哈希表----数据结构
引入
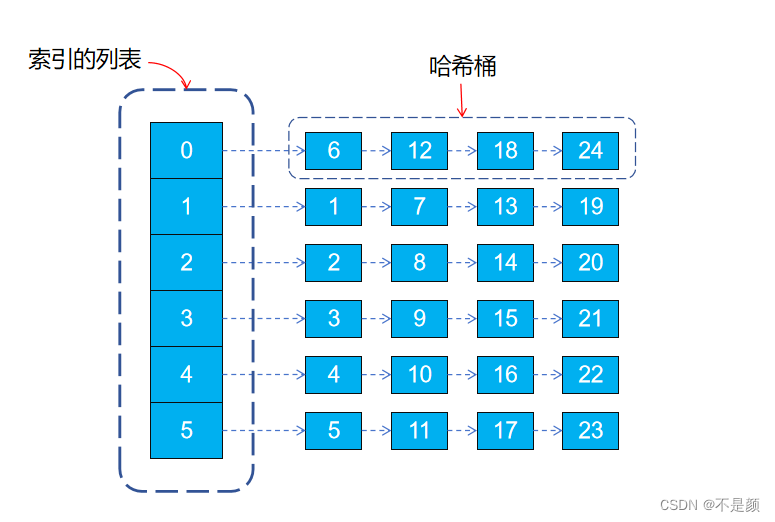
如果你是一个队伍的队长,现在有 24 个队员,需要将他们分成 6 组,你会怎么分?其实有一种方法是让所有人排成一排,然后从队头开始报数,报的数字就是编号。当所有人都报完数后,这 24 人也被分为了 6 组,看下方。
(你可能会让 1~4 号为第一组,5~8 号为第二组……但是这样有新成员加入时,就很难决定新成员的去向)
编号除以 6 能被整除的为第一组: 6 12 18 24
编号除以 6 余数是 1 的为第二组:1 7 13 19
编号除以 6 余数是 2 的为第三组:2 8 14 20
编号除以 6 余数是 3 的为第四组:3 9 15 21
编号除以 6 余数是 4 的为第五组:4 10 16 22
编号除以 6 余数是 5 的为第六组:5 11 17 23
OK呀,也是分好了。通过这种方式划分小组,无论是往小组中添加成员,还是快速确定成员的小组都非常方便,例如新加一个队员编号为 25 号,就能够很从容地让他加入到第二组。这种编号方式就是高效的散列,或者称为“哈希”,所以我们经常听说的哈希表也叫做散列表。(哈希就是Hash英文的音译,而Hash的意思是散列)
以上的过程是通过把关键码值 key (编号) 映射到表中的一个位置(数组的下标)来访问记录,从而加快了查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
上面的例子中每个人的编号都是一个关键码值 key ,例如 17 通过映射函数(编号%6 )就能得到一个位置 5 ,就能在数组里下标为 5 的位置找到第六组的所有成员,从而快速找到 17 所在的位置,如下图。
到这里你可以想象一下,一个 key 经过了加工得到了所在的地址,知道地址就可以快速访问所在的地方,就比如你知道一个学生的学号,你通过一系列操作你可以得知那个学生所在的宿舍楼,甚至知道所在的宿舍,从而去那个宿舍交流一下。
哈希表概念
散列表-哈希表 它是基于快速存取的角度设计的,“以空间换时间”。
为什么哈希表很快呢?例如在上面的例子中,问你队伍中存在编号为 17 的队员吗?如果你一个一个遍历你要遍历 24次,不能排除任何一个数据。假设数组有序,你使用二分查找一次也只能排除一半的数据,但是你使用哈希表你可以一次排除六分之五的数据,只需要到第六组中去遍历了,假如小组数量变多是不是效率更高了。
键(key):组员的编号,如:1、15、36……每个编号都是独一无二的,具有唯一性,为了快速访问到某一个组员。
值(value):组员存储的信息,可以是一个整型,可以是一个结构体、也可以是一个类。
索引:用 key 映射到数组的下标(0,1,2,3,4,5)用来快速定位并检索数据
哈希桶:用来保存索引的数组(或链表)存放的成员为索引值相同的组员
映射函数:将文件编号映射到索引上,采用求余法。如文件编号 17 % 5,得到索引 2
哈希表的实现
哈希表的数据结构定义
我的哈希桶的实现方式是链表。
#define DEFAULT_SIZE 16 //默认的哈希表大小typedef struct _ListNode //哈希链表
{void* date; //值,指向保存的数据int key; //键struct _ListNode* next;
}ListNode;typedef ListNode* List;
typedef ListNode* Element; typedef struct _HashTable
{int TableSize;List* lists; //二级指针,指向指针数组,指针数组里的元素是一级指针,指向了哈希桶
}HashTable; 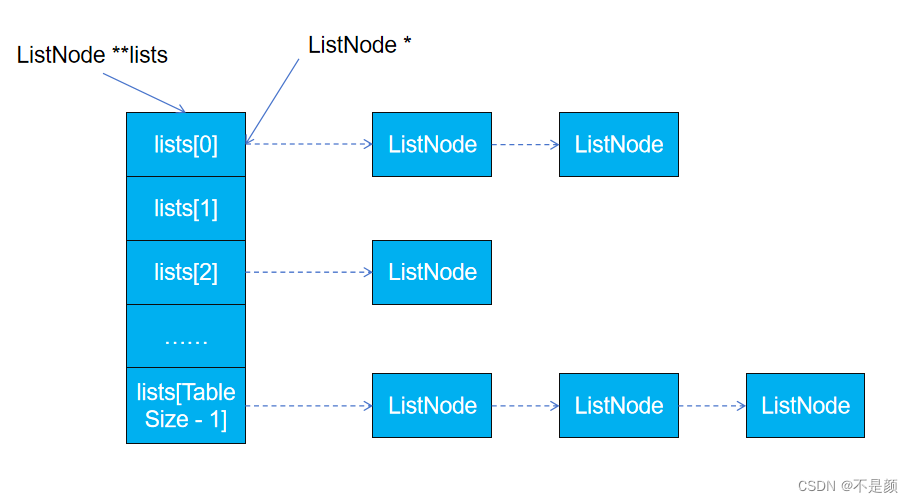
我们是用指向HashTable的指针,访问lists二级指针,lists[i]【(*lists + i)】都是指向了ListNode的指针,用lists[i]去访问哈希桶,如果不太明白可以看看哈希表的初始化。
哈希函数
其实哈希函数的参数不仅仅只有整型,例如参数可以是一个字符串,将字符串的首字符的ASCII码返回也是一个函数。只需要对任意给定的关键字值key,代入函数后若能得到包含该关键字的记录在表中的地址就可以了。
如图:
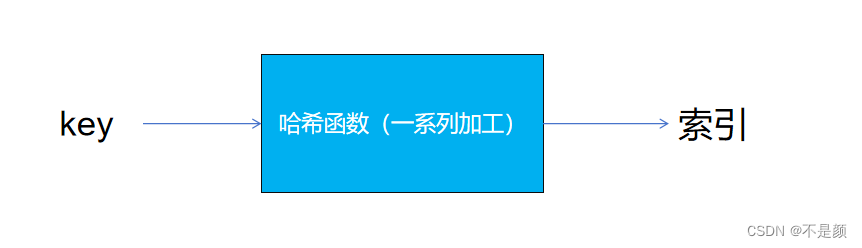
int Hash(int key, int TableSize)
{//根据 key 得到索引,也就得到了哈希桶的位置return (key % TableSize);
}初始化哈希表
HashTable* initHash(int TableSize)
{if (TableSize <= 0) //哈希桶的数量不能小于 1{TableSize = DEFAULT_SIZE; //使用默认的大小}HashTable* Hash = NULL; //指向哈希表结构体Hash = (HashTable * ) malloc(sizeof(HashTable));if (Hash == NULL) //防御性编程{cout << "哈希表分配内存失败" << endl;return NULL;}//为二级指针分配内存,指向指针数组,每一个指针指向一个哈希桶Hash->lists = (List*)malloc(sizeof(List) * TableSize);if (Hash->lists == NULL) //防御性编程{cout << "哈希表分配内存失败" << endl;free(Hash); // 运行到这一步,说明Hash不为空,别忘记释放return NULL;}for (int i = 0; i < TableSize; i++){Hash->lists[i] = (ListNode*)malloc(sizeof(ListNode));if (Hash->lists[i] == NULL) //防御性编程{for (int j = 0; j < i; j++){free(Hash->lists[j]);}free(Hash->lists);free(Hash);return NULL;}else{memset(Hash->lists[i], 0, sizeof(ListNode)); //将指向的节点初始化,全部变成0}}return Hash;
