HyperGBM用4记组合拳提升AutoML模型泛化能力
本文作者:杨健,九章云极 DataCanvas 主任架构师
如何有效提高模型的泛化能力,始终是机器学习领域的重要课题。经过大量的实践证明比较有效的方式包括:
- 利用Early Stopping防止过拟合
- 通过正则化降低模型的复杂度
- 使用更多的训练数据
- 尽量使用更少的特征
- 使用CV来选择模型和超参数
- 使用Ensemble来提升泛化能力
Early stopping以及正则化是比较基本的方法这里就不赘述,此外HyperGBM中还提供了4种高级特性,专门用来提升模型的泛化能力:
- Pseudo-labeling半监督学习
- 二阶特征筛选
- K-fold Cross-validation
- Greedy ensemble
1.Pseudo-labeling
伪标签技术主要应用在分类任务上,本质上是通过半监督学习的方法来增加更多的训练数据,以提升模型的泛化能力。其过程如下图所示,主要分为三个阶段:
1.第一阶段用训练数据训练模型;
2.第二阶段使用第一阶段训练好的模型在无标注的数据上预测,将其中置信度较高的数据合并到训练集中;
3.第三阶段使用合并后的数据重新训练模型;
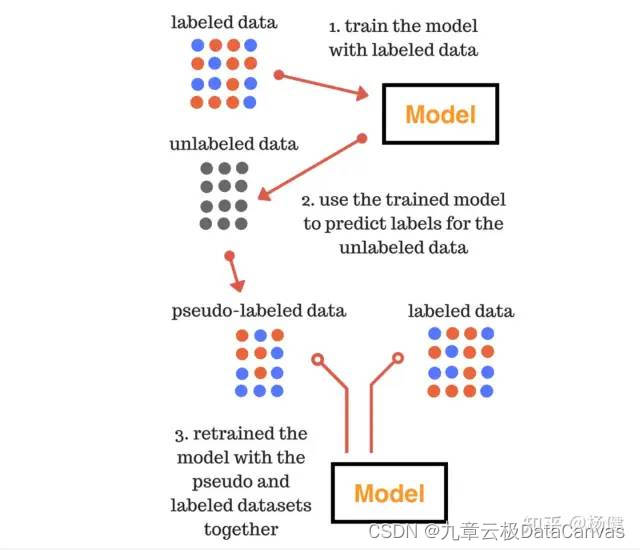
Image from: https://www.analyticsvidhya.com/blog/2017/09/pseudo-labelling-semi-supervised-learning-technique/
示例代码,HyperGBM中只需设置pseudo_labeling会自动完成伪标签学习:
from tabular_toolbox.datasets import dsutils
from sklearn.model_selection import train_test_split
from hypergbm.search_space import search_space_general
from hypergbm import make_experiment
# load data into Pandas DataFrame
df = dsutils.load_bank()
target = 'y'
train, test = train_test_split(df, test_size=0.3)
test.pop(target)#create an experiment
experiment = make_experiment(train,target=target,pseudo_labeling=True)
#run experiment
estimator = experiment.run()
# predict on test data without target values
pred = estimator.predict(test)
2.二阶特征筛选
通过特征筛选过滤掉无效特征或者噪音数据,能有效降低模型的复杂度。传统的特征筛选方法,一类是在训练之前通过相关性指标评估或者是基于模型的特征评估排序,然后根据阈值或者是排序选择n个特征用于训练,另一类是先训练模型然后根据模型本身提供的特征重要性来选择一部分特征重新训练。第一类方法有明显的缺陷就是特征的评估标准和实际用于训练的模型无关,也不会考虑特征之间的交互关系。第二类方法有明显的改进但也存在一个问题,就是模型提供是在训练数据上的重要性,并不能体现在评估数据或测试数据上特征的重要性。因此HyperGBM中引入了独特的二阶特征筛选策略来克服以上缺点。它的工作方式如下:首先执行一阶段AutoML过程,然后选择其中表现最好的n个模型使用permutation模式评估特征重要性,删除低于某一阈值的特征后,重新执行AutoML过程。
这里主要介绍一下permutation特征筛选:首先,基于已经训练好的模型在评估集上得到一个baseline评分,然后分别将每一列特征变成噪音数据后重新评估,评分等于或高于baseline评分说明该特征对模型没有增益甚至于是有损的,如果评分下降说明该特征是对模型有益的,用这个和baseline评分的差值做为特征筛选的参考值选择特征。
示例代码如下:
#create an experiment
experiment = make_experiment(train,target=target,
feature_reselection=True,
feature_reselection_estimator_size=10,
feature_reselection_threshold=1e-5,
)
3.K-fold Cross-validation
交叉验证被证明是模型选择和超参数优化中最有效的验证方式,示例代码如下:
#create an experiment
experiment = make_experiment(train,target=target,
cv=True,
num_folds=3,
)
4.Greedy Ensemble
Greedy Ensemble是使用基于voting的集成学习方法,实现原理可以参考:
https://www.sciencedirect.com/science/article/abs/pii/S0031320310005340
示例代码:
#create an experiment
experiment = make_experiment(train,target=target,
ensemble_size=20, # 0 to disable ensemble
)
以上四种方法可以组合起来使用。
相关文章:
HyperGBM用4记组合拳提升AutoML模型泛化能力
本文作者:杨健,九章云极 DataCanvas 主任架构师 如何有效提高模型的泛化能力,始终是机器学习领域的重要课题。经过大量的实践证明比较有效的方式包括: 利用Early Stopping防止过拟合通过正则化降低模型的复杂度使用更多的训练数…...

