4-爬虫-selenium(等待元素加载、元素操作、操作浏览器执行js、切换选项卡、前进后退异常处理)、xpath、动作链
1 selenium等待元素加载
2 selenium元素操作
3 selenium操作浏览器执行js
4 selenium切换选项卡
5 selenium前进后退异常处理
6 登录cnblogs
7 抽屉半自动点赞
8 xpath
9 动作链
10 自动登录12306
上节回顾
# 1 bs4 解析库---》xml(html)-遍历文档树-属性 文本 标签名-搜索文档树:find find_all-5 种过滤器:字符串,正则,布尔,列表,方法-find(name='字符串',src='正则',class_='布尔',href='列表',text='字符串',方法)-遍历文档树和搜索文档树可以连用find() 结果是:Tag类的对象,BeautifulSoup继承了它结果可以继续 . 也可以继续 find-find的其他参数-limit-recursive-链式调用-小说,图片# 2 css选择器-id选择器-标签选择器-类选择器-属性选择器- 标签- .类- #id- div a- div>asoup.select('css选择器') 可能是多个,放到列表中# 3 selenium :控制浏览器,解决requests不能执行js的问题-浏览器驱动:浏览器版本-pip install selenium-快速使用import timefrom selenium import webdriver# 跟人操作浏览器一样,打开了谷歌浏览器,拿到浏览器对象bro=webdriver.Chrome()# 在地址栏中输入地址bro.get('https://www.baidu.com')time.sleep(5)bro.close() # 关闭当前tab页bro.quit() # 关闭浏览器# 4 模拟登录百度-查找标签# By.ID # 根据id号查找标签# By.NAME # 根据name属性查找标签# By.TAG_NAME # # 根据标签查找标签# By.CLASS_NAME # 按类名找# By.LINK_TEXT # a标签文字# By.PARTIAL_LINK_TEXT # a标签文字,模糊匹配#---------selenium 自己的--------# By.CSS_SELECTOR # 按css选择器找# By.XPATH #按xpath找-操作标签-点击-写文字# 5 无头浏览器-bro.page_source# 6 找到标签-属性-文本-标签名-位置-大小
1 selenium等待元素加载
# 代码操作非常快---》有的标签还没加载---》找就找不到---》就会报错
# 设置等待:显示等待,隐士等待
bro.implicitly_wait(10) # 找某个标签,如果找不到,最多等待10s
2 selenium元素操作
# 点击操作click()# 写文字send_keys("内容")# 清空文字clear()
3 执行js
# 在使用selenium操作浏览器的时候,可以自己写js执行,会用这东西做什么?-创建新的选项卡-打印出一些变量(属于当前爬取的页面中的变量)-获取当前登录的cookie-滑动屏幕
import timefrom selenium import webdriver
from selenium.webdriver.common.by import By
bro = webdriver.Chrome()
bro.get('https://www.pearvideo.com/category_1')
bro.implicitly_wait(10)
bro.maximize_window()
# 1 基本使用
# bro.execute_script('alert("美女")')
# 2 打印出一些变量
# res=bro.execute_script('console.log(urlMap)')
# print(res)# 3 新建选项卡
# bro.execute_script('open()')# 4 滑动屏幕
# bro.execute_script('scrollTo(0,document.documentElement.scrollHeight)')# 5 获取当前访问地址
# bro.execute_script('alert(location)')
# bro.execute_script('location="http://www.baidu.com"')# 6 打印cookie
bro.execute_script('alert(document.cookie)')
time.sleep(10)
bro.close()
4 切换选项卡
from selenium import webdriver
import time
bro = webdriver.Chrome()
bro.get('https://www.pearvideo.com/')
bro.implicitly_wait(10)
print(bro.window_handles)
# 开启选项卡
bro.execute_script('window.open()')
# 获取出所有选项卡bro.switch_to.window(bro.window_handles[1]) # 切换到某个选项卡
bro.get('http://www.taobao.com')time.sleep(2)
bro.switch_to.window(bro.window_handles[0]) # 切换到某个选项卡
bro.get('http://www.baidu.com')time.sleep(2)
bro.execute_script('window.open()')
bro.execute_script('window.open()')
bro.close() # 关闭选项卡
bro.quit() # 关闭页面
5 前进后退异常处理
from selenium import webdriver
