HBase学习笔记(2)—— API使用
对HBase中常用的API操作进行简单的介绍
对应HBase学习笔记(1)—— 知识点总结-CSDN博客中介绍的HBase Shell常用操作
更多用法请参考官网:Apache HBase ™ Reference Guide
依赖导入
<dependencies><dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-server</artifactId><version>2.4.11</version><exclusions><exclusion><groupId>org.glassfish</groupId><artifactId>javax.el</artifactId></exclusion></exclusions></dependency><dependency><groupId>org.glassfish</groupId><artifactId>javax.el</artifactId><version>3.0.1-b06</version></dependency></dependencies>打包所用的插件:
<build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-shade-plugin</artifactId><version>3.2.4</version><executions><execution><phase>package</phase><goals><goal>shade</goal></goals></execution></executions></plugin></plugins></build>建立连接
package com.why;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import java.io.IOException;public class HBaseConnect2 {public static Connection connection = null;static {try {connection = ConnectionFactory.createConnection(); //使用配置文件中的参数hbase.zookeeper.quorumSystem.out.println(connection);} catch (IOException e) {System.out.println("连接创建失败");throw new RuntimeException(e);}}/*** 关闭连接* @throws IOException*/public static void closeConnection() throws IOException {if (connection != null){connection.close();}}}
DDL操作
package com.why;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.NamespaceDescriptor;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;public class HBaseDDL {//获取连接private static Connection connection = HBaseConnect2.connection;/*** 创建命名空间* @param namespace 命名空间名称* @throws IOException*/public static void createNamespace(String namespace) throws IOException {//获取admin(admin的连接是轻量级的,不是线程安全的,不推荐池化或缓存)Admin admin = connection.getAdmin();//创建命名空间builderNamespaceDescriptor.Builder builder = NamespaceDescriptor.create(namespace);// builder.addConfiguration("user","why");try{admin.createNamespace(builder.build());}catch (IOException e){System.out.println("命名空间已经存在");e.printStackTrace();}admin.close();}/*** 查看所有命名空间* @throws IOException*/public static void listNamespaces() throws IOException {Admin admin = connection.getAdmin();try {String[] strings = admin.listNamespaces();System.out.println("命名空间如下:");for(String string : strings){System.out.println(string);}}catch (IOException e){e.printStackTrace();}admin.close();}/*** 判断表格是否存在* @param namespace 命名空间* @param table 表格名称* @return* @throws IOException*/public static boolean isTableExist(String namespace,String table) throws IOException {Admin admin = connection.getAdmin();boolean isExist = false;try {//通过tableExists方法判断表格是否存在isExist = admin.tableExists(TableName.valueOf(namespace,table));}catch (IOException e){e.printStackTrace();}admin.close();return isExist;}/*** 创建表格* @param namespace 命名空间* @param table 表格名称* @param columnFamilies 列族名称* @throws IOException*/public static void createTable(String namespace , String table , String... columnFamilies) throws IOException {//判断是否至少有一个列族if(columnFamilies.length == 0){System.out.println("至少要有一个列族");return;}//判断表格是否已经存在if(isTableExist(namespace,table)){System.out.println("表格已经存在");return;}Admin admin = connection.getAdmin();//创建表格描述的构建器TableDescriptorBuilder tableDescriptorBuilder = TableDescriptorBuilder.newBuilder(TableName.valueOf(namespace, table));//添加参数for(String columnFamily : columnFamilies){//创建列族描述的构建器ColumnFamilyDescriptorBuilder columnFamilyDescriptorBuilder = ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes(columnFamily));columnFamilyDescriptorBuilder.setMaxVersions(5); //添加最大版本数tableDescriptorBuilder.setColumnFamily(columnFamilyDescriptorBuilder.build()); //创建添加完参数的列族描述}try {admin.createTable(tableDescriptorBuilder.build());}catch (IOException