支持向量机 (SVM):初学者指南

一、说明
SVM(支持向量机)简单而优雅用于分类和回归的监督机器学习方法。该算法试图找到一个超平面,将数据分为不同的类,并具有尽可能最大的边距。本篇我们将介绍如果最大边距不存在的时候,如何创造最大边距。
二、让我们逐步了解 SVM
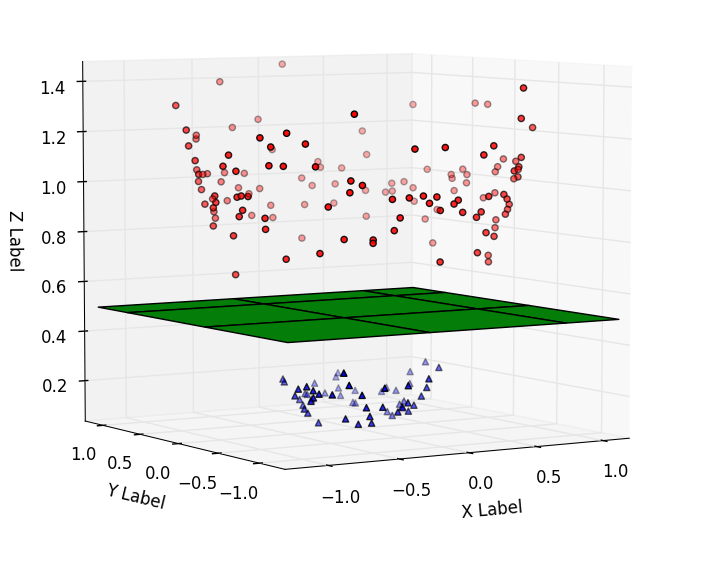
假设我们有一维湿度数据,红点代表不下雨的日子,蓝点代表下雨的日子。

根据我们拥有的一维观测数据,我们可以确定阈值。该阈值将充当分类器。由于我们的数据是一维的,分类器将有一个阈值。如果我们的数据是二维的,我们会使用一条线。
观察到的数据(最近的数据点)与分类器阈值之间的最短距离称为边距。能够提供最大margin的阈值称为Maximal Margin Classifier (Hyperplane)。在我们的例子中,它将位于双方最接近数据的中点。
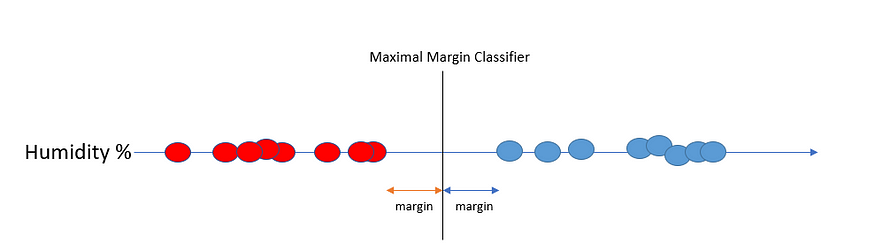
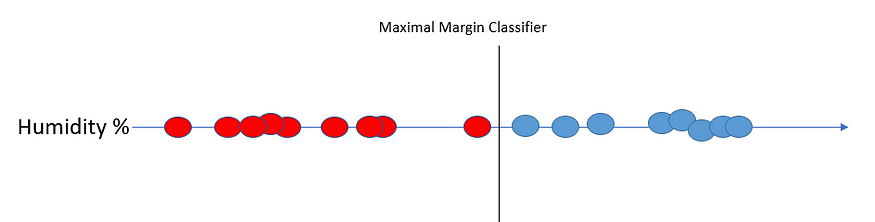
最大保证金在实践中不太适用。因为它对异常值没有抵抗力。想象一下,我们有一个具有蓝色值的离群红点。在这种情况下,分类器将非常接近蓝点,远离红点。
为了改善这一点,我们应该允许异常值和错误分类。我们在系统中引入偏差(并减少方差)。现在,边距称为软边距。使用软间隔的分类器称为支持向量分类器或软间隔分类器。边缘上和软边缘内的数据点称为支持向量。
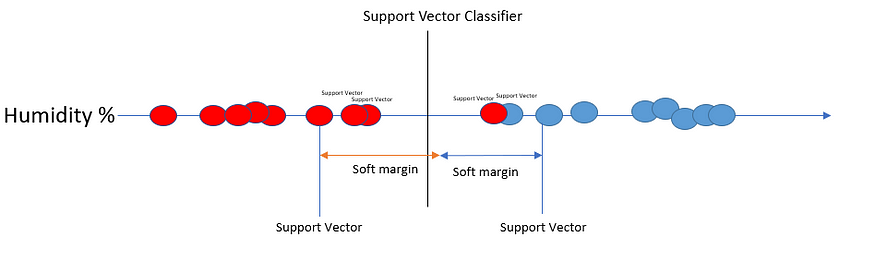
我们使用交叉验证来确定软边距应该在哪里。
在 2D 数据中,支持向量分类器是一条线。在 3D 中,它是一个平面。在 4 个或更多维度中,支持向量分类器是一个超平面。从技术上讲,所有 SVC 都是超平面,但在 2D 情况下更容易将它们称为平面。
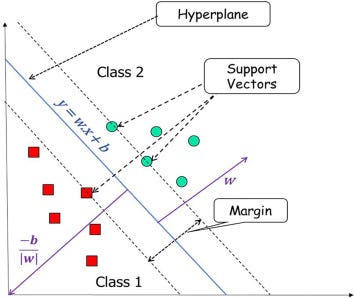
//www.analyticsvidhya.com/blog/2021/05/support-vector-machines/和https://www.sciencedirect.com/topics/computer-science/support-vector-machine
正如我们在上面看到的,支持向量分类器可以处理异常值并允许错误分类。但是,我们如何处理如下所示的重叠数据呢?

