【数据开发】大数据平台架构,Hive / THive介绍
1、大数据引擎
大数据引擎是用于处理大规模数据的软件系统,
常用的大数据引擎包括Hadoop、Spark、Hive、Pig、Flink、Storm等。
其中,Hive是一种基于Hadoop的数据仓库工具,可以将结构化的数据映射到Hadoop的分布式文件系统上,并提供类SQL查询功能。
与传统数据库相比,Hive的优势在于能够处理海量数据,并且可以在廉价的硬件上运行。同时,Hive的查询语言与SQL相似,易于使用和学习。
与传统数据库相比,数据引擎的区别在于:
1.数据量:传统数据库通常处理的是小规模数据,而大数据引擎可以处理海量数据。
2.处理方式:传统数据库采用事务处理的方式,而大数据引擎采用批处理或流处理的方式。
3.硬件要求:传统数据库需要高性能的硬件支持,而大数据引擎可以在廉价的硬件上运行。
4.数据类型:传统数据库通常处理结构化数据,而大数据引擎可以处理结构化、半结构化和非结构化数据。
总之,大数据引擎是为了处理海量数据而设计的软件系统,与传统数据库相比具有更高的数据处理能力和更灵活的数据处理方式。
数据处理方式对比
- 批处理:批处理是一种数据处理方式,它将一批数据作为一个整体进行处理,通常是离线处理。批处理适合处理大量数据,但处理速度较慢,适用于需要全量数据分析的场景,例如数据仓库、离线计算等。
- 流处理:流处理是一种实时数据处理方式,它将数据流作为输入,实时处理并输出结果。流处理适合处理实时数据,处理速度快,适用于需要实时计算的场景,例如实时监控、实时推荐等。
数据类型对比:
- 半结构化数据:半结构化数据是介于结构化数据和非结构化数据之间的一种数据类型,它具有一定的结构,但不像结构化数据那样严格定义。半结构化数据通常采用XML、JSON、YAML等格式存储,例如网页、日志等。
- 非结构化数据:非结构化数据是指没有固定结构的数据,例如文本、图片、音频、视频等。非结构化数据通常难以通过传统的关系型数据库进行处理,需要借助大数据技术进行处理和分析。
Hadoop、Hive和Spark对比
虽然都是大数据处理的开源框架,它们有着不同的特点和用途。
- Hadoop是一个分布式计算框架,主要用于存储和处理大规模数据集。它包括HDFS(Hadoop分布式文件系统)和MapReduce两个主要组件,可以实现分布式存储和计算,以及高可靠性和容错性。
- Hive是基于Hadoop的数据仓库工具,它提供了类SQL查询功能,可以将结构化的数据映射到Hadoop的分布式文件系统上。Hive通过将SQL语句转换为MapReduce任务来实现查询和分析,可以方便地进行数据处理和分析。
- Spark是一个**快速、通用、可扩展的大数据处理引擎,它支持批处理和流处理,**并提供了高级API,如Spark SQL、Spark Streaming、MLlib和GraphX等。Spark通过内存计算和RDD(弹性分布式数据集)来提高计算性能,可以处理更大规模的数据和更复杂的计算任务。
