大数据技术架构(组件)31——Spark:Optimize--->JVM On Compute
2.1.9.4、Optimize--->JVM On Compute
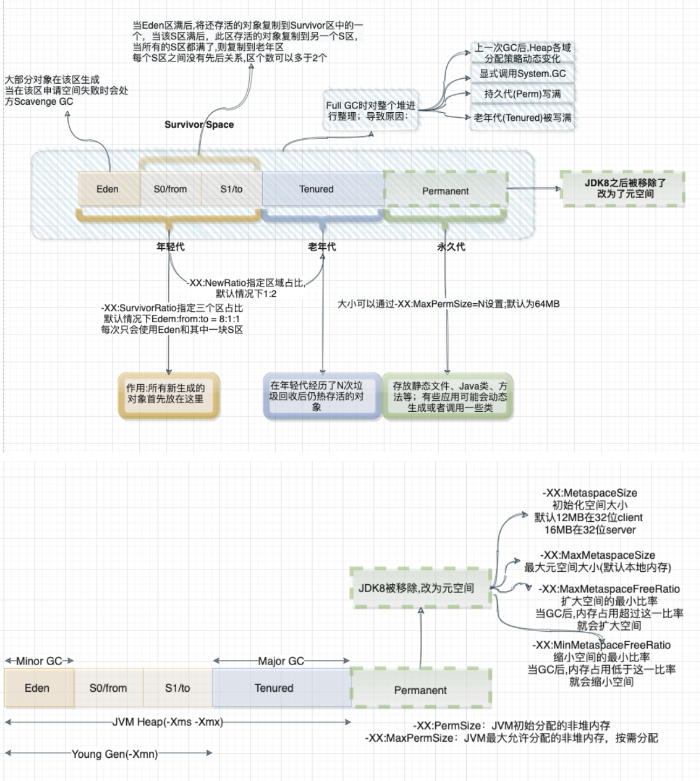
首要的一个问题就是GC,那么先来了解下其原理:
1、内存管理其实就是对象的管理,包括对象的分配和释放,如果显式的释放对象,只要把该对象赋值为null,即该对象变为不可达.GC将负责回收这些不可达对象的内存空间。
2、GC采用有向图的方式记录并管理堆中的所有对象,通过这些方式来确定哪些对象是可达的,哪些对象是不可达的。根据上图的JVM内存分配来看,当Eden满了之后,一个小型的GC将会被触发,Eden和Survivor1中幸存的仍被使用的对象被复制到Survivor2中。同时Survivor1和Survivor2区域进行交换,当一个对象生存的时间足够长,或者Survivor2满了,那么就会把存活的对象移到Old代,当Old空间快满的时候,这个时候会触发一个Full GC.
根据以上简单对GC的回顾,Spark GC调优的目的是确保Old代只存生命周期长的RDD,Young 代只保存短生命周期的对象,尽量避免发生Full GC。
那么这里梳理一下spark中关于Jvm的一些参数调优以及一些调优步骤:
1、针对MetaSpace:
-XX:MetaspaceSize:初始化元空间的大小
-XX:MaxMetaspaceSize:最大元空间大小
-XX:MinMetaspaceFreeRatio:扩大空间的最小比率,当GC后,内存占用超过这一比率后,就会扩大空间
-XX:MaxMetaspaceFreeRatio:缩小空间的最小比率,当GC后,内存占用低于这一比率,就会缩小空间。
默认的Metaspace只会受限于本地内存大小,当Metaspace达到MetaSpaceSize的当前大小时,就会触发GC.
2、GC查看步骤:
2.1、首先查看GC统计日志观察GC启动次数是否太多,可以给JVM设置参数-verbose:GC -XX:+PrintGCDetails,那么就可以在Worker日志中看到每次GC花费的时间;如果某个任务在结束之前,多次发生了Full GC,那么说明执行该任务的内存不够
spark-submit --name "app-name" \
--master local[4] \
--conf spark.shuffle.spill=false \
--conf "spark.executor.extraJavaOptions=-XX:+PrintGCDetails -XX:+PrintGCTimeStamps" \
jar_name.jar
2.2、如果GC信息显示,Old代空间快满了,那么可以降低spark.memory.storageFraction来减少RDD缓存占用的内存。先不要考虑执行性能问题,先让程序跑起来再说
2.3、如果Major GC比较少,但是Minor GC比较多,可以把Eden内存调大些。
3、计算内存和存储内存调整(钨丝计划就是专门来解决JVM性能问题的)