e){e.printStackTrace();}admin.close();}/*** 查看所有表格* @throws IOException*/public static void listTableNames() throws IOException {Admin admin = connection.getAdmin();try {TableName[] tableNames = admin.listTableNames();System.out.println("所有表格如下");for(TableName tableName : tableNames){System.out.println(tableName.getNamespaceAsString() + ":" + tableName.getNameAsString());}}catch (IOException e){e.printStackTrace();}admin.close();}/*** 修改表格中某一个列族的版本号* @param namespace* @param table* @param columnFamily 列族* @param version 版本号*/public static void modifyTable(String namespace , String table , String columnFamily , int version) throws IOException {if(!isTableExist(namespace,table)){System.out.println("表格不存在,无法修改");return;}Admin admin = connection.getAdmin();try {//获取表格描述TableDescriptor descriptor = admin.getDescriptor(TableName.valueOf(namespace, table));//创建新的表格描述构建器TableDescriptorBuilder tableDescriptorBuilder = TableDescriptorBuilder.newBuilder(descriptor);//获取列族描述ColumnFamilyDescriptor columnFamily1 = descriptor.getColumnFamily(Bytes.toBytes(columnFamily));//创建新的列族描述构建器ColumnFamilyDescriptorBuilder columnFamilyDescriptorBuilder = ColumnFamilyDescriptorBuilder.newBuilder(columnFamily1);//设置参数columnFamilyDescriptorBuilder.setMaxVersions(version);//将新的列族描述添加到表格描述中tableDescriptorBuilder.modifyColumnFamily(columnFamilyDescriptorBuilder.build());admin.modifyTable(tableDescriptorBuilder.build());}catch (IOException e){e.printStackTrace();}admin.close();}/**** @param namespace* @param table* @return true表示删除成功*/public static boolean deleteTable(String namespace , String table) throws IOException {if(!isTableExist(namespace,table)){System.out.println("表格不存在,无法删除");return false;}Admin admin = connection.getAdmin();try {TableName tableName = TableName.valueOf(namespace, table);admin.disableTable(tableName);admin.deleteTable(tableName);}catch (IOException e){e.printStackTrace();}admin.close();return true;}}
DML操作
package com.why;import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.CompareOperator;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.filter.ColumnValueFilter;
import org.apache.hadoop.hbase.filter.FilterList;
import org.apache.hadoop.hbase.filter.SingleColumnValueFilter;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;public class HBaseDML {private static Connection connection = HBaseConnect2.connection;/*** 插入数据** @param namespace* @param table* @param rowKey* @param columnFamily* @param column* @param value* @throws IOException*/public static void insert(String namespace, String table, String rowKey, String columnFamily, String column, String value) throws IOException {//首先获取表格tableTable table1 = connection.getTable(TableName.valueOf(namespace, table));System.out.println("表格创建成功");//创建put对象Put put = new Put(Bytes.toBytes(rowKey));System.out.println("put对象创建成功");//向put对象中添加数据put.addColumn(Bytes.toBytes(columnFamily), Bytes.toBytes(column), Bytes.toBytes(value));try {table1.put(put);System.out.println("数据插入成功");} catch (IOException e) {e.printStackTrace();}table1.close();}/*** 读取数据** @param namespace* @param table* @param rowKey* @param columnFamily* @param column* @throws IOException*/public static void get(String namespace, String table, String rowKey, String columnFamily, String column) throws IOException {//获取tableTable table1 = connection.getTable(TableName.valueOf(namespace, table));//获取get对象Get get = new Get(Bytes.toBytes(rowKey));//设置读取某一列的数据(如果不设置的话则读取所有数据)get.addColumn(Bytes.toBytes(columnFamily), Bytes.toBytes(column));try {//调用get方法读取数据Result result = table1.get(get);//获取到所有的cellCell[] cells = result.rawCells();//打印valuefor (Cell cell : cells) {String value = new