- 总体来说,Hadoop提供了分布式存储和计算的基础设施,Hive提供了类SQL查询功能,而Spark则提供了更高级的数据处理和分析功能。
- 它们可以相互配合使用,例如使用Hadoop作为底层存储和计算基础设施,使用Hive进行数据查询和分析,使用Spark进行更高级的数据处理和分析。
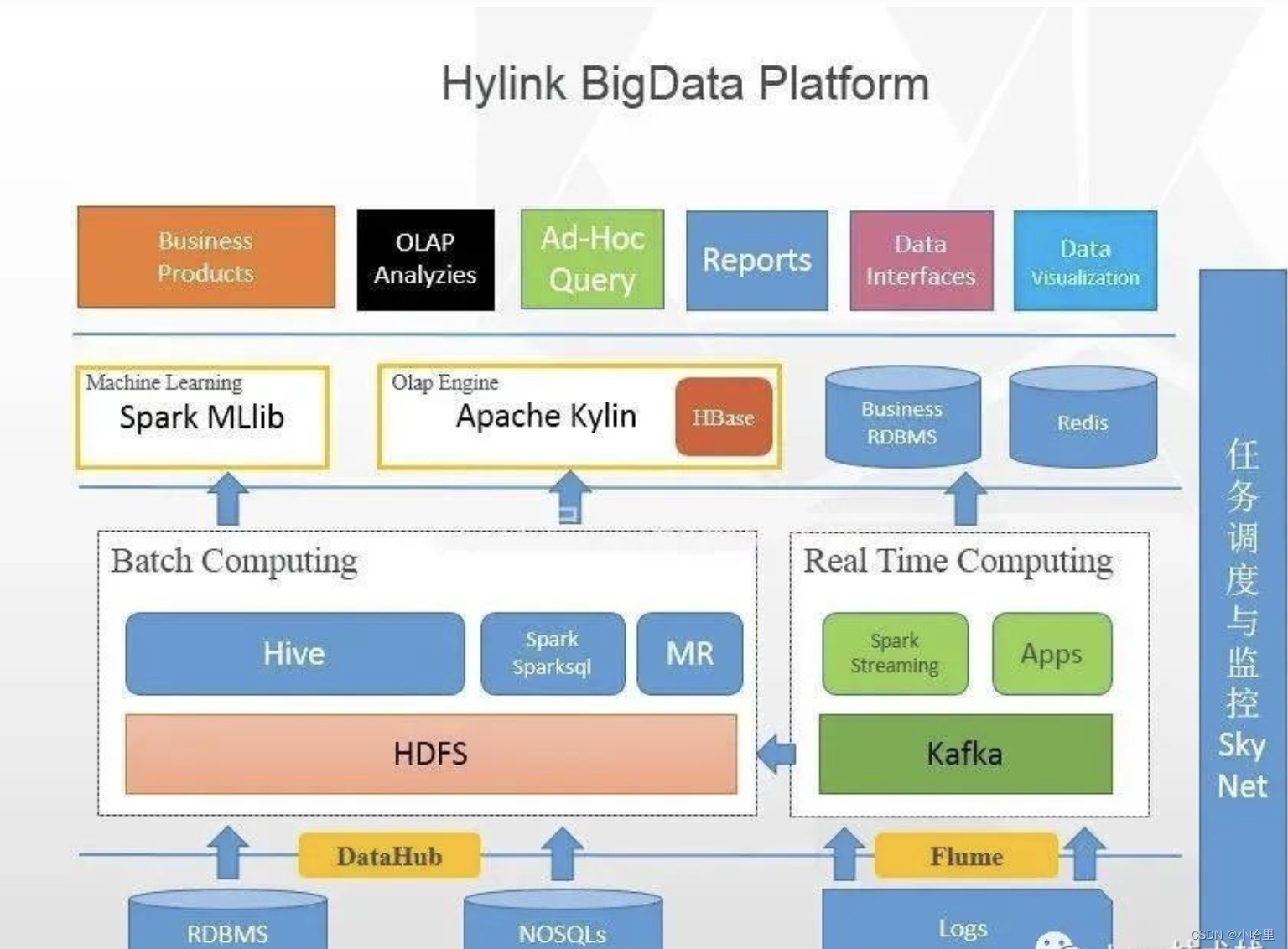
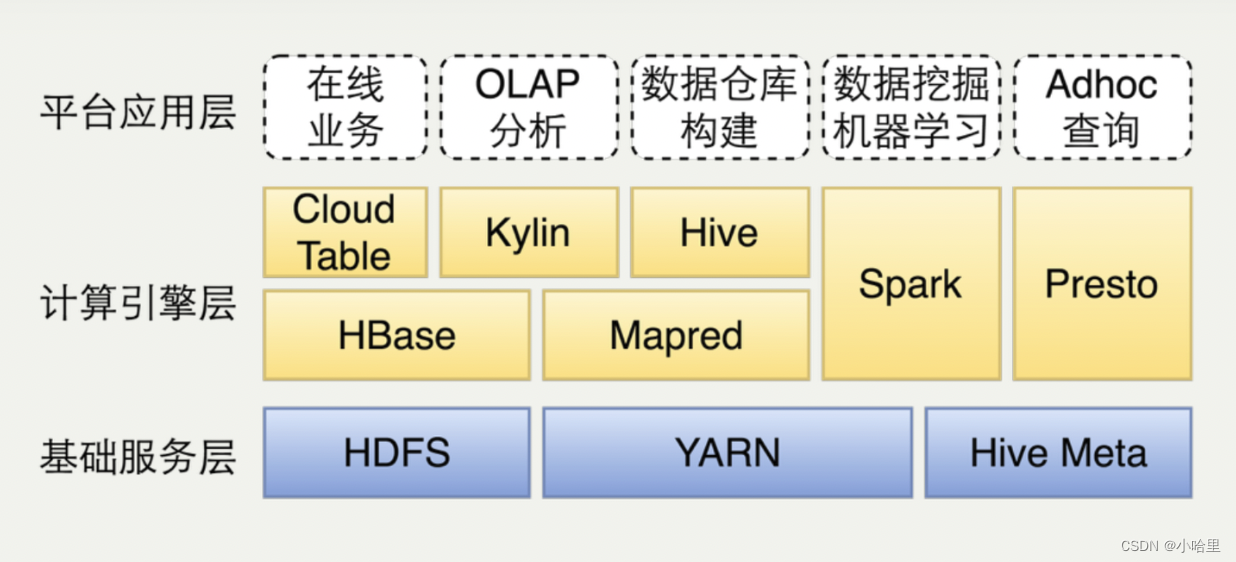
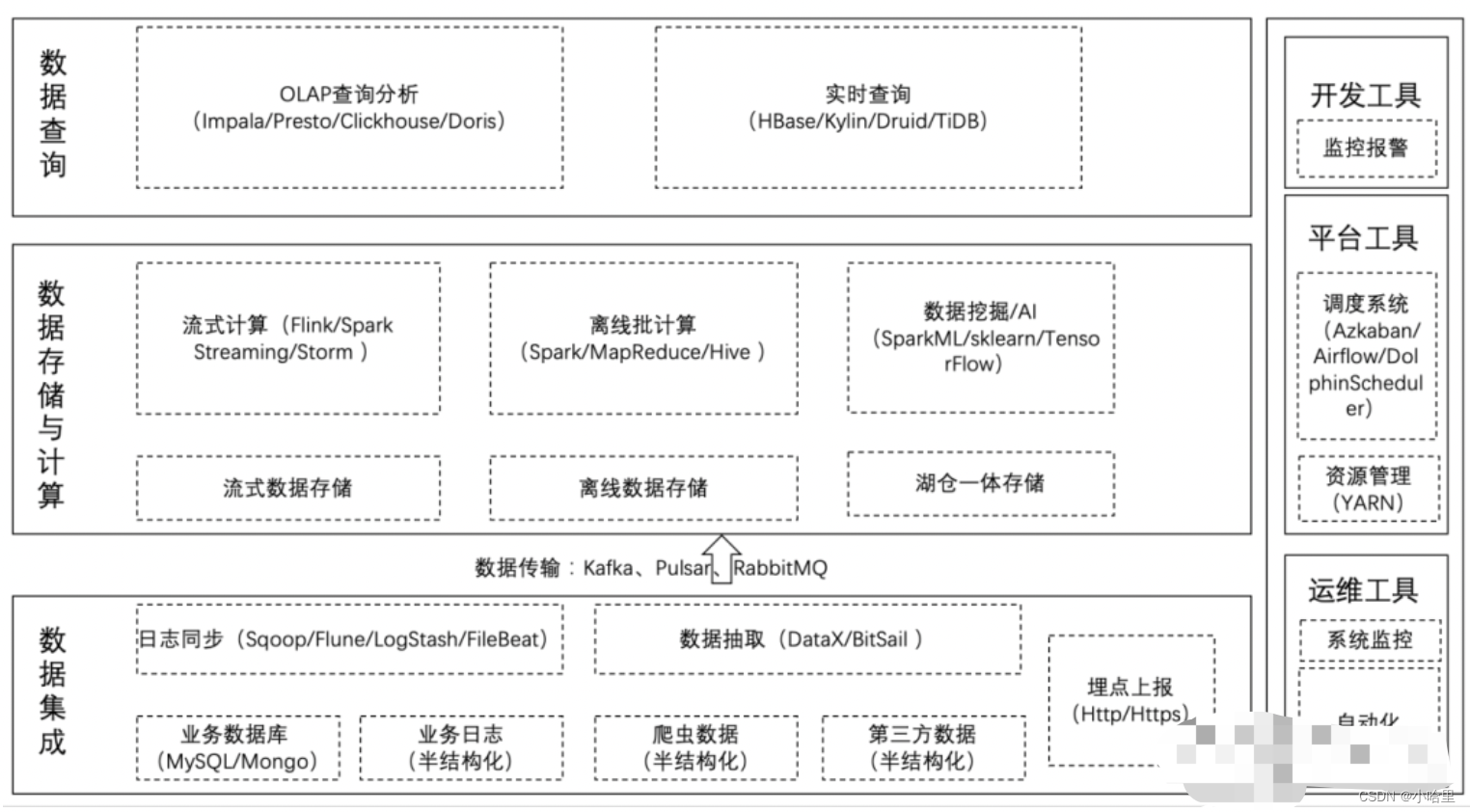
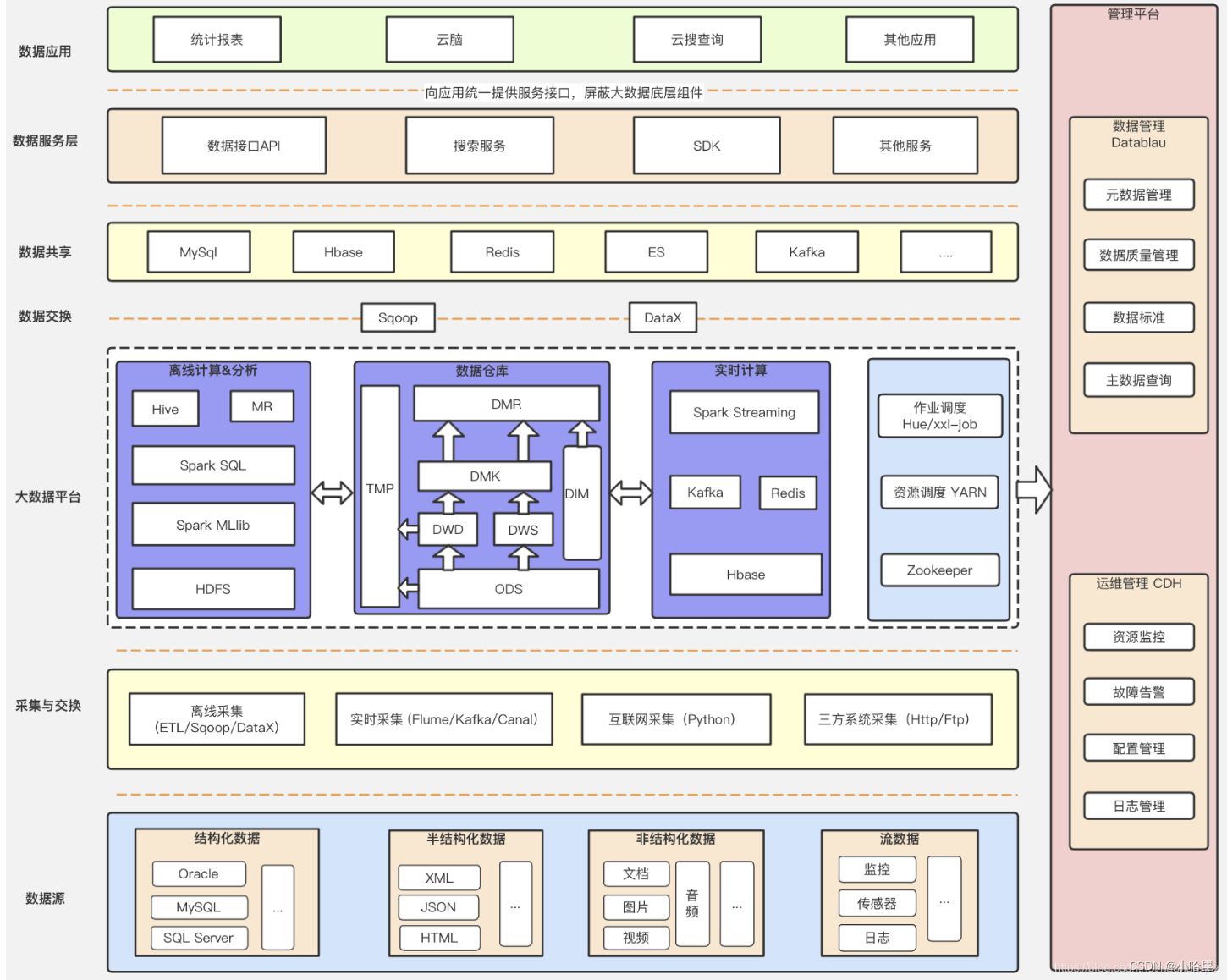
2、什么是Hive / THive
什么是Hive?
- Hive是一个基于Hadoop的数据仓库工具。
- 它提供了一个类似于SQL的查询语言,称为HiveQL,用于查询和分析大规模数据集。
- Hive将结构化数据映射到Hadoop的分布式文件系统和Hadoop的分布式处理引擎上,允许用户使用类似于SQL的语言查询数据,并将数据转换为其他格式,例如MapReduce任务。
- Hive引擎是一个基于Hadoop的数据仓库工具,它提供了一个类似于SQL的查询语言,称为HiveQL,用于查询和分析大规模数据集。
什么是THive?
- THive是一个开源的Hive JDBC驱动程序,它可以让用户使用任何支持JDBC的工具(例如Tableau,Excel等)连接到Hive。
- 因此,THive并不是一个数据仓库工具,而是一个Hive的JDBC驱动程序。
因此,Hive和THive是两个不同的东西,Hive是一个数据仓库工具,而THive是一个Hive的JDBC驱动程序。
Hive引擎分类
- 速度排名:THive on MapReduce < THive on Spark < Presto
- Hive可以使用两种不同的引擎:MapReduce和Tez。MapReduce是Hadoop的默认引擎,而Tez是一个更快的引擎,它使用了更高级别的优化技术。
- THive on MapReduce是THive的另一个变种,它使用了MapReduce作为计算引擎。MapReduce是Hadoop的默认计算引擎,它可以处理大规模数据集,但速度较慢。
- THive on Spark是THive的一个变种,它使用了Spark作为计算引擎。Spark是一个快速的分布式计算引擎,它可以在内存中进行计算,因此比MapReduce更快。THive on Spark可以提供更快的查询速度和更好的性能。
- Presto是一个分布式SQL查询引擎,它可以查询多个数据源,包括Hive、MySQL、PostgreSQL等。Presto的查询速度非常快,可以处理PB级别的数据。与Hive不同,Presto不需要将数据转换为MapReduce任务,因此可以提供更快的查询速度和更好的性能。
