【Linux】七、基础IO
预备知识
文件 = 属性(本质上也是数据)+内容;
文件的所有操作大致有两种,对内容的操作,和对属性的操作;
文件在磁盘中放置,磁盘是硬件,只有操作系统可以真正的访问磁盘;C\C++程序要读写需要先变为进程;而文件在磁盘上放着,我们访问文件需要先写代码,fopen等,然后编译,生成exe文件,运行后访问文件,所以访问文件本质上是进程在访问文件;进程访问文件是需要通过接口访问;之前接触的接口是C\C++语言层面的接口,但是访问文件相当于要向硬件写入,所以只有操作系统(通过驱动程序)才能向硬件写入;
如果普通用户也想写入呢?
就必须让操作系统提供接口才能实现普通用户的写入;
于是就有了文件类的系统调用接口;
为什么语言上有文件操作的调用接口函数呢?
1、因为操作系统的文件操作调用接口使用比较难,所以在语言层面上进行了封装;所以导致了不同的语言有不同的语言级别的文件访问接口(都不一样),但是都因为封装的是系统调用接口;所以就需要学习操作系统的文件接口,底层都是调用操作系统的接口,操作系统只有一套;
2、跨平台,代码可以在Linux、windows等平台跑,所有的语言基本都是跨平台的;如果C/C++不提供文件的系统接口的封装,那么所有的访问文件的操作都必须直接使用操作系统的接口,而用语言的客户也需要访问文件;一旦使用系统接口编写文件代码,这份代码无法在其他平台直接运行了,所以代码就不具备跨平台性了;将所有的平台的代码都实现一遍,条件编译,动态裁剪;
显示器是硬件,printf向显示器打印也是一种写入,与磁盘写入文件没有本质的区别;
Linux认为一切皆是文件;
对于文件的操作而言,就是文件的读和写;
对于显示器而言:printf/cout就是一种写入;
键盘:输入,相当于给了显示器一份进行显示,scanf/cin 对应着是一种读;
站在所写的程序的角度,要加载到内存;cin就相当于input;显示器就相当于output;
普通文件 -> fopen/fread -> 进程内部(内存)-> fwrite -> 文件中;
普通文件到进程内部相当于input;从进程内部到文件中相当于output;
所以文件的概念就是:站在系统的角度,能够被input读取或者能够output写出的设备就叫做文件;也就是说,
狭义的文件是:磁盘中的文件;
广义上的文件:显示器、键盘、网卡、声卡、显卡、磁盘、几乎所有的外设,都可以称之为文件;
键盘显示器也可以看做文件;
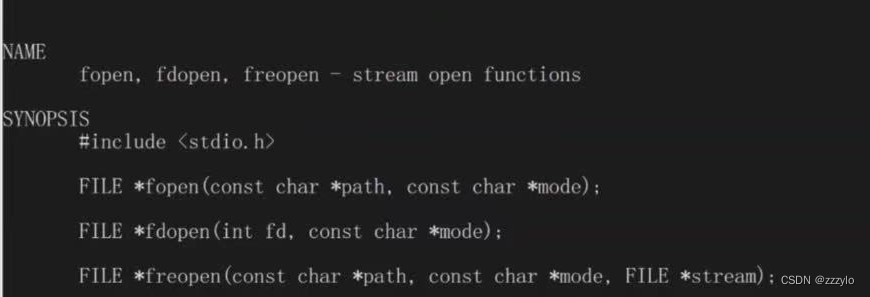
C语言的接口
r:只读;
r+:读写;
w:先清空文件,再写入;
w+:读写,如果不存在则会创建;
a:写到文件的结尾,向文件中追加新增内容;
a+:
代码
#include <stdio.h> #include <unistd.h>int main() {FILE *fp = fopen("log.txt", "w"); //在当前文件夹下没有log.txt,而w会创建,那么文件会在哪里创建?// 当前路径,一般是可执行程序在哪里,创建的文件就在哪里;// if (fp == NULL){perror("fopen");return 1;}//进行文件操作;fclose(fp);return 0; }在当前文件夹下没有log.txt,而w会创建,那么文件会在哪里创建?
在当前路径下,一般是可执行程序在哪里,创建的文件就在哪里;
是进程运行后创建的,当一个进程运行起来的时候,每一个进程都会记录自己所处的工作路径;底层会将cwb与log.txt拼接起来,生成最终的路径;
#include <stdio.h> #include <unistd.h>int main() {FILE *fp = fopen("log.txt", "w"); if (fp == NULL){perror("fopen");return 1;}//进行文件操作;const char *s1 = "hello fwrite\n";//\n的作用是在文件中换行输入;fwrite(s1, strlen(s1), 1, fp);const char *s2 = "hello fprintf\n";fprintf(fp, "%s", s2);const char *s3 = "hello fputs\n";fputs(s3, fp);fclose(fp);return 0; }输出结果:
;
fwrite函数中需要使用 strlen(s1)+1 来将'\0'写进文件中吗?
不需要,因为 \0 仅仅是C语言的规定,当加1后会出现乱码
因为普通文件对 \0 无法解释,文件只需要保存有效数据;
w:先清空文件,再写入;
命令行:echo goodball > log.txt 向文件中写入内容goodball;
> log.txt 将文件中的内容清空;
按行读取内容
#include <stdio.h>int main() {FILE *fp = fopen("log.txt", "r"); if (fp == NULL){perror("fopen");return 1;}//按行读取const line[64];//fgets 会自动在字符结尾添加\0while (fgets(line, sizeof(line), fp) != NULL){printf("%s",line);fprintf(stdout, "%s", line);}return 0; }此时可以显示出文件log.txt 的内容;
修改代码为
#include <stdio.h>int main(int argc,char *argv[]) {if (argc != 2){printf("argc error!\n");return 1;}FILE *fp = fopen(argv[1], "r"); if (fp == NULL){perror("fopen");return 1;}//按行读取const line[64];//fgets 会自动在字符结尾添加\0while (fgets(line, sizeof(line), fp) != NULL){printf("%s",line);fprintf(stdout, "%s", line);}return 0; }此时就写出了一个cat命令;查看文件中的内容;
C\C++程序会默认打开三个数据流
标准输入:键盘 extern FILE *stdin;
标准输出:显示器 extern FILE *stdout;
标准错误:显示器 extern FILE *stderr;
标准输入输出流都是文件指针;

系统接口的使用
库函数的使用一定会调用系统接口;
四个系统接口:open、close、read、write;
OPEN
使用前两个接口较多;
const char *pathname:打开文件的路径+文件名;
int flags:代表一些选项,O_APPEND,追加;O_CREAT,如果文件不存在则会创建O_TRUNC,清空;再使用OPEN时必须要带O_RDONLY(只读)、O_WRONLY(只写)、O_RDWR(读和写)其中的一个;
如何给函数传递标志位?
上边所有的选项都是宏定义;在C中想要传标记位(布尔型/整型)只能传一种选项(表示一种状态),如果想要传递多个,可以考虑一个整型有32位,于是多个标记位可以通过每个位进行传递;
位图
#include <stdio.h> #include <unistd.h> #include <string.h>//0000 0000 用整形中的不同的bit位;就可以表示一种状态; #define ONE 0x1 //0000 0001 #define TWO 0x2 //0000 0010 #define THREE 0x4 //0000 0100void show(int flags) {if(flags & ONE) printf("hello one\n");if (flags & TWO) printf("hello two\n");if (flags & THREE) printf("hello three\n"); }int main() {show(ONE);printf("---------------------------------\n");show(TWO);printf("---------------------------------\n");show(ONE | TWO);printf("---------------------------------\n");show(ONE | TWO | THREE);printf("---------------------------------\n");return 0; }运行结果:
操作系统中传递标志位的方案就是按照代码所述进行传递的;也就是flags;
返回值:
#include <stdio.h> #include <unistd.h> #include <string.h> #include <sys/types.h> #include <sys/stat.h> #include <fcnt.h>int main() {int fd = open("log.txt", O_WRONLY);if (fd < 0){perror("open");return 1;}//open successprintf("open success,fd:%d \n", fd);return 0; }此时会报错没有log.txt 文件,因为系统接口不会帮你去自动创建文件,需要使用对应的标志位;标志位操作如函数所示;
#include <stdio.h> #include <unistd.h> #include <string.h> #include <sys/types.h> #include <sys/stat.h> #include <fcnt.h>int main() {int fd = open("log.txt", O_WRONLY|O_CREAT);if (fd < 0){perror("open");return 1;}//open successprintf("open success,fd:%d \n", fd);return 0; }但此时的运行结果正常,但是文件的权限如图
在需要创建文件的时候不能使用第一个open函数,应该使用第二个函数,一般仅仅需要读取的时候会用到第一个接口,当需要创建文件的时候就需要使用第二个接口,来给文件添加权限;
用法
#include <stdio.h> #include <unistd.h> #include <string.h> #include <sys/types.h> #include <sys/stat.h> #include <fcnt.h>int main() {int fd = open("log.txt", O_WRONLY|O_CREAT,0666);// 0666表示 :rw-rw-rw-if (fd < 0){perror("open");return 1;}//open successprintf("open success,fd:%d \n", fd);return 0; }但此时的运行创建的文件权限并不是 rw-rw-rw- 而是rw-rw-r-- 是因为在系统中存在umask,这时存在一个接口,可以在进程的上下文中设置属于进程的umask;
#include <sys/types.h>
#include <sys/stat.h>
mode_t umask(mode_t mask);
#include <stdio.h> #include <unistd.h> #include <string.h> #include <sys/types.h> #include <sys/stat.h> #include <fcnt.h>int main() {umask(0);int fd = open("log.txt", O_WRONLY|O_CREAT,0666);// 0666表示 :rw-rw-rw-if (fd < 0){perror("open");return 1;}//open successprintf("open success,fd:%d \n", fd);close(fd);//关闭return 0; }通过umask操作后既可以创建好666权限的log.txt文件;
如果文件已经存在的话,就用两个参数的函数;
write函数;
#include <stdio.h> #include <unistd.h> #include <string.h> #include <sys/types.h> #include <sys/stat.h> #include <fcnt.h>int main() {umask(0);//int fd = open("log.txt", O_WRONLY|O_CREAT,0666);// 0666表示 :rw-rw-rw-int fd = open("log.txt", O_WRONLY);if (fd < 0){perror("open");return 1;}const char *s = "hello write";write(fd, s, strlen(s));//open successprintf("open success,fd:%d \n", fd);return 0; }此时文件中写入hello write,但是当再次使用write向这个文件写aa,文件中的内容会变成aallo write;如果想打开文件的时候先清空需要在open中使用标志位O_TRUNC,文件中就会变为aa;标志位O_APPEND 追加;
read
返回值,读到的字节数;
#include <stdio.h> #include <unistd.h> #include <string.h> #include <sys/types.h> #include <sys/stat.h> #include <fcnt.h>int main() {int fd = open("log.txt", O_RDONLY);if (fd < 0){perror("open");return 1;}printf("open success,fd:%d \n", fd);char buffer[64];memset(buffer, '\0',sizeof(buffer));read(fd, buffer, sizeof(buffer));printf("%s", buffer);return 0; }这就是read文件;