String(CellUtil.cloneValue(cell));System.out.println(value);}} catch (IOException e) {e.printStackTrace();}table1.close();}/*** 扫描表** @param namespace* @param table* @param startRow* @param stopRow* @throws IOException*/public static void scan(String namespace, String table, String startRow, String stopRow) throws IOException {//获取tableTable table1 = connection.getTable(TableName.valueOf(namespace, table));//创建scan对象Scan scan = new Scan();//添加扫描的起止rowKeyscan.withStartRow(Bytes.toBytes(startRow));scan.withStopRow(Bytes.toBytes(stopRow));try {ResultScanner scanner = table1.getScanner(scan);for (Result result : scanner) {Cell[] cells = result.rawCells();for (Cell cell : cells) {System.out.print(newString(CellUtil.cloneRow(cell)) + "-" + newString(CellUtil.cloneFamily(cell)) + "-" + newString(CellUtil.cloneQualifier(cell)) + "-" + newString(CellUtil.cloneValue(cell)) + "\t");}System.out.println();;}} catch (IOException e) {e.printStackTrace();}table1.close();}/*** 扫描表(有过滤器)** @param namespace* @param table* @param startRow* @param stopRow* @param columnFamily* @param column* @param value*/public static void scanWithFilter(String namespace, String table, String startRow, String stopRow, String columnFamily, String column, String value) throws IOException {//获取tableTable table1 = connection.getTable(TableName.valueOf(namespace, table));//创建scan对象Scan scan = new Scan();//添加扫描的起止rowKeyscan.withStartRow(Bytes.toBytes(startRow));scan.withStopRow(Bytes.toBytes(stopRow));//创建过滤器列表FilterList filterList = new FilterList();//创建列过滤器,作用:只保留当前列的数据ColumnValueFilter columnValueFilter = new ColumnValueFilter(Bytes.toBytes(columnFamily),Bytes.toBytes(column),CompareOperator.EQUAL,Bytes.toBytes(value));// // (2) 结果保留整行数据
// // 结果同时会保留没有当前列的数据
// SingleColumnValueFilter singleColumnValueFilter = new
// SingleColumnValueFilter(
// // 列族名称
// Bytes.toBytes(columnFamily),
// // 列名
// Bytes.toBytes(column),
// // 比较关系
// CompareOperator.EQUAL,
// // 值
// Bytes.toBytes(value)
// );filterList.addFilter(columnValueFilter);scan.setFilter(filterList);try {ResultScanner scanner = table1.getScanner(scan);for (Result result : scanner) {Cell[] cells = result.rawCells();for (Cell cell : cells) {System.out.print(newString(CellUtil.cloneRow(cell)) + "-" + newString(CellUtil.cloneFamily(cell)) + "-" + newString(CellUtil.cloneQualifier(cell)) + "-" + newString(CellUtil.cloneValue(cell)) + "\t");}System.out.println();;}} catch (IOException e) {e.printStackTrace();}table1.close();}/*** 删除数据* @param nameSpace* @param table* @param rowKey* @param columnFamily* @param column* @throws IOException*/public static void delete(String nameSpace, String table, String rowKey, String columnFamily, String column) throws IOException {//获取 tableTable table1 = connection.getTable(TableName.valueOf(nameSpace, table));//创建 Delete 对象Delete delete = new Delete(Bytes.toBytes(rowKey));//添加删除信息//删除单个版本(默认最新)delete.addColumn(Bytes.toBytes(columnFamily),Bytes.toBytes(column));// //删除所有版本
// delete.addColumns(Bytes.toBytes(columnFamily),Bytes.toBytes(column));//删除列族delete.addFamily(Bytes.toBytes(columnFamily));try {table1.delete(delete);}catch (IOException e){e.printStackTrace();}table1.close();}
}
说明:本学习笔记根据基于尚硅谷课程进行整理,课程链接:hbase
未完待续~
相关文章:
—— API使用)
HBase学习笔记(2)—— API使用
对HBase中常用的API操作进行简单的介绍 对应HBase学习笔记(1)—— 知识点总结-CSDN博客中介绍的HBase Shell常用操作 更多用法请参考官网:Apache HBase ™ Reference Guide 依赖导入 <dependencies><dependency><groupId>o…...
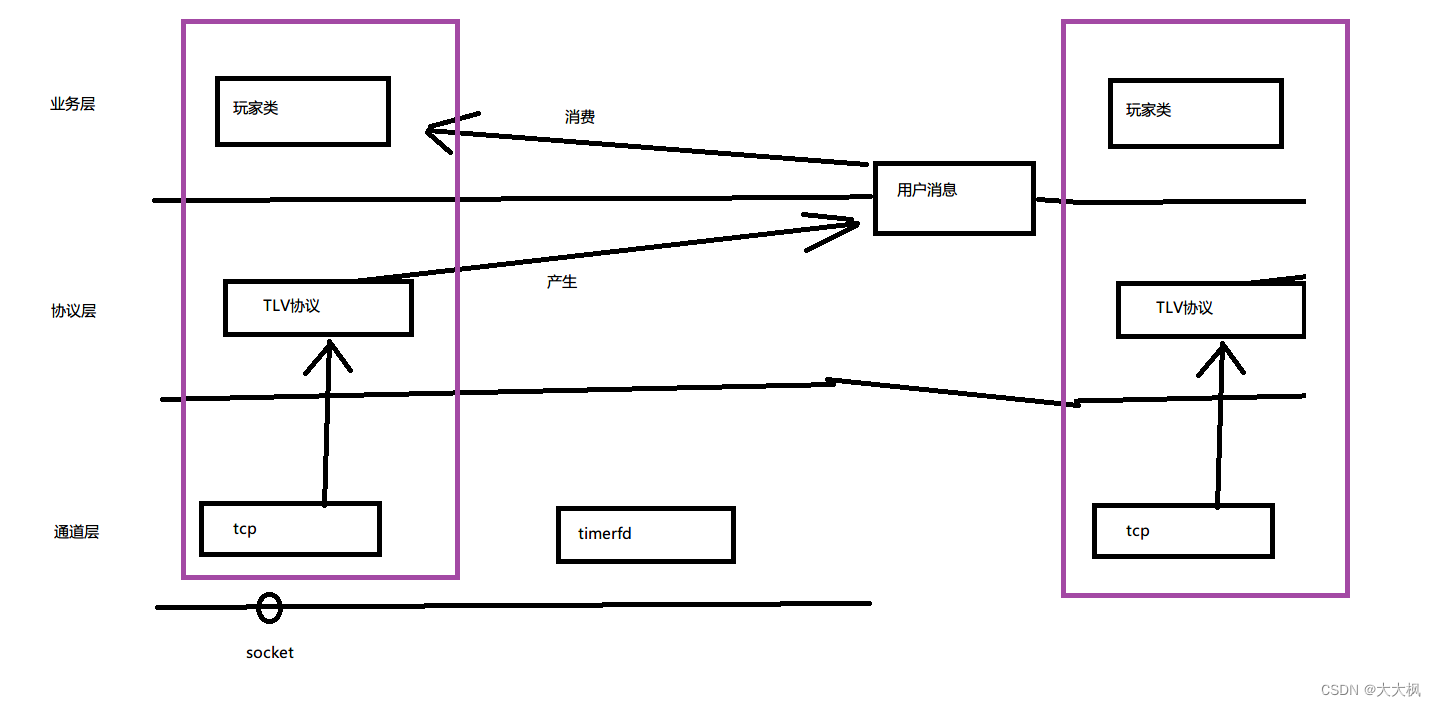
C/C++轻量级并发TCP服务器框架Zinx-游戏服务器开发004:游戏核心消息处理 - 玩家类的实现
文章目录 0 代码仓库1 需求2 AOI设计2.1 AOI算法简介2.2 AOI数据结构及实现2.2.1 玩家2.2.2 网格对象2.2.3 游戏世界矩形2.2.4 获取周围玩家的实现2.2.5 代码测试 2.3 GameRole结合AOI创建玩家2.3.1 创建游戏世界全局对象-GameRole继承AOIWorld的Player2.3.2 把玩家到游戏世界的…...

