【3D图像分割】基于Pytorch的VNet 3D 图像分割5(改写数据流篇)
在这篇文章:【3D 图像分割】基于 Pytorch 的 VNet 3D 图像分割2(基础数据流篇) 的最后,我们提到了:
在采用vent模型进行3d数据的分割训练任务中,输入大小是16*96*96,这个的裁剪是放到Dataset类里面裁剪下来的image和mask。但是在训练时候发现几个问题:
- 加载数据耗费了很长时间,从启动训练,到正式打印开始按batch循环,这段时间就有30分钟
batch=64, torch.utils.data.DataLoader里面的num_workers=8,训练总是到8的倍数时候,要停顿较长时间等待- 4个GPU并行训练的,GPU的利用率长时间为0,偶尔会升上去,一瞬间又为0
free -m查看的内存占用,发现buff和cache会逐步飙升,慢慢接近占满。
请问出现这种情况,会是哪里存在问题啊?模型是正常训练和收敛拟合的也比较好,就是太慢了。分析myDataset数据读取的代码,有几个地方可能是较为耗时,和占用内存的地方:
getAnnotations函数,需要从csv文件中获取文件名和结节对应坐标,最后存储为一个字典,这个是始终要占着内存空间的;getNpyFile_Path函数,dataFile_paths和labelFile_paths都需要调用,有些重复了,这部分的占用是可以降低一倍的;get_annos_label函数,也是一样的问题,有些重复了,这部分的占用是可以降低一倍的。
上面这几个函数,都是在类的__init__阶段就完成的,这种多次的循环,可能是在开始batch循环前这部分时间,耗费时间的主要原因;其次,由于重复占用内存,进一步加剧了性能降低,使得后续的训练变的比较慢。
为了解决上面的这些问题,产生了本文2.0 的Dataset数据加载的版本,其最大的改动就是将原本从csv文件获取结节坐标的形式,改为从npy文件中获取。这样,image、mask、Bbox都是一一对应的单个文件了。从后续的实际训练发现,也确实是如此,解决了这个耗时的问题,让训练变的很快。
所以,只要我们将牟定的值进行精简,减少__init__阶段的内存占用,这个问题就应该可以完美解决了。所以,本篇就是遵照这个原则,尽量的在数据预处理阶段,就把能不要的就丢弃,只留下最简单的一一结构。将预处理前置,避免在构建数据阶段调用。
LUNA16数据的预处理,可以参照这里,本篇就是通过这里方式,产生的数据,如下:
- 【3D 图像分割】基于 Pytorch 的 VNet 3D 图像分割6(数据预处理)
- 【3D 图像分割】基于 Pytorch 的 VNet 3D 图像分割7(数据预处理)
- 【3D 图像分割】基于 Pytorch 的 VNet 3D 图像分割8(CT肺实质分割)
- 【3D 图像分割】基于 Pytorch 的 VNet 3D 图像分割9(patch 的 crop 和 merge 操作)
一、搭设数据流框架
在pytorch中,构建训练用的数据流,都遵循下面这样一个结构。其中主要的思路是这样的:
- 在
__init__中,是类初始化阶段,就执行的。在这里需要牟定某个值,将训练需要的内容,都获取到,但尽量少的占用内容和花费时间; - 在
__getitem__中,会根据__init__牟定的那个值,获取到一个图像和标签信息,读取和增强等等操作,最后返回Tensor值; __len__返回的是一个epoch训练牟定值的长度。
下面就是一个简易的框架结构,留作参考,后续的构建数据流,都可以对这里补充。
class myDataset_v3(Dataset):def __init__(self, data_dir, isTrain=True):self.data = []if isTrain:self.data ···else:self.data ···def __len__(self):return len(self.data)def __getitem__(self, index):# ********** get file dir **********image, label = self.data[index] # get whole data for one subject# ********** change data type from numpy to torch.Tensor **********image = torch.from_numpy(image).float() label = torch.from_numpy(label).float() return image, label
在这篇文章中,对这个类里面的参数,进行了详细的介绍,感兴趣的可以直达去学习:【BraTS】Brain Tumor Segmentation 脑部肿瘤分割3(构建数据流)
二、完善框架内容
相信通过前面6、7、8、9四篇博客的介绍,你已经将Luna16的原始数据集,处理成了一一对应的,我们训练所需要的数据形式,包括:
_bboxes.npy:记录了结节中心点的坐标和半径;_clean.nrrd:CT原始图像数组;_mask.nrrd:标注文件mask数组,和_clean.nrrd的shape一样;
还包括一些其他的.npy,记录的都是整个变换阶段的一些量,在训练阶段是使用不到的,这里就不展开了。最最关注的就是上面三个文件,并且是根据seriesUID一一对应的。
如果是这样的数据情况下,我们构建myDataset_v3(Dataset)数据量,思考:在__init__阶段,可以以哪个为锚点,尽量少占用内存的情况下,将所需要的图像、标注信息都可以在__getitem__阶段,依次获取到呢?
那就是seriesUID的文件名。他是可以一拖三的,并且一个列表就可以了,这样是最节省内存的方式。于是我们在__init__阶段的定义如下:
class myDataset_v3(Dataset):def __init__(self, data_dir, crop_size=(16, 96, 96), isTrain=False):self.bboxesFile_path = []for file in os.listdir(data_dir):if '_bboxes.npy' in file:self.bboxesFile_path.append(os.path.join(data_dir, file))self.crop_size = crop_sizeself.crop_size_z, self.crop_size_h, self.crop_size_w = crop_sizeself.isTrain = isTrain
然后在__len__的定义,就自然而然的知道了,如下:
def __len__(self):return len(self.bboxesFile_path)
最为重要,且最难的,也就是__getitem__的定义,在这里需要做一下几件事情:
- 获取各个文件的路径;
- 获取文件对应的数据;
- 裁剪出目标
patch; - 数组转成
Tensor。
然后,在定义__getitem__中,就发现了问题,如下:
def __getitem__(self, index):bbox_path = self.bboxesFile_path[index]img_path = bbox_path.replace('_bboxes.npy', '_clean.nrrd')label_path = bbox_path.replace('_bboxes.npy', '_mask.nrrd')img, img_shape = self.load_img(img_path)label = self.load_mask(label_path)zyx_centerCoor = self.getBboxes(bbox_path)def getBboxes(self, bboxFile_path):bboxes_array = np.load(bboxFile_path, allow_pickle=True)bboxes_list = bboxes_array.tolist()xyz_list = [[zyx[0], zyx[2], zyx[1]] for zyx in bboxes_list]return random.choice(xyz_list)
主要是因为一个_bboxes.npy记录的结节坐标点,并不只有一个结节。如果将获取bbox的放到__getitem__,就会发现他一次只能裁剪出一个patch,就不可能对多个结节的情况都处理到。所以我这里采用了random.choice的方式,随机的选择一个结节。
但是,这种方式是不好的,因为他会降低结节在学习过程中出现的次数,尽管是随机的,但是相当于某些类型的数据量变少了。同样学习的epoch次数下,那些只有一个结节的,就被学习的次数相对变多了。
为了解决这个问题,直接将结节数与文件名一一对应起来,这样对于每一个结节来说,机会都是均等的了。代码如下所示:
import os
import random
import numpy as np
import matplotlib.pyplot as plt
from tqdm import tqdm
import torch
from torch.utils.data import Dataset
import nrrd
import cv2class myDataset_v3(Dataset):def __init__(self, data_dir, crop_size=(16, 96, 96), isTrain=False):self.dataFile_path_bboxes = []for file in os.listdir(data_dir):if '_bboxes.npy' in file:one_path_bbox_list = self.getBboxes(os.path.join(data_dir, file))self.dataFile_path_bboxes.extend(one_path_bbox_list)self.crop_size = crop_sizeself.crop_size_z, self.crop_size_h, self.crop_size_w = crop_sizeself.isTrain = isTraindef __getitem__(self, index):bbox_path, zyx_centerCoor = self.dataFile_path_bboxes[index]img_path = bbox_path.replace('_bboxes.npy', '_clean.nrrd')label_path = bbox_path.replace('_bboxes.npy', '_mask.nrrd')img, img_shape = self.load_img(img_path)# print('img_shape:', img_shape)label = self.load_mask(label_path)# print('zyx_centerCoor:', zyx_centerCoor)cutMin_list = self.getCenterScope(img_shape, zyx_centerCoor)if self.isTrain:rd = random.random()if rd > 0.5:cut_list = [cutMin_list[0], cutMin_list[0]+self.crop_size_z, cutMin_list[1], cutMin_list[1]+self.crop_size_h, cutMin_list[2], cutMin_list[2]+self.crop_size_w] ### z,y,xstart1, start2, start3 = self.random_crop_around_nodule(img_shape, cut_list, crop_size=self.crop_size, leftTop_ratio=0.3)elif rd > 0.1:start1, start2, start3 = self.random_crop_negative_nodule(img_shape, crop_size=self.crop_size)else:start1, start2, start3 = cutMin_listelse:start1, start2, start3 = cutMin_listimg_crop = img[start1:start1 + self.crop_size_z, start2:start2 + self.crop_size_h,start3:start3 + self.crop_size_w]label_crop = label[start1:start1 + self.crop_size_z, start2:start2 + self.crop_size_h,start3:start3 + self.crop_size_w]# print('before:', img_crop.shape, label_crop.shape)# 计算需要pad的大小if img_crop.shape != self.crop_size:pad_width = [(0, self.crop_size_z-img_crop.shape[0]), (0, self.crop_size_h-img_crop.shape[1]), (0, self.crop_size_w-img_crop.shape[2])]img_crop = np.pad(img_crop, pad_width, mode='constant', constant_values=0)if label_crop.shape != self.crop_size:pad_width = [(0, self.crop_size_z-label_crop.shape[0]), (0, self.crop_size_h-label_crop.shape[1]), (0, self.crop_size_w-label_crop.shape[2])]label_crop = np.pad(label_crop, pad_width, mode='constant', constant_values=0)# print('after:', img_crop.shape, label_crop.shape)img_crop = np.expand_dims(img_crop, 0) # (1, 16, 96, 96)img_crop = torch.from_numpy(img_crop).float()label_crop = torch.from_numpy(label_crop).long() # (16, 96, 96) label不用升通道维度return img_crop, label_cropdef __len__(self):return len(self.dataFile_path_bboxes)def load_img(self, path_to_img):if path_to_img.startswith('LKDS'):img = np.load(path_to_img)else:img, _ = nrrd.read(path_to_img)img = img.transpose((0, 2, 1)) # 与xyz坐标变换对应return img/255.0, img.shapedef load_mask(self, path_to_mask):mask, _ = nrrd.read(path_to_mask)mask[mask>1] = 1mask = mask.transpose((0, 2, 1)) # 与xyz坐标变换对应return maskdef getBboxes(self, bboxFile_path):bboxes_array = np.load(bboxFile_path, allow_pickle=True)bboxes_list = bboxes_array.tolist()one_path_bbox_list = []for zyx in bboxes_list:xyz = [zyx[0], zyx[2], zyx[1]]one_path_bbox_list.append([bboxFile_path, xyz])return one_path_bbox_listdef getCenterScope0(self, img_shape, zyx_centerCoor):cut_list = [] # 切割需要用的数for i in range(len(img_shape)): # 0, 1, 2 → z,y,xif i == 0: # za = zyx_centerCoor[-i - 1] - self.crop_size_z/2 # zb = zyx_centerCoor[-i - 1] + self.crop_size_z/2 # y,zelse: # y, xa = zyx_centerCoor[-i - 1] - self.crop_size_w/2b = zyx_centerCoor[-i - 1] + self.crop_size_w/2# 超出图像边界 1if a < 0:a = self.crop_size_zb = self.crop_size_w# 超出边界 2elif b > img_shape[i]:if i == 0:a = img_shape[i] - self.crop_size_zb = img_shape[i]else:a = img_shape[i] - self.crop_size_wb = img_shape[i]else:passcut_list.append(int(a))cut_list.append(int(b))return cut_listdef getCenterScope(self, img_shape, zyx_centerCoor):img_z, img_y, img_x = img_shapezc, yc, xc = zyx_centerCoorzmin = max(0, zc - self.crop_size_z // 3)ymin = max(0, yc - self.crop_size_h // 2)xmin = max(0, xc - self.crop_size_w // 2)cutMin_list = [int(zmin), int(ymin), int(xmin)]return cutMin_listdef random_crop_around_nodule(self, img_shape, cut_list, crop_size=(16, 96, 96), leftTop_ratio=0.3):""":param img::param label::param center::param radius::param cut_list::param crop_size::param leftTop_ratio: 越大,阴性样本越多(需要考虑crop_size):return:"""img_z, img_y, img_x = img_shapecrop_z, crop_y, crop_x = crop_sizez_min, z_max, y_min, y_max, x_min, x_max = cut_list# print('z_min, z_max, y_min, y_max, x_min, x_max:', z_min, z_max, y_min, y_max, x_min, x_max)z_min = max(0, int(z_min-crop_z*leftTop_ratio))z_max = min(img_z, int(z_min + crop_z*leftTop_ratio))y_min = max(0, int(y_min-crop_y*leftTop_ratio))y_max = min(img_y, int(y_min+crop_y*leftTop_ratio))x_min = max(0, int(x_min-crop_x*leftTop_ratio))x_max = min(img_x, int(x_min+crop_x*leftTop_ratio))z_start = random.randint(z_min, z_max)y_start = random.randint(y_min, y_max)x_start = random.randint(x_min, x_max)return z_start, y_start, x_startdef random_crop_negative_nodule(self, img_shape, crop_size=(16, 96, 96), boundary_ratio=0.5):img_z, img_y, img_x = img_shapecrop_z, crop_y, crop_x = crop_sizez_min = 0#crop_z*boundary_ratioz_max = img_z-crop_z#img_z - crop_z*boundary_ratioy_min = 0#crop_y*boundary_ratioy_max = img_y-crop_y#img_y - crop_y*boundary_ratiox_min = 0#crop_x*boundary_ratiox_max = img_x-crop_x#img_x - crop_x*boundary_ratioz_start = random.randint(z_min, z_max)y_start = random.randint(y_min, y_max)x_start = random.randint(x_min, x_max)return z_start, y_start, x_start
上述就是本次改写后新的数据流完整代码,没有加入数据增强的操作。在训练时,引入了三种多样性:
- 确保
mask有结节目标的情况下,随机的变换结节在patch中的位置; - 全图随机的进行裁剪,主要是产生负样本;
- 直接使用结节为中心点的方式进行裁剪。
这样做的目的,其实是考虑到结节在patch中的位置,可能会影响到最终的预测。因为最后我们在使用的推理阶段,其实是不知道结节在图像中的哪个位置的,只能遍历所有的patch,然后再将预测的结果拼接成一个完整的mask,进而对mask的处理,知道了所有结节的位置。
这就要求结节无论是出现在图像中的任何位置,都需要找到他,并且尽量少的假阳性。
这块是很少看到论文涉及到的内容,我不清楚是不是论文只关于了指标,而忘记了假阳性这样一个附加产物。还有就是这些patch的获取方式,是预先裁剪下来,直接读取patch数组的形式,进行训练的。这种也不好,多样性不够,还比较的麻烦。
这一小节还要讲的,就是getCenterScope和random_crop_around_nodule两个函数。getCenterScope中为什么整除3,是因为多次查看,总结出来的。如果是整除2,就发现所有的结节,都偏下,这点的原因,还没有想明白。知道的求留言。
如果是一个二维的平面,已知中心点,那么找到左上角的最小值,那就应该是中心点坐标,减去二分之一的宽高。但是,在z轴也采用减去二分之一的,发现所有裁剪出来的结节就很靠下。

