【实战-08】flink 消费kafka自定义序列化
目的
让从kafka消费出来的数据,直接就转换成我们的对象
mvn pom
<!--
Licensed to the Apache Software Foundation (ASF) under one
or more contributor license agreements. See the NOTICE file
distributed with this work for additional information
regarding copyright ownership. The ASF licenses this file
to you under the Apache License, Version 2.0 (the
"License"); you may not use this file except in compliance
with the License. You may obtain a copy of the License athttp://www.apache.org/licenses/LICENSE-2.0Unless required by applicable law or agreed to in writing,
software distributed under the License is distributed on an
"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
KIND, either express or implied. See the License for the
specific language governing permissions and limitations
under the License.
-->
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.boke</groupId><artifactId>Flink1.7.1</artifactId><version>1.0-SNAPSHOT</version><packaging>jar</packaging><name>Flink Quickstart Job</name><properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><flink.version>1.17.1</flink.version><target.java.version>1.8</target.java.version><scala.binary.version>2.12</scala.binary.version><maven.compiler.source>${target.java.version}</maven.compiler.source><maven.compiler.target>${target.java.version}</maven.compiler.target><log4j.version>2.17.1</log4j.version></properties><repositories><repository><id>apache.snapshots</id><name>Apache Development Snapshot Repository</name><url>https://repository.apache.org/content/repositories/snapshots/</url><releases><enabled>false</enabled></releases><snapshots><enabled>true</enabled></snapshots></repository></repositories><dependencies><!-- Apache Flink dependencies --><!-- These dependencies are provided, because they should not be packaged into the JAR file. --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java</artifactId><version>${flink.version}</version>
<!-- <scope>provided</scope>--></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients</artifactId><version>${flink.version}</version>
<!-- <scope>provided</scope>--></dependency><!-- table 环境依赖【connectors 和 formats 和driver】 https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/dev/configuration/overview/ --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-api-java</artifactId><version>${flink.version}</version>
<!-- <scope>provided</scope>--></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-api-java-bridge</artifactId><version>${flink.version}</version>
<!-- <scope>provided</scope>--></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-jdbc</artifactId><version>3.1.0-1.17</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.18</version></dependency><!--idea 运行比西甲这个否则报错:【 Make sure a planner module is on the classpath】--><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-planner-loader</artifactId><version>${flink.version}</version><!-- <scope>provided</scope>--></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-runtime</artifactId><version>${flink.version}</version><!-- <scope>provided</scope>--></dependency><!--第三方的包--><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.83</version></dependency><!-- Add connector dependencies here. They must be in the default scope (compile). --><!-- Example:<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka</artifactId><version>${flink.version}</version></dependency>--><!-- Add logging framework, to produce console output when running in the IDE. --><!-- These dependencies are excluded from the application JAR by default. --><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-slf4j-impl</artifactId><version>${log4j.version}</version><scope>runtime</scope></dependency><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-api</artifactId><version>${log4j.version}</version><scope>runtime</scope></dependency><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-core</artifactId><version>${log4j.version}</version><scope>runtime</scope></dependency></dependencies><build><plugins><!-- Java Compiler --><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.1</version><configuration><source>${target.java.version}</source><target>${target.java.version}</target></configuration></plugin><!-- We use the maven-shade plugin to create a fat jar that contains all necessary dependencies. --><!-- Change the value of <mainClass>...</mainClass> if your program entry point changes. --><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-shade-plugin</artifactId><version>3.1.1</version><executions><!