【论文阅读】Equivariant Contrastive Learning for Sequential Recommendation
【论文阅读】Equivariant Contrastive Learning for Sequential Recommendation
文章目录
- 【论文阅读】Equivariant Contrastive Learning for Sequential Recommendation
- 1. 来源
- 2. 介绍
- 3. 前置工作
- 3.1 序列推荐的目标
- 3.2 数据增强策略
- 3.3 序列推荐的不变对比学习
- 4. 方法介绍
- 4.1顺序推荐的等变对比学习
- 4.2 轻度增强的学习不变性
- 4.3 侵入式增强的学习等变性
- 4.4 优化
- 4.4.1 模型训练和推理
- 4.4.2 模型复杂度
- 5. 实验
- 5.1 数据集
- 5.2 总的结果
- 5.3 时间复杂度分析
- 6. 总结
1. 来源

- 2023-RecSys
- https://github.com/Tokkiu/ECL
2. 介绍
对比学习(CL)有利于对具有信息性自我监督信号的顺序推荐模型的训练。
- 现有的解决方案应用一般的顺序数据增强策略来生成正对,并鼓励它们的表示是不变的。
- 然而,由于用户行为序列的固有属性,一些增强策略,如项目替代,可能会导致用户意图的改变。对所有增强策略学习不加选择的不变表示可能是次优的。
因此,作者提出了顺序推荐的等变对比学习(ECL-SR),它赋予SR模型具有强大的鉴别能力,使学习到的用户行为表征对侵入性增强(例如,项目替代)敏感,而对轻度增强(例如,特征水平的退出掩蔽)不敏感。详细地说,作者使用条件鉴别器来捕获由于项目替代而导致的行为差异,这鼓励了用户行为编码器与侵入性增强是等变的。在四个基准数据集上的综合实验表明,所提出的ECL-SR框架与最先进的SR模型相比,具有具有竞争力的性能。
顺序推荐的目的是通过从用户与项目的交互序列中了解用户的动态偏好,来预测给定用户可能感兴趣的下一个项目。顺序推荐作为一种重要的推荐范式,在电子商务、社交媒体、视频网站等多个Web服务领域中发挥着至关重要的作用。尽管近年来有了广泛的研究和重大的进展,但顺序推荐仍然面临着一个重大的挑战:
- 数据的稀疏性。
这个问题的出现是因为,作为顺序推荐基础的用户-项目交互数据,与大量的用户和项目,即数百万个用户或项目相比,通常是有限的。为了解决这一挑战,自监督学习(SSL)近年来通过从原始用户-项交互数据中挖掘自监督信号来缓解数据稀疏性问题,从而引起了越来越多的关注。因此,近年来,各种研究通过将SSL纳入顺序推荐来开发更准确的顺序推荐系统。这些研究一般都集中于探索各种数据增强策略,以丰富和增强推荐系统的输入数据,从而提高其推荐性能。例如,
- S3Rec 是第一个利用项目掩蔽和裁剪技术来增强用户的顺序交互数据,并为顺序的模型预训练设计相应的借口任务推荐。
- CL4SRec 应用三种基于序列的操作来进行数据增强,以提高顺序推荐的性能:项屏蔽、序列重新排序和序列裁剪。
- DuoRec 进一步结合了无监督和有监督的数据增强方法,以减轻顺序推荐中的表示退化。