所以,这里采用了减去三分之一,让他在z轴上,往上移动了一点。这里的疑问还没有搞明白,知道的评论区求指教。
random_crop_around_nodule是控制了裁剪左上角最小值和最大值的坐标,在这个区间内随机的确定,进而使得结节的裁剪,更加的多样性。如下图所示:
我只要想让每一次的裁剪都有结节在,只需要结节左上角的坐标,落在一定的区间内即可。leftTop_ratio参数,就是用于控制左上角的点,远离左上角的距离。
这个值需要自己根据patch的大小自己决定,多次查看很重要。
三、验证数据流
构建好数据量的类函数,还不能算完。因为你不知道此时的数据流,是不是符合你要求的。所以如果能够模拟训练过程,提前看看每一个patch的结果,那就再好不过了。
本章节就是这个目的,我们把图像和mask通通打出来看看,这样就知道是否存在问题了。查看的方法也比较的简单,可以抄过去用到之后自己的项目里。
def getContours(output):img_seged = output.numpy().astype(np.uint8)img_seged = img_seged * 255# ---- Predict bounding box results with txt ----kernel = np.ones((5, 5), np.uint8)img_seged = cv2.dilate(img_seged, kernel=kernel)_, img_seged_p = cv2.threshold(img_seged, 127, 255, cv2.THRESH_BINARY)try:_, contours, _ = cv2.findContours(np.uint8(img_seged_p), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)except:contours, _ = cv2.findContours(np.uint8(img_seged_p), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)return contoursif __name__=='__main__':data_dir = r"./valid"dataset_valid = myDataset_v3(data_dir, crop_size=(48, 96, 96), isTrain=False) # 送入datasetvalid_loader = torch.utils.data.DataLoader(dataset_valid, # 生成dataloaderbatch_size=1, shuffle=False,num_workers=0) # 16) # 警告页面文件太小时可改为0print("valid_dataloader_ok")print(len(valid_loader))for batch_index, (data, target) in tqdm(enumerate(valid_loader)):name = dataset_valid.dataFile_path_bboxes[batch_index]print('name:', name)print('image size ......')print(data.shape) # torch.Size([batch, 1, 16, 96, 96])print('label size ......')print(target.shape) # torch.Size([2])# 按着batch进行显示for i in range(data.shape[0]):onePatch = data[i, 0, :, :]onePatch_target = target[0, :, :, :]print('one_patch:', onePatch.shape, np.max(onePatch.numpy()), np.min(onePatch.numpy()))fig, ax = plt.subplots(6, 8, figsize=[14, 16])for i in range(6):for j in range(8):one_pic = onePatch[i * 4 + j]img = one_pic.numpy()*255.0# print('one_pic img:', one_pic.shape, np.max(one_pic.numpy()), np.min(one_pic.numpy()))one_mask = onePatch_target[i * 4 + j]contours = getContours(one_mask)for contour in contours:x, y, w, h = cv2.boundingRect(contour)xmin, ymin, xmax, ymax = x, y, x + w, y + h# print('contouts:', xmin, ymin, xmax, ymax)cv2.drawContours(img, contour, -1, (0, 0, 255), 2)# cv2.rectangle(img, (int(xmin), int(ymin)), (int(xmax), int(ymax)), (0, 0, 255),# thickness=1)ax[i, j].imshow(img, cmap='gray')ax[i, j].axis('off')# print('one_target:', onePatch.shape, np.max(onePatch.numpy()), np.min(onePatch.numpy()))fig, ax = plt.subplots(6, 8, figsize=[14, 16])for i in range(6):for j in range(8):one_pic = onePatch_target[i * 4 + j]# print('one_pic mask:', one_pic.shape, np.max(one_pic.numpy()), np.min(one_pic.numpy()))ax[i, j].imshow(one_pic, cmap='gray')ax[i, j].axis('off')plt.show()
显示出来的图像如下所示:

你可以多看几张,看的多了,也就顺便给验证了结节裁剪的是否有问题。同时,也可以采用训练模型,看看在训练情况下,阳性带结节的样本,和全是黑色的,没有结节的样本占到多少。这也为我们改上面的代码,提供了参考标准。
四、总结
本文其实是对前面博客数据流问题的一个总结,和找到解决问题的方法了。同时将一个验证数据量的过程给展示了出来,方便我们后续更多的其他任务,都是很有好处的。
如果你是一名初学者,我相信该收获满满。如果你是奔着项目来的,那肯定也找到了思路。数据集的差异,主要体现在前处理上,而到了训练阶段,本篇可以帮助你快速的动手。
最后,留下你的点赞和收藏。如果有问题,欢迎评论和私信。后续会将训练和验证的代码进行介绍,这部分同样是重点。
相关文章:
【3D图像分割】基于Pytorch的VNet 3D 图像分割5(改写数据流篇)
在这篇文章:【3D 图像分割】基于 Pytorch 的 VNet 3D 图像分割2(基础数据流篇) 的最后,我们提到了: 在采用vent模型进行3d数据的分割训练任务中,输入大小是16*96*96,这个的裁剪是放到Dataset类…...
【漏洞复现】Apache_Shiro_1.2.4_反序列化漏洞(CVE-2016-4437)
感谢互联网提供分享知识与智慧,在法治的社会里,请遵守有关法律法规 文章目录 1.1、漏洞描述1.2、漏洞等级1.3、影响版本1.4、漏洞复现1、基础环境2、漏洞分析3、漏洞验证 说明内容漏洞编号CVE-2016-4437漏洞名称Apache_Shiro_1.2.4_反序列化漏洞漏洞评级…...