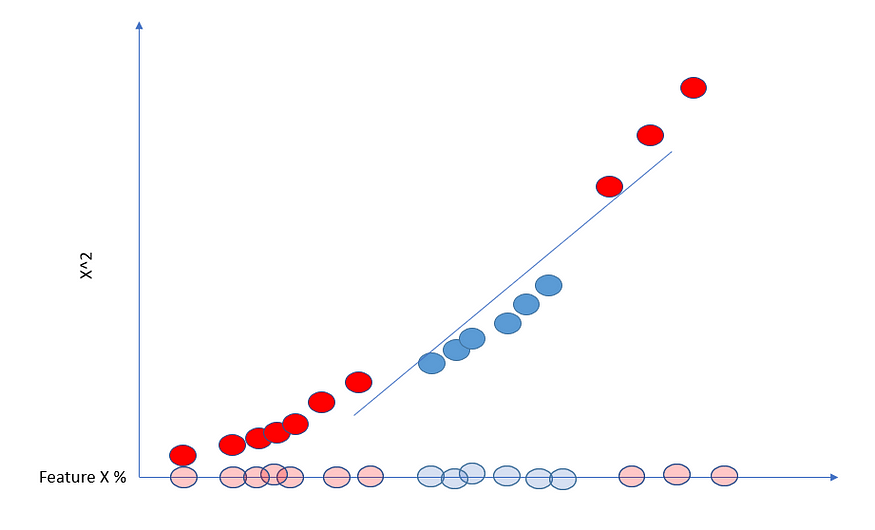
这就是支持向量机发挥作用的地方。让我们为问题添加另一个维度。我们有特征 X,作为新的维度,我们取 X 的平方并将其绘制在 y 轴上。
由于现在的数据是二维的,我们可以画一条支持向量分类器线。
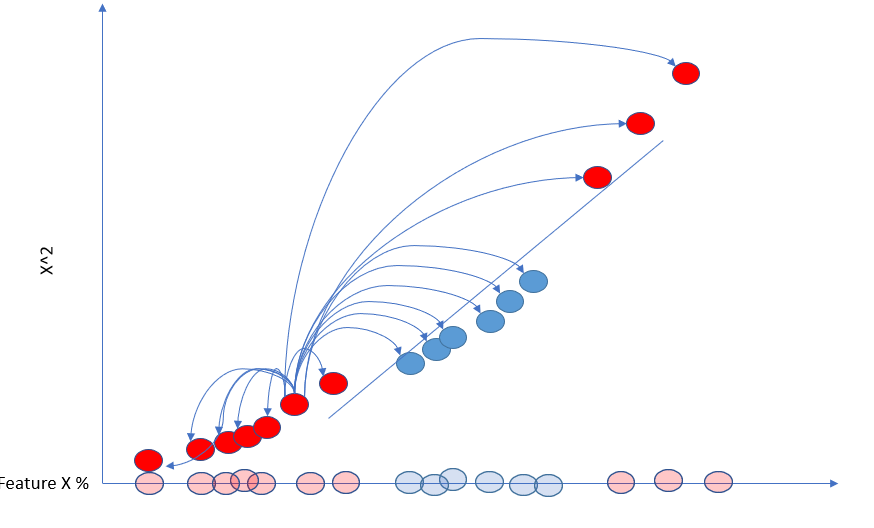
支持向量机获取低维数据,将其移至更高维度,并找到支持向量分类器。
与我们上面所做的类似,支持向量机使用核函数来查找更高维度的支持向量分类器。核函数是一种函数,它采用原始输入空间中的两个输入数据点,并计算变换后(高维)特征空间中它们对应的特征向量的内积。
核函数允许 SVM 在变换后的特征空间中运行,而无需显式计算变换后的特征向量,这对于大型数据集或复杂的变换来说计算成本可能很高。相反,核函数直接在原始输入空间中计算特征向量之间的内积。这称为内核技巧。
三、多项式核
多项式核用于将输入数据从低维空间变换到高维空间,在高维空间中使用线性决策边界更容易分离类。
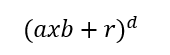
多项式核。
a和b是两个不同的观测值,r是多项式系数,d是多项式的次数。假设d为 2,r为 1/2。
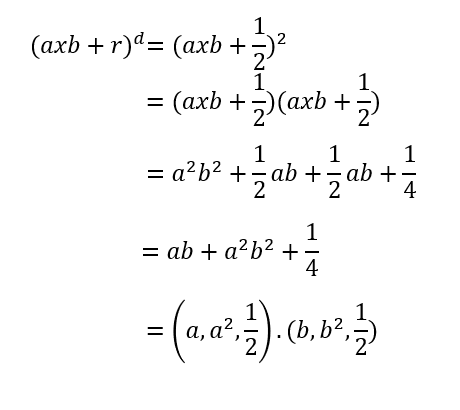
数学。
我们最终得到一个点积。第一项(a和b)是 x 轴,第二项(a²和b²)是 y 轴。因此,我们需要做的就是计算每对点之间的点积。例如更高维度中两点之间的关系;a = 9,b = 14 => (9 x 114 + 1/2)² = 16000,25。
四、径向内核 (RBF)
径向核在无限维度中查找支持向量分类器。
它为距离测试点较近的点分配较高的权重,为较远的点(如最近的邻居)分配较低的权重。较远的观察对数据点的分类影响相对较小。
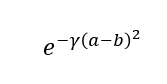
内核函数。
它计算两个数据之间的平方距离。Gamma 由交叉验证确定,它会缩放平方距离,这意味着它会缩放两个点彼此之间的影响。在此公式中,随着两点之间的距离增加,该值将接近于零。
当类之间的决策边界是非线性且复杂的时,径向核特别有用,因为它可以捕获输入特征之间的复杂关系。
五、Python实现
我们可以使用支持向量机sklearn.
from sklearn.svm import SVC

