Flink(一)【WordCount 快速入门】
前言
学完了 Hadoop、Spark,本想着先把 Kafka、Flume 这些工具先学完的,但想了想还是把核心的技术先学完最后再去把那些工具学学。
最近心有点累哈哈哈,偷偷立个 flag,反正也没人看,明年的今天来这里还愿哈,愿望这种事情我是从来是不会说出来的,毕竟言以泄败,事以密成嘛。
那我隐晦低表达一下,摘录自《解忧杂货店》的一条句子:
这是克朗对自己梦想的描述,其实他不是自不量力,而是假如放弃了这个梦想,他的生活就失去了光,他未来的几十年生活会枯燥无味,会活的没有一点激情。
就像一个曾经自己深爱过的姑娘一样,明明无法在一起,却还是始终记挂着,因为心里眼里只有她,所以别人在你眼中,都会黯然失色的,没有色彩的东西,又怎么能投入激情去爱呢?
我的愿望有两个,在上面中有所体现,但我希望结果不要是遗憾,第一个愿望明年这会大概知道结果了,第二个愿望应该会晚一点,也许在2025年的春天,也许会更早一点...
API 环境搭建
添加依赖
pom.xml
<properties><flink.version>1.13.0</flink.version><java.version>1.8</java.version><scala.binary.version>2.12</scala.binary.version><slf4j.version>1.7.30</slf4j.version>
</properties>
<dependencies>
<!-- 引入 Flink 相关依赖--><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java_${scala.binary.version}</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients_${scala.binary.version}</artifactId><version>${flink.version}</version>
</dependency>
<!-- 引入日志管理相关依赖--><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-api</artifactId><version>${slf4j.version}</version></dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>${slf4j.version}</version></dependency><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-to-slf4j</artifactId><version>2.14.0</version>
</dependency>
</dependencies>
log4j.properties
log4j.rootLogger=error, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%-4r [%t] %-5p %c %x - %m%n
入门案例
0、数据准备
在 根目录下创建 words.txt
hello flink
hello java
hello spark
hello hadoop1、批处理
批处理所用到的算子API 都继承自 DataSet,而新版的 Flink 已经做到了流批一体,这里只做演示,以后这类 API 应该是要被弃用了。
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.AggregateOperator;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.FlatMapOperator;
