[PyTorch][chapter 61][强化学习-免模型学习1]
前言:
在现实的学习任务中,环境
其中的转移概率P,奖赏函数R 是未知的,或者状态X也是未知的
称为免模型学习(model-free learning)
目录:
1: 蒙特卡洛强化学习
2:同策略-蒙特卡洛强化学习
3: 异策略- 蒙特卡洛强化学习
一 蒙特卡洛强化学习
在免模型学习的情况下,策略迭代算法会遇到两个问题:
1: 是策略无法评估
因为无法做全概率展开。此时 只能通过在环境中执行相应的动作观察得到的奖赏和转移的状态、
解决方案:一种直接的策略评估代替方法就是“采样”,然后求平均累积奖赏,作为期望累积奖赏的近似,这称为“蒙特卡罗强化学习”。
2: 策略迭代算法估计的是 状态值函数(state value function) V,而最终的策略是通过 状态 动作值函数(state-action value function) Q 来获得。
模型已知时,有很简单的从 V 到 Q 的转换方法,而模型未知 则会出现困难。
解决方案:所以我们将估计对象从 V 转为 Q,即:估计每一对 “状态-动作”的值函数。
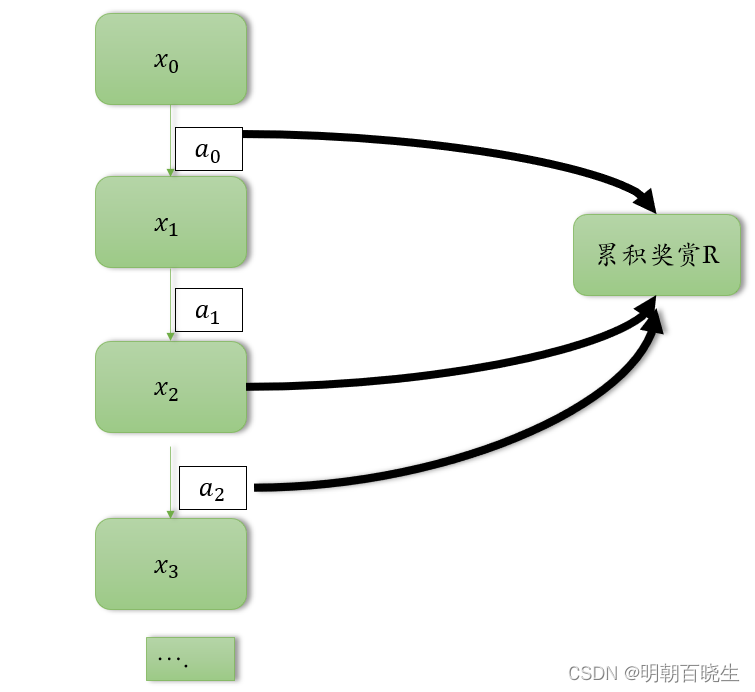
模型未知的情况下,我们从起始状态出发,使用某种策略进行采样,执行该策略T步,
并获得轨迹 ,
然后 对轨迹中出现的每一对 状态-动作,记录其后的奖赏之和,作为 状态-动作 对的一次
累积奖赏采样值. 多次采样得到多条轨迹后,将每个状态-动作对的累积奖赏采样值进行平均。即得到 状态-动作值函数的估计.
二 同策略蒙特卡洛强化学习
要获得好的V值函数估计,就需要不同的采样轨迹。
我们将确定性的策略 称为原始策略
原始策略上使用 -贪心法的策略记为
以概率
选择策略1: 策略1 :
以概率
选择策略2: 策略2:均匀概率选取动作,
对于最大化值函数的原始策略
其中贪心策略
中:
当前最优动作被选中的概率
每个非最优动作选中的概率 ,多次采样后将产生不同的采样轨迹。
因此对于最大值函数的原始策略,同样有