两者之间没有硬性界限,可以相互借用空间,通过参数spark.memory.fraction(默认0.75)来设置整个堆空间的比例。
spark.storage.memoryFraction:设置RDD持久化数据在Executor内存能占用的比例,默认是0.6;如果作业有较多的RDD持久化的话,那么该参数值可以调高些,避免内存不够缓存所有的数据,导致溢写磁盘;如果作业中shuffle类操作比较多,且频繁发生GC,那么可以适当调低该参数值。
spark.yarn.executor.memoryoverhead:如果数据量很大,导致Stage内存溢出,导致后面的Stage无法获取数据,如出现Shuffle file not found、Executor Task lost、Out Of Memory等问题时,可以调整该参数增大堆外内存。
spark.core.connection.ack.wait.timeout:当然对于not found ,file lost问题也可能是因为某些task去其他节点上拉取数据,而该节点正好正在进行GC,导致连接超时(默认60s),那么可以试着调大该参数值。
spark.shuffle.memoryFraction:设置shuffle过程一个task拉取上一个Stage的task输出后,进行聚合操作时能够使用Executor内存的比例,默认是0.2;如果shuffle使用的内存超过了这个限制,那么就会把多余的数据溢写到磁盘中,如果作业中RDD持久化的操作比较少的话,shuffle比较多的话,那么可以调大该值,降低缓存内存占用比例。
2.1.9.5、Optimize--->Shuffle On Compute
更详细的参数配置见2.1.8.6部分。
1、使用Broadcast实现Mapper端Shuffle。
也就是常说的MapJoin,即将较小的RDD进行广播到Executor上,让该Executor上的所有Task都共享该数据
2、Shuffle传输过程中的序列化和压缩。
序列化和压缩
spark.serializer=org.apache.spark.serializer.KryoSerializer
spark.shuffle.compress=true
spark.shuffle.spill.compress=true
spark.io.compression.codec=snappy
使用KryoSerializer的原因是因为其支持relocation,也就是说在把对象进行序列化之后进行排序,这种排序效果和先对数据排序再序列化是一样的。这个属性会在UnsafeShuffleWriter进行排序中用到。
3、为了避免Spark下的JVM GC可能会导致Shuffle拉取文件失败的问题,可以使用以下措施:
3.1、调整获取Shuffle数据的重试次数,默认是3次
3.2、调整获取Shuffle数据重试间隔,通过spark.shuffle.io.retryWait参数配置,默认为5s
3.3、适当增大reduce端的缓存空间,否则会spill到磁盘,同时也减少GC次数,可以通过spark.reducer.maxSizeInFlight参数配置
