模型蒸馏学习
知识蒸馏:获取学生网络和教师网络指定蒸馏位点的输出特征并计算蒸馏 loss 的过程
知乎-mmrazor-模型蒸馏
知识蒸馏算法往往分为 reponse-based基于响应、feature-based基于特征 和 relation-based基于关系三类。
也可为 data-free KD、online KD、self KD(可视为一种特殊的 online KD)和比较经典的 offline KD
- feature-based 方法以教师模型特征提取器产生的中间层特征为学习对象
而ChannelWiseDivergence(cwd算法)使用的是预测之前的logistic特征图(在channel维度上取最大值,即为最终的预测结果),就是feature-based的蒸馏方法
mmrazor可以使用不同架构的student和teacher模型
- 可以使用connector对不同维度进行对齐,以计算语义分割的蒸馏loss
- 对于 feature-base 的方法,当学生和教师网络输出特征维度不同时,往往会对学生网络对应特征进行后处理以保证蒸馏 loss 正确计算(connector实现)
mmseg的模型,在deconde_head.conv_seg后拿到的特征图为logist的特征图,其内的元素都为小数,而非预测的0/1
cwd算法是一种什么样的蒸馏算法呢是data-free的吗,还是online的呢,还是offline的呢
适用于mmseg的cwd模型蒸馏配置文件(default_hook中的Student_CheckpointHook是自定义的hook,继承自mmegin中的CheekpointHook)
cwd算法:首先使用softmax归一化方法将每个通道的feature map转换成一个分布,然后最小化两个网络对应通道的Kullback Leibler (KL)散度。通过这样做,我们的方法着重于模拟网络间通道的软分布。特别的是,KL的差异使学习能够更多地关注通道图中最突出的区域,大概对应于语义分割最有用的信号
- 现象:
由于model capacity gap的存在,student往往弱于teacher模型,但也并不绝对,如果model本身的gap不是很离谱,student还是有超越teacher的可能的,因为student模型一般可以学习teacher模型蒸馏位点的特征和ground truth多种知识,学习效率会更高,如果本身student没有太大的问题,还是有机会学的更好的。
_base_ = ['mmseg::_base_/datasets/pascal_voc12.py','mmseg::_base_/schedules/schedule_160k.py','mmseg::_base_/default_runtime.py'
]# 模型的optim_wrapper,学习率和学习策略将来自于继承的schedule_160k,如果不改的话
# wandb的可视化设置在mmseg的default_runtime,也继承自mmseg# schedule_160k.py中的自动保存权重的部分
default_hooks = dict(_delete_=True,timer=dict(type='IterTimerHook'),logger=dict(type='LoggerHook', interval=100, log_metric_by_epoch=False),param_scheduler=dict(type='ParamSchedulerHook'),# 使用了自定义的Student_CheckpointHookcheckpoint=dict(type='Student_CheckpointHook', by_epoch=False, interval=-1, max_keep_ckpts=2, save_best=['mDice', 'mIoU']),# checkpoint中,interval=-1则不会保存least.pthsampler_seed=dict(type='DistSamplerSeedHook'),visualization=dict(type='SegVisualizationHook'))teacher_ckpt = '/root/autodl-tmp/all_workdir/mmseg_work_dir/baseline-convnext-tiny-upernet-rotate/best_mDice_iter_6800.pth' # noqa: E501
teacher_cfg_path = 'mmseg::all_changed/baseline-convnext-tiny_upernet-rotate.py' # noqa: E501student_cfg_path = 'mmseg::all_changed/pspnet_r18-d8_b16-160k_voc-material-512x512.py' # noqa: E501