P6软件中的前锋线设置
卷首语 所谓前锋线,是指从评估时刻的时标点出发,用点划线一次连接各项活动的实际进展位置所形成的的线段,其通常为折线。 关键路径法 前锋线比较法,是通过在进度计划中绘制实际进度前锋线以判断活动实际进度与计划进度的偏差&a…...

Spring Boot + Vue3 前后端分离 实战 wiki 知识库系统<二>---后端架构完善与接口开发
数据库准备: 在上一次Spring Boot Vue3 前后端分离 实战 wiki 知识库系统<一>---Spring Boot项目搭建已经将SpringBoot相关的配置环境给搭建好了,接下来则需要为咱们的项目创建一个数据库。 1、mysql的安装: 关于mysql的安装这里就…...
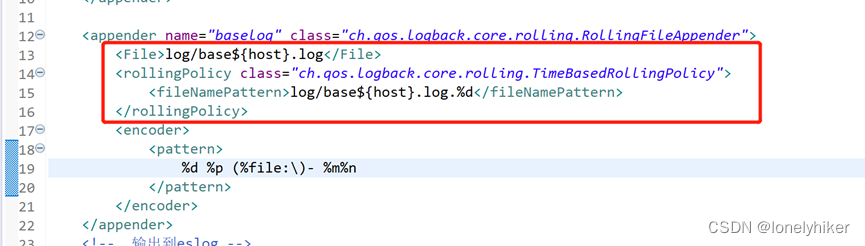
如何在logback.xml中自定义动态属性
原文地址:http://blog.jboost.cn/trick-logback-prop.html 当使用logback来记录Web应用的日志时,我们通过在logback.xml中配置appender来指定日志输出格式及输出文件路径,这在一台主机或一个文件系统上部署单个实例没有问题,但是…...
嵌入式系统硬件设计与实践(第一步下载eda软件)
【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing 163.com】 现实生活中,我们经常发现有的人定了很多的目标,但是到最后一个都没有实现。这听上去有点奇怪,但确实是实实在在…...
Portraiture4免费磨皮插件支持PS/LR
Portraiture 4免去了繁琐的手工劳动,选择性的屏蔽和由像素的平滑,以帮助您实现卓越的肖像润色。智能平滑,并删除不完善之处,同时保持皮肤的纹理和其他重要肖像的细节,如头发,眉毛,睫毛等。 一键…...

Python学习笔记202302
1、numpy.empty 作用:根据给定的维度和数值类型返回一个新的数组,其元素不进行初始化。 用法:numpy.empty(shape, dtypefloat, order‘C’) 2、logging.debug 作用:Python 的日志记录工具,这个模块为应用与库实现了灵…...

2023年大数据面试开胃菜
1、kafka的message包括哪些信息一个Kafka的Message由一个固定长度的header和一个变长的消息体body组成,header部分由一个字节的magic(文件格式)和四个字节的CRC32(用于判断body消息体是否正常)构成。当magic的值为1的时候,会在magic和crc32之间多一个字节…...