算法中,每采样一条轨迹,就根据该轨迹涉及的所有"状态-动作"对值函数进行更新
同策略蒙特卡罗强化学习算法最终产生的是E-贪心策略。然而,引入E-贪心策略是为了便于策略评估,而不是最终使用
三 同策略蒙特卡洛算法 Python
# -*- coding: utf-8 -*-
"""
Created on Fri Nov 3 09:37:32 2023@author: chengxf2
"""# -*- coding: utf-8 -*-
"""
Created on Thu Nov 2 19:38:39 2023@author: cxf
"""import random
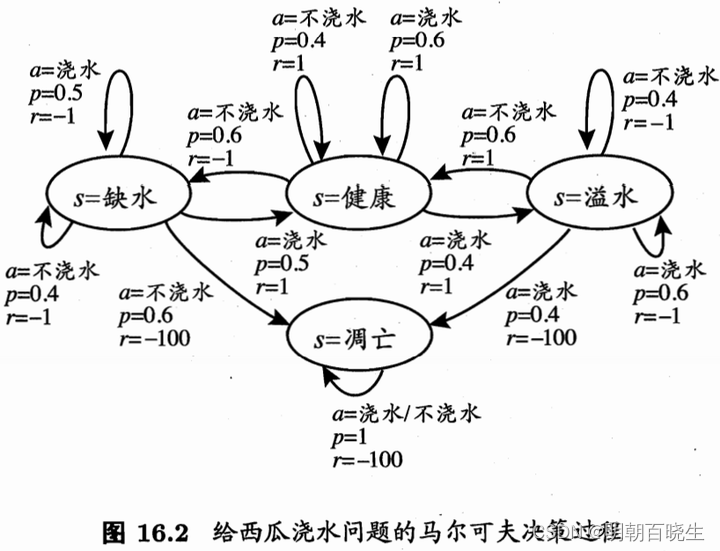
from enum import Enumclass State(Enum):'''状态空间X'''shortWater =1 #缺水health = 2 #健康overflow = 3 #溢水apoptosis = 4 #凋亡class Action(Enum):'''动作空间A'''water = 1 #浇水noWater = 2 #不浇水class Env():def reward(self, nextState):r = -100if nextState is State.shortWater:r =-1elif nextState is State.health:r = 1elif nextState is State.overflow:r= -1else:r = -100return rdef action(self, state, action):if state is State.shortWater:#print("\n state--- ",state, "\t action---- ",action)if action is Action.water :S =[State.shortWater, State.health]proba =[0.5, 0.5]else:S =[State.shortWater, State.apoptosis]proba =[0.4, 0.6]elif state is State.health:#健康if action is Action.water :S =[State.health, State.overflow]proba =[0.6, 0.4]else:S =[State.shortWater, State.health]proba =[0.6, 0.4]elif state is State.overflow:#溢水if action is Action.water :S =[State.overflow, State.apoptosis]proba =[0.6, 0.4]else:S =[State.health, State.overflow]proba =[0.6, 0.4]else: #凋亡S =[State.apoptosis]proba =[1.0]#print("\n S",S, "\t prob ",proba)nextState = random.choices(S, proba)[0]r = self.reward(nextState)#print("\n nextState ",nextState,"\t reward ",r)return nextState,rdef __init__(self):self.X = Noneclass Agent():def initPolicy(self):self.Q ={}self.count ={}brandom = True #使用随机策略for state in self.S:for action in self.A:self. Q[state, action] = 0self.count[state,action]= 0randProb= [0.5,0.5]return self.Q, self.count, randProb,brandomdef randomPolicy(self,randProb,T):A = self.Aenv = Env()state = State.shortWater #从缺水开始history =[]for t in range(T):a = random.choices(A, randProb)[0]nextState,r = env.action(state, a)item = [state,a,r,nextState]history.append(item)state = nextStatereturn historydef runPolicy(self,policy,T):env = Env()state = State.shortWater #从缺水开始history =[]for t in range(T):action = policy[state]nextState,r = env.action(state, action)item = [state,action,r,nextState]history.append(item)state = nextStatereturn historydef getTotalReward(self, t,T, history):denominator =T -ttotalR = 0.0for i in range(t,T):#列表下标为0 开始,所以不需要t+1r= history[i][2]totalR +=rreturn totalR/denominatordef updateQ(self, t ,history,R):#[state,action,r,nextState]state = history[t][0]action = history[t][1]count = self.count[state,action]self.Q[state, action]= (self.Q[state,action]*count+R)/(count+1)self.count[state,action] = count+1def learn(self):Q,count,randProb,bRandom =self.initPolicy()T =10policy ={}for s in range(1,self.maxIter): #采样第S 条轨迹if bRandom: #使用随机策略history = self.randomPolicy(randProb, T)#print(history)else:print("\n 迭代次数 %d"%s ,"\t 缺水:",policy[State.shortWater].name,"\t 健康:",policy[State.health].name,"\t 溢水:",policy[State.overflow].name,"\t 凋亡:",policy[State.apoptosis].name)history = self.runPolicy(policy, T)#已经有了一条轨迹了for t in range(0,T-1):R = self.getTotalReward(t, T, history)self.updateQ(t, history, R)rand = random.random()if rand < self.epsilon: #随机策略执行bRandom = Trueelse:bRandom = Falsefor state in self.S:maxR = self.Q[state, self.A[0]]for action in self.A:r = self.Q[state,action]if r>=maxR:policy[state] = actionmaxR = rreturn policydef __init__(self):self.S = [State.shortWater, State.health, State.overflow, State.apoptosis]self.A = [Action.water, Action.noWater]self.Q ={}self.count ={}self.policy ={}self.maxIter =5self.epsilon = 0.2if __name__ == "__main__":agent = Agent()agent.learn()相关文章:
[PyTorch][chapter 61][强化学习-免模型学习1]
前言: 在现实的学习任务中,环境 其中的转移概率P,奖赏函数R 是未知的,或者状态X也是未知的 称为免模型学习(model-free learning) 目录: 1: 蒙特卡洛强化学习 2:同策略-蒙特卡洛强化学习 3&am…...

