Python 之 Pandas 文件操作和读取 CSV 参数详解
文章目录
- 一、Pandas 读取文件
- 二、CSV 文件读取
- 1. 基本参数
- 2. 通用解析参数
- 3. 空值处理相关参数
- 4. 时间处理相关参数
- 5. 分块读入相关参数
一、Pandas 读取文件
- 当使用 Pandas 做数据分析的时,需要读取事先准备好的数据集,这是做数据分析的第一步。Panda 提供了多种读取数据的方法,针对不同的文件格式,有以下几种:
- (1) read_csv() 用于读取文本文件。
- (2) read_excel() 用于读取文本文件。
- (3) read_json() 用于读取 json 文件。
- (4) read_sql_query() 读取 sql 语句的。
- 其通用的流程如下:
- (1) 导入库 import pandas as pd。
- (2) 找到文件所在位置(绝对路径 = 全称)(相对路径 = 和程序在同一个文件夹中的路径的简称)。
- (3) 变量名 = pd.读写操作方法(文件路径,具体的筛选条件,……)。
二、CSV 文件读取
- CSV 又称逗号分隔值文件,是一种简单的文件格式,以特定的结构来排列表格数据。 CSV 文件能够以纯文本形式存储表格数据,比如电子表格、数据库文件,并具有数据交换的通用格式。CSV 文件会在 Excel 文件中被打开,其行和列都定义了标准的数据格式。
- 将 CSV 中的数据转换为 DataFrame 对象是非常便捷的。和一般文件读写不一样,它不需要你做打开文件、读取文件、关闭文件等操作。相反,您只需要一行代码就可以完成上述所有步骤,并将数据存储在 DataFrame 中。
- 下面进行实例演示,源数据如下:
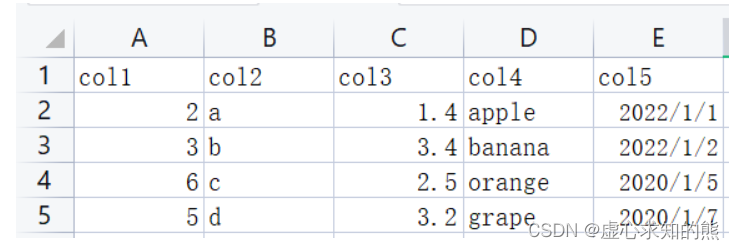
- 首先,我们对 CSV 文件进行读取,可以通过相对路径,也可以通过 os 动态取得绝对路径 os.getcwd() os.path.json。
import pandas as pd
df = pd.read_csv("./data/my_csv.csv")
print(df,type(df))
# col1 col2 col3 col4 col5
#0 2 a 1.4 apple 2022/1/1
#1 3 b 3.4 banana 2022/1/2
#2 6 c 2.5 orange 2022/1/5
#3 5 d 3.2 grape 2022/1/7 <class 'pandas.core.frame.DataFrame'>
- 我们可以通过 os.getcwd() 读取文件的存储路径。
import os
os.getcwd()
#'C:\\Users\\CQB\\Desktop\\内蒙农业大学数据分析教案和代码\\第16天'
- 其语法模板如下:
read_csv(filepath_or_buffer, sep=',', header='infer', names=None, index_col=None, usecols=None, squeeze=None, prefix=None,
mangle_dupe_cols=True, dtype=None, engine=None, converters=None, true_values=None, false_values=None, skipinitialspace=False,
skiprows=None, skipfooter=0, nrows=None, na_values=None, keep_default_na=True, na_filter=True, verbose=False,
skip_blank_lines=True, parse_dates=None, infer_datetime_format=False, keep_date_col=False, date_parser=None, dayfirst=False,
cache_dates=True, iterator=False, chunksize=None, compression='infer', thousands=None, decimal='.', lineterminator=None,
quotechar='"', quoting=0, doublequote=True, escapechar=None, comment=None, encoding=None, encoding_errors='strict', dialect=None,
error_bad_lines=None, warn_bad_lines=None, on_bad_lines=None, delim_whitespace=False, low_memory=True, memory_map=False,
float_precision=None, storage_options=None)
1. 基本参数
- (1) filepath_or_buffer(数据输入的路径):可以是文件路径、可以是 URL,也可以是实现 read 方法的任意对象。这个参数,就是我们输入的第一个参数。
- 我们可以直接 read_csv 读取我们想要的文件。
import pandas as pd
pd.read_csv(r"data\students.csv")
#id name address gender birthday
#0 1 朱梦雪 地球村 女 2004/11/2
#1 2 许文博 月亮星 女 2003/8/7
#2 3 张兆媛 艾尔星 女 2004/11/2
#3 4 付延旭 克哈星 男 2003/10/11
#4 5 王杰 查尔星 男 2002/6/12
#5 6 董泽宇 塔桑尼斯 男 2002/2/12
- 还可以是一个 URL,如果访问该 URL 会返回一个文件的话,那么 pandas 的 read_csv函 数会自动将该文件进行读取。比如:我们服务器上放的数据,将刚才的文件返回。
- 但需要注意的是,他需要网络请求,因此读取文件比较慢。
pd.read_csv("http://my-teaching.top/static/data/students.csv")
- 里面还可以是一个 _io.TextIOWrapper,其中,pandas 默认使用 utf-8 读取文件,比如:
f = open(r"data\students.csv", encoding="utf-8")
pd.read_csv(f)
#id name address gender birthday
#0 1 朱梦雪 地球村 女 2004/11/2
#1 2 许文博 月亮星 女 2003/8/7
#2 3 张兆媛 艾尔星 女 2004/11/2
#3 4 付延旭 克哈星 男 2003/10/11
#4 5 王杰 查尔星 男 2002/6/12
#5 6 董泽宇 塔桑尼斯 男 2002/2/12
- (2) sep:读取 csv 文件时指定的分隔符,默认为逗号。注意:csv 文件的分隔符和我们读取 csv 文件时指定的分隔符一定要一致。
import pandas as pd
pd.read_csv(r"data\students_step.csv")
#id|name|address|gender|birthday
#0 1|朱梦雪|地球村|女|2004/11/2
#1 2|许文博|月亮星|女|2003/8/7
#2 3|张兆媛|艾尔星|女|2004/11/2
#3 4|付延旭|克哈星|男|2003/10/11
#4 5|王杰|查尔星|男|2002/6/12
#5 6|董泽宇|塔桑尼斯|男|2002/2/12
- 由于指定的分隔符和 csv 文件采用的分隔符不一致,因此多个列之间没有分开,而是连在一起了。 所以,我们需要将分隔符设置成 \t 才可以。
df = pd.read_csv(r"data\students_step.csv", sep="|")
df
#id name address gender birthday
#0 1 朱梦雪 地球村 女 2004/11/2
#1 2 许文博 月亮星 女 2003/8/7
#2 3 张兆媛 艾尔星 女 2004/11/2
#3 4 付延旭 克哈星 男 2003/10/11
#4 5 王杰 查尔星 男 2002/6/12
#5 6 董泽宇 塔桑尼斯 男 2002/2/12
- (3) delim_whitespace:默认为 False,设置为 True 时,表示分割符为空白字符,可以是空格、\t 等等。不管分隔符是什么,只要是空白字符,那么可以通过 delim_whitespace=True 进行读取。
- 如下,我们对 delim_whitespace 不设置,也就是默认为 False,会发现读取有点问题。
df = pd.read_csv(r"data\students_whitespace.txt", sep=" ")
df
#id name address gender birthday
#0 1 朱梦雪 地球村 女 2004/11/2
#1 2 许文博\t月亮星 女 2003/8/7 NaN
#2 3 张兆媛 艾尔星 女 2004/11/2
#3 4 付延旭 克哈星 男 2003/10/11
#4 5 王杰\t查尔星 男 2002/6/12 NaN
#5 6 董泽宇\t塔桑尼斯 男 2002/2/12 NaN
- 对此,我们将 delim_whitespace 设置为 True,便会得到我们想要的读取结果。
df = pd.read_csv(r"data\students_whitespace.txt", delim_whitespace=True)
df
#id name address gender birthday
#0 1 朱梦雪 地球村 女 2004/11/2
#1 2 许文博 月亮星 女 2003/8/7
#2 3 张兆媛 艾尔星 女 2004/11/2
#3 4 付延旭 克哈星 男 2003/10/11
#4 5 王杰 查尔星 男 2002/6/12
#5 6 董泽宇 塔桑尼斯 男 2002/2/12
- (4) header:用作列名的行号,以及数据的开头。
- 默认行为是推断列名:如果没有传递任何名称,则该行为与 header=0 相同,并且从文件的第一行推断列名,如果显式传递列名,则该行为与 header=None 相同。