Mac连接linux的办法(自带终端和iterm2)
1. 使用Mac自带终端Terminal 1.1 点击右上角的聚焦搜索,再输入终端 1.2 查找linux系统的ip地址 在虚拟机里输入如下命令,找到蓝色区域的就是ip地址 ip addr 如果没有显示ip地址,可以重新安装一下虚拟机,之后确保以太网的连接是打…...
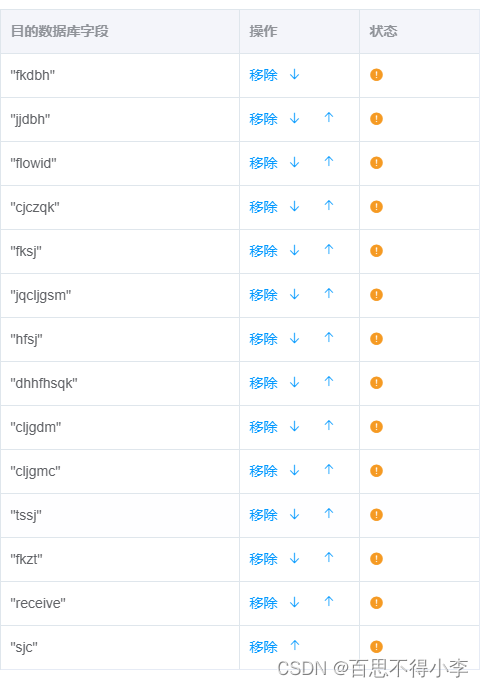
js调整table表格上下相邻元素顺序
有时候我们会遇到要通过箭头控制table表格上下顺序的需求,如下: 点击向下就将该元素下移一位,下面的一位元素就移上来,点击向上就将该元素上移一位,上面的一位元素就移下来,也就是相邻元素互换位置顺序: <el-table :data="targetTable" border style=&quo…...
基于ruoyi框架项目-部署到服务器上
基于ruoyi框架项目-部署到服务器上 文章目录 基于ruoyi框架项目-部署到服务器上1.前端vue编译,后的dist下内容打包(前后端分离版本需要)2.后端打包成jar包(如果是thymeleaf仅需打包jar)3.上传到服务器目录下4. docker部…...
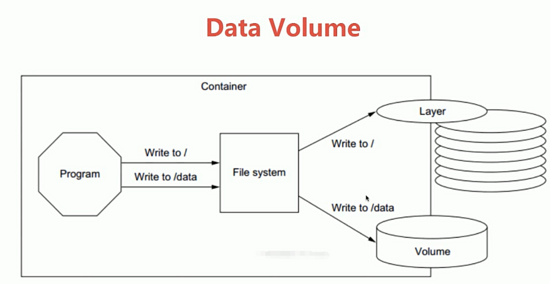
Docker 持久化存储和数据共享_Volume
有些容器会自动产生一些数据,为了不让数据随着 container 的消失而消失,保证数据的安全性。例如:数据库容器,数据表的表会产生一些数据,如果我把 container 给删除,数据就丢失。为了保证数据不丢失…...

