第11章_数据处理之增删改
文章目录
- 1 插入数据
- 1.1 实际问题
- 1.2 方式 1:VALUES的方式添加
- 1.3 方式2:将查询结果插入到表中
- 演示代码
- 2 更新数据
- 演示代码
- 3 删除数据
- 演示代码
- 4 MySQL8新特性:计算列
- 演示代码
- 5 综合案例
- 课后练习
1 插入数据
1.1 实际问题
解决方式:使用 INSERT 语句向表中插入数据。
1.2 方式 1:VALUES的方式添加
使用这种语法一次只能向表中插入一条数据。
情况1:为表的所有字段按默认顺序插入数据
INSERT INTO 表名
VALUES (value1,value2,....);
值列表中需要为表的每一个字段指定值,并且值的顺序必须和数据表中字段定义时的顺序相同。
举例:
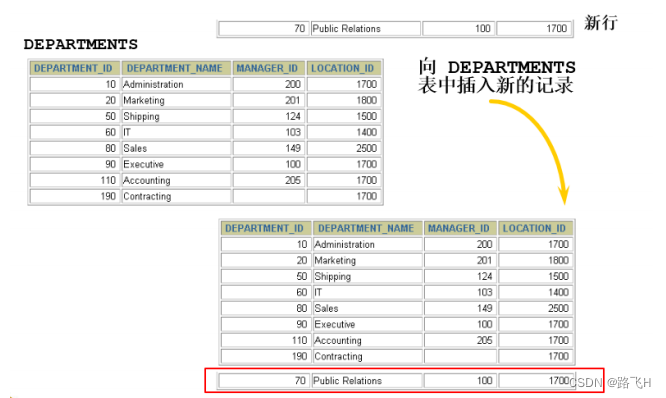
INSERT INTO departments
VALUES (70, 'Pub', 100, 1700);INSERT INTO departments
VALUES (100, 'Finance', NULL, NULL);
情况2:为表的指定字段插入数据
INSERT INTO 表名(column1 [, column2, …, columnn])
VALUES (value1 [,value2, …, valuen]);
为表的指定字段插入数据,就是在INSERT语句中只向部分字段中插入值,而其他字段的值为表定义时的默认值。
在 INSERT 子句中随意列出列名,但是一旦列出,VALUES中要插入的value1,…valuen需要与column1,…columnn列一一对应。如果类型不同,将无法插入,并且MySQL会产生错误。
举例:
INSERT INTO departments(department_id, department_name)
VALUES (80, 'IT');
情况3:同时插入多条记录
INSERT语句可以同时向数据表中插入多条记录,插入时指定多个值列表,每个值列表之间用逗号分隔开,基本语法格式如下:
INSERT INTO table_name
VALUES
(value1 [,value2, …, valuen]),
(value1 [,value2, …, valuen]),
……
(value1 [,value2, …, valuen]);
或者
INSERT INTO table_name(column1 [, column2, …, columnn])
VALUES
(value1 [,value2, …, valuen]),
(value1 [,value2, …, valuen]),
……
(value1 [,value2, …, valuen]);
举例:
INSERT INTO emp(emp_id,emp_name)
VALUES (1001,'shkstart'),
(1002,'atguigu'),
(1003,'Tom');
#Query OK, 3 rows affected (0.00 sec)
#Records: 3 Duplicates: 0 Warnings: 0
使用INSERT同时插入多条记录时,MySQL会返回一些在执行单行插入时没有的额外信息,这些信息的含义如下:
- Records:表明插入的记录条数
- Duplicates:表明插入时被忽略的记录,原因可能是这些记录包含了重复的主键值。
- Warnings:表明有问题的数据值,例如发生数据类型转换。
一个同时插入多行记录的INSERT语句等同于多个单行插入的INSERT语句,但是多行的INSERT语句在处理过程中 效率更高 。因为MySQL执行单条INSERT语句插入多行数据比使用多条INSERT语句快,所以在插入多条记录时最好选择使用单条INSERT语句的方式插入。
小结:
- VALUES 也可以写成 VALUE ,但是VALUES是标准写法。
- 字符和日期型数据应包含在单引号中
1.3 方式2:将查询结果插入到表中
INSERT还可以将SELECT语句查询的结果插入到表中,此时不需要把每一条记录的值一个一个输入,只需要使用一条INSERT语句和一条SELECT语句组成的组合语句即可快速地从一个或多个表中向一个表中插入多行。
基本语法格式如下:
INSERT INTO 目标表名
(tar_column1 [, tar_column2, …, tar_columnn])
SELECT
(src_column1 [, src_column2, …, src_columnn])
FROM 源表名
[WHERE condition]
- 在 INSERT 语句中加入子查询。
- 不必书写 VALUES 子句。
- 子查询中的值列表应与 INSERT 子句中的列名对应。
举例:
INSERT INTO emp2
SELECT *
FROM employees
WHERE department_id = 90;INSERT INTO sales_reps(id, name, salary, commission_pct)
SELECT employee_id, last_name, salary, commission_pct
FROM employees
WHERE job_id LIKE '%REP%';
演示代码
#0. 储备工作
USE atguigudb;CREATE TABLE IF NOT EXISTS emp1(
id INT,
`name` VARCHAR(15),
hire_date DATE,
salary DOUBLE(10,2)
);DESC emp1;
/*
+-----------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-----------+--------------+------+-----+---------+-------+
| id | int | YES | | NULL | |
| name | varchar(15) | YES | | NULL | |
| hire_date | date | YES | | NULL | |
| salary | double(10,2) | YES | | NULL | |
+-----------+--------------+------+-----+---------+-------+
*/SELECT *
FROM emp1;#Empty set (0.12 sec)#1. 添加数据
#方式1:一条一条的添加数据# ① 没有指明添加的字段
#正确的
INSERT INTO emp1
VALUES (1,'Tom','2000-12-21',3400); #注意:一定要按照声明的字段的先后顺序添加
#错误的
INSERT INTO emp1
VALUES (2,3400,'2000-12-21','Jerry');SELECT *
FROM emp1;
/*
+------+------+------------+---------+
| id | name | hire_date | salary |
+------+------+------------+---------+
| 1 | Tom | 2000-12-21 | 3400.00 |
+------+------+------------+---------+
*/# ② 指明要添加的字段 (推荐)
INSERT INTO emp1(id,hire_date,salary,`name`)
VALUES(2,'1999-09-09',4000,'Jerry');