- 显式传递 header=0 以替换现有名称。标题可以是整数列表,指定列上多索引的行位置,例如 [0,1,3]。未指定的中间行将被跳过(例如,本例中跳过 2 行)。
- 这里需要注意,如果 skip_blank_lines=True,此参数将忽略注释行和空行,因此 header=0 表示数据的第一行,而不是文件的第一行。
- (5) names:当 names 没被赋值时,header 会变成 0,即选取数据文件的第一行作为列名;当 names 被赋值,header 没被赋值时,那么 header 会变成 None。如果都赋值,就会实现两个参数的组合功能。
- (a) names 没有被赋值,header 也没赋值:
- 这种情况下,header 为 0,即选取文件的第一行作为表头。
pd.read_csv(r"data\students.csv")
#id name address gender birthday
#0 1 朱梦雪 地球村 女 2004/11/2
#1 2 许文博 月亮星 女 2003/8/7
#2 3 张兆媛 艾尔星 女 2004/11/2
#3 4 付延旭 克哈星 男 2003/10/11
#4 5 王杰 查尔星 男 2002/6/12
#5 6 董泽宇 塔桑尼斯 男 2002/2/12
- (b) names 没有被赋值,header 被赋值:
- 如果不指定 names,指定 header 为 1,则选取第二行当做表头,第二行下面为数据。
pd.read_csv(r"data\students.csv", header=1)
#1 朱梦雪 地球村 女 2004/11/2
#0 2 许文博 月亮星 女 2003/8/7
#1 3 张兆媛 艾尔星 女 2004/11/2
#2 4 付延旭 克哈星 男 2003/10/11
#3 5 王杰 查尔星 男 2002/6/12
#4 6 董泽宇 塔桑尼斯 男 2002/2/12
- (c) names 被赋值,header 没有被赋值:
pd.read_csv(r"data\students.csv", names=["编号", "姓名", "地址", "性别", "出生日期"])
#编号 姓名 地址 性别 出生日期
#0 id name address gender birthday
#1 1 朱梦雪 地球村 女 2004/11/2
#2 2 许文博 月亮星 女 2003/8/7
#3 3 张兆媛 艾尔星 女 2004/11/2
#4 4 付延旭 克哈星 男 2003/10/11
#5 5 王杰 查尔星 男 2002/6/12
#6 6 董泽宇 塔桑尼斯 男 2002/2/12
- 可以看到,names 适用于没有表头的情况,指定 names 没有指定 header,那么 header 相当于 None。
- 一般来说,读取文件的时候会有一个表头,一般默认是第一行,但是有的文件中是没有表头的,那么这个时候就可以通过 names 手动指定、或者生成表头,而文件里面的数据则全部是内容。
- 所以这里 id、name、address、date 也当成是一条记录了,本来它是表头的,但是我们指定了 names,所以它就变成数据了,表头是我们在 names 里面指定的。
- (a) names 和 header 都被赋值:
pd.read_csv(r"data\students.csv",names=["编号", "姓名", "地址", "性别", "出生日期"],header=1)
#编号 姓名 地址 性别 出生日期
#0 2 许文博 月亮星 女 2003/8/7
#1 3 张兆媛 艾尔星 女 2004/11/2
#2 4 付延旭 克哈星 男 2003/10/11
#3 5 王杰 查尔星 男 2002/6/12
#4 6 董泽宇 塔桑尼斯 男 2002/2/12
- 这个时候,相当于先不看 names,只看 header,header 为 0 代表先把第一行当做表头,下面的当成数据;然后再把表头用 names 给替换掉。
- names 和 header 的使用场景主要如下:
- (1) csv 文件有表头并且是第一行,那么 names 和 header 都无需指定;
- (2) csv 文件有表头、但表头不是第一行,可能从下面几行开始才是真正的表头和数据,这个时候指定 header 即可;
- (3) csv 文件没有表头,全部是纯数据,那么我们可以通过 names 手动生成表头;
- (4) csv 文件有表头、但是这个表头你不想用,这个时候同时指定 names 和 header。先用 header 选出表头和数据,然后再用 names 将表头替换掉,就等价于将数据读取进来之后再对列名进行 rename。
- (6) index_col:我们在读取文件之后所得到的 DataFrame 的索引默认是 0、1、2……,我们可以通过 set_index 设定索引,但是也可以在读取的时候就指定某列为索引。
df = pd.read_csv(r"data\students.csv", index_col="birthday")
df
# id name address gender
#birthday
#2004/11/2 1 朱梦雪 地球村 女
#2003/8/7 2 许文博 月亮星 女
#2004/11/2 3 张兆媛 艾尔星 女
#2003/10/11 4 付延旭 克哈星 男
#2002/6/12 5 王杰 查尔星 男
#2002/2/12 6 董泽宇 塔桑尼斯 男
- 也可以用来删除指定列。
df.index=df['birthday']
del df['birthday']
df
# id name address gender
#birthday
#2004/11/2 1 朱梦雪 地球村 女
#2003/8/7 2 许文博 月亮星 女
#2004/11/2 3 张兆媛 艾尔星 女
#2003/10/11 4 付延旭 克哈星 男
#2002/6/12 5 王杰 查尔星 男
#2002/2/12 6 董泽宇 塔桑尼斯 男
- 我们在读取的时候指定了 name 列作为索引; 此外,除了指定单个列,还可以指定多列作为索引,比如 [“id”, “name”]。同时,我们除了可以输入列名外,还可以输入列对应的索引。比如:“id”、“name”、“address”、"date"对应的索引就分别是 0、1、2、3。
df2 = pd.read_csv(r"data\students.csv", index_col=["gender","birthday"])
df2
# id name address
#gender birthday
#女 2004/11/2 1 朱梦雪 地球村
# 2003/8/7 2 许文博 月亮星
# 2004/11/2 3 张兆媛 艾尔星
#男 2003/10/11 4 付延旭 克哈星
# 2002/6/12 5 王杰 查尔星
# 2002/2/12 6 董泽宇 塔桑尼斯
- 使用 loc 删选也是同样的道理。
df2.loc["女"]
# id name address
#birthday
#2004/11/2 1 朱梦雪 地球村
#2003/8/7 2 许文博 月亮星
#2004/11/2 3 张兆媛 艾尔星
- (7) usecols:返回列的子集。
- 如果是类似列表的,则所有元素都必须是位置性的(即文档列中的整数索引),或者是与用户在名称中提供的列名或从文档标题行推断的列名相对应的字符串。如果给出了名称,则不考虑文档标题行。
pd.read_csv(r"data\students.csv", usecols=["name","birthday"])
# name
#0 朱梦雪
#1 许文博
#2 张兆媛
#3 付延旭
#4 王杰
#5 董泽宇
2. 通用解析参数
- (1) encoding:表示这只编码格式,utf-8,gbk。
pd.read_csv(r"data\students_gbk.csv") # UnicodeDecodeError
- 如果提示错误喂 UnicodeDecodeError —> 需要想到编码问题。
- pandas 默认使用 utf-8 格式读取。
pd.read_csv(r"data\students_gbk.csv", encoding="gbk")
#id name address gender birthday
#0 1 朱梦雪 地球村 女 2004/11/2
#1 2 许文博 月亮星 女 2003/8/7
#2 3 张兆媛 艾尔星 女 2004/11/2
#3 4 付延旭 克哈星 男 2003/10/11
#4 5 王杰 查尔星 男 2002/6/12
#5 6 董泽宇 塔桑尼斯 男 2002/2/12
- (2) dtype:在读取数据的时候,设定字段的类型。
- 比如,公司员工的 id 一般是:00001234,如果默认读取的时候,会显示为 1234,所以这个时候要把他转为字符串类型,才能正常显示为 00001234。
df = pd.read_csv(r"data\students_step_001.csv", sep="|")
df
#id name address gender birthday
#0 1 朱梦雪 地球村 女 2004/11/2
#1 2 许文博 月亮星 女 2003/8/7
#2 3 张兆媛 艾尔星 女 2004/11/2
#3 4 付延旭 克哈星 男 2003/10/11
#4 5 王杰 查尔星 男 2002/6/12
#5 6 董泽宇 塔桑尼斯 男 2002/2/12
- 我们将 id 的数据类型设置为字符串,便可以显示为 001 之类的。
df = pd.read_csv(r"data\students_step_001.csv", sep="|", dtype ={"id":str})
df
#id name address gender birthday
#0 001 朱梦雪 地球村 女 2004/11/2
#1 002 许文博 月亮星 女 2003/8/7
#2 003 张兆媛 艾尔星 女 2004/11/2
#3 004 付延旭 克哈星 男 2003/10/11
#4 005 王杰 查尔星 男 2002/6/12
#5 006 董泽宇 塔桑尼斯 男 2002/2/12