3.4、ShuffleMapTask端也可以增大Map任务写缓存,可以通过spark.shuffle.file.buffer,默认为32k
3.5、可以适当调大计算内存,减少溢写磁盘。
2.1.9.6、Optimize---->Data Skew
spark层面的数据倾斜定位可以通过以下几个方面:
1、通过spark web ui界面,查看每个Stage下的每个Task运行的数据量大小
2、通过Log日志分析定位是在哪个Stage中出现了倾斜,然后再定位到具体的Shuffle代码
3、代码走读,重点看Join,各种byKey的关键性代码
4、数据特征分布分析
针对数据倾斜有以下几种解决手段:
2.1.9.6.1、聚合过滤导致倾斜的Keys
可过滤针对业务逻辑中不需要的倾斜数据,例如无效数值
2.1.9.6.2、提高并行度
其主要思想在于把一个Task处理的数据量拆分为多份给不同的task进行处理,进而减轻Task的压力,其本质在于数据的分区策略。
例如
1、通过repartition或者coalesce进行重分区
2、对外部数据读取设置最小分区数
3、在使用涉及到shuffle类算子时,可以显示指定分区数(默认spark会推导分区数)
4、设置默认spark.default.parallelism并行度
2.1.9.6.3、随机Key二次聚合
使用场景:对于各种byKey操作,可以将每个key通过加上随机数前缀进行拆分,先做局部聚合,然后将随机数拆掉在做全局聚合。
2.1.9.6.4、MapJoin
使用场景:两个RDD的数据量,其中一个RDD的数据量特别小,可以放到内存中。
2.1.9.6.5、采样倾斜Key单独处理
使用场景:两个RDD进行join操作,如果一个RDD倾斜严重,那么可以通过采样方式进行拆分,然后再分别和另外一个RDD进行join,最后把结果进行union。
2.1.9.6.6、随机Join
使用场景:两个RDD中的某一个Key或者某几个Key对应的数量很大,那么在Join的时候会发生倾斜。可以将RDD1中的一个或者几个Key加上随机数前缀,然后RDD2在相同的Key上做同样的处理。
2.1.9.6.7、扩容Join
使用场景:如果两个RDD的倾斜Key特别多,则可以将其中一个RDD的数据进行扩容N倍,另一个RDD的每条数据都打上一个n以内的随机前缀,最后进行join
相关文章:
大数据技术架构(组件)31——Spark:Optimize--->JVM On Compute
2.1.9.4、Optimize--->JVM On Compute首要的一个问题就是GC,那么先来了解下其原理:1、内存管理其实就是对象的管理,包括对象的分配和释放,如果显式的释放对象,只要把该对象赋值为null,即该对象变为不可达.GC将负责回…...
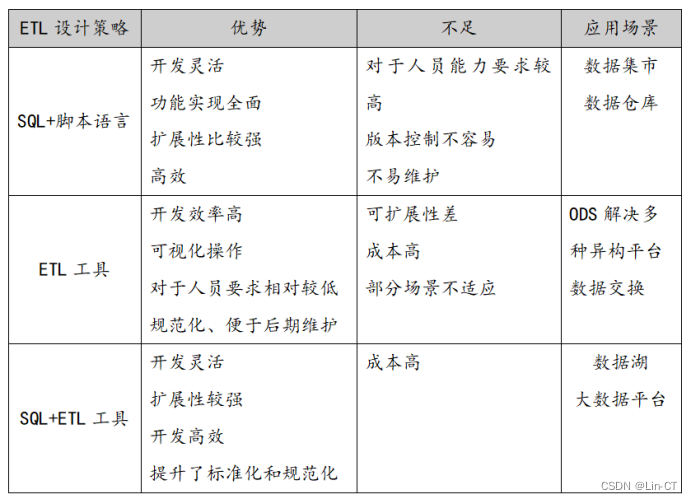
ETL基础概念及要求详解
ETL基础概念及要求详解概念ETL与ELT数据湖与数据仓库ETL应用场景ETL具体流程及操作要求抽取清洗转换加载ETL设计模式SQL脚本语言ETL工具设计ETL工具SQLETL接口设计要求明确接口属性约定接口形式确定接口抽取方法规范接口格式概念 ETL即Extract(抽取)Tra…...

