Pytorch网络模型训练
现有网络模型的使用与修改
vgg16_false = torchvision.models.vgg16(pretrained=False) # 加载一个未预训练的模型
vgg16_true = torchvision.models.vgg16(pretrained=True)
# 把数据分为了1000个类别print(vgg16_true)以下是vgg16预训练模型的输出
VGG((features): Sequential((0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(1): ReLU(inplace=True)(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(3): ReLU(inplace=True)(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(6): ReLU(inplace=True)(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(8): ReLU(inplace=True)(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(11): ReLU(inplace=True)(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(13): ReLU(inplace=True)(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(15): ReLU(inplace=True)(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(18): ReLU(inplace=True)(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(20): ReLU(inplace=True)(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(22): ReLU(inplace=True)(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(25): ReLU(inplace=True)(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(27): ReLU(inplace=True)(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(29): ReLU(inplace=True)(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False))(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))(classifier): Sequential((0): Linear(in_features=25088, out_features=4096, bias=True)(1): ReLU(inplace=True)(2): Dropout(p=0.5, inplace=False)(3): Linear(in_features=4096, out_features=4096, bias=True)(4): ReLU(inplace=True)(5): Dropout(p=0.5, inplace=False)(6): Linear(in_features=4096, out_features=1000, bias=True))
)预训练模型的输出从1000类别转为10类别
import torchvision
from torch import nn
# 因为数据集过大,所以注释掉此行代码
# train_data = torchvision.datasets.ImageNet("./data_image_net", split='train', download=True,
# transform=torchvision.transforms.ToTensor())vgg16_false = torchvision.models.vgg16(pretrained=False) # 加载一个未预训练的模型
vgg16_true = torchvision.models.vgg16(pretrained=True)
# 把数据分为了1000个类别print(vgg16_true)# vgg16_true.add_module("add_linear", nn.Linear(1000, 10))
vgg16_true.classifier.add_module("add_linear", nn.Linear(1000, 10))
# 在预训练模型的最后添加了一个新的全连接层,用于将最后的输出转化为10个类别
print(vgg16_true)print(vgg16_false)
vgg16_false.classifier[6] = nn.Linear(4096, 10)
# 未预训练模型的最后一层的输出特征数更改为了10
print(vgg16_false)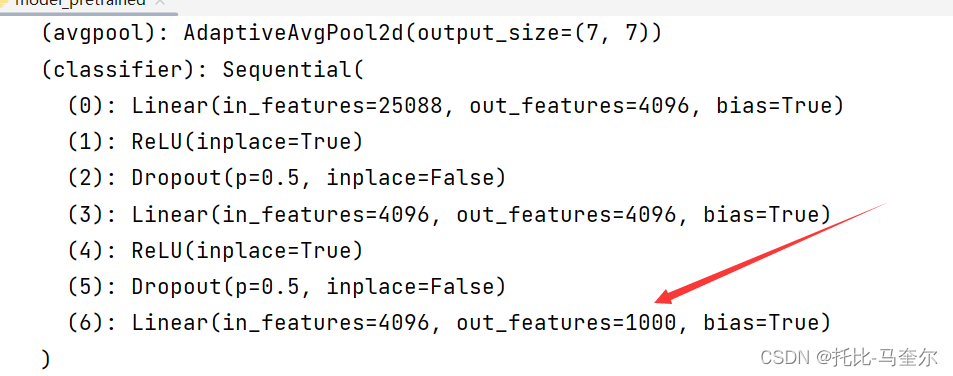
网络模型的保存与读取
加载未预训练的模型
vgg16 = torchvision.models.vgg16(pretrained=False)方式一
# 保存方式1 保存的模型结构+模型参数
torch.save(vgg16, "vgg16_method1.pyth")#读取方式1
model = torch.load("vgg16_method1.pth")方式二
# 保存方式2 不再保存模型结构,而是保存模型的参数为字典结构 推荐
torch.save(vgg16.state_dict(), "vgg16_method2.pyth")# 方式2,加载模型
# model = torch.load("vgg16_method2.pth") #这样输出的是字典类型
# print(model)
vgg16 = torchvision.models.vgg16(pretrained=False)
vgg16.load_state_dict(torch.load("vgg16_method2.pth")) # 将其恢复为网络模型
print(vgg16)完整的模型训练套路
准备数据集
# 准备数据集
train_data = torchvision.datasets.CIFAR10("../data", train=True, transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10("../data", train=False, transform=torchvision.transforms.ToTensor(),download=True)train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集的长度为{}".format(train_data_size)) # 50000
print("测试数据集的长度为{}".format(test_data_size)) # 10000# 利用Dataloader来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)创建网络模型
# 创建网络模型 神经网络的代码在train_module文件
tudui = Tudui()train_module文件
# 搭建神经网络
class Tudui(nn.Module):def __init__(self):super(Tudui, self).__init__()# 简化操作,并且按顺序进行操作self.model1 = Sequential(Conv2d(3, 32, 5, padding=2),MaxPool2d(2),Conv2d(32, 32, 5, padding=2),MaxPool2d(2),Conv2d(32, 64, 5, padding=2),MaxPool2d(2),Flatten(),Linear(1024, 64),Linear(64, 10))def forward(self, x):x = self.model1(x)return x构建损失函数
# 损失函数
loss_fn = nn.CrossEntropyLoss()构建优化器
# 优化器
# 如果学习率过大,模型可能会在最小值附近震荡而无法收敛;如果学习率过小,模型训练可能会过于缓慢
learning_rate = 0.01
# 使用随机梯度下降算法来更新模型的权重
optimizer = torch.optim.SGD(tudui.parameters(), lr=learning_rate)设置训练集参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮数
epoch = 10添加tensorboard
# 将数据写入 TensorBoard 可视化的日志文件中
writer = SummaryWriter("../logs_train")训练步骤
# tudui.train()
for data in train_dataloader:imgs, targets = dataoutputs = tudui(imgs)loss = loss_fn(outputs, targets)# 优化器优化模型optimizer.zero_grad()# 将优化器中的梯度缓存(如果有的话)清零loss.backward()# 计算损失函数(loss)相对于模型参数的梯度optimizer.step()total_train_step = total_train_step + 1if total_train_step % 100 == 0:# .item()是将tensor张量变为正常的数字print("训练次数:{},Loss:{}".format(total_train_step, loss.item()))# loss.item()是当前步骤的损失值writer.add_scalar("train_loss", loss.item(), total_train_step)# 使用add_scalar可以将一个标量添加到之前的所有标量值中,# 这样就可以在TensorBoard中绘制一个标量随时间变化的图表测试步骤