具有不同内核的 SVC。来源
SVC接受一些参数:
C是正则化参数。较大的值会使模型在训练数据上犯更多错误(错误分类)。因此,它的目的是有一个更好的概括。默认值为 1。kernel设置核函数。默认为rbf。其他选择是:Linear、poly、sigmoid和precompulated。此外,您还可以传递自己的内核函数。degree指定多项式核的次数。仅当内核是多项式时它才可用。默认值为 3。gamma控制核函数的形状。它可用于rbf、poly和sigmoid内核,较小的 gamma 值使决策边界更平滑,较大的值使决策边界更复杂。默认值是比例,等于 1 / (n_features x X.var())。auto是 1 / n_features。或者您可以传递一个浮点值。coef0仅用于 poly 和 sigmoid 内核。它控制多项式核函数中高阶项的影响。默认值为 0。shrinking控制是否使用收缩启发式。这是一个加速启发式过程。tol是停止标准的容差。当目标函数的变化小于tol时,优化过程将停止。class_weight平衡分类问题中类别的权重。可以将其设置为平衡,以根据课程频率自动调整权重。默认值为“无”。max_iter是迭代极限。-1 表示无限制(默认)。probability指定是否启用概率估计。当它设置为 True 时,估计器将估计类概率,而不仅仅是返回预测的类标签。当probability设置为 True 时,可以使用predict_proba该类的方法来获取新数据点的类标签的估计概率。SVCcache_size用于设置SVM算法使用的内核缓存的大小。当训练样本数量非常大或者内核计算成本很高时,内核缓存会很有用。通过将核评估存储在缓存中,SVM 算法可以在计算正则化参数 C 的不同值的决策函数时重用结果。
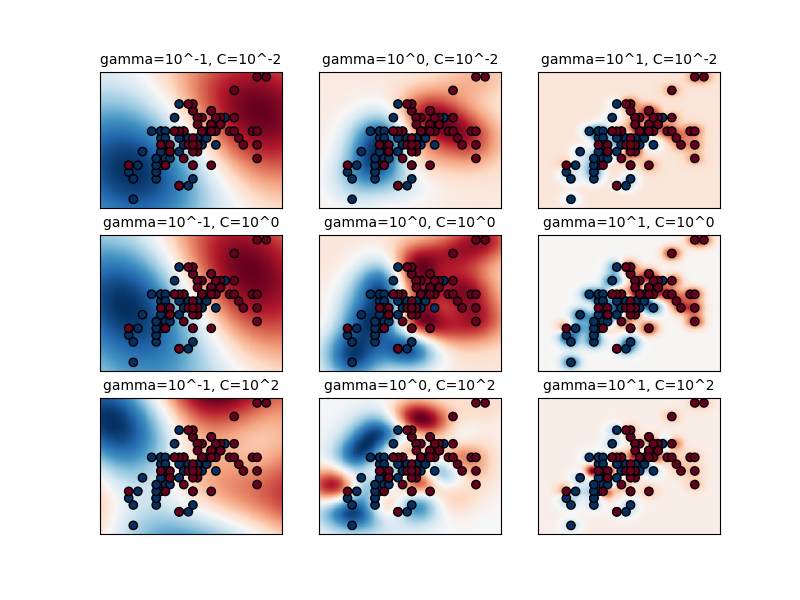
SVC 使用具有不同参数的 RBF 内核。来源
一个简单的实现:
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC# cancer data
cancer = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(cancer.data, cancer.target, random_state=42)# parameters
params = {'C': 1.0, 'kernel': 'rbf', 'gamma': 'scale',
'probability': False, 'cache_size': 200}# training
svc = SVC(**params)
svc.fit(X_train, y_train)# we can use svc's own score function
score = svc.score(X_test, y_test)
print("Accuracy on test set: {:.2f}".format(score))
#Accuracy on test set: 0.95六、回归
我们也可以在回归问题中使用支持向量机。
from sklearn.svm import SVR
epsilon是指定回归线周围容差大小的参数。回归线由 SVR 算法确定,使其在一定的误差范围内拟合训练数据,该误差范围由参数定义epsilon。
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.svm import SVR
from sklearn.metrics import mean_squared_error# the California Housing dataset
california = fetch_california_housing()
X_train, X_test, y_train, y_test = train_test_split(california.data, california.target, random_state=42)# training
svr = SVR(kernel='rbf', C=1.0, epsilon=0.1)
svr.fit(X_train, y_train)# Evaluate the model on the testing data
y_pred = svr.predict(X_test)
mse = mean_squared_error(y_test, y_pred)print("MSE on test set: {:.2f}".format(mse))
#MSE on test set: 1.35 我们还可以使用 来绘制边界matplotlib。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.svm import SVC# Load the Iris dataset
iris = load_iris()# Extract the first two features (sepal length and sepal width)
X = iris.data[:, :2]
y = iris.target# Create an SVM classifier
svm = SVC(kernel='linear', C=1.0)
svm.fit(X, y)# Create a mesh of points to plot in
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02),np.arange(y_min, y_max, 0.02))# Plot the decision boundary
Z = svm.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, cmap=plt.cm.Paired, alpha=0.8)# Plot the training points
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.Paired)
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.xticks(())
plt.yticks(())
plt.title('SVM decision boundary for Iris dataset')plt.show()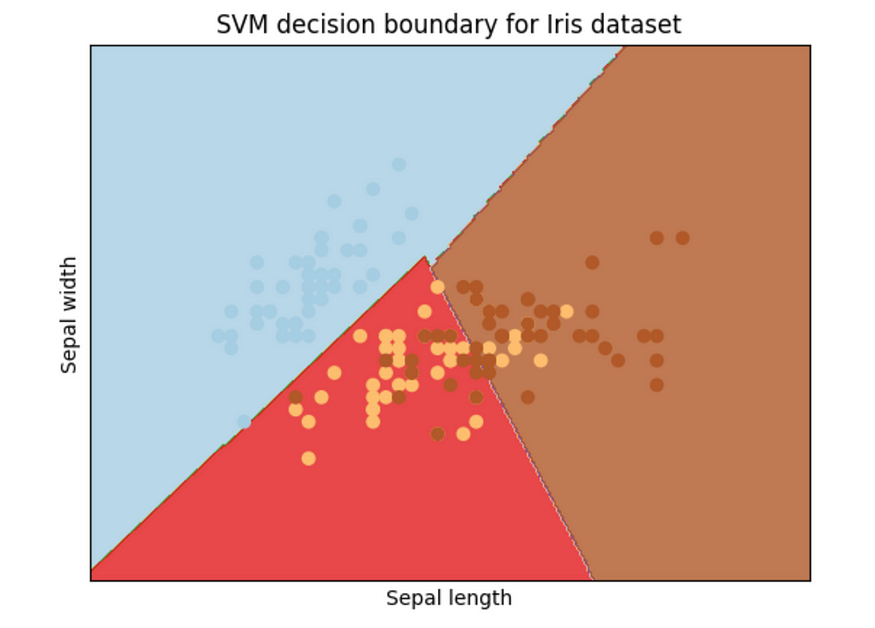
边界。图片由作者提供。
SVM 是一种相对较慢的方法。
import time
from sklearn.datasets import load_breast_cancer
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split# Load the breast cancer dataset
data = load_breast_cancer()
X, y = data.data, data.target# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)# Fit a logistic regression model and time it
start_time = time.time()
lr = LogisticRegression(max_iter=1000)
lr.fit(X_train, y_train)
end_time = time.time()
lr_runtime = end_time - start_time# Fit an SVM model and time it
start_time = time.time()
svm = SVC(kernel='linear', C=1.0)
svm.fit(X_train, y_train)
end_time = time.time()
svm_runtime = end_time - start_time# Print the runtimes
print("Logistic regression runtime: {:.3f} seconds".format(lr_runtime))
