NLP之Bert实现文本多分类
文章目录
- 代码
- 代码整体流程解读
- debug上面的代码
代码
from pypro.chapters03.demo03_数据获取与处理 import train_list, label_list, val_train_list, val_label_list
import tensorflow as tf
from transformers import TFBertForSequenceClassificationbert_model = "bert-base-chinese"model = TFBertForSequenceClassification.from_pretrained(bert_model, num_labels=32)
model.compile(metrics=['accuracy'], loss=tf.nn.sigmoid_cross_entropy_with_logits)
model.summary()
result = model.fit(x=train_list[:24], y=label_list[:24], batch_size=12, epochs=1)
print(result.history)
# 保存模型(模型保存的本质就是保存训练的参数,而对于深度学习而言还保存神经网络结构)
model.save_weights('../data/model.h5')model = TFBertForSequenceClassification.from_pretrained(bert_model, num_labels=32)
model.load_weights('../data/model.h5')
result = model.predict(val_train_list[:12]) # 预测值
print(result)
result = tf.nn.sigmoid(result)
print(result)
result = tf.cast(tf.greater_equal(result, 0.5), tf.float32)
print(result)
代码整体流程解读
这段代码的目的是利用TensorFlow和transformers库来进行文本序列的分类任务。下面是整体流程的概述和逐步计划:
-
导入必要的库和数据:
- 从一个叫做
pypro.chapters03.demo03_数据获取与处理的模块中导入了四个列表:train_list,label_list,val_train_list,val_label_list。这些列表分别包含训练数据、训练标签、验证数据和验证标签。 - 导入TensorFlow和transformers库。
- 从一个叫做
-
初始化预训练的BERT模型:
- 使用
bert-base-chinese模型初始化一个用于序列分类的BERT模型。 - 模型被配置为对32个不同的标签进行分类。
- 使用
-
编译模型:
- 使用sigmoid交叉熵作为损失函数,并跟踪准确度作为性能指标。
-
模型摘要:
- 输出模型的概要信息,包括每一层的名称、类型、输出形状和参数数量。
-
训练模型:
- 使用提供的训练数据和标签(仅取前24个样本)来训练模型。
- 批量大小设置为12,训练仅进行1个时代(epoch),这意味着数据将通过模型传递一次。
-
输出训练结果:
- 打印训练过程中记录的历史数据,通常包括损失值和准确度。
-
保存模型权重:
- 将训练后的模型权重保存到本地文件
model.h5。
- 将训练后的模型权重保存到本地文件
-
加载模型权重:
- 初始化一个新的模型结构,并加载之前保存的权重。
-
模型预测:
- 使用验证数据(仅取前12个样本)进行预测。
-
激活函数处理:
- 将预测结果通过sigmoid函数处理,转换成0到1之间的值。
-
转换预测结果:
- 通过比较预测值是否大于或等于0.5来将概率转换为二进制分类结果。
debug上面的代码
下面逐行解释上述代码:
-
from pypro.chapters03.demo03_数据获取与处理 import train_list, label_list, val_train_list, val_label_list这行代码从
demo03_数据获取与处理模块中导入四个列表。这些列表包含训练数据和标签(train_list,label_list),以及验证数据和标签(val_train_list,val_label_list)。这是数据准备步骤的一部分。 -
import tensorflow as tf这行代码导入了TensorFlow库,它是一个广泛用于机器学习和深度学习任务的开源库。
-
from transformers import TFBertForSequenceClassification这里导入了
transformers库中的TFBertForSequenceClassification类。transformers库包含了许多预训练模型,用于NLP任务,这里特别导入的是适用于TensorFlow的BERT模型,用于序列分类任务。 -
bert_model = "bert-base-chinese"定义一个字符串变量
bert_model,它保存了预训练模型的名称。在这里,我们将使用中文BERT基础模型。 -
model = TFBertForSequenceClassification.from_pretrained(bert_model, num_labels=32)使用
bert-base-chinese模型和TFBertForSequenceClassification类创建一个新的序列分类模型实例。num_labels=32表明有32个不同的类别用于分类。 -
model.compile(metrics=['accuracy'], loss=tf.nn.sigmoid_cross_entropy_with_logits)编译模型,设置度量为准确度(
accuracy),并使用sigmoid_cross_entropy_with_logits作为损失函数,这通常用于二分类问题,但在这里,由于是多标签分类(32个类别),可能是对每个标签进行二分类。 -
model.summary()输出模型的摘要信息,包括模型中的层,每层的输出形状和参数数量等详细信息。
-
result = model.fit(x=train_list[:24], y=label_list[:24], batch_size=12, epochs=1)开始训练模型,仅使用前24个样本作为训练数据和标签。批处理大小设置为12,意味着每次梯度更新将基于12个样本。
epochs=1表示整个数据集只通过模型训练一次。 -
print(result.history)打印出训练过程中的历史数据,如损失和准确度。
-
model.save_weights('../data/model.h5')保存训练好的模型权重到本地文件
model.h5。 -
model = TFBertForSequenceClassification.from_pretrained(bert_model, num_labels=32)再次初始化一个模型,用于演示如何从头加载一个模型。
-
model.load_weights('../data/model.h5')加载先前保存的模型权重。
-
result = model.predict(val_train_list[:12]) # 预测值使用验证数据集中的前12个样本进行预测,得到模型的输出。
-
print(result)打印出预测结果。
-
result = tf.nn.sigmoid(result)将模型的原始输出通过sigmoid函数转换,得到一个在0到1之间的值,表示属于每个类别的概率。
-
print(result)再次打印经过sigmoid激活函数处理后的预测结果。
-
result = tf.cast(tf.greater_equal(result, 0.5), tf.float32)将sigmoid输出的概率转换为二分类结果。对于每个标签,如果概率大于或等于0.5,则认为该样本属于该标签(转换为1),否则不属于(转换为0)。
-
`print
(result)`
最后,打印出转换后的分类结果。
整体而言,这段代码展示了使用预训练的BERT模型在一个多标签文本分类任务上的训练、保存、加载和预测的完整过程。
相关文章:

NLP之Bert实现文本多分类
文章目录 代码代码整体流程解读debug上面的代码 代码 from pypro.chapters03.demo03_数据获取与处理 import train_list, label_list, val_train_list, val_label_list import tensorflow as tf from transformers import TFBertForSequenceClassificationbert_model "b…...

对话大众软件子公司:中国的智舱、智驾比欧洲早一代
作者 | 德新 编辑 | 王博 尤其在上海车展之后,大部分的外资车企都在转型调整。 2023年的上海车展是一个重要节点。在这之前,疫情阻断了国内和海外频繁的线下交流,而国内汽车的新能源化和智能化在这期间完成了一次飞跃式的发展。所以车展开…...

基于FPGA的图像RGB转HSV实现,包含testbench和MATLAB辅助验证程序
目录 1.算法运行效果图预览 2.算法运行软件版本 3.部分核心程序 4.算法理论概述 4.1. RGB与HSV色彩空间 4.2. RGB到HSV转换原理 5.算法完整程序工程 1.算法运行效果图预览 将FPGA的仿真结果导入到matlab中: 2.算法运行软件版本 vivado2019.2 matlab2022a …...

小型企业如何数字化转型?ZohoCRM助力小企业转型
小型企业数字化之路倍加艰难,其组织规模有限、资源有限,数字化布局或转型,也存在与数字平台匹配度的问题。其实小型企业可以通过CRM客户管理系统实现高效的客户关系管理,进一步提高市场竞争力。 建立高效易用的客户关系管理系统 …...
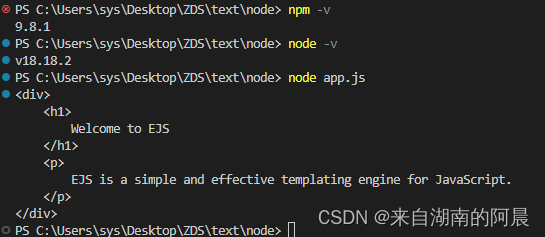
聊聊模板引擎<Template engine>
模板引擎是什么 模板引擎是一种用于生成动态内容的工具,通常用于Web开发中。它能够将静态的模板文件和动态数据结合起来,生成最终的HTML、XML或其他文档类型。模板引擎通过向模板文件中插入变量、条件语句、循环结构等控制语句,从而实现根据…...