万宾科技智能井盖监测仪器助力建设数字化城市
市政公共设施建设在近几年来发展迅速,市政设备的更新换代,资产管理等也成为其中的重要一项。在市政设施建设过程中,井盖也是不可忽视的,一方面,根据传统的管理井盖模式来讲,缺乏有效的远程监控管理方法和手…...
第十一章《搞懂算法:聚类是怎么回事》笔记
聚类是机器学习中一种重要的无监督算法,可以将数据点归结为一系列的特定组合。归为一类的数据点具有相同的特性,而不同类别的数据点则具有各不相同的属性。 11.1 聚类算法介绍 人们将物理或抽象对象的集合分成由类似 的对象组成的多个类的过程被称为聚…...
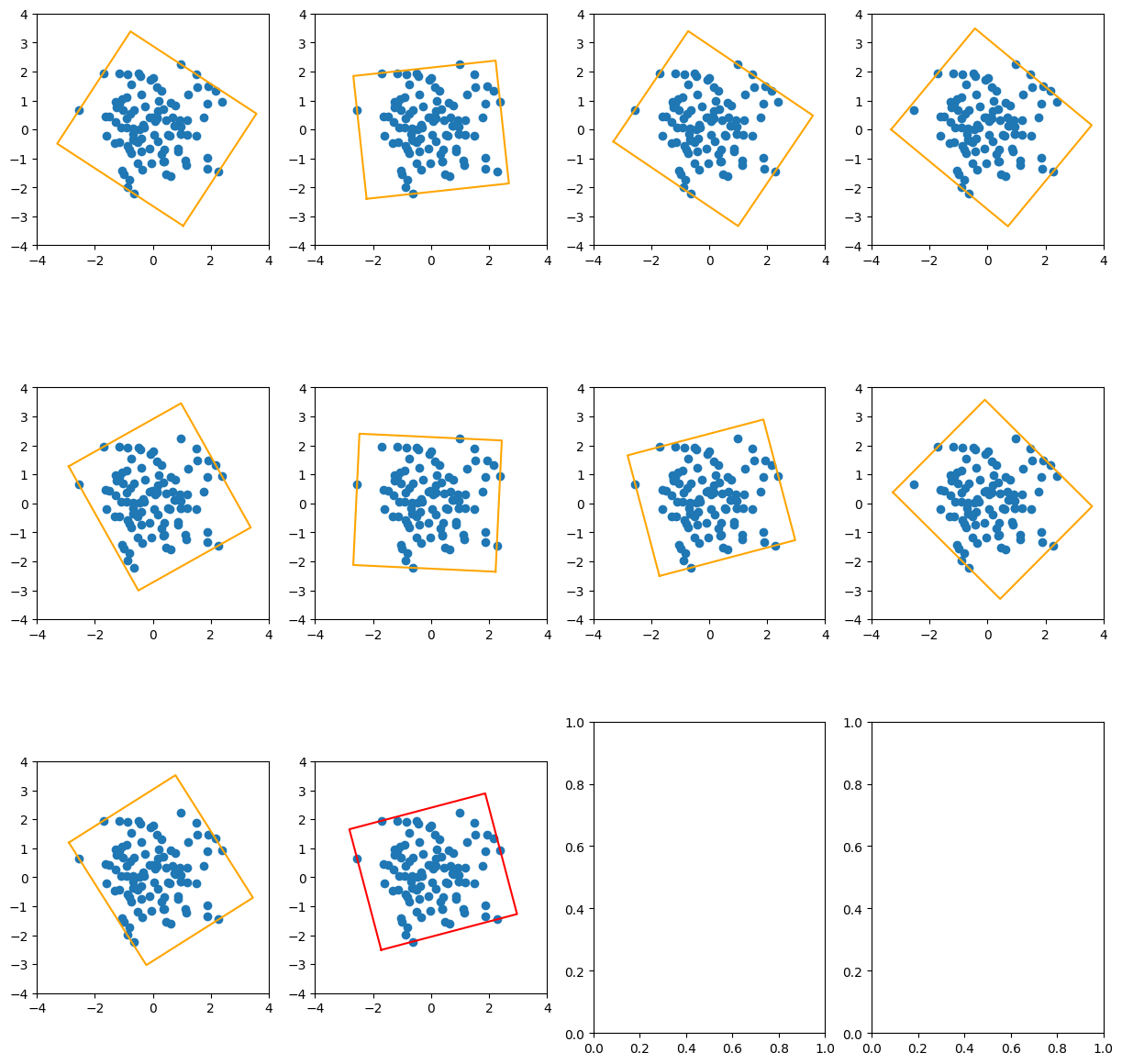
给定n个点或一个凸边形,求其最小外接矩形,可视化
这里写目录标题 原理代码 原理 求n个点的最小外接矩形问题可以等价为先求这n个点的凸包,再求这个凸包的最小外接矩形。 其中求凸包可以使用Graham-Scan算法 需要注意的是, 因为Graham-Scan算法要求我们从先找到凸包上的一个点,所以我们可以先…...

