析训练集的tid特征标签分布测试集数据探索同上 数据集联合分析file_id分析API分析 特征工程与基线模型构造特征与特…...
Xcode中如何操作Git
👨🏻💻 热爱摄影的程序员 👨🏻🎨 喜欢编码的设计师 🧕🏻 擅长设计的剪辑师 🧑🏻🏫 一位高冷无情的编码爱好者 大家好,我是全栈工…...
浅述边缘计算场景下的云边端协同融合架构的应用场景示例
云计算正在向一种更加全局化的分布式节点组合形态进阶,而边缘计算是云计算能力向边缘侧分布式拓展的新触角。随着城市建设进程加快,海量设备产生的数据,若上传到云端进行处理,会对云端造成巨大压力。如果利用边缘计算来让云端的能…...

C++中禁止在栈中实例化的类
C中禁止在栈中实例化的类 栈空间通常有限。如果您要编写一个数据库类,其内部结构包含数 TB 数据,可能应该禁止在栈上实例化它,而只允许在自由存储区中创建其实例。为此,关键在于将析构函数声明为私有的: class Monst…...

MsgPack和Protobuf
MsgPack可以在C下序列化类,Protobuf只能在C#下序列化类 Cocos Creator安装msgpack-lite 项目文件夹执行 rpm -i msgpack-lite...
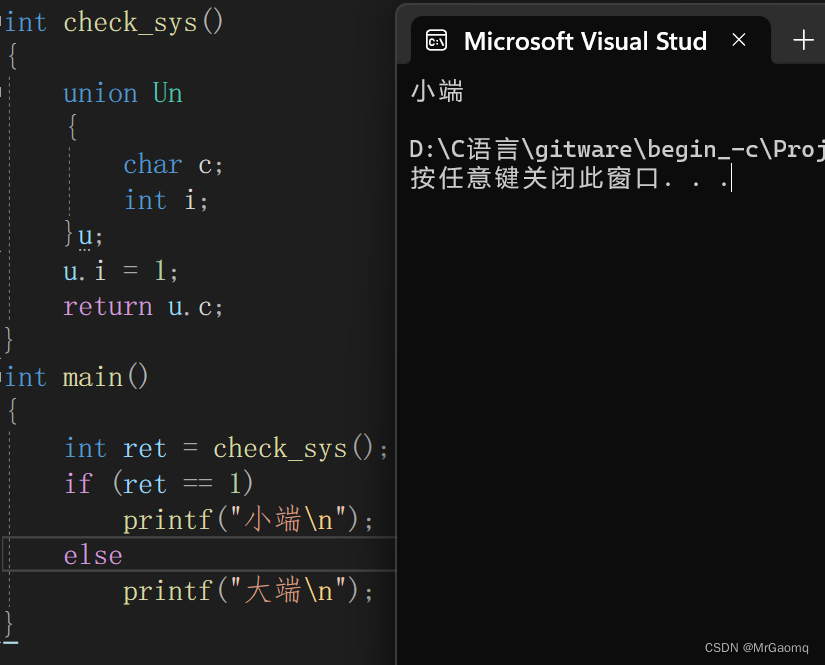
自定义类型联合体
目录 联合体联合体类型的声明联合体的特点相同成员的结构体和联合体对比联合体大小的计算联合体的应用联合的一个练习 感谢各位大佬对我的支持,如果我的文章对你有用,欢迎点击以下链接 🐒🐒🐒 个人主页 🥸🥸…...
)
【Shell 系列教程】Shell printf 命令( 六)
文章目录 往期回顾Shell printf 命令printf 的转义序列 往期回顾 【Shell 系列教程】shell介绍(一)【Shell 系列教程】shell变量(二)【Shell 系列教程】shell数组(三)【Shell 系列教程】shell基本运算符&a…...

2022年电工杯数学建模B题5G网络环境下应急物资配送问题求解全过程论文及程序
2022年电工杯数学建模 B题 5G网络环境下应急物资配送问题 原题再现: 一些重特大突发事件往往会造成道路阻断、损坏、封闭等意想不到的情况,对人们的日常生活会造成一定的影响。为了保证人们的正常生活,将应急物资及时准确地配送到位尤为重要…...

git reflog 恢复git reset --hard 回退的内容
首先使用 git reflog 查看处理的历史,历史是由新到旧排列的,找到回退前的commit的id,找的过程可以只关注HEAD的部分,HEAD括号中的值越大越旧,越小越新。 找到后执行以下命令 git reset --hard 你的commit_id 然后…...

kali Linux中更换为阿里镜像源
准备: kali Linux 阿里源链接 deb kali安装包下载_开源镜像站-阿里云 kali-rolling main non-free contrib deb-src kali安装包下载_开源镜像站-阿里云 kali-rolling main non-free contrib 配置: 打开kali 终端输入:sudo nano /etc/apt…...