根据增强对象,现有的增强策略可以分为两类:
- 序列级增强(如图1(a)所示的项目裁剪)
- 特征级增强(如图1(b)所示的辍学)
前者直接作用于用户-项目交互序列,而后者作用于潜在特征空间。直观地说,序列级别上的增强更有可能导致显著的语义转移,即导致与原始用户行为的意外偏差,因此作者将它们定义为“侵入性的”增强。相比之下,与序列级的增强相比,特征级别的增强对语义的影响更容易控制,因此特征级的增强被认为是“温和的”。这两类增强在现有的对比学习框架中被不加区分地使用,它鼓励学习到的用户行为表示对增强策略引起的变化是不变的。在这里,“不变”是指从原始实例中学习到的代表,以及通过对比学习从相应的增强实例中学习到的代表是相似的。然而,这种顺序推荐的不变对比学习范式的基本原理仍需进一步研究。事实上,作者观察到,使用侵入性增强策略从相同的原始实例中产生的不同的积极实例在语义上可能不是“相同的”。其主要原因是,
- 侵入性的增强方法,如项目裁剪、插入和替换,可能会打破原始用户-项目交互序列中存在的项目之间的关键关联。
- 例如,如图1 (a)所示,当作者将随机项目裁剪应用于用户行为序列(即“智能手机耳机、口红、衬衫、袜子、运动鞋”),这两个产生了积极的实例(“智能手机、耳机、口红”和“口红、衬衫、袜子、运动鞋”)没有相同的语义。前者主要关注数字产品,而后者主要关注服装。由于短的交互序列的更脆弱,这个问题可能会变得更糟。
为了实证验证上述观察结果,作者研究了一种典型的不变对比学习(ICL),称为CL4SRec 的方法,它的主要目的是学习由不同的增强策略生成的积极实例的不变表示。使用 CL4SRec 为骨干,作者比较了不同序列级(侵入性)增强和特征级(轻度)增强的不变对比学习的性能。
- 关于增强功能的详细介绍可以在Sec 2.2中找到。
- 如图1 ©所示,带有附加特征级增强(黄条)的CL4SRec [50]的性能始终优于基本模型(用虚线表示)。然而,当CL4SRec中使用的特性级增强被序列级增强所取代时,性能(绿条)就不那么令人满意了1。序列级的增强不能持续地提高推荐性能,有时甚至会降低推荐性能。实证研究表明,当前的不变对比学习范式更适合于在特征水平上进行的轻度增强。
因此,一个自然的问题出现了:
- 作者如何构建一个更可靠的对比学习框架,受益于温和的特征级增强和侵入性的序列级增强,以进一步提高顺序推荐的性能?
为了弥补这一重大差距,本文提出了一个新的框架,称为顺序推荐的等变对比学习(ECL-SR)。ECL-SR 能够基于温和的特征级增强和侵入性的序列级增强构建强大的对比学习,以学习更多的信息表示。ECL-SR 背后的核心思想是学习序列表示,可以识别侵入性序列级增强引起的差异的不变性,同时保留不变性学习。在数学上,ECL-SR 在一个统一的框架内利用温和的和侵入性的增强,以鼓励对比学习的不变性和等方差特性来学习信息更丰富的表示。不变性使表征对非必要的变化不敏感,而等方差则鼓励表征在响应增强时发生可预测的变化。具体来说,ECL-SR分别通过对轻度增强和侵袭性增强采用对比性损失等预测损失来学习不变性和等方差。图2说明了等变对比学习和不变约束学习之间的联系。事实上,不变约束学习可以看作是等变对比学习的一种特殊情况,作者在第3.1节对此进行详细讨论。

在四个基准数据集上的实验表明,ECL-SR 有效地利用了温和增强和等变对比学习的侵入性增强之间的互补性,优于基本SR模型和基于不变对比学习的SR模型。此外,作者还探讨了各种增强策略的有效性,以及ECL-SR中成分和超参数的影响。
作者的主要贡献可以总结如下:
- 作者提出了ECL-SR框架,它有效地利用温和和侵入性的增强来丰富用户的行为表示。
- 作者进一步实例化了ECL-SR框架,将退出作为轻度增强,将掩盖项目替代作为侵入性增强,说明了这两种增强之间的协同效应。
- 作者使用了一种生成器-鉴别器架构来实现屏蔽项替代,并捕获原始交互序列与其增强的对应序列之间的用户行为差异,从而促进了侵入性增强的等方差的学习。
- 作者在4个基准SR数据集上进行了全面的实验,证明了ECL-SR比经典SR模型和最先进的基于对比学习的SR模型的优势。
3. 前置工作

3.1 序列推荐的目标

3.2 数据增强策略
1)给定原始用户序列 S u S_u Su,可以采用几种随机序列级(侵入性)增强策略:
- 插入
- 它首先在 S u S_u Su 中随机选择一个位置,然后将从其他用户的交互历史中随机选择的一个项目插入到该位置中。该策略在序列上执行多次,以生成一个增强版本。增强的例子可以表示为:

- 它首先在 S u S_u Su 中随机选择一个位置,然后将从其他用户的交互历史中随机选择的一个项目插入到该位置中。该策略在序列上执行多次,以生成一个增强版本。增强的例子可以表示为:
- 删除
- 它随机删除原始序列中的一个项目,并重新运行该操作,形成一个增广序列:

- 它随机删除原始序列中的一个项目,并重新运行该操作,形成一个增广序列:
- 替换
- 它从 S u S_u Su 中随机选择一部分项目被替换为 𝑙𝑟。𝑙𝑟 中的项目是从 S u S_u Su 的所有阴性样本中随机选择的。替代比率根据经验设置为0.2。被替换序列的一个例子如下:

- 它从 S u S_u Su 中随机选择一部分项目被替换为 𝑙𝑟。𝑙𝑟 中的项目是从 S u S_u Su 的所有阴性样本中随机选择的。替代比率根据经验设置为0.2。被替换序列的一个例子如下:
- 裁剪
- 它从 S u S_u Su 中随机选择一个从位置 𝑖 到 𝑖+𝑙𝑐 的连续子序列,并删除它。作物长度(𝑙𝑐)由 𝑙𝑐 = 𝛼 | S u S_u Su| 定义,其中经验为𝛼= 0.8。裁剪序列的一个例子如下所示:

- 它从 S u S_u Su 中随机选择一个从位置 𝑖 到 𝑖+𝑙𝑐 的连续子序列,并删除它。作物长度(𝑙𝑐)由 𝑙𝑐 = 𝛼 | S u S_u Su| 定义,其中经验为𝛼= 0.8。裁剪序列的一个例子如下所示:
- 重新排序
- 它从 S u S_u Su 的 𝑖 到 𝑖+𝑙𝑐 位置随机选择一个连续的子序列,并对其进行洗牌。重排序的长度(𝑙𝑐)由 𝑙𝑐 = 𝛼 | S u S_u Su| 定义,其中经验为𝛼= 0.2。重新排序序列的一个例子如下图所示:

- 它从 S u S_u Su 的 𝑖 到 𝑖+𝑙𝑐 位置随机选择一个连续的子序列,并对其进行洗牌。重排序的长度(𝑙𝑐)由 𝑙𝑐 = 𝛼 | S u S_u Su| 定义,其中经验为𝛼= 0.2。重新排序序列的一个例子如下图所示:
2)给定用户表示 ℎ𝑢,可以应用以下温和的增强策略:
-
扰动
- 根据表示 ℎ𝑢 得到随机噪声进行增强。形式上,给定在𝑑维嵌入空间中的 ℎ𝑢,扰动操作可以通过以下方式实现:

噪声向量Δ受以下约束条件:

正如在SimGCL 中所阐述的,这些约束有助于控制 Δ 的大小和偏差 ℎ𝑢,这有助于保留来自原始表示的大部分信息,同时保持一些方差。注意,对于每一种表示,添加的随机噪声是不同的。
- 根据表示 ℎ𝑢 得到随机噪声进行增强。形式上,给定在𝑑维嵌入空间中的 ℎ𝑢,扰动操作可以通过以下方式实现:
-
规范化
- 它直接在ℎ𝑢上应用规范化操作。该操作保留了原始表示的大部分信息,同时也以一种温和的方式调整了整个表示空间,以生成正样本。与此同时,它有助于减轻人气流行偏见,正如之前的 NISER 所示。该操作的实施方式如下:

- 它直接在ℎ𝑢上应用规范化操作。该操作保留了原始表示的大部分信息,同时也以一种温和的方式调整了整个表示空间,以生成正样本。与此同时,它有助于减轻人气流行偏见,正如之前的 NISER 所示。该操作的实施方式如下:
3.3 序列推荐的不变对比学习
在本节中,作者将描述现有的工作如何将不变对比学习应用于顺序推荐。这些方法背后的基本思想是引入一个辅助任务和一个CL损失(例如,InfoNCE 损失)来帮助挖掘自我监督信号。具体来说,如图2所示,不同的数据增强方法(侵入性或轻度,如Sec 1)应用于原始序列以生成正视图2。相应地,来自不同序列的视图被认为是负的。然后,利用CL损失将正视图拉近,将负视图与嵌入空间分开。这从本质上鼓励了用户序列编码器对各种数据增强方法不敏感,从而导致更一般化的用户行为表示。推荐任务和辅助任务通常联合训练如下:

4. 方法介绍

4.1顺序推荐的等变对比学习
基于不变对比学习的SR方法鼓励所有对用户序列增强方法不敏感的表示。其有效性的一个关键前提是,所选择的增强方法只在原始序列中引入非必要的变化,而不改变语义。
- 然而,一些侵入性增强方法,如随机作物和替代,容易违反这一前提,从而影响不变对比学习对SR的有效性。
在本文中,作者提出训练一个神经网络来敏感地检测由侵入性增强引起的差异。为了实现这一点,作者将不变对比学习推广到SR的等变对比学习(ECL)中。作者在图2中展示了该框架的高级结构。上部用于学习轻度增强的不变性,下部分用于预测学习等方差的侵入性增强。
等变的概念可以定义为:
![]()
𝑔∈𝐴是一组侵入性数据增强方法,T𝑔(𝕊𝑢)表示的函数𝑔增强输入用户交互序列𝕊𝑢,𝑓𝜃用户行为编码器编码动态用户兴趣行为表示𝑓𝜃(𝕊𝑢),和T𝑔”表示一个固定的转换3。值得注意的是,ICL方法本质上是ECL-SR的一个子例,其中标识函数用于T𝑔‘,因此,
![]()
最后,ECL-SR对用户序列𝕊𝑢的优化目标如下4:

其中,ˆ𝕊1𝑢和ˆ𝕊2𝑢是使用温和增强方法生成的两个积极视图;𝑔从侵入性增强方法中采样;𝜙𝜁(·)表示识别侵入性增强的预测头;𝛼和𝛽是平衡超参数的。L𝐸𝐶𝐿的目标是使用预测头部输出𝜙𝜁(𝑓𝜃(T𝑔(𝕊𝑢)))来预测侵入性增强𝑔,这鼓励共享编码器与侵入性增强等变。
在下面的章节中,作者将详细解释ECL-SR框架以及如何实现它。图3显示了实例化的ECL-SR的总体结构,它由三个主要组件组成:
- 用户行为编码器(UBE)
- 生成器(G)
- 条件鉴别器(CD)。
UBE的主要目标是从用户交互中捕获关键模式,并向用户推荐最合适的项目。
- 作者在UBE中引入了ICL,它有助于学习不变的特征以进行温和的增强。鼓励使用G和CD来学习等方差。
- 在实现中,作者用SASRec(分别为𝑓𝜃(·)和𝑓D(·))实例化 UBE 和 CD,G与BERT4Rec(分别为𝑓G(·)),它由几个堆叠的自注意块组成。
- 基于之前的研究,作者分别选择退出掩蔽和项目替代作为轻度和侵入性增强的例子。
- 作者还进行了综合性的实验,并分析该框架中更多的增强组合。
4.2 轻度增强的学习不变性
为了鼓励从 UBE 生成的表征对轻度增强不敏感,作者对UBE采用了不变对比学习,如图3的左分支所示。具体来说,作者通过应用特征级的辍学屏蔽作为默认的轻度增强来生成正实例 𝕊+𝑢。该批次中的其他样品被视为阴性实例。首先,利用用户行为序列 𝕊𝑢 的潜在表示 h𝑢𝑡=𝑓𝜃({𝑣𝑢𝑗}𝑡𝑗=1),受前人的启发,作者取最后一个𝑘表示的平均值,得到一个聚合表示h𝑢与窗口大小𝑘如下:

类似地,作者使用相同的策略来获得 𝕊+𝑢 的聚合表示 h+𝑢。然后采用InfoNCE损失将正实例更近,将负实例推到语义空间中,可以表示为:

其中,𝑀(𝑢)为包含𝑢的小批处理中的用户,𝑠𝑖𝑚(·,·)为余弦相似度函数,𝜏为温度。
4.3 侵入式增强的学习等变性
预测侵入性增强的一个简单解决方案是在方程3中使用一个简单的线性层作为预测头𝜙𝜁(·),当被破坏的序列容易重构时,这可能是次优的。为了提高模型学习等方差的能力,作者采用了一种受启发的生成器-鉴别器结构来获得硬侵入性增广视图。
生成器的目标是产生“硬”正序列,与原始序列相比有微小的差异,而鉴别器的目标是准确地检测到由生成器引入的最轻微的变化。为此,采用替换项目检测损失(RIDL)作为预测损失关于掩码项目的替代,以促进等方差的学习。下面是一个如何学习使用生成器-鉴别器结构的项目替换的等方差的例子:
- 给定一个用户行为序列 𝕊𝑢=[𝑣𝑢1,𝑣𝑢2,……,𝑣𝑢𝐿],作者首先用掩码比率 𝛾 随机屏蔽 𝕊𝑢 的几个项目。掩蔽的交互序列可以表示为𝕊‘𝑢=𝑚𝑢·𝕊𝑢,其中 𝑚𝑢 =[𝑚𝑢1,𝑚𝑢2,…,𝑚𝑢𝐿]和 𝑚𝑢𝑡 ∈{0,1}。
- 然后,作者使用 BERT4Rec [40]作为生成器 𝑓G(·),恢复𝕊‘𝑢 中的随机掩码项,以获得部分替换的用户交互序列 𝕊𝑢’‘=𝑓G(𝕊’𝑢)。利用该方法,作者构造了具有较小语义扰动的假交互序列,这对鉴别器正确识别被替代的条目提出了挑战。生成器接受的训练带有以下损失:

其中,𝕊𝑚𝑢 是𝕊‘𝑢中的掩蔽项集合,𝑣𝑚* 表示掩蔽项 𝑣𝑚 的地面真实项,𝑝(·)是与式1相同的函数。 - 条件鉴别器(CD)的目的是针对UBE h𝑢𝑡=𝑓𝜃({𝑣𝑢𝑗}𝑡𝑗=1)的输出表示作为条件,执行替换项目检测(RID)任务。通过这种方式,CD的梯度传播回UBE,这鼓励UBE生成更多信息的用户行为表示,因此CD可以区分𝕊𝑢和𝕊𝑢之间的微小差异。在作者的实现中,作者使用SASRec [24]块和一个额外的MLP层来实例化CD(表示为𝑓D(·))。作者使用连接等聚合函数将条件信息注入到区分建模过程中。对于用户序列中的每个项,CD需要预测它是否已被替换。作者计算交叉熵损失如下:

其中,w是一个可学习的参数矩阵,𝜎表示s型函数,𝑣𝑡𝑢‘’∈𝕊𝑢‘’。
为什么所提出的ECL-SR可以实现等方差?
- 等变性是当一个群变换T𝑔应用于输入序列𝕊𝑢时,得到的输出特征也经过相应的变换T𝑔‘。
- 在ECL-SR,等变性是因为设计生成器和条件鉴别器可以鼓励用户行为编码器检测语义变化(即区别T𝑔(𝕊𝒖)和原始序列𝕊𝑢)造成的侵入性增强而不是忽略它们,理论上支持最近的工作在计算机视觉。需要注意的是,我们提出的 ECL-SR 不同于之前关于变性的工作,因为它只通过选择损失函数RIDL来鼓励等变性质,而不是强制执行严格的等变性。为此,ECL-SR将每种类型的侵入性增强视为一个组,并使用一个条件鉴别器来预测输入序列中的增强(例如,项目替代)的存在。
4.4 优化
4.4.1 模型训练和推理
-
在训练阶段,项目嵌入是跨所有三个模块共享的。用户行为编码器和鉴别器的参数(除了RID的额外线性层外)也被共享,以避免过拟合。ECL-SR模型的所有组件都以端到端的方式进行训练。因此,对整个ECL-SR框架采用组合损失函数进行了优化:

其中,𝜆·控制每个辅助损失的贡献。 -
在推理阶段,作者同时去除生成器和条件鉴别器,只使用UBE来完成下一个项目预测任务。
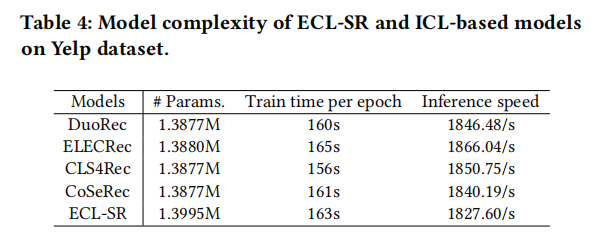
4.4.2 模型复杂度
模型复杂度实例化的ECLSR的复杂性来自于3个部分:
- 用户行为编码器(UBE)
- 生成器(G)
- 条件鉴别器(CD)。
它们都共享相同的嵌入表,其中包含了大部分参数。UBE+CD的复杂性接近于SASRec,因为它们的参数被共享,以提高训练的稳定性和效率。G的复杂性仍然接近于BERT4Rec 。因此,ECL-SR的整体复杂性与SASRec结合BERT4Rec(共享嵌入表)的复杂性相当。为了确保与SASRec相似的计算效率,作者保持UBE和G的总层数与实验中使用的其他自注意方法相同。此外,为了最小化计算开销,作者固定了10个时代训练后G的参数。在推理过程中,ECL-SR的速度与SASRec相当,因为只使用了UBE。作者在Tab 4中总结了模型复杂度的比较。
5. 实验
5.1 数据集

5.2 总的结果

5.3 时间复杂度分析
更多实验参考原文。
6. 总结
在本文中,作者提出了ECL-SR框架,它有效地利用温和的和侵入性的增强来增强用户的行为表示。具体地说,作者引入了一个条件鉴别器来捕获原始交互序列与其编辑版本之间的用户行为差异,这已被证明是一个有用的目标,鼓励用户行为编码器是等变的屏蔽项目替代增强。作者在四个基准SR数据集上的实验证明了ECL-SR的有效性,与经典SR模型和基于不变对比学习的SR模型相比,它具有良好的性能。在未来,作者计划探索更多使用ECL-SR框架的数据增强方法的组合。
相关文章:
【论文阅读】Equivariant Contrastive Learning for Sequential Recommendation
【论文阅读】Equivariant Contrastive Learning for Sequential Recommendation 文章目录 【论文阅读】Equivariant Contrastive Learning for Sequential Recommendation1. 来源2. 介绍3. 前置工作3.1 序列推荐的目标3.2 数据增强策略3.3 序列推荐的不变对比学习 4. 方法介绍4…...
智行破晓,驭未来航程!——经纬恒润智能驾驶数据闭环云平台OrienLink重磅来袭
2023是被AI技术标记的⼀年。年初,OpenAI的GPT崭露头角;6月,Tesla在CVPR2023上对World Model进行深度解读;8月,SIGGRAPH见证GH200、L40S显卡和ChatUSD的登场,FSD V12彰显端到端智能驾驶的实力;9月…...
深入理解WPF中的依赖注入和控制反转
在WPF开发中,依赖注入(Dependency Injection)和控制反转(Inversion of Control)是程序解耦的关键,在当今软件工程中占有举足轻重的地位,两者之间有着密不可分的联系。今天就以一个简单的小例子&…...