import org.apache.flink.api.java.operators.UnsortedGrouping;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;public class BatchWordCount {public static void main(String[] args) throws Exception {// 1. 创建一个执行批式数据处理环境ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();// 2. 从文件中读取数据 String类型 批式数据处理环境得到的 DataSource 继承自 DataSetDataSource<String> lineDS = env.readTextFile("input/words.txt");// 3. 将每行数据转换成一个二元组类型// 输入类型: String 输出类型: Tuple2FlatMapOperator<String, Tuple2<String, Long>> wordAndOne =// String lines: 输入数据行 Collector<Tuple2<String,Long>> out: 输出类型lineDS.flatMap((String line, Collector<Tuple2<String, Long>> out) -> {String[] words = line.split(" ");for (String word : words) {out.collect(Tuple2.of(word, 1L));}}).returns(Types.TUPLE(Types.STRING, Types.LONG)); //使用 Java 泛型的时候, 由于泛型擦除的存在, 需要显示信息返回返回值类型// 4. 根据 word 分组UnsortedGrouping<Tuple2<String, Long>> wordGroup = wordAndOne.groupBy(0); // 0 是索引位置// 5. 分组内进行聚合AggregateOperator<Tuple2<String, Long>> res = wordGroup.sum(1); // 1 也是索引位置// 6. 打印结果res.print();}
}
运行结果:
(hadoop,1)
(flink,1)
(hello,4)
(java,1)
(spark,1)Process finished with exit code 0因为现在已经是流批一体的框架了,所以提交 Flink 批处理任务需要用下面的语句:
$ bin/flink run -Dexecution.runtime-mode=BATCH BatchWordCount.jar2、流处理
2.1、有界数据流处理
这里我们用离线数据(提前创建好的文件)用流处理API DataStream 的算子来做处理。
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;public class BoundedStreamWordCount {public static void main(String[] args) throws Exception {// 1. 创建一个流式的执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironment();// 2. 流式数据处理环境得到的 DataSource 继承自 DataStreamDataStreamSource<String> lineDS = env.readTextFile("input/words.txt");// 3. flatMap 打散数据 返回元组SingleOutputStreamOperator<Tuple2<String, Long>> wordAndOne = lineDS.flatMap((String line, Collector<Tuple2<String, Long>> out) -> {String[] words = line.split(" ");for (String word : words) {out.collect(Tuple2.of(word, 1L));}}).returns(Types.TUPLE(Types.STRING, Types.LONG));// 4. 根据 word 分组KeyedStream<Tuple2<String, Long>, String> wordGroupByKey = wordAndOne.keyBy(t -> t.f0);// 5. 根据键对索引为 1 处的值进行合并SingleOutputStreamOperator<Tuple2<String, Long>> res = wordGroupByKey.sum(1);// 6. 输出结果res.print();// 7. 执行env.execute(); // 这里我们的数据是有界的,但是真正开发环境是无界的,这里需要用execute方法等待新数据的到来}