Python Selenium元素定位方法详解
引言 在Web自动化测试中,元素定位是一项非常重要的技术。Python Selenium提供了各种元素定位方法,可以帮助我们定位页面上的元素并与之交互。本文将详细介绍Python Selenium中常用的元素定位方法,并提供实例代码。 1. ID定位 ID是元素在HT…...
)
分布式事务,你了解多少?(上)
本文主要是讲述分布式事务的理论及常用的技术方案,主要源自各类学习和工作总结,如有不妥之处,还望指正。分布式事务的其他基础请自行查阅资料。 一、分布式事务产生的原因 分布式事务的产生,源自互联网、电商等的发展,…...

ClickHouse主键索引最佳实践
在本文中,我们将深入研究ClickHouse索引。我们将对此进行详细说明和讨论: ClickHouse的索引与传统的关系数据库有何不同ClickHouse是怎样构建和使用主键稀疏索引的ClickHouse索引的最佳实践 您可以选择在自己的机器上执行本文给出的所有Clickhouse SQL…...
)
Flink 基础 -- 应用开发(项目配置)
1、概述 本节中的指南将向您展示如何通过流行的构建工具(Maven, Gradle)配置项目,添加必要的依赖项(即连接器和格式,测试),并涵盖一些高级配置主题。 每个Flink应用程序都依赖于一组Flink库。至少,应用程序依赖于Flink api&…...