- 因此,Hive、THive on Spark、THive on MapReduce和Presto都是用于查询和分析大规模数据集的工具,但它们使用的计算引擎不同,因此在性能和查询速度方面也存在一定的差异。
3、数据存储: Mysql=>HDFS=>数仓
Mysql=>HDFS=>数仓
- 数仓有更强的数据处理能力,但是限定数据格式之类的要求
- Mysql轻量级,数据量少,但是格式和可定义的的功能多。
- Mysql和数仓都是结构化数据,HDFS是非结构化数据。
HDFS(Hadoop分布式文件系统)和MySQL是两种不同类型的数据存储系统,它们有以下区别:
- 数据类型:HDFS适合存储大规模的非结构化数据,如日志、图像、音频、视频等,而MySQL适合存储结构化数据,如表格数据。
- 存储方式:HDFS是一种分布式文件系统,数据被分割成多个块并存储在不同的服务器上,而MySQL是一种关系型数据库系统,数据被存储在表格中。
- 存储容量:HDFS可以存储海量数据,可以通过添加新的服务器来扩展存储容量,而MySQL存储容量相对较小,需要更高级的硬件支持才能扩展存储容量。
- 数据处理方式:HDFS采用批处理方式进行数据处理,适合离线数据处理和分析,而MySQL支持实时查询和更新,适合在线数据处理和交互式查询。
- 数据安全性:HDFS提供了数据冗余和备份机制,可以保证数据的高可靠性和容错性,而MySQL需要通过备份和复制等方式来保证数据的安全性。
总之,HDFS和MySQL是两种不同类型的数据存储系统,适用于不同的数据存储和处理场景。HDFS适合存储大规模的非结构化数据,如日志、图像、音频、视频等,而MySQL适合存储结构化数据,如表格数据。
数据仓库(Data Warehouse)是一种用于存储和管理企业数据的系统,它可以将不同来源的数据集成到一个统一的数据模型中,以便进行数据分析和决策支持。与HDFS和MySQL相比,数据仓库有以下区别:
-
数据类型:数据仓库通常存储结构化数据,如表格数据,而HDFS适合存储大规模的非结构化数据,如日志、图像、音频、视频等,MySQL则可以存储结构化数据和半结构化数据。
-
数据集成:数据仓库可以将不同来源的数据集成到一个统一的数据模型中,以便进行数据分析和决策支持,而HDFS和MySQL通常只能存储和处理单一来源的数据。
-
数据处理方式:数据仓库通常采用OLAP(联机分析处理)方式进行数据处理,支持复杂的多维分析和数据挖掘,而HDFS和MySQL通常采用OLTP(联机事务处理)方式进行数据处理,支持实时查询和更新。
-
存储容量:HDFS可以存储海量数据,可以通过添加新的服务器来扩展存储容量,MySQL存储容量相对较小,需要更高级的硬件支持才能扩展存储容量,而数据仓库也需要高性能的硬件支持来存储和处理大规模的数据。
总之,数据仓库、HDFS和MySQL都是不同类型的数据存储和处理系统,适用于不同的数据存储和处理场景。数据仓库适合存储和处理结构化数据,支持复杂的多维分析和数据挖掘,HDFS适合存储大规模的非结构化数据,MySQL适合存储结构化数据和半结构化数据。