# 说明:没有进行赋值的hire_date 的值为 null
INSERT INTO emp1(id,salary,`name`)
VALUES(3,4500,'shk');SELECT *
FROM emp1;
/*
+------+-------+------------+---------+
| id | name | hire_date | salary |
+------+-------+------------+---------+
| 1 | Tom | 2000-12-21 | 3400.00 |
| 2 | Jerry | 1999-09-09 | 4000.00 |
| 3 | shk | NULL | 4500.00 |
+------+-------+------------+---------+
*/# ③ 同时插入多条记录 (推荐)
INSERT INTO emp1(id,NAME,salary)
VALUES
(4,'Jim',5000),
(5,'张俊杰',5500);#方式2:将查询结果插入到表中
SELECT * FROM emp1;
/*输出
+------+-----------+------------+---------+
| id | name | hire_date | salary |
+------+-----------+------------+---------+
| 1 | Tom | 2000-12-21 | 3400.00 |
| 2 | Jerry | 1999-09-09 | 4000.00 |
| 3 | shk | NULL | 4500.00 |
| 4 | Jim | NULL | 5000.00 |
| 5 | 张俊杰 | NULL | 5500.00 |
+------+-----------+------------+---------+
*/INSERT INTO emp1(id,NAME,salary,hire_date)
#查询语句
SELECT employee_id,last_name,salary,hire_date # 查询的字段一定要与添加到的表的字段一一对应
FROM employees
WHERE department_id IN (70,60);DESC emp1;
DESC employees;SELECT *
FROM emp1;
/*
+------+-----------+------------+----------+
| id | name | hire_date | salary |
+------+-----------+------------+----------+
| 1 | Tom | 2000-12-21 | 3400.00 |
| 2 | Jerry | 1999-09-09 | 4000.00 |
*/
#说明:emp1表中要添加数据的字段的长度不能低于employees表中查询的字段的长度。
# 如果emp1表中要添加数据的字段的长度低于employees表中查询的字段的长度的话,就有添加不成功的风险。
2 更新数据
使用 UPDATE 语句更新数据。语法如下:
UPDATE table_name
SET column1=value1, column2=value2, … , column=valuen [WHERE condition]
- 可以一次更新多条数据。
- 如果需要回滚数据,需要保证在DML前,进行设置:SET AUTOCOMMIT = FALSE;
使用 WHERE 子句指定需要更新的数据。
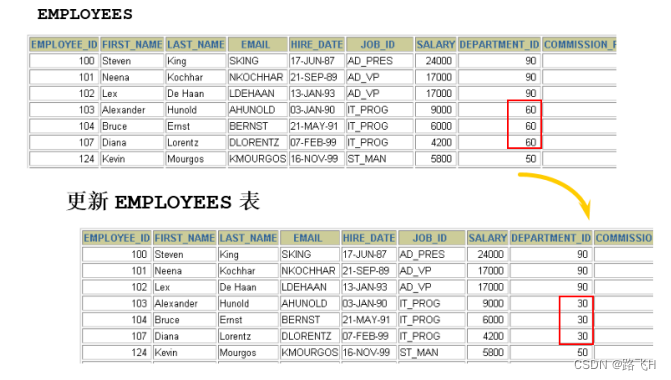
UPDATE employees
SET department_id = 70
WHERE employee_id = 113;
如果省略 WHERE 子句,则表中的所有数据都将被更新
UPDATE copy_emp
SET department_id = 110;
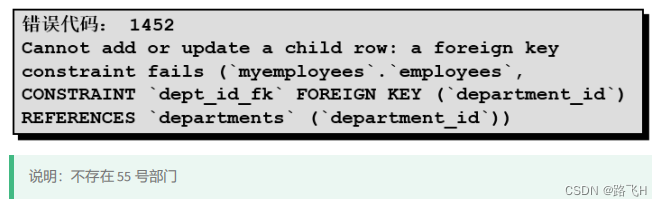
更新中的数据完整性错误
UPDATE employees
SET department_id = 55
WHERE department_id = 110;
#说明:不存在 55 号部门
演示代码
#2. 更新数据 (或修改数据)
# UPDATE .... SET .... WHERE ...
# 可以实现批量修改数据的。UPDATE emp1
SET hire_date = CURDATE()
WHERE id = 5;SELECT * FROM emp1;
/*部分输出
+------+-----------+------------+----------+
| id | name | hire_date | salary |
+------+-----------+------------+----------+
| 1 | Tom | 2000-12-21 | 3400.00 |
| 2 | Jerry | 1999-09-09 | 4000.00 |
| 3 | shk | NULL | 4500.00 |
| 4 | Jim | NULL | 5000.00 |
| 5 | 张俊杰 | 2022-02-14 | 5500.00 |
*/#同时修改一条数据的多个字段
UPDATE emp1
SET hire_date = CURDATE(),salary = 6000
WHERE id = 2;
/*输出
+------+-----------+------------+----------+
| id | name | hire_date | salary |
+------+-----------+------------+----------+
| 1 | Tom | 2000-12-21 | 3400.00 |
| 2 | Jerry | 2022-02-14 | 6000.00 |
*/#题目:将表中姓名中包含字符a的提薪20%
UPDATE emp1
SET salary = salary * 1.2
WHERE NAME LIKE '%r%';
/*
+------+-----------+------------+----------+
| id | name | hire_date | salary |
+------+-----------+------------+----------+
| 1 | Tom | 2000-12-21 | 3400.00 |
| 2 | Jerry | 2022-02-14 | 7200.00 |
*/#修改数据时,是可能存在不成功的情况的。(可能是由于约束的影响造成的)
UPDATE employees
SET department_id = 10000
WHERE employee_id = 102;
3 删除数据
- 使用 DELETE 语句从表中删除数据
DELETE FROM table_name [WHERE <condition>];
table_name指定要执行删除操作的表;“[WHERE ]”为可选参数,指定删除条件,如果没有WHERE子句,DELETE语句将删除表中的所有记录。 - 使用 WHERE 子句删除指定的记录。
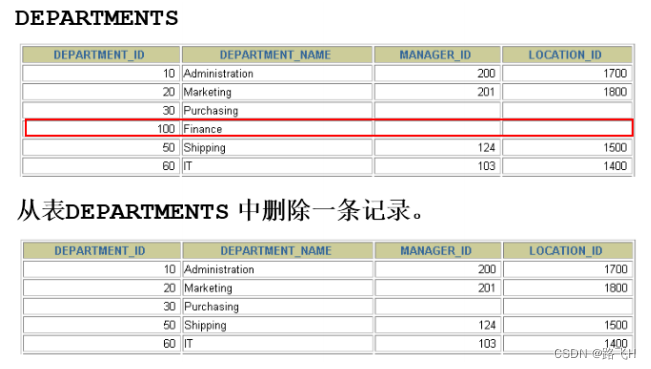
DELETE FROM departments
WHERE department_name = 'Finance';
- 如果省略 WHERE 子句,则表中的全部数据将被删除
DELETE FROM copy_emp; - 删除中的数据完整性错误
DELETE FROM departments
WHERE department_id = 60;

