Flink 基础 -- 应用开发(项目配置)
1、概述
本节中的指南将向您展示如何通过流行的构建工具(Maven, Gradle)配置项目,添加必要的依赖项(即连接器和格式,测试),并涵盖一些高级配置主题。
每个Flink应用程序都依赖于一组Flink库。至少,应用程序依赖于Flink api,此外,还依赖于某些连接器库(如Kafka, Cassandra)和第三方依赖,用户需要开发自定义函数来处理数据。
1.1 开始进行
要开始使用Flink应用程序,请使用以下命令、脚本和模板来创建Flink项目。
Maven
您可以使用下面的Maven命令基于 Archetype创建一个项目,或者使用提供的快速入门bash脚本。
所有Flink Scala api都已弃用,并将在未来的Flink版本中删除。您仍然可以在Scala中构建应用程序,但是应该使用Java版本的DataStream和/或Table API。
See FLIP-265 Deprecate and remove Scala API support
Maven command
$ mvn archetype:generate \-DarchetypeGroupId=org.apache.flink \-DarchetypeArtifactId=flink-quickstart-java \-DarchetypeVersion=1.18.0
这允许您命名新创建的项目,并将交互地询问您的groupId、artifactId和包名。
Quickstart script
$ curl https://flink.apache.org/q/quickstart.sh | bash -s 1.18.0
1.2 您需要哪些依赖项?
要开始处理Flink作业,通常需要以下依赖项:
- Flink APIs,以开发您的工作
- 连接器和格式,以便将您的作业与外部系统集成
- 测试实用程序,以测试您的工作
除此之外,您可能还需要添加开发自定义功能所需的第三方依赖项。
1.3 Flink APIs
Flink提供了两个主要的API:数据流API和表API & SQL。它们可以单独使用,也可以混合使用,这取决于你的用例:
| 想要使用的APIs | 需要添加的依赖项 |
|---|---|
| DataStream | flink-streaming-java |
| DataStream with Scala | flink-streaming-scala_2.12 |
| Table API | flink-table-api-java |
| Table API with Scala | flink-table-api-scala_2.12 |
| Table API + DataStream | flink-table-api-java-bridge |
| Table API + DataStream with Scala | flink-table-api-scala-bridge_2.12 |
1.3 运行和打包
如果您希望通过简单地执行主类来运行作业,则需要在类路径中使用flink-clients。对于Table API程序,您还需要flink-table-runtime和flink-table-planner-loader。
根据经验,我们建议将应用程序代码及其所需的所有依赖项打包到一个fat/uber JAR中。这包括作业的打包连接器、格式和第三方依赖项。此规则不适用于 Java APIs、DataStream Scala api和前面提到的运行时模块,这些模块已经由Flink自己提供,不应该包含在job uber JAR中。这个作业JAR可以提交到已经运行的Flink集群,或者添加到Flink应用程序容器映像中,而无需修改发行版。
1.4 What’s next?
- 要开始开发您的工作,请查看数据流API和表API & SQL。
- 有关如何根据构建工具打包作业的详细信息,请查看以下特定指南
Maven
Gradle - 有关项目配置的更高级主题,请查看高级主题部分。
2、如何使用Maven来配置您的项目
本指南将向您展示如何使用Maven配置Flink作业项目(Flink job project),Maven是由Apache Software Foundation开发的开源构建自动化工具,使您能够构建、发布和部署项目。您可以使用它来管理软件项目的整个生命周期。
2.1 要求
- Maven 3.8.6 (recommended or higher)
- Java 8 (deprecated) or Java 11
2.2 将项目导入到IDE中
一旦创建了项目文件夹和文件,我们建议您将该项目导入到IDE中进行开发和测试。
IntelliJ IDEA支持开箱即用的Maven项目。Eclipse提供了m2e插件来导入Maven项目。
注意:对于Flink来说,Java的默认JVM堆大小可能太小,您必须手动增加它。在Eclipse中,选择“Run Configurations -> Arguments”,在“VM Arguments”中输入“-Xmx800m”。在IntelliJ IDEA中,建议从Help |编辑自定义虚拟机选项菜单中更改JVM选项。有关详细信息,请参阅本文。
关于IntelliJ的注意事项:要使应用程序在IntelliJ IDEA中运行,必须在运行配置中勾选Include dependencies with "Provided" scope框。如果这个选项不可用(可能是由于使用较旧的IntelliJ IDEA版本),那么一个变通方法是创建一个调用应用程序的main()方法的测试。
2.3 构建项目
如果你想构建/打包你的项目,导航到你的项目目录并运行mvn clean package’ 命令。您将在这里找到一个JAR文件,其中包含您的应用程序(以及您可能作为依赖项添加到应用程序中的连接器和库):target/<artifact-id>-<version>.jar
注意:如果您使用与DataStreamJob不同的类作为应用程序的主类/入口点,我们建议您相应地更改pom.xml文件中的mainClass设置,以便Flink可以从JAR文件运行应用程序,而无需额外指定主类。
2.4 向项目添加依赖项
在项目目录中打开pom.xml文件,并在dependencies 选项卡之间添加依赖项
例如,你可以像这样添加Kafka连接器作为依赖项:
<dependencies><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka</artifactId><version>1.18.0</version></dependency></dependencies>
然后在命令行上执行mvn install。
从Java Project Template、 Scala Project Template或Gradle创建的项目被配置为在运行mvn clean package时自动将应用程序依赖项包含到应用程序JAR中。对于没有从这些模板中设置的项目,我们建议添加Maven Shade Plugin来构建包含所有必需依赖项的应用程序jar。