}
运行结果:
3> (java,1)
13> (flink,1)
1> (spark,1)
5> (hello,1)
5> (hello,2)
5> (hello,3)
5> (hello,4)
15> (hadoop,1)我们可以发现,输出的单词的顺序是乱序的,因为集群模式下数据流不是在本地执行的,而是在多个节点中执行,所以也就无法保证先输入的单词最先输出。
Idea下Flink API 会使用多线程来模拟集群下的多节点并行处理,而我们每行数据前面的 "编号>" 代表的就是线程的 id(对应 Flink 运行时占据的最小资源,也叫任务槽),默认使用当前电脑的所有 CPU 数。
我们还可以发现,hello是同一个节点上处理的,这是因为我们在做分组的时候,把分组后的数据分到了同一个节点(子任务)上。
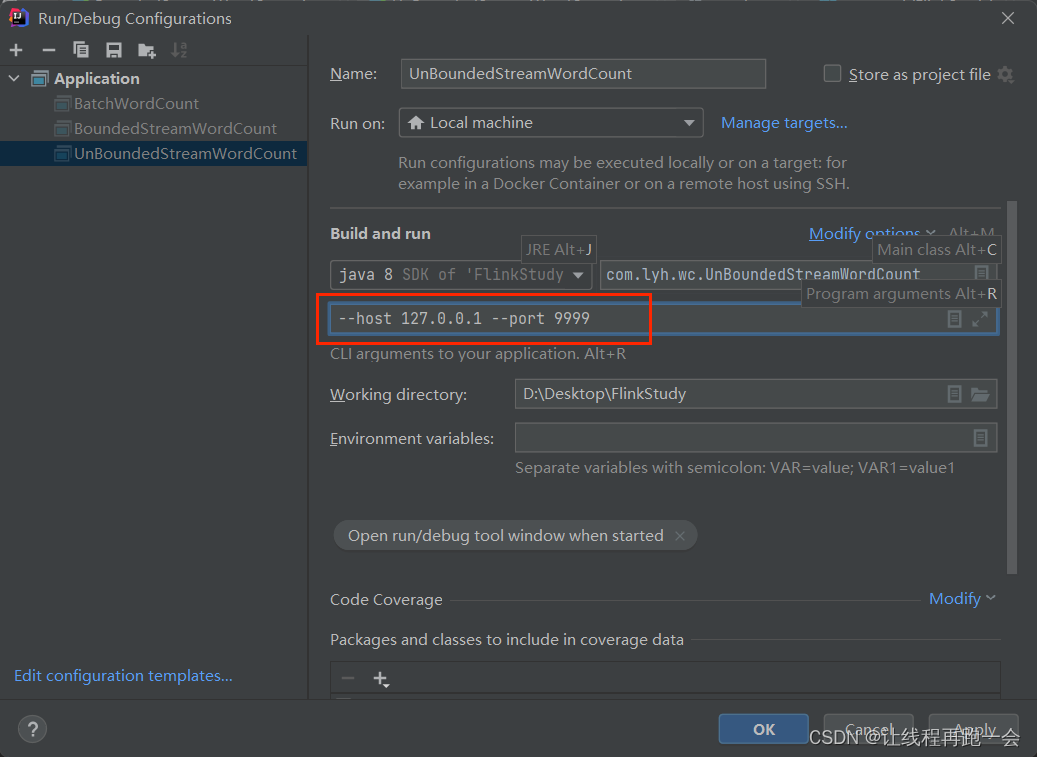
2.2、无界数据流处理
这里我们使用 netcat 来模拟产生数据流
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;public class UnBoundedStreamWordCount {public static void main(String[] args) throws Exception {// 1. 创建一个流式的执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironment();// 2. 流式数据处理环境得到的 DataSource 继承自 DataStreamParameterTool parameterTool = ParameterTool.fromArgs(args);String host = parameterTool.get("host");Integer port = parameterTool.getInt("port");DataStreamSource<String> lineDS = env.socketTextStream(host,port);// 3. flatMap 打散数据 返回元组SingleOutputStreamOperator<Tuple2<String, Long>> wordAndOne = lineDS.flatMap((String line, Collector<Tuple2<String, Long>> out) -> {String[] words = line.split(" ");for (String word : words) {out.collect(Tuple2.of(word, 1L));}}).returns(Types.TUPLE(Types.STRING, Types.LONG));// 4. 根据 word 分组KeyedStream<Tuple2<String, Long>, String> wordGroupByKey = wordAndOne.keyBy(t -> t.f0);// 5. 根据键对索引为 1 处的值进行合并SingleOutputStreamOperator<Tuple2<String, Long>> res = wordGroupByKey.sum(1);// 6. 输出结果res.print();// 7. 执行env.execute(); // 这里我们的数据是有界的,但是真正开发环境是无界的,这里需要用execute方法等待新数据的到来}
}
运行结果:
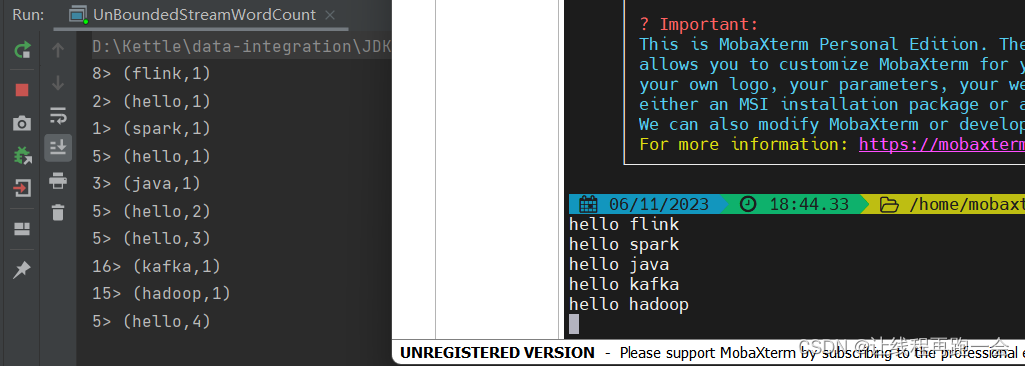
可以看到,处理是相当快的,毕竟数据量很小,但是会想到 SparkStreaming 的处理过程,我们之前用 SparkStreaming 的时候还需要设置 Reciver 的接收间隔,而我们的 Flink 则是真正的实时处理。
总结
Flink 的学习终于开始了,还是一样的要求,不照搬视频课件内容,每行代码要有自己的思考,每行博客也要是自己思考的总结。
还有,最近感觉愈发词穷,该多看书了,以后养成每次博客加一条书摘的习惯。
相关文章:
Flink(一)【WordCount 快速入门】
前言 学完了 Hadoop、Spark,本想着先把 Kafka、Flume 这些工具先学完的,但想了想还是把核心的技术先学完最后再去把那些工具学学。 最近心有点累哈哈哈,偷偷立个 flag,反正也没人看,明年的今天来这里还愿哈,…...