print("SVM runtime: {:.3f} seconds".format(svm_runtime))"""
Logistic regression runtime: 0.112 seconds
SVM runtime: 0.547 seconds
"""支持向量机 (SVM) 可能会很慢,原因如下:
- SVM 是计算密集型的:SVM 涉及解决凸优化问题,对于具有许多特征的大型数据集来说,计算成本可能很高。SVM 的时间复杂度通常至少为 O(n²),其中 n 是数据点的数量,对于非线性内核来说,时间复杂度可能要高得多。
- 用于调整超参数的交叉验证:SVM需要调整超参数,例如正则化参数
C和核超参数,这涉及使用交叉验证来评估不同的超参数设置。这可能非常耗时,尤其是对于大型数据集或复杂模型。 - 大量支持向量:对于非线性SVM,支持向量的数量会随着数据集的大小或模型的复杂性而快速增加。这可能会减慢预测时间,尤其是在模型需要频繁重新训练的情况下。
我们可以通过尝试以下一些方法来加速 SVM:
- 使用线性核:线性 SVM 的训练速度比非线性 SVM 更快,因为优化问题更简单。如果您的数据是线性可分的或者不需要高度复杂的模型,请考虑使用线性核。
from sklearn.datasets import fetch_openml
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC, LinearSVC
import time# Load MNIST digits dataset
mnist = fetch_openml('mnist_784', version=1)
data, target = mnist['data'], mnist['target']
X_train, X_test, y_train, y_test = train_test_split(data, target, test_size=0.2, random_state=42)# Train linear SVM
start_time = time.time()
linear_svc = LinearSVC()
linear_svc.fit(X_train, y_train)
linear_train_time = time.time() - start_time# Train non-linear SVM with RBF kernel
start_time = time.time()
rbf_svc = SVC(kernel='rbf')
rbf_svc.fit(X_train, y_train)
rbf_train_time = time.time() - start_timeprint('Linear SVM training time:', linear_train_time)
print('Non-linear SVM training time:', rbf_train_time)"""
Linear SVM training time: 109.03955698013306
Non-linear SVM training time: 165.98812198638916
"""- 使用较小的数据集:如果您的数据集非常大,请考虑使用较小的数据子集进行训练。您可以使用随机抽样或分层抽样等技术来确保子集代表完整数据集。
- 使用特征选择:如果您的数据集具有许多特征,请考虑使用特征选择技术来减少特征数量。这可以降低问题的维度并加快训练速度。
- 使用较小的值
C:正则化参数C控制最大化边际和最小化分类误差之间的权衡。较小的值C可以产生具有较少支持向量的更简单的模型,这可以加速训练和预测。
import time
from sklearn.datasets import load_breast_cancer
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split# Load the breast cancer dataset
data = load_breast_cancer()
X, y = data.data, data.target# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)for C in [0.1, 1, 10]:start_time = time.time()svm = SVC(kernel='linear', C=C, random_state=42)svm.fit(X_train, y_train)train_time = time.time() - start_timeprint('Training time with C={}: {:.2f}s'.format(C, train_time))"""
Training time with C=0.1: 0.08s
Training time with C=1: 0.55s
Training time with C=10: 0.90s
"""- 使用缓存:SVM 涉及计算数据点对之间的内积,这可能会导致计算成本高昂。Scikit-learn 的 SVM 实现包括一个缓存,用于存储常用数据点的内积值,这可以加快训练和预测速度。您可以使用参数调整缓存的大小
cache_size。
from sklearn.datasets import load_breast_cancer
from sklearn.svm import SVC
import time# Load the dataset
X, y = load_breast_cancer(return_X_y=True)# Train the model without a cache
start_time = time.time()
clf = SVC(kernel='linear', cache_size=1).fit(X, y)
end_time = time.time()
print(f"Training time without cache: {end_time - start_time:.3f} seconds")# Train the model with a cache of 200 MB
start_time = time.time()
clf_cache = SVC(kernel='linear', cache_size=200, max_iter=10000).fit(X, y)
end_time = time.time()
print(f"Training time with cache: {end_time - start_time:.3f} seconds")"""
Training time without cache: 0.535 seconds
Training time with cache: 0.014 seconds
"""七、结论
一般来说,SVM 适用于特征数量与样本数量相比相对较少且不同类之间有明显分离余量的分类任务。SVM 还可以处理高维数据以及特征和目标变量之间的非线性关系。然而,SVM 可能不适合非常大的数据集,因为它们可能是计算密集型的并且需要大量内存。
参考文章:
相关文章:
支持向量机 (SVM):初学者指南
照片由 Unsplash上的 vackground.com提供 一、说明 SVM(支持向量机)简单而优雅用于分类和回归的监督机器学习方法。该算法试图找到一个超平面,将数据分为不同的类,并具有尽可能最大的边距。本篇我们将介绍如果最大边距不存在的时候…...
UnityShader(五)
这次要用表面着色器实现一个水的特效。先翻到最下边看代码,看不懂再看下面的解释。 首先第一步要实现水的深浅判断,实现深水区和浅水区的区分。 这里需要用到深度图的概念。不去说太多概念,只去说怎么实现的,首先我们的水面是在…...
Java中的类和对象
文章目录 一、类和对象的基本概念二、类和对象的定义和使用1.创建类的语法2.创建类的对象3.范例(创建一个类的对象) 三、this引用1.什么是this引用2.this引用的特性 四、构造方法五、封装1.封装的概念2.访问限定符3.封装扩展包3.1包的概念3.2常见的包 六、static成员1.static修…...