重要:请注意,所有这些核心API依赖项都应该将它们的作用域设置为 provided。这意味着需要对它们进行编译,但是不应该将它们打包到项目的最终应用程序JAR文件中。如果没有设置为provided,最好的情况是最终的JAR变得过大,因为它还包含所有Flink核心依赖项。最坏的情况是,添加到应用程序JAR文件中的Flink核心依赖项与您自己的一些依赖项版本发生冲突(通常可以通过反向类加载来避免这种情况)。
要正确地将依赖项打包到应用程序JAR中,必须将Flink API依赖项设置为compile 范围。
2.5 打包应用程序
根据您的用例,在将Flink应用程序部署到Flink环境之前,可能需要以不同的方式对其进行打包。
如果你想为Flink Job创建一个JAR,并且只使用Flink依赖关系而不使用任何第三方依赖关系(即使用JSON格式的文件系统连接器),你不需要创建一个uber/fat JAR或遮挡任何依赖关系。
如果您想为Flink Job创建一个JAR,并使用Flink发行版中没有内置的外部依赖项,您可以将它们添加到发行版的类路径中,或者将它们隐藏到您的uber/fat应用程序JAR中。
有了生成的uber/fat JAR,你可以通过以下命令将其提交到本地或远程集群:
bin/flink run -c org.example.MyJob myFatJar.jar
要了解有关如何部署Flink作业的详细信息,请查看部署指南。
2.6 用于创建带有依赖项的uber/fat JAR的模板
要构建一个包含声明的连接器和库所需的所有依赖项的应用程序JAR,您可以使用以下插件定义:
<build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-shade-plugin</artifactId><version>3.1.1</version><executions><execution><phase>package</phase><goals><goal>shade</goal></goals><configuration><artifactSet><excludes><exclude>com.google.code.findbugs:jsr305</exclude></excludes></artifactSet><filters><filter><!-- Do not copy the signatures in the META-INF folder.Otherwise, this might cause SecurityExceptions when using the JAR. --><artifact>*:*</artifact><excludes><exclude>META-INF/*.SF</exclude><exclude>META-INF/*.DSA</exclude><exclude>META-INF/*.RSA</exclude></excludes></filter></filters><transformers><transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"><!-- Replace this with the main class of your job --><mainClass>my.programs.main.clazz</mainClass></transformer><transformer implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer"/></transformers></configuration></execution></executions></plugin></plugins>
</build>
默认情况下,Maven阴影插件将包括runtime 和compile范围内的所有依赖项。
3、连接器和格式
Flink应用程序可以通过连接器读取和写入各种外部系统。它支持多种格式,以便编码和解码数据以匹配Flink的数据结构。
数据流和Table API/SQL的可用连接器和格式概述。
3.1 Available artifacts
为了使用连接器和格式,您需要确保Flink能够访问实现它们的构件。对于Flink社区支持的每个连接器,我们在Maven Central上发布两个工件:
flink-connector-<NAME>它是一个瘦JAR,只包括连接器代码,但不包括最终的第三方依赖flink-sql-connector-<NAME>它是一个超级JAR,可以与所有连接器第三方依赖项一起使用
这同样适用于格式(formats)。注意,有些连接器可能没有相应的flink-sql-connector-<NAME>构件,因为它们不需要第三方依赖项。
uber/fat jar主要用于与SQL客户端一起使用,但您也可以在任何数据流/表应用程序中使用它们。
3.2 Using artifacts
为了使用连接器/格式模块,你可以:
- 在您的作业JAR中为瘦JAR及其传递依赖项 Shade
- 在你的工作JAR中添加超级JAR
- 将uber JAR直接拷贝到Flink发行版的
/lib文件夹中
对于shading 依赖,请查看特定的Maven和Gradle指南。有关Flink分布的参考,请查看Flink分布的解剖。
决定是shade uber JAR、瘦JAR还是仅仅在发行版中包含依赖取决于您和您的用例。如果您为依赖项添加阴影,您将对作业JAR中的依赖项版本有更多的控制。在对瘦JAR进行shade 的情况下,您将对传递依赖项有更多的控制,因为您可以在不更改连接器版本的情况下更改版本(允许二进制兼容性)。如果在Flink分发
/lib文件夹中直接嵌入连接器uber JAR,您将能够在一个地方控制所有作业的连接器版本。
4、测试依赖
Flink提供了用于测试作业的实用程序,您可以将其添加为依赖项。
4.1 DataStream API Testing
如果要为使用DataStream API构建的作业开发测试,则需要添加以下依赖项:
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-test-utils</artifactId><version>1.18.0</version><scope>test</scope>
</dependency>
在各种测试实用程序中,该模块提供了MiniCluster,这是一个轻量级的可配置Flink集群,可在JUnit测试中运行,可以直接执行作业。
有关如何使用这些实用程序的更多信息,请参阅DataStream API测试一节
4.2 Table API Testing
如果你想在IDE中本地测试Table API & SQL程序,除了前面提到的flink-test-utils之外,你可以添加以下依赖项:
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-test-utils</artifactId><version>1.18.0</version><scope>test</scope>