【CIO人物展】国家能源集团信息技术主管王爱军:中国企业数智化转型升级的内在驱动力...
王爱军 本文由国家能源集团信息技术主管王爱军投递并参与《2023中国数智化转型升级优秀CIO》榜单/奖项评选。丨推荐企业—锐捷网络 大数据产业创新服务媒体 ——聚焦数据 改变商业 随着全球信息化和网络化的进程日益加速,数字化转型已经成为当下各大企业追求的核心…...
(后续补充)vue+express、gitee pm2部署轻量服务器
首先 防火墙全部关闭算了 首先 防火墙全部关闭算了 首先 防火墙全部关闭算了 首先 防火墙全部关闭算了 首先 防火墙全部关闭算了 首先 防火墙全部关闭算了 关闭防火墙 systemctl stop firewalld 重新载入防火墙使设置生效 firewall-cmd --reload 后端的 pm2.config.cjs …...
第G7周:Semi-Supervised GAN 理论与实战
🍨 本文为🔗365天深度学习训练营 中的学习记录博客 🍦 参考文章:365天深度学习训练营-第G7周:Semi-Supervised GAN 理论与实战(训练营内部成员可读) 🍖 原作者:K同学啊|接…...
美国Embarcadero产品经理Marco Cantù谈Delphi/C++ Builder目前开发应用领域
美国Embarcadero产品经理Marco Cant 日前在欧洲的一次信息技术会议上谈到了Delphi/C Builder目前开发应用领域:RAD Studio Delphi/C Builder目前应用于哪些开发领域?使用 Delphi 和 CBuilder 进行开发为当今众多企业提供了动力。 航空航天 大型数据采集 …...
【iOS】——知乎日报第三周总结
文章目录 一、获取新闻额外信息二、工具栏按钮的布局三、评论区文字高度四、评论区长评论和短评论的数目显示五、评论区的cell布局问题和评论消息的判断 一、获取新闻额外信息 新闻额外信息的URL需要通过当前新闻的id来获取,所以我将所有的新闻放到一个数组中&…...
leetcode每日一题-周复盘
前言 该系列文章用于我对一周中leetcode每日一题or其他不会的题的复盘总结。 一方面用于自己加深印象,另一方面也希望能对读者的算法能力有所帮助。 该复盘对我来说比较容易的题我会复盘的比较粗糙,反之较为细致 解答语言:Golang 周一&a…...
[NLP] LlaMa2模型运行在Mac机器
本文将介绍如何使用llama.cpp在MacBook Pro本地部署运行量化版本的Llama2模型推理,并基于LangChain在本地构建一个简单的文档Q&A应用。本文实验环境为Apple M1 芯片 8GB内存。 Llama2和llama.cpp Llama2是Meta AI开发的Llama大语言模型的迭代版本,…...
基于若依的ruoyi-nbcio流程管理系统增加仿钉钉流程设计(六)
更多ruoyi-nbcio功能请看演示系统 gitee源代码地址 前后端代码: https://gitee.com/nbacheng/ruoyi-nbcio 演示地址:RuoYi-Nbcio后台管理系统 这节主要讲条件节点与并发节点的有效性检查,主要是增加这两个节点的子节点检查,因为…...

听GPT 讲Rust源代码--library/std(15)
题图来自 An In-Depth Comparison of Rust and C[1] File: rust/library/std/src/os/wasi/io/fd.rs 文件路径:rust/library/std/src/os/wasi/io/fd.rs 该文件的作用是实现与文件描述符(File Descriptor)相关的操作,具体包括打开文…...
腾讯云CVM服务器操作系统镜像大全
腾讯云CVM服务器的公共镜像是由腾讯云官方提供的镜像,公共镜像包含基础操作系统和腾讯云提供的初始化组件,公共镜像分为Windows和Linux两大类操作系统,如TencentOS Server、Windows Server、OpenCloudOS、CentOS Stream、CentOS、Ubuntu、Deb…...

