2023年辽宁省数学建模竞赛B题数据驱动的水下导航适配区分类预测
2023年辽宁省数学建模竞赛
B题 数据驱动的水下导航适配区分类预测
原题再现:
“海洋强国”战略部署已成为推动中国现代化建设的重要组成部分,国家对此提出“发展海洋经济,保护海洋生态环境,加快建设海洋强国”的明确要求。
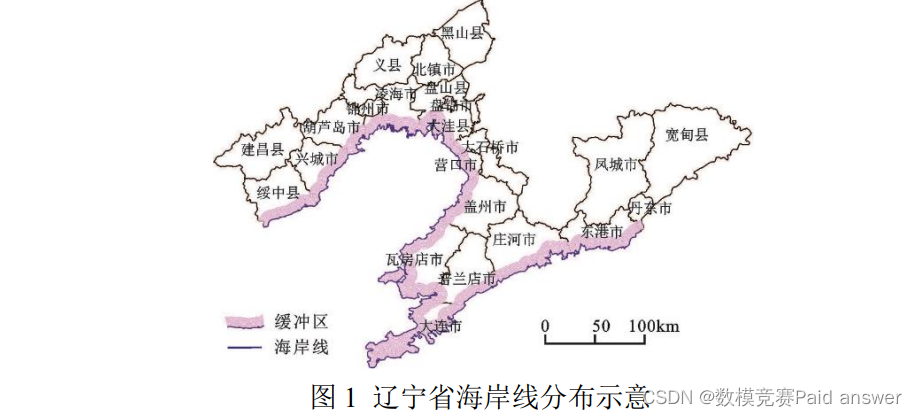
《辽宁省“十四五”海洋经济发展规划》明确未来全省海洋经济的发展战略、发展目标、重大任务、空间部署和保障措施。规划范围包括辽宁省全部海域和大连、丹东、锦州、营口、盘锦和葫芦岛 6 个市以及海洋经济发展所依托的相关陆域,规划期限为 2021 年至 2025 年,展望到 2035 年。辽宁省作为中国最北沿海省份,拥有 2292.4 公里海岸线(如图 1 所示)。
在“海洋强省”建设目标的背景下,完成海洋经济发展规划的目标重在海洋高新技术领域创新。其中关键核心技术之一是攻克水下导航与定位的适配区分类预测技术。
水下航行器在执行水下任务时需要保持自主、无源、高隐蔽性、不受地域和时域限制、高精度的导航与定位。重力辅助导航是满足上述条件的主要方法之一。
在重力辅助导航系统中,影响导航可靠性与精度的关键步骤是选择匹配性高的航行区域,即适配区。适配区的标定与识别技术是最具挑战性的问题之一。选取适配区前需要对研究海域的重力基准图(基础性的是重力异常基准图)进行插值加密处理,基于重力基准图所提供水下航行器航行区域的重力异常变化情况对适配区的选取进行分析。
重力异常(值)的定义为:实际地球内部的物质密度分布不均匀,导致实际观测重力值与理论上的正常重力值总存在偏差,在排除各种干扰因素影响后,仅仅由地球物质密度分布不匀所引起的重力的变化,简称为重力异常。
在重力异常变化显著区域,导航系统可获得高的定位精度;反之,在重力异常变化平坦区域,导航系统会出现定位精度的不敏感。由于不同区域的重力异常特征分布不同,建立可行的适配区分类预测模型,对保障水下航行器的导航精度至关重要。
假设X为影响区域匹配性的特征属性指标,Y为刻画区域适配性的输出结果, F为以X为输入以Y为输出的分类预测系统。
基于上述背景分析,请参考附件中的重力异常数据建立数学模型,解决以下问题:
问题一:附件 1,给出一组分辨率为 1’×1’(相邻两格网点间的距离是 1’)的重力异常基准数据 A,试通过精细化基准图,合理划分区域,完成各区域的适配性标定(标签Y)。
问题二:根据问题一中各划分区域的适配性标定结果Y ,合理选择区域的特征属性指标(特征X),试建立有效的区域适配区分类预测模型(系统F)。
问题三:利用附件二中的重力异常基准数据 B,试对问题二所建立的系统F进行迁移性预测并讨论该系统F对新重力异常数据的适用性。
附件
附件 1:重力异常基准数据 A
附件 2:重力异常基准数据 B
代码实例
from sklearn import datasets
#朴素贝叶斯from sklearn.naive_bayes import GaussianNB
from sklearn.naive_bayes import MultinomialNB
from sklearn.naive_bayes import BernoulliNB
#SVM
from sklearn.svm import SVC
#KNN
from sklearn.neighbors import KNeighborsClassifier
#数据集分割
from sklearn.model_selection import train_test_splitcancers=datasets.load_breast_cancer()
X=cancers.data
Y=cancers.target
# 注意返回值: 训练集train,x_train,y_train,测试集test,x_test,y_test
# x_train为训练集的特征值,y_train为训练集的目标值,x_test为测试集的特征值,y_test为测试集的目标值
# 注意,接收参数的顺序固定
# 训练集占80%,测试集占20%
#此处是将数据集拆分为训练集和测试集