</dependency>
这将自动引入查询规划器和运行时,它们分别用于规划和执行查询。
Flink -table-test-utils模块已在Flink 1.15中引入,被认为是实验性的。
5、高级配置主题
5.1 Flink分布的解剖
Flink本身由一组类和依赖项组成,这些类和依赖项构成了Flink运行时的核心,并且在启动Flink应用程序时必须出现。运行系统所需的类和依赖关系处理诸如协调、网络、检查点、故障转移、api、操作符(如窗口)、资源管理等领域。
这些核心类和依赖项被打包在flink-dist.jar中,它可以在下载的发行版的/lib文件夹中获得,并且是基本Flink容器映像的一部分。您可以将这些依赖关系看作类似于Java的核心库,其中包含String和List之类的类。
为了保持核心依赖尽可能小并避免依赖冲突,Flink核心依赖不包含任何连接器或库(即CEP, SQL, ML),以避免在类路径中有过多的默认类和依赖。
Flink发行版的/lib目录还包含各种jar,其中包括常用模块,例如执行Table作业所需的所有模块以及一组连接器和格式。这些是默认加载的,可以通过从/lib文件夹中删除它们来从类路径中删除。
Flink还在/opt文件夹下提供了额外的可选依赖项,这可以通过移动/lib文件夹中的jar来启用。
有关类加载的更多信息,请参阅Flink中的类加载一节。
5.2 Scala版本
不同的Scala版本之间不是二进制兼容的。所有(传递地)依赖于Scala的Flink依赖都以其构建的Scala版本为后缀(例如:flink-streaming-scala_2.12)。
如果你只使用Flink的Java api,你可以使用任何Scala版本。如果您正在使用Flink的Scala api,则需要选择与应用程序的Scala版本匹配的Scala版本。
有关如何为特定的Scala版本构建Flink的详细信息,请参阅构建指南。
2.12.8之后的Scala版本与之前的2.12.x 版本不兼容。这将阻止Flink项目升级其2.12.X版本在2.12.8之后。您可以按照构建指南在本地为以后的Scala版本构建Flink。为此,您需要添加-Djapicmp.skip在构建时跳过二进制兼容性检查。
5.3 表依赖剖析
Flink发行版默认包含执行Flink SQL作业所需的jar(在/lib文件夹中),特别是:
- flink-table-api-java-uber-1.18.0.jar → contains all the Java APIs
- flink-table-runtime-1.18.0.jar → contains the table runtime
- flink-table-planner-loader-1.18.0.jar → contains the query planner
以前,这些jar都打包到flink-table.jar中。从Flink 1.15开始,为了允许用户将
flink-table-planner-loader-1.18.0.jar与flink-table-planner_2.12-1.18.0.jar交换,这个文件现在被分成三个jar。
虽然 Table Java API构件内置于发行版中,但默认情况下不包括表Scala API构件。当使用Flink Scala API的格式和连接器时,您需要手动下载并将这些JAR包含在distribution /lib文件夹中(推荐),或者将它们打包为Flink SQL作业的uber/fat JAR中的依赖项。
有关更多详细信息,请查看如何连接到外部系统。
Table Planner and Table Planner Loader
从Flink 1.15开始,该分布包含两个规划器:
flink-table-planner_2.12-1.18.0.jar, in/opt, contains the query planner- flink-table-planner-loader-1.18.0.jar, loaded by default in
/lib,contains the query planner hidden behind an isolated classpath (you won’t be able to address anyio.apache.flink.table.plannerdirectly)
这两个规划器jar包含相同的代码,但是它们的打包不同。在第一种情况下,必须使用相同的Scala版本的JAR。在第二种情况下,您不需要考虑Scala,因为它隐藏在JAR中。
默认情况下,发行版使用flink-table-planner-loader。如果需要访问和使用查询规划器的内部,可以交换jar(在distribution /lib文件夹中复制并粘贴flink-table-planner_2.12.jar)。请注意,您将被限制使用您正在使用的Flink发行版的Scala版本。
这两个计划器不能同时存在于类路径中。如果将它们都加载到
/lib中,则表作业将失败。
在即将到来的Flink版本中,我们将停止在Flink发行版中发布
flink-table-planner_2.12工件。我们强烈建议迁移作业和自定义连接器/格式以使用API模块,而不依赖于规划器内部。如果您需要来自计划器的一些功能,这些功能目前没有通过API模块公开,请打开一个票证以便与社区讨论。
5.4 Hadoop的依赖性
一般规则:没有必要将Hadoop依赖项直接添加到应用程序中。如果你想在Hadoop中使用Flink,你需要有一个包含Hadoop依赖项的Flink设置,而不是将Hadoop作为一个应用程序依赖项添加。换句话说,Hadoop必须依赖于Flink系统本身,而不是包含应用程序的用户代码。Flink将使用由HADOOP_CLASSPATH环境变量指定的Hadoop依赖项,可以这样设置:
export HADOOP_CLASSPATH=`hadoop classpath`
这种设计有两个主要原因:
- 一些Hadoop交互发生在Flink的核心,可能在用户应用程序启动之前。其中包括为检查点设置HDFS,通过Hadoop的Kerberos令牌进行身份验证,或者部署在YARN上。
- Flink的反向类加载方法从核心依赖项中隐藏了许多传递依赖项。这不仅适用于Flink自己的核心依赖,也适用于安装过程中出现的Hadoop依赖。这样,应用程序就可以使用相同依赖项的不同版本,而不会遇到依赖冲突。当依赖树变得非常大时,这非常有用。
如果你在IDE中开发或测试时需要Hadoop依赖项(例如,HDFS访问),你应该将这些依赖项配置为类似于依赖项的范围(例如,test 或provided)。
相关文章:
)
Flink 基础 -- 应用开发(项目配置)
1、概述 本节中的指南将向您展示如何通过流行的构建工具(Maven, Gradle)配置项目,添加必要的依赖项(即连接器和格式,测试),并涵盖一些高级配置主题。 每个Flink应用程序都依赖于一组Flink库。至少,应用程序依赖于Flink api&…...