刷题记录:牛客NC23054华华开始学信息学 线段树+分块
传送门:牛客 题目描述: 题目latex公式较多,此处省略 输入: 10 6 1 1 1 2 4 6 1 3 2 2 5 7 1 6 10 2 1 10 输出: 3 5 26这道题让我体验到的线段树相对于树状数组的常数巨大 我们倘若直接用单点修改的话,如果D过小比如1那么我们足足要加n次,时间复杂度爆…...

二叉搜索树(查找,插入,删除)
目录 1.概念 2.性质 3.二叉搜索树的操作 1.查找 2.插入 3.删除(难点) 1.概念 二叉搜索树又称二叉排序树.利用中序遍历它就是一个有顺序的一组数. 2.性质 1.若它的左子树不为空,则左子树上所有节点的值都小于根节点的值 2.若它的右子树不为空,则右子树上所有节点的值都…...

C# PictureEdit 加载图片
方法一: 如果要加载的图片的长宽比不是太过失衡, 1.可以改变picturebox的SizeMode属性为 PictureBoxSizeMode.StretchImage, 2.或者Dev控件 PictureEdit的SizeMode属性为Zoom。(zoom:缩放;clip剪短;stret…...
3种方法设置PDF“打开密码”,总有一种适合你
PDF文件是我们工作中经常用到的文件之一,对于重要的文件,设置“打开密码”是一种很好的保护方式。下面就来说说,设置PDF“打开密码”有哪三种方法? 方法一:在线网站加密 市面上有很多可以直接在线上加密PDF文件的产品…...
-计算机网络(笔记))
第三章 数据链路层(点到点的传输服务)-计算机网络(笔记)
计算机网络 第三章 数据链路层(点到点的传输服务) 数据链路层属于计算机网络的低层。数据链路层使用的信道主要有以下两种类型: (1)点到点信道。这种信道使用一对一的点到点通信方式。 (2)广…...

volatile关键字与CAS机制
volatile关键字 volatile关键字可以对类的成员变量与静态变量进行修饰 volatile关键字的作用 1.保证被修饰属性的可见性,被修饰后的属性如果被更改后其他线程是会立即可见的 2.保证被修饰属性的有序性,被修饰后的属性禁止修改指令执行的顺序 注意:volatile关键字不能保证属性…...

LeetCode题解 动态规划(四):416 分割等和子集;1049 最后一块石头的重量 II
背包问题 下图将背包问题做了分类 其中之重点,是01背包,即一堆物件选哪样不选哪样放入背包里。难度在于,以前的状态转移,多只用考虑一个变量,比如爬楼梯的阶层,路径点的选择,这也是能用滚动数组…...