空间曲面@常见曲面方程
文章目录 曲面的基本问题特殊曲面球面方程球的标准形方程一般形方程例 柱面柱面方程不同维度下同方程的图形常见柱面方程 旋转曲面旋转曲面的方程旋转情况分类以yOz上的曲线绕 z z z轴旋转为例 旋转曲面的方程常见旋转曲面方程 锥面其他曲面 曲面的基本问题 根据曲面(点的几何…...

unity 接收和发送Udp消息
因为需要用到unity和其他的程序交互,其他程序可以提供Udp消息,因此找了合适的相互连接方法。这里直接上代码。 工具类: using System; using System.Collections; using System.Collections.Generic; using System.IO; using System.Net; u…...

机器学习股票大数据量化分析与预测系统 - python 计算机竞赛
文章目录 0 前言1 课题背景2 实现效果UI界面设计web预测界面RSRS选股界面 3 软件架构4 工具介绍Flask框架MySQL数据库LSTM 5 最后 0 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 机器学习股票大数据量化分析与预测系统 该项目较为新颖&am…...
)
架构描述语言(ADL)
1.架构描述语言(ADL) 架构描述语言(Architecture Description Language, ADL)是一种为明确说明软件系统的概念架构和对这些概念架构建模提供功能的语言。 2.ADL基本构成要素 ADL即架构描述语言,其基本构成要素包括:…...
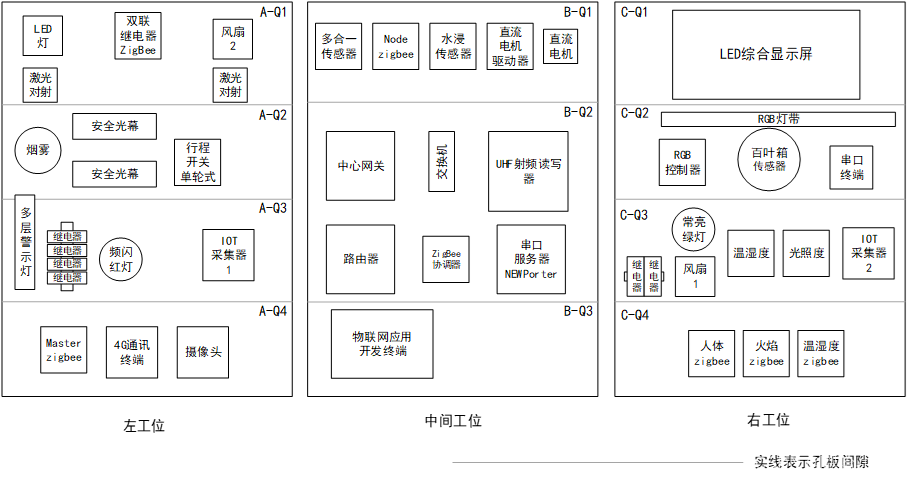
GZ038 物联网应用开发赛题第2套