将MySQL中的数据导出到HDFS,再将HDFS中的数据导入到数据仓库,中间的原理主要包括以下几个方面:
-
数据抽取:将MySQL中的数据抽取到HDFS中,通常采用Sqoop进行数据抽取。Sqoop通过MapReduce作业实现数据抽取,首先将数据划分为多个数据块,然后在每个数据块上运行MapReduce作业,将数据转换为Hadoop的输入格式并写入HDFS。
-
数据转换:将抽取的数据进行转换和清洗,使其符合数据仓库的数据模型和数据质量要求。通常采用ETL(Extract-Transform-Load)工具进行数据转换和清洗,如Apache Nifi、Talend等。ETL工具可以对数据进行格式转换、数据清洗、数据合并等操作,以便将数据转换为数据仓库需要的格式。
-
数据加载:将转换后的数据加载到数据仓库中,通常采用数据仓库的ETL工具进行数据加载,如ODI(Oracle Data Integrator)、Informatica等。ETL工具可以将转换后的数据加载到数据仓库中,并进行数据校验和质量控制,以保证数据的准确性和完整性。
-
数据建模:在数据仓库中进行数据建模,以便进行数据分析和决策支持。数据建模通常采用ER建模工具进行建模,如ERwin、PowerDesigner等。ER建模工具可以根据数据仓库的需求进行数据建模,包括实体、属性、关系等。
-
数据分析:在数据仓库中进行数据分析和决策支持,通常采用BI(Business Intelligence)工具进行数据分析和报表生成,如Tableau、QlikView等。BI工具可以从数据仓库中提取数据,并进行数据分析和可视化展示,以便进行决策支持和业务分析。
总之,将MySQL中的数据导出到HDFS,再将HDFS中的数据导入到数据仓库,需要进行数据抽取、转换、加载、建模和分析等多个步骤,其中涉及到多种技术和工具的应用,以实现数据的高效、准确和可靠的处理和分析。
相关文章:
【数据开发】大数据平台架构,Hive / THive介绍
1、大数据引擎 大数据引擎是用于处理大规模数据的软件系统, 常用的大数据引擎包括Hadoop、Spark、Hive、Pig、Flink、Storm等。 其中,Hive是一种基于Hadoop的数据仓库工具,可以将结构化的数据映射到Hadoop的分布式文件系统上,并提…...
)
SOEM源码解析——ecx_init_context(初始化句柄)
0 工具准备 1.SOEM-master-1.4.0源码1 ecx_init_context函数总览 /*** @brief 初始化句柄* @param context 句柄*/ void ecx_init_context(ecx_contextt *context) {int lp;*(context->slavecount) = 0;/* clean ec_slave array */...