- (3) converters:在读取数据的时候对列数据进行变换.
- 例如将 id 增加 10,但是注意 int(x),在使用 converters 参数时,解析器默认所有列的类型为 str,所以需要进行类型转换。
pd.read_csv('data\students.csv', converters={"id": lambda x: int(x) + 10})
#id name address gender birthday
#0 11 朱梦雪 地球村 女 2004/11/2
#1 12 许文博 月亮星 女 2003/8/7
#2 13 张兆媛 艾尔星 女 2004/11/2
#3 14 付延旭 克哈星 男 2003/10/11
#4 15 王杰 查尔星 男 2002/6/12
#5 16 董泽宇 塔桑尼斯 男 2002/2/12
- (4) true_values 和 false_values:指定哪些值应该被清洗为 True,哪些值被清洗为 False。
- 我们以性别为例,男设置为 True,女设置为 False。
pd.read_csv('data\students.csv', true_values=['男'], false_values=['女'])
# id name address gender birthday
#0 1 朱梦雪 地球村 False 2004/11/2
#1 2 许文博 月亮星 False 2003/8/7
#2 3 张兆媛 艾尔星 False 2004/11/2
#3 4 付延旭 克哈星 True 2003/10/11
#4 5 王杰 查尔星 True 2002/6/12
#5 6 董泽宇 塔桑尼斯 True 2002/2/12
- 这里的替换规则为,只有当某一列的数据类别全部出现在 true_values + false_values 里面,才会被替换。
- (5) skiprows:表示过滤行,想过滤掉哪些行,就写在一个列表里面传递给 skiprows 即可。注意的是,这里是先过滤,然后再确定表头,比如:
pd.read_csv('data\students.csv', skiprows=[0,3])
# 1 朱梦雪 地球村 女 2004/11/2
#0 2 许文博 月亮星 女 2003/8/7
#1 4 付延旭 克哈星 男 2003/10/11
#2 5 王杰 查尔星 男 2002/6/12
#3 6 董泽宇 塔桑尼斯 男 2002/2/12
- 这里把第一行过滤掉了,因为第一行是表头,所以在过滤掉之后第二行就变成表头了。 当然里面除了传入具体的数值,来表明要过滤掉哪些行,还可以传入一个函数。
pd.read_csv('data\students.csv', skiprows=lambda x: x > 0 and x % 2 == 0)
# id name address gender birthday
#0 1 朱梦雪 地球村 女 2004/11/2
#1 3 张兆媛 艾尔星 女 2004/11/2
#2 5 王杰 查尔星 男 2002/6/12
- 由于索引从 0 开始,所以凡是索引大于 0、并且%2 等于 0 的记录都过滤掉。索引大于 0,是为了保证表头不被过滤掉。
- (6) skipfooter:表示从文件末尾过滤行。
pd.read_csv('data\students.csv', skipfooter=1)
- 上述代码运行后会出现报错,并且表格中的数据都变成乱码,具体原因下方有解释。
pd.read_csv('data\students.csv', skipfooter=1, engine="python", encoding="utf-8")
# id name address gender birthday
#0 1 朱梦雪 地球村 女 2004/11/2
#1 2 许文博 月亮星 女 2003/8/7
#2 3 张兆媛 艾尔星 女 2004/11/2
#3 4 付延旭 克哈星 男 2003/10/11
#4 5 王杰 查尔星 男 2002/6/12
- pandas 解析数据时用的引擎,目前解析引擎有两种:c、python。默认为 c,因为 c 引擎解析速度更快,但是特性没有 python 引擎全。
- skipfooter 接收整型,表示从结尾往上过滤掉指定数量的行,因为引擎退化为 python,那么要手动指定 engine=“python”,不然会警告。另外需要指定 encoding=“utf-8”,因为 csv 存在编码问题,当引擎退化为 python 的时候,在 Windows 上读取会乱码。
- (7) nrows:表示设置一次性读入的文件行数,在读入大文件时很有用,比如 16G 内存的 PC 无法容纳几百 G 的大文件。
pd.read_csv('data\students.csv', nrows=3)
# id name address gender birthday
#0 1 朱梦雪 地球村 女 2004/11/2
#1 2 许文博 月亮星 女 2003/8/7
#2 3 张兆媛 艾尔星 女 2004/11/2
3. 空值处理相关参数
- na_values:该参数可以配置哪些值需要处理成 NaN。
pd.read_csv('data\students.csv', na_values=["女", "朱梦雪"])#id name address gender birthday
#0 1 NaN 地球村 NaN 2004/11/2
#1 2 许文博 月亮星 NaN 2003/8/7
#2 3 张兆媛 艾尔星 NaN 2004/11/2
#3 4 付延旭 克哈星 男 2003/10/11
#4 5 王杰 查尔星 男 2002/6/12
#5 6 董泽宇 塔桑尼斯 男 2002/2/12
- 可以看到将女和朱梦雪设置成了NaN,这里的情况是不同的列中包含了不同的值。
4. 时间处理相关参数
- parse_dates:指定某些列为时间类型,这个参数一般搭配 date_parser 使用。
- date_parser:是用来配合 parse_dates 参数的,因为有的列虽然是日期,但没办法直接转化,需要我们指定一个解析格式。
df = pd.read_csv('data\students.csv')
df.dtypes
#id int64
#name object
#address object
#gender object
#birthday object
#dtype: object
- 我们通过 parse_dates 将 birthday 设置为时间类型。
df = pd.read_csv('data\students.csv', parse_dates=["birthday"])
df.dtypes
#id int64
#name object
#address object
#gender object
#birthday datetime64[ns]
#dtype: object
5. 分块读入相关参数
- (1) iterator:迭代器,iterator 为 bool 类型,默认为 False。
- 如果为 True,那么返回一个 TextFileReader 对象,以便逐块处理文件。这个在文件很大、内存无法容纳所有数据文件时,可以分批读入,依次处理。
chunk = pd.read_csv('data\students.csv', iterator=True)
chunk
#<pandas.io.parsers.TextFileReader at 0x1b27f00ef88>
- 我们已经对文件进行了分块操作,可以先提取出前两行。
print(chunk.get_chunk(2))
# id name address gender birthday
#0 1 朱梦雪 地球村 女 2004/11/2
#1 2 许文博 月亮星 女 2003/8/7
- 文件还剩下四行,但是我们指定读取100,那么也不会报错,不够指定的行数,那么有多少返回多少。
print(chunk.get_chunk(100))
# id name address gender birthday
#2 3 张兆媛 艾尔星 女 2004/11/2
#3 4 付延旭 克哈星 男 2003/10/11
#4 5 王杰 查尔星 男 2002/6/12
#5 6 董泽宇 塔桑尼斯 男 2002/2/12
- 这里需要注意的是,在读取完毕之后,再读的话就会报错了。
- (2) chunksize:整型,默认为 None,设置文件块的大小。
- chunksize 还是返回一个类似于迭代器的对象,当我们调用 get_chunk,如果不指定行数,那么就是默认的 chunksize。
chunk = pd.read_csv('data\students.csv', chunksize=2)
print(chunk)
print(chunk.get_chunk())
#<pandas.io.parsers.TextFileReader object at 0x000001B27F05C5C8>
# id name address gender birthday
#0 1 朱梦雪 地球村 女 2004/11/2
#1 2 许文博 月亮星 女 2003/8/7
- 我们再使用两次 print(chunk.get_chunk()) 就可以分步读取出所有的数据,因为这里的 chunksize 设置为 2。
- 我们也可以指定 chunk.get_chunk() 的参数。
- 以上便是 pandas 的 read_csv 函数中绝大部分参数了,同时其中的部分参数也适用于读取其它类型的文件。
- 其实在读取 csv 文件时所使用的参数不多,很多参数平常我们都不会用到的,不过不妨碍我们了解一下,因为在某些特定的场景下它们是可以很方便地帮我们解决一些问题的。
- 个人感觉分块读取这个参数最近在工作中提高了很大的效率。
相关文章:
Python 之 Pandas 文件操作和读取 CSV 参数详解
文章目录一、Pandas 读取文件二、CSV 文件读取1. 基本参数2. 通用解析参数3. 空值处理相关参数4. 时间处理相关参数5. 分块读入相关参数一、Pandas 读取文件 当使用 Pandas 做数据分析的时,需要读取事先准备好的数据集,这是做数据分析的第一步。Panda 提…...