【Redis】hash数据类型-常用命令
文章目录 前置知识常用命令HSETHGETHEXISTSHDELHKEYSHVALSHGETALLHMGET关于HMSETHLENHSETNXHINCRBYHINCRBYFLOAT 命令小结 前置知识 redis自身就是键值对结构了,哈希类型是指值本⾝⼜是⼀个键值对结构,形如key"key",value{{field1…...

【大数据】Apache NiFi 数据同步流程实践
Apache NiFi 数据同步流程实践 1.环境2.Apache NIFI 部署2.1 获取安装包2.2 部署 Apache NIFI 3.NIFI 在手,跟我走!3.1 准备表结构和数据3.2 新建一个 Process Group3.3 新建一个 GenerateTableFetch 组件3.4 配置 GenerateTableFetch 组件3.5 配置 DBCP…...
git怎么使用 拉取代码
废话不多说 直接开干 Git 是一款十分实用的版本控制工具,非常方便地管理代码的变更。但是,在使用 Git 过程中,不可避免地会遇到一些问题。其中,删除分支是一个常见的问题。 查看引用历史记录: git reflog找到你删除的…...

Apple :苹果将在明年年底推出自己的 AI,预计将随 iOS 18 一起推出
本心、输入输出、结果 文章目录 Apple :苹果将在明年年底推出自己的 AI,预计将随 iOS 18 一起推出前言三星声称库克相关图片弘扬爱国精神 Apple :苹果将在明年年底推出自己的 AI,预计将随 iOS 18 一起推出 编辑:简简单…...
数据结构-双向链表
1.带头双向循环链表: 前面我们已经知道了链表的结构有8种,我们主要学习下面两种: 前面我们已经学习了无头单向非循环链表,今天我们来学习带头双向循环链表: 带头双向循环链表:结构最复杂,一般用…...
CV计算机视觉每日开源代码Paper with code速览-2023.11.6
精华置顶 墙裂推荐!小白如何1个月系统学习CV核心知识:链接 点击CV计算机视觉,关注更多CV干货 论文已打包,点击进入—>下载界面 点击加入—>CV计算机视觉交流群 1.【点云3D目标检测】(NeurIPS2023)…...

GB28181学习(十五)——流传输方式
前言 基于GB/T28181-2022版本,实时流的传输方式包括3种: UDPTCP被动TCP主动 UDP 流程 注意: m字段指定传输方式为RTP/AVP; 抓包 SIP服务器发送INVITE请求; INVITE sip:xxx192.168.0.111:5060 SIP/2.0 Via: SIP…...

【Linux】:初识git || centos下安装git || 创建本地仓库 || 配置本地仓库 || 认识工作区/暂存区(索引)以及版本库
📮1.初识git Git 原理与使用 课程⽬标 • 技术⽬标:掌握Git企业级应⽤,深刻理解Git操作过程与操作原理,理解⼯作区,暂存区,版本库的含义 • 技术⽬标:掌握Git版本管理,⾃由进⾏版本回退、撤销、修改等Git操…...

Vue 3 中,watch 和 watchEffect 的区别
结论先行: watch 和 watchEffect 都是监听器,都是用来监听响应式数据的变化并执行相应操作。区别是: watch:需要指明要监听的数据,而且在回调函数中可以获取到属性变化的前后值; 适用于需要精确控制监视…...
鲜花展示服务预约小程序的效果如何
鲜花产品的市场需求度非常高,互联网深入各个行业,很多鲜花商家都会通过线上建立平台实现产品销售、获客引流、转化复购、生意增长等,当然除了搭建鲜花商城小程序外,对鲜花供应商及门店还有展示预约方面的需求。 通过【雨科】平台可…...

Linux下多个盘符乱的问题处理
参考文档: linux下man fstab命令查看帮助,有一段说明,可以使用UUID,或者LABEL 来绑定盘。这里使用UUID来绑定 Instead of giving the device explicitly, one may indicate the filesystem that is to be mounted by its UUID …...

uniapp小程序使用web-view组件页面分享后,点击没有home小房子解决办法
uniapp小程序使用web-view组件页面分享后,点击没有home小房子解决办法 小程序 :IOS 测试正常, 安卓 不显示home 微信小程序使用的是全局自定义导航,通过首页 banner 跳转到一个 web-view 页面,展示官网。 web-view 页…...