model = dict(_scope_='mmrazor',type='SingleTeacherDistill',architecture=dict(cfg_path=student_cfg_path, pretrained=False),teacher=dict(cfg_path=teacher_cfg_path, pretrained=False),teacher_ckpt=teacher_ckpt,distiller=dict(type='ConfigurableDistiller',distill_losses=dict(loss_cwd=dict(type='ChannelWiseDivergence', tau=1, loss_weight=5)),student_recorders=dict(logits=dict(type='ModuleOutputs', source='decode_head.conv_seg')),teacher_recorders=dict(logits=dict(type='ModuleOutputs', source='decode_head.conv_seg')),connectors=dict(loss_conv_stu=dict(type='ConvModuleConncetor', in_channel=2, out_channel=2, kernel_size=1, stride=1, padding=0,norm_cfg=dict(type='BN')),loss_conv_tea=dict(type='ConvModuleConncetor', in_channel=2, out_channel=2, kernel_size=3, stride=2, padding=1, padding_mode='circular',norm_cfg=dict(type='BN'))),loss_forward_mappings=dict(loss_cwd=dict(preds_S=dict(from_student=True, recorder='logits', connector='loss_conv_stu'), # 含义:从student_recorders(from_student=True)中读取名为logits的数据# 加上connnecor字段后,表示从student_recorders中读取名为logists的数据,而后将数据通过名为loss_conv_stu的连接器preds_T=dict(from_student=False, recorder='logits', connector='loss_conv_tea')))))# 从teacher_recorders中读取名为logits的数据,而后将数据通过名为loss_conv_tea的连接器# 而无论是loss_cwd、logits、loss_conv_stu、loss_conv_tea都是自定的名称find_unused_parameters = Truetrain_cfg = dict(type='IterBasedTrainLoop', max_iters=160000, val_interval=200)
val_cfg = dict(_delete_=True, type='mmrazor.SingleTeacherDistillValLoop')train_dataloader = dict(batch_size=16) # 更改batch_size,否则会继承到pascal_voc12.py中的设置
# 这个16会作为teacher模型的推理batch和student模型的训练batchwork_dir = '/root/autodl-tmp/all_workdir/mmrazor_wokdir/distill/convnext-tiny-upernet_to_pspnet-r18'
模型蒸馏一
-
- 基于响应的KD(DKD ,FitNets):
基于响应的KD以teacher模型的分类预测结果为目标知识,具体指的是分类器最后一个全连接层的输出(成为logits)。与最终的输出相比,logits没有经过softmax进行归一化,非目标类对应的输出值尚未被抑制。
教师模型和学生模型之间的损失差异一般用KD散度,一般会用temperature(tau)大于1的参数对logits进行软化,以减小目标类和非目标类的预测值差异。
logits具备的含义为模型判断当前样本为各类别的信心为多少
1) logits提供的软标签信息,比one-hot的真实标签有着更高的熵值,从而提供了更多的信息量和数据之间更小梯度差异
2) 软标签有着与标签平滑类似的效果,提高了模型的泛化能力
3)除了gt标签外,还学习了软标签,使得模型学到了更多的知识,更倾向于学到不同的知识,优化方向更稳定
- 基于响应的KD(DKD ,FitNets):
-
- 基于特征的KD(AB,AT,ofd,Factor Transfer):
蒸馏位点位于模型中途获得的特征
通常,teacher模型的通道大于学生通道,二者无法完全对齐,一般在学生的特征图后面接卷积,将两者在维度和通道上对齐,从而实现特征点的一一对应
1)特征维度对齐,特征加权,mmrazor的connector模块的抽象
2)知识定位,设计规则选出更为重要的教师特征
- 基于特征的KD(AB,AT,ofd,Factor Transfer):
-
- 基于关系的KD(FSP, RKD):也使用特征,但计算不是特征点的一对一差异,而是特征关系的差异
1)样本间关系蒸馏:在分类和分割中应用广泛,因为构建高质量的关系矩阵需要大量样本
- 基于关系的KD(FSP, RKD):也使用特征,但计算不是特征点的一对一差异,而是特征关系的差异
总结:在语义分割中的cwd算法,可以看作是基于响应的KD,也可以看作是基于特征的KD,因为在传统的cwd算法中,使用的是在通过softmax之前的位置作为蒸馏位点,输出对应的特征图,去计算损失。
相关文章:

模型蒸馏学习
知识蒸馏:获取学生网络和教师网络指定蒸馏位点的输出特征并计算蒸馏 loss 的过程 知乎-mmrazor-模型蒸馏 知识蒸馏算法往往分为 reponse-based基于响应、feature-based基于特征 和 relation-based基于关系三类。 也可为 data-free KD、online KD、self KDÿ…...

总结Kibana DevTools如何操作elasticsearch的常用语句
一、操作es的工具 ElasticSearch HeadKibana DevToolsElasticHQ 本文主要是总结Kibana DevTools操作es的语句。 二、搜索文档 1、根据ID查询单个记录 GET /course_idx/_doc/course:202、term 匹配"name"字段的值为"6789999"的文档 类似于sql语句中的等…...

【QT】QT自定义C++类
在使用Qt的ui设计时,Qt为我们提供了标准的类,但是在很多复杂工程中,标准的类并不能满足所有的需求,这时就需要我们自定义C类。 下面以自定义的QPushButton作一个很简单的例子。 先新建默认Qt Widgets Application项目 一、自定义…...

【多媒体文件格式】AVI、WAV、RIFF
AVI、RIFF AVI:Audio/Video Interleaved(音频视频交织/交错),用于采集、编辑、播放的RIFF文件。由Microsoft公司1992年11月推出,是Microsoft公司开发的一种符合RIFF文件规范的数字音频与视频文件格式,原先…...
AI创作系统ChatGPT商业运营系统源码+支持GPT4/支持ai绘画
一、AI创作系统 SparkAi创作系统是基于OpenAI很火的ChatGPT进行开发的Ai智能问答系统和Midjourney绘画系统,支持OpenAI-GPT全模型国内AI全模型。本期针对源码系统整体测试下来非常完美,可以说SparkAi是目前国内一款的ChatGPT对接OpenAI软件系统。那么如…...

JWT简介 JWT结构 JWT示例 前端添加JWT令牌功能 后端程序
目录 1. JWT简述 1.1 什么是JWT 1.2 为什么使用JWT 1.3 JWT结构 1.4 验证过程 2. JWT示例 2.1 后台程序 2.2 前台加入jwt令牌功能 1. JWT简述 1.1 什么是JWT Json web token (JWT), 是为了在网络应用环境间传递声明而执行的一种基于JSON的开放标准((RFC 7…...
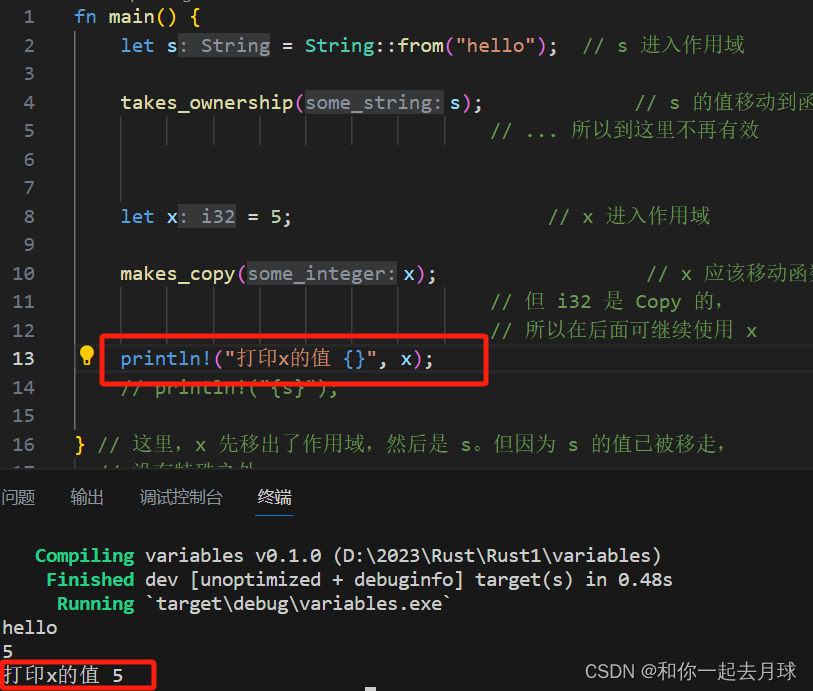
Rust核心功能之一(所有权)
目录 1、什么是所有权? 1.1 所有权规则 1.2 变量作用域 1.3 String 类型 1.4 内存与分配 变量与数据交互的方式(一):移动 变量与数据交互的方式(二):克隆 只在栈上的数据:拷贝…...
和JWT 详解)
跨域(CORS)和JWT 详解
跨域 (CORS) 概念 同源策略 (Same-Origin Policy) 同源策略是一项浏览器安全特性,它限制了一个网页中的脚本如何与另一个来源(域名、协议、端口)的资源进行交互。这对于防止跨站点请求伪造和数据泄露非常重要。 为什么需要跨域? 跨域问题通…...