多平台商品采集——API接口:支持淘宝、天猫、1688、拼多多等多个电商平台的爆款、销量、整店商品采集和淘客功能
item_get-获得淘宝商品详情 item_get_app-获得淘宝app商品详情原数据 item_get_pro-获得淘宝商品详情高级版 item_search-按关键字搜索淘宝商品 item_search_img-按图搜索淘宝商品(拍立淘) item_search_shop-获得店铺的所有商品 API请求地址 公共…...
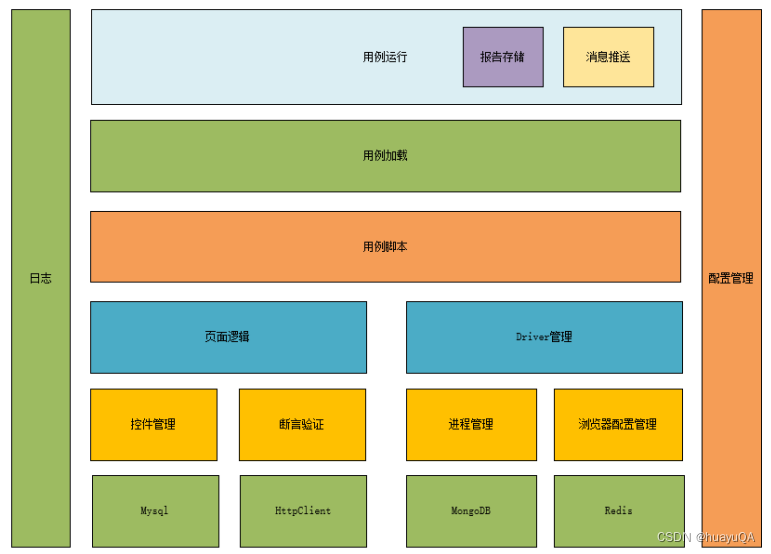
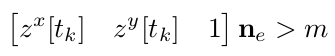
towr code阅读
1. Introduction towr是非常优美的足式机器人规划代码,通过阅读towr重要的几个迭代版本的代码深入了解。 2 v0.1 第一代的版本,foot的位置是提前给定的,只对COG的trajectory进行优化。 2.1 cost 公式 仅仅只考虑加速度, ∫ …...

Channel扇出模式
文章目录 扇出模式reflectSelect 方式 扇出模式 有扇入模式,就有扇出模式,扇出模式是和扇入模式相反的。扇出模式只有一个输入源 Channel,有多个目标 Channel,扇出比就是 1 比目标 Channel 数的值,经常用在设计模式中…...

学者观察 | 联邦学习与区块链、大模型等新技术的融合与挑战-北京航空航天大学童咏昕
导语 当下,数据已成为经济社会发展中不可或缺的生产要素,正在发挥越来越大的价值。但是在数据使用过程中,由于隐私、合规或者无法完全信任合作方等原因,数据的拥有者并不希望彻底和他方共享数据。为解决原始数据自主可控与数据跨…...

ubuntu连接蓝牙耳机
本人也是经历了重重困难,特写此篇希望对读者能够带来帮助 1. 编辑 /etc/bluetooth/main.conf 文件,设定ControllerMode bredr 这一步使用vim编写完成后,保存退出的时候,会显示说没有修改权限,执行以下命令 sudo chm…...

长春理工大学漏洞报送证书
获取来源:edusrc(教育漏洞报告平台) url:主页 | 教育漏洞报告平台 兑换价格:10金币 获取条件:提交长春理工大学任意中危或以上级别漏洞...

Excel和Chatgpt是最好的组合。
内容来源:bitfool1 Excel和Chatgpt是最好的组合。 您可以轻松地自动化数据处理。 我向您展示如何在不打字公式的情况下将AI与Excel一起使用: 建立chatgpt 主要目的是使用Chatgpt自动编写Excel宏。 这消除了键入公式的需求,并让您在自然语言…...

Java用Jsoup库实现的多线程爬虫代码
因为没有提供具体的Python多线程跑数据的内容,所以我们将假设你想要爬取的网站是一个简单的URL。以下是一个基本的Java爬虫程序,使用了Jsoup库来解析HTML和爬虫ip信息。 import org.jsoup.Jsoup; import org.jsoup.nodes.Document; import org.jsoup.nod…...

layui控件开发,实现下拉搜索从数据库获取数据
1 标签部分使用带搜索的下拉框 <div class"layui-inline"><label class"layui-form-label">单位</label><div class"layui-input-inline"><select name"org" lay-search id"org_dwbh" lay-filt…...