文件描述符(分析接口的细节,引入fd)
如何深入理解上边的代码?
当打开一个文件的时候,文件描述符fd的值为3,为什么没有0,1,2;为什么是连续的;
0对应标准输入,1对应标准输出,2对应标准错误;
int main() {fprintf(stdout, "hello stdout\n");const char *s = "hello 1"\n;write(1, s, strlen);return 0; }此代码将两行都直接输出到显示器中;
int main() {int a = 10;fscanf(stdin, "%d", &a);printf("%d\n", a);return 0; }此时可以直接输入一个数,此数字也将打印出;
int main() {char input[16];ssize_t s = read(0, input, sizeof(input));if (s > 0){input[s] = '\0';printf("%s\n", input);}return 0; }这个代码与上面的代码效果一样;
FILE 文件指针 :FILE是一个结构体,C标准库设计的FILE结构体,一般内部会有多种成员;C文件库函数内部一定要调用系统调用,在系统角度,只认识fd不认识FILE是什么,所以FILE结构体中一定封装了fd;
而stdin、stdout、stderr是FILE* 的所以是FILE结构体,内部肯定有fd;
周边文件(fd的理解,fd和FILE,fd分配规则,fd和重定向,缓冲区)
所以fd是什么呢?
进程要访问文件,必须要先打开文件;
一个进程可以打开多个文件;
一般而言,进程:打开的文件可以是1:n的;
一个文件要想被访问,需要加载到内存中才能被访问;
如果是多个进程都打开自己的文件呢?那么系统中会出现大量的被打开的文件;
所以操作系统需要把大量的文件管理起来;
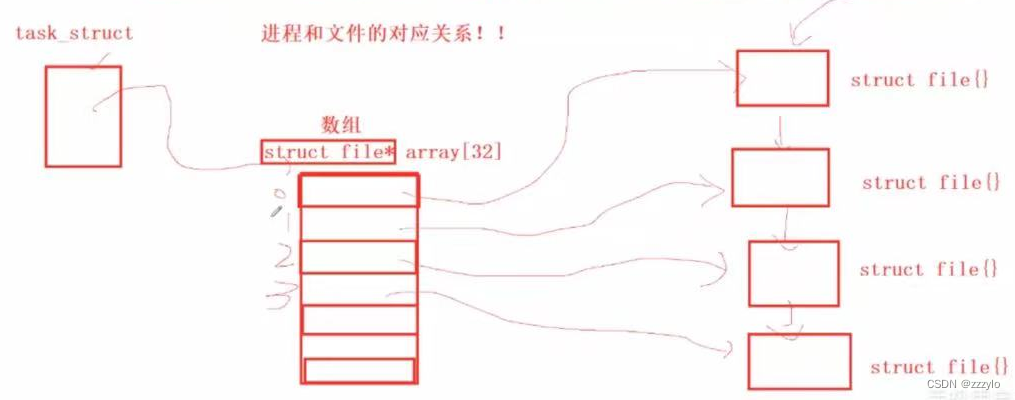
在内核中,操作系统内部要管理每一个被打开的文件,构建结构体
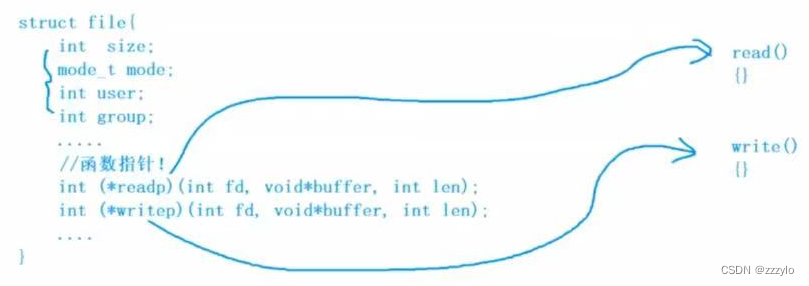
struct file
{
struct file *next;
struct file *prev;
//包含了一个被打开的文件的几乎所有的内容;(不仅仅包含属性,包括文件的权限、
//链接信息等)
}
打开一个文件就创建struct file 的对象,充当一个被打开的文件;
所有打开的文件通过这样的链表来管理;所以当进程和文件的对应关系就是只要找到链表的头部就可以找到所有的文件;
fd的本质就是一个数组的下标;
文件分为两种,被打开的文件(内存文件)和没有被打开的文件;假设有100000个文件,只有500个被打开,其他的文件都在磁盘中,等待被打开(内容+属性);被打开的文件是被进程打开,是通过进程使用open系统调用,调用系统打开文件;
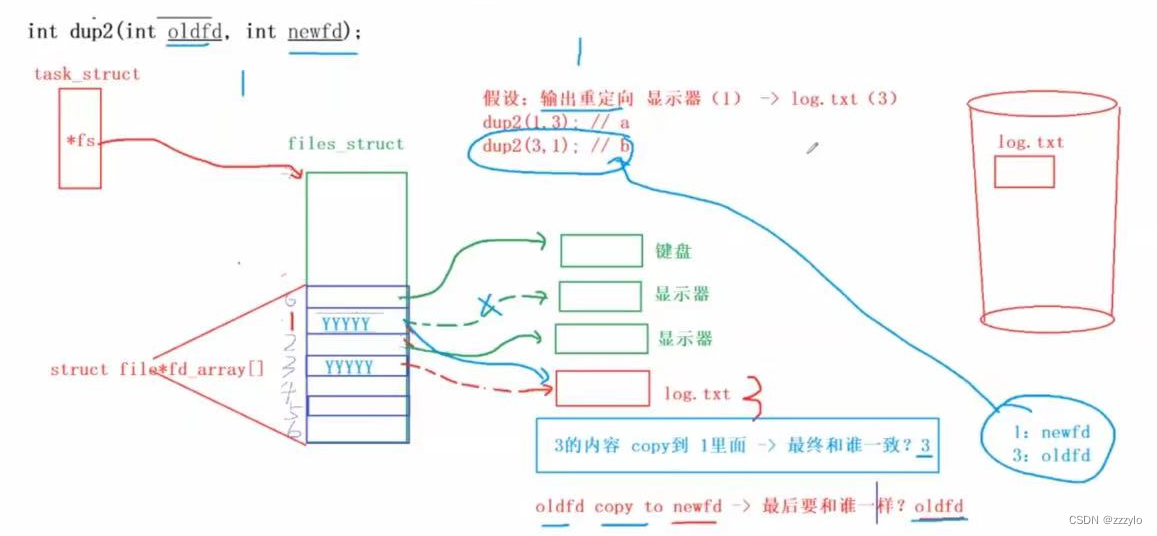
files_struct与其左侧的部分为进程管理,右侧的部分是文件管理;
当使用fopen函数时,会调用open系统调用接口,然后得到一个文件描述符fd,然后将fd封装为FILE,最后一FILE * 的方式返回fopen函数;
fwrite函数,传递进来一个FILE * ,内部有fd,并且内部封装这write,就会将fd传到write中,最后操作系统内部能找到进程的task_struct,然后找到进程内部的*fs指针,就找到files_struct,然后找到fd_array[],配合传进的fd就找到了struct_file ,内存文件就被找到了;

