详解交叉验证中【KFold】【Stratified-KFold】【StratifiedShuffleSplit】的区别
交叉验证是一种统计分析方法,它的目的是通过在同一数据集上重复并分割训练和测试数据,来评估机器学习模型的性能。以下是这三种交叉验证方法的区别:
-
KFold(K-折叠)
- 在KFold交叉验证中,原始数据集被分为K个子集。
- 每次,其中的一个子集被用作测试集,而其余的K-1个子集合并后被用作训练集。
- 这个过程重复进行K次,每次选择不同的子集作为测试集。
- KFold不保证每个折叠的类分布与完整数据集中的分布相同。
-
Stratified-KFold(分层K-折叠)
- Stratified-KFold是KFold的变体,它会返回分层的折叠:每个折叠中的标签分布都尽可能地与完整数据集中的标签分布相匹配。
- 这种方法特别适用于类分布不均衡的情况,确保每个折叠都有代表性的类比例。
- 就像KFold一样,每个折叠轮流被用作测试集,其他折叠用作训练集。
-
StratifiedShuffleSplit(分层随机分割)
- StratifiedShuffleSplit是另一种分层抽样技术,它也确保了每次分割中都能维持原始数据集中各个类的比例。
- 与Stratified-KFold不同,StratifiedShuffleSplit将数据集随机打乱,然后切分为训练集和测试集。这个过程会根据需要重复多次。
- 这种方法提供了更多的随机性,并可以通过指定测试集的大小来控制训练集和测试集的比例。
接下来我们用代码来解释他们的区别:
一. Kfold
先来创建数据集:
splits = 5
tx = range(10)
ty = [0] * 5 + [1] * 5再来导入相应的模块:
from sklearn.model_selection import KFold
from sklearn.model_selection import StratifiedKFold
from sklearn.model_selection import StratifiedShuffleSplit,
from sklearn import datasets先实例化一个KFold,shuffle = Flase的情况:
Kfold = KFold (n_splits=splits, shuffle=False)再来看看Kfold是如何来做交叉验证的:
print("Fold")
for train_index, test_index in Kfold.split(tx, ty):print("TRAIN:", train_index, "TEST:", test_index)输出结果为:

可以看到,Kfold的测试集是按照顺序不重复的每次取出两个,一共做5次训练。
当shuffle = true时再来运行一次代码:
Kfold = KFold (n_splits=splits, shuffle=False)print("Fold")
for train_index, test_index in Kfold.split(tx, ty):print("TRAIN:", train_index, "TEST:", test_index)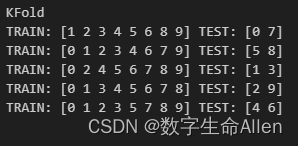
可以看到Kfold的测试集是无规则不重复的每次取出两个,一共做5次训练。
二. Stratified-KFold
我们用相同的数据集,先来看看shuffle = False的情况:
stratKfold = StratifiedKFold(n_splits=splits, shuffle=False)
print("stratKFold")
for train_index, test_index in stratKfold.split(tx, ty):print("TRAIN:", train_index, "TEST:", test_index)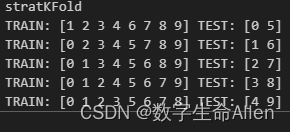
可以看到测试集被分层了。因为我们是二分类数据,所以每次都是从0类中抽一个,1类中抽一个,而且是按顺序抽取,即从0类的第一个数据,1类的第一个数据组合形成一个测试集。数据是不重复的。
先来看看shuffle = true的情况:

可以看到测试集依然被分层抽取,但不是按照顺序抽取,且依旧保证数据是不重复的。
三. StratifiedShuffleSplit
先来实例化一个StratifiedShuffleSplit并分隔数据集:
shufflesplit = StratifiedShuffleSplit(n_splits=splits, random_state=42, test_size=2)
for train_index, test_index in shufflesplit.split(tx, ty):print("TRAIN:", train_index, "TEST:", test_index)
可以看到测试集被分层了,同时我们可以根据test_size选择测试集的比例,并且数据是可以重复的,可以看到测试集3出现了2次。但我们把test_size设置为0.3时:

可以看到测试集有3个样本,多个数据发生了重复。
总结一下:Kfold交叉验证不考虑样本标签是否均衡的问题,仅是单纯的将样本分为K份,1份是测试,k-1份做训练;Stratified-KFold会根据样本标签分类,让训练集和测试集都保持原有样本的标签分类情况,shuffle = False or true决定的是分隔是顺序分隔还是随机分隔,同时数据是不可重复利用的;StratifiedShuffleSplit可以对数据进行重复利用,也只有StratifiedShuffleSplit可以控制测试集和训练集的比例。
相关文章:
详解交叉验证中【KFold】【Stratified-KFold】【StratifiedShuffleSplit】的区别
交叉验证是一种统计分析方法,它的目的是通过在同一数据集上重复并分割训练和测试数据,来评估机器学习模型的性能。以下是这三种交叉验证方法的区别: KFold(K-折叠) 在KFold交叉验证中,原始数据集被分为K个…...

数学建模比赛中常用的建模提示词(数模prompt)
以下为数学建模比赛中常用的建模提示词,希望对你有所帮助! 帮我总结一下数学建模有哪些预测类算法? 灰色预测模型级比检验是什么意思? 描述一下BP神经网络算法的建模步骤 对于分类变量与分类变量相关性分析用什么算法 前10年的数据分别是1&a…...

Spark 新特性+核心回顾
Spark 新特性核心 本文来自 B站 黑马程序员 - Spark教程 :原地址 1. 掌握Spark的Shuffle流程 1.1 Spark Shuffle Map和Reduce 在Shuffle过程中,提供数据的称之为Map端(Shuffle Write)接收数据的称之为Reduce端(Sh…...
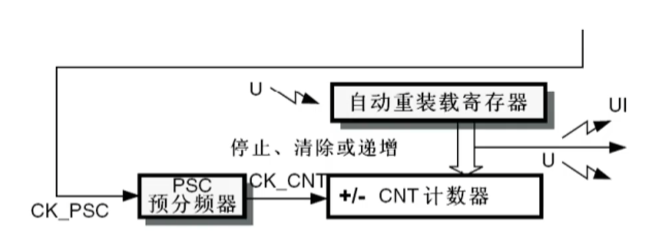
STM32 TIM定时器,配置,详解(1)
计数器寄存器(TIMx_CNT)、预分频器寄存器(TIMx_PSC)、自动重载寄存器(TIMx_ARR)。 PSC预分频器,顾名思义,先预备一下分频,有时候频率过高,后面的定时器承受不住,就先用PSC先分频一下。如何分频的?将每接受到…...

Helix Toolkit:为.NET开发者带来的3D视觉盛宴
推荐一个基于.Net开源的3、功能强大的3D图形库和工具包,适用于WPF应用程序的3D渲染和开发。 01 项目简介 Helix Toolkit是一个开源的3D库,主要用于WPF应用程序。它有许多优点,例如提供各种各样的功能,包括基于MVVM的3D模型编辑器…...
PHP分类信息网站源码系统 电脑+手机+微信端三合一 带完整前后端部署教程
大家好啊!今天源码小编来给大家分享一款PHP分类信息网站类源码系统。这款源码系统是一套专业的信息发布类网站综合管理系统,适合各类地方信息和行业分类站点建站。随着这几年我们国家网民爆炸式的增 长,网络信息也随之越来越庞大,…...
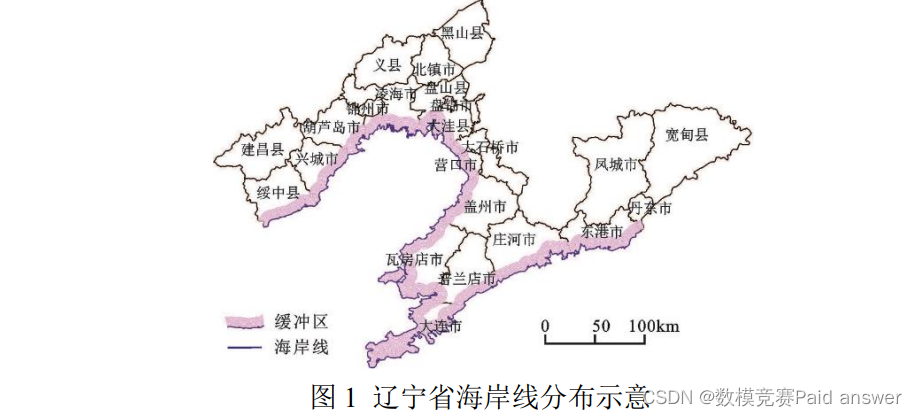
2023年辽宁省数学建模竞赛B题数据驱动的水下导航适配区分类预测
2023年辽宁省数学建模竞赛 B题 数据驱动的水下导航适配区分类预测 原题再现: “海洋强国”战略部署已成为推动中国现代化建设的重要组成部分,国家对此提出“发展海洋经济,保护海洋生态环境,加快建设海洋强国”的明确要求。 …...