-- Run shade goal on package phase --><execution><phase>package</phase><goals><goal>shade</goal></goals><configuration><createDependencyReducedPom>false</createDependencyReducedPom><artifactSet><excludes><exclude>org.apache.flink:flink-shaded-force-shading</exclude><exclude>com.google.code.findbugs:jsr305</exclude><exclude>org.slf4j:*</exclude><exclude>org.apache.logging.log4j:*</exclude></excludes></artifactSet><filters><filter><!-- Do not copy the signatures in the META-INF folder.Otherwise, this might cause SecurityExceptions when using the JAR. --><artifact>*:*</artifact><excludes><exclude>META-INF/*.SF</exclude><exclude>META-INF/*.DSA</exclude><exclude>META-INF/*.RSA</exclude></excludes></filter></filters><transformers><transformer implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer"/><transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"><mainClass>com.boke.DataStreamJob</mainClass></transformer></transformers></configuration></execution></executions></plugin></plugins><pluginManagement><plugins><!-- This improves the out-of-the-box experience in Eclipse by resolving some warnings. --><plugin><groupId>org.eclipse.m2e</groupId><artifactId>lifecycle-mapping</artifactId><version>1.0.0</version><configuration><lifecycleMappingMetadata><pluginExecutions><pluginExecution><pluginExecutionFilter><groupId>org.apache.maven.plugins</groupId><artifactId>maven-shade-plugin</artifactId><versionRange>[3.1.1,)</versionRange><goals><goal>shade</goal></goals></pluginExecutionFilter><action><ignore/></action></pluginExecution><pluginExecution><pluginExecutionFilter><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><versionRange>[3.1,)</versionRange><goals><goal>testCompile</goal><goal>compile</goal></goals></pluginExecutionFilter><action><ignore/></action></pluginExecution></pluginExecutions></lifecycleMappingMetadata></configuration></plugin></plugins></pluginManagement></build>
</project>核心代码
package com.boke.kafka;
import com.alibaba.fastjson.JSONObject;
public class Student {
public String name;
public Integer age;
public Student(String name, Integer age) {this.name = name;this.age = age;
}public static Student fromJson(String s){JSONObject jsonObject = JSONObject.parseObject(s);String name = jsonObject.getString("name");Integer age = jsonObject.getInteger("age");return new Student(name,age);
}public String getName() {return name;
}public void setName(String name) {this.name = name;
}public Integer getAge() {return age;
}public void setAge(Integer age) {this.age = age;
}
}
//下面是main主函数
package com.boke.kafka;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.typeinfo.TypeHint;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.connector.kafka.source.reader.deserializer.KafkaRecordDeserializationSchema;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.KafkaDeserializationSchema;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import java.nio.charset.StandardCharsets;
public class kafkaSource {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
KafkaSource source = KafkaSource.builder()
.setBootstrapServers(“brokers”)
.setTopics(“input-topic”)
.setGroupId(“my-group”)
.setStartingOffsets(OffsetsInitializer.earliest())//【无论如何都从最早开始消费】
// .setStartingOffsets(OffsetsInitializer.latest())//【无论如何都从最新开始消费】
// .setStartingOffsets(OffsetsInitializer.committedOffsets(OffsetResetStrategy.EARLIEST))//【groupid 存在offset 则从offset消费,否则从最早开始消费】
// .setStartingOffsets(OffsetsInitializer.committedOffsets(OffsetResetStrategy.LATEST))//【groupid 存在offset 则从offset消费,否则从最新开始消费】
// .setDeserializer(KafkaRecordDeserializationSchema.of(new KafkaDeserializationSchemaWrapper<>(new SimpleStringSchema())))
// .setDeserializer(KafkaRecordDeserializationSchema.of(new SimpleStringSchema());
.setDeserializer(KafkaRecordDeserializationSchema.of(new MyKafkaDeserializationSchema()))
// .setDeserializer(KafkaRecordDeserializationSchema.valueOnly())
.build();
env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");
}
}
class MyKafkaDeserializationSchema implements KafkaDeserializationSchema{
@Override
public boolean isEndOfStream(Student nextElement) {return false;
}
//Deserializes the Kafka record.
//Params:
//record – Kafka record to be deserialized.
//Returns:
//The deserialized message as an object (null if the message cannot be deserialized).
@Override
public Student deserialize(ConsumerRecord<byte[], byte[]> record) throws Exception {
/*
*自定义kafka反序列化
*如果数据异常,可以直接返回nulll即可,源码中有一句英文:null if the message cannot be deserialized
* */
String topic = record.topic();
long KafkaTimeStamp = record.timestamp();
int partitionNum = record.partition();
String value = new String(record.value(), StandardCharsets.UTF_8);
return Student.fromJson(value);
}
@Override
public TypeInformation<Student> getProducedType() {return TypeInformation.of(new TypeHint<Student>() {});
}
}
相关文章:

【实战-08】flink 消费kafka自定义序列化
目的 让从kafka消费出来的数据,直接就转换成我们的对象 mvn pom <!-- Licensed to the Apache Software Foundation (ASF) under one or more contributor license agreements. See the NOTICE file distributed with this work for additional information …...

深入浅出 Django 异步编程
随着 Web 应用对性能的要求日益提高,异步编程成为了提升响应速度、提高系统吞吐量的重要手段。Django 作为一个成熟的 Python Web 框架,自 3.1 版本开始支持了异步编程。在本文中,我们将探讨 Django 异步编程的关键概念,并提供实际…...

力扣 138. 随机链表的复制
文章目录 1.解题思路2.代码实现 1.解题思路 在原先链表的每一个元素后面插入一个与前一个相同val的值的结点,然后由于是在原链表进行的操作,因此找每个random就变得很方便直接访问即可,此题目的精髓是cur1->randomp->random->next,看懂这串代码…...

STM32外部中断大问题
问题:一直进入中断,没有触发信号,也一直进入。 描述:开PA0为外部中断,刚刚很好,一个触发信号一个中断,中断函数没有丢,也没有抢跑,开PA1为外部中断也是,都很好…...
FPGA配置采集AR0135工业相机,提供2套工程源码和技术支持
目录 1、前言免责声明 2、AR0135工业相机简介3、我这里已有的 FPGA 图像处理解决方案4、设计思路框架AR0135配置和采集图像缓存视频输出 5、vivado工程1–>Kintex7开发板工程6、vivado工程1–>Zynq7100开发板工程7、上板调试验证8、福利:工程代码的获取 1、前…...
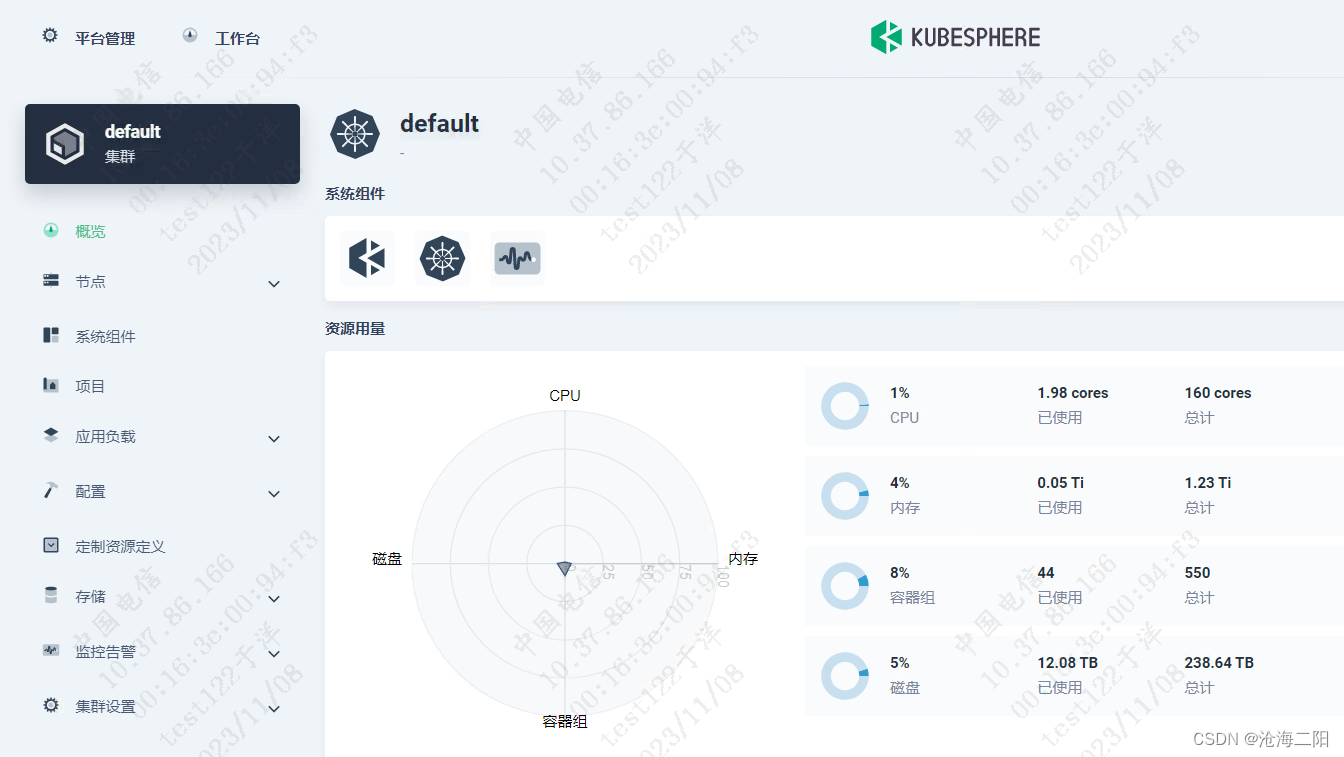