import time
bro = webdriver.Chrome()
bro.get('https://www.pearvideo.com/')
bro.implicitly_wait(10)# 获取出所有选项卡
time.sleep(2)
bro.get('http://www.taobao.com')time.sleep(2)bro.get('http://www.baidu.com')
time.sleep(2)
bro.back()
time.sleep(2)
bro.back()
time.sleep(2)
bro.forward()
bro.quit() # 关闭页面
6 登录cnblogs
# 以后要爬取的数据,要登录后才能看到-如果使用selenium,速度慢---》不能开启多线程---》速度不会太快-如果使用requests发送请求,登录不好登录,自动登录不进去--》拿不到cookie-使用selenium登录---》拿到cookie---》换到别的机器,使用这个cookie,依然是登录状态
import timefrom selenium import webdriver
from selenium.webdriver.chrome.options import Options
import json
from selenium.webdriver.common.by import By
# 去掉自动化软件控制的检测
options = Options()
options.add_argument("--disable-blink-features=AutomationControlled") # 去掉自动化控制
bro = webdriver.Chrome(options=options)
# bro = webdriver.Chrome()
########### 纯自动登录#######得到了cookie
bro.get('https://www.cnblogs.com/')
bro.implicitly_wait(10)
bro.maximize_window()
login_btn = bro.find_element(By.LINK_TEXT, '登录')
login_btn.click()time.sleep(2)# 找到用户名和密码输入框
username = bro.find_element(By.CSS_SELECTOR, '#mat-input-0')
password = bro.find_element(By.ID, 'mat-input-1')submit_btn = bro.find_element(By.CSS_SELECTOR,'body > app-root > app-sign-in-layout > div > div > app-sign-in > app-content-container > div > div > div > form > div > button')
# 验证码
code=bro.find_element(By.ID,'rectMask')
time.sleep(1)username.send_keys('@qq.com')
time.sleep(1)
password.send_keys('#')
time.sleep(1)
submit_btn.click() # 一种情况直接登录成功 一种情况会弹出验证码
code.click()
time.sleep(10)# 让程序先停在这---》手动操作浏览器---》把验证码搞好---》程序再继续往下走
# 到现在,是登录成功的状态
# 取出cookie存起来
cookies = bro.get_cookies()
with open('cnblogs.json', 'w', encoding='utf-8') as f:json.dump(cookies, f)time.sleep(2)
bro.close()import timefrom selenium import webdriver
from selenium.webdriver.chrome.options import Options
import json
from selenium.webdriver.common.by import By# 去掉自动化软件控制的检测
options = Options()
options.add_argument("--disable-blink-features=AutomationControlled") # 去掉自动化控制
bro = webdriver.Chrome(options=options)bro.get('https://www.cnblogs.com/')
bro.implicitly_wait(10)
bro.maximize_window()time.sleep(5)
# 取出cookie--》写入到浏览器中---》刷新浏览器---》登录状态
with open('cnblogs.json', 'r') as f:cookies = json.load(f)
# 写到浏览器中
for item in cookies:bro.add_cookie(item) # 如果是没登录的cookie,往里写会报错# 刷新浏览器
bro.refresh()time.sleep(5)
bro.close()7 抽屉半自动点赞
# 使用selenium登录---》拿到cookie
# 点赞 使用requests 用cookie点赞####自动登录---使用selenium####
import json# import time