空间曲面@常见曲面方程
文章目录 曲面的基本问题特殊曲面球面方程球的标准形方程一般形方程例 柱面柱面方程不同维度下同方程的图形常见柱面方程 旋转曲面旋转曲面的方程旋转情况分类以yOz上的曲线绕 z z z轴旋转为例 旋转曲面的方程常见旋转曲面方程 锥面其他曲面 曲面的基本问题 根据曲面(点的几何…...

unity 接收和发送Udp消息
因为需要用到unity和其他的程序交互,其他程序可以提供Udp消息,因此找了合适的相互连接方法。这里直接上代码。 工具类: using System; using System.Collections; using System.Collections.Generic; using System.IO; using System.Net; u…...

机器学习股票大数据量化分析与预测系统 - python 计算机竞赛
文章目录 0 前言1 课题背景2 实现效果UI界面设计web预测界面RSRS选股界面 3 软件架构4 工具介绍Flask框架MySQL数据库LSTM 5 最后 0 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 机器学习股票大数据量化分析与预测系统 该项目较为新颖&am…...
)
架构描述语言(ADL)
1.架构描述语言(ADL) 架构描述语言(Architecture Description Language, ADL)是一种为明确说明软件系统的概念架构和对这些概念架构建模提供功能的语言。 2.ADL基本构成要素 ADL即架构描述语言,其基本构成要素包括:…...
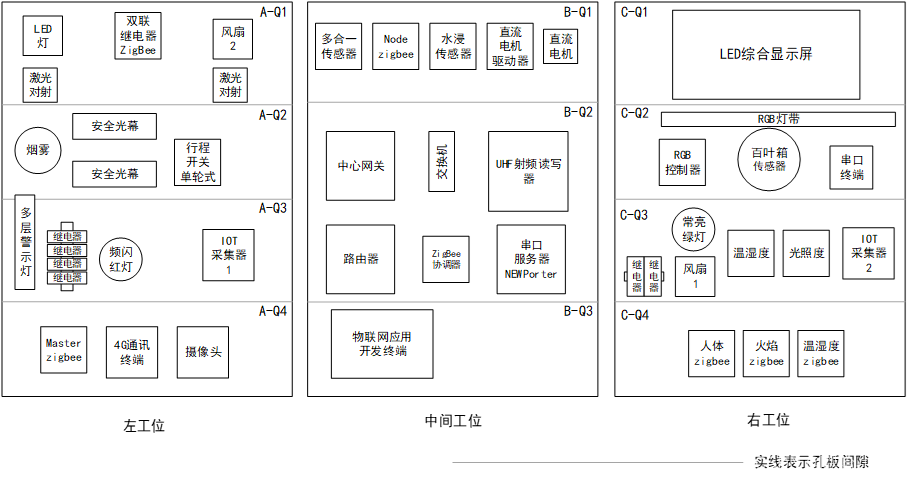
GZ038 物联网应用开发赛题第2套