网络运维Day04-补充
文章目录 周期性计划任务周期性计划任务使用案例一案例二 周期性计划任务 在固定时间可以完成相同的任务,被称之为周期性计划任务由crond服务提供需要将定时任务,写到一个文件书写格式如下 分 时 日 月 周 任务(绝对路径)分:0-59时ÿ…...
前端埋点方式
前言: 想要了解用户在系统中所做的操作,从而得出用户在本系统中最常用的模块、在系统中停留的时间。对于了解用户的行为、分析用户的需求有很大的帮助,想实现这种需求可以通过前端埋点的方式。 埋点方式: 1.什么是埋点?…...

iOS导航栏返回按钮
导航栏返回按钮隐藏: override func pushViewController(_ viewController: UIViewController, animated: Bool) {if let vc self.viewControllers.last {let backItem UIBarButtonItem()backItem.title ""vc.navigationItem.backBarButtonItem backI…...
2023中国视频云市场报告:腾讯云音视频解决方案份额连续六次蝉联榜首,加速全球化布局
近日,国际数据公司(IDC)发布了《中国视频云市场跟踪(2023上半年)》报告,腾讯云音视频的解决方案份额连续六次蝉联榜首,并在视频生产创作与媒资管理市场份额中排名第一。同时,在实时音…...