}查找这个键在哈希表中是否存在
Element Find(HashTable* hash, int key)
{int i = 0;List list = NULL;Element e = NULL; //Element 和 List 本质一样i = Hash(key, hash->TableSize); //确定哈希桶位置list = hash->lists[i]; //指向哈希桶e = list->next; while (e != NULL && e->key != key){e = e->next;}return e; //存在就返回这个节点,不存在就返回 NULL
}哈希表插入元素
//哈希表插入元素,键key和值(*date)
void insertHash(HashTable* hash, int key, void* date)
{Element e = NULL , temp = NULL; //temp为指向新加节点List lists = NULL;e = Find(hash, key);if (e == NULL){temp = (ListNode*)malloc(sizeof(ListNode));if (temp == NULL) //防御性编程{cout << "为新加节点分配内存失败" << endl;return;}lists = hash->lists[Hash(key, hash->TableSize)]; //指向新加节点所在的哈希桶//采用前插法,插入节点temp->date = date;temp->key = key;temp->next = lists->next;lists->next = temp;}else{cout << "此键已经存在于哈希表" << endl;}
}哈希表删除元素
void deleteHash(HashTable* hash, int key)
{int i = 0;i = Hash(key, hash->TableSize);Element e = NULL,last = NULL;List l = NULL;l = hash->lists[i];last = l;e = l->next;while (e != NULL && e->key != key){last = e; //last保存着要删除的节点的上一个节点e = e->next;}if (e != NULL) //存在这个元素{last->next = e->next;free(e);}else{;}
}哈希表元素中提取数据
void* getDate(Element e)
{return e ? e->date : NULL;
}销毁哈希表
void destoryHash(HashTable* hash)
{int i = 0;List l = NULL;Element tmp = NULL,next = NULL;for (int i = 0; i < hash->TableSize; i++){l = hash->lists[i];tmp = l->next; while (tmp != NULL){next = tmp->next;free(tmp);tmp = next;}free(l);}free(hash->lists);free(hash);
}全部代码
#define _CRT_SECURE_NO_WARNINGS 1#include <iostream>
using namespace std;#define DEFAULT_SIZE 16 //默认的哈希表大小typedef struct _ListNode //哈希链表
{void* date; //值,指向保存的数据int key; //键struct _ListNode* next;
}ListNode;typedef ListNode* List;
typedef ListNode* Element;typedef struct _HashTable
{int TableSize;List* lists;
}HashTable;//哈希函数
int Hash(int key, int TableSize)
{//根据 key 得到索引,也就得到了哈希桶的位置return (key % TableSize);
}//初始化哈希表
HashTable* initHash(int TableSize)