2023年全国职业院校技能大赛 高职组 物联网应用开发 任 务 书 (第2套卷) 工位号:______________ 第一部分 竞赛须知 一、竞赛要求 1、正确使用工具,操作安全规范; 2、竞赛过程中如有异议,可向现场考评人员反映,不得扰乱赛场秩序; 3、遵守赛场纪律,尊重考评人员,…...
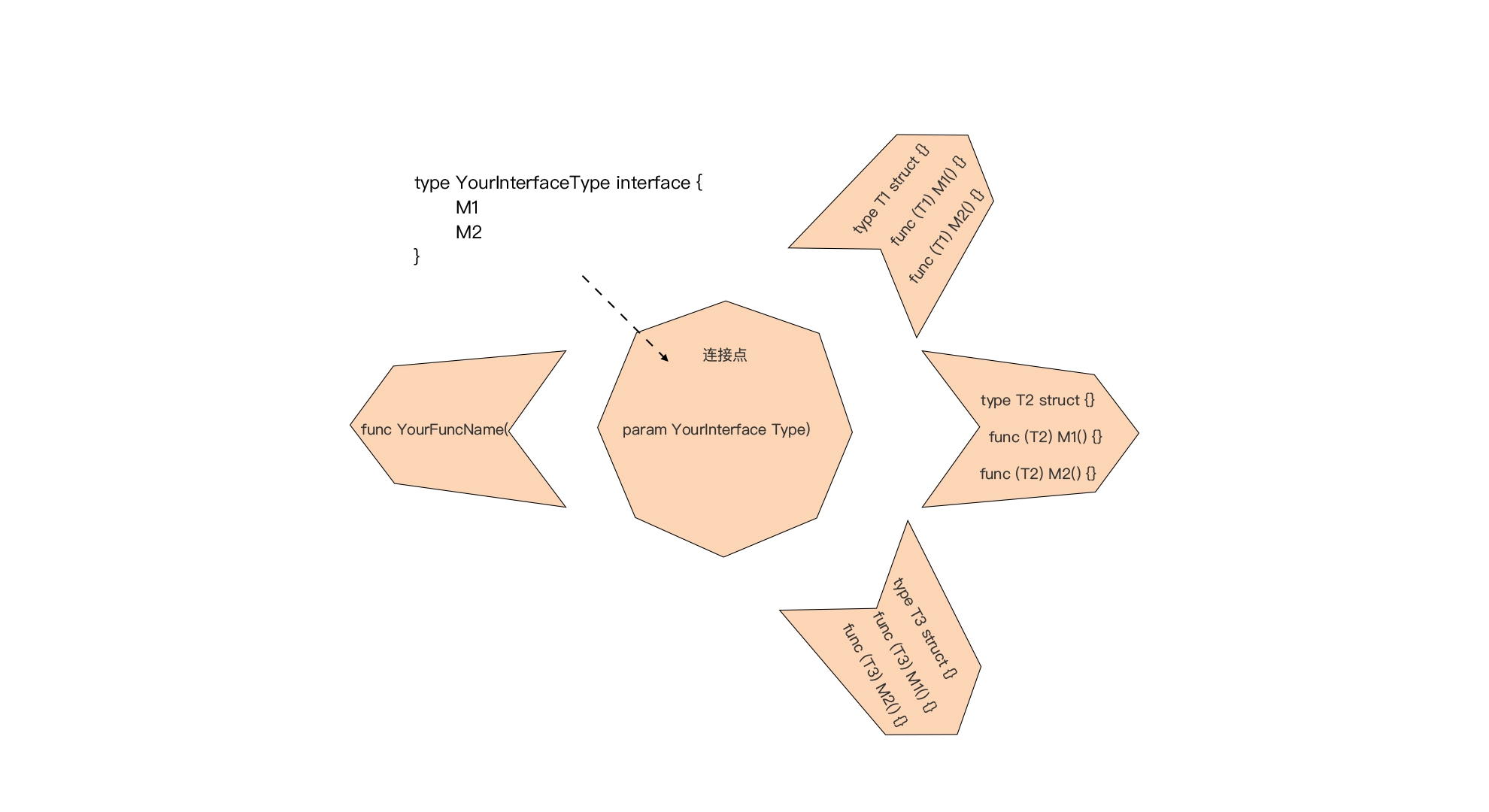
Go 接口:Go中最强大的魔法,接口应用模式或惯例介绍
Go 接口:Go中最强大的魔法,接口应用模式或惯例介绍 文章目录 Go 接口:Go中最强大的魔法,接口应用模式或惯例介绍一、前置原则二、一切皆组合2.1 一切皆组合2.2 垂直组合2.2.1 第一种:通过嵌入接口构建接口2.2.2 第二种:通过嵌入接…...
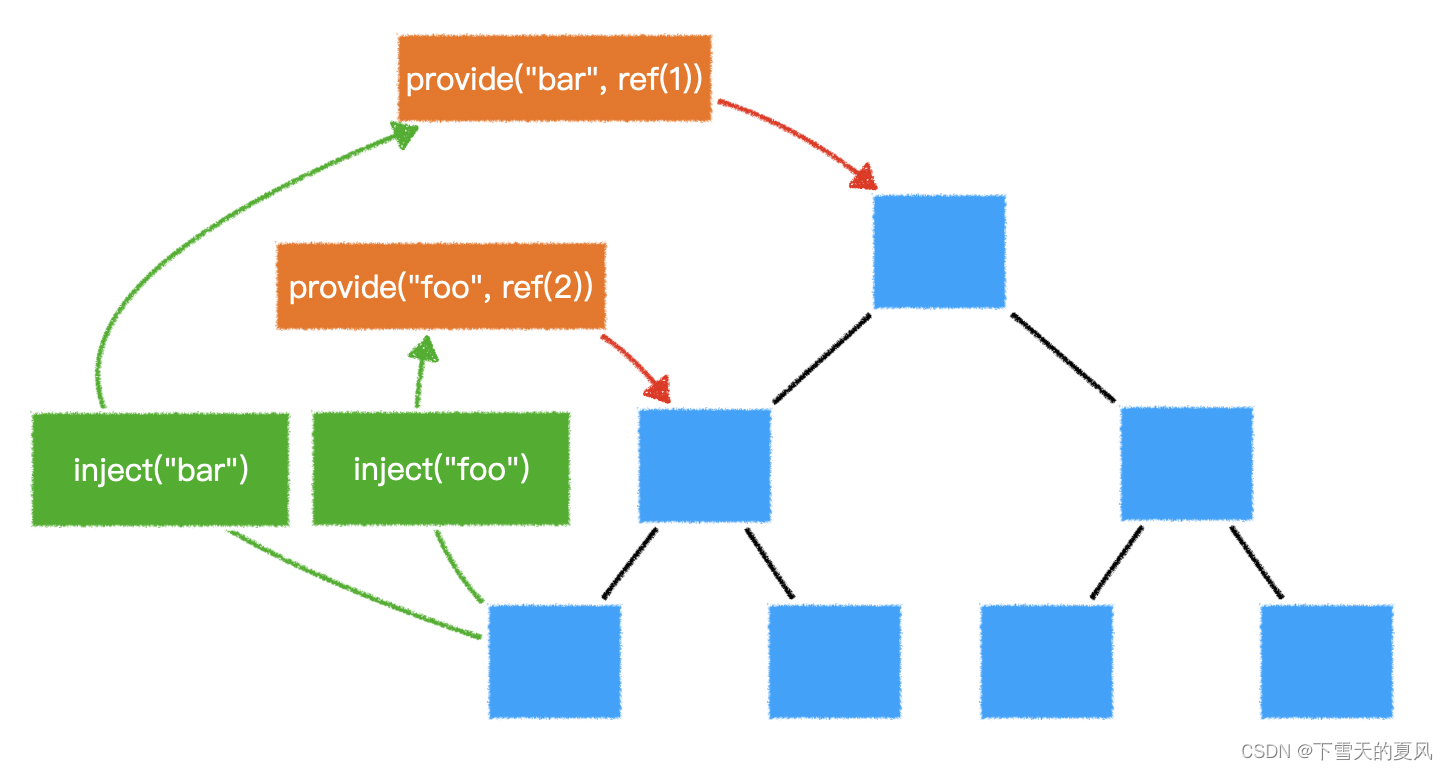
Vue3全局共享数据
目录 1,Vuex2,provide & inject2,global state4,Pinia5,对比 1,Vuex vue2 的官方状态管理器,vue3 也是可以用的,需要使用 4.x 版本。 相对于 vuex3.x,有两个重要变…...
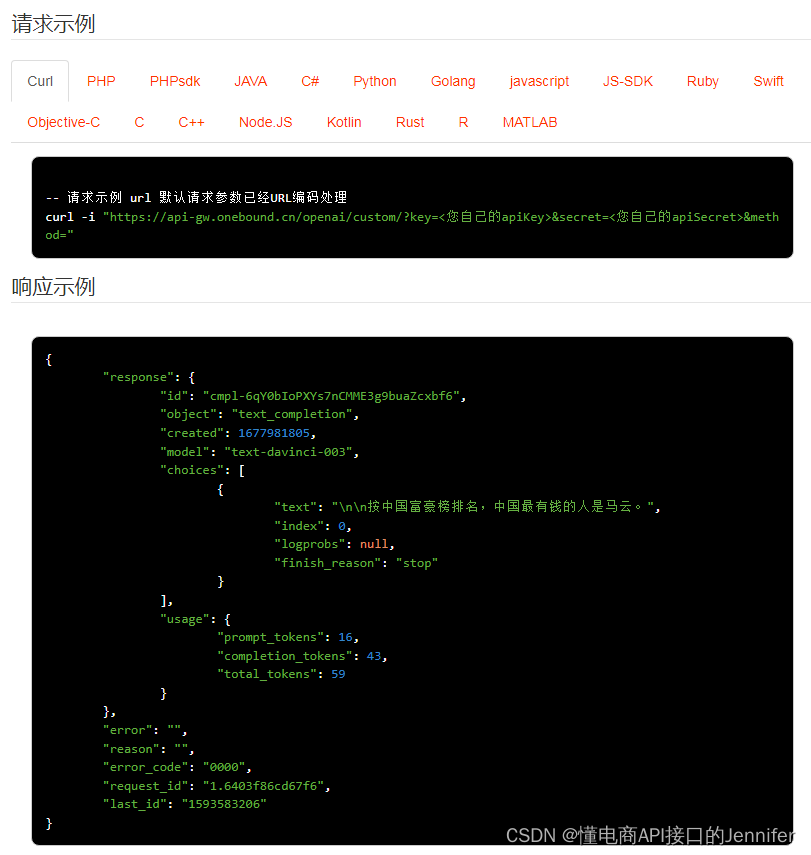
openai自定义API操作 API 返回值说明
custom-自定义API操作 openai.custom 公共参数 名称类型必须描述keyString是调用key(获取测试key)secretString是调用密钥api_nameString是API接口名称(包括在请求地址中)[item_search,item_get,item_search_shop等]cacheStrin…...

