强化学习(RL)的学习笔记
1. 前言
(1)PPO的优点
PPO(Proximal Policy Optimization)算法相比其他强化学习方法有几个显著优点:
- 稳定性和鲁棒性:PPO通过限制策略更新的幅度来避免训练过程中的大幅波动,这增加了算法的稳定性和鲁棒性。这是通过引入一个被称为“信任区域”的概念来实现的,它限制了新策略与旧策略之间的偏离程度。
- 简单的实现:与其他需要复杂计算的强化学习算法(如TRPO)相比,PPO简化了这些计算,使得实现起来更为简单,同时保持了相似的性能,这使得它在实践中更受欢迎。
- 样本效率:PPO在使用每个数据样本方面比一些其他算法更有效,它可以在每次迭代中重复利用数据,从而提高样本的使用效率。
- 适用性广:PPO被证明在连续动作空间的多种环境中有效,这意味着它适用于各种任务,包括机器人控制和游戏等。
- 超参数调整容易:PPO相对于其他算法来说对超参数的选择不那么敏感,这降低了调整参数的难度。
- 高性能:PPO在多个基准测试和任务中显示出了优秀的性能,包括与其他先进的RL算法相比。
(2)策略梯度的优点
- 处理连续动作空间: 策略梯度非常适合于连续动作空间的问题。例如,如果你在控制一个机器人的臂,它的动作是连续的角度变化,策略梯度方法可以学习在任何给定状态下应该施加什么样的扭矩。
- 更好的探索机制:策略梯度方法通常会有更好的探索机制,因为它们可以在选择动作时采取随机性。这种随机性使智能体有可能探索到新的、可能更好的动作。
- 适合非马尔可夫决策过程:策略梯度方法可以在非马尔可夫(非完全可观测)的环境中工作得很好,因为它们不需要像值函数方法那样严格地依赖于状态的马尔可夫性质。
2. 学习资料
2.1 Hung-yi Lee(李宏毅)RL course
Machine Learning 2017 (Hung-yi Lee, NTU) 23-1~23-3
3. 常见术语
PPO:Proximal Policy Optimization,近端策略优化
Imitation Learning:模仿学习
GPT4-AllTools:模仿学习是一种让机器通过观察和复制专家行为来学习特定任务的技术。就像是当我们小时候学习骑自行车或做饭时观察父母的动作并尝试效仿他们一样。
行动者+评论家(Actor+Critic)
在机器学习的强化学习任务中,行动者负责做决定并采取行动,而评论家则评估这些行动,并指导行动者如何调整策略以做得更好。通过这种合作,行动者学会更好地完成任务。
4. RL面临的挑战
奖励延迟(Reward Delay)
Reward Delay 是指在行为和由该行为引起的奖励之间存在时间延迟。这种延迟使得学习过程复杂化,因为学习算法需要能够将行为与可能在很长一段时间后才出现的结果联系起来。
李宏毅老师用 Space Invader 讲解 Reward Delay:
- 但是如果machine只知道開火以後就得到reward
- 它最後learn出來的結果它只會瘋狂開火
- 對它來說往左移、往右移沒有任何reward它不想做
- Reward delay
- In space invader, only “fire” obtains reward
- Although the moving before “fire” is important
- In Go playing, it may be better to sacrifice immediate reward to gain more long-term reward
5. 常见概念
5.1 基本流程
5.1.1 Sample函数:探索行动的策略
Sample函数在训练过程中对应着“样本增广”的作用;
5.1.2 Gradient Ascent
Note:如果比赛胜利的话,就从参数上提升此次动作序列(sequence)出现的概率 θ \theta θ。
θ new ← θ old + η ∇ R ˉ θ o l d \theta^{\text {new}} \leftarrow \theta^{\text {old }}+\eta \nabla \bar{R}_{\theta^{old}} θnew←θold +η∇Rˉθold