【每日一题】移除链表元素(C语言)
移除链表元素,链接奉上 目录 思路:代码实现:链表题目小技巧: 思路: 在正常情况: 下我们移除链表元素时,需要该位置的前结点与后节点, 在特别情况时: 例如 我们发现&…...

stm32 ADC
目录 简介 stm32的adc 框图 ①电压输入范围 ②输入通道 编辑③ADC通道 ④ADC触发 ⑤ADC中断 ⑥ADC数据 ⑦ADC时钟 ADC的四种转换模式 hal库代码 标准库代码 简介 自然界的信号几乎都是模拟信号,比如光亮、温度、压力、声音,而为了方便存储、…...
linux网络服务综合项目
前期环境配置 #主要写了192.168.146.130的代码,131的配置代码和其一样 [rootserver ~]# nmtui #通过图形化界面修改ens160的ip 192.168.146.130 [rootserver ~]# hostnamectl set-hostname Server-Web #修改130主机名…...
----数组--移除元素(三))
每日一题(LeetCode)----数组--移除元素(三)
每日一题(LeetCode)----数组–移除元素(三) 1.题目([283. 移动零](https://leetcode.cn/problems/sqrtx/)) 给定一个数组 nums,编写一个函数将所有 0 移动到数组的末尾,同时保持非零元素的相对顺序。 请…...

AI:57-基于机器学习的番茄叶部病害图像识别
🚀 本文选自专栏:AI领域专栏 从基础到实践,深入了解算法、案例和最新趋势。无论你是初学者还是经验丰富的数据科学家,通过案例和项目实践,掌握核心概念和实用技能。每篇案例都包含代码实例,详细讲解供大家学习。 📌📌📌在这个漫长的过程,中途遇到了不少问题,但是…...
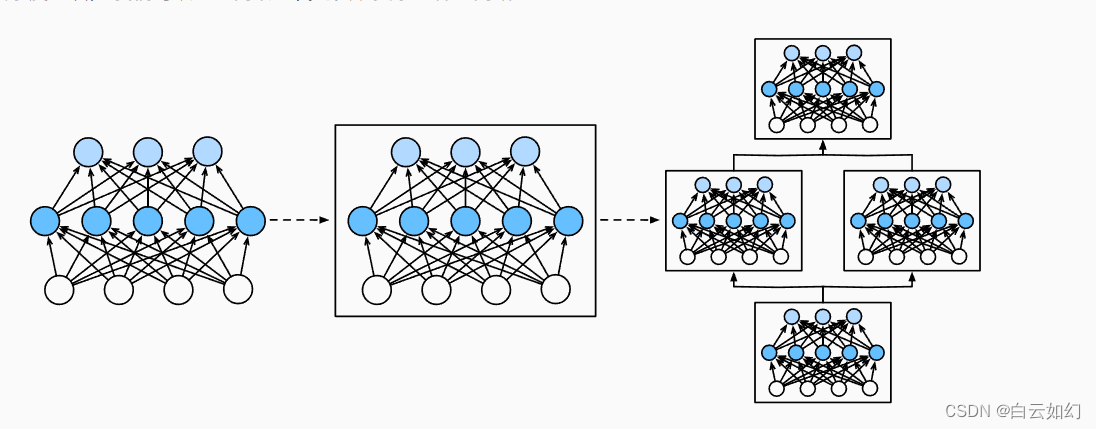
人工智能-深度学习计算:层和块
我们关注的是具有单一输出的线性模型。 在这里,整个模型只有一个输出。 注意,单个神经网络 (1)接受一些输入; (2)生成相应的标量输出; (3)具有一组相关 参数…...

Linux第一个小程序进度条
缓冲区 在写进度条程序之前我们需要介绍一下缓冲区,缓冲区有两种,输入和输出缓冲区,这里主要介绍输出缓冲区。在我们用C语言写代码时,输出一些信息,实际上是先输出到输出缓冲区里,然后才输出到我们的显…...