蓝桥杯每日一题2023.11.6
取位数 - 蓝桥云课 (lanqiao.cn) 题目描述 题目分析 由题意我们知道len中为现阶段长度,如果其与k相等也就是找到了正确的位数,否则就调用递归来进行搜索,每次搜索一位数。 #include <stdio.h> // 求x用10进制表示时的数位长度 int …...
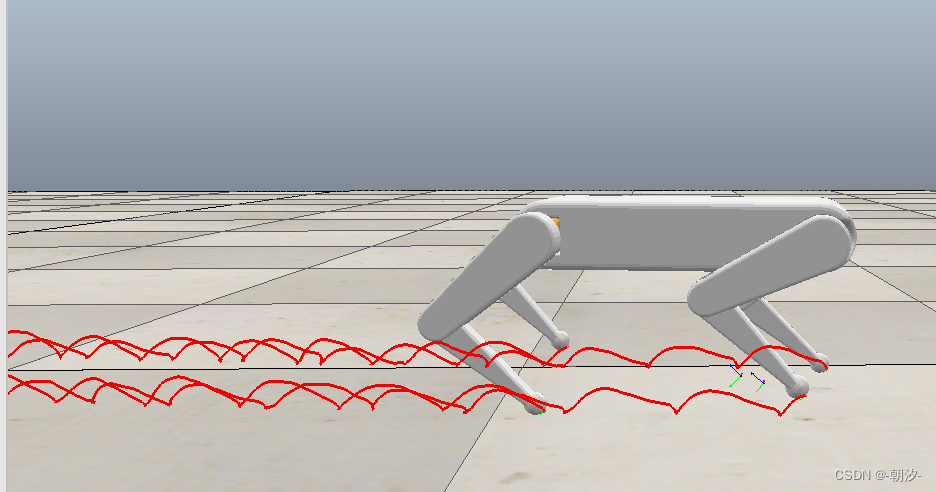
V-REP和Python的联合仿真
机器人仿真软件 各类免费的的机器人仿真软件优缺点汇总_robot 仿真 软件收费么_dyannacon的博客-CSDN博客 课程地址 https://class.guyuehome.com/p/t_pc/course_pc_detail/column/p_605af87be4b007b4183a42e7 课程资料 guyueclass: 古月学院课程代码 旋转变换 旋转的左乘与…...

WPF布局控件之DockPanel布局
前言:博主文章仅用于学习、研究和交流目的,不足和错误之处在所难免,希望大家能够批评指出,博主核实后马上更改。 概述: DockPanel 位置子控件基于子 Dock 属性,你有 4 个选项停靠,左 (默认) &…...
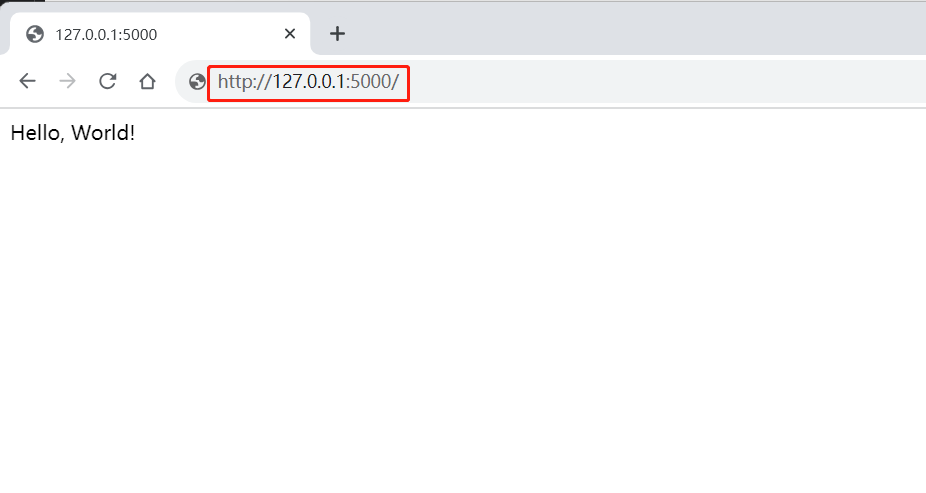
【实战Flask API项目指南】之二 Flask基础知识
实战Flask API项目指南之 Flask基础知识 本系列文章将带你深入探索实战Flask API项目指南,通过跟随小菜的学习之旅,你将逐步掌握Flask 在实际项目中的应用。让我们一起踏上这个精彩的学习之旅吧! 前言 当小菜踏入Flask后端开发的世界&…...
C++链接库std::__cxx11::basic_string和std::__1::basic_string链接问题总结)
Linux 编译链接那些事儿(02)C++链接库std::__cxx11::basic_string和std::__1::basic_string链接问题总结
1 问题背景说明 在自己的项目源码中引用libeasysqlite.so时编译成功,但运行时遇到问题直接报错,找不到符号 symbol:_ZN3sql5FieldC1ENSt3__112basic_stringIcNS1_11char_traitsIcEENS1_9allocatorIcEEEENS_10field_typeEi。 2 问题描述和解…...
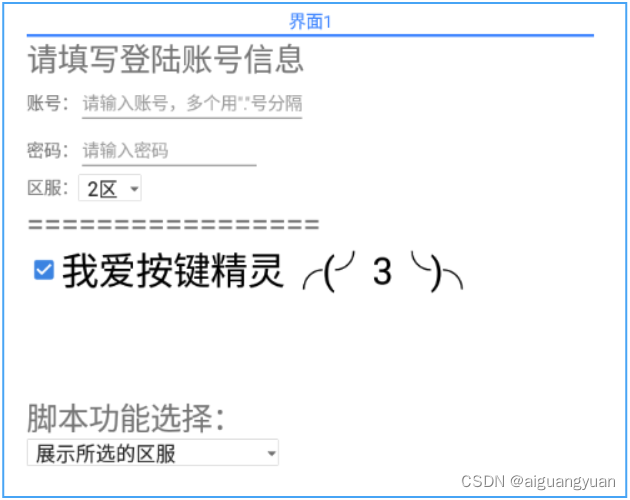
按键精灵中的UI界面操作
1. 按键精灵中UI界面常用的控件 1. 文字框 界面1: {标签页1:{文字框:{名称:"文字框1",显示内容:"显示内容",文字大小:0,高度:0,宽度:0,注释:"文字大小、高度、宽度是可选属性,如需使用默认值,可保持值为0或直接删除此属性&qu…...

dpdk 程序如何配置网卡收发包队列描述符配置?
问题描述 dpdk 程序在配置网卡队列时会涉及收发包队列描述符数量配置问题,收发包描述符的数量看似是一个简单的配置,却对转发性能有着一定的影响。实际业务程序中,收发包描述符大小配置一般参考 dpdk 内部示例程序配置进行,经验之…...

