【Python大数据笔记_day04_Hadoop】
分布式和集群
分布式:多台服务器协同配合完成同一个大任务(每个服务器都只完成大任务拆分出来的单独1个子任务)
集群:多台服务器联合起来独立做相同的任务(多个服务器分担客户发来的请求)
注意:集群如果客户端请求量(任务量)多,多个服务器同时处理不同请求(不同任务),如果请求量少,一台服务器干活,其他服务器备份使用

Hadoop框架
概述
Hadoop简介:是Apache旗下的一个用Java语言实现的存储个计算大规模数据的软件平台.
Hadoop起源:Doug Cutting 创建的最早起源一个Nutch项目.
三驾马车:谷歌的三篇论文加速了Hadoop的研发
Hadoop框架意义:作为大数据解决方案,越来越多的企业将Hadoop技术作为进入大数据领域的必备技术.
狭义上来说:Hadoop指Apache这款开源框架,他的核心组件有:HDFS,MR,YANR
广义上来说:Hadoop通常是指一个更广泛的概念——Hadoop生态圈
Hadoop发行版本:分为开源社区版和商业版
开源社区版:指由Apache软件基金会维护的版本,是官方维护的版本体系,版本丰富,兼容性稍差
商业版:指由第三方商业公司在社区版Hadoop基础上进行了一些修改、整合以及各个组件兼容性测试而发行的版本,如cloudera的CDH等。
版本更新
1.x版本系列: hadoop的第二代开源版本,该版本基本已被淘汰 hadoop组成: HDFS(存储)和MapReduce(计算和资源调度)
2.x版本系列: 架构产生重大变化,引入了Yarn平台等许多新特性 hadoop组成: HDFS(存储)和MapReduce(计算)和YARN(资源调度)
3.x版本系列: 因为2版本的jdk1.7不更新,基于jdk1.8升级产生3版本 hadoop组成: HDFS(存储)和MapReduce(计算)和YARN(资源调度)
Hadoop架构解析[重点]
简单聊下hadoop架构?
当前版本hadoop组成: HDFS , MapReduce ,YARN
HDFS:(分布式文件系统),解决海量数据存储
元数据: 描述核心数据的数据
NameNode:集群当中的主节点,主要用于管理集群当中的各种数据
SecondaryNameNode:主要能用于辅助NameNode进行文件块元数据存储
DataNode:集群当中的从节点,主要用于存储真实的海量的业务数据
YARN:(作业调度和集群资源管理的框架),解决资源任务调度
ResourceManager: 接收用户的计算请求任务,并负责集群的资源管理和分配
NodeManager: 负责执行主节点分配的任务(给MR的计算程序提供资源)
MapReduce:(分布式运算编程框架),解决海量数据计算
如何计算: 核心思想就是分而治之 Map负责分解,Reduce负责合并
MR程序: 使用java/python然后去编写MR程序,成本高 如何解决? 在hive平台上编写sql,执行sql底层自动转为MR程序
MapReduce计算需要的数据和产生的结果需要HDFS来进行存储
MapReduce的运行需要由Yarn集群来提供资源调度。
Hadoop集群启动[练习]
启动
# 一键启动hdfs和yarn集群
[root@node1 ~]# start-all.sh# 单独启动mr计算任务历史服务
[root@node1 ~]# mapred --daemon start historyserver页面
如果没有做一下配置,需要使用ip地址访问:
HDFS: http://192.168.88.161:9870/
YARN: http://192.168.88.161:8088/
jobhistory: http://192.168.88.161:19888/
可以进入C:\Windows\System32\drivers\etc 目录打开hosts文件,添加以下内容:
192.168.88.161 node1
192.168.88.162 node2
192.168.88.163 node3
配置完成后,可以直接通过node1访问
HDFS: http://node1:9870/
YARN: http://node1:8088/
jobhistory: http://node1:19888/
官方示例
在Hadoop的安装包中,官方提供了MapReduce程序的示例examples,以便快速上手体验MapReduce。该示例是使用java语言编写的,被打包成为了一个jar文件。
官方示例jar路径: /export/server/hadoop-3.3.0/share/hadoop/mapreduce
圆周率练习
hadoop jar hadoop-mapreduce-examples-3.3.0.jar pi x y
第一个参数pi:表示MapReduce程序执行圆周率计算;
第二个参数x:用于指定map阶段运行的任务次数,并发度,举例:x=10
第三个参数y:用于指定每个map任务取样的个数,举例: y=50
[root@node1 ~]# cd /export/server/hadoop-3.3.0/share/hadoop/mapreduce
[root@node1 mapreduce]# hadoop jar hadoop-mapreduce-examples-3.3.0.jar pi 10 50
...