{if (TableSize <= 0) //哈希桶的数量不能小于 1{TableSize = DEFAULT_SIZE; //使用默认的大小}HashTable* Hash = NULL; //指向哈希表Hash = (HashTable * ) malloc(sizeof(HashTable));if (Hash == NULL) {cout << "哈希表分配内存失败" << endl;return NULL;}//为哈希桶分配内存,为指针数组,每一个指针指向一个哈希桶Hash->lists = (List*)malloc(sizeof(ListNode*) * TableSize);if (Hash->lists == NULL) //防御性编程{cout << "哈希表分配内存失败" << endl;free(Hash); // 运行到这一步,说明Hash不为空,别忘记释放return NULL;}for (int i = 0; i < TableSize; i++){Hash->lists[i] = (ListNode*)malloc(sizeof(ListNode));if (Hash->lists[i] == NULL) //防御性编程{for (int j = 0; j < i; j++){free(Hash->lists[j]);}free(Hash->lists);free(Hash);return NULL;}else{memset(Hash->lists[i], 0, sizeof(ListNode)); //将指向的节点初始化}}return Hash;
}//查找这个键在哈希表中是否存在
Element Find(HashTable* hash, int key)
{int i = 0;List list = NULL;Element e = NULL;i = Hash(key, hash->TableSize); //确定哈希桶位置list = hash->lists[i]; //指向哈希桶e = list->next; while (e != NULL && e->key != key){e = e->next;}return e; //存在就返回这个节点,不存在就返回 NULL
}//哈希表插入元素,键key和值(*date)
void insertHash(HashTable* hash, int key, void* date)
{Element e = NULL , temp = NULL; //temp为指向新加节点List lists = NULL;e = Find(hash, key);if (e == NULL){temp = (ListNode*)malloc(sizeof(ListNode));if (temp == NULL) //防御性编程{cout << "为新加节点分配内存失败" << endl;return;}lists = hash->lists[Hash(key, hash->TableSize)]; //指向新加节点所在的哈希桶//采用前插法,插入节点temp->date = date;temp->key = key;temp->next = lists->next;lists->next = temp;}else{cout << "此键已经存在于哈希表" << endl;}
}//哈希表删除元素
void deleteHash(HashTable* hash, int key)
{int i = 0;i = Hash(key, hash->TableSize);Element e = NULL,last = NULL;List l = NULL;l = hash->lists[i];last = l;e = l->next;while (e != NULL && e->key != key){last = e; //last保存着要删除的节点的上一个节点e = e->next;}if (e != NULL) //存在这个元素{last->next = e->next;free(e);}else{;}
}//哈希表元素中提取数据
void* getDate(Element e)
{return e ? e->date : NULL;
}//销毁哈希表
void destoryHash(HashTable* hash)
{int i = 0;List l = NULL;Element tmp = NULL,next = NULL;for (int i = 0; i < hash->TableSize; i++){l = hash->lists[i];tmp = l->next; while (tmp != NULL){next = tmp->next;free(tmp);tmp = next;}free(l);}free(hash->lists);free(hash);
}
int main(void)
{const char* elems[] = { "苍老师","一花老师","天老师" };HashTable *hash = NULL;hash = initHash(31);insertHash(hash, 1, (void*)elems[0]);insertHash(hash, 2, (void*)elems[1]);insertHash(hash, 3, (void*)elems[2]);deleteHash(hash, 3);for (int i = 0; i < 3; i++){Element e = Find(hash, i + 1);if (e){cout << (const char *)getDate(e) << endl;}else{cout << "键值为" << i + 1 << "的元素不存在" << endl;}}return 0;
}如果不太理解的话,可以多看看结构体的定义和初始化,谢谢你看到这里!
相关文章:
哈希表----数据结构
引入 如果你是一个队伍的队长,现在有 24 个队员,需要将他们分成 6 组,你会怎么分?其实有一种方法是让所有人排成一排,然后从队头开始报数,报的数字就是编号。当所有人都报完数后,这 24 人也被分…...