让代码变美的第一天 - 观察者模式
文章目录 丑陋的模样变美步骤第一步 - 基本预期第二步 - 核心逻辑梳理第三步 - 重构重构1 - 消息定义重构2 - 消息订阅重构3 - 消息发布 高级用法按顺序订阅异步订阅多消息订阅 丑陋的模样 当我们开发一个功能,代码可能如下: private void test() {fun…...
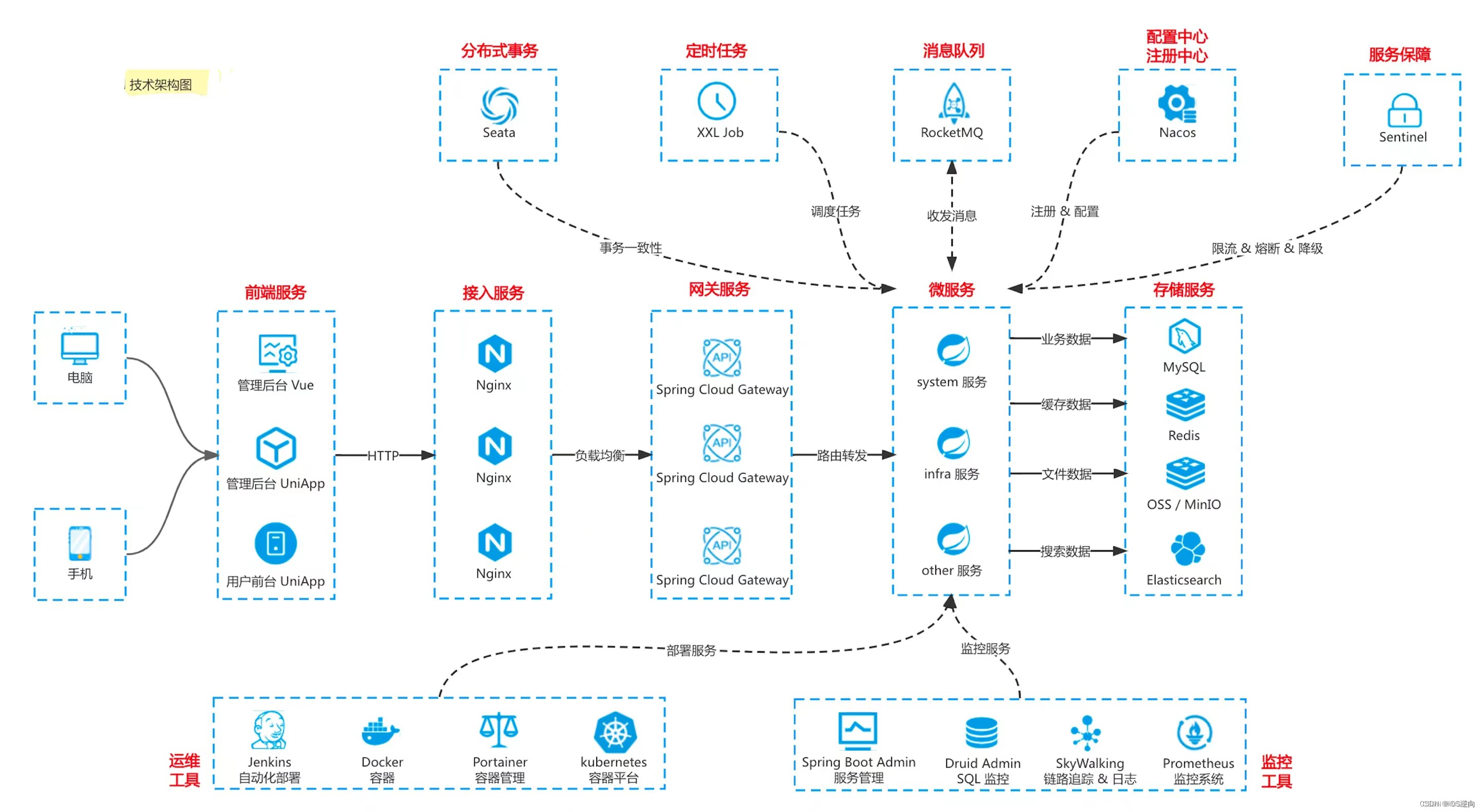
微服务-网关设计
文章目录 引言I 网关部署java启动jar包II 其他服务部署细节2.1 服务端api 版本号III 网关常规设置3.1 外部请求系统服务都需要通过网关访问3.2 第三方平台回调校验文件的配置IV 微服务日志跟踪4.1 打印线程ID4.2 封装线程池任务执行器4.3 将自身MDC中的数据复制给子线程4.4 微服…...

WxJava使用lettuce的redis实现access_token的共享
使用WxJava微信开发时,调用接口获取access_token,如果多个服务部署,就需要使用到缓存来保存access_token以达到重复利用,WxJava 也提供了相关的实现类WxMaRedisConfigImpl,但是这个是基于jedis客户端的实现,…...

干货:如何运作一个全新品牌?
新品牌推广是真金白银的事儿,在你不了解情况的时候,最好以观察为主,不要不管三七二十一就动手。小马识途营销顾问建议创业者首先要找到自己的细分市场,按如下步骤去运作一个新品牌。 第一步、社群试水 先建立一个目标受众的社群&a…...