二蛋赠书七期:《云原生数据中台:架构、方法论与实践》
前言 大家好!我是二蛋,一个热爱技术、乐于分享的工程师。在过去的几年里,我一直通过各种渠道与大家分享技术知识和经验。我深知,每一位技术人员都对自己的技能提升和职业发展有着热切的期待。因此,我非常感激大家一直…...
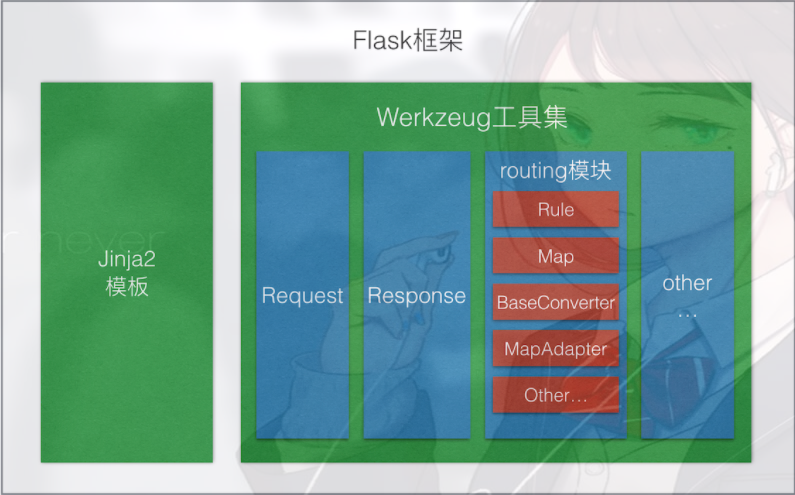
计算机毕设 基于大数据的服务器数据分析与可视化系统 -python 可视化 大数据
文章目录 0 前言1 课题背景2 实现效果3 数据收集分析过程**总体框架图****kafka 创建日志主题****flume 收集日志写到 kafka****python 读取 kafka 实时处理****数据分析可视化** 4 Flask框架5 最后 0 前言 🔥 这两年开始毕业设计和毕业答辩的要求和难度不断提升&a…...
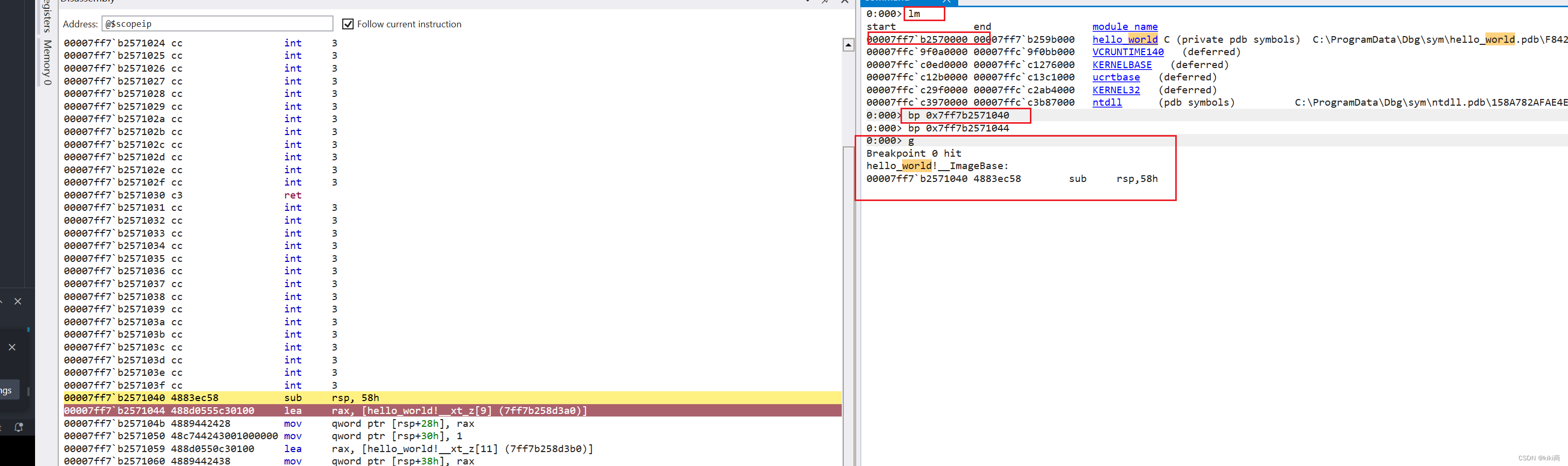
初识rust
调试下rust 的执行流程 参考: 认识 Cargo - Rust语言圣经(Rust Course) 新建一个hello world 程序: fn main() {println!("Hello, world!"); }用IDA 打开exe,并加载符号: 根据字符串找到主程序入口: 双击…...
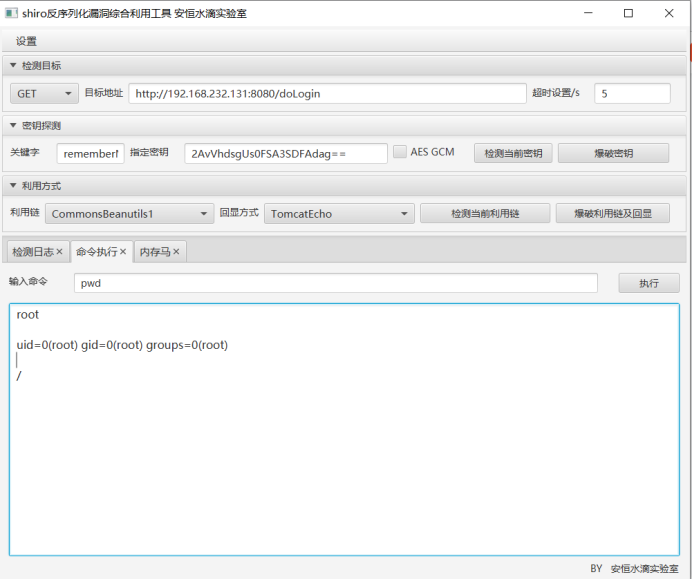
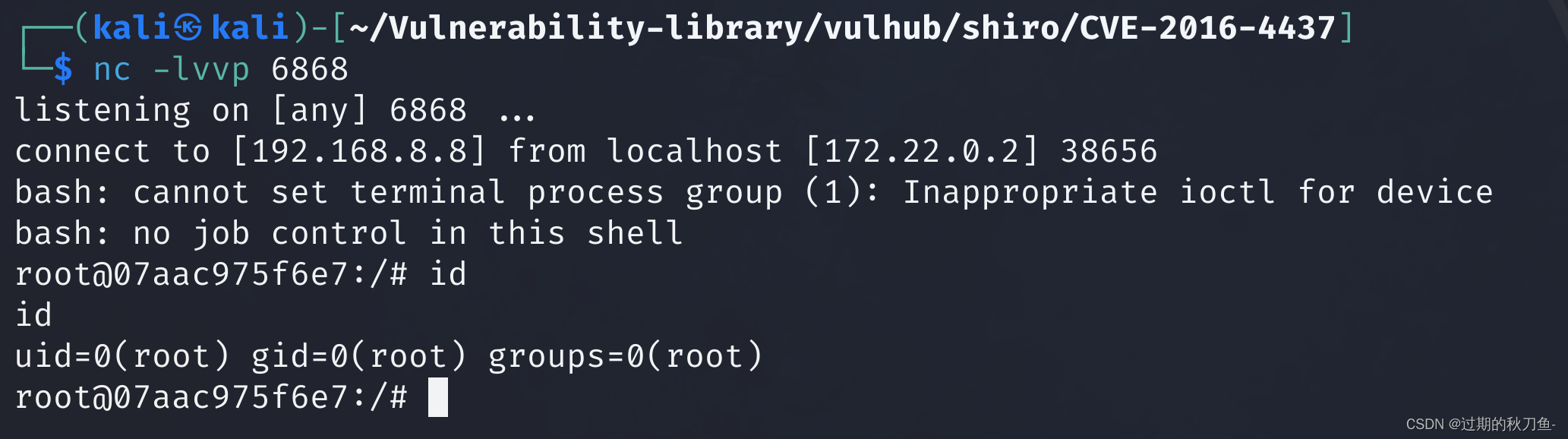
shiro-cve2016-4437漏洞复现
一、漏洞特征 Apache Shiro是一款开源强大且易用的Java安全框架,提供身份验证、授权、密码学和会话管理。Shiro框架直观、易用,同时也能提供健壮的安全性。 因为在反序列化时,不会对其进行过滤,所以如果传入恶意代码将会造成安全问题 在 1.2.4 版本前, 加…...

