PySpark 优雅的解决依赖包管理
背景
平台所有的Spark任务都是采用Spark on yarn cluster的模式进行任务提交的,driver和executor随机分配在集群的各个节点,pySpark 由于python语言的性质,所以pySpark项目的依赖注定不能像java/scala项目那样把依赖打进jar包中轻松解决问题。所以本文主要目标就是解决pySpark在分布式的情况下,如何优雅的解决项目中的依赖问题,目前总结出如下三种办法供大家使用。
1、Nodemanager节点直接安装依赖
使用pip install 或者conda install 在每台nodemanager上安装所需依赖。
这个方法是最简单也是最优先能解决pySpark依赖的方法,但是缺点也十分明显。
优点: 操作简单,易上手,能快速解决依赖问题
缺点:1、每台nodemanager都需要安装依赖,并且未来新加入nodemanager的机器也需要安装依赖。如果未来新节点忘记安装就会导致失败。
2、直接在服务器上安装未经测试过得版本极有可能导致已经安装的python依赖与新依赖包冲突,导致大数据任务执行失败。对环境是一种污染和侵入。
适用范围:集群规模不大,用的人少,影响范围可控,想快速解决问题
2、Python zip项⽬
- pip freeze >requirements.txt
将本地的pip依赖写⼊到requirements.txt⽂件中,根据⾃⼰情况进⾏增删改。 - pip install -r requirements.txt --target ${PROJECT_NAME}
将依赖打⼊到项⽬当中,main⽅法和依赖要平级 - python -m zipapp ${PROJECT_NAME} -m “main:main”
打包出⼀个.pyz⽂件 - mv ${PROJECT_NAME}.pyz ${PROJECT_NAME}.zip
spark不仅支持提交单个.py文件执行,还支持提交整个zip包来执行,其中zip包中就包含了你所需要的简单依赖。
优点:引入的依赖简洁明了,并且调试起来也比较方便,毕竟打包时间快,方便提交任务,也不需要额外的任务。
缺点:不能控制python版本,用的python版本都是nodemanager上的python版本。
适用范围:引入的依赖不多,项目极小的情况下,并且不考虑依赖的复用。
3、Spark使⽤独⽴的Python虚拟环境提交任务
1、创建python的虚拟环境
- 搭建annaconda或找⼀台有annaconda环境的机器
- 创建虚拟环境,名字为sparkenv,包含模块pandas
conda create --name sparkenv --copy python=3.6.7(版本根据实际情况更改)
⽣成的⽬录在⽂件夹
/opt/anaconda2/envs/sparkenv
使⽤pip安装所需依赖
/opt/anaconda2/envs/sparkenv/bin/pip install ****=**
- 压缩成zip⽂件
1 cd /opt/anaconda2/envs/sparkenv
2 zip -r -q sparkenv.zip *
- 将sparkenv.zip⽂件上传⾄hdfs(一般都是放在hdfs的),如
hadoop fs -put /tmp/aaa/sparkenv.zip
2、任务配置Spark参数
- 配置[⾃定义配置]
--archives hdfs:///tmp/aaa/sparkenv.zip#test-sparkenv
这个配置加在spark -submit命令后就行。
- 配置[Spark Conf 配置]
1 spark.yarn.appMasterEnv.PYSPARK_PYTHON=test-sparkenv/bin/python3.6
2 spark.yarn.appMasterEnv.PYSPARK_DRIVER_PYTHON=test-sparkenv/bin/python3.6
3 spark.executorEnv.PYSPARK_PYTHON=test-sparkenv/bin/python3.6
4 spark.executorEnv.PYSPARK_DRIVER_PYTHON=test-sparkenv/bin/python3.6
上面这四个分别用–conf引入
比如 --conf spark.yarn.appMasterEnv.PYSPARK_PYTHON=test-sparkenv/bin/python3.6
优点:独立的python环境,想用什么版本的自己决定。基于业务的独立依赖包闭环,低依赖冲突风险。可实现依赖复用,多部门共用虚拟环境。
缺点:包很大,不论是上传包还是调试都非常麻烦。
适用环境:需要使⽤不⽤于服务器的python版本;并且引⼊的依赖错综复杂的场景,适合中大型的pySpark项目。
相关文章:

PySpark 优雅的解决依赖包管理
背景 平台所有的Spark任务都是采用Spark on yarn cluster的模式进行任务提交的,driver和executor随机分配在集群的各个节点,pySpark 由于python语言的性质,所以pySpark项目的依赖注定不能像java/scala项目那样把依赖打进jar包中轻松解决问题…...

UNI-APP_获取手机品牌
在uni-app中,使用uni.getSystemInfoSync().brand可以获取设备的品牌信息。根据不同设备的品牌,uni.getSystemInfoSync().brand可能返回以下一些常见值 “Apple” - 苹果 “Samsung” - 三星 “Huawei” - 华为 “Xiaomi” - 小米 “OPPO” - OPPO “Vivo…...

新登录接口独立版变现宝升级版知识付费小程序-多领域素材资源知识变现营销系统
源码简介: 资源入口 点击进入 源码亲测无bug,含前后端源码,非线传,修复最新登录接口 梦想贩卖机升级版,变现宝吸取了资源变现类产品的很多优点,摒弃了那些无关紧要的东西,使本产品在运营和变现…...

「掌握创意,释放想象」——Photoshop 2023,你的无限可能!
Adobe Photoshop 2023(PS2023) 来了,全世界数以百万计的设计师、摄影师和艺术家使用 Photoshop 将不可能变为可能。从海报到包装,从基本的横幅到漂亮的网站,从令人难忘的徽标到引人注目的图标,Photoshop 2023让创意世界不断前进。借助直观的工…...

SQLSugar查询返回DataTable
SQLSugar是一个用于执行SQL查询的C#库,它提供了简单易用的API接口来执行SQL查询。要查询返回DataTable,可以使用SQLSugar的QueryHelper类。 以下是一个示例代码,展示了如何使用SQLSugar的QueryHelper类查询返回DataTable: 首先&…...
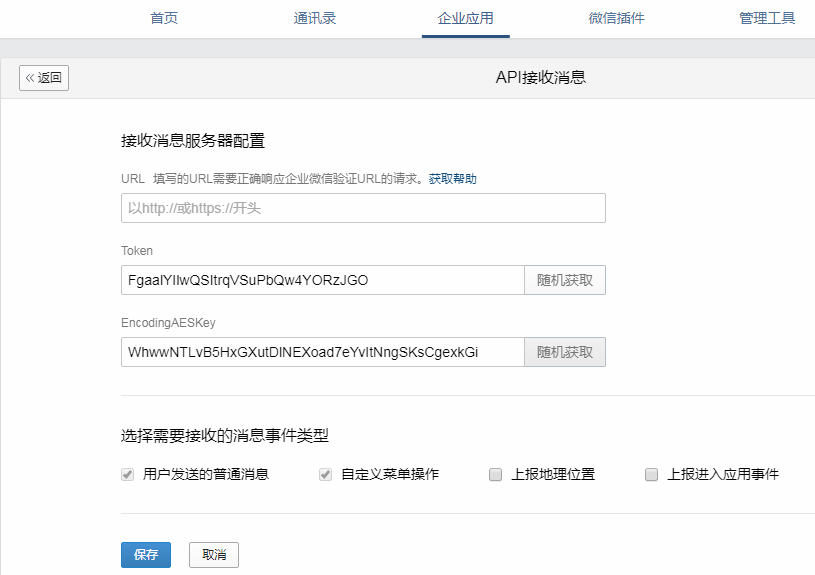
企业微信开启接收消息+验证URL有效性
企业微信开启接收消息验证URL有效性 📔 千寻简笔记介绍 千寻简笔记已开源,Gitee与GitHub搜索chihiro-notes,包含笔记源文件.md,以及PDF版本方便阅读,且是用了精美主题,阅读体验更佳,如果文章对…...