多测师肖sir_高级金牌讲师_jenkins搭建
jenkins操作手册 一、jenkins介绍 1、持续集成(CI) Continuous integration 持续集成 团队开发成员每天都有集成他们的工作,通过每个成员每天至少集成一次,也就意味着一天有可 能多次集成。在工作中我们引入持续集成,通…...

Ps:色彩范围
Ps菜单:选择/色彩范围 Select/Color Range 色彩范围 Color Range是一个功能强大选择命令,不仅可以基于颜色进行选择,而且可以基于影调进行选择。不仅可以用来检测人脸选择肤色,也可用来选择超出印刷色域范围的区域。 在图层蒙版的…...
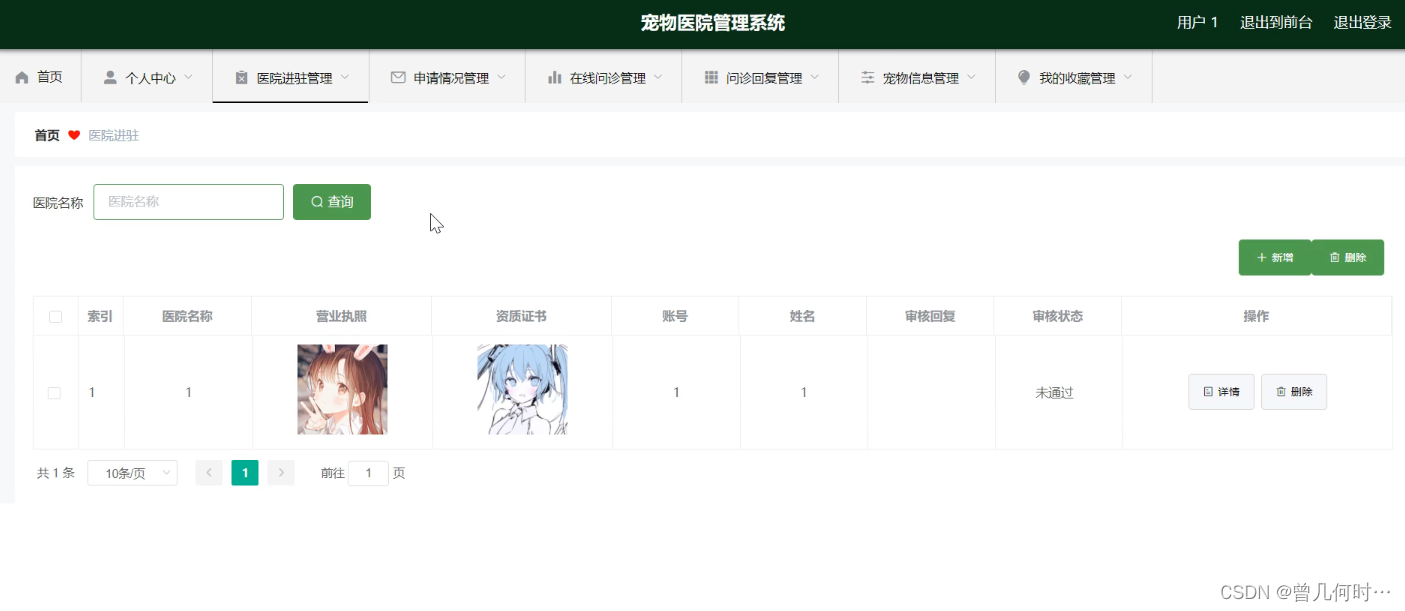
基于SSM的宠物医院管理系统
末尾获取源码 开发语言:Java Java开发工具:JDK1.8 后端框架:SSM 前端:Vue 数据库:MySQL5.7和Navicat管理工具结合 服务器:Tomcat8.5 开发软件:IDEA / Eclipse 是否Maven项目:是 目录…...