jsp基本表格和简单算法表格
基本表格; <% page language"java" contentType"text/html; charsetUTF-8"pageEncoding"UTF-8"%><!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd…...

在线存储系统源码 网盘网站源码 云盘系统源码
Cloudreve云盘系统源码-支持本地储存和对象储存,界面美观 云盘系统安装教程 测试环境:PHP7.1 MYSQL5.6 Apache 上传源码到根目录 安装程序: 浏览器数据 http://localhost/CloudreveInstallerlocalhost更换成你的网址 安装完毕 记住系统默认的账号密码 温馨提示:如果默认…...
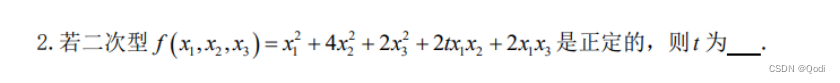
线性代数(六)| 二次型 标准型转换 正定二次型 正定矩阵
文章目录 1. 二次型化为标准型1.1 正交变换法1.2 配方法 2 . 正定二次型与正定矩阵 1. 二次型化为标准型 和第五章有什么样的联系 首先上一章我们说过对于对称矩阵,一定存在一个正交矩阵Q,使得$Q^{-1}AQB $ B为对角矩阵 那么这一章中,我们…...
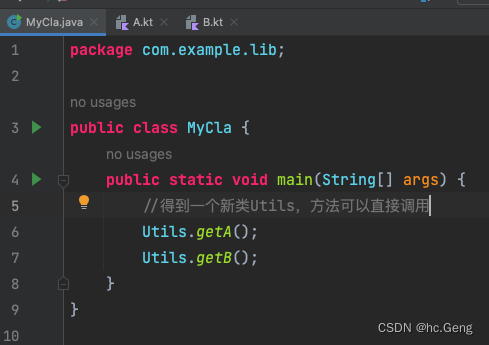
Kotlin系列之注解详解
目录 注解:file:JvmName 注解:JvmField 注解:JvmOverloads 注解:JvmStatic 注解:JvmMultifileClass 注解:JvmSynthetic 注解:file:JvmName file:JvmName(“XXX”) 放在类的最顶层&#x…...
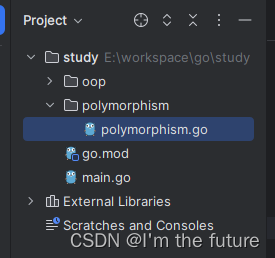
Go 面向对象,多态,基本数据类型
程序功能解读 第一行为可执行程序的包名,所有的Go源文件头部必须有一个包生命语句,Go通过包名来管理命名空间。 第三行import是引用外部包的说明 func关键字声明定义一个函数,如果是main则代表是Go程序入口函数 Go源码特征解读 源程序以.g…...