文件描述符的分配规则
#include <stdio.h> #include <unistd.h> #include <sys/types.h> #include <sys/stat.h> #include <fcntl.h>int main() {int fd = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC,0666);if (fd < 0){perror("open");return 1;}printf("fd:%d\n", fd);close(fd);return 0; }此时运行输出的为3,因为0、1、2被占用了;
#include <stdio.h> #include <unistd.h> #include <sys/types.h> #include <sys/stat.h> #include <fcntl.h>int main() {close(0);int fd = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC);if (fd < 0){perror("open");return 1;}printf("fd:%d\n", fd);close(fd);return 0; }此时输出的是0;fd的分配规则是,前边关掉0,后边就会分配0,前边关掉2,就会分配2;
当操作系统打开文件时,需要先在内存中打开这个文件,打开文件后,有了进程对象,就要和这个进程关联起来在对应的fd_arrray[]中搜索哪个数字没有被占用,会遍历整个fd_array,找到最小的,没有被占用的文件描述符;
例1
#include <stdio.h> #include <unistd.h> #include <sys/types.h> #include <sys/stat.h> #include <fcntl.h>int main() {close(1);int fd = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);if (fd < 0){perror("open");return 1;}printf("fd:%d\n", fd);return 0; }此时将代码close(fd)删除,显示器不显示结果,打开log.txt文件后,文件中显示内容 fd:1
例2
#include <stdio.h> #include <unistd.h> #include <sys/types.h> #include <sys/stat.h> #include <fcntl.h>int main() {close(1);int fd = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);if (fd < 0){perror("open");return 1;}printf("fd:%d\n", fd);fflush(stdout);close(fd);return 0; }此时的运行结果与上边的例1,运行结果一样;
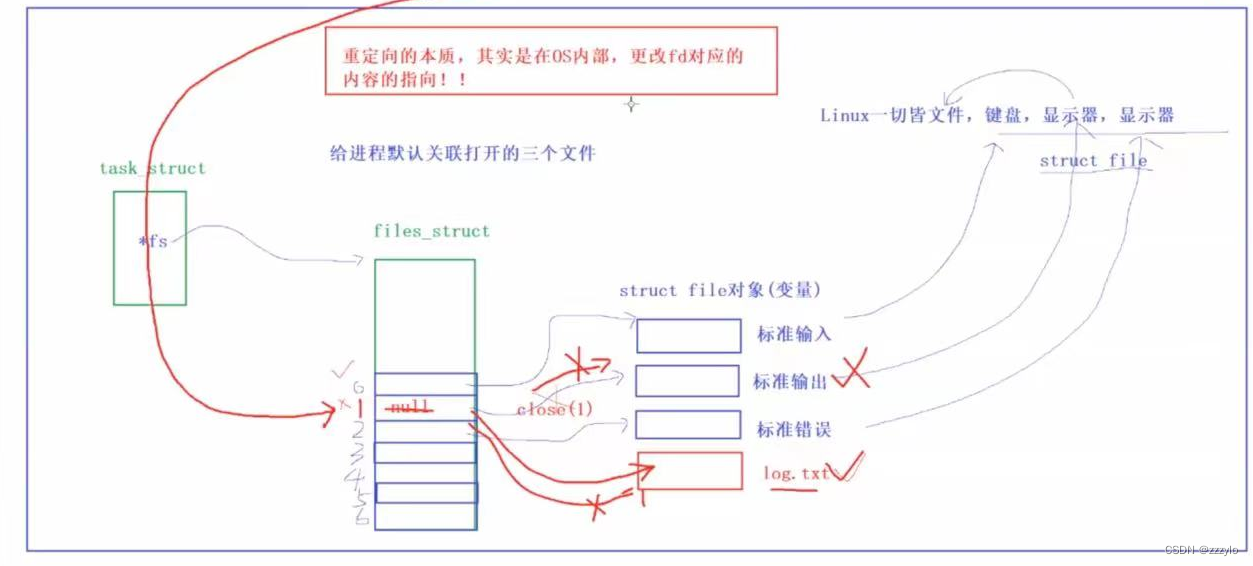
在close(1)后边的内容本来是应该打印到显示器中的,但是都打印到了文件中,但是将close(1)删除后,内容就会被打印到显示器中;这就叫做除数重定向;
重定向
输出重定向原理
在打开文件会先创建log.txt文件的struct_file对象,如果此时将1关闭(将是将进程和这个文件的关联关系去掉),那么此时open开始遍历file_struct,于是此时1就指向了log.txt;而C语言层面,stdout,只认识数字1,于是就发生了上面的情况;
输入重定向
#include <stdio.h> #include <unistd.h> #include <sys/types.h> #include <sys/stat.h> #include <fcntl.h>int main() {int fd = open("log.txt", O_RDONLY);if (fd < 0){perror("open");return 1;}printf("fd:%d\n", fd);char buffer[64];fgets(buffer, sizeof buffer, stdin);printf("%s\n", buffer);return 0; }此时会将文件log.txt文件中的第一行打印出来,因为gets函数只打印第一行;
本来应该从键盘中读取的内容,现在从文件中读取了,这就是输入重定向;
追加重定向
#include <stdio.h> #include <unistd.h> #include <sys/types.h> #include <sys/stat.h> #include <fcntl.h>int main() {close(1);int fd = open("log.txt", O_RDONLY|O_APPEND|O_CREAT);if (fd < 0){perror("open");return 1;}fprintf(stdout,"hello baby!\n");return 0; }输入重定向会将文件中的内容清空再向文件中打印,将open的方式改变一下就可以实现,追加重定向;但是此时还有一些问题,在重定向时需要关闭0,1,2,再打开文件描述符才有的;事实上重定向并不是这么实现的;
重定向的系统调用 dup
dup2,是将oldfd拷贝给newfd,拷贝的东西是files_struct结构体中的指针;就是将3的内容拷贝到1中;也就是让原来指向3的指向1;
代码
#include <stdio.h> #include <unistd.h> #include <sys/types.h> #include <sys/stat.h> #include <fcntl.h>int main(int argc,char argv[]) {if (argc != 2){return 2;}int fd = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC);if (fd < 0){perror("open");return 1;}dup2(fd, 1);fprintf(stdout,"%s\n", argv[1]);return 0; }此为输出重定向的使用,输入和追加重定向方法与前边一致;
如何理解一切皆文件?
Linux的设计哲学,体现在软件设计层面;
如何用C语言实现面向对象甚至是运行时的多态?
类包含,成员属性和成员方法;
C语言中struct,结构体是面向对象语言的起点;
struct不能包含函数;
但是如果必须在struct中包含成员方法;
但是可以包含函数指针;这时就可以使用C语言封装一个类;
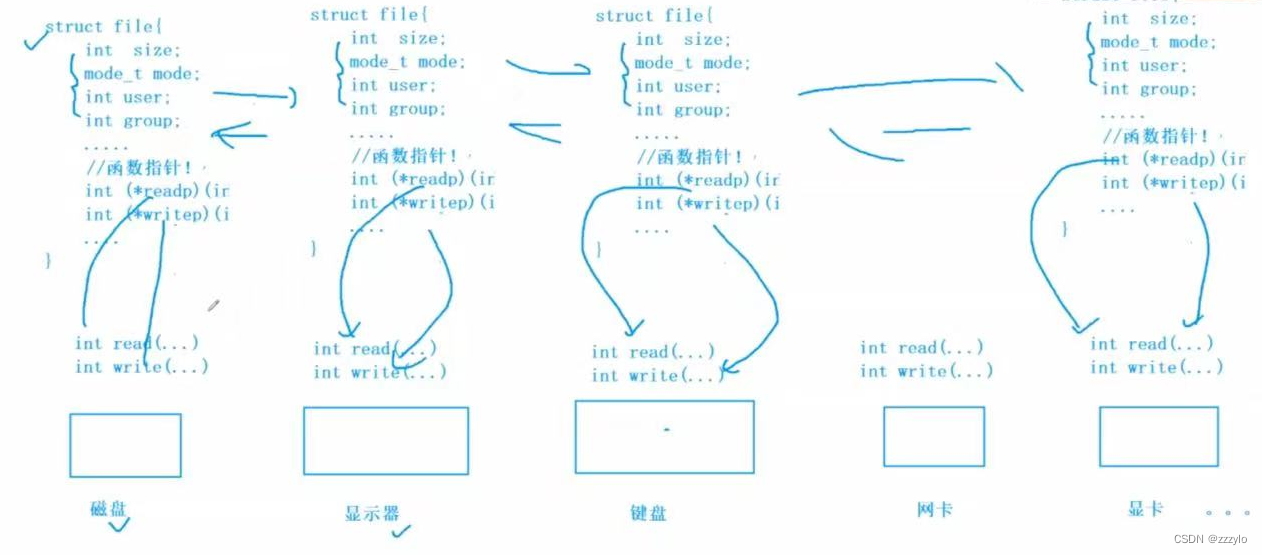
首先底层不同的硬件,对应着不同的操作方法;但是这些硬件都是外设,所以每一个设备的核心访问函数,都可以是read、write、I/O;所以,所有的设备都可以有自己的read和write,但是代码的实现一定是不一样的;
此时就相当于直接使用函数指针调用不同外设对应的读写方法,操作系统只通过struct file即可对应到各种硬件,这样就没有硬件的差别了,所有的外设都是struct file;
这就是Linux的一切皆文件;这种设计方案叫做VFS,虚拟文件系统;