Job Finished in 29.04 seconds
Estimated value of Pi is 3.16000000000000000000词频统计[重点]
需求:
WordCount算是大数据统计分析领域的经典需求了,相当于编程语言的HelloWorld。统计文本数据中, 相同单词出现的总次数。用SQL的角度来理解的话,相当于根据单词进行group by分组,相同的单词 分为一组,然后每个组内进行count聚合统计。 已知hdfs中word.txt文件内容如下,计算每个单词出现的次数
步骤
1.HDFS根目录中创建input目录,存储word.txt文件
可以在window本地提前创建word.txt文件存储,内容如下:
zhangsan lisi wangwu zhangsan
zhaoliu lisi wangwu zhaoliu
xiaohong xiaoming hanmeimei lilei
zhaoliu lilei hanmeimei lilei


2.在shell命令行中执行如下命令
[root@node1 ~]# cd /export/server/hadoop-3.3.0/share/hadoop/mapreduce
[root@node1 mapreduce]# hadoop jar hadoop-mapreduce-examples-3.3.0.jar wordcount /input /output3.去HDFS中查看是否生成output目录
注意: output输出目录,在执行第2步命令后会自动生成,如果提前手动创建或者已经存在,就会报以下错误:
org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory hdfs://node1.itcast.cn:8020/output already exists
4.进入output目录查看part-r-00000文件,结果如下:
hanmeimei 2
lilei 3
lisi 2
wangwu 2
xiaohong 1
xiaoming 1
zhangsan 2
zhaoliu 3
Hadoop-HDFS
特点
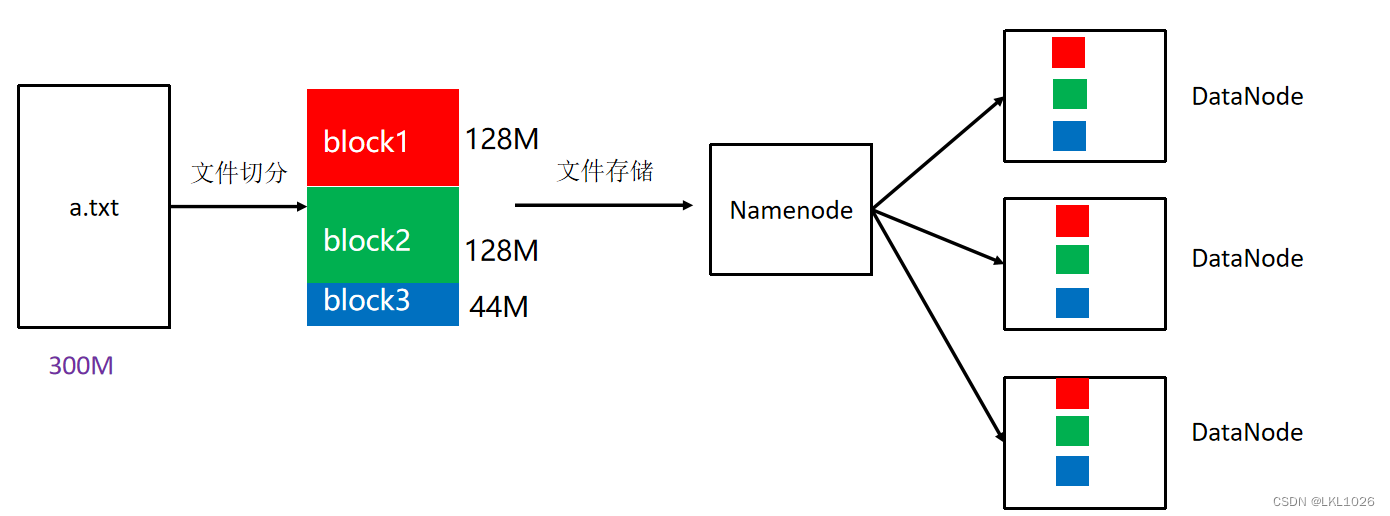
HDFS存储大文件,把大文件默认切割成128M大小的block块,进行存储
HDFS存储块的时候,会给每个块进行备份(一共三份)
HDFS文件系统可存储超大文件,时效性稍差。
HDFS具有硬件故障检测和自动快速恢复功能。
HDFS为数据存储提供很强的扩展能力。
HDFS存储一般为一次写入,多次读取,只支持追加写入,不支持随机修改。
HDFS可在普通廉价的机器上运行。
架构
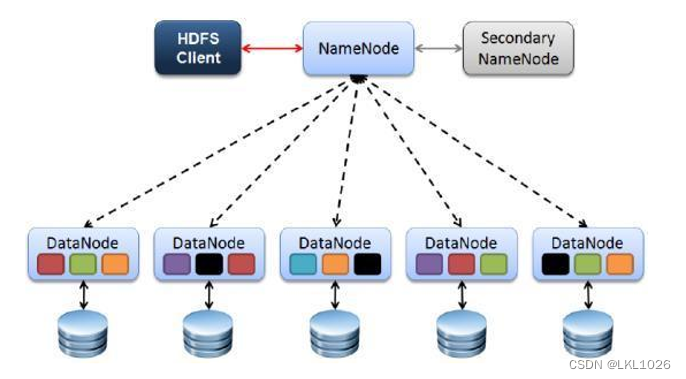
1、Client
发请求就是客户端。
文件切分。文件上传 HDFS 的时候,Client 将文件切分成 一个一个的Block,然后进行存储