演示代码
#3. 删除数据 DELETE FROM .... WHERE....
DELETE FROM emp1
WHERE id = 1;
/*SELECT * FROM emp1;输出
+------+-----------+------------+----------+
| id | name | hire_date | salary |
+------+-----------+------------+----------+
| 2 | Jerry | 2022-02-14 | 7200.00 |
| 3 | shk | NULL | 4500.00 |
| 4 | Jim | NULL | 5000.00 |
*/
#在删除数据时,也有可能因为约束的影响,导致删除失败
DELETE FROM departments
WHERE department_id = 50;
#小结:DML操作默认情况下,执行完以后都会自动提交数据。
# 如果希望执行完以后不自动提交数据,则需要使用 SET autocommit = FALSE.
4 MySQL8新特性:计算列
什么叫计算列呢?简单来说就是某一列的值是通过别的列计算得来的。例如,a列值为1、b列值为2,c列不需要手动插入,定义a+b的结果为c的值,那么c就是计算列,是通过别的列计算得来的。
在MySQL 8.0中,CREATE TABLE 和 ALTER TABLE 中都支持增加计算列。下面以CREATE TABLE为例进行讲解。
举例:定义数据表tb1,然后定义字段id、字段a、字段b和字段c,其中字段c为计算列,用于计算a+b的值。 首先创建测试表tb1,语句如下:
CREATE TABLE tb1(
id INT,
a INT, b INT,
c INT GENERATED ALWAYS AS (a + b) VIRTUAL );
插入演示数据,语句如下:
INSERT INTO tb1(a,b) VALUES (100,200);
查询数据表tb1中的数据,结果如下:
SELECT * FROM tb1;
/*
+ ------ +------ +------ +------ +
| id | a | b | c |
+ ------ +------ +------ +------ +
| NULL | 100 | 200 | 300 |
+ ------ +------ +------ +------ +
1 row in set (0.00 sec)
*/
更新数据中的数据,语句如下:
UPDATE tb1 SET a = 500;
演示代码
#4. MySQL8的新特性:计算列
USE atguigudb;CREATE TABLE test1(
a INT,
b INT,
c INT GENERATED ALWAYS AS (a + b) VIRTUAL #字段c即为计算列
);INSERT INTO test1(a,b)
VALUES(10,20);SELECT * FROM test1;
/*输出
+------+------+------+
| a | b | c |
+------+------+------+
| 10 | 20 | 30 |
+------+------+------+
*/
UPDATE test1
SET a = 100;
/*SELECT * FROM test1;
+------+------+------+
| a | b | c |
+------+------+------+
| 100 | 20 | 120 |
+------+------+------+
*/
5 综合案例
# 1、创建数据库test01_library
# 2、创建表 books,表结构如下:
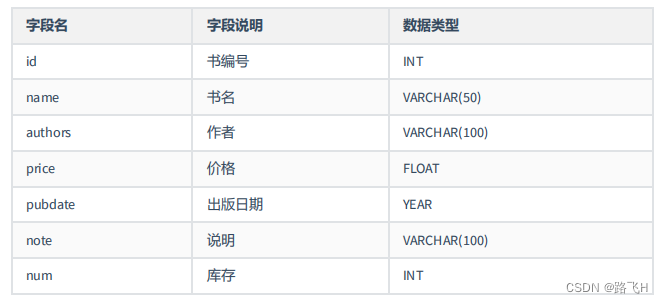
# 3、向books表中插入记录
# 1)不指定字段名称,插入第一条记录
# 2)指定所有字段名称,插入第二记录
# 3)同时插入多条记录(剩下的所有记录)
# 4、将小说类型(novel)的书的价格都增加5。
# 5、将名称为EmmaT的书的价格改为40,并将说明改为drama。
# 6、删除库存为0的记录。
# 7、统计书名中包含a字母的书
# 8、统计书名中包含a字母的书的数量和库存总量
# 9、找出“novel”类型的书,按照价格降序排列
# 10、查询图书信息,按照库存量降序排列,如果库存量相同的按照note升序排列
# 11、按照note分类统计书的数量
# 12、按照note分类统计书的库存量,显示库存量超过30本的
# 13、查询所有图书,每页显示5本,显示第二页
# 14、按照note分类统计书的库存量,显示库存量最多的
# 15、查询书名达到10个字符的书,不包括里面的空格
# 16、查询书名和类型,其中note值为novel显示小说,law显示法律,medicine
# 显示医药,cartoon显示卡通,joke显示笑话
# 17、查询书名、库存,其中num值超过30本的,显示滞销,大于0并低于10的,
# 显示畅销,为0的显示需要无货
# 18、统计每一种note的库存量,并合计总量
# 19、统计每一种note的数量,并合计总量
# 20、统计库存量前三名的图书
# 21、找出最早出版的一本书
# 22、找出novel中价格最高的一本书
# 23、找出书名中字数最多的一本书,不含空格
答案:
#5.综合案例
# 1、创建数据库test01_library
CREATE DATABASE IF NOT EXISTS test01_library CHARACTER SET 'utf8';USE test01_library;# 2、创建表 books,表结构如下:
CREATE TABLE IF NOT EXISTS books(
id INT,
`name` VARCHAR(50),
`authors` VARCHAR(100),
price FLOAT,
pubdate YEAR,
note VARCHAR(100),
num INT
);DESC books;
/*
+---------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+---------+--------------+------+-----+---------+-------+
| id | int | YES | | NULL | |
| name | varchar(50) | YES | | NULL | |
| authors | varchar(100) | YES | | NULL | |
| price | float | YES | | NULL | |
| pubdate | year | YES | | NULL | |
| note | varchar(100) | YES | | NULL | |
| num | int | YES | | NULL | |
+---------+--------------+------+-----+---------+-------+
*/
SELECT * FROM books;# 3、向books表中插入记录
# 1)不指定字段名称,插入第一条记录
INSERT INTO books
VALUES(1,'Tal of AAA','Dickes',23,'1995','novel',11);
# 2)指定所有字段名称,插入第二记录
INSERT INTO books(id,NAME,AUTHORS,price,pubdate,note,num)
VALUES(2,'EmmaT','Jane lura',35,'1993','joke',22);
# 3)同时插入多条记录(剩下的所有记录)
INSERT INTO books(id,NAME,AUTHORS,price,pubdate,note,num)
VALUES
(3,'Story of Jane','Jane Tim',40,2001,'novel',0),
(4,'Lovey Day','George Byron',20,2005,'novel',30),
(5,'Old land','Honore Blade',30,2010,'Law',0),
(6,'The Battle','Upton Sara',30,1999,'medicine',40),
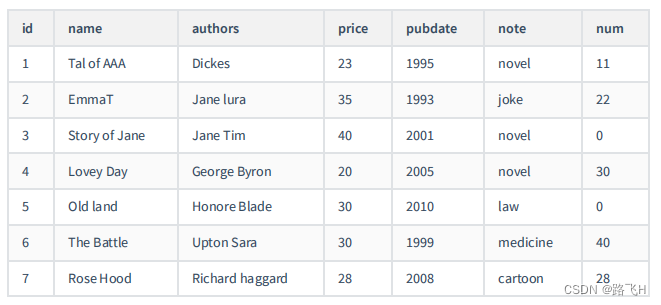
(7,'Rose Hood','Richard haggard',28,2008,'cartoon',28);/*SELECT * FROM books
+------+---------------+-----------------+-------+---------+----------+------+
| id | name | authors | price | pubdate | note | num |
+------+---------------+-----------------+-------+---------+----------+------+
| 1 | Tal of AAA | Dickes | 23 | 1995 | novel | 11 |
| 2 | EmmaT | Jane lura | 35 | 1993 | joke | 22 |
| 3 | Story of Jane | Jane Tim | 40 | 2001 | novel | 0 |
| 4 | Lovey Day | George Byron | 20 | 2005 | novel | 30 |
| 5 | Old land | Honore Blade | 30 | 2010 | Law | 0 |
| 6 | The Battle | Upton Sara | 30 | 1999 | medicine | 40 |
| 7 | Rose Hood | Richard haggard | 28 | 2008 | cartoon | 28 |
+------+---------------+-----------------+-------+---------+----------+------+
*/
# 4、将小说类型(novel)的书的价格都增加5。
UPDATE books