∇ R ˉ θ ≈ 1 N ∑ n = 1 N R ( τ n ) ∇ log P ( τ n ∣ θ ) = 1 N ∑ n = 1 N R ( τ n ) ∑ t = 1 T n ∇ log p ( a t n ∣ s t n , θ ) = 1 N ∑ n = 1 N ∑ t = 1 T n R ( τ ∘ n ) ∇ log p ( a t n ∣ s t n , θ ) \begin{aligned} \nabla \bar{R}_\theta & \approx \frac{1}{N} \sum_{n=1}^N R\left(\tau^n\right) \nabla \log P\left(\tau^n \mid \theta\right)=\frac{1}{N} \sum_{n=1}^N R\left(\tau^n\right) \sum_{t=1}^{T_n} \nabla \log p\left(a_t^n \mid s_t^n, \theta\right) \\ & =\frac{1}{N} \sum_{n=1}^N \sum_{t=1}^{T_n} R\left(\tau_{\circ}^n\right) \nabla \log p \left(a_t^n \mid s_t^n, \theta\right)\end{aligned} ∇Rˉθ≈N1n=1∑NR(τn)∇logP(τn∣θ)=N1n=1∑NR(τn)t=1∑Tn∇logp(atn∣stn,θ)=N1n=1∑Nt=1∑TnR(τ∘n)∇logp(atn∣stn,θ)
∇ log p ( a t n ∣ s t n , θ ) = ∇ p ( a t n ∣ s t n , θ ) p ( a t n ∣ s t n , θ ) \nabla \log p\left(a_t^n \mid s_t^n, \theta\right) = \frac{\nabla p\left(a_t^n \mid s_t^n, \theta\right)}{p\left(a_t^n \mid s_t^n, \theta\right)} ∇logp(atn∣stn,θ)=p(atn∣stn,θ)∇p(atn∣stn,θ)
关于从直觉上理解这里为什么要除以 p ( a t n ∣ s t n , θ ) p\left(a_t^n \mid s_t^n, \theta\right) p(atn∣stn,θ)
Q:请问,可以从直觉上解释 why divided by p ( a t n ∣ s t n , θ ) p\left(a_t^n \mid s_t^n, \theta\right) p(atn∣stn,θ)吗?
ChatGPT4:
- 从直觉上来说, ∇ log p ( a t n ∣ s t n , θ ) \nabla \log p\left(a_t^n \mid s_t^n, \theta\right) ∇logp(atn∣stn,θ)中的除以 p ( a t n ∣ s t n , θ ) p\left(a_t^n \mid s_t^n, \theta\right) p(atn∣stn,θ)这一步出现在对数概率的梯度中,它可以被解释为一种“归一化(Normalization)”过程。
- 在策略梯度方法中,我们希望调整参数 θ \theta θ以增加好动作的概率,并减少坏动作的概率。为了做到这一点,我们需要考虑动作的概率:如果一个好动作已经有很高的概率被选择,我们不需要太大幅度地增加它的概率;而如果一个好动作目前只有很小的概率被选择,我们可能希望更显著地增加其被选中的概率。
- 通过计算概率的对数梯度,我们实际上是在计算“相对于动作概率的变化率”。这样,对于那些已经很可能发生的动作,我们只进行小幅度的调整;而对于不太可能发生但却是好动作的情况,我们会做出更大的调整。
4.2 Sarsa和Q-Learning——最初的强化学习算法
2.1 基于Q-Learning的强化学习——使用Q表进行动作选择
其实Q-Learning的思想很简单,就跟把大象放进冰箱是差不多的,
基本的步骤是:
- 观察环境,得到observation;
- 根据obs查询Q表格,选择Q值最大的action;
- 执行该动作。
3.2 Sarsa和Q-Learning的预期目标
其实这两种算法的目标不同,导致了结果不同:
Sarsa:使得sample()行为的reward的平均水平达到最大;
Q-Learning:使得maxQ()行为的reward的达到最大;
3 DQN——用神经网络取代Q表格
3.1 为什么要用神经网络取代Q表呢?
如果动作状态的空间是连续的,则使用Q表可能无法对这种空间进行表述,(连续状态的可能取值是无限多的),
于是我们将“状态-Q值”看作是一种映射,也就是说:使用函数映射的思想来描述“状态-Q值”的映射关系;
既然是函数映射,于是我们的DNN就闪亮登场了~
4 Actor-Critic算法
在我看来Actor和Critic有着这样的特点:
Actor——本能者
Critic——经验者
具体的形式就是Q Function;
量化Q的方法我们采用TD,(这也是李教授讲授的方法),
我感觉Critic有着将reward规则进行可导化的作用;
感性认识:表达了模型对规则的理解,(同时将reward函数进行可导化);
相关文章:
的学习笔记)
强化学习(RL)的学习笔记
1. 前言 (1)PPO的优点 PPO(Proximal Policy Optimization)算法相比其他强化学习方法有几个显著优点: 稳定性和鲁棒性:PPO通过限制策略更新的幅度来避免训练过程中的大幅波动,这增加了算法的稳…...