jpa Repository的常用写法总结
一、前言 之前项目在xml中写sql,感觉标签有很多,比较灵活; 最近在写新项目,使用了jpa,只能在java中写sql了,感觉不太灵活,但是也得凑付用。 以下总结下常用入参出参写法。 二、Repository代…...
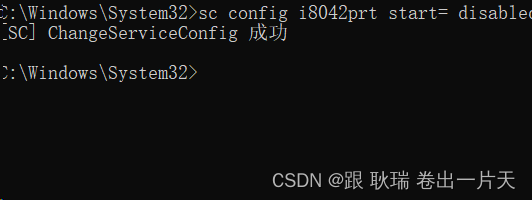
笔记本电脑 禁用/启用 自带键盘
现在无论办公还是生活 很多人都会选择笔记本电脑 但很多人喜欢机械键盘 或者 用一些外接键盘 但是很多时候我们想操作 会碰到笔记本原来的键盘导致错误操作 那么 我们就需要将笔记本原来的键盘禁用掉 我们先以管理员身份运行命令窗口 然后 有两个命令 禁用默认键盘 sc conf…...
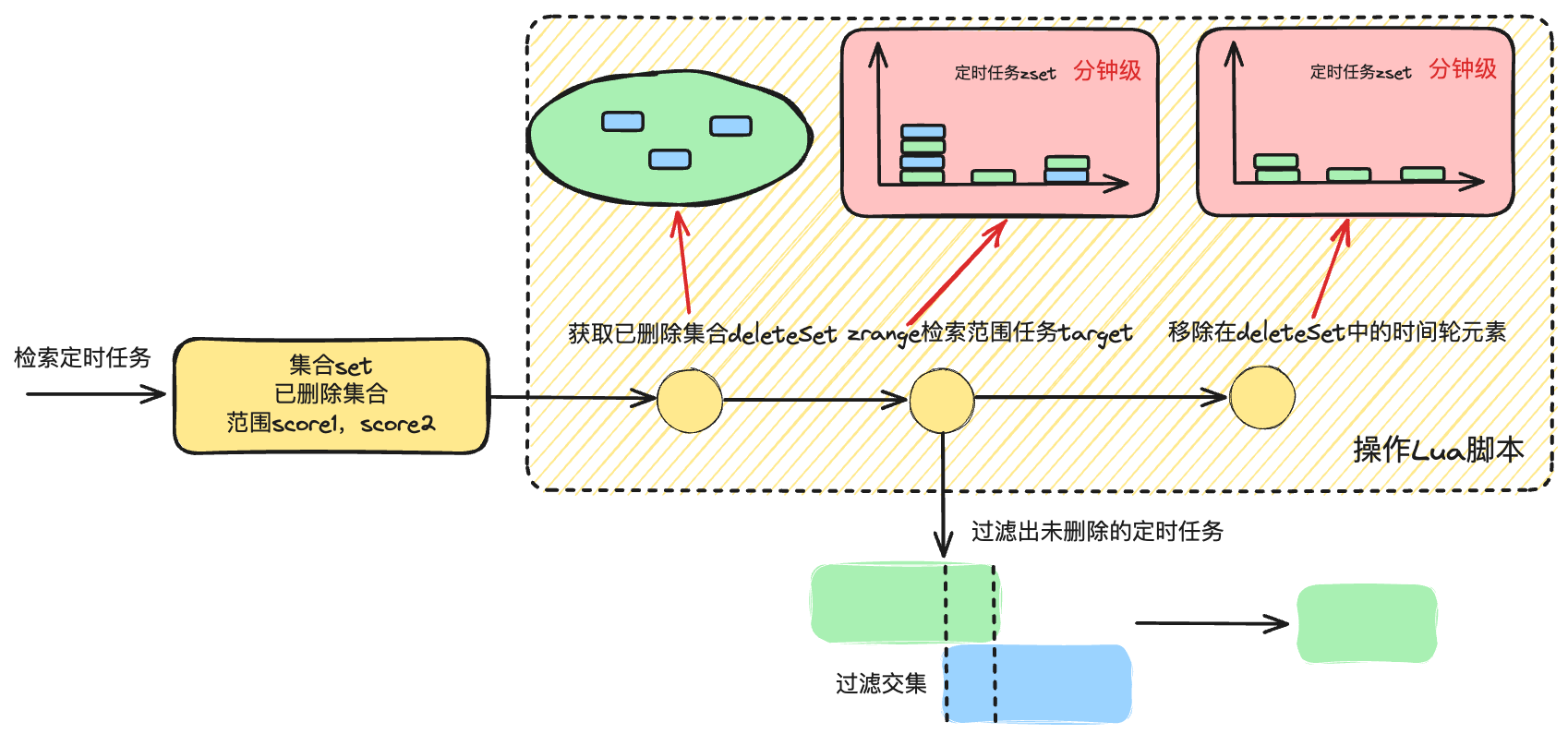
基于 golang 从零到一实现时间轮算法 (三)
引言 本文参考小徐先生的相关博客整理,项目地址为: https://github.com/xiaoxuxiansheng/timewheel/blob/main/redis_time_wheel.go。主要是完善流程以及记录个人学习笔记。 分布式版实现 本章我们讨论一下,如何基于 redis 实现分布式版本的…...
k8s 1.28安装
容器运行时,containerd 按照官方的指导,需要安装runc和cni插件,提示的安装方式,有三种: 二进制安装包源码apt-get 或 dnf安装 我们这里选用第三种,找到docker官方提供的安装方式 ubuntu-containerd # A…...