电脑访问不到在同网络的手机设备
手机连接了同网络的wifi,但是电脑ping不通手机的ip,这可能是路由出了问题,因为最终是走的mac地址,访问不了是因为电脑不知道手机的mac地址,则可以这样设置绑定mac地址,管理员权限启动cmd,然后执…...

国内MES系统应用研究报告:“企业MES应用现状”| 百世慧®
随着制造企业数字化转型需求的增强,工业软件的需求也不断被激发。 2022年,中国MES软件及服务市场规模实现23.8%的较高速增长。同时,随着工业互联网、MOM的兴起和不断发展,也推动着MES持续发展和不断迭代,如今MES向着更…...
C++模板元模板实战书籍讲解第一章题目讲解
目录 第一题 C代码示例 第二题 C代码示例 第三题 3.1 使用std::integral_constant模板类 3.2 使用std::conditional结合std::is_same判断 总结 第四题 C代码示例 第五题 C代码示例 第六题 C代码示例 第七题 C代码示例 总结 第一题 对于元函数来说,…...
)
Java在互联网网络安全中的应用(三)
目录 1. 互联网网络安全概述 2. Java的网络安全特性 3. 用Java加固网络应用 4. 安全传输 5. 安全框架和工具 6. 实际应用案例 7. 最佳实践和资源 目标 本次技术分享的目标是介绍Java技术在互联网网络安全中的应用,包括关键概念、最佳实践和实际案例。 1. 互…...

VMLogin如何解决跨境电商多账号管理难题?
做跨境电商的,比如亚马逊、eBay这些卖家。随着团队规模的扩大,或者多店铺运营,那么多个店铺多个账号管理就成为了一个困难。如何解决这个问题呢? 首先来看看很多电商卖家多账号管理会面临的问题 经营者通常需要同时管理多个市场…...
STM32创建工程步骤
以创建led工程为例: 新建一个led文件夹 新建一个以led命名的工程(用keil_uVision5)并添加三个组。 Library文件夹里放置库函数文件。 User: 点亮led灯的程序; 直接给寄存器赋值 调用库函数。 #include "stm…...
)
软考 系统架构设计师系列知识点之边缘计算(1)
所属章节: 第11章. 未来信息综合技术 第4节. 边缘计算概述 1. 边缘计算概念 在介绍边缘计算之前,有必要先介绍一下章鱼。章鱼就是用“边缘计算”来解决实际问题的。作为无脊椎动物中智商最高的一种动物,章鱼拥有巨量的神经元,但…...

vue:写一个数组box和list数组,在保留box数组中原有对象的同时,将list数组中每一个对象插入到box数组后面
前言:由于源码涉及到后端调用数据和一些无关的功能所以我就专门针对这个功能的代码,这样好方便理解。 1、在data中定义两个数组:box和list,并给它们初始化值 data() {return {box: [/*初始的box数组对象*/],list: [/*初始的list…...