SET price = price + 5
WHERE note = 'novel';
/*
+------+---------------+-----------------+-------+---------+----------+------+
| id | name | authors | price | pubdate | note | num |
+------+---------------+-----------------+-------+---------+----------+------+
| 1 | Tal of AAA | Dickes | 28 | 1995 | novel | 11 |
| 2 | EmmaT | Jane lura | 35 | 1993 | joke | 22 |
| 3 | Story of Jane | Jane Tim | 45 | 2001 | novel | 0 |
| 4 | Lovey Day | George Byron | 25 | 2005 | novel | 30 |
| 5 | Old land | Honore Blade | 30 | 2010 | Law | 0 |
| 6 | The Battle | Upton Sara | 30 | 1999 | medicine | 40 |
| 7 | Rose Hood | Richard haggard | 28 | 2008 | cartoon | 28 |
+------+---------------+-----------------+-------+---------+----------+------+
*/# 5、将名称为EmmaT的书的价格改为40,并将说明改为drama。
UPDATE books
SET price = 40,note = 'drama'
WHERE NAME = 'EmmaT';# 6、删除库存为0的记录。
DELETE FROM books
WHERE num = 0;# 7、统计书名中包含a字母的书
SELECT NAME
FROM books
WHERE NAME LIKE '%a%';
/*
+------------+
| NAME |
+------------+
| Tal of AAA |
| EmmaT |
| Lovey Day |
| The Battle |
+------------+
*/# 8、统计书名中包含a字母的书的数量和库存总量
SELECT COUNT(*),SUM(num)
FROM books
WHERE NAME LIKE '%a%';# 9、找出“novel”类型的书,按照价格降序排列SELECT NAME,note,price
FROM books
WHERE note = 'novel'
ORDER BY price DESC;# 10、查询图书信息,按照库存量降序排列,如果库存量相同的按照note升序排列
SELECT *
FROM books
ORDER BY num DESC,note ASC;# 11、按照note分类统计书的数量
SELECT note,COUNT(*)
FROM books
GROUP BY note;# 12、按照note分类统计书的库存量,显示库存量超过30本的
SELECT note,SUM(num)
FROM books
GROUP BY note
HAVING SUM(num) > 30;# 13、查询所有图书,每页显示5本,显示第二页
SELECT *
FROM books
LIMIT 5,5;# 14、按照note分类统计书的库存量,显示库存量最多的
SELECT note,SUM(num) sum_num
FROM books
GROUP BY note
ORDER BY sum_num DESC
LIMIT 0,1;# 15、查询书名达到10个字符的书,不包括里面的空格
SELECT CHAR_LENGTH(REPLACE(NAME,' ',''))
FROM books;SELECT NAME
FROM books
WHERE CHAR_LENGTH(REPLACE(NAME,' ','')) >= 10;# 16、查询书名和类型,其中note值为novel显示小说,law显示法律,medicine显示医药,
#cartoon显示卡通,joke显示笑话
SELECT NAME "书名",note,CASE note WHEN 'novel' THEN '小说'WHEN 'law' THEN '法律'WHEN 'medicine' THEN '医药'WHEN 'cartoon' THEN '卡通'WHEN 'joke' THEN '笑话'ELSE '其他'END "类型"
FROM books;
/*
+------------+----------+--------+
| 书名 | note | 类型 |
+------------+----------+--------+
| Tal of AAA | novel | 小说 |
| EmmaT | drama | 其他 |
| Lovey Day | novel | 小说 |
| The Battle | medicine | 医药 |
| Rose Hood | cartoon | 卡通 |
+------------+----------+--------+
*/# 17、查询书名、库存,其中num值超过30本的,显示滞销,大于0并低于10的,
#显示畅销,为0的显示需要无货
SELECT NAME AS "书名",num AS "库存", CASE WHEN num > 30 THEN '滞销'WHEN num > 0 AND num < 10 THEN '畅销'WHEN num = 0 THEN '无货'ELSE '正常'END "显示状态"
FROM books;
/*
+------------+--------+--------------+
| 书名 | 库存 | 显示状态 |
+------------+--------+--------------+
| Tal of AAA | 11 | 正常 |
| EmmaT | 22 | 正常 |
| Lovey Day | 30 | 正常 |
| The Battle | 40 | 滞销 |
| Rose Hood | 28 | 正常 |
+------------+--------+--------------+*/# 18、统计每一种note的库存量,并合计总量
SELECT IFNULL(note,'合计库存总量') AS note,SUM(num)
FROM books
GROUP BY note WITH ROLLUP;
/*
+--------------------+----------+
| note | SUM(num) |
+--------------------+----------+
| cartoon | 28 |
| drama | 22 |
| medicine | 40 |
| novel | 41 |
| 合计库存总量 | 131 |
+--------------------+----------+
*/# 19、统计每一种note的数量,并合计总量
SELECT IFNULL(note,'合计总量') AS note,COUNT(*)
FROM books
GROUP BY note WITH ROLLUP;
/*
+--------------+----------+
| note | COUNT(*) |
+--------------+----------+
| cartoon | 1 |
| drama | 1 |
| medicine | 1 |
| novel | 2 |
| 合计总量 | 5 |
+--------------+----------+
*/# 20、统计库存量前三名的图书
SELECT *
FROM books
ORDER BY num DESC
LIMIT 0,3;# 21、找出最早出版的一本书
SELECT *
FROM books
ORDER BY pubdate ASC
LIMIT 0,1;# 22、找出novel中价格最高的一本书
SELECT *
FROM books
WHERE note = 'novel'
ORDER BY price DESC
LIMIT 0,1;# 23、找出书名中字数最多的一本书,不含空格
SELECT *
FROM books
ORDER BY CHAR_LENGTH(REPLACE(NAME,' ','')) DESC
LIMIT 0,1;
课后练习
#第11章_数据处理之增删改的课后练习
#练习1:
#1. 创建数据库dbtest11
CREATE DATABASE IF NOT EXISTS dbtest11 CHARACTER SET 'utf8';#2. 运行以下脚本创建表my_employees
USE dbtest11;CREATE TABLE my_employees(id INT(10),first_name VARCHAR(10),last_name VARCHAR(10),userid VARCHAR(10),salary DOUBLE(10,2)
);CREATE TABLE users(id INT,userid VARCHAR(10),department_id INT
);
#3.显示表my_employees的结构DESC my_employees;
/*
+------------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+------------+--------------+------+-----+---------+-------+
| id | int | YES | | NULL | |
| first_name | varchar(10) | YES | | NULL | |
| last_name | varchar(10) | YES | | NULL | |
| userid | varchar(10) | YES | | NULL | |
| salary | double(10,2) | YES | | NULL | |