KubeSphere v3.4.0 部署K8S Docker + Prometheus + grafana
KubeSphere v3.4.0 部署K8S 1、整体思路2、修改linux主机名3、 离线安装3.1 问题列表3.2 执行命令成功列表 1、整体思路 将KubeSphere v3.4.0 安装包传输到其中一台机器修改Linux主机名(选取3台,修改为master01、master02、master03)安装官方…...
Codeforces Round 908 (Div. 2)题解
目录 A. Secret Sport 题目分析: B. Two Out of Three 题目分析: C. Anonymous Informant 题目分析: A. Secret Sport 题目分析: A,B一共打n场比赛,输入一个字符串由A和‘B’组成代表A赢或者B赢(无平局),因为题目说明这个人…...
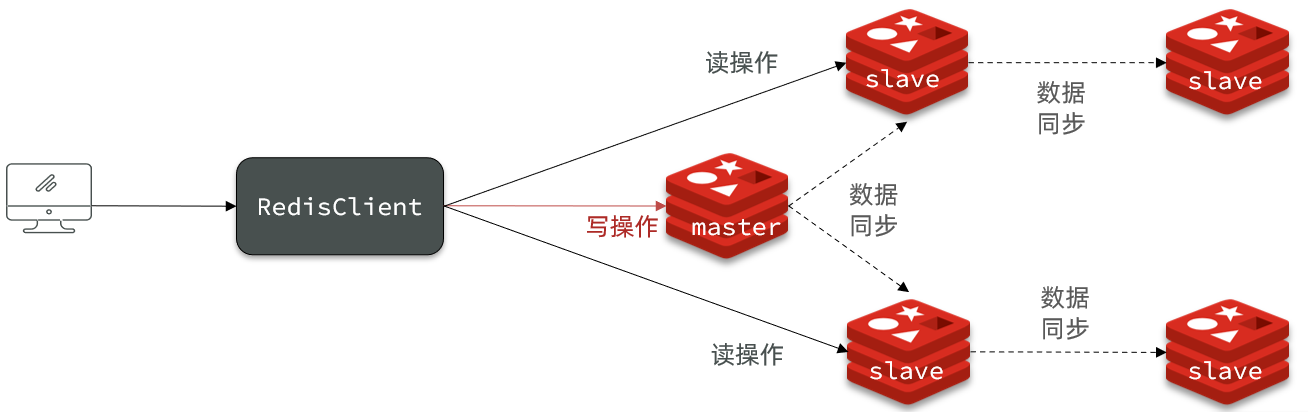
Redis笔记 Redis主从同步
文章目录 Redis主从搭建主从架构主从数据同步原理全量同步增量同步repl_backlog原理 主从同步优化小结 Redis主从 搭建主从架构 单节点Redis的并发能力是有上限的,要进一步提高Redis的并发能力,就需要搭建主从集群,实现读写分离。 主从数据…...
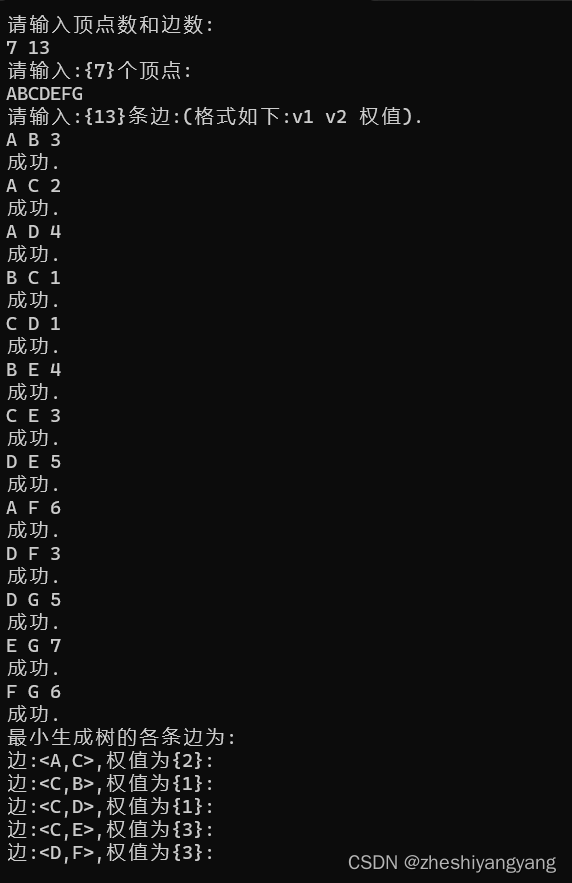
数据结构-Prim算法构造无向图的最小生成树
引子: 无向图如果是一个网,那么它的所有的生成树中必有一颗生成树的边的权值之和是最小的,我们称 这颗权值和最小的树为:“最小生成树”(MST)。 其中,一棵树的代价就是树中所有权值之和。 而…...
MFC串口通信(SerialPort)
目录 1、SerialPort类的介绍和使用: (1)、SerialPort类的功能介绍 (2)、SerialPort类提供接口函数的介绍 1)、InitPort函数 2)、控制串口监视线程函数 3)、获取事件,…...