11.Z-Stack协议栈使用
f8wConfig.cfg文件 选择信道、设置PAN ID 选择信道 #define DEFAULT_CHANLIST 0x00000800 DEFAULT_CHANLIST 表明Zigbee模块要工作的网络,当有多个信道参数值进行或操作之后,把结果作为 DEFAULT_CHANLIST值 对于路由器、终端、协调器的意义࿱…...
设计模式—结构型模式之适配器模式
设计模式—结构型模式之适配器模式 将一个接口转换成客户希望的另一个接口,适配器模式使接口不兼容的那些类可以一起工作,适配器模式分为类结构型模式(继承)和对象结构型模式(组合)两种,前者&a…...

【LeetCode】187. 重复的DNA序列
187. 重复的DNA序列 难度:中等 题目 DNA序列 由一系列核苷酸组成,缩写为 A, C, G 和 T.。 例如,"ACGAATTCCG" 是一个 DNA序列 。 在研究 DNA 时,识别 DNA 中的重复序列非常有用。 给定一个表示 DNA序列 的字符串 …...

C++17中std::any的使用
类sdk:any提供类型安全的容器来存储任何类型的单个值。通俗地说,std::any是一个容器,可以在其中存储任何值(或用户数据),而无需担心类型安全。void*的功能有限,仅存储指针类型,被视为不安全模式。std::any可以被视为vo…...