前端框架Vue学习 ——(二)Vue常用指令
文章目录 常用指令 常用指令 指令: HTML 标签上带有 “v-” 前缀的特殊属性,不同指令具有不同含义。例如: v-if, v-for… 常用指令: v-bind:为 HTML 标签绑定属性值,如设置 href,css 样式等 <a v-bind:href"…...
`flash_erase` 擦除Flash存储器)
Linux 指令心法(十四)`flash_erase` 擦除Flash存储器
文章目录 flash_erase 作用flash_erase的主要特点和使用场景flash_erase命令应用方法flash_erase命令可以解决哪些问题?flash_erase命令使用时注意事项 flash_erase 作用 这是一个用于擦除Flash存储器的命令。它可以擦除指定的Flash块或扇区,以便在写入新数据之前…...
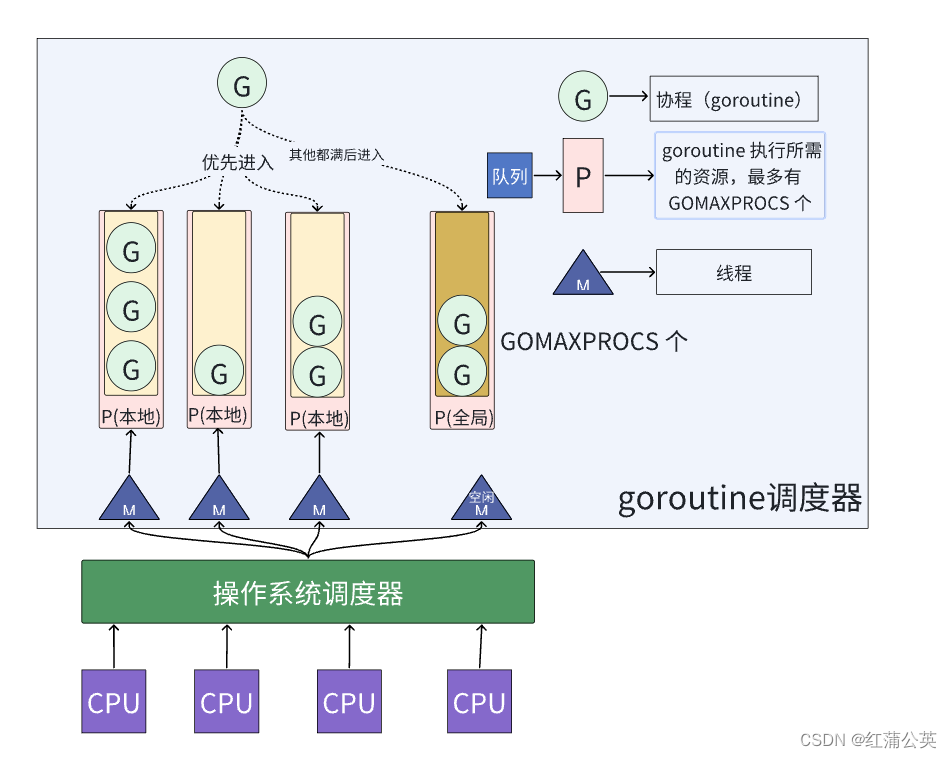
GoLong的学习之路(二十一)进阶,语法之并发(go最重要的特点)(协程的主要用法)
并发编程在当前软件领域是一个非常重要的概念,随着CPU等硬件的发展,我们无一例外的想让我们的程序运行的快一点、再快一点。Go语言在语言层面天生支持并发,充分利用现代CPU的多核优势,这也是Go语言能够大范围流行的一个很重要的原…...