微服务的异步通信技术RabbitMQ
文章目录前言1.WorkQueue(工作队列)消息预取机制2.Publish&Subscribe(发布-订阅)1.Fanout(广播)2.DirectExchange(路由)3.TopicExchange(话题)MQ的优点前…...
Word处理控件Aspose.Words功能演示:使用 C++ 在 Word (DOC/DOCX) 中添加或删除水印
Aspose.Words 是一种高级Word文档处理API,用于执行各种文档管理和操作任务。API支持生成,修改,转换,呈现和打印文档,而无需在跨平台应用程序中直接使用Microsoft Word。此外, Aspose API支持流行文件格式处…...
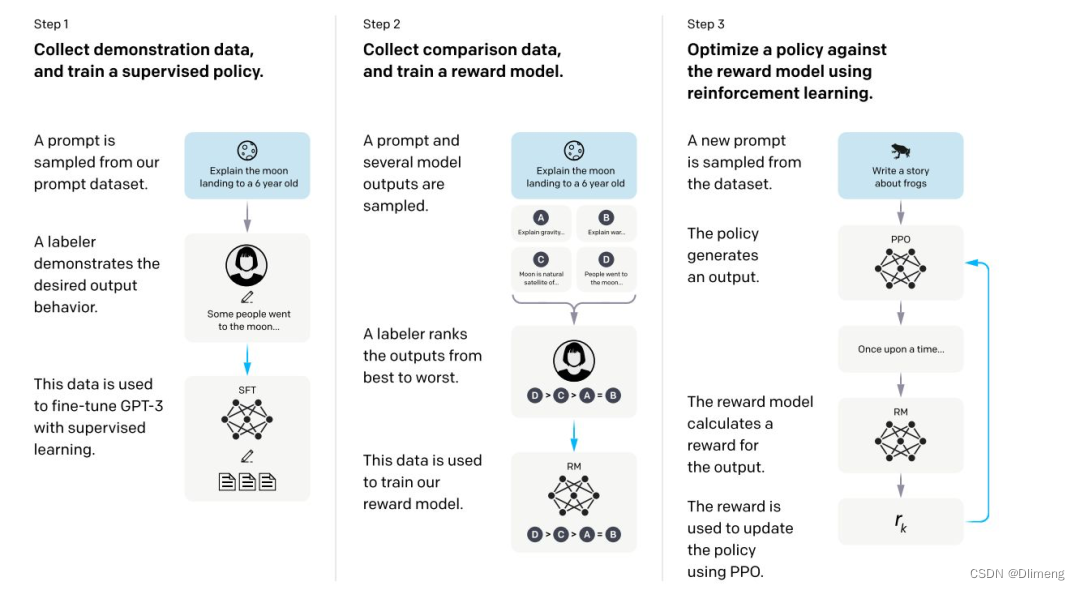
chatGPT模型原理
文章目录简介BertGPT 初代GPT-2GPT-3chatGPT开源ChatGPT简介 openai 的 GPT 大模型的发展历程。 Bert 2018年,自然语言处理 NLP 领域也步入了 LLM 时代,谷歌出品的 Bert 模型横空出世,碾压了以往的所有模型,直接在各种NLP的建模…...
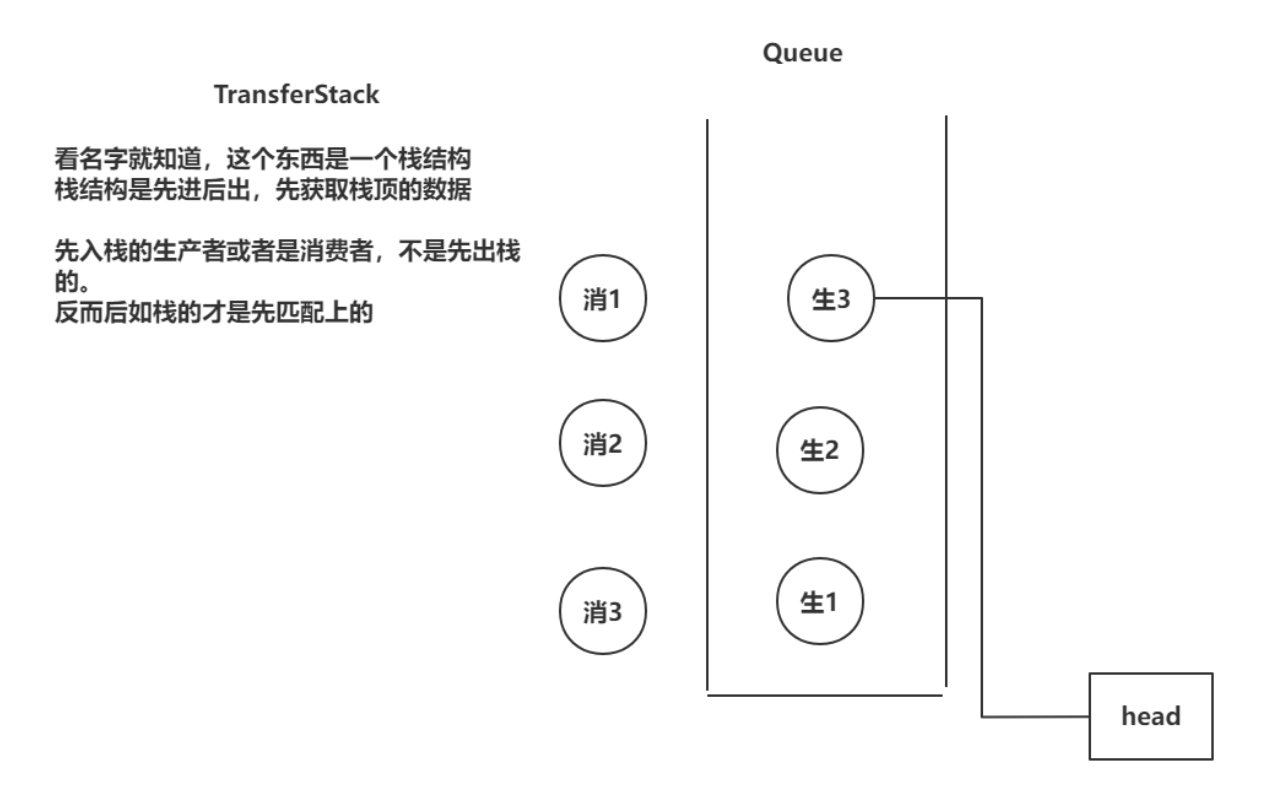
四、阻塞队列
文章目录基础概念生产者消费者概念JUC阻塞队列的存取方法ArrayBlockingQueueArrayBlockingQueue的基本使用生产者方法实现原理ArrayBlockingQueue的常见属性add方法实现offer方法实现offer(time,unit)方法put方法消费者方法实现原理remove方法poll方法poll(time,unit)方法take方…...
企业电子招投标采购系统源码之登录页面
信息数智化招采系统 服务框架:Spring Cloud、Spring Boot2、Mybatis、OAuth2、Security 前端架构:VUE、Uniapp、Layui、Bootstrap、H5、CSS3 涉及技术:Eureka、Config、Zuul、OAuth2、Security、OSS、Turbine、Zipkin、Feign、Monitor、…...
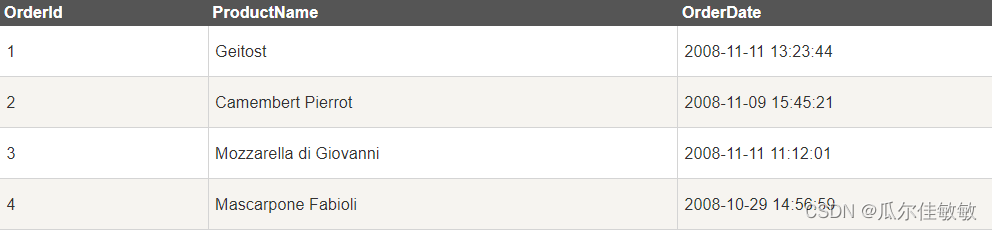
SQL零基础入门学习(十三)
上一篇(SQL零基础入门学习(十二)) SQL 视图(Views) 视图是可视化的表。 SQL CREATE VIEW 语句 在 SQL 中,视图是基于 SQL 语句的结果集的可视化的表。 视图包含行和列,就像一个…...