#
# from selenium import webdriver
# from selenium.webdriver.chrome.options import Options
# import json
# from selenium.webdriver.common.by import By
#
# bro = webdriver.Chrome()
# bro.get('https://dig.chouti.com/')
# bro.implicitly_wait(10)
# bro.maximize_window()
#
# btn_login = bro.find_element(By.ID, 'login_btn')
# time.sleep(1)
# btn_login.click()
# time.sleep(1)
#
# phone = bro.find_element(By.NAME, 'phone')
# password = bro.find_element(By.CSS_SELECTOR,
# 'body > div.login-dialog.dialog.animated2.scaleIn > div > div.login-footer > div.form-item.login-item.clearfix.mt24 > div > input.input.pwd-input.pwd-input-active.pwd-password-input')
#
# submit_login = bro.find_element(By.CSS_SELECTOR,
# 'body > div.login-dialog.dialog.animated2.scaleIn > div > div.login-footer > div:nth-child(4) > button')
#
# phone.send_keys('你的手机号')
# password.send_keys('你的密码')
# time.sleep(2)
# submit_login.click()
#
# input('等你')
#
# cookies = bro.get_cookies()
# with open('chouti.json', 'w', encoding='utf-8') as f:
# json.dump(cookies, f)
#
# time.sleep(2)
# bro.close()#### 使用requests点赞# 访问首页,解析出id号
import requests
from bs4 import BeautifulSoup#### 携带cookie访问#####
session = requests.Session()
cookie = {} # 本地取出来,写入
with open('chouti.json', 'r') as f:cookie_list = json.load(f)
##### selenium的cookie和requests的cookie格式不一样,要转换 {key:value,key:value}
for item in cookie_list:cookie[item['name']] = item['value']
header={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36'}
res = session.get('https://dig.chouti.com/', cookies=cookie,headers=header)
soup = BeautifulSoup(res.text, 'html.parser')print(res.text)divs = soup.find_all(name='div', class_='link-item')
for div in divs:article_id = div.attrs.get('data-id')data = {'linkId': article_id}res1 = session.post('https://dig.chouti.com/link/vote', data=data,headers=header)print(res1.text)8 xpath
# 在 xml中查找元素,解析库-解析库自带的-css选择器-xpath---》通用的---》即为XML路径语言(XML Path Language),它是一种用来确定XML文档中某部分位置的语言# 记住的:nodename 选取此节点的所有子节点。/ 从根节点选取。// 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。. 选取当前节点。.. 选取当前节点的父节点。@ 选取属性。doc = '''
<html><head><base href='http://example.com/' /><title>Example website</title></head><body><div id='images'><a href='image1.html' id='lqz'>Name: My image 1 <br /><img src='image1_thumb.jpg' /></a><a href='image2.html'>Name: My image 2 <br /><img src='image2_thumb.jpg' /></a><a href='image3.html'>Name: My image 3 <br /><img src='image3_thumb.jpg' /></a><a href='image4.html'>Name: My image 4 <br /><img src='image4_thumb.jpg' /></a><a href='image5.html' class='li li-item' name='items'>Name: My image 5 <br /><img src='image5_thumb.jpg' /></a><a href='image6.html' name='items'><span><h5>test</h5></span>Name: My image 6 <br /><img src='image6_thumb.jpg' /></a></div></body>
</html>
'''