携手ChainGPT 人工智能基础设施 波场TRON革新 Web3 版图
近日,波场TRON与 Web3 人工智能基础设施服务商 ChainGPT 正式达成合作。通过本次合作,双方将进一步推动人工智能和区块链技术的融合,在实现优势互补的同时,真正惠及日常生活。 作为一站式的加密AI中心,ChainGPT 的人工智能工具需要进行大量计算,能耗高,而波场TRON采用的创新型…...

pdfH5实现pdf预览功能
1.引入 npm install pdfh5 2.使用 <view id"pdfBox" class""></view> showPdf(url) {this.pdfh5 new Pdfh5("", {URIenable: false,zoomEnanle: true,maxZoom: 2,pdfurl: url})this.pdfh5.on("complete", function(st…...

Redis的持久化机制
多级缓存使用到了一个装饰设计模式:相当于我不影响我之前缓存本身的代码,但是我可以对我的缓存去做增强,因此多级缓存就是采用装饰模式去实现的~! 多级缓存可以采用装饰模式去重构~! Redis当中的持久化机制ÿ…...
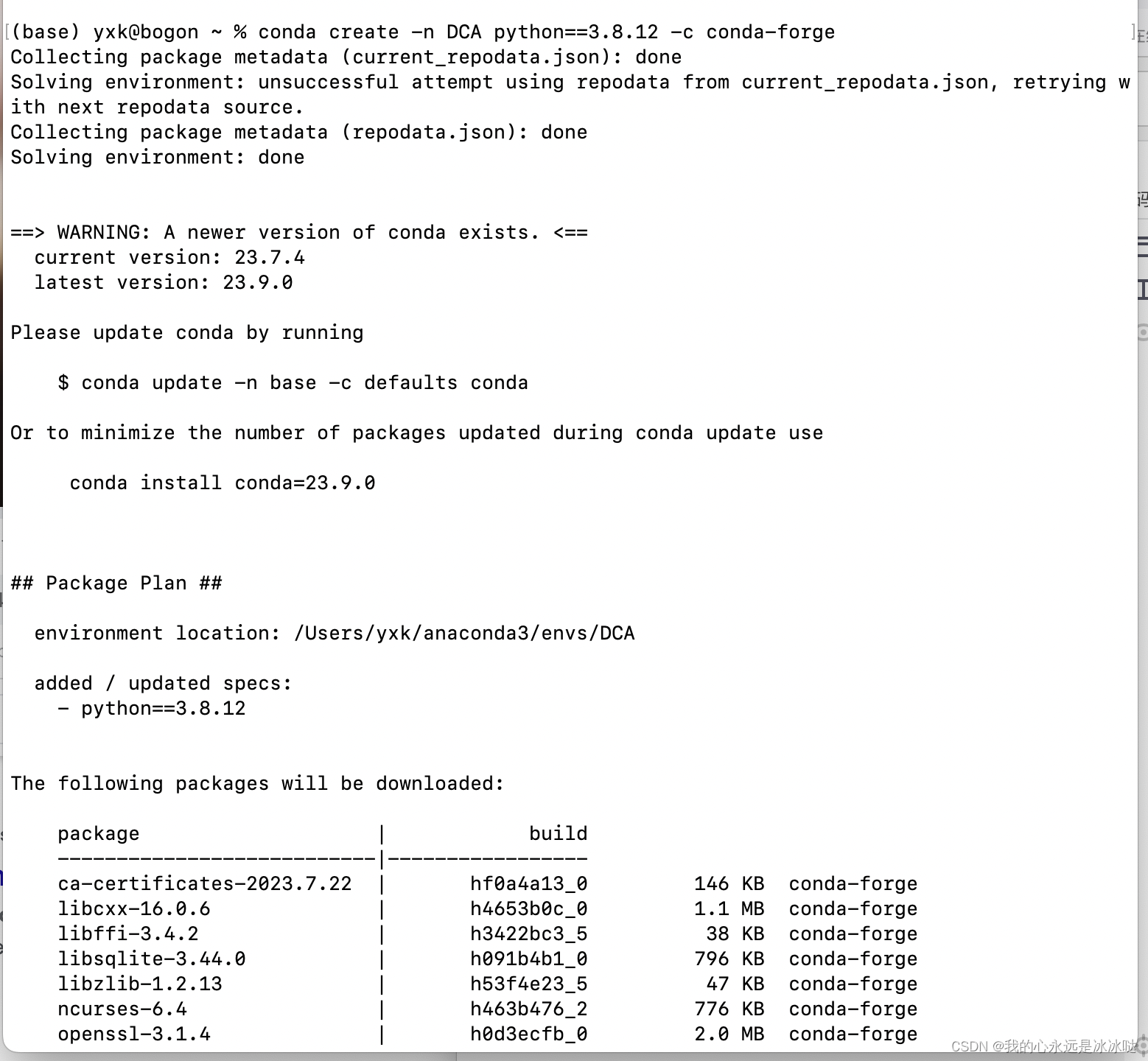
mac装不了python3.7.6
今天发现一个很奇怪的问题 但是我一换成 conda create -n DCA python3.8.12就是成功的 这个就很奇怪...