Java实现简单KV数据库
用Java实现一个简单的KV数据库 开发思路: 用map存储数据,再用一个List记录操作日志,开一个新线程将List中的操作写入日志文件中,再开一个线程用于网络IO服务接收客户端的命令,再启动时检查日志,如果有数据就…...

【Spark分布式内存计算框架——Spark Streaming】5. DStream(上)
3. DStream SparkStreaming模块将流式数据封装的数据结构:DStream(Discretized Stream,离散化数据流,连续不断的数据流),代表持续性的数据流和经过各种Spark算子操作后的结果数据流。 3.1 DStream 是什么…...
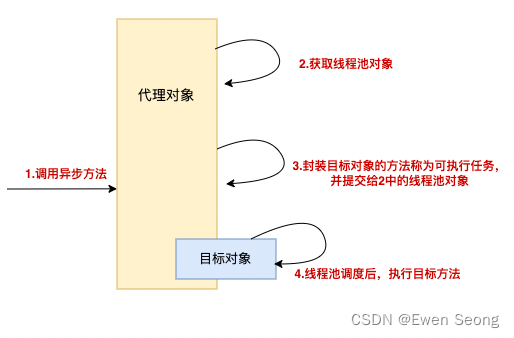
Spring系列-9 Async注解使用与原理
背景: 本文作为Spring系列的第九篇,介绍Async注解的使用、注意事项和实现原理,原理部分会结合Spring框架代码进行。 本文可以和Spring系列-8 AOP原理进行比较阅读 1.使用方式 Async一般注解在方法上,用于实现方法的异步…...