华为政企园区网络交换机产品集
产品类型产品型号产品说明 核心/汇聚交换机CloudEngine S5731-H24P4XCCloudEngine S5731-H24P4XC 提供 24个10/100/1000BASE-T以太网端口,4个万兆SFP,CloudEngine S5731-H 系列交换机是华为公司推出的新一代智能千兆交换机,基于华为公司统…...

NVMe FDP会被广泛使用吗?
文章开头,我们需要先了解固态硬盘的读写机制。我们知道,固态硬盘的存储单元是由闪存颗粒组成的,无法实现物理性的数据覆盖,只能擦除然后写入,重复这一过程。因而,我们可以想象得到,在实际读写过…...
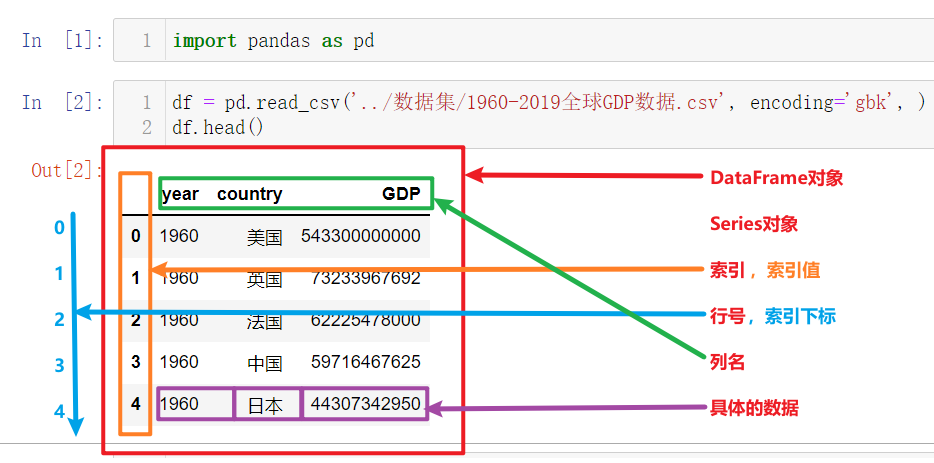
[黑马程序员Pandas教程]——Pandas数据结构
目录: 学习目标认识Pandas中的数据结构和数据类型Series对象通过numpy.ndarray数组来创建通过list列表来创建使用字典或元组创建s对象在notebook中不写printSeries对象常用API布尔值列表获取Series对象中部分数据Series对象的运算DataFrame对象创建df对象DataFrame…...

AI 绘画 | Stable Diffusion 提示词
Prompts提示词简介 在Stable Diffusion中,Prompts是控制模型生成图像的关键输入参数。它们是一种文本提示,告诉模型应该生成什么样的图像。 Prompts可以是任何文本输入,包括描述图像的文本,如“一只橘色的短毛猫,坐在…...

tomcat默认最大线程数、等待队列长度、连接超时时间
tomcat默认最大线程数、等待队列长度、连接超时时间 tomcat的默认最大线程数是200,默认核心线程数(最小空闲线程数)是10。 在核心线程数满了之后,会直接启用最大线程数(和JDK线程池不一样,JDK线程池先使用工作队列再使用最大线程…...