2023世界传感器大会开幕,汉威科技多领域创新产品引瞩目
11月5日,2023世界传感器大会在郑州国际会展中心正式拉开帷幕。据悉,本次大会由河南省人民政府、中国科学技术协会主办,郑州市人民政府、河南省工业和信息化厅、河南省科学技术协会、中国仪器仪表学会承办。 大会由“一会一赛一展”组成&#…...

什么是机器学习中的正则化?
1. 引言 在机器学习领域中,相关模型可能会在训练过程中变得过拟合和欠拟合。为了防止这种情况的发生,我们在机器学习中使用正则化操作来适当地让模型拟合在我们的测试集上。一般来说,正则化操作通过降低过拟合和欠拟合的可能性来帮助大家获得…...

PostgreSQL JDBC连接详解(附DEMO)
PostgreSQL JDBC连接详解 PostgreSQL JDBC连接详解摘要引言1. JDBC基础1.1 JDBC简介1.2 JDBC驱动程序1.3 建立JDBC连接 2. 配置PostgreSQL JDBC连接2.1 PostgreSQL连接JDBC2.2 PostgreSQL连接JDBC是否成功2.3 PostgreSQL连接JDBC获取表信息注释等2.4 PostgreSQL连接JDBC根据表名…...

学习视频剪辑:巧妙运用中画、底画,制作画中画,提升视频效果
随着数字媒体的普及,视频剪辑已经成为一项重要的技能。在视频剪辑过程中,制作画中画可以显著提升视频效果、信息传达和吸引力。本文讲解云炫AI智剪如何巧妙运用中画、底画批量制作画中画来提升视频剪辑水平,提高剪辑效率。 操作1、先执行云…...