JavaEE平台技术——预备知识(Maven、Docker)
JavaEE平台技术——预备知识(Maven、Docker) 1. Maven2. Docker 在观看这个之前,大家请查阅前序内容。 😀JavaEE的渊源 😀😀JavaEE平台技术——预备知识(Web、Sevlet、Tomcat) 1. M…...

从论文到落地:剖析因果U-Net+波束形成在语音增强中的工程化细节与调优心得
因果U-Net与波束形成的工程实践:语音增强从实验室到产品的关键路径 在视频会议成为工作常态的今天,远场语音拾取质量直接决定了沟通效率。传统单通道降噪算法在小型会议室表现尚可,但当麦克风与声源距离超过3米,混响与噪声问题就会…...
函数3行代码搞定商品组合推荐)
别再手动排列了!用Python的permutations()函数3行代码搞定商品组合推荐
电商组合推荐新思路:用Python permutations()实现智能商品搭配 每次大促活动前,电商运营团队最头疼的就是如何设计吸引眼球的商品组合。传统人工排列不仅效率低下,还容易遗漏优质搭配方案。其实Python标准库中的itertools.permutations()函数…...

AI辅助开发:让快马智能生成2048论坛登录模块的异常处理与安全加固代码
AI辅助开发:让快马智能生成2048论坛登录模块的异常处理与安全加固代码 最近在开发2048论坛的登录模块时,我发现手动编写所有异常处理和安全加固代码非常耗时。幸运的是,我发现了InsCode(快马)平台,它集成了多款AI大模型ÿ…...

如何实现真实感前端游戏碰撞响应:从弹性到摩擦的完整指南
如何实现真实感前端游戏碰撞响应:从弹性到摩擦的完整指南 【免费下载链接】frontend-stuff 📝 A continuously expanded list of frameworks, libraries and tools I used/want to use for building things on the web. Mostly JavaScript. 项目地址: …...

新手编程入门:用快马AI快速生成你的第一个龙虾美食展示网页
今天想和大家分享一个特别适合编程新手的实践项目——用纯HTML和CSS制作一个龙虾美食展示网页。作为一个刚入门的前端学习者,我发现这个项目既能巩固基础,又能做出看得见的成果,特别有成就感。 项目构思与结构设计 首先明确网页的基本框架。…...

PyTorch系列 —— 深入解析nn.Module与nn.Linear的魔法调用机制
1. 从魔法调用开始:为什么m(input)能直接计算? 第一次看到m nn.Linear(20, 30)后面跟着output m(input)这种写法时,我盯着屏幕愣了三秒——这明明是个类实例,怎么可以直接当函数用?后来才发现,这正是PyTo…...

BepInEx:Unity游戏插件开发的终极框架完全指南
BepInEx:Unity游戏插件开发的终极框架完全指南 【免费下载链接】BepInEx Unity / XNA game patcher and plugin framework 项目地址: https://gitcode.com/GitHub_Trending/be/BepInEx BepInEx(Bepis Injector Extensible)是一款专为U…...

【FineBI】自定义地图制作全流程:从数据导入到可视化优化
1. 数据准备与导入:从Excel到FineBI的完美衔接 第一次用FineBI做自定义地图时,最让我头疼的就是数据导入环节。后来发现只要掌握几个关键点,整个过程能节省至少半小时。首先确保Excel数据表满足这三个条件:第一列必须是区域名称&a…...

解锁Sony相机潜能:PMCA-RE工具全方位技术指南
解锁Sony相机潜能:PMCA-RE工具全方位技术指南 【免费下载链接】Sony-PMCA-RE Reverse Engineering Sony Digital Cameras 项目地址: https://gitcode.com/gh_mirrors/so/Sony-PMCA-RE 副标题:探索相机底层控制与自定义应用开发的开源解决方案 第…...

【智能值守革命】抖音直播录制全攻略:从人工监控到无人值守的技术跃迁
【智能值守革命】抖音直播录制全攻略:从人工监控到无人值守的技术跃迁 【免费下载链接】DouyinLiveRecorder 可循环值守和多人录制的直播录制软件,支持抖音、TikTok、Youtube、快手、虎牙、斗鱼、B站、小红书、pandatv、sooplive、flextv、popkontv、twi…...