可达矩阵-邻接矩阵-以及有向图的python绘制
参考1 自定义输入矩阵来绘制 根据参考代码, 自定义 代码如下: # 编程实现有向图连通性的判断 from pylab import mplmpl.rcParams[font.sans-serif] [SimHei] mpl.rcParams[axes.unicode_minus] False import numpy as np import networkx as nx imp…...

react typescript @别名的使用
1、config/webpack.config.js中找到alias,添加: path.resolve(src) ,如下: alias: {// Support React Native Web// https://www.smashingmagazine.com/2016/08/a-glimpse-into-the-future-with-react-native-for-web/"react-native&qu…...

C++性能优化笔记-6-C++元素的效率差异-7-类型转换
C元素的效率差异 类型转换signed与unsigned转换整数大小转换浮点精度转换整数到浮点转换浮点到整数转换指针类型转换重新解释对象的类型const_caststatic_castreinterpret_castdynamic_cast转换类对象 类型转换 在C语法中,有几种方式进行类型转换: // …...

c#中switch常用模式
声明模式 首先检查value的类型,然后根据类型输出相应的消息 public void ShowMessage(object value) {switch (value){case int i: Console.WriteLine($"value is int:{i}"); break;case long l: Console.WriteLine($"value is long:{l}"); b…...

Flink SQL 常用作业sql
目录 flink sql常用配置kafka source to mysql sink窗口函数 开窗datagen 自动生成数据表tumble 滚动窗口hop 滑动窗口cumulate 累积窗口 grouping sets 多维分析over 函数TopN flink sql常用配置 设置输出结果格式 SET sql-client.execution.result-modetableau;kafka source…...
nodejs国内镜像及切换版本工具nvm
淘宝 NPM 镜像站(http://npm.taobao.org)已更换域名,新域名: Web 站点:https://npmmirror.com Registry Endpoint:https://registry.npmmirror.com 详见: 【望周知】淘宝 NPM 镜像换域名了&…...

用Rust和Scraper库编写图像爬虫的建议
本文提供一些有关如何使用Rust和Scraper库编写图像爬虫的一般建议: 1、首先,你需要安装Rust和Scraper库。你可以通过Rustup或Cargo来安装Rust,然后使用Cargo来安装Scraper库。 2、然后,你可以使用Scraper库的Crawler类来创建一个…...

Java 语言环境搭建
JDK 是一种用于构建在 Java 平台上发布的应用程序、Applet 和组件的开发环境,即编写 Java 程序必须使用 JDK,它提供了编译和运行 Java 程序的环境。 在安装 JDK 之前,首先要到 Oracle 网站获取 JDK 安装包。JDK 安装包被集成在 Java SE 中&a…...
酷开科技 | 酷开系统里萌萌哒小维在等你!
在一片金黄淡绿的颜色中,深秋的脚步更近了,在这个气候微凉的季节里,你是不是更想拥有一种温暖的陪伴呢?酷开科技智慧AI语音功能更懂你,贴心的小维用心陪伴你的每一天。 01.全天候陪伴 在酷开系统中,只要你…...

Bash 4关联数组:错误“声明:-A:无效选项”
Bash 4 associative arrays: error “declare: -A: invalid option” 就是bash版本太低 1.先确定现在的版本 bash -version 我的就是版本太低 升级新版本bash4.2 即可 升级步骤 1.下载bash-4.2wget http://ftp.gnu.org/gnu/bash/bash-4.2.tar.gz 2. 下载完成解压 tar -zxvf…...

干货|AI辅助完成论文的正确打开方式!
论文写作中可能遇到问题 1. 选题问题:是否无法确定研究方向和选择合适的题目? 2. 文献综述问题:是否困惑如何进行文献调研和综述? 3. 方法论问题:是否不知道该选择何种研究方法? 4. 数据处理问题&#…...
SpringBoot--Web开发篇:含enjoy模板引擎整合,SpringBoot整合springMVC;及上传文件至七牛云;restFul
SpringBoot的Web开发 官网学习: 进入spring官网 --> projects --> SpringBoot --> LEARN --> Reference Doc. --> Web --> 就能看到上述页面 静态资源映射规则 官方文档 总结: 只要是静态资源,放在类路径下࿱…...