# 测试步骤开始
# tudui.eval()
total_test_loss = 0
total_accuracy = 0
# 不会对以下的代码进行调优
with torch.no_grad():for data in test_dataloader:imgs, targets = dataoutputs = tudui(imgs)loss = loss_fn(outputs, targets)total_test_loss = total_test_loss + loss.item()# argmax(1)是横向看,argmax(0)是纵向看accuracy = (outputs.argmax(1) == targets).sum()# argmax在找到模型预测的最大概率对应的类别# 预测正确的个数total_accuracy = total_accuracy + accuracyprint("整体测试集上的Loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy/test_data_size))
# 测试集上的总损失
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy/test_data_size, total_test_step)
total_test_step = total_test_step + 1利用GPU训练
# 定义训练的设备
# device = torch.device("cpu/cuda")
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# GPU训练的关键
tudui = tudui.cuda()
# tudui = tudui.to(device)相关文章:
Pytorch网络模型训练
现有网络模型的使用与修改 vgg16_false torchvision.models.vgg16(pretrainedFalse) # 加载一个未预训练的模型 vgg16_true torchvision.models.vgg16(pretrainedTrue) # 把数据分为了1000个类别print(vgg16_true) 以下是vgg16预训练模型的输出 VGG((features): S…...
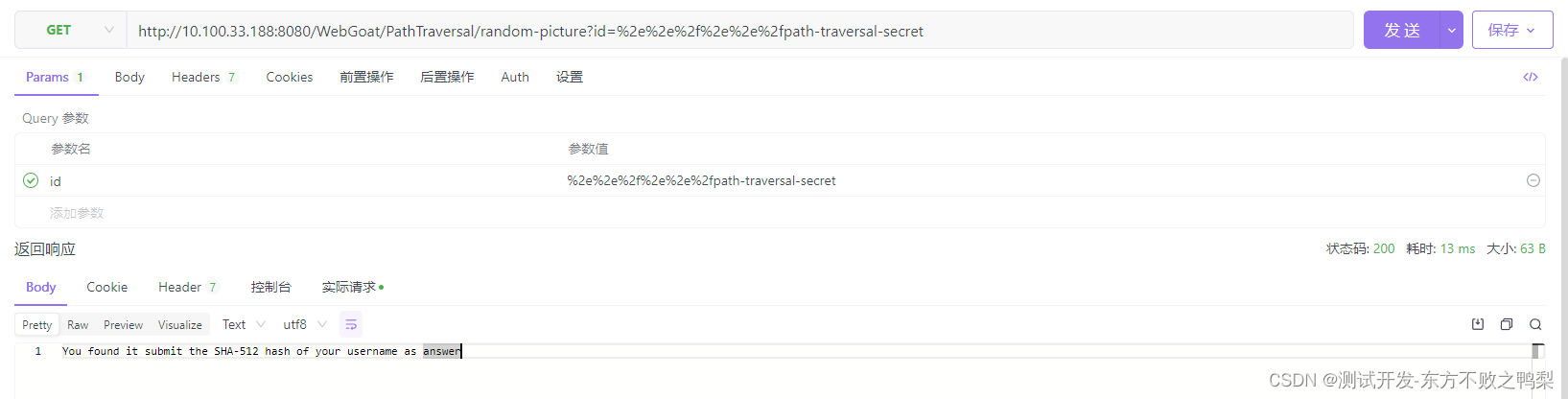
webgoat-Path traversal
Path traversal 路径(目录)遍历是一种漏洞,攻击者能够访问或存储外部的文件和目录 应用程序运行的位置。这可能会导致从其他目录读取文件,如果是文件,则会导致读取文件 上传覆盖关键系统文件。 它是如何工作的&#…...