from lxml import etreehtml = etree.HTML(doc)
# html=etree.parse('search.html',etree.HTMLParser())
# 1 所有节点
# a=html.xpath('//*')
# 2 指定节点(结果为列表)
# a=html.xpath('//head')
# 3 子节点,子孙节点
# a=html.xpath('//div/a')
# a=html.xpath('//body/a') #无数据
# a=html.xpath('//body//a')
# 4 父节点
# a=html.xpath('//body//a[@href="image1.html"]/..')
# a=html.xpath('//body//a[1]/..')
# 也可以这样
# a=html.xpath('//body//a[1]/parent::*')
# a=html.xpath('//body//a[1]/parent::div')
# 5 属性匹配
# a=html.xpath('//body//a[@href="image1.html"]')# 6 文本获取 /text()
# a=html.xpath('//body//a[@href="image1.html"]/text()')# 7 属性获取 @属性名
# a=html.xpath('//body//a/@href')
# # 注意从1 开始取(不是从0)
# a=html.xpath('//body//a[1]/@href')# 8 属性多值匹配
# a 标签有多个class类,直接匹配就不可以了,需要用contains
# a=html.xpath('//body//a[@class="li"]')
# a=html.xpath('//body//a[contains(@class,"li")]')
# a=html.xpath('//body//a[contains(@class,"li")]/text()')
# 9 多属性匹配
# a=html.xpath('//body//a[contains(@class,"li") or @name="items"]')
# a=html.xpath('//body//a[contains(@class,"li") and @name="items"]/text()')
# a=html.xpath('//body//a[contains(@class,"li")]/text()')
# 10 按序选择
# a=html.xpath('//a[2]/text()')
# a=html.xpath('//a[2]/@href')
# 取最后一个
# a=html.xpath('//a[last()]/@href')
# a=html.xpath('//a[last()-1]/@href') # 倒数第二个
# 位置小于3的
# a = html.xpath('//a[position()<3]/@href')# 倒数第三个
# a=html.xpath('//a[last()-2]/@href')
# 11 节点轴选择
# ancestor:祖先节点
# 使用了* 获取所有祖先节点
# a=html.xpath('//a/ancestor::*')
# # 获取祖先节点中的div
# a=html.xpath('//a/ancestor::div')
# attribute:属性值
# a=html.xpath('//a[1]/attribute::*')
# a=html.xpath('//a[1]/attribute::href')# child:直接子节点
# a=html.xpath('//a[1]/child::*')
# descendant:所有子孙节点
# a=html.xpath('//a[6]/descendant::*')
# following:当前节点之后所有节点
# a=html.xpath('//a[1]/following::*')
# a=html.xpath('//a[1]/following::*[1]/@href')
# following-sibling:当前节点之后同级节点
# a=html.xpath('//a[1]/following-sibling::*')
# a=html.xpath('//a[1]/following-sibling::a')
# a=html.xpath('//a[1]/following-sibling::*[2]')
# a=html.xpath('//a[1]/following-sibling::*[2]/@href')# print(a)'''
/
//
.
..
取文本 /text()
取属性 /@属性名
根据属性过滤 [@属性名=属性值]
class 特殊
[contains(@class,"li")]
'''# 终极大招 直接复制# 案例
import requests
res=requests.get('https://www.w3school.com.cn/xpath/xpath_syntax.asp')
from lxml import etreehtml = etree.HTML(res.text)
# a=html.xpath('//div[@id="intro"]//strong/text()')
# a=html.xpath('/html/body/div/div[4]/div[2]/p/strong')
a=html.xpath('//*[@id="intro"]/p/strong/text()')
print(a)9 动作链