【FFMPEG源码分析】从ffplay源码摸清ffmpeg框架(二)
demux模块 从前面一篇文章中可以得知,demux模块的使用方法大致如下: 分配AVFormatContext通过avformat_open_input(…)传入AVFormatContext指针和文件路径,启动demux通过av_read_frame(…) 从AVFormatContext中读取demux后的audio/video/subtitle数据包…...
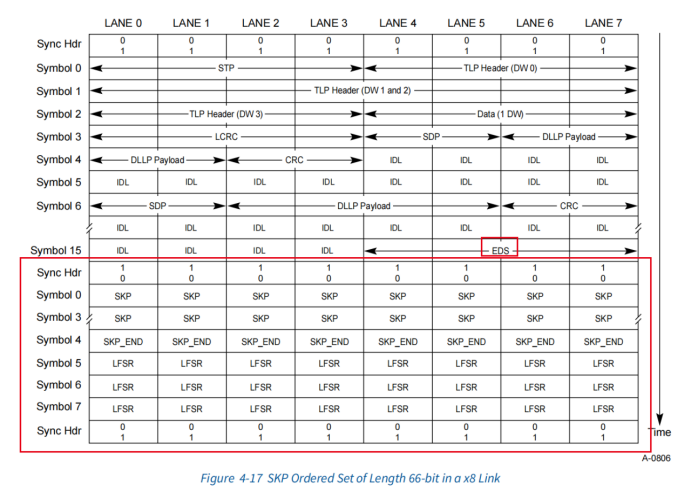
PCIE 学习笔记(入门简介)
PCIE 学习笔记书到用时方恨少啊,一年前学PCIE的笔记,再拿出来瞅瞅。发到博客上,方便看。PCIE基础PCIE和PCI的不同PCIE采用差分信号传输,并且是dual-simplex传输——每条lane上有TX通道和RX通道,所以每条lane上的信号是…...
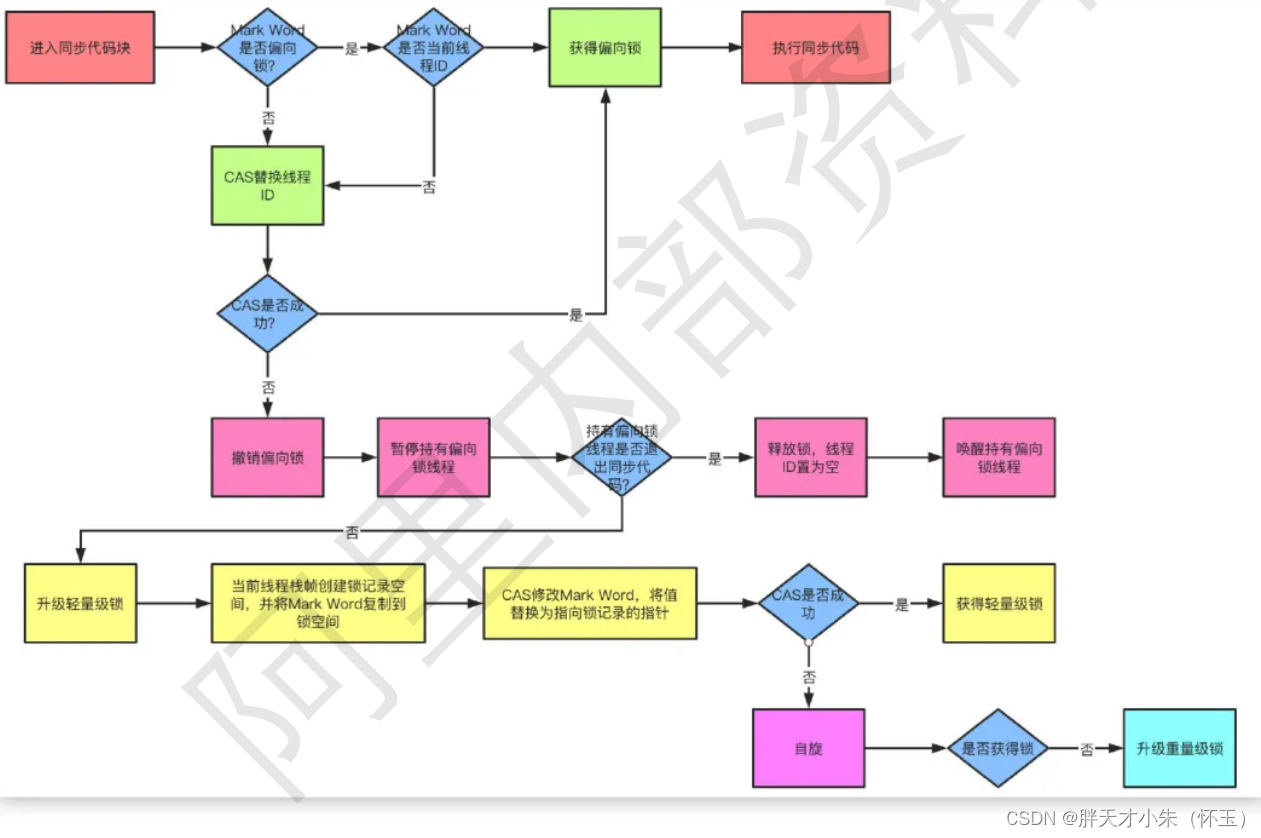
锁的优化机制了解嘛?请进!
点个关注,必回关 文章目录自旋锁:自适应锁:锁消除:锁粗化:偏向锁:轻量级锁:从JDK1.6版本之后,synchronized本身也在不断优化锁的机制,有些情况下他并不会是一个很重量级的…...

5.点赞功能 Redis
Redis(1)简介Redis 是一个高性能的 key-value 数据库原子 – Redis的所有操作都是原子性的。多个操作也支持事务,即原子性,通过MULTI和EXEC指令包起来。非关系形数据库数据全部存在内存中,性能高。(2&#…...
)
Java序列化和反序列化(详解)
一、理解Java序列化和反序列化 Serialization(序列化):将java对象以一连串的字节保存在磁盘文件中的过程,也可以说是保存java对象状态的过程。序列化可以将数据永久保存在磁盘上(通常保存在文件中)。 deserialization(反序列化):将保存在磁…...