SLAM_语义SLAM相关论文
目录 1. 综述 2. 相关文章 Probabilistic Data Association for Semantic SLAM VSO:Visual Semantic Odometry 语义信息分割运动物体...

【技巧】并发读取Mysql数据保证读取到的数据不重复
【技巧】并发读取Mysql数据保证读取到的数据不重复 使用场景: 并发场景下, 保证不获取到重复的数据 思路: 先通过 MYSQL锁 去占位打标识,然后再去取数据 相当于几个人抢蛋糕, A先把蛋糕打上记号 蛋糕是A的, 然后再慢慢吃 表结构 表 t_userid name val used_flag 是否使用…...

Lavarel异步队列的使用
系统为window 启动队列: php artisan queue:listen设置队列类 .env文件需设置:QUEUE_CONNECTIONredis <?phpnamespace App\Jobs;use Illuminate\Bus\Queueable; use Illuminate\Contracts\Queue\ShouldQueue; use Illuminate\Foundation\Bus\Disp…...
JVM知识分享(PPT在资源里)
一、前言 1.自动内存管理 有句经典的话是这样说,Java与C之间有一堵由内存动态分配和垃圾收集技术所围成的高墙,墙外面的人想进去,墙里面的人却想出来。对于Java程序员来说,在虚拟机自动内存管理机制的帮助下,不再需要…...
整合Salesforce Org需要避免的3大风险
管理多个Salesforce实例是成长型企业可能遇到的场景,每个Salesforce实例都包含可能需要整合的关键业务数据和流程。 除了整合,组织可能会在不同的发展阶段采用Salesforce(例如CRM、服务、运营)。整合的最终结果是多个Salesforce实例被统一,并…...
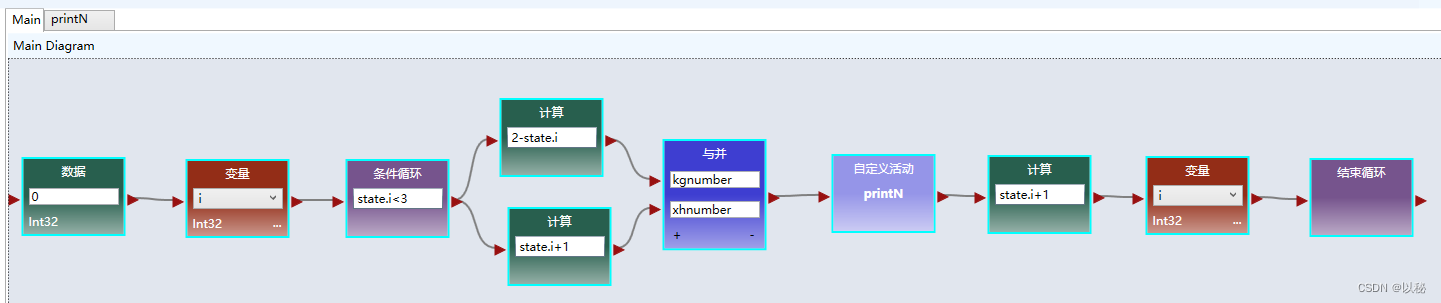
viple进阶3:打印不同形状的三角形
(1)题目:打印实心的三角形(正三角) 第一步:观察图形。首行是1颗星,其余的每一行都比上一行多1颗星;其次,每一行的星号数和行数值相等,第一行有1颗星ÿ…...
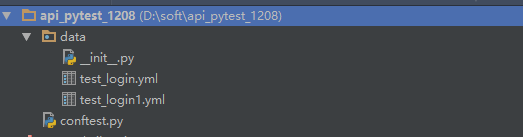
pytest+yaml实现接口自动化框架
前言 httprunner 用 yaml 文件实现接口自动化框架很好用,最近在看 pytest 框架,于是参考 httprunner的用例格式,写了一个差不多的 pytest 版的简易框架 项目结构设计 项目结构完全符合 pytest 的项目结构,pytest 是查找 test_.…...