Vim基本使用操作
前言:作者也是初学Linux,可能总结的还不是很到位 Linux修炼功法:初阶功法 ♈️今日夜电波:美人鱼—林俊杰 0:21━━━━━━️💟──────── 4:14 …...

【深蓝学院】手写VIO第8章--相机与IMU时间戳同步--作业
0. 题目 1. T1 逆深度参数化时的特征匀速模型的重投影误差 参考常鑫助教的答案:思路是将i时刻的观测投到world系,再用j时刻pose和外参投到j时刻camera坐标系下,归一化得到预测的二维坐标(这里忽略了camera的内参,逆深…...

Naocs配置中心配置映射List、Map、Map嵌套List等方式
一、配置映射List 1、常规逐个配置方式,示例如下: 代码: @Data @Configuration @ConfigurationProperties(prefix = "list-json-str") public class ConfListByJsonStr implements Serializable, InitializingBean {@ApiModelProperty("映射结果集")…...

如何通过CRM系统进行销售机会管理?
销售机会管理是在销售过程中对潜在客户的精细化管理,销售机会管理的本质是公司用于管理销售机会通用的工具和方法。对于希望建立长期客户关系的现代销售团队来说,CRM客户管理系统是必不可少的工具。那企业如何通过CRM系统进行销售机会管理? …...

解决idea启动tomcat控制台中文乱码
#1.tomcat日志中文乱码# 如图这种情况,一般在idea用tomcat跑一个web项目启动后tomcat日志在控制台打印出来会出现中文乱码的情况 解决方案1:tomcat的日志配置文件的编码修改,找到tomcat安装目录conf下的logging.properties,encod…...

vscode + cmake + opencv example
nice try on macos CMakeLists.txt cmake_minimum_required(VERSION 3.20) #添加OPENCV库 #指定OpenCV版本,代码如下 #find_package(OpenCV 3.3 REQUIRED) #如果不需要指定OpenCV版本,代码如下 find_package(OpenCV REQUIRED)#添加OpenCV头文件 includ…...

day57【动态规划】647.回文子串 516.最长回文子序列
文章目录 647. 回文子串516.最长回文子序列 647. 回文子串 力扣题目链接 代码随想录讲解 题意:给你一个字符串 s ,请你统计并返回这个字符串中 回文子串 的数目。 回文字符串 是正着读和倒过来读一样的字符串。 子字符串 是字符串中的由连续字符组成的…...

分享vmware和Oracle VM VirtualBox虚拟机的区别,简述哪一个更适合我?
VMware和Oracle VM VirtualBox虚拟机的区别主要体现在以下几个方面: 首先两种软件的安装使用教程如下: 1:VMware ESXI 安装使用教程 2:Oracle VM VirtualBox安装使用教程 商业模式:VMware是一家商业公司,而…...

YOLOV5模型运行
1安装包 如果已经有了torch-cuda环境直接在环境下 pip install -r requirements.txt 2解决报错代码 raise ImportError("Failed to initialize: {0}".format(exc)) from exc ImportError: Failed to initialize: Bad git executable. The git executable must be …...