安装anaconda时控制台conda-version报错
今天根据站内的一篇博客教程博客在此安装anaconda时,检查conda版本时报错如下: >>>>>>>>>>>> ERROR REPORT <<<<<<<<<<<< Traceback (most recent call last): File “D:\An…...
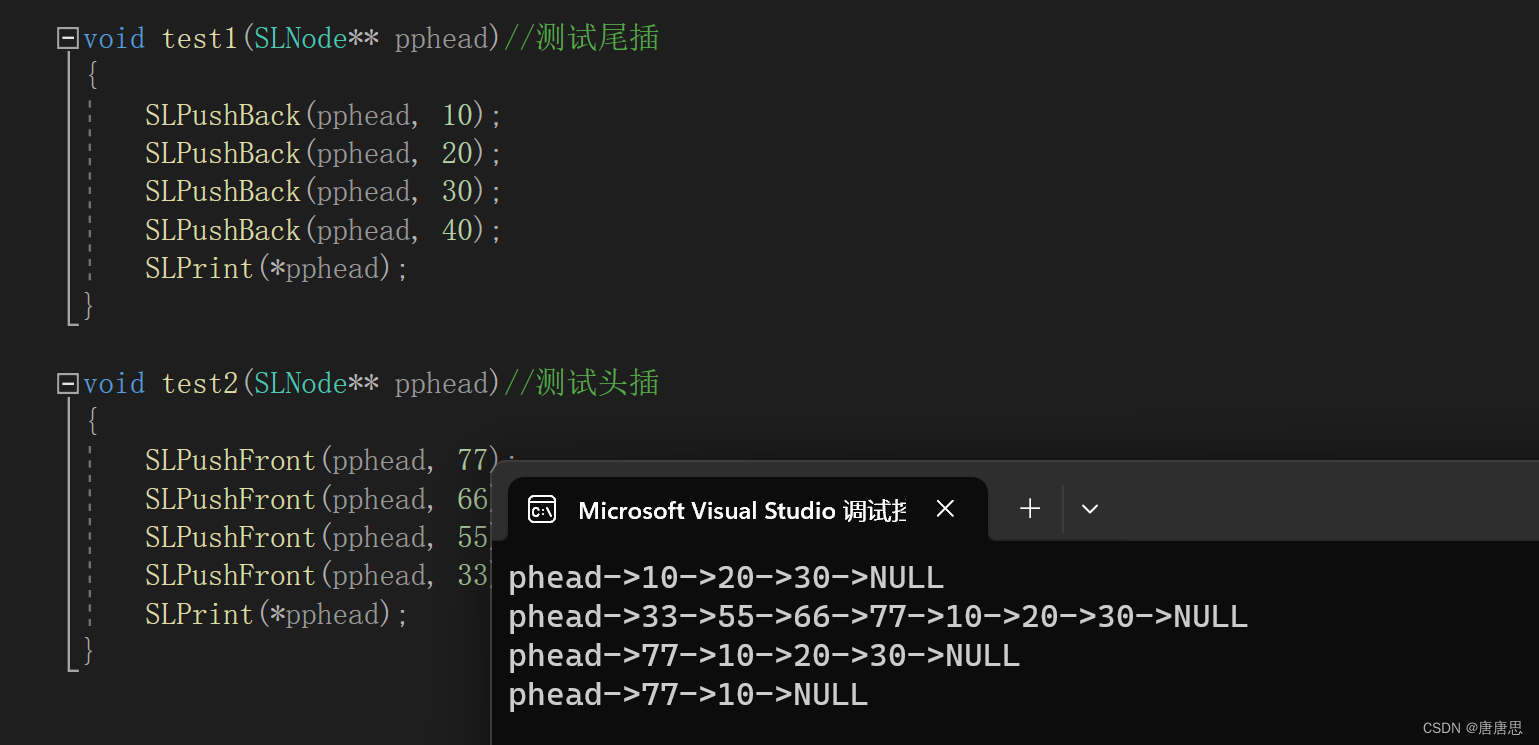
链表(1)
目录 单链表 主函数test.c test1 test2 test3 test4 头文件&函数声明SList.h 函数实现SList.c 打印SLPrint 创建节点CreateNode 尾插SLPushBack 头插SLPushFront 头删SLPopBck 尾删SLPopFront 易错点 本篇开始链表学习。今天主要是单链表&OJ题目。 单链…...
智慧农业:农林牧数据可视化监控平台
数字农业是一种现代农业方式,它将信息作为农业生产的重要元素,并利用现代信息技术进行农业生产过程的实时可视化、数字化设计和信息化管理。能将信息技术与农业生产的各个环节有机融合,对于改造传统农业和改变农业生产方式具有重要意义。 图扑…...
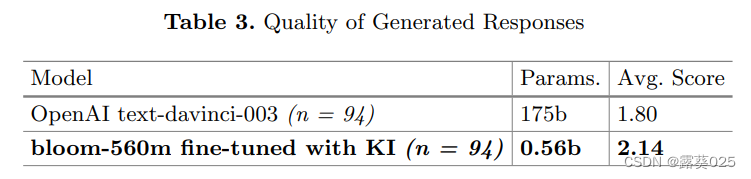
知识注入以对抗大型语言模型(LLM)的幻觉11.6
知识注入以对抗大型语言模型(LLM)的幻觉 摘要1 引言2 问题设置和实验2.1 幻觉2.2 生成响应质量 3 结果和讨论3.1 幻觉3.2 生成响应质量 4 结论和未来工作 摘要 大型语言模型(LLM)内容生成的一个缺点是产生幻觉,即在输…...