Python教程:随机函数,开始猜英文单词的游戏
开始猜英文单词的游戏… 总计生命次数:3次 -----------游戏开始中…----------- ????请猜一个,4位数的单词:mafr 猜错了,再努力一下 -----------你还有2次生命------------ ma?&…...
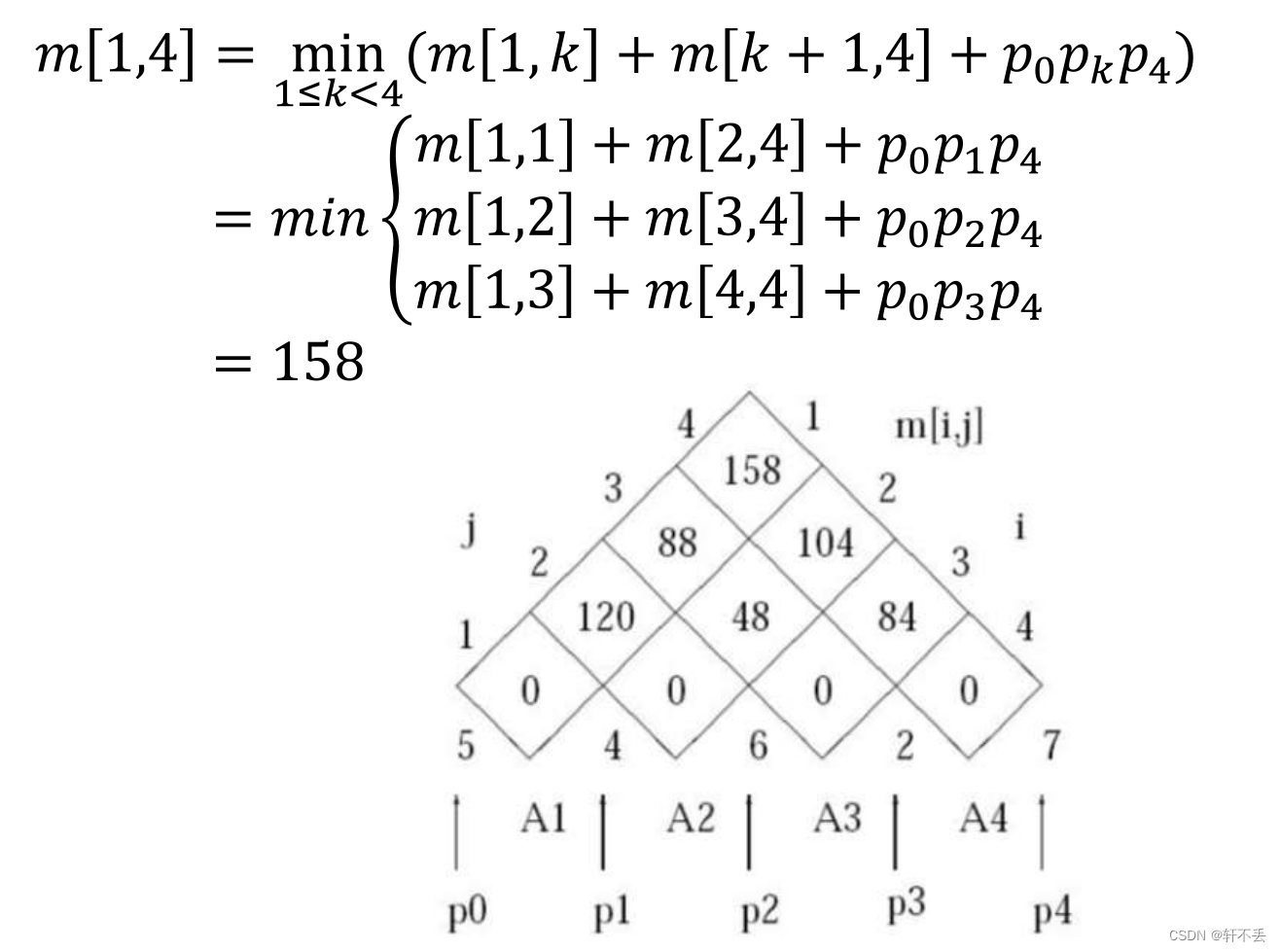
Unit2_1:动态规划DP
文章目录 一、介绍二、0-1背包问题问题描述分析伪代码时间复杂度 三、钢条切割问题问题描述分析伪代码过程 四、矩阵链乘法背景性质分析案例伪代码 一、介绍 动态规划类似于分治法,它们都将一个问题划分为更小的子问题 最优子结构:问题的最优解包含子问题的最优解。