优雅的controller层设计
controller层设计 Controller 层逻辑 MVC架构下,我们的web工程结构会分为三层,自下而上是dao层,service层和controller层。controller层为控制层,主要处理外部请求。调用service层,一般情况下,contro…...

同步、通信、死锁
基础概念竞争资源引起两个问题死锁:因资源竞争陷入永远等待的状态饥饿:一个可运行程序由于其他进程总是优先于它,而被调用程序总是无限期地拖延而不能执行进程互斥:若干进程因相互争夺独占型资源而产生的竞争关系进程同步…...
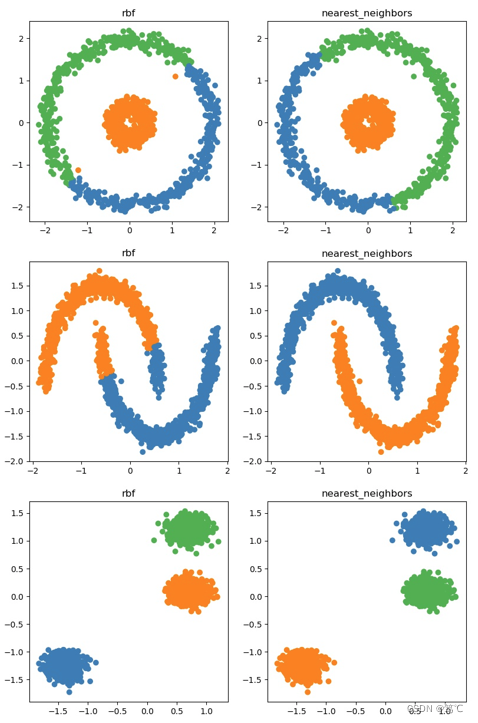
【聚类】谱聚类解读、代码示例
【聚类】谱聚类详解、代码示例 文章目录【聚类】谱聚类详解、代码示例1. 介绍2. 方法解读2.1 先验知识2.1.1 无向权重图2.1.2 拉普拉斯矩阵2.2 构建图(第一步)2.2.1 ϵ\epsilonϵ 邻近法2.2.2 k 近邻法2.2.3 全连接法2.3 切图(第二步…...
,简介)
最牛逼的垃圾回收期ZGC(1),简介
1丶什么是ZGC? ZGC是JDK 11中引入的一种可扩展的、低延迟的垃圾收集器。ZGC最主要的特点是:在非常短的时间内(一般不到10ms),就可以完成一次垃圾回收,而且这个时间是与堆的大小无关的。另外,ZGC支持非常大…...

微服务的Feign到底是什么
Feign是什么 分区是一种数据库优化技术,它可以将大表按照一定的规则分成多个小表,从而提高查询和维护的效率。在分区的过程中,数据库会将数据按照分区规则分配到不同的分区中,并且可以在分区中使用索引和其他优化技术来提高查询效…...

JavaScript 正则表达式
正则表达式(英语:Regular Expression,在代码中常简写为regex、regexp或RE)使用单个字符串来描述、匹配一系列符合某个句法规则的字符串搜索模式。搜索模式可用于文本搜索和文本替换。什么是正则表达式?正则表达式是由一…...

【批处理脚本】-1.15-文件内字符串查找命令find
"><--点击返回「批处理BAT从入门到精通」总目录--> 共7页精讲(列举了所有find的用法,图文并茂,通俗易懂) 在从事“嵌入式软件开发”和“Autosar工具开发软件”过程中,经常会在其集成开发环境IDE(CodeWarrior,S32K DS,Davinci,EB Tresos,ETAS…)中,…...
【手撕面试题】JavaScript(高频知识点二)
目录 面试官:请你谈谈JS的this指向问题 面试官:说一说call apply bind的作用和区别? 面试官:请你谈谈对事件委托的理解 面试官:说一说promise是什么与使用方法? 面试官:说一说跨域是什么&a…...