x_train,x_test,y_train,y_test=train_test_split(X, Y, test_size=0.2)
#朴素贝叶斯
#高斯贝叶斯分类器
model_linear =GaussianNB()
model_linear.fit(x_train, y_train)
train_score = model_linear.score(x_train, y_train)
test_score = model_linear.score(x_test, y_test)
print('高斯贝叶斯训练集的准确率:%.3f; 测试集的准确率:%.3f'%(train_score, test_score))
preresult=model_linear.predict(x_test)
print(preresult)
#多项式贝叶斯分类器
model_linear =MultinomialNB()
model_linear.fit(x_train, y_train)
train_score = model_linear.score(x_train, y_train)
test_score = model_linear.score(x_test, y_test)
print('多项式贝叶斯训练集的准确率:%.3f; 测试集的准确率:%.3f'%(train_score, test_score))
preresult=model_linear.predict(x_test)
print(preresult)
#伯努利贝叶斯分类器
model_linear=BernoulliNB()
model_linear.fit(x_train, y_train)
train_score = model_linear.score(x_train, y_train)
test_score = model_linear.score(x_test, y_test)
print('伯努利贝叶斯训练集的准确率:%.3f; 测试集的准确率:%.3f'%(train_score, test_score))
preresult=model_linear.predict(x_test)
print(preresult)
#SVM法model_linear = SVC(C=1.0, kernel='linear') # 线性核
model_linear.fit(x_train, y_train)
train_score = model_linear.score(x_train, y_train)
test_score = model_linear.score(x_test, y_test)
print('SVM法训练集的准确率:%.3f; 测试集的准确率:%.3f'%(train_score, test_score))
preresult=model_linear.predict(x_test)
print(preresult)
#KNN法
model_linear =KNeighborsClassifier(n_neighbors=15)
model_linear.fit(x_train, y_train)
train_score = model_linear.score(x_train, y_train)
test_score = model_linear.score(x_test, y_test)
print('KNN法训练集的准确率:%.3f; 测试集的准确率:%.3f'%(train_score, test_score))
preresult=model_linear.predict(x_test)
print(preresult)
相关文章:
2023年辽宁省数学建模竞赛B题数据驱动的水下导航适配区分类预测
2023年辽宁省数学建模竞赛 B题 数据驱动的水下导航适配区分类预测 原题再现: “海洋强国”战略部署已成为推动中国现代化建设的重要组成部分,国家对此提出“发展海洋经济,保护海洋生态环境,加快建设海洋强国”的明确要求。 …...