@Autowired和@Resource注解的区别和联系
直接看原文 原文链接: 【精选】Autowired和Resource注解的区别和联系【精选】 ------------------------------------------------------------------------------------------------------------------------------- 先说联系 联系 Autowired和Resource注解都是作为bean…...

WinToGo玩腻了?试试给你的移动硬盘装个Ubuntu 22.04 LTS吧!支持UEFI启动,VMWare虚拟机安装全流程图文详解
移动硬盘上的Ubuntu 22.04 LTS:超越WinToGo的全新便携体验 如果你已经玩腻了WinToGo,想要尝试一些新鲜事物,那么将Ubuntu 22.04 LTS安装到移动硬盘上绝对是个值得考虑的选择。不同于Windows的便携系统,Linux To Go提供了更轻量、…...

3分钟快速上手:B站m4s视频转换MP4完整教程
3分钟快速上手:B站m4s视频转换MP4完整教程 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 核心关键词:m4s转MP4 长尾关键…...

MPLAB PM3烧录器搭配LabVIEW避坑指南:从驱动安装到‘Operation Succeeded’全流程
MPLAB PM3烧录器与LabVIEW高效联调实战:从零搭建到工业级稳定烧录 1. 硬件连接与驱动配置的隐藏细节 第一次将MPLAB PM3烧录器从包装盒取出时,多数开发者会直接进入软件配置环节,却忽略了物理连接的稳定性往往决定了整个项目的成败。PM3的ICS…...
,仅限首批200家ISV申请下载)
Java 25结构化并发落地清单(含Checklist.xlsx+ByteBuddy增强插件+Prometheus监控埋点模板),仅限首批200家ISV申请下载
更多请点击: https://intelliparadigm.com 第一章:Java 25结构化并发的核心演进与工业适配意义 Java 25正式将结构化并发(Structured Concurrency)从孵化器模块 jdk.incubator.concurrent 提升为标准 API(java.util.…...

Windows 10系统臃肿不堪?这个开源工具让你3步重获清爽体验
Windows 10系统臃肿不堪?这个开源工具让你3步重获清爽体验 【免费下载链接】Win10BloatRemover Configurable CLI tool to easily and aggressively debloat and tweak Windows 10 by removing preinstalled UWP apps, services and more. Originally based on the …...
)
告别预编译包:手把手教你为你的Qt项目定制编译Windows静态库(Qt5.15/6.5 + CMake实战)
从零构建Qt静态库:为商业项目打造极致精简的Windows部署方案 当你的Qt应用程序需要交付给客户时,几十MB的DLL依赖文件往往成为部署的噩梦。想象一下,一个简单的工具软件因为QtCore、QtGui等动态库的拖累,安装包膨胀到上百MB——这…...

STM32定时器PWM输出简单总结
PWM输出 脉冲宽度调制模式可以生成一个信号,该信号频率由TIMx_ARR自动重载寄存器值决定,其占空比则由TIMx_CCRx捕获比较寄存器值决定。 通过向TIMx_CCMRx寄存器中的OCxM位写入110(PWM模式1)或111(PWM模式2)…...

揭秘3140亿参数Grok-1:马斯克AI巨兽的多语言能力技术突破
揭秘3140亿参数Grok-1:马斯克AI巨兽的多语言能力技术突破 【免费下载链接】grok-1 Grok open release 项目地址: https://gitcode.com/GitHub_Trending/gr/grok-1 Grok-1作为一款备受关注的开源AI模型,凭借其3140亿的惊人参数规模,在自…...
)
用YOLOv5和LabelImg从零制作FPS游戏数据集(含自动划分脚本)
从零构建FPS游戏AI训练数据集:YOLOv5与LabelImg实战指南 1. 数据集构建基础认知 在计算机视觉项目中,数据质量往往比算法选择更能决定最终效果。对于FPS游戏场景的目标检测,我们需要捕捉的关键元素通常包括玩家角色、武器、装备等。与传统数据…...

【花雕学编程】Arduino BLDC 之机器人动态权重分配的混合控制器
基于 Arduino 平台结合 BLDC(无刷直流电机)的机器人动态权重分配混合控制器,代表了移动机器人控制策略从“单一目标优化”向“多目标动态平衡”的进阶。该系统不再固守固定的控制参数,而是根据机器人的实时状态(如速度…...