DP适用的原…...
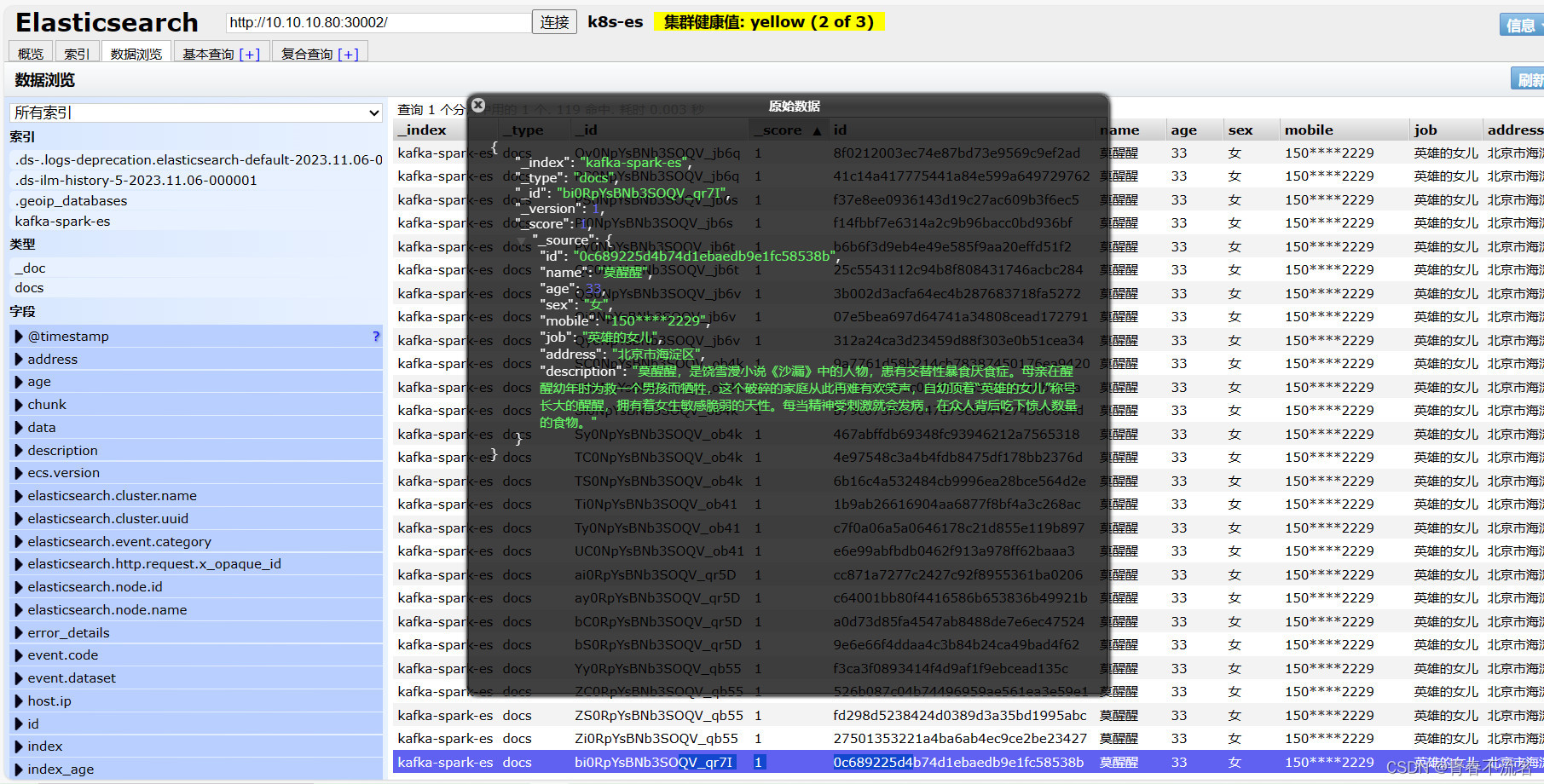
k8s提交spark应用消费kafka数据写入elasticsearch7
一、k8s集群环境 k8s 1.23版本,三个节点,容器运行时使用docker。 spark版本时3.3.3 k8s部署单节点的zookeeper、kafka、elasticsearch7 二、spark源码 https://download.csdn.net/download/TT1024167802/88509398 命令行提交方式 /opt/module/spark…...