本地部署 CogVLM
本地部署 CogVLM CogVLM 是什么CogVLM Github 地址部署 CogVLM启动 CogVLM CogVLM 是什么 CogVLM 是一个强大的开源视觉语言模型(VLM)。CogVLM-17B 拥有 100 亿视觉参数和 70 亿语言参数。 CogVLM-17B 在 10 个经典跨模态基准测试上取得了 SOTA 性能&am…...
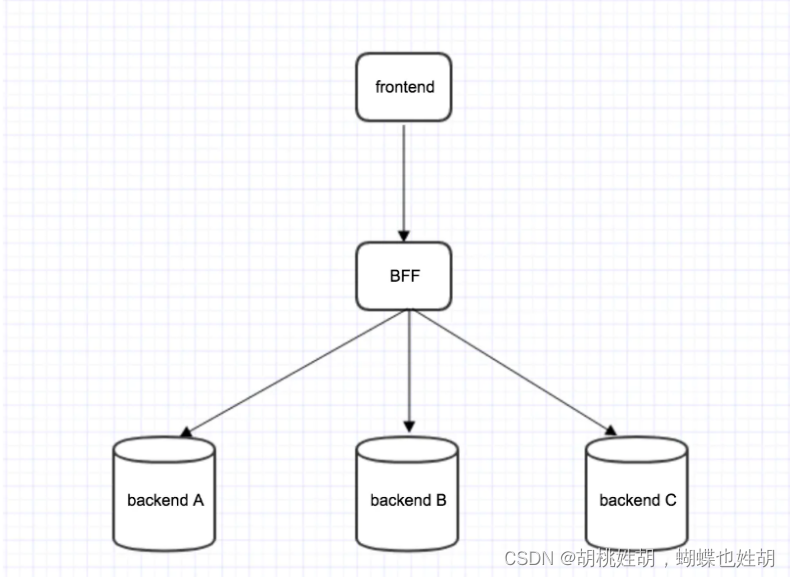
bff层解决了什么痛点
bff层 -- 服务于前端的后端 什么是bff? Backend For Frontend(服务于前端的后端),也就是服务器设计API的时候会考虑前端的使用,并在服务端直接进行业务逻辑的处理,又称为用户体验适配器。BFF只是一种逻辑…...

面试经典150题——Day33
文章目录 一、题目二、题解 一、题目 76. Minimum Window Substring Given two strings s and t of lengths m and n respectively, return the minimum window substring of s such that every character in t (including duplicates) is included in the window. If there …...
再谈Android重要组件——Handler(Native篇)
前言 最近工作比较忙,没怎么记录东西了。Android的Handler重要性不必赘述,之前也写过几篇关于hanlder的文章了: Handler有多深?连环二十七问Android多线程:深入分析 Handler机制源码(二) And…...
Javaweb之javascript的详细解析
JavaScript html完成了架子,css做了美化,但是网页是死的,我们需要给他注入灵魂,所以接下来我们需要学习JavaScript,这门语言会让我们的页面能够和用户进行交互。 1.1 介绍 通过代码/js效果演示提供资料进行效果演示&…...

Linux常用命令——cd命令
在线Linux命令查询工具 cd 切换用户当前工作目录 补充说明 cd命令用来切换工作目录至dirname。 其中dirName表示法可为绝对路径或相对路径。若目录名称省略,则变换至使用者的home directory(也就是刚login时所在的目录)。另外,~也表示为home directo…...

VHDL基础知识笔记(1)
1.实体:其电路意义相当于器件,它相当于电路原理图上的元器件符号。它给出了器件的输入输出引脚。实体又被称为模块。 2.结构体:这个部分会给出实体(或者说模块)的具体实现,指定输入和输出的行为。结构体的…...
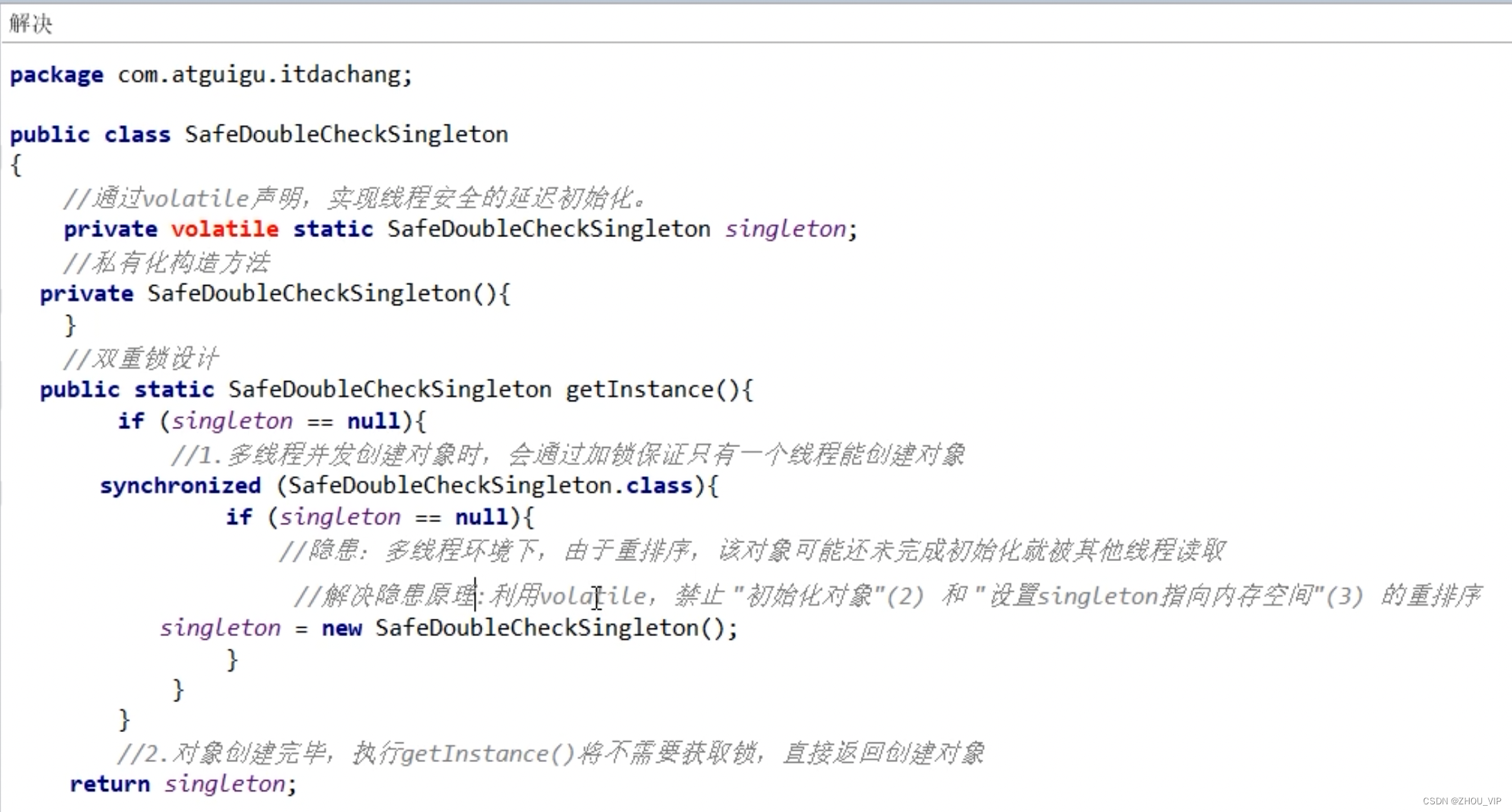
volatile-日常使用场景
6.4 如何正确使用volatile 单一赋值可以,但是含复合运算赋值不可以(i之类的) volatile int a 10; volatile boolean flag true; 状态标志,判断业务是否结束 作为一个布尔状态标志,用于指示发生了一个重要的一次…...