2023年全国职业院校技能大赛 高职组 物联网应用开发 任 务 书 (第2套卷) 工位号:______________ 第一部分 竞赛须知 一、竞赛要求 1、正确使用工具,操作安全规范; 2、竞赛过程中如有异议,可向现场考评人员反映,不得扰乱赛场秩序; 3、遵守赛场纪律,尊重考评人员,…...
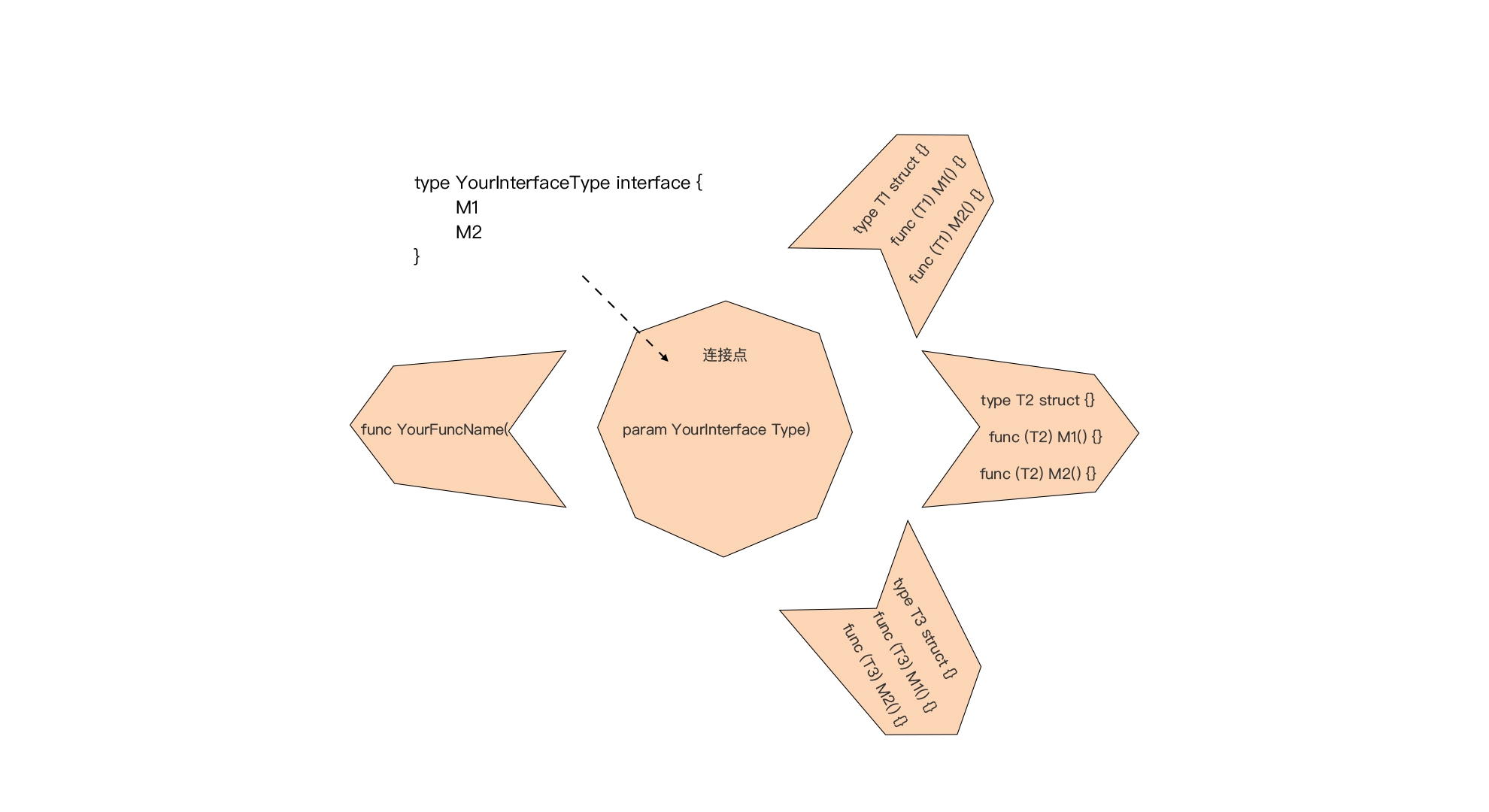
Go 接口:Go中最强大的魔法,接口应用模式或惯例介绍
Go 接口:Go中最强大的魔法,接口应用模式或惯例介绍 文章目录 Go 接口:Go中最强大的魔法,接口应用模式或惯例介绍一、前置原则二、一切皆组合2.1 一切皆组合2.2 垂直组合2.2.1 第一种:通过嵌入接口构建接口2.2.2 第二种:通过嵌入接…...
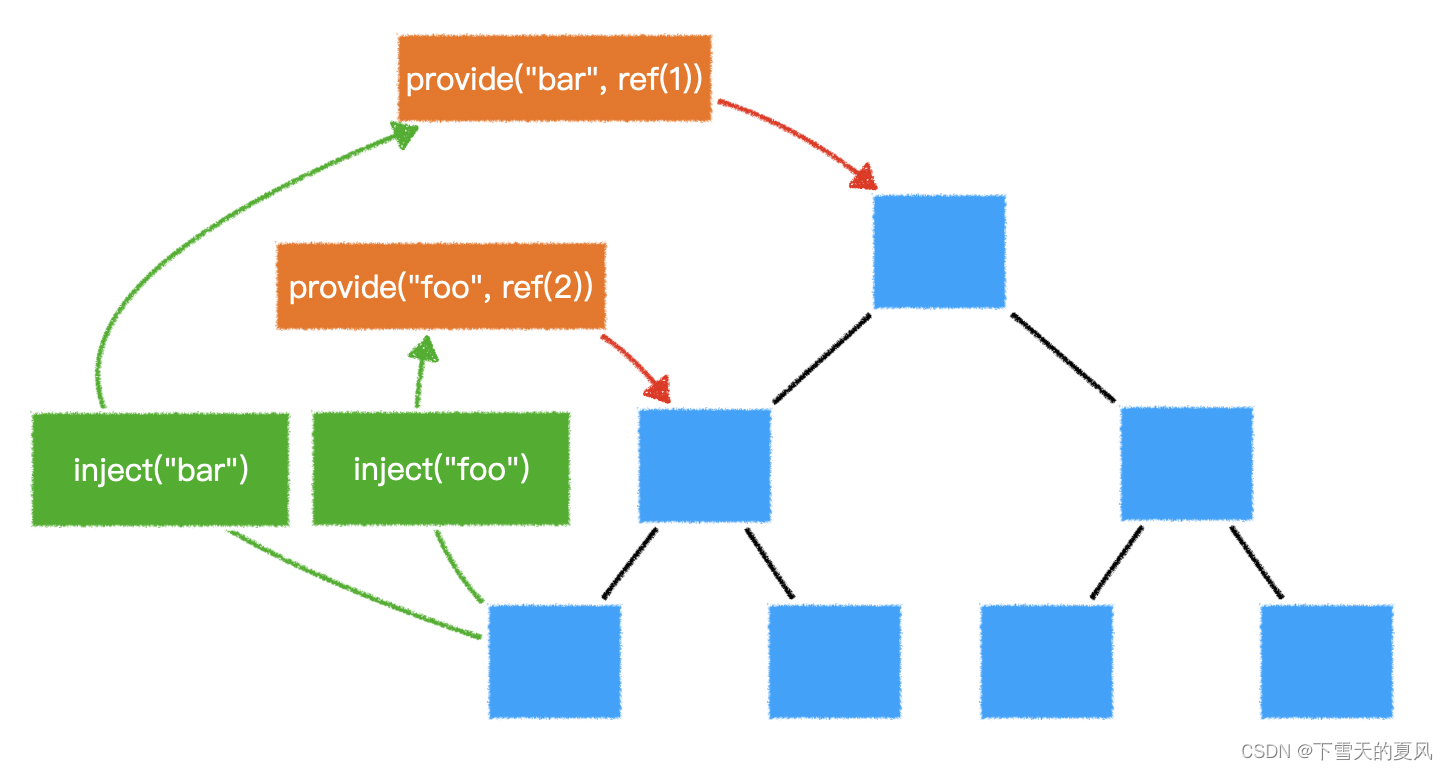
Vue3全局共享数据
目录 1,Vuex2,provide & inject2,global state4,Pinia5,对比 1,Vuex vue2 的官方状态管理器,vue3 也是可以用的,需要使用 4.x 版本。 相对于 vuex3.x,有两个重要变…...
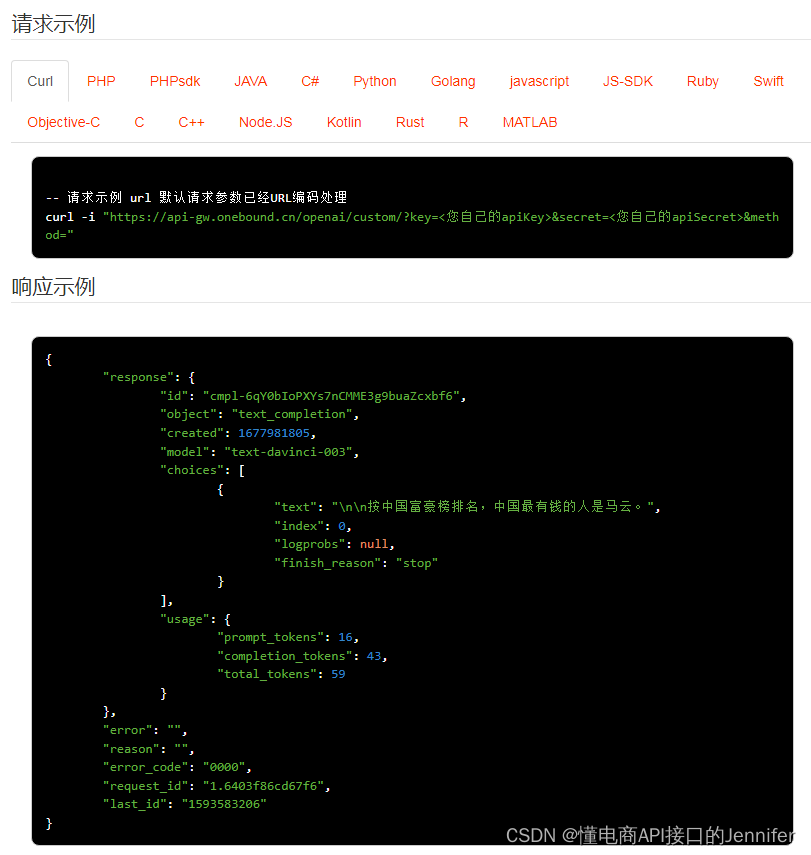
openai自定义API操作 API 返回值说明
custom-自定义API操作 openai.custom 公共参数 名称类型必须描述keyString是调用key(获取测试key)secretString是调用密钥api_nameString是API接口名称(包括在请求地址中)[item_search,item_get,item_search_shop等]cacheStrin…...