Python自动化测试实战篇(6)用PO分层模式及思想,优化unittest+ddt+yaml+request登录接口自动化测试
这些是之前的文章,里面有一些基础的知识点在前面由于前面已经有写过,所以这一篇就不再详细对之前的内容进行描述 Python自动化测试实战篇(1)读取xlsx中账户密码,unittest框架实现通过requests接口post登录网站请求&…...

Linux 进程:父子进程
目录一、了解子进程二、创建子进程1.创建子进程2.区分父子进程三、理解子进程四、创建子进程的意义进程就是运行中的应用程序,如果一个程序较为庞大,我们可以给这个程序创建多个进程,每个进程负责一部分代码的运行。 A进程如果创建了B进程&am…...
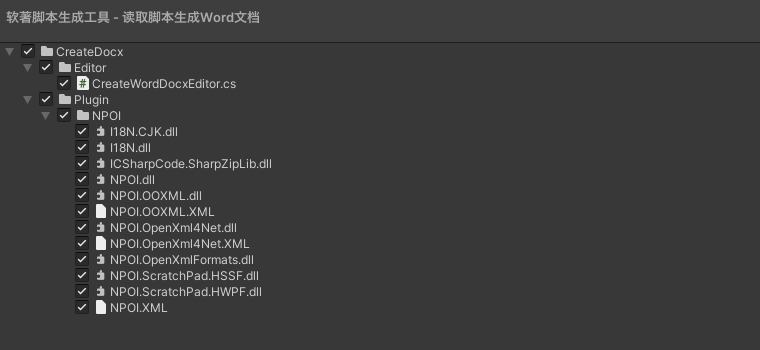
Unity 之 实现读取代码写进Word文档功能实现 -- 软著脚本生成工具
Unity 之 实现读取代码写进Word文档功能前言一,实现步骤1.1 逻辑梳理1.2 用到工具二,实现读写文件2.1 读取目录相关2.2 读写文件三,编辑器拓展3.1 编辑器拓展介绍3.2 实现界面可视化四,源码分享4.1 工具目录4.2 完整代码前言 之所…...
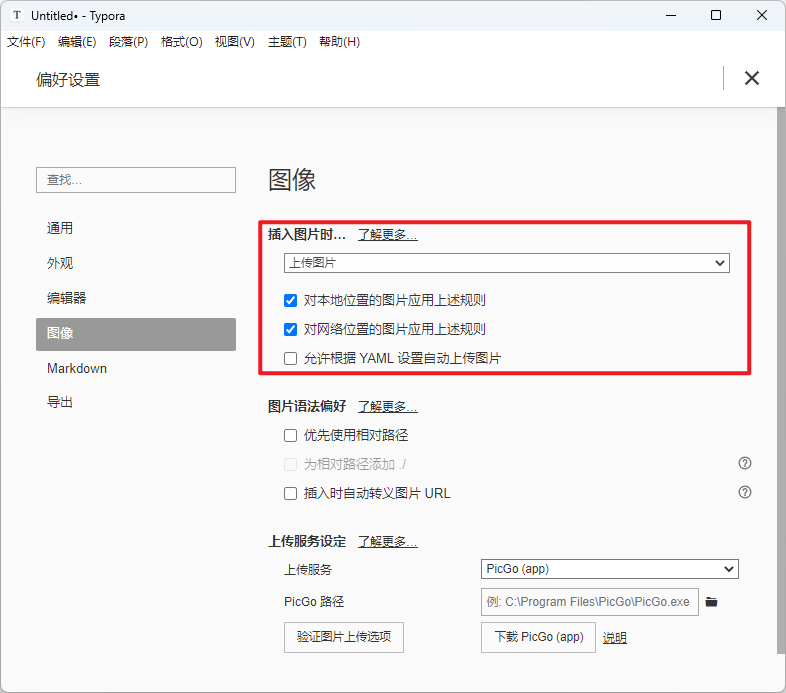
Typora图床配置:Typora + PicGo + 阿里云OSS
文章目录一、前景提要二、相关链接三、搭建步骤1. 购买阿里云对象存储OSS2. 对象存储OSS:创建Bucket3. 阿里云:添加OSS访问用户及权限4. 安装Typora5. 配置PicGo方法一:使用PicGo-Core (Command line)方法二:使用PicGo(app)6. 最后…...