缓冲区
什么是缓冲区?
是一段内存空间;
用户层缓冲区:char buffer[64],scanf(bufer);为了方便;
为什么要有缓冲区?
写透模式(WT),相当于寄件人直接将包裹送给收件人,成本高,慢;
写回模式(WB),通过顺丰快递邮寄包裹,;
顺丰快递,相当于缓冲区,快;主要为了提高用户的相应速度;
常见的缓冲区刷新策略
立即刷新;
行刷新(行缓冲)\n;将\n之前的数据刷新出去;
满刷新(全缓冲);将缓冲区写满了才能刷新出去;
特殊情况:
用户强制刷新(fflush);
进程退出;
缓冲策略,一般+特殊;
缓冲区在哪里?
#include <stdio.h> #include <string.h> #include <unistd.h> #include <sys/types.h> #include <sys/stat.h> #include <fcntl.h>int main() {//C语言提供的printf("hello printf\n");fprintf(stdout, "hello fprintf\n");const char *s = "hello fputs\n";fputs(s, stdout);//操作系统提供的const char *ss = "hello write\n";write(1, ss, strlen(ss));fork();return 0; }运行结果:
当使用指令 ./myfile > log.txt时,log.txt中的内容;
如果将代码中的fork函数注释后,那log.txt文件中的内容与第一个一样;
这种现象与fork有关;
可以看见,C语言提供的部分被打印了两次;
关于缓冲区的认识
一般而言行缓冲的设备文件一般是显示器;
全缓冲的设备文件一般是磁盘文件;
所有的设备都倾向于全缓冲,因为缓冲区满了才刷新,需要更少次的外设的访问,也就提高了效率;和外部设备IO的时候,数据的大小不是最主要的矛盾,和外设的IO过程是最耗费时间的;其他刷新策略是结合具体的情况做的妥协;
显示器:直接给用户看的,一方面要照顾效率,一方面要照顾用户体验,极端情况,是可以自定义规则的;
解决上面的问题
C,IO接口打印了两次;
系统接口,只打印了一次;
首先fork上面的代码执行完了并不代表数据已经刷新了;
缓冲区是由C标准库提供的;
fputs是通过进程写到C标准库维护的缓冲区中,然后再通过C标准库将缓冲区的内容刷新到操作系统中,而刷新方法就是调用write接口;而调用write接口就会直接将数据写给操作系统,不会写给缓冲区;
在代码中C语言提供的部分,如果想显示器打印的话,刷新策略是行刷新,那么最后执行fork的时候一定是函数执行完了,并且数据已经被刷新了;fork无意义;
如果对应的程序进行了重定向,本质是本来应该向显示器打印,变成了要想磁盘文件打印,隐形的刷新策略变成了全缓冲,那么\n就没有意义了;fork的时候一定是函数一定执行完了,但是数据还没有刷新;在当前进程对应的C标准库中的缓冲区中;这部分数据属于父进程的数据;fork之后父子进程各自退出,而刷新就是写入的过程,在退出时发生写时拷贝,所以就会出现两份的数据;
C标准库给我们提供的用户级缓冲区,还存在内核级缓冲区;
#include <stdio.h> #include <string.h> #include <unistd.h>int main() {//C语言提供的printf("hello printf\n");fprintf(stdout, "hello fprintf\n");const char *s = "hello fputs\n";fputs(s, stdout);//操作系统提供的const char *ss = "hello write\n";write(1, ss, strlen(ss));fflush(stdout);fork();return 0; }在fork之前加一个fflush函数,此时执行命令 ./myfile > log.txt 后,log.txt中的文件与直接运行文件输出的结果一样;
fflush是C语言提供的接口,所以刷新的时候是将数据直接刷新到缓冲区中,在fork之后数据已经没了,所以就没有了,还有在fflush的时候只刷新了stdout,那只传入stdout就能刷新到缓冲区吗,C语言中打开文件调用的接口是fopen,fopen对应的的返回值是FILE *,struct FILE,FILE是结构体,内部封装了fd,但不是只封装了fd,除了fd还有该文件fd对应的语言层的缓冲区结构;
C语言中打开的file,叫做文件流;cout cin 是类,类中包含fd、定义buffer,<<是操作符,使用operator对<<进行重载,将数据打印到类内的buffer中,然后定期去刷新;