# 模拟鼠标点住,拖动的效果,实现滑块认证# 两种形式-形式一:actions=ActionChains(bro) #拿到动作链对象actions.drag_and_drop(sourse,target) #把动作放到动作链中,准备串行执行actions.perform()-方式二:ActionChains(bro).click_and_hold(sourse).perform()distance=target.location['x']-sourse.location['x']track=0while track < distance:ActionChains(bro).move_by_offset(xoffset=2,yoffset=0).perform()track+=2
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.support.wait import WebDriverWait # 等待页面加载某些元素
import time
from selenium.webdriver.common.by import Bydriver = webdriver.Chrome()
driver.get('http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable')
driver.implicitly_wait(3)
driver.maximize_window()try:driver.switch_to.frame('iframeResult') ##切换到iframeResultsourse = driver.find_element(By.ID, 'draggable')target = driver.find_element(By.ID, 'droppable')# 方式一:基于同一个动作链串行执行# actions = ActionChains(driver) # 拿到动作链对象# actions.drag_and_drop(sourse, target) # 把动作放到动作链中,准备串行执行# actions.perform()# 方式二:不同的动作链,每次移动的位移都不同ActionChains(driver).click_and_hold(sourse).perform() # 鼠标点中源 标签 不松开distance=target.location['x']-sourse.location['x']track = 0while track < distance:ActionChains(driver).move_by_offset(xoffset=2, yoffset=0).perform()track += 2ActionChains(driver).release().perform()time.sleep(10)finally:driver.close()10 自动登录12306
import time
from selenium.webdriver import ActionChains
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
# 12306检测到咱们用了自动化测试软件,
options = Options()
options.add_argument("--disable-blink-features=AutomationControlled") # 去掉自动化控制
bro = webdriver.Chrome(chrome_options=options)
bro.get('https://kyfw.12306.cn/otn/resources/login.html')
bro.implicitly_wait(5)
bro.maximize_window()
user_login = bro.find_element(By.CSS_SELECTOR,'#toolbar_Div > div.login-panel > div.login-box > ul > li.login-hd-code.active > a')user_login.click()
time.sleep(1)username = bro.find_element(By.ID, 'J-userName')
password = bro.find_element(By.ID, 'J-password')
submit_btn = bro.find_element(By.ID, 'J-login')
username.send_keys('18953675221')
password.send_keys('')
time.sleep(3)
submit_btn.click()time.sleep(5)# 找到滑块
span = bro.find_element(By.ID, 'nc_1_n1z')
ActionChains(bro).click_and_hold(span).perform()
ActionChains(bro).move_by_offset(xoffset=300, yoffset=0).perform()
ActionChains(bro).release().perform()
time.sleep(5)bro.close()相关文章:
、xpath、动作链)
4-爬虫-selenium(等待元素加载、元素操作、操作浏览器执行js、切换选项卡、前进后退异常处理)、xpath、动作链
1 selenium等待元素加载 2 selenium元素操作 3 selenium操作浏览器执行js 4 selenium切换选项卡 5 selenium前进后退异常处理 6 登录cnblogs 7 抽屉半自动点赞 8 xpath 9 动作链 10 自动登录12306 上节回顾 # 1 bs4 解析库---》xml(html)-遍历文档树-属性 文本 标签名-搜索文…...
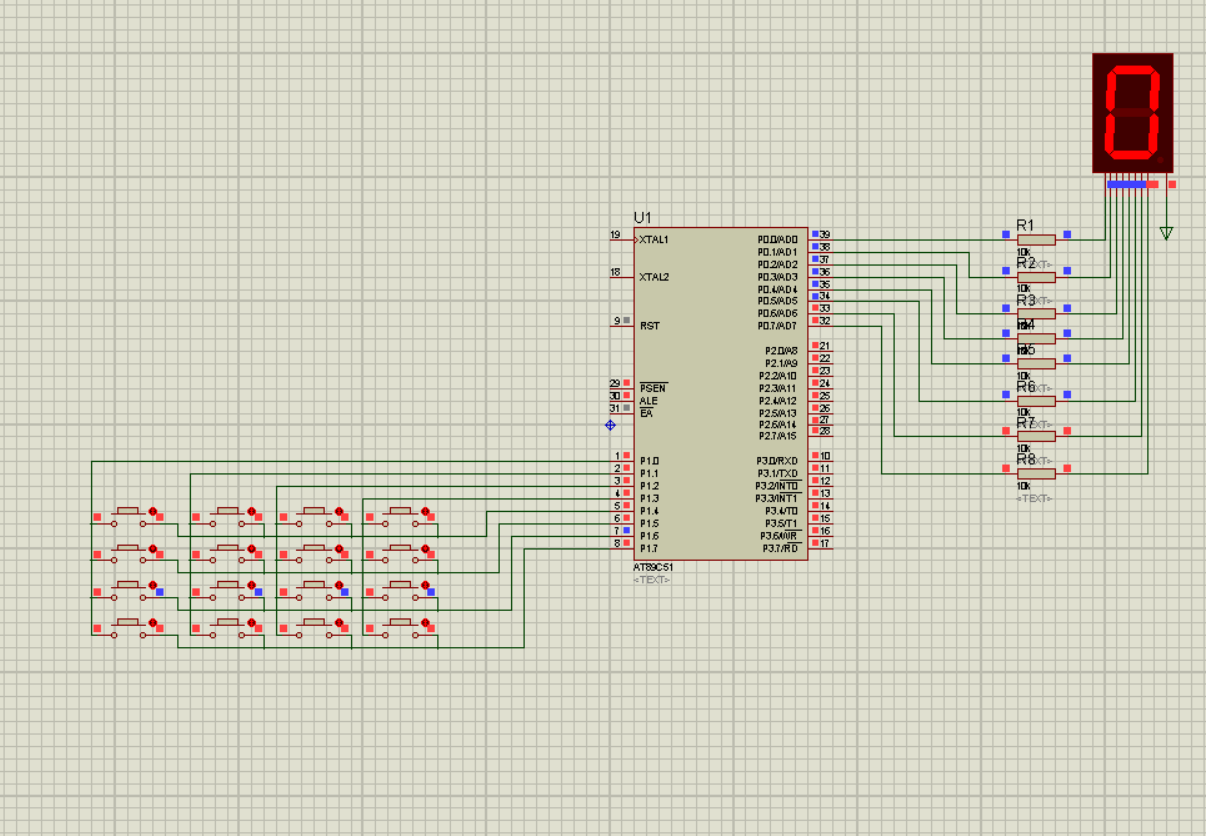
矩阵键盘独立接口设计(Keil+Proteus)
前言 实验:通过4*4的矩阵键盘,按下某个按钮之后会在数码管上面显示对应的键号。(0~F) 基础操作参考这篇博客: LED数码管的静态显示与动态显示(KeilProteus)-CSDN博客https://blog.csdn.net/w…...