HFSS仿真结果怎么看?以T型波导为例,读懂S参数与电场动态图
HFSS仿真结果深度解析:从S参数到电场动态图的实战指南当你第一次在HFSS中完成T型波导仿真后,面对满屏的曲线和彩色云图,是否感到既兴奋又困惑?那些起伏的S参数曲线究竟告诉你什么信息?电场图中跳跃的颜色又代表怎样的物…...

亚马逊 Rufus 关停,Alexa 正式上线:卖家必须读懂的6条新规则
2026年5月13日,亚马逊官方正式宣布,下线Rufus,推出全新AI购物助手:Alexa for Shopping。但是,这不是粗暴地直接下线 Rufus,而是一次购物AI底层架构的重组 —— 将 Rufus 的商品专长 与 Alexa的用户理解力&a…...

2026年,揭秘那些真正安全的原生态食材厂家你不可不知的秘密
随着人们生活水平的提升以及对健康的日益重视,选择真正安全的原生态食材已经成为许多人购买食物的标准。但市场的繁杂使得甄别真正安全的食材厂家变得愈加困难。今天,我将通过几个关键角度,为大家揭秘那些真正安全的原生态食材厂家的秘密&…...

腾讯 Marvis 初级使用教程——从安装到上手
腾讯最新系统级AI助手Marvis(2026年5月20日发布),官网 https://marvis.qq.com,主打“一句话操作电脑”、跨端协同、GUI Agent执行。虽然是个【小龙虾】,但上手其实不难。这篇就简单写写 Marvis 的安装和基础使用&#…...

广州因特智能:AI视觉软硬结合,打破半导体检测装备“卡脖子”困境
【导语:广州因特智能科技孵化于西安电子科技大学广州研究院,专注用AI视觉技术解决工业场景的“卡脖子”检测难题,为半导体、光通信、新能源三大领域提供高端检测装备。】校地合作孵化,构建完整能力体系广州因特智能科技由西安电子…...
)
GIS工程应用记录(AI辅助编程)
问题的问题:语境坍缩“从各个角度提出问题,AI做出对应积极答复和修改,结果没有什么变化。”这,就是元问题最核心的症状。你尝试了所有你已知的“高级”协作手段,但就像重拳打在棉花上,AI永远在积极回应&…...
)
为什么你的DeepSeek微调loss震荡不止?(Meta/DeepSeek联合团队未公开的梯度裁剪+LoRA初始化双校准协议)
更多请点击: https://codechina.net 第一章:DeepSeek微调loss震荡的根本归因剖析 DeepSeek系列模型在微调过程中频繁出现loss剧烈震荡现象,其本质并非单一因素所致,而是数据、优化器、梯度动态与模型结构四者耦合失稳的系统性表现…...

PvZ Toolkit终极指南:三步掌握植物大战僵尸最强修改器
PvZ Toolkit终极指南:三步掌握植物大战僵尸最强修改器 【免费下载链接】pvztoolkit 植物大战僵尸 PC 版综合修改器 项目地址: https://gitcode.com/gh_mirrors/pv/pvztoolkit PvZ Toolkit是一款专为植物大战僵尸PC版设计的综合修改器工具,能够让你…...

yuzu模拟器完整指南:在电脑上畅玩Switch游戏的终极解决方案
yuzu模拟器完整指南:在电脑上畅玩Switch游戏的终极解决方案 【免费下载链接】yuzu 任天堂 Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/yu/yuzu 想在电脑上体验任天堂Switch游戏的魅力吗?yuzu模拟器正是你寻找的完美答案。作为…...

圈复杂度>12=技术债炸弹?DeepSeek静态分析实战:从17.8→3.2的重构路径全披露
更多请点击: https://codechina.net 第一章:圈复杂度>12技术债炸弹?DeepSeek静态分析实战:从17.8→3.2的重构路径全披露 当函数圈复杂度(Cyclomatic Complexity)持续高于12,它不再是…...