线上JAVA应用平稳运行一段时间后出现JVM崩溃问题 | 京东云技术团队
一、问题是怎么发现的 系统是一个定时任务系统,需要定时执行业务代码,业务代码主要是访问MYSQL数据库和缓存进行操作,该开始启动,系统日志一切正常,但是运行一段时间到凌晨后,系统就自动崩溃了,…...
进口跨境商城源码:高效、安全、可扩展的电商平台解决方案
电子商务的兴起为跨境贸易提供了前所未有的机会和挑战。在这个全球化的时代,跨境电商平台成为许多企业进军国际市场的首选。然而,搭建一个高效、安全、可扩展的进口跨境商城并非易事。 1. 解决方案概述 我们推出的 "进口跨境商城源码" 提供了一…...
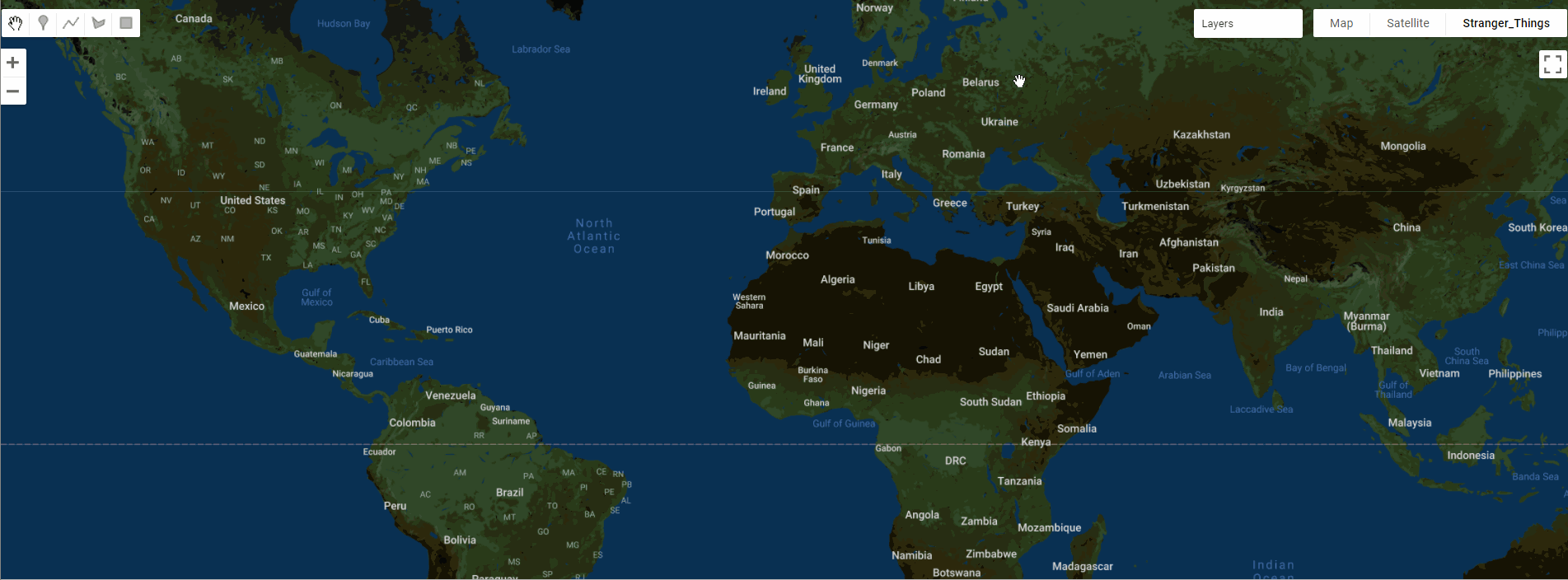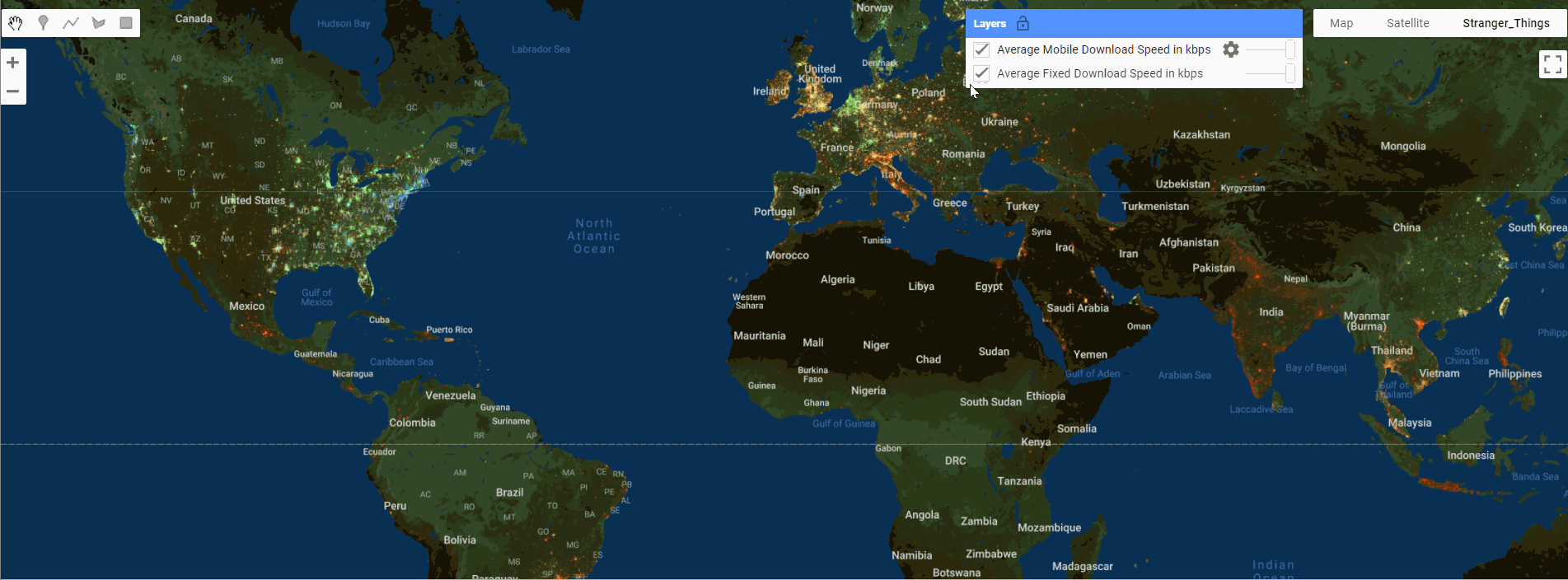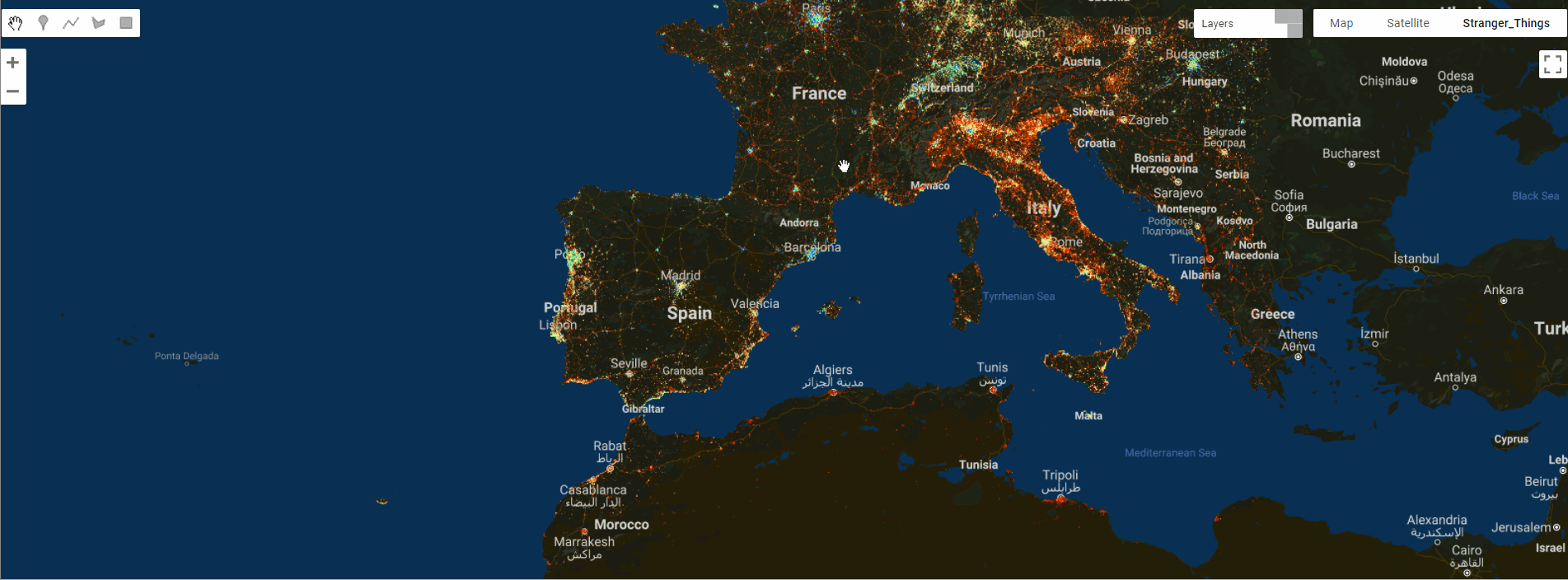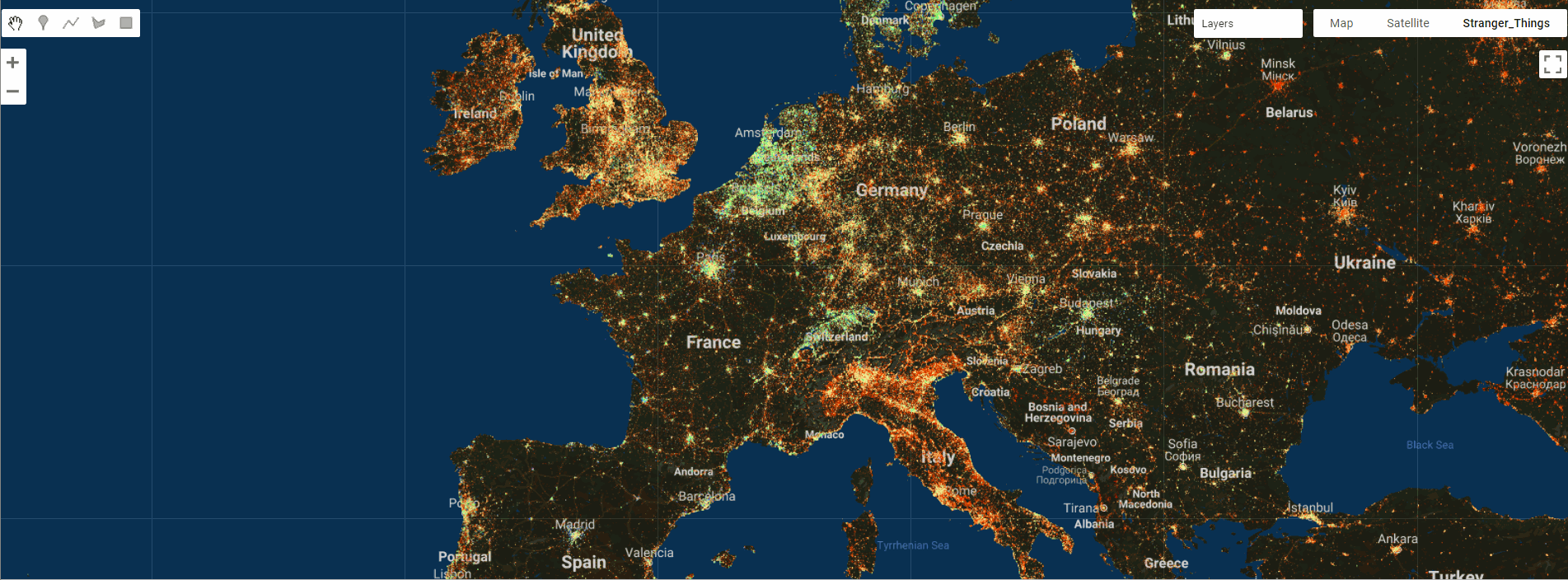