国产猫罐头可以作为长期主食吗?口碑好的顶级猫罐头推荐
我一直在分析和尝试国产猫罐头,我家猫已经吃了几十款了。今天,我想和大家分享一些关于国产猫罐头的经验和心得。 近年来,国产宠粮市场呈现出爆发趋势,各个猫粮商在配方、营养数据和包装上展开了激烈的角逐,无一不让我…...

大数据毕业设计选题推荐-营业厅营业效能监控平台-Hadoop-Spark-Hive
✨作者主页:IT毕设梦工厂✨ 个人简介:曾从事计算机专业培训教学,擅长Java、Python、微信小程序、Golang、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。 ☑文末获取源码☑ 精彩专栏推荐⬇⬇⬇ Java项目 Py…...

CSS的Grid布局与Flex布局
Grid布局 Grid布局是一种CSS布局模式,它使用一个二维的网格系统来定位元素。它允许您将容器分为行和列,然后将元素放置在特定的行和列中。Grid布局非常适合创建复杂的网页布局和对齐元素。 以下是grid布局的基本语法: .container { displ…...
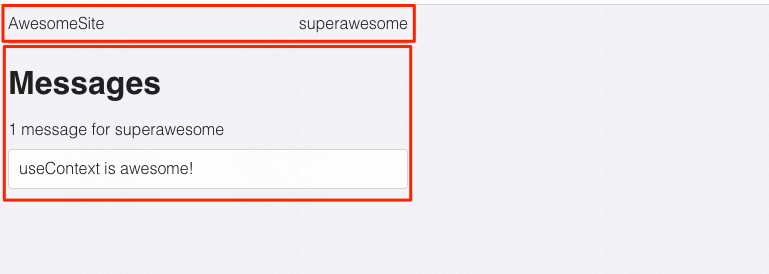
常见React Hooks 钩子函数用法
一、useState useState()用于为函数组件引入状态(state)。纯函数不能有状态,所以把状态放在钩子里面。 import React, { useState } from react import ./Button.cssexport function UseStateWithoutFunc() {const [name, setName] useStat…...
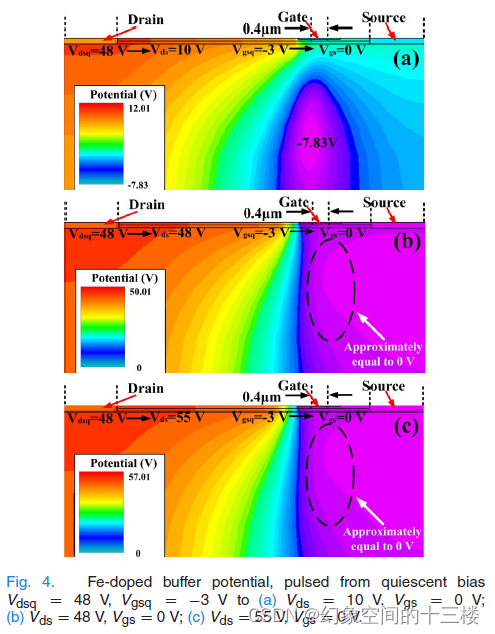
AlGaN/GaN HEMT 中缓冲区相关电流崩溃的缓冲区电位模拟表征
标题:Characterization of Buffer-Related Current Collapse by Buffer Potential Simulation in AlGaN/GaN HEMTs 来源:IEEE TRANSACTIONS ON ELECTRON DEVICES (18年) 摘要 - 在本文中,通过使用脉冲 I-V 测量和二维漂移扩散模拟研究了 Al…...
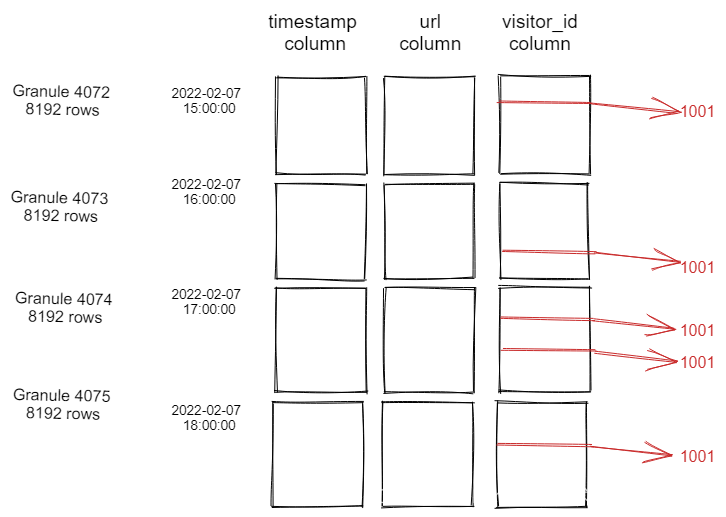
深入理解ClickHouse跳数索引
一、跳数索引 影响ClickHouse查询性能的因素很多。在大多数场景中,关键因素是ClickHouse在计算查询WHERE子句条件时是否可以使用主键。因此,选择适用于最常见查询模式的主键对于表的设计至关重要。 然而,无论如何仔细地调优主键ÿ…...