设计用户缓冲区
代码
#include <stdio.h> #include <string.h> #include <unistd.h> #include <sys/types.h> #include <sys/stat.h> #include <fcntl.h> #include <assert.h> #include <stdlib.h>#define NUM 1024struct MyFILE_ {int fd;char buffer[NUM];int end;//当前缓冲区的结尾 };typedef struct MyFILE_ MyFILE;MyFILE *fopen_(const char *pathname, const char *mode) {assert(pathname);assert(mode);//pathname和mode不能为空;MyFILE *fp = NULL;if (strcmp(mode, "r") == 0){}else if (strcmp(mode, "r+") == 0){}else if (strcmp(mode, "w") == 0){int fd = open(pathname, O_WRONLY | O_TRUNC | O_CREAT, 0666);if (fd >= 0)//如果申请或者打开失败了就会返回fp=NULL;//如果成功打开并申请空间,fp返回申请的空间地址;{fp = (MyFILE*)malloc(sizeof(MyFILE));memset(fp, 0, sizeof(MyFILE));//将缓冲区清空;fp->fd = fd;}}else if (strcmp(mode, "w+") == 0){}else if (strcmp(mode, "a") == 0){}else if (strcmp(mode, "a+") == 0){}else{//什么都不做}return fp; }//向缓冲区中写入message的数据 void fputs_(const char *message, MyFILE *fp) {assert(message);assert(fp);strcpy(fp->buffer + fp->end,message);//strcpy函数会自己在后边加\0;fp->end += strlen(message);//向标准输入、标准输出、标准错误中刷新时需要调整策略;if (fp->fd == 0){//标准输入}else if (fp->fd == 1){//标准输出//行刷新if (fp->buffer[fp->end - 1] == '\n'){fprintf(stderr, "fflush:%s", fp->buffer);write(fp->fd, fp->buffer, fp->end);fp->end = 0;}}else if (fp->fd == 2){//标准错误}else{//其他文件}}fflush_(MyFILE *fp) {assert(fp);if (fp->end != 0)//判断缓冲区中有内容才刷新;{//其实是将数据写到了内核;write(fp->fd, fp->buffer, fp->end);syncfs(fp->fd);//将数据写入到磁盘中;fp->end = 0;} }fclose_(MyFILE *fp) {assert(fp);fflush_(fp);close(fp->fd);free(fp); }int main() {MyFILE *fp = fopen_("./log.txt", "w");if (fp == NULL){printf("open file error");return 0;}fputs_("1:hello world", fp);fputs_(:2:hello world\n", fp);fputs_("3:hello world", fp);fputs_("4:hello world\n", fp);fclose_(fp);return 0; }此时最终的打印结果是,1:hello world 2:hello world
3:hello world 4:hello world
遇到\n才刷新;
而刷新策略是用户通过执行C标准库中的代码逻辑来执行刷新动作;
效率提高体现在因为C提供了缓冲区,那么我们就通过策略减少了IO的执行次数而不是数据量;
修改myshell支持重定向
#include <stdio.h> #include <stdlib.h> #include <string.h> #include <unistd.h> #include <sys/wait.h> #include <sys/types.h> #include <sys/stat.h> #include <fcntl.h> #include <assert.h>#define NUM 1024 #define SIZE 32 #define SEP " "//保存打散之后的命令行字符串; char *g_argv[SIZE]; //保存完整的命令行字符串; char cmd_line[NUM];//定义一个大小是1024的缓冲区;#define INPUT_REDIR 1 #define OUTPUT_REDIR 2 #define APPEND_REDIR 3 #define NONE_REDIR 0int redir_status=NONE_REDIR;char *CheckRedit(char *start) {assert(start);char *end = start + strlen(start) - 1;//此时直接指向字符串最后一个有效字符while (end >= start){if (*end == '>'){if (*(end-1) == '>'){redir_status = APPEND_REDIR;*(end - 1) = '\0';end++;break;}redir_status = OUTPUT_REDIR;*end = '\0';end++;break;}else if (*end == '<'){redir_status = INPUT_REDIR;*end = '\0';end++;break;}else{end--;}}if (end >= start){return end;//要打开的文件;}else{return NULL;} }//shell 运行原理通过让子进程执行命令,父进程等待并且解析命令 //除了要执行系统的命令还要执行自己的命令,如果自己的命令崩溃那么不会影响父进程,使得父进程能够继续解析命令; int main() {//0、命令行解释器一定是一个常驻内存的进程,就是不退出;while (1){//1、打印出提示信息//[zyl@123456host myshell]printf("[root@我的主机 myshell]# \n");//后边需要加\n ,否则数据在缓冲区内;fflush(stdout);//在输入命令时总是换行,与printf里的内容不在一行;memset(cmd_line, '\0', sizeof cmd_line);//sizeof可以不带圆括号;//2、获取用户的输入,输入的是各种命令和选项:ls -a -l -i//ls -a -l > log.txt//ls -a -l >> log.txt//ls -a -a << log.txtif (fgets(cmd_line, sizeof cmd_line, stdin) == NULL){continue;}cmd_line[strlen(cmd_line) - 1] = '\0';//由于在输入时输入了回车,所以在打印的时候也会打印处一行空行,//于是通过上边的这行代码将 \n 置为0;//分析是否有重定向;"ls -a -l > log.txt" 也及时先找到 > 符号,然后将其转化为ls -a -l \0 log.txt//然后将log.txt文件打开进行重定向就可以了;char *sep = CheckRedit(cmd_line);printf("echo: %s\n", cmd_line);//3、命令行字符串解析:将输入的命令 "ls -a -l -i" 转换成 "ls" "-a" "-l" "-i"g_argv[0] = strtok(cmd_line, SEP);//第一次调用,要传入原始字符int index = 1;if (strcmp(g_argv[0], "ls") == 0)//使得ls命令行带有颜色{g_argv[index++] = "--color=auto";}//while 先调用函数,然后赋值给g_argv,然后while检测g_argv中的值;while (g_argv[index] = strtok(NULL, SEP));//第二次,如果还要解析原始字符串,传入NULL;for (index = 0; g_argv[index]; index++){printf("g_argv[%d]: %s\n", index, g_argv[index]);}//4、内置命令处理:让父进程自己执行的额命令,叫做内置命令(内建命令);//本质就是shell中的函数调用;//如果没有第四步,那么执行任何命令都会运行execvp,那么在cd .. 的时候就会出现路径不发生变化的现象//只会使子进程的路径发生变化,已运行完就会退出;但是pwb打印出来的相当于是父进程的路径没有改变;if (strcmp(g_argv[0], "cd") == 0)//不想让子进程执行,希望使父进程执行命令,{//chdir函数更改当前的路径if (g_argv[1] != NULL){chdir(g_argv[1]);}continue;}//5、fork()pid_t id = fork();if (id == 0){if (sep != NULL){int fd = -1;//说明命令曾经有重定向switch (redir_status){case INPUT_REDIR:fd = open(sep, O_WRONLY);dup2(fd, 0);break;case OUTPUT_REDIR:fd = open(sep, O_WRONLY | O_TRUNC | O_CREAT, 0666);dup2(fd, 1);break;case APPEND_REDIR:fd = open(sep, O_WRONLY | O_APPEND | O_CREAT, 0666);dup2(fd, 1);break;default:pritnf("bug?\n");break;}}//childprintf("下面的功能让子进程进行!\n");execvp(g_argv[0], g_argv);exit(1);}int status = 0;pid_t ret = waitpid(id, &status, 0);if (ret > 0){printf("exit code: %d\n", WEXITSTATUS(status));}}//return 0; }
前边小问题的解决
close(fd)之后,文件没有数据;
#include <stdio.h> #include <string.h> #include <sys/types.h> #include <sys/stat.h> #include <fcntl.h> #include <unistd.h>int main() {close(1);int fd = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);if (fd < 0){perror("open");return 0;}printf("hello world : %d\n",fd);//向stdout 中打印;close(fd);return 0; }此时打开文件log.txt文件没有内容,正常是应该有内容的;
当在close前边加一个 fflush(stdout) ;在运行程序后打开文件log.txt就有了内容;
printf相当于数据暂时存放在stdout的缓冲区中,如果close(fd),相当于还未刷新就直接关闭了stdout,使得数据无法刷新出来;
1,2stdout和stderr有什么不同?
#include <iostream> #include <stdio.h> #include <string.h> #include <sys/types.h> #include <sys/stat.h> #include <fcntl.h> #include <unistd.h>int main() {//stdout -> 1printf("hello printf 1\n");fprintf(stdout, "hello fprintf 1\n");//stderr -> 2perror("hello perror 2");const char *s1 = "hello write 1\n";write(1, s1, strlen(s1));const char *s2 = "hello write 2\n";write(2, s2, strlen(s2));std::cout << "hello cout 1" << std::endl;std::cerr << "hello cerr 2" << std::endl;return 0; }直接运行程序的结果
当使用指令 ./myfile > log.txt后,文件log.txt中的内容为
可见指令的重定向是往1 号文件描述符写入;1与2对应的都是显示器文件,但他们两个是不同的显示器文件,可以认为是同一个显示器文件被打开了两次;
错误信息依旧往显示器上打印,一般而言如果程序运行有可能有问题的画建议使用stderr打印,如果是常规的文本内容的话一般使用stdout打印;
可以通过此将错误信息和标准输出分两个文件打印出来,也就有了错误日志;
可以使用命令 ./myfile > good.txt 2 > err.txt;
命令 ./myfile > log.txt 2 > &1;意思是将1中的内容给2拷贝一份,2也就指向了与1相同的位置;
自己实现perror
void myperror(const char *msg) {fprintf(stderr, "%s,%s\n", msg, strerror(errno)); }