完蛋!百融云被大阳线包围了!
没想到让AI指数爬出底部的,不是离婚的两口子承诺不减持了,而是国产游戏圈神作《完蛋!我被女友包围了》。确实,资本市场不相信眼泪,AI的涨跌也与爱情无关。 之前有一个来自美国和澳大利亚的大数据团队做过一个有趣的统…...

数据结构 编程1年新手视角的平衡二叉树AVL从C与C++实现③
对应地,我们可以将insert函数中省略的操作补上 if(getBalance(node)2){ if(getBalance(node->left)1){ noderightRotate(node); //对应LL型 } else if(getBalance(node->left)-1{ node->left leftRotate(node->left); //对应LR型 noderightRotate(n…...
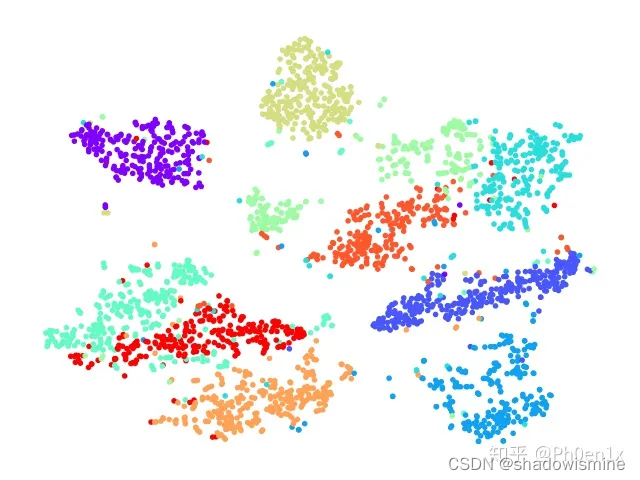
数据可视化PCA与t-SNE
PCA(主成分分析)和t-SNE(t分布随机近邻嵌入)都是降维技术,可以用于数据的可视化和特征提取。 降维:把数据或特征的维数降低,其基本作用包括: 提高样本密度,以及使基于欧…...