GEE数据集——2019、2020、2021、2022和2023年全球固定宽带和移动(蜂窝)网络性能Shapefile 格式数据集
全球固定宽带和移动(蜂窝)网络性能 全球固定宽带和移动(蜂窝)网络性能,分配给缩放级别 16 网络墨卡托图块(赤道处约 610.8 米 x 610.8 米)。数据以 Shapefile 格式和 Apache Parquet 格式提供&…...
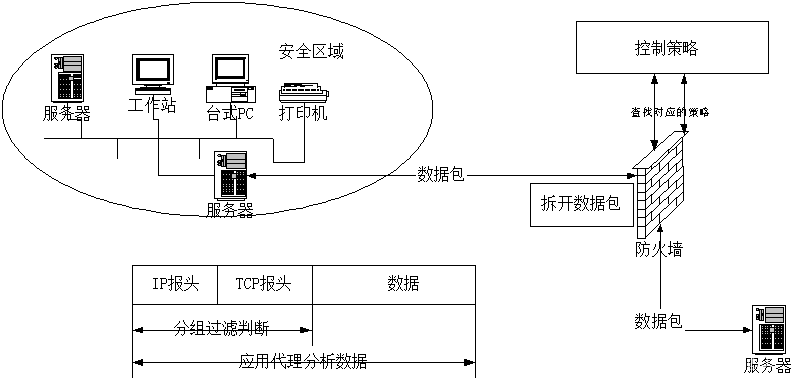
什么是防火墙?详解三种常见的防火墙及各自的优缺点
目录 防火墙的定义 防火墙的功能 防火墙的特性 防火墙的必要性 防火墙的优点 防火墙的局限性 防火墙的分类 分组过滤防火墙 优点: 缺点: 应用代理防火墙 优点 缺点 状态检测防火墙 优点 缺点 防火墙的定义 防火墙的本义原是指古代人们…...