暗黑破坏神2存档编辑器:安全高效的d2s文件修改与角色属性调整工具
暗黑破坏神2存档编辑器:安全高效的d2s文件修改与角色属性调整工具 【免费下载链接】d2s-editor 项目地址: https://gitcode.com/gh_mirrors/d2/d2s-editor 暗黑破坏神2存档编辑器(d2s-editor)是一款专为《暗黑破坏神2》玩家设计的开源…...

Winhance-zh_CN:如何免费让你的Windows系统焕然一新
Winhance-zh_CN:如何免费让你的Windows系统焕然一新 【免费下载链接】Winhance-zh_CN A Chinese version of Winhance. C# application designed to optimize and customize your Windows experience. 项目地址: https://gitcode.com/gh_mirrors/wi/Winhance-zh_C…...

深度学习框架YOLOV8模型如何训练水下生物检测数据集 构建基于YOLOv8➕pyqt5的水下生物检测系统 海胆‘, ‘海参‘, ‘扇贝‘, ‘海星‘, ‘水草
享基于YOLOv8➕pyqt5的水下生物检测系统内含7600张水下生物数据集 包括[‘海胆’, ‘海参’, ‘扇贝’, ‘海星’, ‘水草’],5类也可自行替换模型,使用该界面做其他检测 这是一个非常经典的计算机视觉应用项目,结合了深度学习的目标检测&…...
:多模态与安全实践)
谷歌Gemini API 应用(二):多模态与安全实践
1. 多模态处理实战:当Gemini遇上图像与文本 第一次用Gemini Pro Vision分析自家猫咪照片时,我被它的理解能力惊到了——不仅能准确识别出"橘猫在抓沙发",还能推断出"猫咪可能处于换牙期需要磨牙玩具"。这种图文结合的智能…...

2025届必备的十大降重复率工具实测分析
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 用于学术论文、科研报告以及各类文档,提供查重与改写服务的在线工具是降重网站。…...

Meshroom终极指南:零基础学会开源3D重建,从照片到模型的完整方案
Meshroom终极指南:零基础学会开源3D重建,从照片到模型的完整方案 【免费下载链接】Meshroom Node-based Visual Programming Toolbox 项目地址: https://gitcode.com/gh_mirrors/me/Meshroom 想要从普通照片创建专业级3D模型吗?Meshro…...

泉盛UV-K5/K6固件自定义:解锁专业对讲机功能的终极指南
泉盛UV-K5/K6固件自定义:解锁专业对讲机功能的终极指南 【免费下载链接】uv-k5-firmware-custom 全功能泉盛UV-K5/K6固件 Quansheng UV-K5/K6 Firmware 项目地址: https://gitcode.com/gh_mirrors/uvk5f/uv-k5-firmware-custom 你是否曾想过,一台…...
)
保姆级教程:用Python+Socket实现西门子CNC产量数据自动采集(附避坑指南)
PythonSocket实现西门子CNC产量数据自动化采集实战指南 在工业4.0时代,生产数据的实时采集与分析已成为智能制造的核心环节。对于使用西门子数控系统(如828D、840DSL等)的制造企业而言,如何绕过复杂的授权流程,通过编程…...

Phi-3-mini-4k-instruct快速上手:Ollama部署指南,开启你的第一个AI项目
Phi-3-mini-4k-instruct快速上手:Ollama部署指南,开启你的第一个AI项目 1. 认识Phi-3-mini-4k-instruct:轻量级AI助手 Phi-3-mini-4k-instruct是一个仅有38亿参数的轻量级AI模型,由微软团队开发。虽然体积小巧,但它在…...

Phi-3-mini-4k-instruct-gguf免配置环境:开箱即用的Web UI,开发者5分钟上手
Phi-3-mini-4k-instruct-gguf免配置环境:开箱即用的Web UI,开发者5分钟上手 1. 认识Phi-3-mini-4k-instruct-gguf Phi-3-mini-4k-instruct-gguf是微软Phi-3系列中的轻量级文本生成模型GGUF版本。这个模型特别适合处理问答、文本改写、摘要整理和简短创…...