【刷题篇】链表(上)
前言🌈前段时间我们学习了单向链表和双向链表,本期将带来3道与链表相关的OJ题来巩固对链表的理解。话不多说,让我们进入今天的题目吧!🚀本期的题目有:反转单链表、链表的中间结点、合并两个有序链表反转单链…...

ConcurrentHashMap设计思路
ConcurrentHashMap设计思路Hashtable vs ConcurrentHashMapHashtable vs ConcurrentHashMap Hashtable 对比 ConcurrentHashMap Hashtable 与 ConcurrentHashMap 都是线程安全的 Map 集合Hashtable 并发度低,整个 Hashtable 对应一把锁,同一时刻&#…...

Unity基于GraphView的行为树编辑器
这里写自定义目录标题概述基于GitHub上:目前这只是做了一些比较基础的功能节点开发,仅仅用于学习交流,非完成品。项目GitHub连接:[https://github.com/HengyuanLee/BehaviorTreeExamples](https://github.com/HengyuanLee/Behavio…...
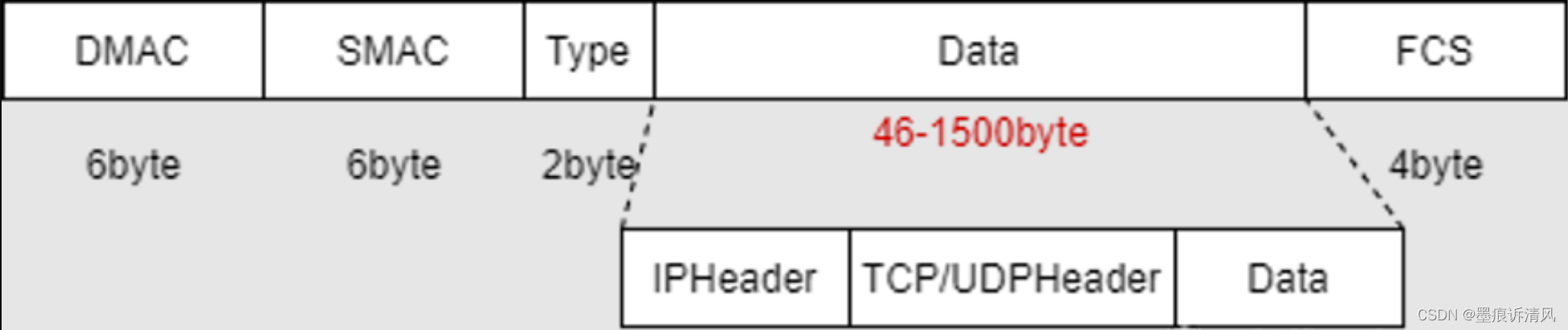
网络流量传输MTU解析
基本概念 以太网的链路层对数据帧的长度会有一个限制,其最大值默认是1500字节,链路层的这个特性称为MTU,即最大传输单元 Maximum Transmission Unit,最大传输单元,指的是数据链路层的最大payload,由硬件网…...
)
30个HTML+CSS前端开发案例(四)
30个HTMLCSS前端开发案例(17-20)鼠标移入文字加载动画效果代码实现效果鼠标悬停缩放效果实现代码效果鼠标移入旋转动画实现代码效果loding加载动画实现代码效果资源包鼠标移入文字加载动画效果 代码实现 <!DOCTYPE html> <html><head&g…...

《TPM原理及应用指南》学习 —— TPM执行环境3
本文对应《A Practical Guide to TPM 2.0 — Using the Trusted Platform Module in the New Age of Security》的第6章第3节。 6.3 Summary —— 总结 Now that you have an execution environment (or maybe both of them) set up, you’re ready to run the code samples f…...