P8976 「DTOI-4」排列,贪心
题目背景 Update on 2023.2.1:新增一组针对 yuanjiabao 的 Hack 数据,放置于 #21。 Update on 2023.2.2:新增一组针对 CourtesyWei 和 bizhidaojiaosha 的 Hack 数据,放置于 #22。 题目描述 小 L 给你一个偶数 n 和两个整数a,b…...

使用 Python 进行自然语言处理第 5 部分:文本分类
一、说明 关于文本分类,文章已经很多,本文这里有实操代码,明确而清晰地表述这种过程,是实战工程师所可以参照和依赖的案例版本。 本文是 2023 年 1 月的 WomenWhoCode 数据科学跟踪活动提供的会议系列文章中的一篇。 之前的文章在…...

uni-app---- 点击按钮拨打电话功能点击按钮调用高德地图进行导航的功能【安卓app端】
uniapp---- 点击按钮拨打电话功能&&点击按钮调用高德地图进行导航的功能【安卓app端】 先上效果图: 1. 在封装方法的文件夹下新建一个js文件,然后把这些功能进行封装 // 点击按钮拨打电话 export function getActionSheet(phone) {uni.showAct…...

通讯录详解(静态版,动态版,文件版)
💓博客主页:江池俊的博客⏩收录专栏:C语言进阶之路👉专栏推荐:✅C语言初阶之路 ✅数据结构探索✅C语言刷题专栏💻代码仓库:江池俊的代码仓库🎉欢迎大家点赞👍评论&#x…...

在windows中搭建vue开发环境
1.环境搭建 具体环境搭建步骤参考链接 注意该博客中初始化命令: vue init webpack MyPortalProject需改为小写: vue init webpack myportalproject不然会报错 Warning: name can no longer contain capital letters2.创建第一个vueelement ui项目 …...

数字化转型:云表低代码开发助力制造业腾飞
数字化转型已成为制造业不可避免的趋势。为了应对市场快速变化、提高运营效率以及降低成本,制造业企业积极追求更加智能化、敏捷的生产方式。在这个转型过程中,低代码技术作为一种强大的工具,正逐渐崭露头角,有望加速制造业的数字…...

Linux学习之vim跳转到特定行数
参考的博客:《Vim跳到最后一行的方法》 《oeasy教您玩转vim - 14 - # 行头行尾》 《Linux:vim 中跳到首行和最后一行》 想要跳到特定行的话,可以在命令模式和正常模式进行跳转。要是对于vim的四种模式不太熟的话,可以到博客《Linu…...