TCP/IP卷一详解第二章Internet地址结构概要
在这一章中介绍了Internet中使用的网络层地址(也就是IP地址),还有如何为Internet中的设备分配地址,以及各种类型的地址等等…… 一、IP地址的表示 为大家所常见的有IPV4地址和IPV6地址,但在IPV4地址中,通…...

如何在Blender中实现专业级3MF格式导入导出:完整解决方案
如何在Blender中实现专业级3MF格式导入导出:完整解决方案 【免费下载链接】Blender3mfFormat Blender add-on to import/export 3MF files 项目地址: https://gitcode.com/gh_mirrors/bl/Blender3mfFormat Blender3mfFormat是Blender的官方插件,为…...
)
SCI投稿别再卡在Data Availability Statement!手把手教你套用5种期刊模板(含避坑点)
SCI投稿Data Availability Statement终极指南:5种场景模板与高阶避坑策略 凌晨三点的实验室,屏幕荧光映着李博士疲惫的脸——距离投稿截止只剩6小时,却被期刊系统里那个红色星号的"Data Availability Statement"字段卡住了。这不是…...

ESP32/ESP32-S2驱动LCD屏幕选型指南:从SPI到8080,手把手教你避开接口坑
ESP32/ESP32-S2驱动LCD屏幕选型实战:从接口特性到项目适配 当你准备为智能家居控制面板或便携式气象站挑选一块合适的LCD屏幕时,面对SPI、8080等不同接口选项,是否曾陷入技术参数与项目需求的拉锯战?本文将从实际工程角度…...

Flutter for OpenHarmony 第三方库六大核心模块整合实战全解|从图片处理、消息通知到加密存储、设备推送 一站式鸿蒙适配开发总结
Flutter for OpenHarmony 六大核心模块整合实战全解|从图片处理、消息通知到加密存储、设备推送 一站式鸿蒙适配开发总结 欢迎加入开源鸿蒙跨平台社区:https://openharmonycrossplatform.csdn.net 🌿 大家好呀👋!我是…...

别再踩坑了!用DeepSpeed Zero-3跑大模型,记得关掉`low_cpu_mem_usage`和`device_map`
DeepSpeed Zero-3与Hugging Face内存优化选项的兼容性深度解析 当你第一次看到DeepSpeed Zero-3 is not compatible with low_cpu_mem_usageTrue or with passing a device_map这个报错时,可能会感到困惑。毕竟,low_cpu_mem_usage和device_map都是Huggin…...

SPIFFS 组件介绍
简介 在嵌入式应用中,将文件(如配置文件、网页资源或固件数据)存储在 Flash 中是一种非常常见的需求。基于原始 SPIFFS 项目,ESP-IDF 中的 SPIFFS 组件为 SPI NOR Flash 提供了一个轻量级文件系统:它支持磨损均衡、一…...

Blender3mfFormat:Blender专业3D打印格式转换终极指南
Blender3mfFormat:Blender专业3D打印格式转换终极指南 【免费下载链接】Blender3mfFormat Blender add-on to import/export 3MF files 项目地址: https://gitcode.com/gh_mirrors/bl/Blender3mfFormat Blender3mfFormat是一个功能强大的Blender插件…...
的底层逻辑与调试技巧)
UE5编辑器进阶:深入理解‘一个Actor一个文件’(OFPA)的底层逻辑与调试技巧
UE5编辑器进阶:深入理解‘一个Actor一个文件’(OFPA)的底层逻辑与调试技巧 当你在World Partition场景中移动一个静态网格体后,发现关卡文件(.umap)的修改日期纹丝不动,而内容浏览器里却多出一个新生成的.uasset文件—…...

C 盘突然爆满?一次彻底排查与迁移实战:从仅剩 12GB 到释放到 46GB
前言很多人都有一个误区: “软件安装到了 D 盘,C 盘就不会继续变大。”我之前也是这么认为的。 结果实际使用一段时间后,C 盘空间还是一路被吃掉,最后只剩下 12GB 左右,已经开始明显影响系统流畅度和开发环境使用。这次…...

实战案例分享:如何用RexUniNLU零样本处理法律合同文本
实战案例分享:如何用RexUniNLU零样本处理法律合同文本 1. 引言 1.1 法律合同处理的现实困境 想象一下,你是一家公司的法务人员,每天需要审阅几十份合同。这些合同来自不同的供应商、客户和合作伙伴,格式各异,内容繁…...