理解文件系统
背景知识
1、前边的内容时进程和被打开的文件之间的对应关系;那么没有被打开的文件在哪里呢?
在磁盘中,磁盘级文件:
2、磁盘级文件的侧重点?
单个文件的角度:这个文件在哪里?这个文件多大?这个文件的其他属性是什么?
站在系统的角度:一共有多少个文件?各自属性在哪里?如何快速找?还能储存多少个文件?如何快速找到指定的文件?
如何对磁盘文件进行分门别类的存储用来支持更好的存取?
3、磁盘文件,了解磁盘是什么?
内存 ——掉电易失存储介质;
磁盘——永久性存储介质;
永久性介质
SSD(固态硬盘,比磁盘快)、U盘、flash卡、光盘、磁带;
磁盘是一个外设,同时还是计算机中唯一的一个机械设备;磁盘很慢CPU纳秒级别、内存微秒级别,磁盘是毫秒或秒级别的;操作系统有一些提速的方式;
4、磁盘的结构
(1)磁盘的物理结构
磁盘盘片,磁头,伺服系统,音圈马达;
一叠光盘就是盘片,音圈马达在光盘中间;
当通电后盘片会快速旋转,大概7200转,在盘片转动的同时,磁头快速左右摇摆,这个摇摆就是寻址;而数据就在盘面上;并且每一个面都有磁头,盘面上会存储数据,而计算机只认识二进制,本质上存储的是二进制,在日常生活中,存在两态的是磁铁,南极和北极,可以将磁盘盘面上想象成很多细小的磁铁颗粒,向磁盘写入,本质就是改变磁盘上的正负性;磁头都是一些电子信号,可以在磁盘的一些位置产生放电行为,改变磁盘的一些区域的正负性,从而将数据向磁盘中写入二进制;
磁头和盘面不是挨着的,因为挨着就会将磁盘刮花,可能会将数据丢失;
磁盘寻道的过程;(可以搜索看网络视频);
(2)磁盘的存储结构
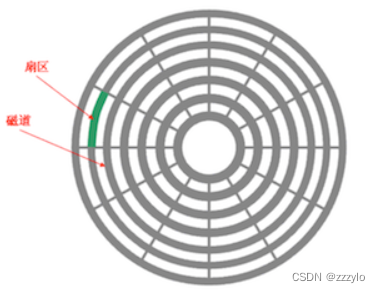
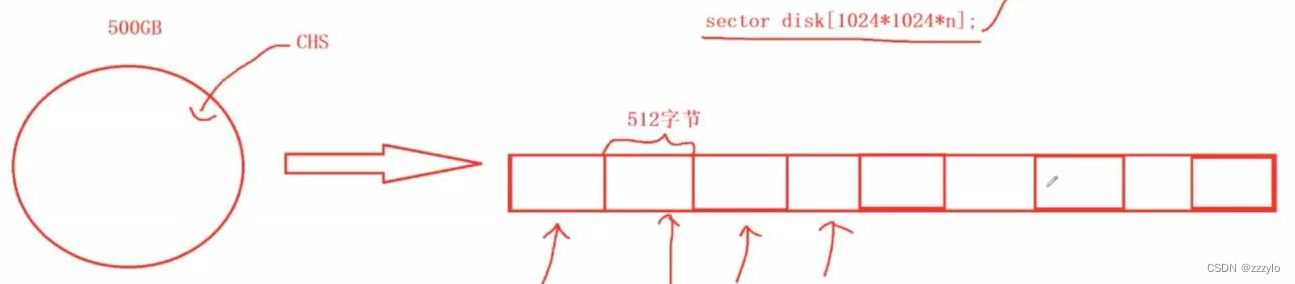
磁道容量比较大,使用时一般使用磁道的一部分,一小部分叫做磁道的扇区;相同半径的多个磁道合起来叫做柱面;扇区是磁盘存储的基本单位(一般512字节,也有4kb的);
在物理上如何将数据写入到一个扇区中?
首先确认在那个盘面上;
然后确认在哪一个磁道(柱面)上;哪一个同心圆上;
然后确定在哪一个扇区上;
这种寻址方案叫做CHS寻址;
如果有了CHS就可以找到任何一个扇区,那么整个盘面就都可以找到了;
(3)磁盘的抽象结构
就像磁带一样,如果将磁带中的磁条拉出来就是线性的;可以将磁盘想象成磁带,就可以将一个大磁盘抽象成数组,要是访问一个扇区,只要知道数组的下标就可以;这种寻址方法叫做LBA寻址方式,所以在要访问磁盘的时候只需要将LBA的寻址方式转换成CHS方式即可;
而操作系统通过LBA去访问;
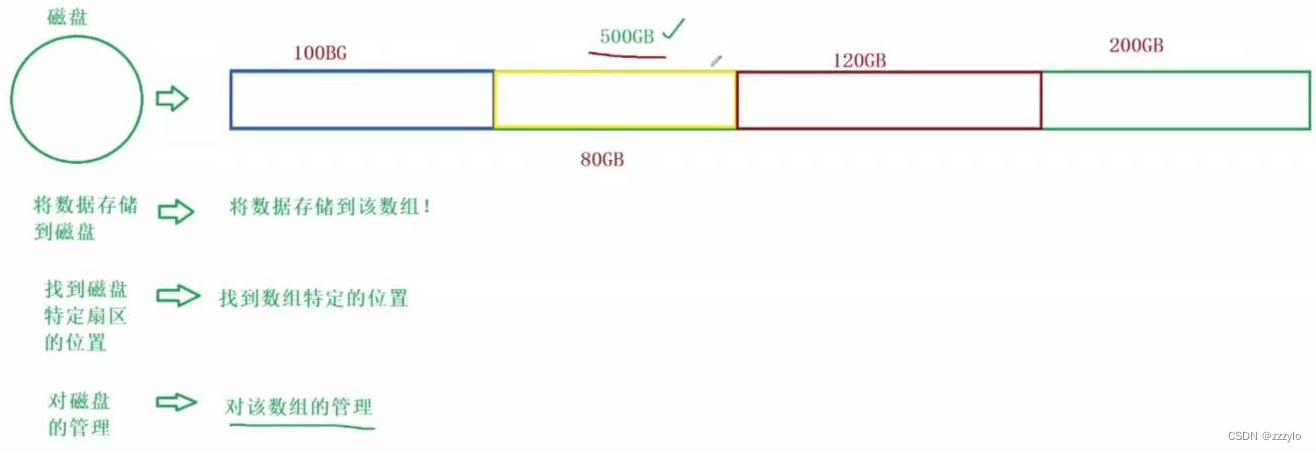
500GB区域太大不方便管理,所以需要将其分为几个区域;
对磁盘的管理转化成了对一个小分区的管理;
而对一个小分区的管理还需要对分区继续做拆分;
相当于国家划分为一个个省,将省拆分为一个个市,再将市划分为县;
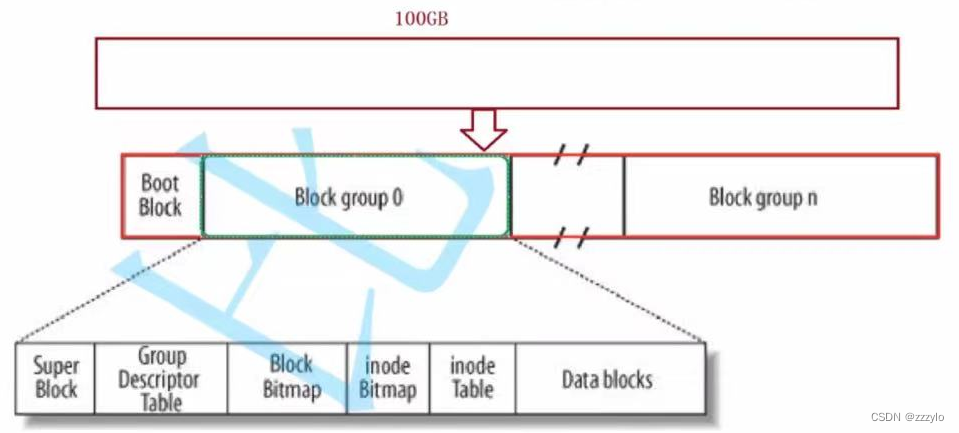
SuperBlock:不是所有的块组都有,文件系统的属性信息,表示的是整个分区(如图中是100GB的信息而不是所在Block group的信息)有多少个块组,那些块组已经满了,中国有过多少个数据块可以被写,有多少个数据块可以被占,inode有多少个,还有多少个没有被使用以及应用了多少;
Data Blocks:虽然磁盘的基本单位是扇区,但是操作系统(文件系统)和磁盘进行IO的基本单位是4kb(8*512byte,块大小,所以磁盘一般称为块设备);因为512太小了,在做数据拷贝的时候可能超过512,所以就会导致多次IO,进而降低效率;如果操作系统使用和磁盘一样的大小,万一磁盘的基本大小变了,那么操作系统的源代码也需要改变,这样就是将硬件和软件进行解耦;所以Data Blocks可以想象成有多个4Kb大小的集合,Linux在存储时是将文件的额内容和属性分开存储的,此部分保存的是文件的内容;(有多个)
inode Table:inode是一个带下为128 字节的空间,保存的是对应文件的属性;inode Table内保存的是该块组的所有文件的inode的集合,需要表示唯一性,所以每一个inode块都要有一个inode编号;一般而言一个文件一个inode一个inode编号;(有多个)
Block Bitmap:假设有10000+个blocks,就有10000+个比特位,比特位和特定的block是一一对应的,比特位为1,代表该block被占用,否则表示可用;
inode Bitmap:假设有10000+个inode节点,inode Bitmap中就有10000+个比特位,比特位和特定的inode是一一对应的,其中Bitmap中比特位为1,代表该inode被占用,否则表示可用;
Group Descriptor Table(GDT):代表块组描述符,表示的是这个块组多大,已经使用了多少,有多少个inode已经占用了多少还剩多少,一共有多少个block,使用了多少;
这样就可以让文件的额信息可追溯,可管理;
将块组分割为上面的内容,并且写入了相关的管理数据,每一个块组都是如此,整个分区就被写入了文件系统信息(有可能一个块组什么信息都没有,也就是这个块组就是的两个Bitmap全是0,这个过程就叫做格式化);
一个文件 “只” 对应一个inode属性节点,inode编号;
一个文件只能有一个block吗?
如果一个文件在4kb内那么就对应一个bloick,如果文件夹太大,有几个G等,就会对应多个inode;
于是有问题:
1、哪些block属于同一个文件?
2、找到文件只要找到对应的inode,就能找到该文件的额inode属性集合,可是文件的内容怎么找?
在inode中包含着一个数组,他可以包含对应的块的编号;先通过inode编号找到对应的inode然后通过block数组找到对应的block;
如果文件特别大怎么办?
在data block中,不是所有的data block只能存文件数据,也可以存其他块文件的块号;相当于多叉树的形式;
inode和文件名
找到文件需要先找到inode编号 -> 分区特定的block group -> inode -> 属性 -> 内容;
Linux中inode属性里面没有文件名这样的说法;
预备知识
1、一个目录下,可以保存很多文件,但是这些文件没有重复的文件名;
2、目录是文件,目录要有自己的inode,要有自己的data block;
3、一个文件的文件名是在他所属目录文件的data block中存储的;目录文件的data block中存储的是文件名和inode编号的映射关系;互为Key值;
此时就可以理解创建文件需要有目录的w权限,需要将文件名写入,显示文件名与属性需要有r权限,有了r权限才能读取目录文件的内容;
1、创建文件,系统做了什么?
根据文件系统找到目录所在的分区,然后找到目录所在的块组,在inode Bitmap中找到为0的比特位,将0置1,同时得到inode编号,在inodeTable中将新建文件的属性填入;然后将从用户层来的文件名和从内核来的inode填到目录文件中去;
2、删除文件,系统做了什么?
找到目录对应的data block,通过文件名找到对应的inode,然后将inode Bitmap中对应的1置为0;并将Block Bitmap对应的1置为0;在从目录中把文件名和inode的映射关系去掉;
恢复只要找到所删除文件的inode就可以找回文件;在Linux中有删除文件的日志,可以找到;能恢复出来的前提是曾经的金瓯的属性和datablock没有被占用;
3、查看文件,系统做了什么?
ls ll cat
ls的时候找到目录,找到目录的 inode,然后找到datablock将文件名全部找到然后显示;
ll找到目录,找到目录对应的datablock,根据文件名对应的inode找到各自文件的属性,然后拼接好显示出来;
echo “hello” >myfile.c,将文件打开然后向文件中写入,文件打开对应的file对象就有了,然后把数据写到file对象内核中的额缓冲区,操作系统定期刷新,把数据刷新到文件上,就是向磁盘上写了,有文件名,目录也知道,所以就能找到文件的inode,就能找到inode对应的属性,也就能找到对应的data block,就将数据刷到了盘上;
cat根据文件名,在当前目录下找到inode,根据文件的inode在特定的block中找到对应的属性,根据属性找到data block,然后将其中的数据刷新到内存中,然后通过内存刷新到显示器中;
inode是固定的,data block是固定的就容易出现一个问题,当看到还有内存空间但是创建不了新的文件,可能是因为没有inode了,或者data block没有空间了;