Kubernetes rancher、prometheus、ELK的安装
目录 一、rancher的安装1. 添加 Helm Chart 仓库2. 为 Rancher 创建命名空间3. 选择 SSL 配置4. 安装 cert-manager 二、prometheus安装三、EFK安装3.1安装elasticsearch3.2安装filebeat3.3安装kibana 一、rancher的安装 有关rancher的安装其实官方网站给的步骤已经很详细了&a…...
为什么我们要努力的学习编程?初学编程从哪里开始学起?
为什么我们要努力的学习编程?初学编程从哪里开始学起? 1、不论在哪里上班,都不是铁饭碗:现在全球经济低迷,使得很多企业倒闭,大到知名国企小到私营企业,大量裁员。任何人都无法保证自己现在的工…...
)
ffmpeg 从内存中读取数据(或将数据输出到内存)
1.为了使本文更通俗易懂,更新了部分内容,将例子改为从内存中打开。 2.增加了将数据输出到内存的方法。 从内存中读取数据 ffmpeg一般情况下支持打开一个本地文件,例如“C:\test.avi” 或者是一个流媒体协议的URL,例如“rtmp:/…...
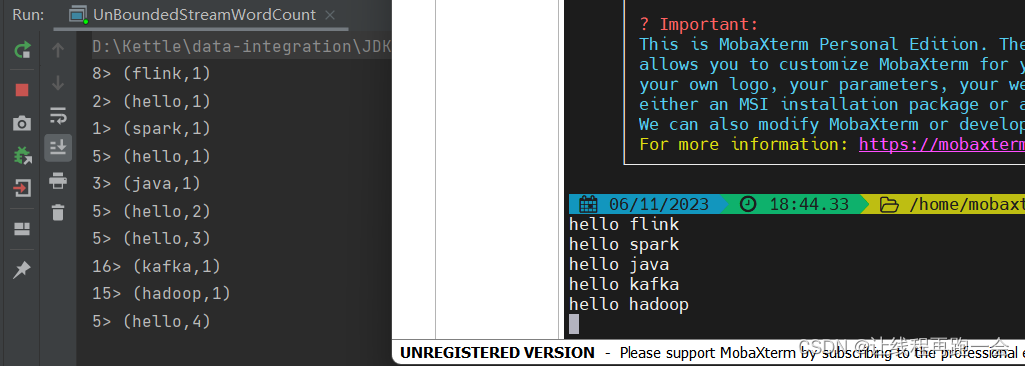
Flink(一)【WordCount 快速入门】
前言 学完了 Hadoop、Spark,本想着先把 Kafka、Flume 这些工具先学完的,但想了想还是把核心的技术先学完最后再去把那些工具学学。 最近心有点累哈哈哈,偷偷立个 flag,反正也没人看,明年的今天来这里还愿哈,…...

【Redis】hash数据类型-常用命令
文章目录 前置知识常用命令HSETHGETHEXISTSHDELHKEYSHVALSHGETALLHMGET关于HMSETHLENHSETNXHINCRBYHINCRBYFLOAT 命令小结 前置知识 redis自身就是键值对结构了,哈希类型是指值本⾝⼜是⼀个键值对结构,形如key"key",value{{field1…...

【大数据】Apache NiFi 数据同步流程实践
Apache NiFi 数据同步流程实践 1.环境2.Apache NIFI 部署2.1 获取安装包2.2 部署 Apache NIFI 3.NIFI 在手,跟我走!3.1 准备表结构和数据3.2 新建一个 Process Group3.3 新建一个 GenerateTableFetch 组件3.4 配置 GenerateTableFetch 组件3.5 配置 DBCP…...
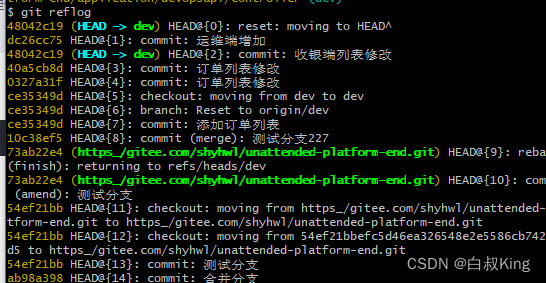
git怎么使用 拉取代码
废话不多说 直接开干 Git 是一款十分实用的版本控制工具,非常方便地管理代码的变更。但是,在使用 Git 过程中,不可避免地会遇到一些问题。其中,删除分支是一个常见的问题。 查看引用历史记录: git reflog找到你删除的…...

Apple :苹果将在明年年底推出自己的 AI,预计将随 iOS 18 一起推出
本心、输入输出、结果 文章目录 Apple :苹果将在明年年底推出自己的 AI,预计将随 iOS 18 一起推出前言三星声称库克相关图片弘扬爱国精神 Apple :苹果将在明年年底推出自己的 AI,预计将随 iOS 18 一起推出 编辑:简简单…...
数据结构-双向链表
1.带头双向循环链表: 前面我们已经知道了链表的结构有8种,我们主要学习下面两种: 前面我们已经学习了无头单向非循环链表,今天我们来学习带头双向循环链表: 带头双向循环链表:结构最复杂,一般用…...
CV计算机视觉每日开源代码Paper with code速览-2023.11.6
精华置顶 墙裂推荐!小白如何1个月系统学习CV核心知识:链接 点击CV计算机视觉,关注更多CV干货 论文已打包,点击进入—>下载界面 点击加入—>CV计算机视觉交流群 1.【点云3D目标检测】(NeurIPS2023)…...