加快网站收录 3小时百度收录新站方法
加快网站收录 3小时百度收录新站方法 3小时百度收录新站方法说起来大家可能不相信,但这确实是真实的(该方法是通过技术提交,让百度快速抓取收录您的网站,不管你网站有没有备案,都能在短时间内被收录,要是你的网站迟迟不…...

GPT实战系列-ChatGLM3本地部署CUDA11+1080Ti+显卡24G实战方案
目录 一、ChatGLM3 模型 二、资源需求 三、部署安装 配置环境 安装过程 低成本配置部署方案 四、启动 ChatGLM3 五、功能测试 新鲜出炉,国产 GPT 版本迭代更新啦~清华团队刚刚发布ChatGLM3,恰逢云栖大会前百川也发布Baichuan2-192K,一…...
图片怎么转换成pdf?
图片怎么转换成pdf?图片可以转换成PDF格式文档吗?当然是可以的呀,当图片转换成PDF文件类型时,我们就会发现图片更加方便的打开分享和传播,而且还可以更加安全的保证我们的图片所有性。我们知道PDF文档是可以加密的&…...
【源码】医学影像PACS实现三维影像后处理等功能
医学影像诊断技术近年来取得了快速发展,包括高性能的影像检查设备的临床应用和数字信息技术的图像显示、存储、传输、处理、识别,这些技术使得计算机辅助检测和诊断成为可能,同时人工智能影像诊断也进入了人们的视野。这些技术进步提高了疾病…...

DOCTYPE是什么,有何作用、 使用方式、渲染模式、严格模式和怪异模式的区别?
前言 持续学习总结输出中,今天分享的是DOCTYPE是什么,有何作用、 使用方式、渲染模式、严格模式和怪异模式的区别。 DOCTYPE是什么,有何作用? DOCTYPE是HTML5的文档声明,通过它可以告诉浏览器,使用那个H…...

Go语言实现HTTP正向代理
文章目录 前言实现思路代码实现 前言 正向代理(Forward Proxy)是一种代理服务器的部署方式,它位于客户端和目标服务器之间,代表客户端向目标服务器发送请求。正向代理可以用来隐藏客户端的真实身份,以及在不同网络环境…...
第11章_数据处理之增删改
文章目录 1 插入数据1.1 实际问题1.2 方式 1:VALUES的方式添加1.3 方式2:将查询结果插入到表中演示代码 2 更新数据演示代码 3 删除数据演示代码 4 MySQL8新特性:计算列演示代码 5 综合案例课后练习 1 插入数据 1.1 实际问题 解决方式&#…...

数据时代的新引擎:数据治理与开发,揭秘数据领域的黄金机遇!
文章目录 一、数据时代的需求二、数据治理与开发三、案例分析四、黄金机遇《数据要素安全流通》《Python数据挖掘:入门、进阶与实用案例分析》《数据保护:工作负载的可恢复性 》《Data Mesh权威指南》《分布式统一大数据虚拟文件系统 Alluxio原理、技术与…...

使用 Golang 实现基于时间的一次性密码 TOTP
上篇文章详细讲解了一次性密码 OTP 相关的知识,基于时间的一次性密码 TOTP 是 OTP 的一种实现方式。这种方法的优点是不依赖网络,因此即使在没有网络的情况下,用户也可以生成密码。所以这种方式被许多流行的网站使用到双因子或多因子认证中&a…...