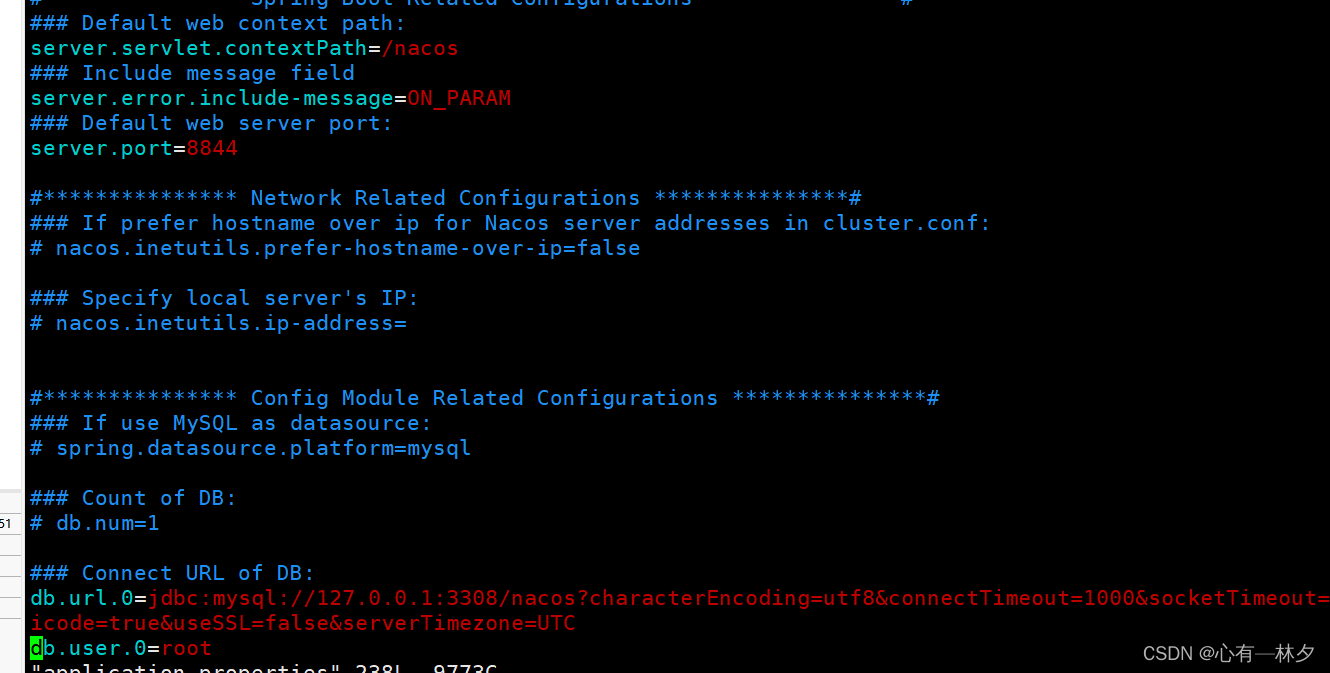
linux傻瓜式安装Java环境及中间件
linux配置Java环境及中间件 1.傻瓜式安装Java1.下载2.追加3.刷新测试 2.傻瓜式安装docker1.docker卸载2.docker安装 3.Docker傻瓜式安装Redis1.傻瓜式安装安装并配置 4.Docker傻瓜式安装RabbitMQ5.Docker傻瓜式安装MySql1.拉取2.配置 6.傻瓜式安装Nacos1.官网下载nacos2.SQL文件…...