Mxnet框架使用
目录 1.mxnet推理API 2.MXNET模型转ONNX 3.运行示例 1.mxnet推理API # 导入 MXNet 深度学习框架 import mxnet as mx if __name__ __main__:# 指定预训练模型的 JSON 文件json_file resnext50_32x4d # 指定模型的参数文件params_file resnext50_32x4d-0000.params # 使…...

每个程序员都应该自己写一个的:socket包装类
每个程序员都应该有自己的网络类。 下面是我自己用的socket类,支持所有我自己常用的功能,支持windows和unix/linux。 目录 客户端 服务端 非阻塞 获取socket信息 完整代码 客户端 作为socket客户端,只需要如下几个功能: //…...

JMeter:断言之响应断言
一、断言的定义 断言用于验证取样器请求或对应的响应数据是否返回了期望的结果。可以是看成验证测试是否预期的方法。 对于接口测试来说,就是测试Request/Response,断言即可以针对Request进行,也可以针对Response进行。但大部分是对Respons…...
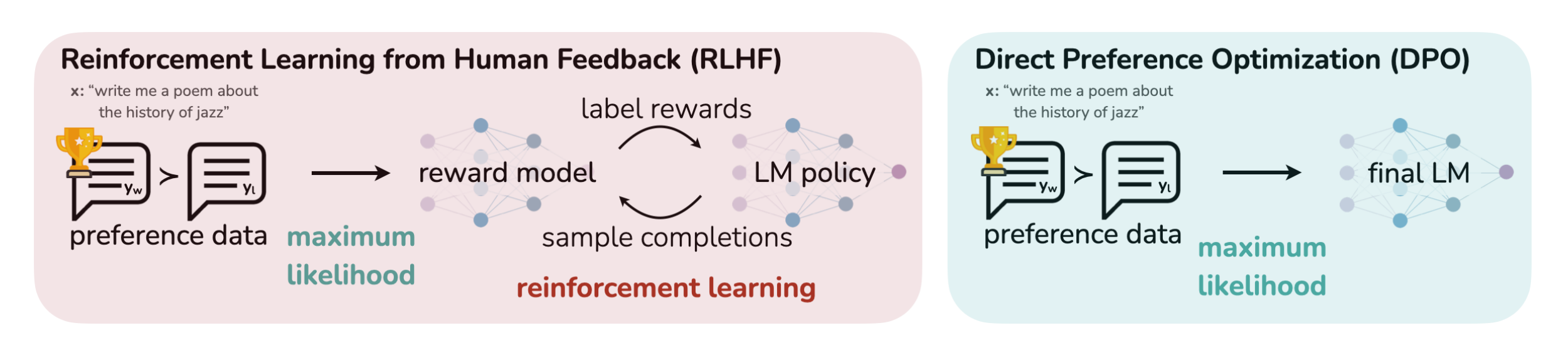
RLHF的替代算法之DPO原理解析:从Zephyr的DPO到Claude的RAILF
前言 本文的成就是一个点顺着一个点而来的,成文过程颇有意思 首先,如上文所说,我司正在做三大LLM项目,其中一个是论文审稿GPT第二版,在模型选型的时候,关注到了Mistral 7B(其背后的公司Mistral AI号称欧洲…...
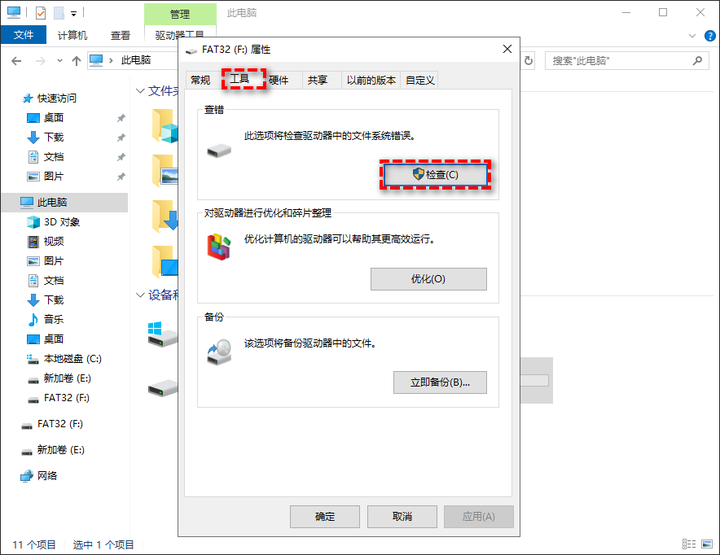
U盘显示无媒体怎么办?方法很简单
当出现U盘无媒体情况时,您可以在磁盘管理工具中看到一个空白的磁盘框,并且在文件资源管理器中不会显示出来。那么,导致这种问题的原因是什么呢?我们又该怎么解决呢? 导致U盘无媒体的原因是什么? 当您遇到上…...
进销存管理系统如何提高供应链效率?
供应链和进销存系统之间有着密切的联系。进销存系统是供应链管理的一部分,用于跟踪和管理产品的采购、库存和销售。进销存管理是供应链管理的核心流程之一,它有助于提高效率、降低成本、增加盈利,同时确保客户满意度,这对于企业的…...