ElasticSearch中实际操作细节点
ElasticSearch中的细节点 文章目录 ElasticSearch中的细节点1、提示:1.1 ElasticSearch相关文档:1.2 Kibana的常用快捷键1.3 kibana的注释方式 2、term与terms的用法以及区别3、ElasticSearch中"index":"false","doc_values&qu…...

VCG 获取指定面片与顶点的索引
文章目录 一、介绍二、实现代码三、实现效果参考资料一、介绍 VCG Lib存在许多中方式对Mesh数据进行编码,其中最为常用的为顶点+三角形(比如三角形网格以及四面体网格)。VCG关于Mesh的定义如下所示: vcg::tri::TriMesh 包含顶点的容器类型(通常是std::vector),具体的顶点…...
开发知识点-Django
Django 1 了解简介2 Django项目结构3 url 地址 和视图函数4 路由配置5 请求及响应6 GET请求和POST请求查询字符串 7 Django设计模式及模板层8 模板层-变量和标签9 模板层-过滤器和继承继承 重写 10 url反向解析11 静态文件12 Django 应用及分布式路由创建之后 注册 一下 13 模型…...

Linux系统笔记参考
Linux系统笔记 一、基本命令 1、简单的几个命令 ls:显示指定目录下的文件目录清单(list) cd:切换目录,改变当前的工作目录(change directory) cd ~ 或 cd 切换到用户主目录(用户家…...

AI:62-基于深度学习的人体CT影像肺癌的识别与分类
🚀 本文选自专栏:AI领域专栏 从基础到实践,深入了解算法、案例和最新趋势。无论你是初学者还是经验丰富的数据科学家,通过案例和项目实践,掌握核心概念和实用技能。每篇案例都包含代码实例,详细讲解供大家学习。 📌📌📌在这个漫长的过程,中途遇到了不少问题,但是…...
数字孪生智慧工厂3D无代码编辑工具提供强大、简单功能
相比传统的2D/2.5D,3d可视化场景脱颖而出,成为更多行业的首选,然而传统的3D可视化场景制作需要花费大量的人力财力及周期来创建复杂的3D模型和场景,对很多企业及个人来说是个挑战,3D可视化场景编辑器通过简单的拖拉拽&…...

python 为什么这么受欢迎?python的优势到底在哪里?
常言道:“流水的语言,铁打的Python”,目前它可以说是已经"睥睨天下,傲视群雄"了。它天生丽质,易于读写,非常实用,从而赢得了广泛的群众基础,被誉为"宇宙最好的编程语言"&am…...

Flutter转换png图片为jpg图片
1.需求 在xxx产品需求中,需要将png图片转为jpg图片。 2.引用库 image: ^4.1.3 Dart图像库提供了以各种图像文件格式加载、保存和操作图像的功能。 该库可以与dart:io和dart:html一起用于命令行、Flutter和web应用程序。 注:4.0是该库先前版本的主要修订…...

c++ grpc 第一个用例
一、linux 包管理工具安装 sudo apt-get update sudo apt-get install -y build-essential autoconf libtool pkg-config cmake sudo apt-get install -y libgflags-dev libgtest-dev sudo apt-get install -y clang libc-dev# 安装 gRPC C 相关依赖 sudo apt-get install -y …...
pandas笔记:读写excel
1 读excel read_excel函数能够读取的格式包含:xls, xlsx, xlsm, xlsb, odf, ods 和 odt 文件扩展名。 支持读取单一sheet或几个sheet。 1.0 使用的数据 1.1 主要使用方法 pandas.read_excel(io, sheet_name0, header0, namesNone, index_colNone, usecolsNon…...

【ES分词】
分词 #测试分词器 POST /_analyze {"text": "小米手机和华为手机都是国产mobilephone", "analyzer": "english" }不管analyzer是改成:standard还是chinese都无法实现中文分词。 处理中文分词一般采用IK分词器 安装链接&…...