详解基于Android的Appium+Python自动化脚本编写
📢专注于分享软件测试干货内容,欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!📢交流讨论:欢迎加入我们一起学习!📢资源分享:耗时200小时精选的「软件测试」资…...
【马蹄集】—— 百度之星 2023
百度之星 2023 目录 BD202301 公园⭐BD202302 蛋糕划分⭐⭐⭐BD202303 第五维度⭐⭐ BD202301 公园⭐ 难度:钻石 时间限制:1秒 占用内存:64M 题目描述 今天是六一节,小度去公园玩,公园一共 N N N 个景点&am…...
大数据毕业设计选题推荐-无线网络大数据平台-Hadoop-Spark-Hive
✨作者主页:IT毕设梦工厂✨ 个人简介:曾从事计算机专业培训教学,擅长Java、Python、微信小程序、Golang、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。 ☑文末获取源码☑ 精彩专栏推荐⬇⬇⬇ Java项目 Py…...

【jvm】虚拟机之本地方法接口与本地方法库
目录 一、本地方法1.1 说明1.2 代码示例1.3 为什么要使用native method 二、现状 一、本地方法 1.1 说明 1.一个Native Method就是一个Java调用非Java代码的接口。 2.一个Native Method是这样一个Java方法:该方法的实现由非Java语言实现,比如C。 3.这个…...
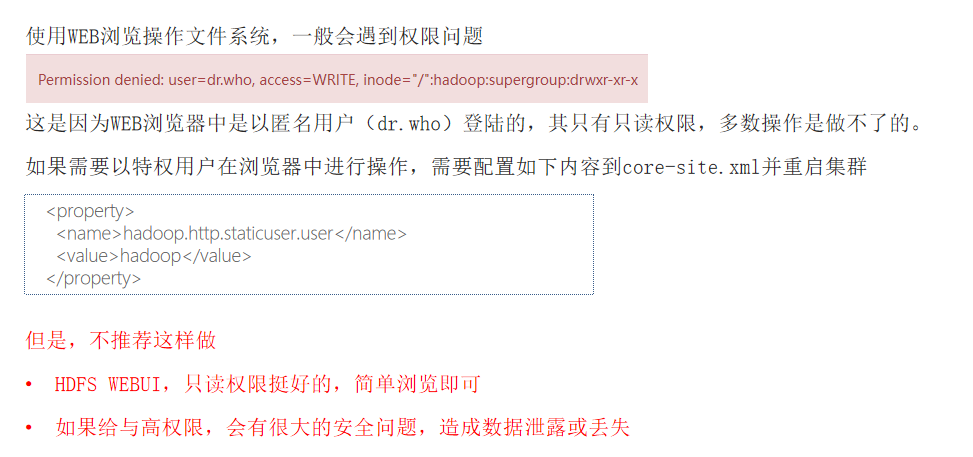
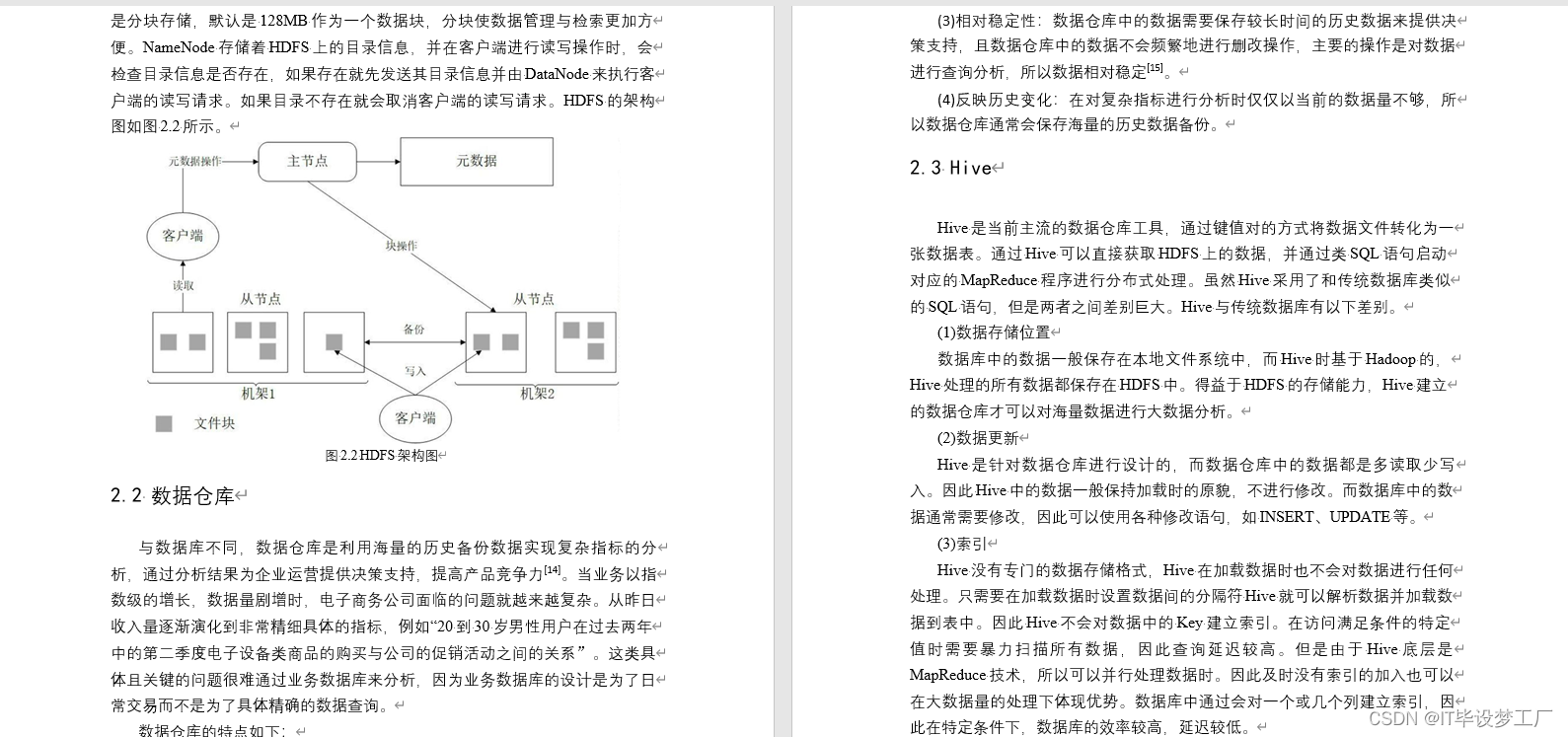
HDFS系统操作命令大全
一,前言 HDFS作为分布式存储的文件系统,有其对数据的路径表达方式 HDFS同linux系统一样,均是以/作为根目录的组织形式 linux:/usr/local/hello.txt HDFS:/usr/local/hello.txt 二,如何区分呢? L…...