软硬连接
ls -li
可以将文件的inode显示出来;
ln -s testLink.txt soft.link
此时就建立了一个软连接
ln testLink.txt hard.Link
此时就建立了一个硬连接;
现象:软连接有自己的inode,硬连接的inode与被连接的文件inode相同,软连接被链接的文件前边数字是1,硬连接被链接的文件前边的数字是2;
软硬连接的区别就是有没有独立的inode,
软连接有独立的inode,意味着软连接是一个独立的文件,而硬连接不是一个独立的文件;
软连接
特性:有独立的inode,可以理解为软连接的文件内容指向的是文件的对应的路径;
应用:如同windows下的快捷方式;
硬连接
特性
创建硬连接不是真正的创建新文件;用的别人的内容和别人的属性;
创建硬连接就是在指定的目录下建立了文件名,和指定的inode的映射关系;
属性中有一个数字从1建立硬连接后变为2,删除被硬连接的文件变为1;
这个数字叫做硬链接数;
inode怎么知道有多少个文件与自己是关联的,,inode内部有一个引用计数(int count),当删除文件的时候并不是把这个文件的inode删除了,而是将引用计数--;当引用计数为0的时候,这个文件才真正的删除;
应用
默认创建目录是引用计数是2,是由于自己的目录名映射到inode;并且自己目录内.文件与其inode映射所以是两次;在此目录下再创建一个目录就变为3,由于新创建的目录中有..文件上一级路径;就可以不进入目录估算出目录中有几个目录;



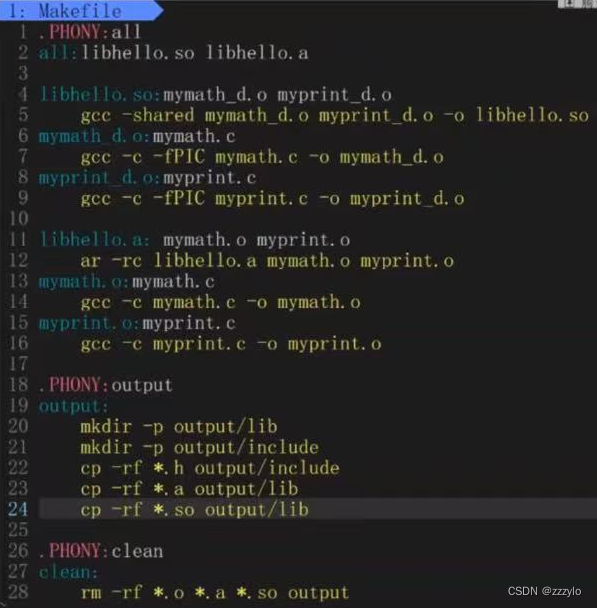
动态库和静态库
1、怎么写库?
库里面不能有main函数
mymath.c
#include "mymath.h"int addToTarget(int from, int to) {int sum = 0;for (int i = from; i <= to; i++){sum += i;}return sum; }mymath.h
#pragma once#include <stdio.h>extern int addToTarget(int from, int to);myprint.c
#include "myprint.h"void Print(const char *str) {printf("%s[%d]\n", str, (int)time(NULL)); }myprint.h
#pragma once#include <stdio.h> #include <time.h>extern void Print(const char *str);静态库 .a
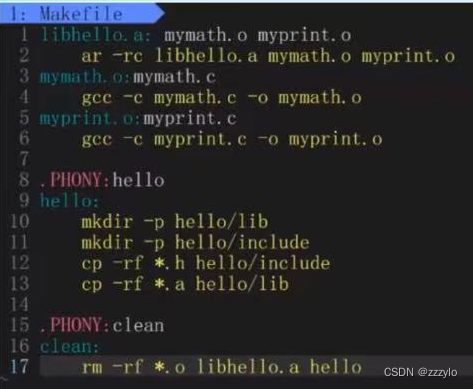
首先将上边两个.c文件编译为.o文件,使用命令
ar -rc lib.a mymath.o myprint.o
即可完成静态库的制作;
ar是gnu归档工具,rc表示replace和create;
库的发布一般是一个文件lib中是各种库文件,include中是对应的头文件;
makfile文件
动态库 .os
gcc -fPIC -c mymath.c -o mymath.o
gcc -fPIC -c myprint.c -o myprint.o
生成两个与位置无关的二进制文件;
这个库形成了,它在内存里的任意位置都可以加载;
使用命令gcc -shared mymath.o myprint.o -o libhello.so
于是就得到一个libhello.so动态库;
执行命令make 生成.o文件后执行make output 生成动态库和静态库;
2、库是怎么使用的?
静态库
方法一
hello库
头文件gcc的默认搜索路径是/usr/include;
库文件的默认搜索路径是:/lib64或者/usr;
接下来将hello/include 拷贝到头文件的默认搜索路径/usr/include中,再将hello/lib拷贝到库文件的默认搜索路径/lib64中;
此时直接编译会报错,因为自己所写的库是第三方库,需要使用命令gcc main.c -lhello;
需要告诉gcc要连接的库是哪一个;(不建议使用这种方式使用自己写的库)
方法二
动态库
在上面动态库生成中生成的两个库文件在同一个文件夹下的时候上面静态库的方法二默认使用的是动态库 ;
如果只有静态库,那么gcc只能针对该库进行静态链接;
如果动静态库同时存在,默认使用的就是动态库;
但是存在一个问题
在成功编译后运行文件会报错;
但是如果动静态库同时存在,当时非要使用静态库呢?
在方法二后边加 -static,作用是摒弃默认优先使用动态库的原则,直接使用静态库的方案;
注:命令 ldd a.out 查看a.out文件的连接库是哪个;
静态库与可执行文件是一体的,而动态库是一个独立的文件;
地址空间中有一段代码区,在使用静态库编译后,可执行文件和静态库都通过页表的映射加载到代码区中;堆区与栈区有一批共享区,当使用动态链接时,先把可执行程序加载进内存,代码中会包含一些关于库的符号链接,当执行可执行程序时遇到了与动态库有关的代码时,才会将动态库加载进内存,然后通过页表映射到共享区;程序运行时会从代码区跳到共享区在跳回去;
当把库加载到内存中时如果有其他的进程也想使用这个库就通过自己的页表将其映射到自己的共享区,动态库也就是共享库;
上边的报错原因是因为只在gcc编译器中输入了动态库的路径,但是加载器并不知道动态库在什么位置;
方法一、向环境变量中加入库路径
LD_LIBRARY_PATH:加载库路径;
使用命令 export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:动态库所在的的路径;
方法二、修改配置文件
sudo touch /etc/ld.so.conf.d/xxx.conf
sudo vim xxx.conf
将库所在的路径拷贝到此conf文件中即可;
方法三
在lib64下建立软链接
为什么要有库
站在使用者角度,库的存在可以大大减少开发周期,提高软件本身的质量;
站在写库的人的角度,使用简单,并且代码安全;
ncurses 字符的界面库;
boost 准标准库;



相关文章:

【Linux】七、基础IO
预备知识 文件 属性(本质上也是数据)内容; 文件的所有操作大致有两种,对内容的操作,和对属性的操作; 文件在磁盘中放置,磁盘是硬件,只有操作系统可以真正的访问磁盘;C\C…...

Elasticsearch语法之Term query不区分大小写
设置关键词是否区分大小写 说明:case_insensitive是term的可选参数,默认为false,表示关键词区分大小写,设置为true表示关键词不区分大小写。该参数在7.10.0开始有效 需求:分别使用关键词"iphone"和"I…...

远程管理SSH服务
一、搭建SSH服务 1、关闭防火墙与SELinux # 关闭firewalld防火墙 # 临时关闭 systemctl stop firewalld # 关闭开机自启动 systemctl disable firewalld # 关闭selinux # 临时关闭 setenforce 0 # 修改配置文件 永久关闭 vim /etc/selinux/config SELINUXdisabled 2、配置…...
Linux 实现原理 — NUMA 多核架构中的多线程调度开销与性能优化
前言 NOTE:本文中所指 “线程” 均为可执行调度单元 Kernel Thread。 NUMA 体系结构 NUMA(Non-Uniform Memory Access,非一致性存储器访问)的设计理念是将 CPU 和 Main Memory 进行分区自治(Local NUMA node&#x…...

Oracle锁处理
背景: 随着数据库版本不断迭代更新, v$session 视图的内容越来越丰富,可以直接使用blocking_session、blocking_instance、final_blocking_instance和final_blocking_session字段进行定位。对于锁层次的排查可以重复查询v$session来确定&am…...
持续集成交付CICD:安装Jenkins Slave(从节点)
目录 一、实验 1.安装Jenkins Slave(从节点) 二、问题 1.salve节点启动jenkins报错 2.终止命令行后jenkins从节点状态不在线 一、实验 1.安装Jenkins Slave(从节点) (1)查看jenkins版本 Version 2.…...

Dart(一):Dart入门
Dart入门 Dart安装创建项目安装依赖(以http为例)依赖库查询地址添加依赖编写运行示例 dart常用命令引用核心库、自定义库、第三方库数据类型Numbers (int, double)Strings (String)Booleans (bool)Lists (List)Maps (Map)Sets (Set)Null (null)Records (…...
[动态规划] (十一) 简单多状态 LeetCode 面试题17.16.按摩师 和 198.打家劫舍
[动态规划] (十一) 简单多状态: LeetCode 面试题17.16.按摩师 和 198.打家劫舍 文章目录 [动态规划] (十一) 简单多状态: LeetCode 面试题17.16.按摩师 和 198.打家劫舍题目分析题目解析状态表示状态转移方程初始化和填表顺序 代码实现按摩师打家劫舍 总结 注:本题与…...