javascript中的new原理及实现
在js中,我们通过new运算符来创建一个对象,它是一个高频的操作。我们一般只是去用它,而很少关注它是如何实现的,它的工作机制是什么。 1 简介 本文介绍new的功能,用法,补充介绍了不加new也同样创建对象的方…...

R语言 PPT 预习+复习
什么狗吧发明的结业考,站出来和我对线 第一章 绪论 吊码没有,就算考R语言特点我也不背,问就是叫么这没用。 第二章 R语言入门 x<-1:20 赋值语句 x 1到20在x上添加均值为0、标准差为2的正态分布噪声 y <- x rnorm (20, 0, 2) 这…...

Godot中型项目工程化实践:目录规范、资源引用与状态管理
1. 这不是续集,而是项目落地的分水岭“Godot 游戏引擎项目(二)”——看到这个标题,很多人第一反应是:“哦,上一篇讲了环境搭建和Hello World,这篇该讲节点树和信号了?”但我在带三个…...

IPD的势、道、法、术、器
目录 简介 一、势:为什么 IPD 是必然选择? 二、道:IPD 的底层哲学 三、法与术:从战略到执行的具体路径 四、器:让流程真正落地的工具与组织 不是每家公司都需要全套 IPD,但每家公司都需要 IPD 思维 简…...
)
别再乱用npm install了!手把手教你用npx only-allow为项目指定包管理器(支持pnpm/yarn/npm)
用only-allow统一团队包管理器:从配置到CI的全流程指南 你是否曾经在拉取一个新项目后,面对npm install、yarn还是pnpm i的抉择感到困惑?或者更糟的是,团队成员混用不同包管理器导致node_modules结构不一致,引发各种诡…...

从理论推导到代码实现:手把手教你用Python/Numpy写出守恒形式的NS方程求解器
从理论推导到代码实现:手把手教你用Python/Numpy写出守恒形式的NS方程求解器计算流体力学(CFD)的魅力在于它将抽象的数学方程转化为可执行的代码,让流体运动的奥秘在计算机中重现。对于已经掌握流体力学理论的中高级学习者来说&am…...

DIY复刻经典:Texar Audio Prism动态处理器克隆套件全攻略
1. 项目概述:Texar Audio Prism 克隆套件如果你在专业音频圈子里混过一段时间,尤其是对上世纪八九十年代那些经典的、带点“魔法”色彩的外置动态处理器感兴趣,那么“Texar Audio Prism”这个名字你大概率不会陌生。它不是最常见的1176或者LA…...

PlayAI语音合成质量到底如何?12款竞品横向对比+5项MOS/LSD/STOI硬指标揭榜
更多请点击: https://kaifayun.com 第一章:PlayAI语音合成质量评测报告 PlayAI 是一款面向开发者与内容创作者的实时语音合成(TTS)服务,支持多语种、多音色及情感可控输出。本报告基于客观可复现的评测流程࿰…...

华硕笔记本终极性能控制指南:用G-Helper完全替代Armoury Crate
华硕笔记本终极性能控制指南:用G-Helper完全替代Armoury Crate 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zen…...
)
【2025】AWVS安装保姆级教程(最新25.1.2可用)
【2025】AWVS安装保姆级教程(最新25.1.2可用) 文章目录 工具下载Host 重定向AWVS安装AWVS查看安装失败原因 工具下载 点击下载即可 下载完的工具后缀格式为.apk,需要将其改为.zip,然后将其解压得到以下工具后续安装使用 Host 重…...

Git Bash 中无法启动 Claude Code ?
最近需要在 git bash 中跑 Claude Code 。git bash 是随 git for windows 套件安装的,很久没更新了,结果启动 Claude Code 报错:Warning: no stdin data received in 3s, proceeding without it. If piping from a slow command, redirect st…...
)
从单体到事件驱动的生死跃迁:DeepSeek架构委员会认证的6阶段迁移路线图(含风险热力图与回滚触发阈值表)
更多请点击: https://codechina.net 第一章:从单体到事件驱动的生死跃迁:DeepSeek架构委员会认证的6阶段迁移路线图(含风险热力图与回滚触发阈值表) 向事件驱动架构(EDA)演进不是功能迭代&…...