二进制搭建以太坊2.0节点-2023最新详细版文档
文章目录 一、配置 JWT 认证二、部署执行节点geth2.1 下载geth二进制文件2.2 geth节点启动三、部署共识节点Prysm3.1 下载Prysm脚本3.2 Prysm容器生成四、检查节点是否同步完成4.1 检查geth执行节点4.2 检查prysm共识节点4.3 geth常用命令五、节点同步详细说明5.1 启动时日志5.…...
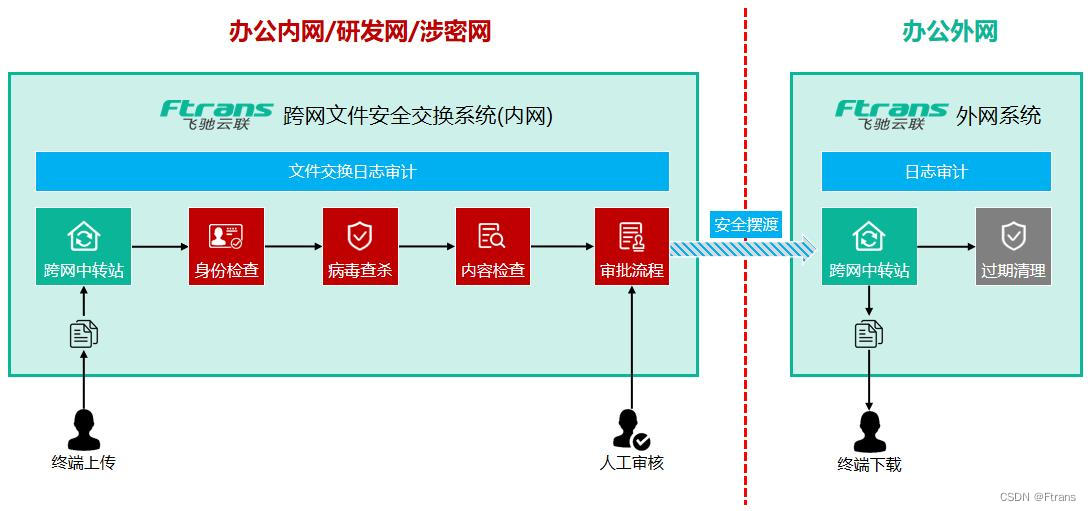
如何简化跨网络安全域的文件发送流程,大幅降低IT人员工作量?
为什么要做安全域的隔离? 随着企业数字化转型的逐步深入,企业投入了大量资源进行信息系统建设,信息化程度日益提升。在这一过程中,企业也越来越重视核心数据资产的保护,数据资产的安全防护成为企业面临的重大挑战。 …...