使用 Python修改JSON 文件中对应键值
文章目录 前言代码分析 前言 在日常的数据处理工作中,经常需要对 JSON 文件进行读取和修改。在 Python 中,处理 JSON 文件非常方便。本文将通过一个简单的示例程序来演示如何读取和修改 JSON 文件。 代码分析 首先,需要导入 json 和 os 模块…...
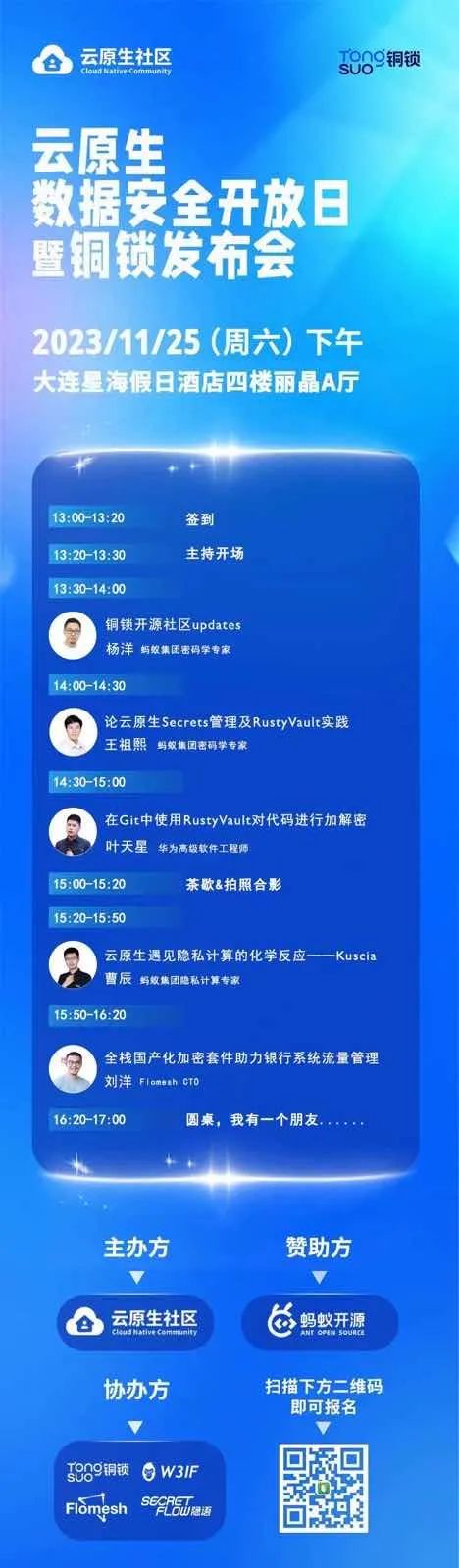
【Rust日报】2023-11-08 RustyVault -- 基于 rust 的现代秘密管理系统
RustyVault -- 基于 rust 的现代秘密管理系统 RustyVault 是一个用 Rust 编写的现代秘密管理系统。RustyVault 提供多种功能,支持多种场景,包括安全存储、云身份管理、秘密管理、Kubernetes 集成、PKI 基础设施、密码计算、传统密钥管理等。RustyVault 可…...
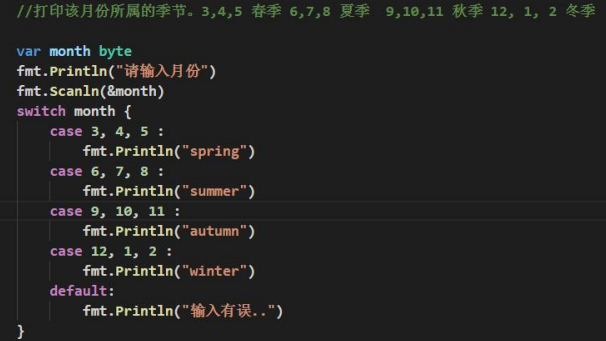
07【保姆级】-GO语言的程序流程控制【if switch for while 】
之前我学过C、Java、Python语言时总结的经验: 先建立整体框架,然后再去抠细节。先Know how,然后know why。先做出来,然后再去一点点研究,才会事半功倍。适当的囫囵吞枣。因为死抠某个知识点很浪费时间的。对于GO语言&a…...

求2个字符串的最短编辑距离 java 实现
EditStepInfo.java: import lombok.Getter; import lombok.Setter;import java.io.Serializable; import java.util.List;Getter Setter public class EditStepInfo implements Serializable {private String str1;private String str2;// str1和 str2 的最短编辑路…...
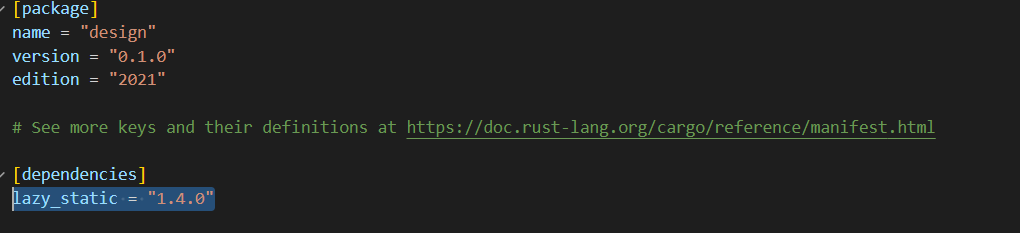
单例模式 rust和java的实现
文章目录 单例模式介绍应用实例:优点使用场景 架构图JAVA 实现单例模式的几种实现方式 rust实现 rust代码仓库 单例模式 单例模式(Singleton Pattern)是最简单的设计模式之一。这种类型的设计模式属于创建型模式,它提供了一种创建…...
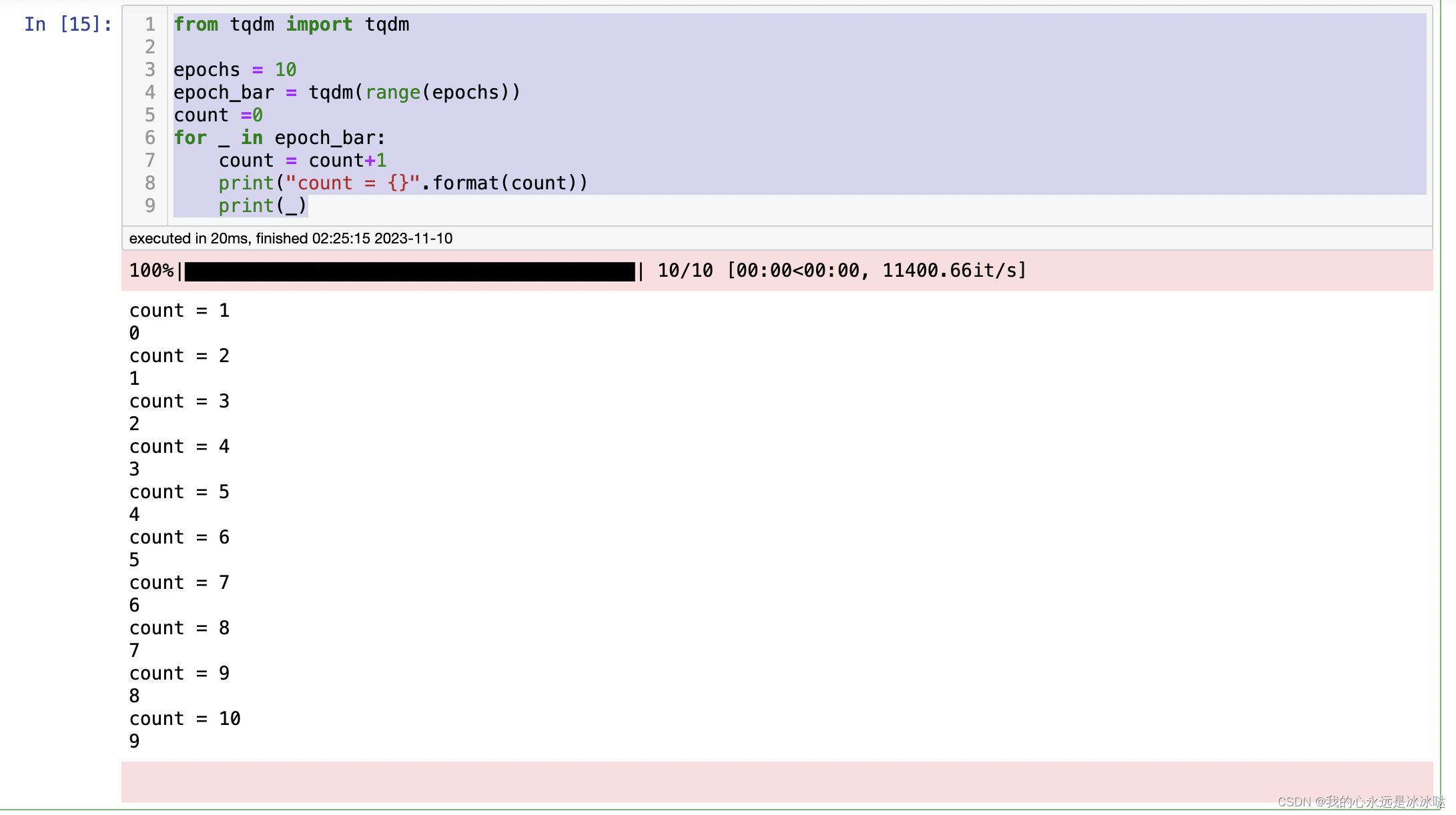
tqdm学习
from tqdm import tqdmepochs 10 epoch_bar tqdm(range(epochs)) count 0 for _ in epoch_bar:count count1print("count {}".format(count))print(_)每次就是一个epoch...
)
运放电路自激振荡了?试试这3种补偿方法(附RC参数估算与仿真对比)
运放电路自激振荡诊断与补偿实战指南 1. 自激振荡的识别与成因分析 当你发现精心设计的运放电路输出端出现异常的高频噪声或正弦波信号时,很可能遇到了自激振荡问题。这种现象在传感器信号调理、有源滤波器和精密放大电路中尤为常见。自激振荡不仅会淹没有用信号&am…...