jsp基本表格和简单算法表格
基本表格; <% page language"java" contentType"text/html; charsetUTF-8"pageEncoding"UTF-8"%><!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd…...

在线存储系统源码 网盘网站源码 云盘系统源码
Cloudreve云盘系统源码-支持本地储存和对象储存,界面美观 云盘系统安装教程 测试环境:PHP7.1 MYSQL5.6 Apache 上传源码到根目录 安装程序: 浏览器数据 http://localhost/CloudreveInstallerlocalhost更换成你的网址 安装完毕 记住系统默认的账号密码 温馨提示:如果默认…...
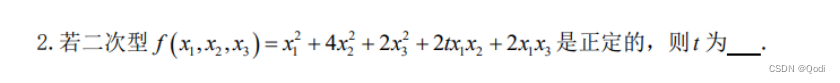
线性代数(六)| 二次型 标准型转换 正定二次型 正定矩阵
文章目录 1. 二次型化为标准型1.1 正交变换法1.2 配方法 2 . 正定二次型与正定矩阵 1. 二次型化为标准型 和第五章有什么样的联系 首先上一章我们说过对于对称矩阵,一定存在一个正交矩阵Q,使得$Q^{-1}AQB $ B为对角矩阵 那么这一章中,我们…...
Kotlin系列之注解详解
目录 注解:file:JvmName 注解:JvmField 注解:JvmOverloads 注解:JvmStatic 注解:JvmMultifileClass 注解:JvmSynthetic 注解:file:JvmName file:JvmName(“XXX”) 放在类的最顶层&#x…...
Go 面向对象,多态,基本数据类型
程序功能解读 第一行为可执行程序的包名,所有的Go源文件头部必须有一个包生命语句,Go通过包名来管理命名空间。 第三行import是引用外部包的说明 func关键字声明定义一个函数,如果是main则代表是Go程序入口函数 Go源码特征解读 源程序以.g…...