仿写知乎日报第三周
新学到的 本周新学习了FMDB数据库,并对Masonry的使用有了更近一步的了解,还了解了cell的自适应高度 FMDB数据库的介绍和使用:iOS——FMDB的介绍与使用 cell自适应高度和Mansonry自动布局 本周写了评论区,在写评论区的时候&…...

Godot Best practices
Get Forward Vector transform.x # 等价手算 var rad node.rotation var forward Vector2(cos(rad), sin(rad))Await and Unity Style Coroutine func coroutine(on_update: Callable, duration: float 1):var elapse_time 0while elapse_time < 1:elapse_time get_p…...

win10 + cmake3.17 编译 giflib5.2.1
所有源文件已经打包上传csdn,大家可自行下载。 1. 下载giflib5.2.1,解压。 下载地址:GIFLIB - Browse Files at SourceForge.net 2. 下载CMakeLists.txt 及其他依赖的文件 从github上的osg-3rdparty-cmake项目: https://github.…...

【rust/esp32】初识slint ui框架并在st7789 lcd上显示
文章目录 说在前面关于slint关于no-std关于dma准备工作相关依赖代码结果参考 说在前面 esp32版本:s3运行环境:no-std开发环境:wsl2LCD模块:ST7789V2 240*280 LCDSlint版本:master分支github地址:这里 关于s…...
-http工作机制、指令和内置变量)
精通Nginx(05)-http工作机制、指令和内置变量
http服务是Nginx最原始的服务,搞清楚其工作机制非常有利于弄懂nginx是如何工作的。 Nginx核心模块为ngx_http_core_module。 目录 http工作机制 配置结构 工作机制 http常用指令 http server listen server_name location 优先级 "/"的特殊用法 root/a…...
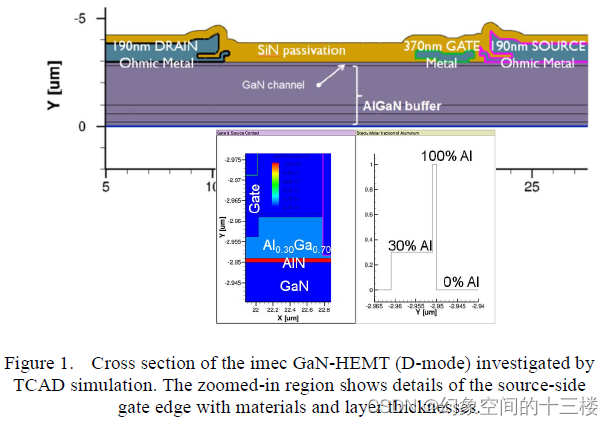
用于 GaN-HEMT 功率器件仿真的 TCAD 方法论
目录 标题:TCAD Methodology for Simulation of GaN-HEMT Power Devices来源:Proceedings of the 26th International Symposium on Power Semiconductor Devices & ICs(14年 ISPSD)GaN-HEMT仿真面临的挑战文章研究了什么文章的创新点文章的研究方法…...
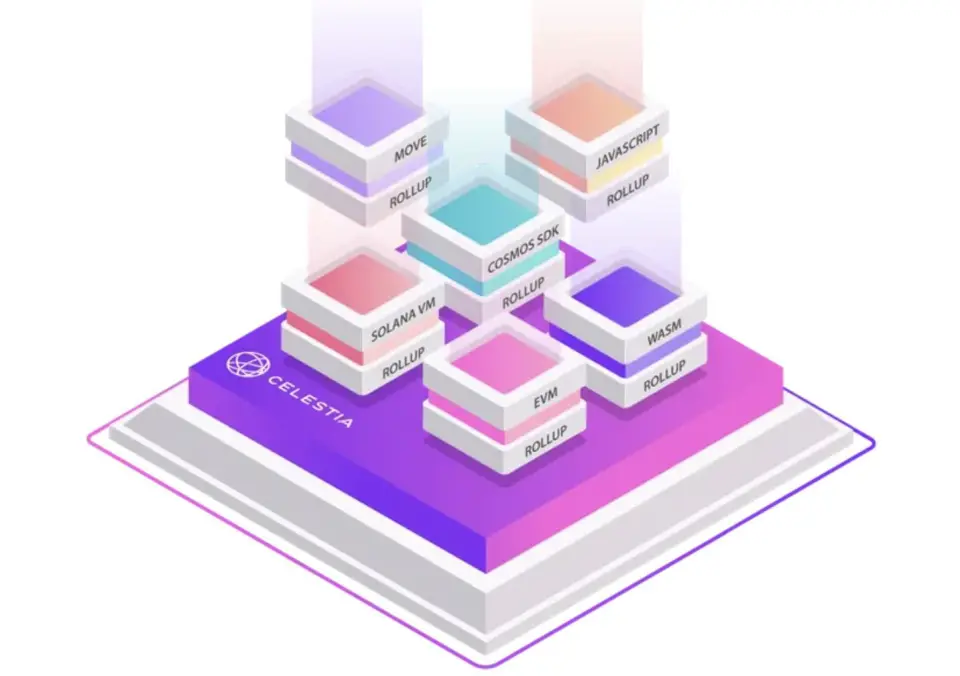
Web3公链之Cosmos生态的项目Celestia
文章目录 Web3公链之Cosmos生态的项目:模块化区块链Celestia什么是CelestiaCelestia网络架构数据可用性问题有哪些可用的解决方案? 发展历史运行节点参考 Web3公链之Cosmos生态的项目:模块化区块链Celestia 什么是Celestia 官网:…...