动态规划算法实现0-1背包问题Java语言实现
问题介绍: 动态规划算法: 动态规划(Dynamic Programming)是一种解决多阶段决策问题的优化算法。它通过将问题分解为一系列子问题,并利用子问题的解来构建更大规模问题的解,从而实现对整个问题的求解。 动态…...

linux查看系统版本
linux主机 hostnamectl -- 可以查看 “系统架构”,“发行版本”和“内核版本”等信息 uname -a -- 查看内核版本 cat /proc/version -- 查看当前操作系统版本信息 cat /etc/issue ,lsb_release -a(ubuntu)-- 查看…...
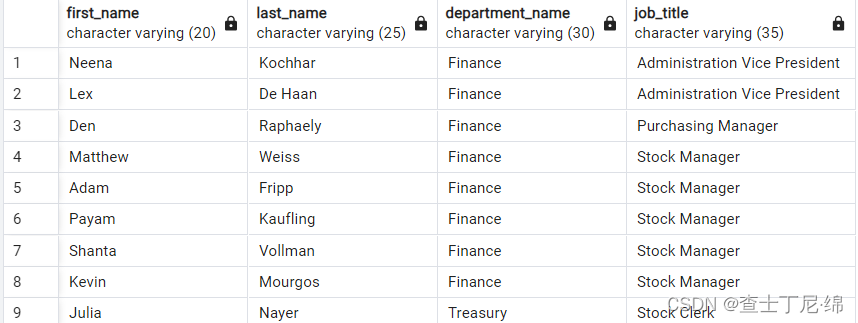
pg14-sql基础(四)-多表联查
多表联查 内联查询 SELECT e.department_id, e.first_name, d.department_name FROM employees e INNER JOIN departments d -- JOIN departments d ON e.department_id d.department_id;左外联查询 SELECT e.department_id, e.first_name, d.department_name FROM employees…...