雷尼绍探头编程 9810
9810 安全移动 使用参数 参数含义#9移动速度 F#117移动速度 F#148#24X 移动 终点绝对坐标#25Y 移动 终点绝对坐标#26Z 移动 终点绝对坐标#123机床移动到终点的绝对坐标 与 终点的理论值 的 差#5041当前绝对坐标 X 值#5042当前绝对坐标 Y 值#5043当前绝对坐标 Z 值#116刀具…...
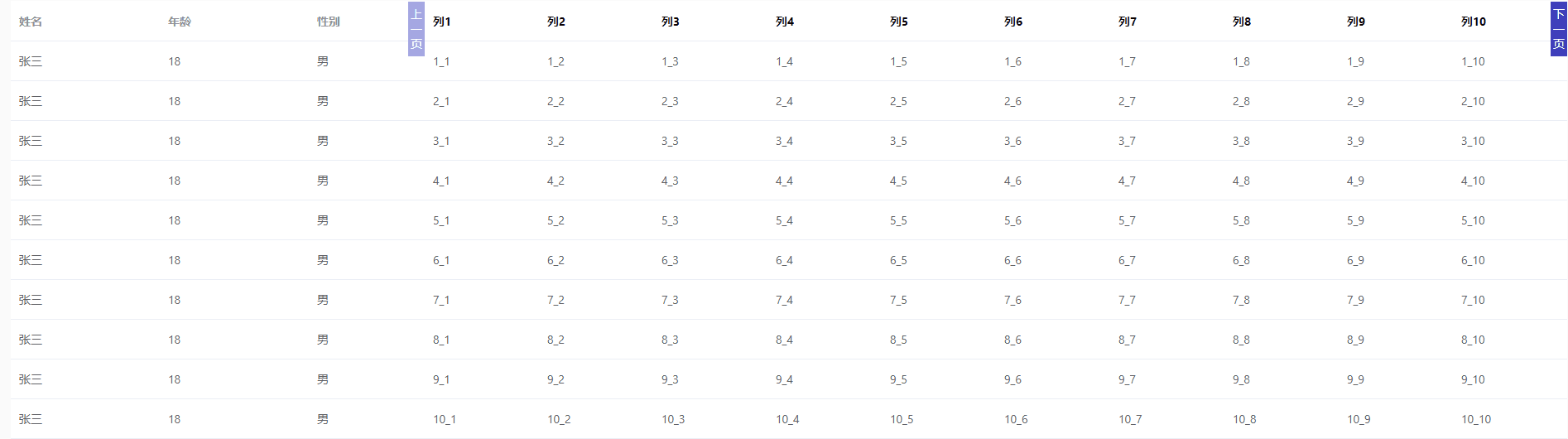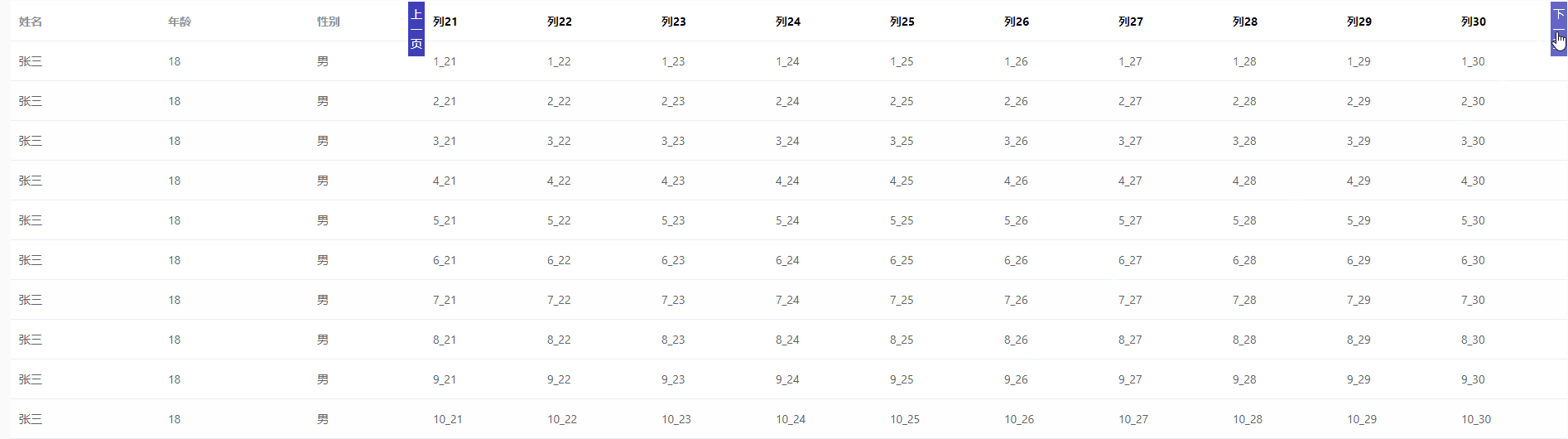