完蛋!百融云被大阳线包围了!
没想到让AI指数爬出底部的,不是离婚的两口子承诺不减持了,而是国产游戏圈神作《完蛋!我被女友包围了》。确实,资本市场不相信眼泪,AI的涨跌也与爱情无关。 之前有一个来自美国和澳大利亚的大数据团队做过一个有趣的统…...

数据结构 编程1年新手视角的平衡二叉树AVL从C与C++实现③
对应地,我们可以将insert函数中省略的操作补上 if(getBalance(node)2){ if(getBalance(node->left)1){ noderightRotate(node); //对应LL型 } else if(getBalance(node->left)-1{ node->left leftRotate(node->left); //对应LR型 noderightRotate(n…...
数据可视化PCA与t-SNE
PCA(主成分分析)和t-SNE(t分布随机近邻嵌入)都是降维技术,可以用于数据的可视化和特征提取。 降维:把数据或特征的维数降低,其基本作用包括: 提高样本密度,以及使基于欧…...

Kubernetes rancher、prometheus、ELK的安装
目录 一、rancher的安装1. 添加 Helm Chart 仓库2. 为 Rancher 创建命名空间3. 选择 SSL 配置4. 安装 cert-manager 二、prometheus安装三、EFK安装3.1安装elasticsearch3.2安装filebeat3.3安装kibana 一、rancher的安装 有关rancher的安装其实官方网站给的步骤已经很详细了&a…...
为什么我们要努力的学习编程?初学编程从哪里开始学起?
为什么我们要努力的学习编程?初学编程从哪里开始学起? 1、不论在哪里上班,都不是铁饭碗:现在全球经济低迷,使得很多企业倒闭,大到知名国企小到私营企业,大量裁员。任何人都无法保证自己现在的工…...
)
ffmpeg 从内存中读取数据(或将数据输出到内存)
1.为了使本文更通俗易懂,更新了部分内容,将例子改为从内存中打开。 2.增加了将数据输出到内存的方法。 从内存中读取数据 ffmpeg一般情况下支持打开一个本地文件,例如“C:\test.avi” 或者是一个流媒体协议的URL,例如“rtmp:/…...
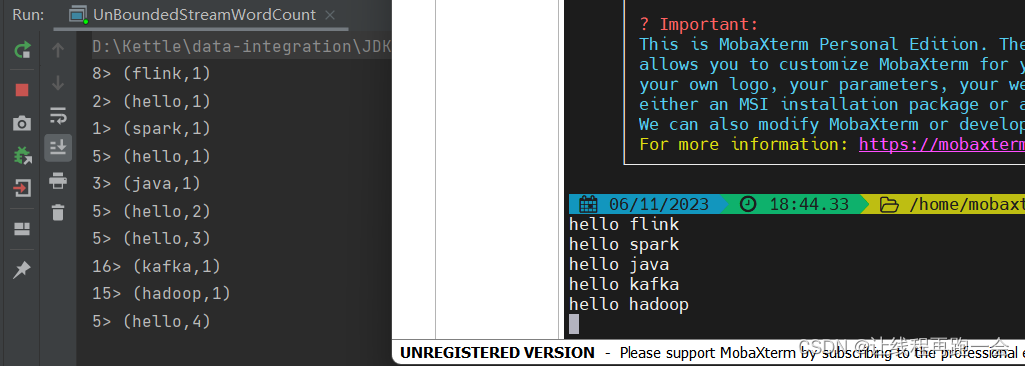
Flink(一)【WordCount 快速入门】
前言 学完了 Hadoop、Spark,本想着先把 Kafka、Flume 这些工具先学完的,但想了想还是把核心的技术先学完最后再去把那些工具学学。 最近心有点累哈哈哈,偷偷立个 flag,反正也没人看,明年的今天来这里还愿哈,…...

【Redis】hash数据类型-常用命令
文章目录 前置知识常用命令HSETHGETHEXISTSHDELHKEYSHVALSHGETALLHMGET关于HMSETHLENHSETNXHINCRBYHINCRBYFLOAT 命令小结 前置知识 redis自身就是键值对结构了,哈希类型是指值本⾝⼜是⼀个键值对结构,形如key"key",value{{field1…...

【大数据】Apache NiFi 数据同步流程实践
Apache NiFi 数据同步流程实践 1.环境2.Apache NIFI 部署2.1 获取安装包2.2 部署 Apache NIFI 3.NIFI 在手,跟我走!3.1 准备表结构和数据3.2 新建一个 Process Group3.3 新建一个 GenerateTableFetch 组件3.4 配置 GenerateTableFetch 组件3.5 配置 DBCP…...
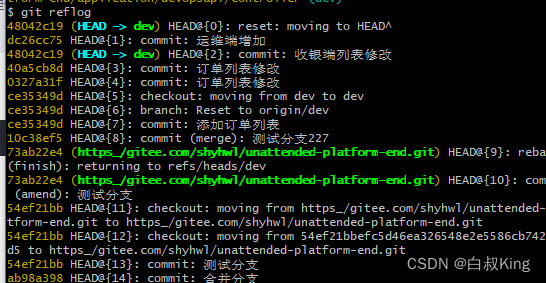
git怎么使用 拉取代码
废话不多说 直接开干 Git 是一款十分实用的版本控制工具,非常方便地管理代码的变更。但是,在使用 Git 过程中,不可避免地会遇到一些问题。其中,删除分支是一个常见的问题。 查看引用历史记录: git reflog找到你删除的…...