+------------+--------------+------+-----+---------+-------+
*/
DESC users;
/*
+---------------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+---------------+-------------+------+-----+---------+-------+
| id | int | YES | | NULL | |
| userid | varchar(10) | YES | | NULL | |
| department_id | int | YES | | NULL | |
+---------------+-------------+------+-----+---------+-------+
*/#4.向my_employees表中插入下列数据
ID FIRST_NAME LAST_NAME USERID SALARY
1 patel Ralph Rpatel 895
2 Dancs Betty Bdancs 860
3 Biri Ben Bbiri 1100
4 Newman Chad Cnewman 750
5 Ropeburn Audrey Aropebur 1550INSERT INTO my_employees
VALUES(1,'patel','Ralph','Rpatel',895);INSERT INTO my_employees VALUES
(2,'Dancs','Betty','Bdancs',860),
(3,'Biri','Ben','Bbiri',1100),
(4,'Newman','Chad','Cnewman',750),
(5,'Ropeburn','Audrey','Aropebur',1550);SELECT * FROM my_employees;
/*
+------+------------+-----------+----------+---------+
| id | first_name | last_name | userid | salary |
+------+------------+-----------+----------+---------+
| 1 | patel | Ralph | Rpatel | 895.00 |
| 2 | Dancs | Betty | Bdancs | 860.00 |
| 3 | Biri | Ben | Bbiri | 1100.00 |
| 4 | Newman | Chad | Cnewman | 750.00 |
| 5 | Ropeburn | Audrey | Aropebur | 1550.00 |
+------+------------+-----------+----------+---------+
*/DELETE FROM my_employees;#方式2:
INSERT INTO my_employees
SELECT 1,'patel','Ralph','Rpatel',895 UNION ALL
SELECT 2,'Dancs','Betty','Bdancs',860 UNION ALL
SELECT 3,'Biri','Ben','Bbiri',1100 UNION ALL
SELECT 4,'Newman','Chad','Cnewman',750 UNION ALL
SELECT 5,'Ropeburn','Audrey','Aropebur',1550;#5.向users表中插入数据
1 Rpatel 10
2 Bdancs 10
3 Bbiri 20
4 Cnewman 30
5 Aropebur 40
INSERT INTO users VALUES
(1,'Rpatel',10),
(2,'Bdancs',10),
(3,'Bbiri',20),
(4,'Cnewman',30),
(5,'Aropebur',40)SELECT * FROM users;#6. 将3号员工的last_name修改为“drelxer”
UPDATE my_employees
SET last_name = 'drelxer'
WHERE id = 3;#7. 将所有工资少于900的员工的工资修改为1000
UPDATE my_employees
SET salary = 1000
WHERE salary < 900;#8. 将userid为Bbiri的users表和my_employees表的记录全部删除#方式1:
DELETE FROM my_employees
WHERE userid = 'Bbiri';DELETE FROM users
WHERE userid = 'Bbiri';#方式2:DELETE m,u
FROM my_employees m
JOIN users u
ON m.userid = u.userid
WHERE m.userid = 'Bbiri';SELECT * FROM my_employees;
SELECT * FROM users;#9. 删除my_employees、users表所有数据
DELETE FROM my_employees;
DELETE FROM users;#10. 检查所作的修正
SELECT * FROM my_employees;
SELECT * FROM users;#11. 清空表my_employees
TRUNCATE TABLE my_employees;
##########################################
#练习2:
# 1. 使用现有数据库dbtest11
USE dbtest11;# 2. 创建表格pet
CREATE TABLE pet(
NAME VARCHAR(20),
OWNER VARCHAR(20),
species VARCHAR(20),
sex CHAR(1),
birth YEAR,
death YEAR
);DESC pet;# 3. 添加记录
INSERT INTO pet VALUES
('Fluffy','harold','Cat','f','2003','2010'),
('Claws','gwen','Cat','m','2004',NULL),
('Buffy',NULL,'Dog','f','2009',NULL),
('Fang','benny','Dog','m','2000',NULL),
('bowser','diane','Dog','m','2003','2009'),
('Chirpy',NULL,'Bird','f','2008',NULL);SELECT *
FROM pet;# 4. 添加字段:主人的生日owner_birth DATE类型。
ALTER TABLE pet
ADD owner_birth DATE;# 5. 将名称为Claws的猫的主人改为kevin
UPDATE pet
SET OWNER = 'kevin'
WHERE NAME = 'Claws' AND species = 'Cat';# 6. 将没有死的狗的主人改为duck
UPDATE pet
SET OWNER = 'duck'
WHERE death IS NULL AND species = 'Dog';# 7. 查询没有主人的宠物的名字;
SELECT NAME
FROM pet
WHERE OWNER IS NULL;# 8. 查询已经死了的cat的姓名,主人,以及去世时间;
SELECT NAME,OWNER,death
FROM pet
WHERE death IS NOT NULL;# 9. 删除已经死亡的狗
DELETE FROM pet
WHERE death IS NOT NULL
AND species = 'Dog';# 10. 查询所有宠物信息
SELECT *
FROM pet;##################################
#练习3:
# 1. 使用已有的数据库dbtest11
USE dbtest11;
# 2. 创建表employee,并添加记录
CREATE TABLE employee(
id INT,
NAME VARCHAR(15),
sex CHAR(1),
tel VARCHAR(25),
addr VARCHAR(35),
salary DOUBLE(10,2));INSERT INTO employee VALUES
(10001,'张一一','男','13456789000','山东青岛',1001.58),
(10002,'刘小红','女','13454319000','河北保定',1201.21),
(10003,'李四','男','0751-1234567','广东佛山',1004.11),
(10004,'刘小强','男','0755-5555555','广东深圳',1501.23),
(10005,'王艳','男','020-1232133','广东广州',1405.16);SELECT * FROM employee;# 3. 查询出薪资在1200~1300之间的员工信息。
SELECT *
FROM employee
WHERE salary BETWEEN 1200 AND 1300;# 4. 查询出姓“刘”的员工的工号,姓名,家庭住址。
SELECT id,NAME,addr
FROM employee
WHERE NAME LIKE '刘%';# 5. 将“李四”的家庭住址改为“广东韶关”
UPDATE employee
SET addr = '广东韶关'
WHERE NAME = '李四';# 6. 查询出名字中带“小”的员工
SELECT *
FROM employee
WHERE NAME LIKE '%小%';
相关文章:
第11章_数据处理之增删改
文章目录 1 插入数据1.1 实际问题1.2 方式 1:VALUES的方式添加1.3 方式2:将查询结果插入到表中演示代码 2 更新数据演示代码 3 删除数据演示代码 4 MySQL8新特性:计算列演示代码 5 综合案例课后练习 1 插入数据 1.1 实际问题 解决方式&#…...