3个突破壁垒方法:网盘直链下载助手如何让文件获取效率提升5倍
3个突破壁垒方法:网盘直链下载助手如何让文件获取效率提升5倍 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘…...

新手友好!Qwen3-ASR-1.7B镜像使用全攻略:从安装到实战
新手友好!Qwen3-ASR-1.7B镜像使用全攻略:从安装到实战 1. 为什么选择Qwen3-ASR-1.7B? 语音识别技术正在改变我们处理音频内容的方式。Qwen3-ASR-1.7B作为阿里云通义千问团队开发的开源语音识别模型,在识别精度和语言支持方面表现…...

ZeroOmega:下一代浏览器代理管理的架构革命
ZeroOmega:下一代浏览器代理管理的架构革命 【免费下载链接】ZeroOmega Manage and switch between multiple proxies quickly & easily. 项目地址: https://gitcode.com/gh_mirrors/ze/ZeroOmega 在当今复杂的网络环境中,代理管理已成为开发…...

GitLab Runner配置总出错?手把手教你调试config.toml文件
GitLab Runner配置总出错?手把手教你调试config.toml文件 当你第一次打开GitLab Runner的config.toml文件时,可能会被里面密密麻麻的参数搞得一头雾水。这个看似简单的配置文件,实际上藏着许多让中高级用户都容易踩坑的细节。今天我们就来彻底…...

Android购物商城APP实战:从零到一构建核心功能模块
1. 项目功能模块拆解与实现路径 一个完整的购物商城APP通常包含四大核心模块:用户系统、商品展示、购物车管理和订单处理。这就像搭建一个实体商店,需要先规划好门面(登录注册)、货架(商品展示)、购物篮&am…...

告别“AI只会聊天”:用OpenClaw+星链4SAPI打造你的办公自动化Agent
你有没有过这种时刻——邮箱右上角的红点像一道催命符,文件夹乱得像个数据坟场,日程表排得跟俄罗斯方块似的,领导一句“把本周情况汇总下”,你就得在聊天记录里搞考古发掘。打开AI,发现它除了陪你聊天,什么…...

花小钱办大事!微调Nova Lite,实现Pro级视觉检测效果
本文介绍了在Amazon Bedrock上对Amazon Nova Lite 1.0进行微调的两个实际应用案例,展示了在专业计算机视觉任务中,如何在保持成本效益的同时显著提升性能。通过对航拍视角检测和低光照监控场景的系统性评估,本例以最小的训练成本实现了增强的…...

AUnit:面向Arduino的轻量级嵌入式单元测试框架
1. AUnit:面向嵌入式Arduino平台的轻量级单元测试框架1.1 设计动因与核心定位AUnit并非凭空诞生的全新框架,而是针对ArduinoUnit 2.2在实际工程中暴露出的三大痛点所进行的深度重构与优化。作为一名长期在资源受限的8位AVR平台(如Arduino UNO…...

NovelAI:从文本生成到内容创作的AIGC实践
1. NovelAI:你的AI创作助手 第一次接触NovelAI时,我正被一篇商业方案折磨得焦头烂额。凌晨三点的咖啡杯旁,这个基于GPT模型的AI工具在15分钟内就帮我完成了初稿框架,那一刻我就知道,内容创作的方式正在被重新定义。Nov…...

OpenClaw自动化流水线:Phi-3-vision处理图片转Excel报表
OpenClaw自动化流水线:Phi-3-vision处理图片转Excel报表 1. 为什么需要自动化报表生成 上周我收到财务同事发来的20张手机拍摄的销售数据表照片,要求整理成统一格式的Excel报表。手动录入数据花了整整3小时,期间还因为看错数字返工两次。这…...