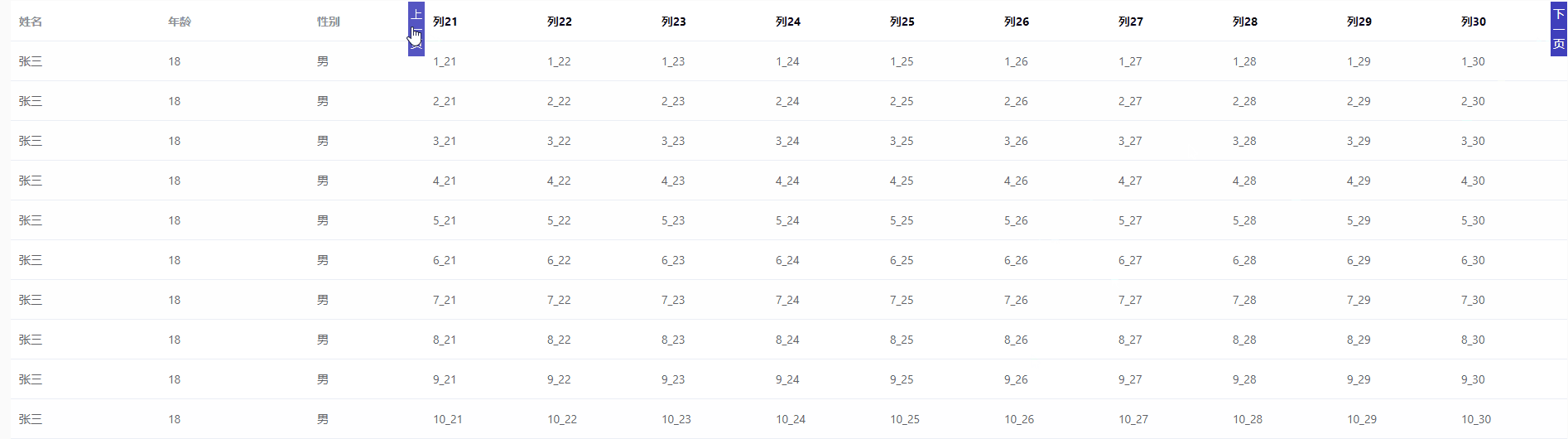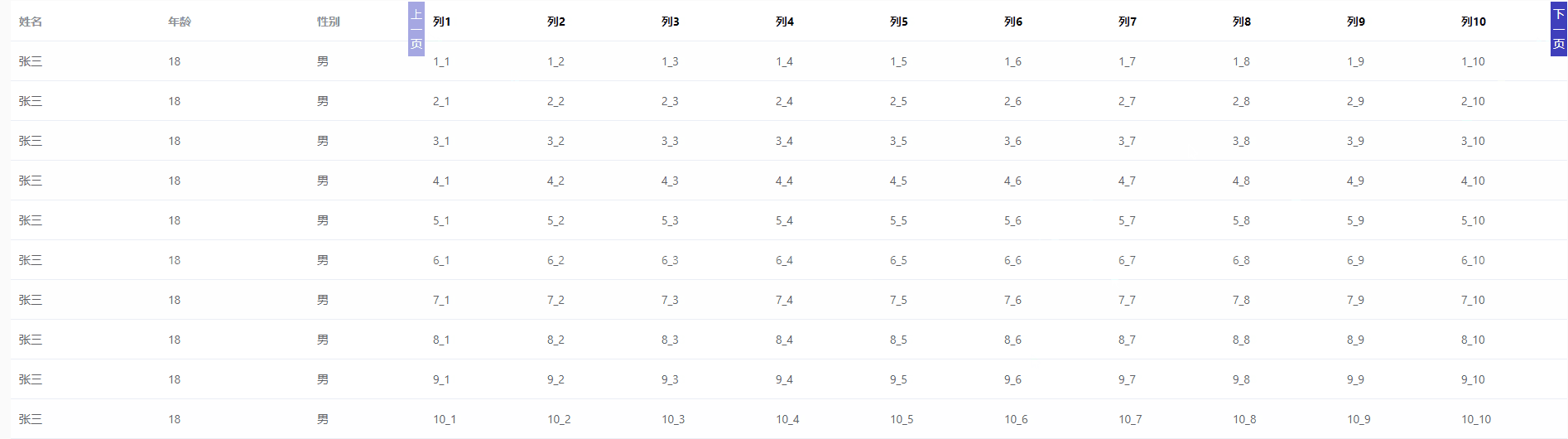
el-table 列分页
<template><div><el-table:data"tableData":key"tampTime"style"width: 100%"><el-table-columnprop"name"label"姓名"width"180"></el-table-column><el-table-columnprop&quo…...