保姆级教程:用iSYSTEM winIDEA和iC5000给S32K148烧录程序,附完整配置流程
从零掌握iSYSTEM工具链:S32K148开发板烧录与调试全流程实战第一次接触iSYSTEM的winIDEA和iC5000仿真器时,很多嵌入式开发者都会感到无从下手。不同于常见的开源工具链,这套专业级开发环境在汽车电子和工业控制领域有着广泛应用,尤…...

新手也能懂的SSRF漏洞实战:用iwebsec靶场复现文件读取与内网探测
从零开始掌握SSRF漏洞:iwebsec靶场实战指南1. 认识SSRF漏洞的本质想象一下,你正在一家高档餐厅点餐,服务员承诺可以帮你从任何地方获取食材——包括隔壁竞争对手的厨房。SSRF(Server-Side Request Forgery)漏洞就像这个…...

ESP32多任务水位监测:从Arduino到ESP-IDF的FreeRTOS实战
1. 项目概述:从Arduino到ESP-IDF的跃迁去年我在做毕业设计时,为了搭建一个ESP32的传感器节点演示程序,第一次深入使用了FreeRTOS。那段时间,我几乎天天和任务调度、队列、信号量打交道,从最初的一头雾水到后来能流畅地…...

炉石传说自动对战助手:5分钟上手,彻底解放双手的终极指南
炉石传说自动对战助手:5分钟上手,彻底解放双手的终极指南 【免费下载链接】Hearthstone-Script Hearthstone script(炉石传说脚本) 项目地址: https://gitcode.com/gh_mirrors/he/Hearthstone-Script 还在为每天重复的炉石…...

Python UiAutomation实战:从网页数据抓取到桌面应用,一个库打通数据采集全链路
Python UiAutomation实战:打通数据采集全链路的智能解决方案 在数据驱动的商业环境中,企业常常面临跨平台数据采集的挑战——财务系统里的交易记录需要与网站后台的报表进行交叉分析,销售数据要从桌面软件导出后上传到云端处理系统。传统的人…...

Burp Suite拦截与替换机制深度解析:从协议层到规则链
1. 这不是“点开就能用”的功能,而是你和目标系统之间的一道可编程闸门很多人第一次在Burp Suite里点开Proxy → Intercept,看到HTTP请求被拦下来,兴奋地改个User-Agent、删个Cookie就点Forward,以为自己已经掌握了“拦截与替换”…...

AI IDE 革命:程序员正在被重新定义
很多开发者第一次使用 Cursor 的 CtrlK 或 Composer(高级多文件编辑模式)时,都会有一种强烈的、甚至让人有些脊背发凉的冲击感。 因为: 它已经不再是那个我们熟悉的、只能在原地等待光标落下的: “代码自动补全插件&am…...

MeloTTS实战:多语言语音合成的高效解决方案
MeloTTS实战:多语言语音合成的高效解决方案 【免费下载链接】MeloTTS High-quality multi-lingual text-to-speech library by MyShell.ai. Support English, Spanish, French, Chinese, Japanese and Korean. 项目地址: https://gitcode.com/GitHub_Trending/me/…...

Atomic Layout核心概念解析:Composition组件如何实现布局与间距分离的终极指南
Atomic Layout核心概念解析:Composition组件如何实现布局与间距分离的终极指南 【免费下载链接】atomic-layout Build declarative, responsive layouts in React using CSS Grid. 项目地址: https://gitcode.com/gh_mirrors/at/atomic-layout Atomic Layout…...

工业云脑:06 现在就能干:树莓派边缘盒子+PLC,10分钟缺陷检测小案例
06 现在就能干:树莓派边缘盒子+PLC,10分钟缺陷检测小案例 今天第九篇06小节——现在就能干:树莓派边缘盒子+PLC,10分钟缺陷检测小案例。新手照着做10分钟就能跑起来,老手一看就知道这玩意儿省了多少钱。以前想上AI检测,得花几万块买专业边缘盒子;现在?树莓派5(RPi 5)…...