机器人物理交互场景及应用的实际意义
机器人物理交互场景是指机器人与物理世界或人类进行实际的物理互动和交互的情境。这些场景涉及机器人在不同环境和应用中使用其物理能力,以执行任务、提供服务或与人类互动。 医疗协助: 外科手术助手:机器人可以用于外科手术,提供…...
Kubernetes Dashboard 用户名密码方式登录
Author:rab 前言 为了 K8s 集群安全,默认情况下 Dashboard 以 Token 的形式登录的,那如果我们想以用户名/密码的方式登录该怎么操作呢?其实只需要我们创建用户并进行 ClusterRoleBinding 绑定即可,接下来是具体的操作…...

Redisson中的对象
Redisson - 是一个高级的分布式协调Redis客服端,能帮助用户在分布式环境中轻松实现一些Java的对象 (Bloom filter, BitSet, Set, SetMultimap, ScoredSortedSet, SortedSet, Map, ConcurrentMap, List, ListMultimap, Queue, BlockingQueue, Deque, BlockingDeque, …...

GNU ld链接器 lang_process()(二)
一、ldemul_create_output_section_statements() 位于lang_process()中11行 。 该函数用于创建与目标有关的输出段的语句。这些语句将用于描述输出段的属性和分配。 void ldemul_create_output_section_statements (void) {if (ld_emulation->create_output_section_sta…...