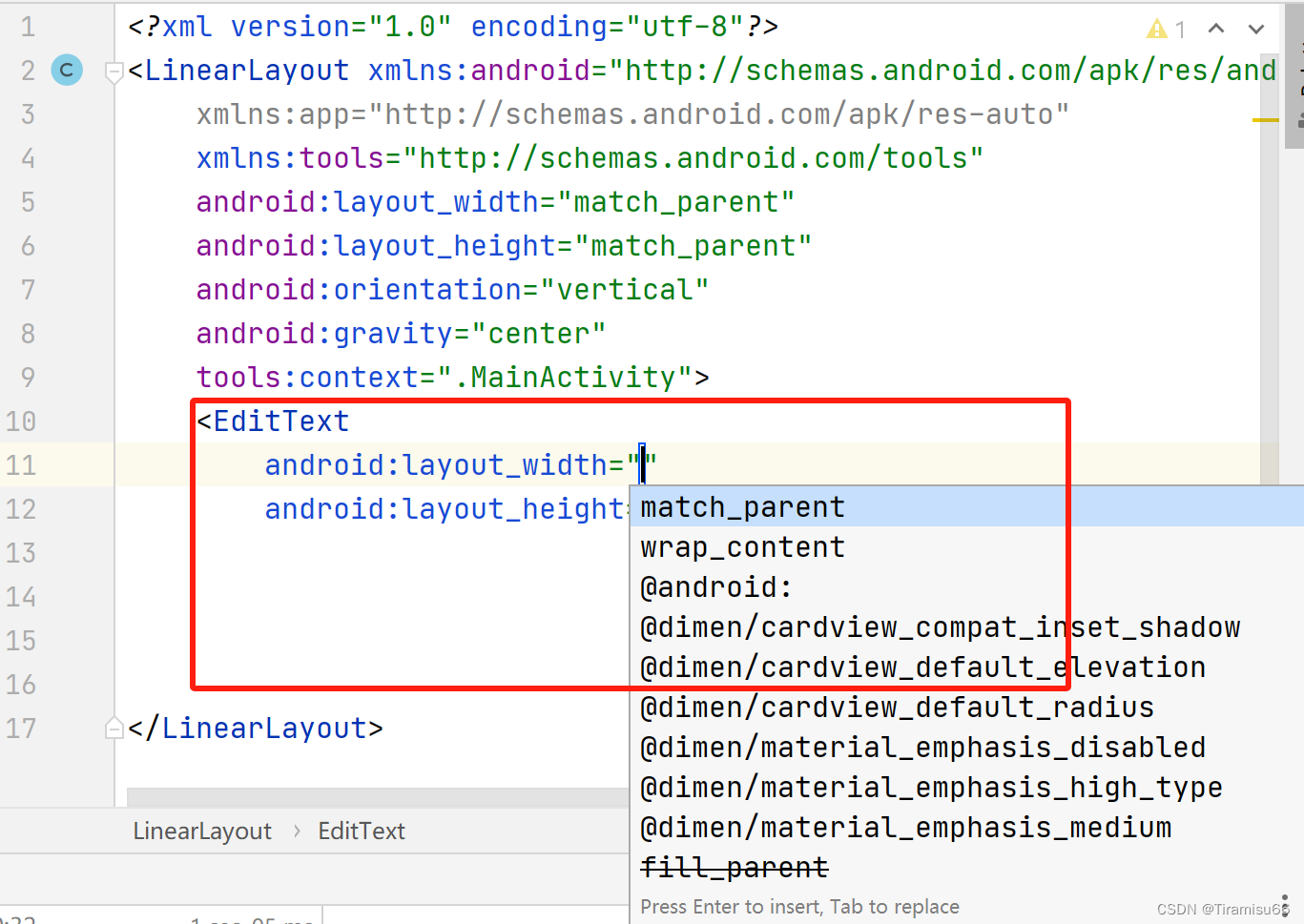
Android Studio代码无法自动补全
Android Studio代码自动无法补全问题解决 在写layout布局文件时,代码不提示,不自动补全,可以采用如下方法: 点击File—>Project Structure,之后如图所示,找到左侧Modules,修改SDK版本号&…...

从零开始搭建微服务
人狠话不多,直接开始少点屁话本着共同学习进步的目的和大家交流如有不对的地方望铁子们多多谅解 准备工具 开发工具 idea Java环境 jdk.18 Maven 3.8.6 仓库镜像阿里云 <mirror><id>alimaven</id><name>aliyun maven</name><url>https:…...

HF Hub 现已加入存储区域功能
我们在 企业版 Hub 服务 方案中推出了 存储区域(Storage Regions) 功能。https://hf.co/enterprise 通过此功能,用户能够自主决定其组织的模型和数据集的存储地点,这带来两大显著优势,接下来的内容会进行简要介绍&…...

linux下实现电脑开机后软件自启动
实现linux的软件自启动,需要四个文件 第一个【displayScreen.desktop】文件,.desktop文件就是一个用来运行程序的快捷方式,也叫启动器,常用来自启动用的文件,内容如下 [Desktop Entry] #要执行的脚本位置 Exec/home/yicaobao/te…...