APP攻防--ADB基础
进入app包 先使用 adb devices查看链接状态 手机连接成功的 adb shell 获取到手机的一个shell 此时想进入app包时没有权限的,APP包一般在data/data/下。没有执行权限,如图 Permission denied 权限被拒绝 此时需要手机root,root后输入 su …...
【Linux】第十站:git和gdb的基本使用
文章目录 一、git的基本操作1.gitee新建仓库注意事项2.git的安装3.git的克隆4.git的add5.git的commit6.git的push7.git log8.git status9. .gitignore 二、Linux调试器---gdb1.背景2.gdb安装、进入与退出3.list/l4.r/run运行程序5. break/b 打断点6.info/i b 查看断点7.delete/…...

Single Image Haze Removal Using Dark Channel Prior(暗通道先验)
去雾算法都会依赖于很强的先验以及假设,并结合相应的物理模型,完成去雾过程。本文作者何凯明及其团队通过大量的无雾图像和有雾图像,归纳总结出无雾图像在其对应的暗通道图像上具有极低的强度值(趋近于0),并…...
)
力扣382.链表随机节点(java利用数组随机返回节点值)
Problem: 382. 链表随机节点 文章目录 思路解题方法复杂度Code 思路 注意链表与数组的特性,对于随机访问读取的操作利用数组可以较方便实现,所以我们可以将链表中的节点值先存入到数组中最后再取出随机生成节点位置的值。 解题方法 1.生成List集合与Rand…...