Apple :苹果将在明年年底推出自己的 AI,预计将随 iOS 18 一起推出
本心、输入输出、结果 文章目录 Apple :苹果将在明年年底推出自己的 AI,预计将随 iOS 18 一起推出前言三星声称库克相关图片弘扬爱国精神 Apple :苹果将在明年年底推出自己的 AI,预计将随 iOS 18 一起推出 编辑:简简单…...
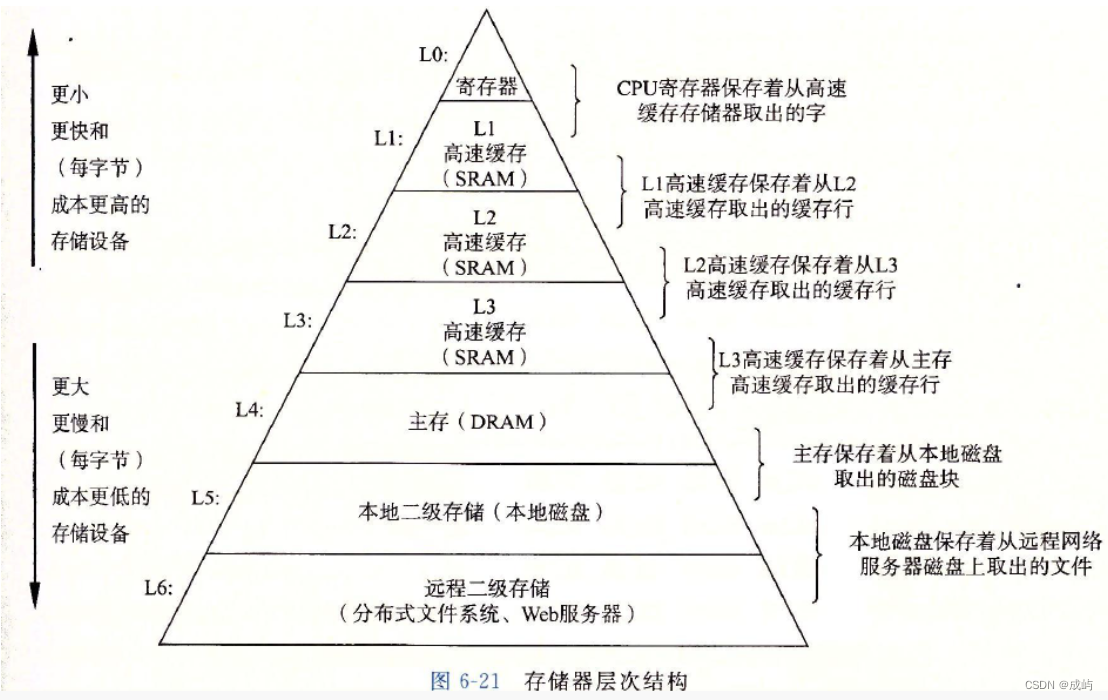
数据结构-双向链表
1.带头双向循环链表: 前面我们已经知道了链表的结构有8种,我们主要学习下面两种: 前面我们已经学习了无头单向非循环链表,今天我们来学习带头双向循环链表: 带头双向循环链表:结构最复杂,一般用…...
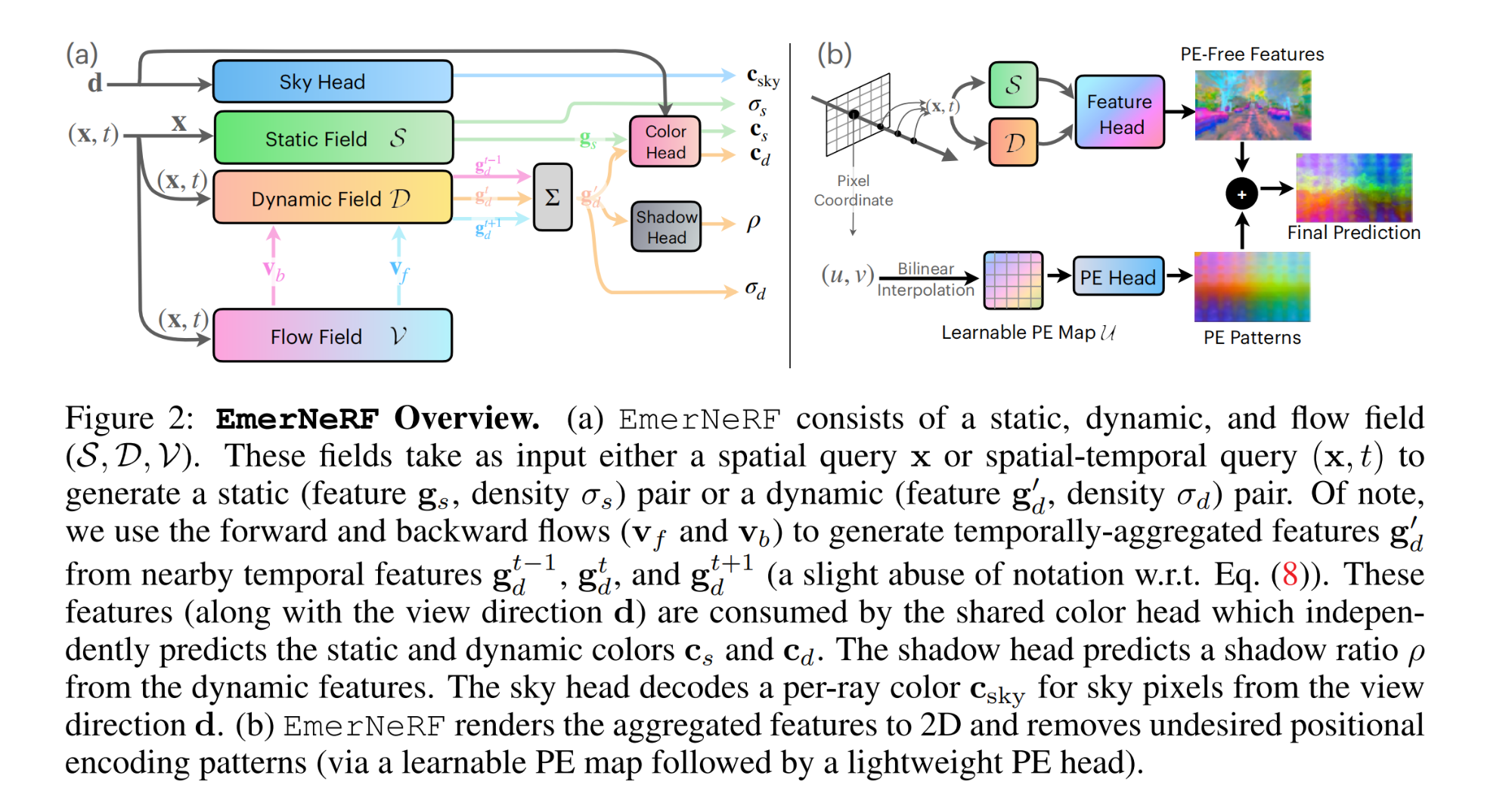
CV计算机视觉每日开源代码Paper with code速览-2023.11.6
精华置顶 墙裂推荐!小白如何1个月系统学习CV核心知识:链接 点击CV计算机视觉,关注更多CV干货 论文已打包,点击进入—>下载界面 点击加入—>CV计算机视觉交流群 1.【点云3D目标检测】(NeurIPS2023)…...