【C/PTA】循环结构进阶练习(二)
本文结合PTA专项练习带领读者掌握循环结构,刷题为主注释为辅,在代码中理解思路,其它不做过多叙述。 7-1 二分法求多项式单根 二分法求函数根的原理为:如果连续函数f(x)在区间[a,b]的两个端点取值异号,即f(a)f(b)<0…...
Visual Studio 2010 软件安装教程(附下载链接)——计算机二级专用编程软件
下载链接: 提取码:2wAKhttps://www.123pan.com/s/JRpSVv-9injv.html 安装步骤如下: 1.如图所示,双击打开【Visual Studio 2010简体中文旗舰版】文件夹 2.如图所示,找到“Setup”文件夹打开,双击运行“setup” 3.如图…...

大促来袭 零点价格如何监测
双十一大促即将到来,各大品牌、店铺都会非常关注价格,这个时候的促销信息会很复杂,平台促销、店铺促销等,不同的优惠信息涉及的券也会很多,同时各优惠券关联的时间点也会不同,有些券零点能用,有…...

python 之 正则表达式模块re
文章目录 findall例子:特点和注意事项: match示例:match 对象的方法和属性:注意事项: search示例:match 对象的方法和属性:注意事项: split示例:参数说明:注意…...
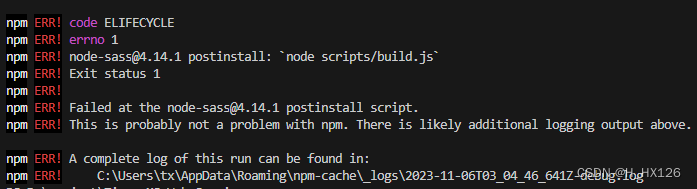
vue项目npm install报错解决
一、报错信息 node-sass4.14.1 postinstall: node scripts/build.js 二、解决方式 (1)删除未成功安装的 node_modules 文件; (2)为 node-sass 单独设置镜像源; npm config set sass_binary_sitehttps:/…...

ubuntu挂载共享目录的方法
ubuntu挂载共享目录的方法 安装NFS配置NFS 安装NFS sudo apt-get install nfs-kernel-server配置NFS 创建work共享目录:(本人将此文件放在桌面)sudo mkdir worksudo gedit /etc/exports添加: /home/zynq/Desktop/work *(rw,sync,no_root_squash,no_subtree_check)运行以下命…...
累计概率分布、概率分布函数(概率质量函数、概率密度函数)、度量空间、负采样(Negative Sampling)
这里写自定义目录标题 机器学习的基础知识累计概率分布概率分布函数度量空间负采样(Negative Sampling)基于分布的负采样(Distribution-based Negative Sampling):基于近邻的负采样(Neighbor-based Negativ…...

〔001〕虚幻 UE5 安装教程
✨ 目录 🎈 下载启动程序🎈 注册个人账户🎈 选择引擎版本🎈 选择安装选项🎈 虚幻商城的使用🎈 每月免费插件🎈 安装插件🎈 下载启动程序 下载地址:https://www.unrealengine.com/zh-CN/download点击上面地址,下载 UE5 启动程序并安装🎈 注册个人账户 打开商…...

Crypto(8) BUUCTF-bbbbbbrsa1
题目描述: from base64 import b64encode as b32encode from gmpy2 import invert,gcd,iroot from Crypto.Util.number import * from binascii import a2b_hex,b2a_hex import randomflag "******************************"nbit 128p getPrime(nbit)…...
软件测试之随机测试详解
在软件测试中除了根据测试用例和测试说明书进行功能测试外,还需要进行随机测试,随机测试是没有书面测试用例、记录期望结果、检查列表、脚本或指令的测试。主要是根据测试者的经验对软件进行功能和性能抽查。随机测试是根据测试说明书执行测试用例的重要…...

【广州华锐互动】3D全景虚拟旅游在文旅行业的应用场景
随着科技的不断发展,3D全景虚拟旅游正在成为一种新兴的旅游体验方式,它可以帮助旅游者更加深入地了解旅游信息,提升旅游体验。下面我们将详细介绍3D全景虚拟旅游可以应用于哪些场景。 一、旅游规划 3D全景虚拟旅游可以帮助旅游者更加直观地进…...