策略模式在数据接收和发送场景的应用
在本篇文章中,我们介绍了策略模式,并在数据接收和发送场景中使用了策略模式。 背景 在最近项目中,需要与外部系统进行数据交互,刚开始交互的系统较为单一,刚开始设计方案时打算使用了if else 进行判断: if(…...

Unity安卓打包实战指南:从环境配置到APK生成全链路排错
1. 这不是“入门教程”,而是一份写给真实开发现场的生存指南你打开Unity,新建一个3D项目,拖进一个Cube,点击Play——它动了。你松了口气,觉得“Unity好像也没那么难”。但当你把APK打包发给测试同事,对方回…...

深度学习从心电信号中解码呼吸频率:原理、实现与临床价值
1. 项目概述:从心电信号中“听”到呼吸声呼吸频率,这个我们每分钟都在进行却很少被精确量化的生命体征,在临床医学中扮演着至关重要的角色。它不仅是评估呼吸系统功能的直接指标,更是反映全身代谢、循环乃至神经系统状态的“窗口”…...

Python开发者首次使用Taotoken接入大模型API的完整步骤指南
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Python开发者首次使用Taotoken接入大模型API的完整步骤指南 对于Python开发者而言,接入大模型API进行应用开发已成为一…...

OpenClaw 连接阿里云百炼图文教程
OpenClaw 连接阿里云百炼图文教程 前置准备 已安装并可以正常打开 OpenClaw Windows。 OpenClaw 顶部 Gateway 状态保持在线。 已准备好可正常登录的阿里云账号。 可以正常访问阿里云百炼登录地址:https://bailian.console.aliyun.com/cn-beijing#/home 建议提…...

长期使用Taotoken聚合服务对项目月度账单的可预测性提升
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Taotoken聚合服务对项目月度账单的可预测性提升 在AI驱动的项目开发与运营中,成本控制与预算规划是团队管理者…...

OpenCore Legacy Patcher完全指南:3步让旧款Mac焕发新生的终极方案
OpenCore Legacy Patcher完全指南:3步让旧款Mac焕发新生的终极方案 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 你是否拥有一台性能尚可但已被…...

零基础怎么学Agent?这个工程师考试内容拆给你看
站在 AI Agent(智能体)爆发的十字路口,很多既没有深厚算法背景、也没有丰富写代码经验的“小白”常常感到迷茫:动辄谈及的大模型交互、复杂的业务编排,零基础真的能学会吗? 事实上,智能体开发早…...

学了几天 Web 安全,终于搞懂什么是 XSS 了
xss的详细介绍最近开始正式学习 Web 安全。前面陆续学了:HTTPCookieSessionJWT RBAC然后发现很多地方都会提到一个东西:XSS以前一直感觉这个漏洞很抽象。网上很多文章一上来就是:<script>alert(1)</script>然后说:“弹…...

XZ1018,100V,40A,NMOS 封装:TO252
封装:TO252类型:NVDS:100V VGS: 20V ID:40ARDS(ON):10V <14mΩRDS(ON):4.5V <19mΩ型号: XZ1018 封装:TO252类型…...

基于KS距离度量交通流分布偏移:提升DRL交通信号控制鲁棒性的工程实践
1. 项目概述与核心挑战在智能交通系统(ITS)领域,基于深度强化学习(DRL)的交通信号控制(Traffic Signal Control)正从研究走向实际部署。作为一名长期关注AI落地应用的从业者,我见过太…...