vue+prismjs 网页代码高亮插件
最近在使用wangEditor的过程中发现编辑器中代码块展示没有问题,但是预览编辑器中的内容样式丢失,看过wangEditor的文档后发现用到了Prism.js,现将使用的经验分享。 使用步骤 1、安装prismjs插件 // 1. 安装prismjs 插件 npm install prismj…...
【软件测试】其实远远不止需求文档这么简单
我们都知道,软件测试是一门依赖性很强的综合技术,软件测试工程师在施行自己的工作时,总是要依赖其他团队的产出。 比如,我们要依赖着需求团队给出的需求分析说明书来确定测试的方向,又要依赖开发团队产出的实际代码产品…...

SAP-PP-常用TCODE
PP主数据管理MM01/MM02物料主数据维护/修改 MM17物料主数据部分字段批量修改 /sapapo/mat1PPDS查看物料主数据 /sapapo/Res01PPDS查看资源主数据 BOM管理CS01/CS02维护/修改/删除BOM 超级BOM涉及到物料分类类型001 ,CT04 创建特性,CL01 创建类 工作中…...

本地柴油发电机组排行2023年最新榜单
柴油发电机是通过燃烧柴油驱动发动机,进而发电的设备,广泛应用于电力中断或无电网地区。1. 柴油发电机的核心工作原理是什么?柴油发电机是一种将化学能转化为电能的设备,其核心是柴油发动机与交流发电机的组合。当柴油在发动机内燃…...

三步实现跨架构程序兼容:Box64高效架构转换指南
三步实现跨架构程序兼容:Box64高效架构转换指南 【免费下载链接】box64 Box64 - Linux Userspace x86_64 Emulator with a twist, targeted at ARM64, RV64 and LoongArch Linux devices 项目地址: https://gitcode.com/gh_mirrors/bo/box64 你是否曾在ARM64…...

电容损坏深度诊断,从外观到 ESR精准区分容衰与漏电
在 PCB 故障中,电容损坏占比超 40%,是当之无愧的 “头号杀手”。很多工程师仅靠 “鼓包漏液” 判断电容好坏,殊不知80% 的电容损坏是隐性的—— 外观平整但容值衰减、ESR 升高、轻微漏电,导致供电不稳、系统重启、噪声增大&#x…...

OpenIPC开源固件:5分钟解锁网络摄像头的终极控制权
OpenIPC开源固件:5分钟解锁网络摄像头的终极控制权 【免费下载链接】firmware Alternative IP Camera firmware from an open community 项目地址: https://gitcode.com/gh_mirrors/fir/firmware 还在为网络摄像头的封闭系统而烦恼吗?想要完全掌控…...

1688运营培训/询盘成本从500元降到63.9!1688运营培训还原1688真实玩法
1688运营培训/询盘成本从500元降到63.9!1688运营培训还原1688真实玩法500块钱一个询盘,你敢信?做1688运营培训这么多年,这个数字我都觉得离谱。前阵子遇到一个老板,一上来就开始吐槽1688,说1688就是个垃圾平…...

别再死记公式了!用Python手写一个卷积层,彻底搞懂CNN里的‘卷’是怎么算的
用Python手写卷积层:从零理解CNN的"卷"运算 当你第一次看到卷积神经网络(CNN)的数学公式时,那些复杂的符号和下标是否让你望而却步?作为计算机视觉领域的基石,CNN的核心在于理解卷积运算的本质。本文将带你用NumPy从零实…...

什么情况下会核销贷款
贷款核销的核心前提是:贷款被认定为 “损失类” 且经 “穷尽追偿” 仍无法收回,银行按监管与会计规则从账面冲销,但债权不消灭、仍可追偿。一、核心认定条件(满足其一即可)破产 / 注销 / 吊销:借款人和担保…...

微信小程序项目实战:从npm安装Vant Weapp到解决样式冲突的完整避坑指南
微信小程序工程化实战:Vant Weapp集成与样式冲突解决方案全解析 第一次在小程序里引入Vant Weapp时,我对着满屏错位的组件样式发呆了半小时——原本优雅的按钮变成了扭曲的色块,表单元素叠在一起像抽象画。这不是个例,根据社区反…...

反向海淘站点常见配置故障复盘与数据一致性优化方案
摘要反向海淘独立站运行过程中,容易出现价格换算异常、页面语种错乱、商品同步失败、订单状态停滞、运费计算偏差等问题。多数故障并非系统底层缺陷,而是配置逻辑理解偏差、数据规范不统一引发。本文结合实际运维场景,汇总高频故障成因&#…...

Windows 11 LTSC安装微软商店的终极解决方案:3步恢复完整应用生态
Windows 11 LTSC安装微软商店的终极解决方案:3步恢复完整应用生态 【免费下载链接】LTSC-Add-MicrosoftStore Add Windows Store to Windows 11 24H2 LTSC 项目地址: https://gitcode.com/gh_mirrors/ltscad/LTSC-Add-MicrosoftStore LTSC-Add-MicrosoftStor…...