用AI魔法打败AI魔法
全文均为AI创作。 此为内容创作模板,在发布之前请将不必要的内容删除当前,AI技术的广泛应用为社会公众提供了个性化智能化的信息服务,也给网络诈骗带来可乘之机,如不法分子通过面部替换语音合成等方式制作虚假图像、音频、视频仿…...
)
从测速到配置:一套完整的cFosSpeed网络加速保姆级教程(适用于小白)
从零开始掌握cFosSpeed:网络加速全流程实战指南对于经常进行在线游戏、视频会议或大文件传输的用户来说,网络延迟和带宽利用率低下往往是影响体验的关键痛点。cFosSpeed作为一款专业的网络流量优化工具,能够显著改善这些问题,但许…...

Unity安卓构建72小时实战指南:从零到真机运行
1. 这不是“又一本Unity教程”,而是我带三个新人从零上线第一款安卓游戏的真实路径你点开这个标题,大概率正站在两个路口之间:一边是满屏“30天速成Unity”“零基础做爆款”的短视频封面,一边是你刚下载完Unity Hub、卡在Android …...

CANN-昇腾NPU-RAG推理-检索增强生成怎么部署
RAG(Retrieval-Augmented Generation)是 LLM 知识库的组合:先检索相关文档,再让 LLM 基于文档回答。昇腾NPU 上部署 RAG 需要两个组件:Embedding 模型(做向量检索)和 LLM(做生成&am…...
_kaic)
ssm207基于SSM的视频播放系统的设计与实现+vue(文档+源码)_kaic
第五章 系统的实现5.1 用户功能模块的实现5.1.1系统主界面用户进入本系统可查看系统信息,系统主界面展示如图5.1所示。图5.1网站主界面5.1.2视频详情界面用户可选择视频查看视频详情信息,并可进行视频播放操作,视频详情界面展示如图5.2所示。…...

双稳健机器学习:用正交性与交叉拟合解决因果推断中的ML偏差
1. 项目概述:当机器学习遇见因果推断的“干扰”难题在实证研究的日常工作中,我们常常面临一个核心矛盾:我们真正关心的,往往只是一个或几个关键参数——比如一项政策对就业率的平均影响(平均处理效应,ATE&a…...

万星easy-vibe:描述需求即发布 零基础无需学语法
开源Easy-Vibe是一套开源AI编程学习方案,把学习顺序从先学语法再做项目翻转为直接做项目。文章拆解了项目驱动、提示词编写、AI编辑器和多Agent协作的完整流程,解释了为什么想法比语法更重要。 github上datawhalechina/easy-vibe:它在GitHub…...

Git Bash 中无法启动 Claude Code ?
最近需要在 git bash 中跑 Claude Code 。git bash 是随 git for windows 套件安装的,很久没更新了,结果启动 Claude Code 报错:Warning: no stdin data received in 3s, proceeding without it. If piping from a slow command, redirect st…...

League Akari:如何通过LCU API实现英雄联盟游戏流程的智能化管理?
League Akari:如何通过LCU API实现英雄联盟游戏流程的智能化管理? 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit Leag…...

终极STL到STEP转换指南:如何实现3D打印模型到CAD设计的无缝衔接
终极STL到STEP转换指南:如何实现3D打印模型到CAD设计的无缝衔接 【免费下载链接】stltostp Convert stl files to STEP brep files 项目地址: https://gitcode.com/gh_mirrors/st/stltostp 在数字化制造和工程设计领域,STL到STEP转换已成为连接3D…...

收藏|2026年大模型算法岗崛起!程序员小白入门高薪赛道全攻略
前些年,算法岗位一直稳居技术圈高薪行列,无数程序员争相入局,也成为计算机专业毕业生求职首选方向。 伴随大模型技术飞速迭代落地,行业就业格局迎来重大变革。如今含金量最高、人才缺口最大、长期发展潜力顶尖的岗位,已…...