GB28181学习(十五)——流传输方式
前言 基于GB/T28181-2022版本,实时流的传输方式包括3种: UDPTCP被动TCP主动 UDP 流程 注意: m字段指定传输方式为RTP/AVP; 抓包 SIP服务器发送INVITE请求; INVITE sip:xxx192.168.0.111:5060 SIP/2.0 Via: SIP…...

【Linux】:初识git || centos下安装git || 创建本地仓库 || 配置本地仓库 || 认识工作区/暂存区(索引)以及版本库
📮1.初识git Git 原理与使用 课程⽬标 • 技术⽬标:掌握Git企业级应⽤,深刻理解Git操作过程与操作原理,理解⼯作区,暂存区,版本库的含义 • 技术⽬标:掌握Git版本管理,⾃由进⾏版本回退、撤销、修改等Git操…...

Vue 3 中,watch 和 watchEffect 的区别
结论先行: watch 和 watchEffect 都是监听器,都是用来监听响应式数据的变化并执行相应操作。区别是: watch:需要指明要监听的数据,而且在回调函数中可以获取到属性变化的前后值; 适用于需要精确控制监视…...
鲜花展示服务预约小程序的效果如何
鲜花产品的市场需求度非常高,互联网深入各个行业,很多鲜花商家都会通过线上建立平台实现产品销售、获客引流、转化复购、生意增长等,当然除了搭建鲜花商城小程序外,对鲜花供应商及门店还有展示预约方面的需求。 通过【雨科】平台可…...