2026 ASNT-TC-1A 无损检测 Ⅱ/Ⅲ 级认证指南|API/ASME 认证必备 + 报考实操
一、行业刚需:为何 ASNT-TC-1A 资质是工业检测领域的「硬通货」在石油天然气、压力容器、钢结构焊接等工业领域,无损检测(NDT)是产品质量保障的核心环节,而ASNT-TC-1A作为美国无损检测学会制定的人员资格鉴定和认证标准…...

从ImageNet到CV落地:深度解读AlexNet的6个工程优化技巧
从AlexNet到现代CV工程:6个历久弥新的优化策略解析 当AlexNet在2012年ImageNet竞赛中以压倒性优势夺冠时,它带来的不仅是准确率的飞跃,更是一套影响深远的工程实践方法论。十年过去,尽管网络架构已迭代数十代,但AlexNe…...

Qwen2.5-Coder-1.5B代码修复实战:常见Bug自动诊断与修复
Qwen2.5-Coder-1.5B代码修复实战:常见Bug自动诊断与修复 你有没有过这样的经历?深夜赶项目,代码跑起来一堆红字,对着报错信息一头雾水,查了半天文档还是找不到问题在哪。或者,接手一个老项目,里…...

小白程序员必看:收藏这份智能体学习指南,轻松入门大模型时代
智能体(Agent)是人工智能领域的重要概念,能够感知环境并自主行动达成目标。文章从自动驾驶、阿尔法狗等实例引入,阐述了智能体的定义和运作机制。传统智能体发展历经反射、目标导向、模型反射、效用和自主学习等阶段。大模型的出现…...

加油卡小程序玩法全解析:刚需场景破局,从充值裂变到合规运营全攻略
国内私家车与新能源车主群体持续扩容,加油、充电作为高频刚性消费场景,自带稳定流量与强付费意愿,加油卡小程序凭借轻量化、易传播、直达用户的优势,成为加油站、第三方车主服务平台、车企布局私域流量的核心载体。不同于潮玩等娱…...

从零开始:用正则表达式处理日期时间格式的完整指南
从零开始:用正则表达式处理日期时间格式的完整指南 在数据处理和文本分析中,日期时间格式的校验一直是个高频需求。无论是表单验证、日志分析还是数据清洗,确保日期时间格式的正确性都至关重要。正则表达式作为文本处理的瑞士军刀,…...

LFM2.5-1.2B-Thinking部署教程:3步实现Python爬虫数据智能处理
LFM2.5-1.2B-Thinking部署教程:3步实现Python爬虫数据智能处理 1. 引言 你是不是经常遇到这样的问题:爬虫抓取了一大堆数据,但面对杂乱无章的文本内容却无从下手?手动整理不仅耗时耗力,还容易出错。现在,…...
)
【SpringBoot 】dynamic 动态数据源配置连接池(转)
前言 在复杂的业务场景中,我们经常需要使用多数据源来满足不同的数据访问需求。Dynamic Datasource 为我们提供了一种灵活切换不同数据源的解决方案。但是多数据源配置连接池 以及说明文档都是收费的。 本篇博文将详细介绍如何配置和优化 Dynamic Datasource 的连接…...

告别复杂配置!5分钟掌握OCAT:OpenCore图形化配置神器
告别复杂配置!5分钟掌握OCAT:OpenCore图形化配置神器 【免费下载链接】OCAuxiliaryTools Cross-platform GUI management tools for OpenCore(OCAT) 项目地址: https://gitcode.com/gh_mirrors/oc/OCAuxiliaryTools 如果你…...

嵌入式开发板选型:需求、预算与扩展性平衡
嵌入式开发板选型策略:平衡需求、预算与扩展性1. 项目概述1.1 嵌入式开发面临的挑战现代嵌入式系统开发面临三大核心矛盾:有限预算与功能需求的矛盾、当前项目需求与未来技术升级的矛盾、性能要求与功耗限制的矛盾。特别是在AIoT和边缘计算领域ÿ…...