C++中显示与隐式加载dll的使用与区别
一、什么是 DLL?DLL(Dynamic Link Library) 是 Windows 下的动态链接库,包含可被多个程序共享的函数、资源或类。使用 DLL 可以实现代码复用、模块化设计和插件机制。在 C 中,调用 DLL 中的函数有两种主要方式…...

软阴影:那个让虚拟世界“温柔起来“的光影小秘密
一、从一只小猫的影子说起 前几天我在朋友家做客,他家养了一只胖乎乎的橘猫,正趴在阳台的窗边晒太阳。我无意间瞥了一眼那只猫脚边的影子,突然被一个细节震撼了—— 那只猫的影子——并不是一片均匀的黑。 仔细看——猫肚子紧贴地板的地方——…...

智能手机相机光谱特性测量与多光谱成像技术
1. 智能手机相机光谱特性测量基础智能手机相机的光谱灵敏度函数(Spectral Sensitivity Function, SSF)和透射率函数是计算摄影领域的核心参数,它们决定了设备对光信号的响应特性。准确获取这些参数对色彩还原、光谱重建和白平衡校准等任务至关重要。1.1 光谱灵敏度函…...
到panic:深入Linux 5.4内核,看异常处理如何层层递进)
从BUG()到panic:深入Linux 5.4内核,看异常处理如何层层递进
从BUG()到panic:Linux内核异常处理的防御体系全解析当你在深夜调试一个内核模块时,突然屏幕刷出一串红色警告——这可能是每个Linux内核开发者都经历过的噩梦时刻。但你是否想过,从第一行警告出现到系统完全崩溃,内核究竟经历了怎…...

Sangfor文件夹可以删除吗?【图文讲解】深信服文件夹残留清理?如何彻底删除深信服?Sangfor文件夹是什么?
(1)问题背景打开C盘,突然冒出个Sangfor 文件夹,占用好几个 GB 空间,想删又不敢删,怕删坏系统、断网崩溃;上网一查,说法五花八门,有人说是病毒,有人说是办公软…...
)
大佬推荐的网络安全学习路线(从基础到高级,超级详细)
大佬推荐的网络安全学习路线(从基础到高级,超级详细) 说起网络安全,你可能会担心它是一个过时的行业。有人说,网络安全快卷死了,你既要攻又要防,并且随着技术的发展,你还要不断地学…...

随机森林算法在儿童出行方式预测中的实战应用与优化
1. 项目概述:用随机森林预测孩子怎么上学做城市交通规划或者做家长接送方案的时候,你肯定想过一个问题:孩子们到底是怎么上学的?是走路、骑车、坐公交还是家长开车送?这个问题看似简单,背后却牵扯到城市规划…...

Atomic Layout核心概念解析:Composition组件如何实现布局与间距分离的终极指南
Atomic Layout核心概念解析:Composition组件如何实现布局与间距分离的终极指南 【免费下载链接】atomic-layout Build declarative, responsive layouts in React using CSS Grid. 项目地址: https://gitcode.com/gh_mirrors/at/atomic-layout Atomic Layout…...

Codex使用API Key授权无法使用插件?
小伙伴们,大家好,我是小溪,见字如面。对于没有ChatGPT账号的小伙伴来说,虽然可以通过API Key授权的方式使用Codex桌面端,但是会有一些限制。比如无法使用插件功能,无法使用Codex移动端进行远程控制等。为了…...

DeepSeek模型微调全链路解析:从数据准备、LoRA配置到推理部署的7大关键步骤
更多请点击: https://intelliparadigm.com 第一章:DeepSeek模型微调全链路概览 DeepSeek系列大语言模型(如DeepSeek-V2、DeepSeek-Coder)凭借其开源特性、高性能推理能力与丰富的领域适配性,已成为工业界与学术界微调…...