数据时代的新引擎:数据治理与开发,揭秘数据领域的黄金机遇!
文章目录 一、数据时代的需求二、数据治理与开发三、案例分析四、黄金机遇《数据要素安全流通》《Python数据挖掘:入门、进阶与实用案例分析》《数据保护:工作负载的可恢复性 》《Data Mesh权威指南》《分布式统一大数据虚拟文件系统 Alluxio原理、技术与…...

使用 Golang 实现基于时间的一次性密码 TOTP
上篇文章详细讲解了一次性密码 OTP 相关的知识,基于时间的一次性密码 TOTP 是 OTP 的一种实现方式。这种方法的优点是不依赖网络,因此即使在没有网络的情况下,用户也可以生成密码。所以这种方式被许多流行的网站使用到双因子或多因子认证中&a…...

微服务之Nacos配置管理
文章目录 一、统一配置管理Nacos操作二、统一配置管理java操作1.引入依赖2.创建配置文件3.测试4.总结 三、Nacos配置自动更新1.添加注解RefreshScope2.使用ConfigurationProperties注解3.总结 四、Nacos多环境配置共享1.配置文件2.多种配置的优先级3.总结 一、统一配置管理Naco…...

PySpark 优雅的解决依赖包管理
背景 平台所有的Spark任务都是采用Spark on yarn cluster的模式进行任务提交的,driver和executor随机分配在集群的各个节点,pySpark 由于python语言的性质,所以pySpark项目的依赖注定不能像java/scala项目那样把依赖打进jar包中轻松解决问题…...

UNI-APP_获取手机品牌
在uni-app中,使用uni.getSystemInfoSync().brand可以获取设备的品牌信息。根据不同设备的品牌,uni.getSystemInfoSync().brand可能返回以下一些常见值 “Apple” - 苹果 “Samsung” - 三星 “Huawei” - 华为 “Xiaomi” - 小米 “OPPO” - OPPO “Vivo…...

新登录接口独立版变现宝升级版知识付费小程序-多领域素材资源知识变现营销系统
源码简介: 资源入口 点击进入 源码亲测无bug,含前后端源码,非线传,修复最新登录接口 梦想贩卖机升级版,变现宝吸取了资源变现类产品的很多优点,摒弃了那些无关紧要的东西,使本产品在运营和变现…...

「掌握创意,释放想象」——Photoshop 2023,你的无限可能!
Adobe Photoshop 2023(PS2023) 来了,全世界数以百万计的设计师、摄影师和艺术家使用 Photoshop 将不可能变为可能。从海报到包装,从基本的横幅到漂亮的网站,从令人难忘的徽标到引人注目的图标,Photoshop 2023让创意世界不断前进。借助直观的工…...