带你深入了解c语言指针后续
前言 🎈个人主页:🎈 :✨✨✨初阶牛✨✨✨ 🐻推荐专栏: 🍔🍟🌯 c语言进阶 🔑个人信条: 🌵知行合一 🍉本篇简介:>:介绍c语言中有关指针更深层的知识. 金句分享: ✨在该…...
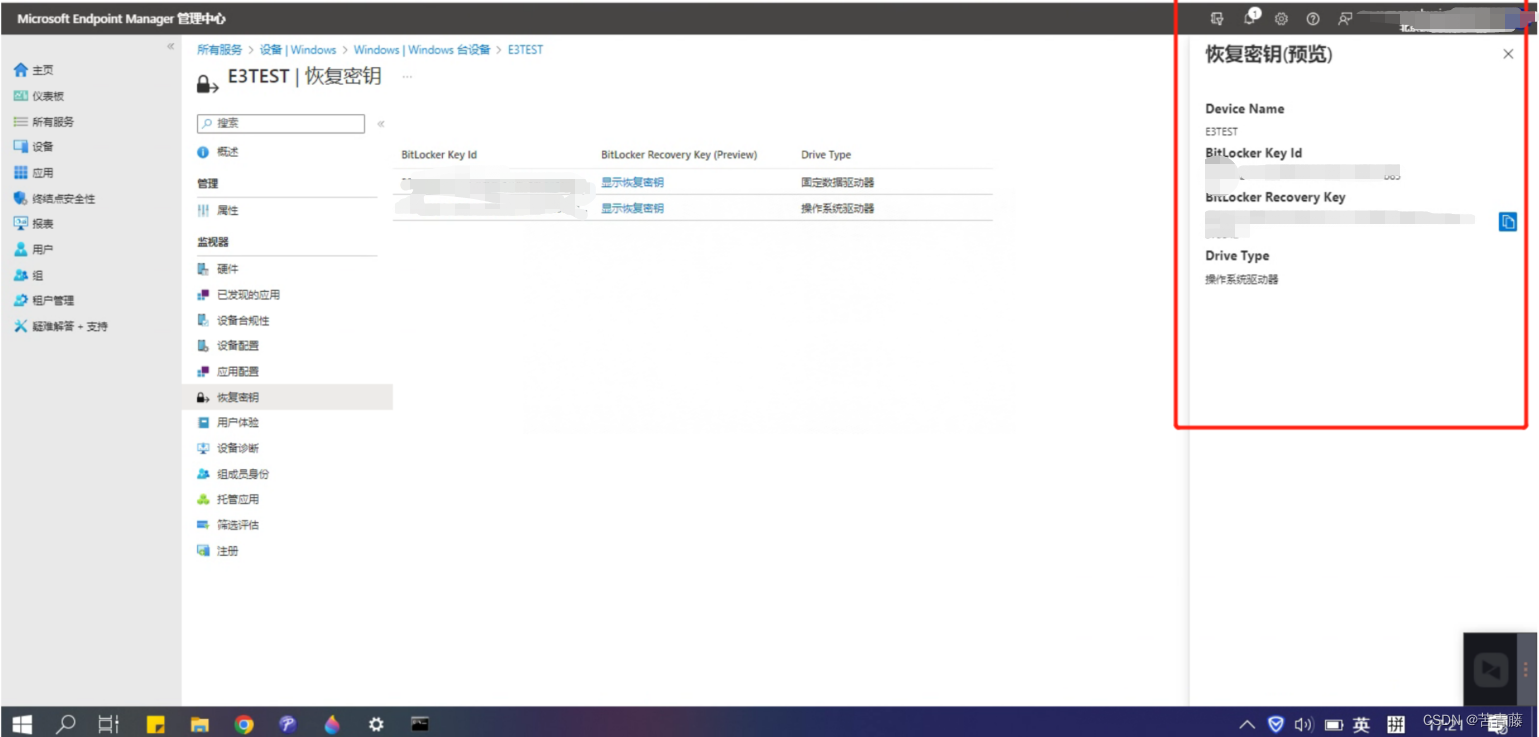
借助Intune无感知开启Bitlocker
希望使用 Intune 部署 BitLocker,但不知道从哪里开始?这是人们最开始使用 Intune 时最常见的问题之一。在本博客中,你将了解有关使用 Intune 管理 BitLocker 的所有信息,包括建议的设置、BitLocker CSP 在客户端上的工作方式&…...

零基础该如何转行Python工程师?学习路线是什么?
最近1年的主要学习时间,都投资到了 python 数据分析和数据挖掘上面来了,虽然经验并不是十分丰富,但希望也能把自己的经验分享下,最近也好多朋友给我留言,和我聊天,问我python该如何学习,才能少走…...
Go项目(商品微服务-1)
文章目录简介建表protohandler商品小结简介 商品微服务主要在于表的设计,建哪些表?表之间的关系是怎样的? 主要代码就是 CURD表和字段的设计是一个比较有挑战性的工作,比较难说清楚,也需要经验的积累,这里…...

物联网数据完整性保障的多层级架构设计与实践
1. 物联网数据完整性的核心挑战在传统IT系统中,数据流动遵循着严格的请求-响应模式,服务器和客户端之间的交互是可预测且有序的。但物联网环境彻底颠覆了这一范式——数以亿计的终端设备以异步、不可预测的方式产生数据流,这种特性使得数据完…...

Sveltos:多集群Kubernetes应用分发与配置管理的核心利器
1. 项目概述:Sveltos,一个被低估的集群应用管理利器如果你和我一样,长期在多集群的Kubernetes环境中摸爬滚打,那你一定对“应用分发”这件事的复杂性深有体会。想象一下,你手头有几十甚至上百个集群,有的在…...

从TTP223到JL523:低成本电容触摸按钮的选型与实战
1. 电容触摸按钮入门:从原理到选型 第一次接触电容触摸按钮是在五年前的一个智能台灯项目上。当时为了给台灯添加一个酷炫的触摸开关,我试遍了市面上各种方案,最终锁定了TTP223这颗经典芯片。没想到几年后,国产的JL523给了我更大的…...

2026最权威的降重复率神器解析与推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 降低人工智能部署以及应用阶段的优化,需要从算力调度、算法剪枝以及参数压缩这三…...

VR文旅大空间|沉浸式体验重塑文旅新场景
随着文旅产业不断升级,传统“走马观花式”的旅游体验已经难以满足游客日益增长的体验需求。如何让游客“留下来、玩得久、愿意分享”,成为各地文旅项目共同思考的问题。在这一背景下,VR大空间文旅逐渐走入大众视野,成为文旅融合发…...

软件测试十年老兵自述:从月薪3K到年薪50W的跃迁密码
一个Bug改变的人生轨迹十年前的那个下午,我还记得格外清晰。作为某外包公司的“点点点”工程师,我机械地对着一个后台管理系统重复着测试用例。月薪3000,坐标二线城市,每天的工作就是执行别人写好的用例,发现Bug就提交…...

设计程序统计行业淡季旺季,职场工作量数据,合理调配人力,解决忙闲不均,人力资源浪费职场现状。
一、实际应用场景描述在许多行业(如零售、旅游、物流、电商、教育培训等)中,普遍存在明显的季节性波动:- 旺季:订单/任务激增,员工超负荷加班- 淡季:业务量骤减,人员闲置、工时不足-…...

安全测试人员必备:手把手教你用WePE+Ghost镜像在VMware里快速部署Win7靶机环境
安全测试人员必备:手把手教你用WePEGhost镜像在VMware里快速部署Win7靶机环境 在网络安全学习和渗透测试领域,拥有一个随时可用的标准化测试环境至关重要。对于刚入门的安全研究员、白帽子或需要进行漏洞复现的技术人员来说,Windows 7系统仍然…...

在Windows 10上搞定OpenPCDet:从KITTI数据集训练到自定义数据集的完整避坑指南
在Windows 10上搞定OpenPCDet:从KITTI数据集训练到自定义数据集的完整避坑指南 3D目标检测技术正在重塑自动驾驶、机器人感知等领域的发展格局。作为该领域的重要开源框架,OpenPCDet以其模块化设计和出色的性能表现吸引了大量研究者和开发者。然而&#…...

AntiDupl.NET:高效智能的重复图片检测与清理解决方案
AntiDupl.NET:高效智能的重复图片检测与清理解决方案 【免费下载链接】AntiDupl A program to search similar and defect pictures on the disk 项目地址: https://gitcode.com/gh_mirrors/an/AntiDupl 你是否曾因电脑中堆积如山的重复图片而感到困扰&#…...