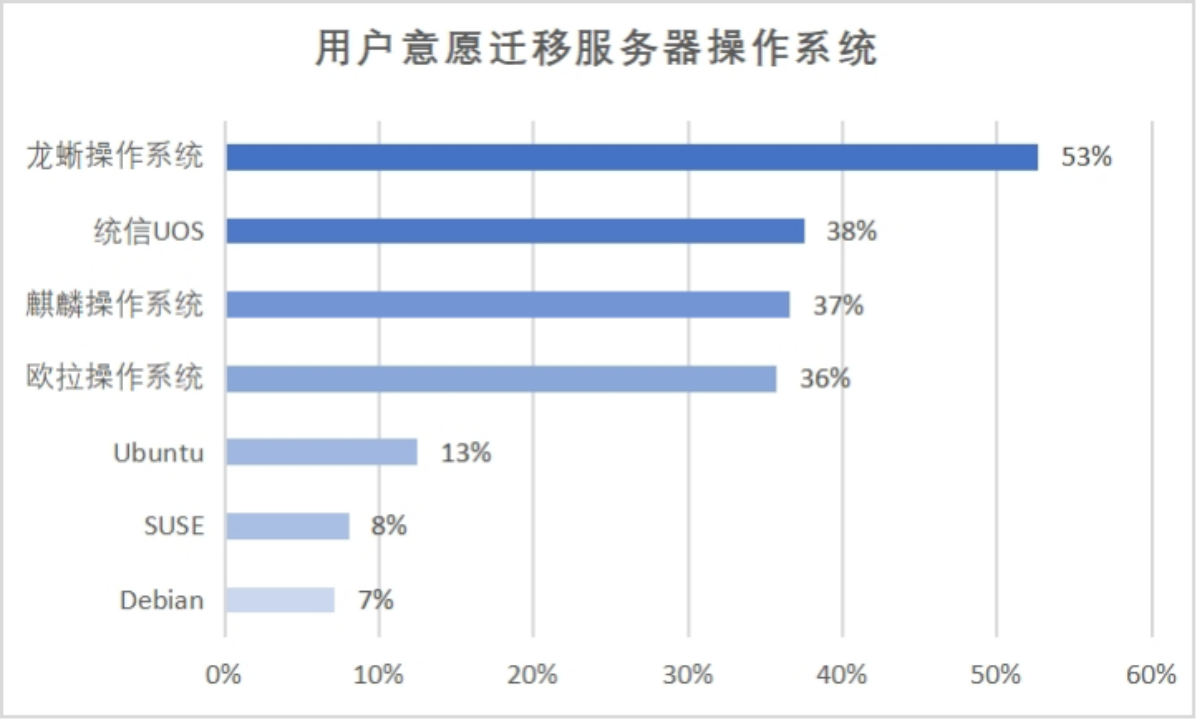
《国产服务器操作系统发展报告(2023)》重磅发布
11月1日,《国产服务器操作系统发展报告(2023)》(以下简称“报告”)在 2023 云栖大会上正式发布,开放原子开源基金会理事长孙文龙、中国信息通信研究院副总工程师石友康、阿里云基础软件部副总裁马涛、浪潮信…...
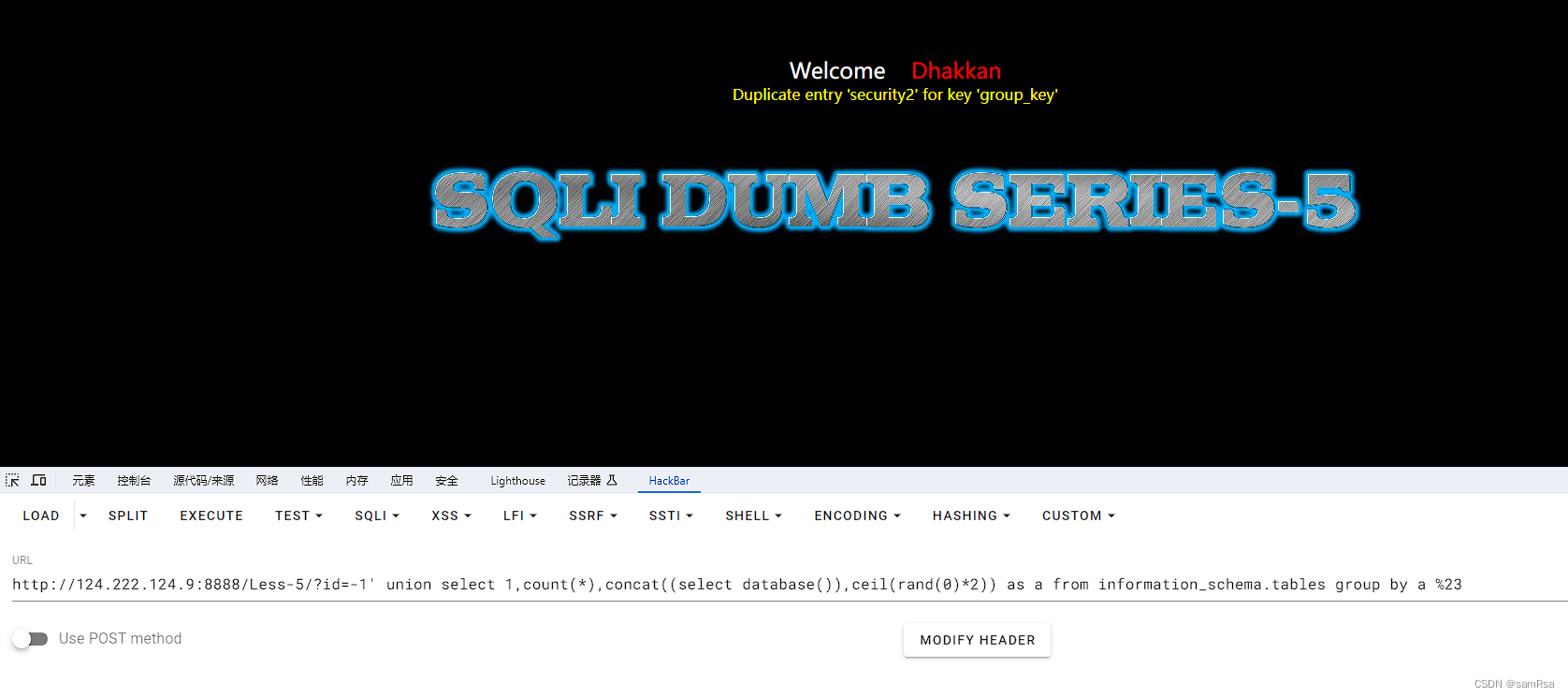
【PTE-day03 报错注入】
报错注入 1、报错注入 group by count2、报错注入 extractvalue3、报错注入updatexml1、报错注入 group by count http://124.222.124.9:8888/Less-5/?id=-1 union select 1,count(*),concat((select database()),ceil(rand(0)*2)) as a from information_schema.tables grou…...
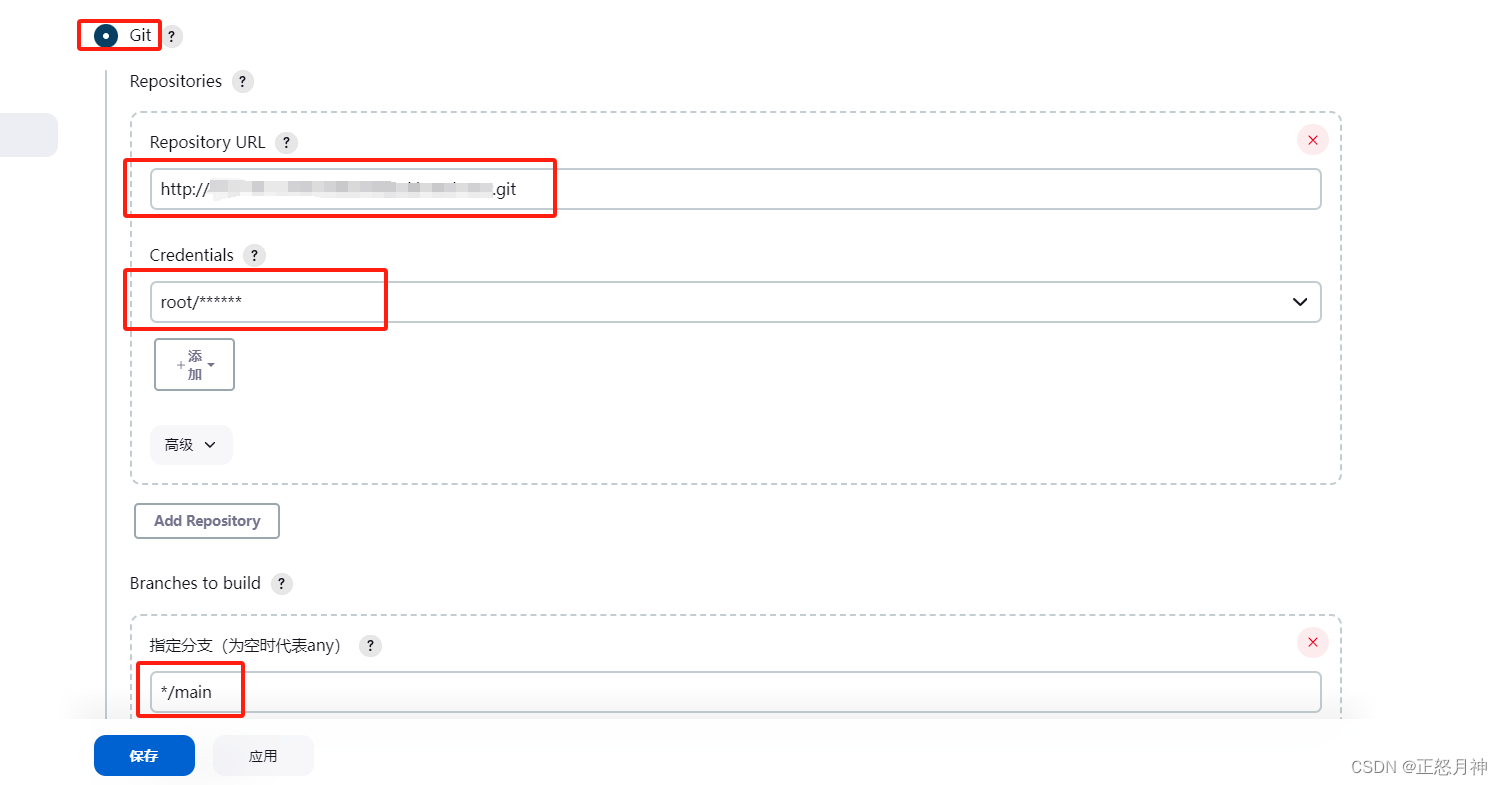
jenkins gitlab CI/CD
jenkins的安装教程就不说了:Jenkins docker 一键发布 (一)_jenkins 一键发布-CSDN博客 最近打算从svn切换到gitlab,所以配置了一下jenkins的git 很简单,直接上图 1 选择 Git 2 录入gitlab的http地址(由于我的git地址不是22端口&…...