SQLSugar查询返回DataTable
SQLSugar是一个用于执行SQL查询的C#库,它提供了简单易用的API接口来执行SQL查询。要查询返回DataTable,可以使用SQLSugar的QueryHelper类。 以下是一个示例代码,展示了如何使用SQLSugar的QueryHelper类查询返回DataTable: 首先&…...
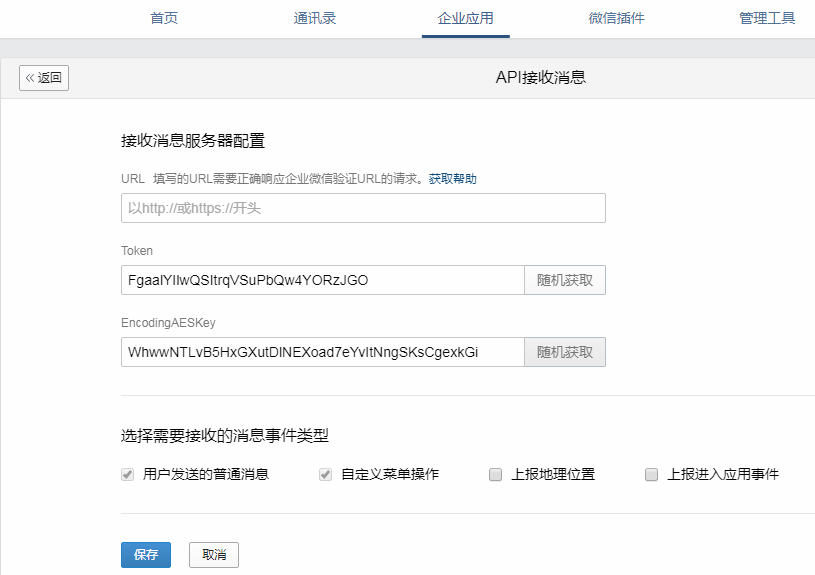
企业微信开启接收消息+验证URL有效性
企业微信开启接收消息验证URL有效性 📔 千寻简笔记介绍 千寻简笔记已开源,Gitee与GitHub搜索chihiro-notes,包含笔记源文件.md,以及PDF版本方便阅读,且是用了精美主题,阅读体验更佳,如果文章对…...

电脑访问不到在同网络的手机设备
手机连接了同网络的wifi,但是电脑ping不通手机的ip,这可能是路由出了问题,因为最终是走的mac地址,访问不了是因为电脑不知道手机的mac地址,则可以这样设置绑定mac地址,管理员权限启动cmd,然后执…...

国内MES系统应用研究报告:“企业MES应用现状”| 百世慧®
随着制造企业数字化转型需求的增强,工业软件的需求也不断被激发。 2022年,中国MES软件及服务市场规模实现23.8%的较高速增长。同时,随着工业互联网、MOM的兴起和不断发展,也推动着MES持续发展和不断迭代,如今MES向着更…...
C++模板元模板实战书籍讲解第一章题目讲解
目录 第一题 C代码示例 第二题 C代码示例 第三题 3.1 使用std::integral_constant模板类 3.2 使用std::conditional结合std::is_same判断 总结 第四题 C代码示例 第五题 C代码示例 第六题 C代码示例 第七题 C代码示例 总结 第一题 对于元函数来说,…...
)
Java在互联网网络安全中的应用(三)
目录 1. 互联网网络安全概述 2. Java的网络安全特性 3. 用Java加固网络应用 4. 安全传输 5. 安全框架和工具 6. 实际应用案例 7. 最佳实践和资源 目标 本次技术分享的目标是介绍Java技术在互联网网络安全中的应用,包括关键概念、最佳实践和实际案例。 1. 互…...

VMLogin如何解决跨境电商多账号管理难题?
做跨境电商的,比如亚马逊、eBay这些卖家。随着团队规模的扩大,或者多店铺运营,那么多个店铺多个账号管理就成为了一个困难。如何解决这个问题呢? 首先来看看很多电商卖家多账号管理会面临的问题 经营者通常需要同时管理多个市场…...
STM32创建工程步骤
以创建led工程为例: 新建一个led文件夹 新建一个以led命名的工程(用keil_uVision5)并添加三个组。 Library文件夹里放置库函数文件。 User: 点亮led灯的程序; 直接给寄存器赋值 调用库函数。 #include "stm…...
)
软考 系统架构设计师系列知识点之边缘计算(1)
所属章节: 第11章. 未来信息综合技术 第4节. 边缘计算概述 1. 边缘计算概念 在介绍边缘计算之前,有必要先介绍一下章鱼。章鱼就是用“边缘计算”来解决实际问题的。作为无脊椎动物中智商最高的一种动物,章鱼拥有巨量的神经元,但…...

vue:写一个数组box和list数组,在保留box数组中原有对象的同时,将list数组中每一个对象插入到box数组后面
前言:由于源码涉及到后端调用数据和一些无关的功能所以我就专门针对这个功能的代码,这样好方便理解。 1、在data中定义两个数组:box和list,并给它们初始化值 data() {return {box: [/*初始的box数组对象*/],list: [/*初始的list…...