Linux下多个盘符乱的问题处理
参考文档: linux下man fstab命令查看帮助,有一段说明,可以使用UUID,或者LABEL 来绑定盘。这里使用UUID来绑定 Instead of giving the device explicitly, one may indicate the filesystem that is to be mounted by its UUID …...

uniapp小程序使用web-view组件页面分享后,点击没有home小房子解决办法
uniapp小程序使用web-view组件页面分享后,点击没有home小房子解决办法 小程序 :IOS 测试正常, 安卓 不显示home 微信小程序使用的是全局自定义导航,通过首页 banner 跳转到一个 web-view 页面,展示官网。 web-view 页…...

万象视界灵坛部署教程:阿里云ECS+Docker一键部署开源多模态感知平台
万象视界灵坛部署教程:阿里云ECSDocker一键部署开源多模态感知平台 1. 项目概述 万象视界灵坛(Omni-Vision Sanctuary)是一款基于OpenAI CLIP技术的高级多模态智能感知平台。它将复杂的语义对齐技术转化为直观的像素风格交互体验࿰…...
)
dfs经典例题——迷宫问题(利用二维数组优化方向判断)
思路:首先关于方向问题,我们可以设定一个默认方向,比如先默认向右,触底向下,然后再是向左向上。只需要平行在dfs函数中即可,每次递归会自动依次按照if条件进行合适方向的查找初始量:地图数组&am…...
和CVaR风险管理,用于求解含高比例)
CSDN首页发布文章基于Min-Max-Max-Min四层优化架构的多能源系统日前-实时两阶段鲁棒调度模型,结合了Wasserstein分布鲁棒优化(DRO)和CVaR风险管理,用于求解含高比例
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
:多模态与安全实践)
谷歌Gemini API 应用(二):多模态与安全实践
1. 多模态处理实战:当Gemini遇上图像与文本 第一次用Gemini Pro Vision分析自家猫咪照片时,我被它的理解能力惊到了——不仅能准确识别出"橘猫在抓沙发",还能推断出"猫咪可能处于换牙期需要磨牙玩具"。这种图文结合的智能…...

Qwen3-TTS-12Hz-1.7B-CustomVoice实战教程:与LangChain集成实现多跳语音问答链
Qwen3-TTS-12Hz-1.7B-CustomVoice实战教程:与LangChain集成实现多跳语音问答链 1. 引言:当语音合成遇上智能问答 想象一下这个场景:你对着手机问了一个复杂的问题,比如“帮我查一下北京明天天气怎么样,然后推荐几个适…...
)
用随机森林预测空气质量?先看看这6个特征谁说了算!(Python特征重要性分析与可视化实战)
随机森林特征重要性分析:解码空气质量预测的6大关键因素 当数据科学家们谈论空气质量预测时,常常陷入一个误区——过分关注模型的预测准确率,却忽视了模型背后的故事。想象一下,你花费数周时间调优的随机森林模型预测准确率达到了…...

为什么92%的车载Java应用在-40℃环境崩溃?:嵌入式JRE热稳定性加固实战手册
第一章:车载Java应用低温崩溃现象全景透视在-20℃至-30℃的严寒环境下,车载信息娱乐系统(IVI)中基于Android Framework构建的Java应用频繁出现ANR、SIGSEGV及ClassLoader初始化失败等非预期终止行为。此类崩溃并非由业务逻辑缺陷直…...

Photon光影包:颠覆级Minecraft视觉体验的沉浸式渲染方案
Photon光影包:颠覆级Minecraft视觉体验的沉浸式渲染方案 【免费下载链接】photon A gameplay-focused shader pack for Minecraft 项目地址: https://gitcode.com/gh_mirrors/photon3/photon 在像素化的方块世界中,如何突破视觉边界实现电影级画面…...
的频道与频率设置详解)
DAB SG(信号发生器)的频道与频率设置详解
1. DAB SG信号发生器基础入门 第一次接触DAB SG信号发生器时,很多人会被那些专业术语搞得一头雾水。其实说白了,这就是个能模拟DAB广播信号的设备,主要用在广播设备测试、信号覆盖测试等场景。我刚开始用的时候也犯迷糊,后来才发现…...

Flutter 3.24.x项目升级AGP 8.6适配Android 15,我踩过的坑和完整配置清单
Flutter 3.24.x项目升级AGP 8.6适配Android 15实战指南 上周在给公司核心项目做技术栈升级时,我花了整整三天时间才把Flutter 3.24.x项目成功迁移到AGP 8.6并适配Android 15(API 35)。这过程中踩过的坑比预想中多得多——从Gradle版本冲突到n…...