Ventoy终极指南:一个U盘启动所有系统,告别重复格式化烦恼 [特殊字符]
Ventoy终极指南:一个U盘启动所有系统,告别重复格式化烦恼 😎 【免费下载链接】Ventoy A new bootable USB solution. 项目地址: https://gitcode.com/GitHub_Trending/ve/Ventoy 还在为每次安装系统都要重新制作启动盘而烦恼吗&#x…...

【DeepSeek-R1代码相似度引擎解密】:3层语义比对机制、Token归一化偏差修正与Jaccard阈值黄金分割点
更多请点击: https://kaifayun.com 第一章:DeepSeek代码重复检测 DeepSeek-R1 模型在训练过程中引入了严格的代码去重机制,其核心目标是消除训练语料中语义等价或高度相似的代码片段,从而提升模型对真实编程模式的学习能力与泛化…...

浅聊26上半年软考架构师
2026年上半年架构师考试已然落幕,大家都考的如何?架构师共有三门考试,上午综合知识(75道选择题)案例分析,时间为8.30-12.30;下午论文,时间为14.30-16.30。下面说说我整体的备考过程。…...

告别FTP龟速:用NTFS-3G在CentOS7上直连移动硬盘拷贝200G大文件
告别FTP龟速:用NTFS-3G在CentOS7上直连移动硬盘拷贝200G大文件当面对数百GB的设计素材、日志文件或数据库备份需要迁移时,传统的FTP传输往往会成为效率瓶颈。我曾在一个视频处理项目中,需要将230GB的4K原始素材从移动硬盘导入服务器ÿ…...

sudo企业级应用【20260525】001篇
文章目录 一、总体设计思路 1️⃣ 设计原则 2️⃣ 日志策略(重点) 二、10 个真实生产场景(含 sudoers 配置) 🔹 Linux 系统管理(3 个) ✅ 场景 1:基础运维(用户 / 权限) ✅ 场景 2:磁盘与文件系统 ✅ 场景 3:网络与防火墙 🔹 云管理(2 个) ✅ 场景 4:云 CLI …...

机器学习与SHAP在教育公平研究中的应用:精准定位学业困境根源
1. 项目概述:当机器学习遇见教育公平,我们如何精准定位学业困境的根源?在拉丁美洲的教育研究领域,一个长期困扰政策制定者和研究者的核心问题是:究竟是什么因素,在复杂的社会经济背景下,系统性地…...

LVGL多页面开发避坑:用内部Timer替代轮询,解决页面切换时的内存踩踏问题
LVGL多页面开发中的内存安全实践:用Timer机制替代轮询的工程解决方案 在嵌入式UI开发中,LVGL因其轻量级和跨平台特性成为热门选择。但当项目复杂度提升到多页面交互时,开发者往往会遇到一个棘手问题:如何在频繁切换页面的同时保证…...

yuzu模拟器完整指南:在电脑上畅玩Switch游戏的终极解决方案
yuzu模拟器完整指南:在电脑上畅玩Switch游戏的终极解决方案 【免费下载链接】yuzu 任天堂 Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/yu/yuzu 想在电脑上体验任天堂Switch游戏的魅力吗?yuzu模拟器正是你寻找的完美答案。作为…...

基于Max78000与规则引导的音频数据集构建:边缘AI声音识别实战
1. 项目概述:当边缘AI遇见棕榈树里的“窃听者”在边缘计算和物联网设备大行其道的今天,我们常常面临一个核心矛盾:一方面,我们希望设备足够“聪明”,能实时识别并响应特定的声音模式,比如工厂里高压阀门的异…...

CA-CFAR、GO-CFAR、SO-CFAR怎么选?一张图看懂三种恒虚警检测算法的适用场景与避坑指南
CA-CFAR、GO-CFAR、SO-CFAR工程选型指南:从算法原理到场景适配 雷达信号处理工程师常常面临一个经典难题:在复杂环境中如何选择合适的恒虚警检测算法?当海面杂波、多目标干扰或低信噪比条件同时出现时,CA、GO、SO三种CFAR变体的性…...