Python教程:随机函数,开始猜英文单词的游戏
开始猜英文单词的游戏… 总计生命次数:3次 -----------游戏开始中…----------- ????请猜一个,4位数的单词:mafr 猜错了,再努力一下 -----------你还有2次生命------------ ma?&…...
Unit2_1:动态规划DP
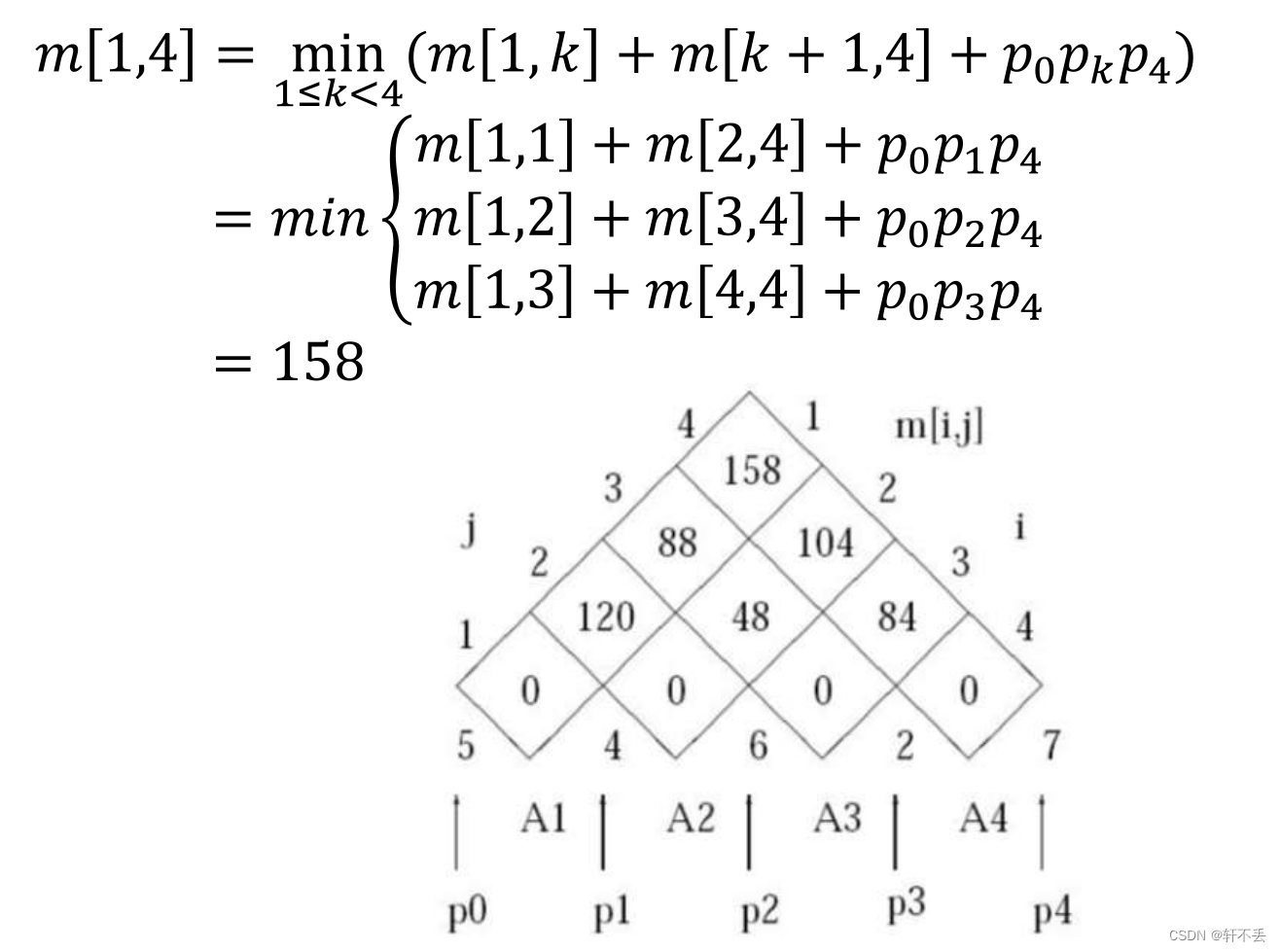
文章目录 一、介绍二、0-1背包问题问题描述分析伪代码时间复杂度 三、钢条切割问题问题描述分析伪代码过程 四、矩阵链乘法背景性质分析案例伪代码 一、介绍 动态规划类似于分治法,它们都将一个问题划分为更小的子问题 最优子结构:问题的最优解包含子问题的最优解。DP适用的原…...

用C语言解决‘换硬币’问题?我来教你如何调试和验证你的循环逻辑
用C语言解决‘换硬币’问题?我来教你如何调试和验证你的循环逻辑 当你第一次面对"换硬币"这类组合问题时,那种既兴奋又困惑的感觉我至今记忆犹新。作为C语言初学者,理解多重循环的运作机制就像在迷宫中寻找出口——每次你以为找到了…...

Tftpd32/Tftpd64不止是TFTP!手把手教你玩转它的DHCP和Syslog服务器功能
Tftpd32/Tftpd64:解锁DHCP与Syslog服务的隐藏潜力当大多数人提起Tftpd32/Tftpd64时,第一反应往往是它作为TFTP服务器的功能。这款轻量级工具确实在文件传输领域表现出色,但它的能力远不止于此。今天,我们将深入探索这款软件中两个…...

政企数据安全:危机与出路
随着数字化转型的浪潮席卷全球,公共部门积累的数据量呈爆炸式增长。从公民个人信息到公共服务记录,从财政预算到基础设施管理数据——这些宝贵资源在提升政府治理效率的同时,也悄然成为网络犯罪分子的“新猎物”。当公共数据逐渐成为数字时代…...

Unity主题系统设计:状态驱动的主题抽象与自动注入方案
1. 这不是换个颜色那么简单:为什么Unity项目里“换肤”总在发布前夜崩盘?你有没有经历过这样的场景:美术同学凌晨两点发来一套新主题资源包,UI设计师说“这次配色更符合品牌调性”,产品说“上线前必须支持深色模式”&a…...

基于声卡与电流互感器的安全交流功率测量系统设计与实践
1. 项目概述:用声卡安全测量交流功率我一直对各种测量技术抱有浓厚的兴趣,毕竟“测量即认知”这句老话在今天依然适用。对于电力消耗和产出,没有什么比直接测量更能说明问题了。交流功率的测量,核心在于同时获取电压和电流的瞬时值…...

为内部知识库问答机器人接入Taotoken多模型增强回答效果
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为内部知识库问答机器人接入Taotoken多模型增强回答效果 构建一个高效的企业内部知识库问答机器人,核心挑战在于如何让…...

UE5 Mac环境搭好了,然后呢?给新手的第一个5分钟:创建、操控并理解你的第一个角色
UE5 Mac环境搭好了,然后呢?给新手的第一个5分钟:创建、操控并理解你的第一个角色当你第一次打开UE5的Mac版本,面对那个闪烁着光芒的启动界面,内心可能既兴奋又忐忑。安装只是第一步,真正的旅程现在才开始。…...

为什么鸿蒙 App 最终都会走向状态驱动?
子玥酱 (掘金 / 知乎 / CSDN / 简书 同名) 大家好,我是 子玥酱,一名长期深耕在一线的前端程序媛 👩💻。曾就职于多家知名互联网大厂,目前在某国企负责前端软件研发相关工作,主要聚…...

企业内统一API网关与Taotoken聚合平台对接方案
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业内统一API网关与Taotoken聚合平台对接方案 在推进AI应用落地的过程中,许多中大型企业面临一个共同挑战:…...

探索Windows 10上的Android世界:揭秘WSA-Windows-10项目的3个技术突破
探索Windows 10上的Android世界:揭秘WSA-Windows-10项目的3个技术突破 【免费下载链接】WSA-Windows-10 This is a backport of Windows Subsystem for Android to Windows 10. 项目地址: https://gitcode.com/gh_mirrors/ws/WSA-Windows-10 想象一下&#…...