Git设置显示中文
git config --global i18n.comitencoding utf-8 git config --global i18n.logoutputencoding utf-8 export LESSCHARSETutf-8...
车辆移动建模与功率调节)
手把手教你学Simulink——基于Simulink的动态无线充电(DWPT)车辆移动建模与功率调节
目录 手把手教你学Simulink ——基于Simulink的动态无线充电(DWPT)车辆移动建模与功率调节 一、引言:让电动汽车“边跑边充” 二、DWPT系统架构与关键问题 1. 系统组成 2. 核心挑战分析 三、车辆移动建模(Simulink实现&…...
)
超越G代码:深入LinuxCNC的HAL层,像搭积木一样自定义你的数控逻辑(附Python联动案例)
超越G代码:深入LinuxCNC的HAL层,像搭积木一样自定义你的数控逻辑(附Python联动案例) 当大多数CNC开发者还在G代码的海洋中挣扎时,少数先行者已经发现了LinuxCNC中隐藏的"魔法工具箱"——硬件抽象层(HAL)。这…...

Raspberry Pi Zero 2 W功耗优化与测试指南
1. Raspberry Pi Zero 2 W功耗深度测试:从满载到极致优化的完整指南 作为一名长期使用树莓派进行嵌入式开发的工程师,我一直对低功耗优化有着浓厚的兴趣。最近拿到Raspberry Pi Zero 2 W后,我决定系统地测试它的功耗表现,并探索各…...

全能纯净影音播放器,通吃所有格式——PotPlayer
文章目录全能纯净影音播放器,通吃所有格式——PotPlayer核心定位官方安全下载渠道极简安装与基础配置(一步到位)1. 安装2.以下是我的常用配置推荐,按需使用核心功能全流程实操高频刚需应用场景全能纯净影音播放器,通吃…...

[Rust][ARM64] 七、中断处理与异常向量表
系列进度 第六篇:MMU 与页表 第七篇(本文):中断处理与异常向量表 第八篇:加载下一阶段(SD 卡 + jump_to) AArch64 异常模型 AArch64 把所有"打断正常执行流"的事件统称为异常(Exception),分四类: 类型 说明 例子 同步异常 执行指令时产生,立即触发 缺页…...

ESM-2与持久同调结合的蛋白质复合物聚类方法
1. 项目概述 在生物信息学和计算生物学领域,蛋白质结构分析一直是个极具挑战性的课题。最近我在研究如何将持久同调(Persistent Homology)与蛋白质语言模型ESM-2结合,开发了一套高效的蛋白质复合物聚类方法。这套方法的核心创新点…...

手机电池寿命翻倍秘诀:BatteryChargeLimit智能充电限制器
手机电池寿命翻倍秘诀:BatteryChargeLimit智能充电限制器 【免费下载链接】BatteryChargeLimit 项目地址: https://gitcode.com/gh_mirrors/ba/BatteryChargeLimit 你是否曾为手机电池一年后续航大幅下降而烦恼?是否担心整夜充电会损伤电池健康&…...

ADAS功能测试:ACC/AEB/LKA验证方法
🎯 ADAS功能测试:ACC/AEB/LKA验证方法> 系统讲解高级驾驶辅助系统(ADAS)的功能测试方法,包括自适应巡航、自动紧急制动、车道保持等。—## 一、ADAS概述### 1.1 ADAS定义ADAS(Advanced Driver Assistanc…...

量子误差缓解中的线性回归与Lasso优化原理
1. 量子误差缓解中的线性回归与Lasso优化原理量子计算中的误差主要来源于量子比特与环境相互作用导致的退相干、门操作误差以及测量误差。量子误差缓解(Quantum Error Mitigation, QEM)技术通过后处理方式修正这些误差,而非量子纠错ÿ…...

Docker AI Toolkit 2026配置仅需117秒?实测Kubernetes Operator集成、Wasm边缘推理支持与CI/CD流水线嵌入全流程
更多请点击: https://intelliparadigm.com 第一章:Docker AI Toolkit 2026核心特性概览与版本演进分析 Docker AI Toolkit 2026 是 Docker 官方联合 PyTorch、ONNX Runtime 与 Hugging Face 社区推出的首个面向生产级 AI 工作流的原生容器化工具套件。它…...