强化学习在并行机构人形机器人控制中的应用
1. 项目概述在机器人控制领域,强化学习(RL)正逐渐成为解决复杂动力学系统问题的有力工具。然而,当面对具有并行驱动机构的人形机器人时,传统RL训练方法往往面临一个关键挑战:大多数仿真环境无法准确模拟闭环运动链(Closed Kinemat…...

ARM指令追踪技术及TRCVICTLR寄存器详解
1. ARM指令追踪技术概述在嵌入式系统开发和调试过程中,指令追踪(Instruction Trace)是一项至关重要的技术。它通过硬件机制记录处理器的执行流程,为开发者提供程序运行的完整轨迹。ARM架构从v7开始引入嵌入式跟踪宏单元࿰…...

SSE 基础知识
SSE 基础知识 一、概念定义 SSE 全称 Server-Sent Events,是基于HTTP协议的服务器单向数据推送技术。 建立一次长连接后,服务端可主动持续向前端推送数据,无需客户端反复轮询请求。 二、核心特点 单向通信:仅服务器 → 客户端发送…...
到panic:深入Linux 5.4内核,看异常处理如何层层递进)
从BUG()到panic:深入Linux 5.4内核,看异常处理如何层层递进
从BUG()到panic:Linux内核异常处理的防御体系全解析当你在深夜调试一个内核模块时,突然屏幕刷出一串红色警告——这可能是每个Linux内核开发者都经历过的噩梦时刻。但你是否想过,从第一行警告出现到系统完全崩溃,内核究竟经历了怎…...
)
保姆级教程:Windows系统下Arcgis 10.2从下载、安装到汉化一次搞定(附常见License启动失败解决方案)
Windows系统下Arcgis 10.2完整安装与汉化实战指南第一次接触Arcgis的新手往往会被复杂的安装流程和神秘的License Manager搞得晕头转向。作为一款功能强大的地理信息系统软件,Arcgis在科研、城市规划、环境监测等领域有着广泛应用,但它的安装过程确实会让…...

Veo 2提示词性能瓶颈诊断:基于1726组AB测试的token敏感度热力图与阈值红线预警
更多请点击: https://kaifayun.com 第一章:Veo 2提示词编写最佳实践总览 Veo 2 是 Google 推出的高性能视频生成模型,其对提示词(prompt)的语义精度、结构清晰度和上下文控制能力高度敏感。高质量提示词并非简单堆砌关…...

武汉国电华美串联谐振试验装置,现场用着心里有底
在高压试验现场干了这么多年,这位老师傅常说,一台好的串联谐振装置,就是试验人员的胆。面对GIS、大型变压器、超高压电缆这些大电容试品,没有趁手的谐振设备,交流耐压试验根本没法干。16875kVA/225kV这个规格ÿ…...

3分钟解锁网易云音乐NCM文件:ncmdumpGUI小白也能懂的完整教程
3分钟解锁网易云音乐NCM文件:ncmdumpGUI小白也能懂的完整教程 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾经下载了网易云音乐的歌曲&a…...

WarcraftHelper终极指南:深度解析魔兽争霸III现代化兼容性解决方案
WarcraftHelper终极指南:深度解析魔兽争霸III现代化兼容性解决方案 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper WarcraftHelper是一款专…...

机器学习的最佳实践:这7个原则让你的模型更稳定
对于软件测试从业者而言,机器学习技术正在快速融入测试流程:从自动化测试用例生成、缺陷预测到测试环境异常检测,机器学习模型的稳定性直接决定了测试结果的可靠性——如果模型在测试环境波动、输入数据变化时性能骤降,不仅无法提…...