Web学习1_HTML
在学校期间学的Web知识忘了一些,很多东西摸棱两可,现重新系统的学习一下。 首先下载安装完vsc后并下载拓展文件live server(模拟一个服务器) Auto Rename Tag(在写网页时,自动对齐前后标签)在设…...
)
华为OD机试真题Java实现【靠谱的车】真题+解题思路+代码(20222023)
靠谱的车 题目 程序员小明打了一辆出租车去上班。出于职业敏感,他注意到这辆出租车的计费表有点问题,总是偏大。 出租车司机解释说他不喜欢数字4,所以改装了计费表,任何数字位置遇到数字4就直接跳过,其余功能都正常。 比如: 23再多一块钱就变为25; 39再多一块钱变…...
【C++入门(下篇)】C++引用,内联函数,auto关键字的学习
前言: 在上一期我们进行了C的初步认识,了解了一下基本的概念还学习了包括:命名空间,输入输出以及缺省参数等相关的知识。今天我们将进一步对C入门知识进行学习,主要还需要大家掌握我们接下来要学习的——引用…...

基于合作型Stackerlberg博弈的考虑差别定价和风险管理的微网运行策略研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

UE5 BaseEditorSettings.ini加载原理与配置生效机制
1. 为什么你改了BaseEditorSettings.ini却没生效?——从UE5编辑器启动流程讲起很多人在UE5项目里折腾半天,把BaseEditorSettings.ini文件翻来覆去改了十几遍,重启编辑器后发现:缩放比例还是不对、网格间距没变、甚至“启用实时预览…...

[智能体-69]:重新认知MCP:协议不生产智能,只是AI全域交互的标准化基石
MCP只是提供了大模型、编排调度、外部工具能够进行结构化交流的标准,而整个系统的智能主要依赖编排调度,与外部软件系统的交互取决于外部工具,包括外部语音交互、视觉交互、数字化交互。当下MCP(Model Context Protocol࿰…...

Veo 2胶片质感生成器失效?——深度解析Color Science v2.3内核中被屏蔽的Cinematic Grain Injection层
更多请点击: https://kaifayun.com 第一章:Veo 2胶片质感生成器失效现象全景透视 近期大量用户反馈,Veo 2 胶片质感生成器在调用 generate_film_effect() 接口后返回空纹理、纯灰帧或 HTTP 503 Service Unavailable 错误,且该问题…...

转行网络安全运维:从0到1的可落地指南
转行网络安全运维:从0到1的可落地指南 一、 「3个核心技能:从零起步也能会」 网上学习资料多到爆炸,不用纠结“哪个最好”,记住一句话:**能学会、能上手的就是好的**!不管是免费视频还是付费课,…...

电子商务设计师软考备战:特别篇 - 综合模拟与备考策略
1. 考试形式与内容结构1.1 考试基本信息考试科目与时间基础知识考试:上午9:00-11:30(150分钟)应用技术考试:下午2:00-4:30(150分钟)题型与分值分布上午考试(基础知识): -…...

网络配置工具类详解
CNet 网络配置工具类详解平台:仅支持 Linux,大量使用 ioctl 系统调用一、概述 CNet 是一个 纯静态方法的网络配置工具类,封装了 Linux 下常用的网络操作:功能类别涵盖内容IP 地址读取/设置本机 IP、子网掩码网关读取/添加/删除/设…...

双稳健机器学习:用正交性与交叉拟合解决因果推断中的ML偏差
1. 项目概述:当机器学习遇见因果推断的“干扰”难题在实证研究的日常工作中,我们常常面临一个核心矛盾:我们真正关心的,往往只是一个或几个关键参数——比如一项政策对就业率的平均影响(平均处理效应,ATE&a…...

PCL 法向量夹角剔除错误匹配点对【2026最新版】
目录 一、 算法简介 1、主要函数 2、参考文献 二、 代码实现 三、 结果展示 四、 参考链接 博客长期更新,本文最新更新时间为:2026年5月24日。代码在PCL1.15.1中测试通过 一、 算法简介 在三维点云配准中,对应点(correspondence)的准确性直接决定了配准算法的精度和鲁棒性…...

ZTE光猫工厂模式解锁:5分钟开启隐藏功能的终极指南
ZTE光猫工厂模式解锁:5分钟开启隐藏功能的终极指南 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 核心关键词:ZTE光猫工厂模式解锁 长尾关键词: ZT…...

3步快速解密中兴光猫配置:ZET工具终极实战指南
3步快速解密中兴光猫配置:ZET工具终极实战指南 【免费下载链接】ZET-Optical-Network-Terminal-Decoder 项目地址: https://gitcode.com/gh_mirrors/ze/ZET-Optical-Network-Terminal-Decoder 中兴光猫配置解密工具是每个网络管理员必备的神器!Z…...