C/C++新手必看:遇到‘uint32_t’未定义别慌,一分钟搞定头文件包含
C/C开发中uint32_t未定义问题的深度解析与实战指南 刚接触C/C开发的程序员在编写跨平台或嵌入式系统代码时,经常会遇到编译器报错"unknown type name uint32_t"的困扰。这个看似简单的错误背后,实际上涉及C/C标准演进、跨平台兼容性以及硬件抽…...

Hermes Agent简介
1、Hermes Agent 是什么?Hermes Agent 是由 Nous Research 在 2026 年 2 月开源发布的一款自进化 AI 智能体框架,采用 MIT 协议,完全免费可商用 。它的核心定位不是简单的聊天机器人或代码补全工具,而是一个部署在你自己服务器上、…...

2026 SMT贴片线数字孪生开发平台选型
SMT贴片线数字孪生平台选型需聚焦“高精度、高节拍、高复杂度”特性。专项能力一:微米级精度的“贴装过程仿真”高精度模型导入:能直接导入贴片机头部组件的精密CAD模型(SolidWorks、CATIA),保持装配约束。关节运动与I…...

数字体验平台DXP与最佳组合:赋能IT团队|Baklib
IT团队为企业提供动力,企业的数字化成功依赖于他们。反过来,工具则为IT团队提供动力。为了帮助IT团队构建高效的解决方案并完成任务,他们需要支持。有一系列技术可以做到这一点。数字体验平台(简称DXP)就是其中一项值得…...

LFM2.5-1.2B-Instruct效果展示:LNG接收站操作规程问答准确性
LFM2.5-1.2B-Instruct效果展示:LNG接收站操作规程问答准确性 1. 模型能力概览 LFM2.5-1.2B-Instruct是一个1.2B参数量的轻量级指令微调大语言模型,专为边缘设备和低资源服务器设计。这个模型在保持较小体积的同时,展现出令人印象深刻的专业…...

外设与通信模块低功耗设计—无线与采集电路降耗
Q:无线通信模块是嵌入式高功耗负载,有哪些针对性降耗方案?A:蓝牙、LoRa、NB-IoT、WiFi 等无线通信模块,是嵌入式系统中功耗最高的外设之一,瞬时发射功耗可达数百毫安,合理管控通信逻辑可大幅降…...

MATLAB网格线进阶:从基础显示到自定义布局与样式
1. MATLAB网格线基础操作:从显示到关闭 刚接触MATLAB绘图时,我经常遇到这样的困惑:明明数据很清晰,但图表总是显得杂乱无章。后来发现,合理使用网格线能显著提升图表可读性。让我们从最基础的网格线操作开始。 显示网格…...
)
用Python和RoboMaster SDK搞定Tello无人机编队飞行(保姆级避坑指南)
用Python和RoboMaster SDK实现Tello无人机编队飞行实战指南 当几台Tello无人机在空中同步完成编队动作时,那种科技感十足的场面总能吸引所有人的目光。作为大疆旗下最具性价比的教育编程无人机,Tello凭借开放的SDK接口和亲民的价格,成为了创客…...

APIKit项目贡献指南:参与开源社区开发的技术要点
APIKit项目贡献指南:参与开源社区开发的技术要点 【免费下载链接】APIKit APIKit:Discovery, Scan and Audit APIs Toolkit All In One. 项目地址: https://gitcode.com/gh_mirrors/api/APIKit APIKit是一款功能强大的API发现、扫描与审计工具包&…...