【EI会议投稿】第三届计算机、人工智能与控制工程国际学术会议 (CAICE 2024)
The 3rd International Conference on Computer, Artificial Intelligence and Control Engineering (CAICE 2024) 第三届计算机、人工智能与控制工程国际学术会议 第三届计算机、人工智能与控制工程国际学术会议(CAICE 2024)将于2024年1月26-28日在西…...

python 之 列表推导式
文章目录 基本结构示例 1:将列表中的元素乘以 2 添加条件判断示例 2:筛选出偶数并加倍 嵌套列表推导式示例 3:生成九九乘法表 使用条件表达式示例 4:根据条件返回不同的值 镶嵌使用详细介绍基本结构示例生成二维数组多重筛选和操作…...

【左程云算法全讲2】链表、栈、队列、递归、哈希表和有序表
系列综述: 💞目的:本系列是个人整理为了秋招面试的,整理期间苛求每个知识点,平衡理解简易度与深入程度。 🥰来源:材料主要源于左程云算法课程进行的,每个知识点的修正和深入主要参考…...
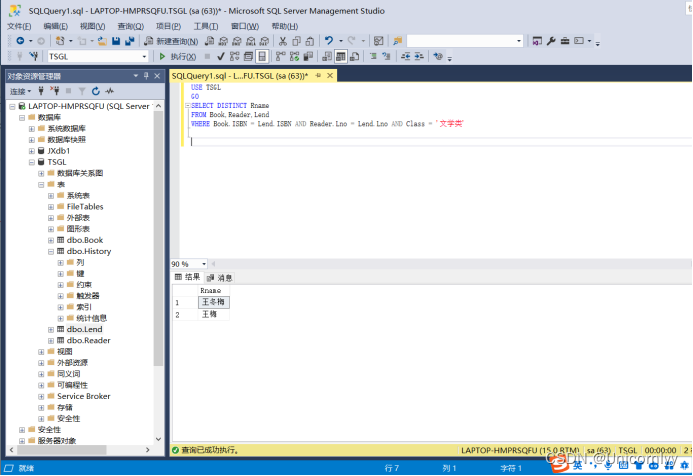
SQL第三次上机作业
1.查询与王利就读同一专业学生的借书证号和姓名 SELECT Lno,Rname FROM Reader WHERE Dept(SELECT DeptFROM ReaderWHERE Rname王利)2.查询比希望出版社出版的所有图书价格都高的图书信息 SELECT * FROM Book WHERE Price>(SELECT MAX(Price)FROM BookWHERE Press希望出版…...

前端事件案例补充
目录 定时器示例 搜索框示例 省市联动 定时器示例 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>Title</title><meta name"viewport" content"widthdevice-width, init…...
)
3.8 Android eBPF HelloWorld调试(二)
写在前面 我们开发eBPF程序的初衷就是再不改动内核的情况下,将内核监控数据传递给到用户态;像应用进程开发一样开发内核监控程序。 Android开机的时候eBPF程序被加载器加载到内核中,但此时它并没有被附加到内核函数上去,也就是ebpf程序并不会执行,我们可以理解为,它仅仅被…...

xss如何快速提取cookies
<script>alert(111)</script> <img srcx onerroralert(document.cookie)>测试一下baidu的xss <script>alert(111)</script><img srcx οnerrοralert(document.cookie)>...

在 ASP.NET C# 中用Aspose.PDF将 PDF 页面转换为 JPG 图像
PDF 是一种通用格式,通常用于打印和共享文档。 (一)C# PDF to JPG Converter API - 免费下载 Aspose.PDF for .NET是一个强大的 PDF 操作 API,可让您在 .NET 应用程序中创建和处理 PDF 文件。此外,它还允许您将 PDF 文…...

Docker Compose安装milvus向量数据库单机版-milvus基本操作
目录 安装Ubuntu 22.04 LTS在power shell启动milvus容器安装docker desktop下载yaml文件启动milvus容器Milvus管理软件Attu python连接milvus配置下载wget示例导入必要的模块和类与Milvus数据库建立连接创建名为"hello_milvus"的Milvus数据表插入数据创建索引基于向量…...
极致性能优化:前端SSR渲染利器Qwik.js | 京东云技术团队
引言 前端性能已成为网站和应用成功的关键要素之一。用户期望快速加载的页面和流畅的交互,而前端框架的选择对于实现这些目标至关重要。然而,传统的前端框架在某些情况下可能面临性能挑战且存在技术壁垒。 在这个充满挑战的背景下,我们引入…...
)
ES6~ES13新特性(二)
文章目录 一、ES71.Array Includes2.指数exponentiation运算符 二、ES81.Object values2.Object entries3.String Padding4.Trailing Commas5.Object Descriptors 三、ES9四、ES101.flat flatMap2.Object fromEntries3.trimStart、trimEnd4.其他知识点 五、ES111.BigInt2.Nulli…...
soildwork2022怎么样添加螺纹孔?
1.退出草图模式,点击需要添加螺纹孔的物体面,选中“特征”中的“异形孔向导” 2.选中“孔类型”为“直螺纹孔”,“标准”,“类型”,“孔规格”终止条件等。 3.设置完之后选择“位置” 4.鼠标左键在物体面上点一下&…...

小说下载器终极指南:一站式解决100+网站小说保存难题
小说下载器终极指南:一站式解决100网站小说保存难题 【免费下载链接】novel-downloader 一个可扩展的通用型小说下载器。 项目地址: https://gitcode.com/gh_mirrors/no/novel-downloader 在数字阅读时代,你是否曾因小说突然下架、网站404或网络中…...

ESP32多任务水位监测:从Arduino到ESP-IDF的FreeRTOS实战
1. 项目概述:从Arduino到ESP-IDF的跃迁去年我在做毕业设计时,为了搭建一个ESP32的传感器节点演示程序,第一次深入使用了FreeRTOS。那段时间,我几乎天天和任务调度、队列、信号量打交道,从最初的一头雾水到后来能流畅地…...

MongoDB Limit 与 Skip 方法详解
MongoDB Limit 与 Skip 方法详解 引言 MongoDB 是一个高性能、可伸缩的文档存储系统,它提供了强大的数据存储和查询功能。在处理大量数据时,Limit 与 Skip 方法是 MongoDB 中常用的查询优化工具。本文将详细介绍 MongoDB 中的 Limit 与 Skip 方法,包括其基本用法、性能影响…...

当 AI Coding 进入复杂企业系统,为什么提效远没有宣传里那么美好 ?
以 Claude Code、Codex 为代表的自主编码智能体(Coding Agents),正在以惊人的速度席卷软件开发者生态。与此同时,类似“10 倍开发效率”“普通人也能随手构建软件”“程序员即将失业”的说法,也随处可见。这种不分场景…...

如何快速掌握MoveIt2:面向ROS 2开发者的工业机器人运动规划完整指南
如何快速掌握MoveIt2:面向ROS 2开发者的工业机器人运动规划完整指南 【免费下载链接】moveit2 :robot: MoveIt for ROS 2 项目地址: https://gitcode.com/gh_mirrors/mo/moveit2 想要为你的机器人实现智能运动规划吗?MoveIt2作为ROS 2生态中最强大…...

基于USB ACA模式实现安卓手机边玩边充的游戏手柄设计
1. 项目缘起:当手机性能过剩,却败给了触摸屏几年前,我清理手机游戏时,发现一个挺无奈的现象:性能足以媲美掌机的智能手机里,只剩下一些慢节奏的平台解谜或者数独。那些曾经让我在掌机上废寝忘食的赛车、动作…...

高精度光照检测
光线检测仪,kotlin开发,调用手机感光模块检测室内外光照强度,用途多多,我主要用途孩子写作业检测光照保护视力。 食用方法∶打开即测,速度快,无广告,手机平视即可,无须直视光线。 买…...

3分钟告别英文恐惧:Android Studio中文界面轻松切换指南
3分钟告别英文恐惧:Android Studio中文界面轻松切换指南 【免费下载链接】AndroidStudioChineseLanguagePack AndroidStudio中文插件(官方修改版本) 项目地址: https://gitcode.com/gh_mirrors/an/AndroidStudioChineseLanguagePack 你是否曾经因…...

终极指南:用D2DX让《暗黑破坏神2》在现代电脑上焕发新生
终极指南:用D2DX让《暗黑破坏神2》在现代电脑上焕发新生 【免费下载链接】d2dx D2DX is a complete solution to make Diablo II run well on modern PCs, with high fps and better resolutions. 项目地址: https://gitcode.com/gh_mirrors/d2/d2dx 还在为经…...

超低功耗电池电压监控电路设计:从LM324到LPV324的硬件方案优化
1. 项目概述与核心需求解析在捣鼓各种电池供电的电子设备时,无论是自己做的无线传感器节点、便携式小工具,还是给孩子改装的玩具,有一个问题总是绕不开:你怎么知道电池快没电了?总不能每次都等到设备彻底罢工ÿ…...