【DeepSeek-R1代码相似度引擎解密】:3层语义比对机制、Token归一化偏差修正与Jaccard阈值黄金分割点
更多请点击: https://kaifayun.com 第一章:DeepSeek代码重复检测 DeepSeek-R1 模型在训练过程中引入了严格的代码去重机制,其核心目标是消除训练语料中语义等价或高度相似的代码片段,从而提升模型对真实编程模式的学习能力与泛化…...

收藏必看|2026 版大厂 AI 岗位薪资曝光!普通程序员转型大模型最全指南
深夜收到大厂 HR 好友发来的内部资料,再三叮嘱切勿对外泄露。如今网络信息传播速度极快,这份 2026 年企业 AI 岗真实薪资内幕,也值得给广大程序员、零基础入行小白参考借鉴。 翻看完整薪资台账后,真切感受到当下大模型赛道的薪资差…...
)
告别外部中断!用EnableInterrupt库轻松搞定Arduino Nano多通道PWM读取(附完整代码)
Arduino Nano多通道PWM读取实战:用EnableInterrupt突破硬件限制当你用Arduino Nano开发四轴飞行器或机器人项目时,是否遇到过这样的尴尬:遥控器的四个通道PWM信号需要同时读取,但Nano只有两个外部中断引脚?这个问题困扰…...
)
Claude端到端测试设计:从零搭建可审计、可回放、可量化的AI服务测试流水线(含开源Schema校验工具)
更多请点击: https://codechina.net 第一章:Claude端到端测试设计 端到端测试是验证Claude模型在真实用户交互链路中行为一致性的关键手段。它覆盖从原始提示输入、上下文管理、流式响应生成,到输出解析与业务校验的全路径,确保模…...

光轮智能 谢晨 访谈总结机器人仿真数据产业
光轮智能 谢晨 访谈总结机器人仿真关于创始人关于数据数据金字塔数据痛点仿真数据的重要性仿真数据的质量b站链接地址公司官网关于创始人 清华物理;哥伦比亚金融;英伟达智驾仿真;小鹏智驾仿真;现为光轮智能CEO 关于数据 数据的…...

关联规则挖掘在Calabi-Yau流形Hodge数分析中的应用与复现
1. 项目概述:当数据挖掘遇见高维几何在理论物理和代数几何的交叉领域,Calabi-Yau流形一直扮演着核心角色。这些具有特殊拓扑结构的空间,不仅是弦理论中额外维度紧化的关键候选者,其本身丰富的数学性质也吸引着无数研究者。然而&am…...

Office RibbonX Editor:简单三步打造你的专属Office界面
Office RibbonX Editor:简单三步打造你的专属Office界面 【免费下载链接】office-ribbonx-editor An overhauled fork of the original Custom UI Editor for Microsoft Office, built with WPF 项目地址: https://gitcode.com/gh_mirrors/of/office-ribbonx-edit…...

观察不同模型在统一 API 下的响应速度与输出风格差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察不同模型在统一 API 下的响应速度与输出风格差异 在为大语言模型应用选择模型时,开发者通常会关注两个核心维度&am…...

Facebook登录协议逆向解析:appsecret_proof与e2e加密机制
1. 这不是“爬虫教程”,而是一次对现代Web身份协议的解剖实验你有没有试过,在调试一个Facebook登录集成时,浏览器Network面板里突然冒出一串带sig、access_token、e2e、c_user的请求,参数长度动辄上千字符,加密方式五花…...

终极指南:5分钟搞定淘宝淘金币全任务自动化脚本
终极指南:5分钟搞定淘宝淘金币全任务自动化脚本 【免费下载链接】taojinbi 淘宝淘金币自动执行脚本,包含蚂蚁森林收取能量,芭芭农场全任务,解放你的双手 项目地址: https://gitcode.com/gh_mirrors/ta/taojinbi 你是否厌倦…...