使用 Python修改JSON 文件中对应键值
文章目录 前言代码分析 前言 在日常的数据处理工作中,经常需要对 JSON 文件进行读取和修改。在 Python 中,处理 JSON 文件非常方便。本文将通过一个简单的示例程序来演示如何读取和修改 JSON 文件。 代码分析 首先,需要导入 json 和 os 模块…...

高中五大联赛中的高校认可度与专业选择优势排名
根据当前(2026年4月)最新公开资料,高中“五大联赛”(即数学、物理、化学、生物、信息学五大学科奥林匹克竞赛)在高校认可度与专业选择优势方面的排名如下: 一、高校认可度排名 综合强基计划、…...

从一次线上事故复盘说起:我们是如何用SLI和SLO定责并改进系统稳定性的
从一次购物车故障复盘看SLI/SLO的工程实践价值 凌晨2点15分,电商平台的监控大屏突然亮起刺眼的红色——购物车下单成功率在10分钟内从99.98%暴跌至76%。值班工程师的钉钉群瞬间被用户投诉截图淹没,而更棘手的是,促销活动还有3小时就要开始。这…...

ESP8266 I2C通信避坑指南:从SHT30读取失败到BH1750数据不准的常见问题排查
ESP8266 I2C通信实战避坑指南:从硬件连接到协议调试的完整解决方案 当你第一次尝试用ESP8266通过I2C总线连接传感器时,可能会遇到各种令人困惑的问题——传感器无响应、数据读取为0、数值异常波动,甚至I2C地址扫描不到。这些问题往往让开发者…...

Keepalived VIP漂移后网络不通?可能是交换机ARP表没刷新!手把手教你配置garp_master_refresh
Keepalived VIP漂移故障排查:从ARP表刷新到高可用架构优化 那天凌晨三点,手机突然响起刺耳的告警铃声——核心业务VIP访问异常。作为值班运维,我瞬间清醒,抓起笔记本就开始排查。这是一次典型的主备切换后VIP不通故障,…...

从理论到实践:AM信号包络检波器的设计与仿真分析
1. AM信号与包络检波基础 收音机里传来的音乐、对讲机中的对话,这些我们熟悉的无线通信场景背后,都离不开一个关键技术——AM调幅信号。AM全称Amplitude Modulation,也就是幅度调制。它的核心思想很简单:用低频的声音信号…...

Zotero重复文献清理深度解析:3步实现高效文献库去重管理
Zotero重复文献清理深度解析:3步实现高效文献库去重管理 【免费下载链接】ZoteroDuplicatesMerger A zotero plugin to automatically merge duplicate items 项目地址: https://gitcode.com/gh_mirrors/zo/ZoteroDuplicatesMerger 你是否曾因文献库中大量重…...

3步搞定显卡驱动残留:Display Driver Uninstaller终极清理指南
3步搞定显卡驱动残留:Display Driver Uninstaller终极清理指南 【免费下载链接】display-drivers-uninstaller Display Driver Uninstaller (DDU) a driver removal utility / cleaner utility 项目地址: https://gitcode.com/gh_mirrors/di/display-drivers-unin…...

CubicSDR核心解密:深入理解解调器线程与信号处理机制
CubicSDR核心解密:深入理解解调器线程与信号处理机制 【免费下载链接】CubicSDR Cross-Platform Software-Defined Radio Application 项目地址: https://gitcode.com/gh_mirrors/cu/CubicSDR CubicSDR作为一款跨平台软件定义无线电(SDRÿ…...

marketingskills与Claude Code集成:打造智能营销助手的完整教程
marketingskills与Claude Code集成:打造智能营销助手的完整教程 【免费下载链接】marketingskills Marketing skills for Claude Code and AI agents. CRO, copywriting, SEO, analytics, and growth engineering. 项目地址: https://gitcode.com/GitHub_Trending…...

GLM-4.7智能体部署实战:从模型选型到性能调优全解析
1. 项目概述:从GLM-4.5到GLM-4.7,一个开源智能体基座的演进之路如果你在过去一年里深度参与过AI智能体或者大语言模型的应用开发,那么“GLM”这个系列对你来说一定不陌生。从GLM-4.5的横空出世,到GLM-4.6的稳步提升,再…...