与 NameNode 交互,获取文件的位置信息。
与 DataNode 交互,读取或者写入数据。
Client 提供一些命令来管理 和访问HDFS,比如启动或者关闭HDFS。
2、NameNode
就是 master,它是一个主管、管理者。
处理客户端读写请求。
管理 HDFS 元数据(文件路径,文件的大小,文件的名字,文件权限,文件切割后的块(block)信息…)。
配置3副本备份策略。
3、DataNode
就是Slave。NameNode 下达命令,DataNode 执行实际的操作。
存储实际的数据块(block)。
执行数据块的读/写操作。
定时向namenode汇报block信息。
4、Secondary NameNode
并非 NameNode 的备份节点。当NameNode 挂掉的时候,它并不能马上替换 NameNode 并提供服务。
只是辅助 NameNode,对HDFS元数据进行合并,合并后再交给NameNode。
在紧急情况下,可辅助恢复 NameNode 部分数据。
副本
block块: HDFS被设计成能够在一个大集群中跨机器可靠地存储超大文件。它将每个文件拆分成一系列的数据块进行存储,这个数据块被称为block,除了最后一个,所有的数据块都是同样大小的。
block 块大小默认: 128M(134217728字节)
注意: 为了容错,文件的所有block都会有副本。每个文件的数据块大小和副本系数都是可配置的。
副本系数默认: 3个hdfs默认文件: https://hadoop.apache.org/docs/r3.3.4/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
shell命令
hdfs的shell命令概念: 安装好hadoop环境之后,可以执行类似于Linux的shell命令对文件的操作,如ls、mkdir、rm等,对hdfs文件系统进行操作查看,创建,删除等。
hdfs的shell命令格式1: hadoop fs -命令 参数
hdfs的shell命令格式2: hdfs dfs -命令 参数hdfs的家目录默认: /user/root 如果在使用命令操作的时候没有加根目录/,默认访问的是此家目录/user/root
查看目录下内容: hdfs dfs -ls 目录的绝对路径
创建目录: hdfs dfs -mkdir 目录的绝对路径
创建文件: hdfs dfs -touch 文件的绝对路径
移动目录/文件: hdfs dfs -mv 要移动的目录或者文件的绝对路径 目标位置绝对路径
复制目录/文件: hdfs dfs -cp 要复制的目录或者文件的绝对路径 目标位置绝对路径
删除目录/文件: hdfs dfs -rm [-r] 要删除的目录或者文件的绝对路径
查看文件的内容: hdfs dfs -cat 要查看的文件的绝对路径 注意: 除了cat还有head,tail也能查看
查看hdfs其他shell命令帮助: hdfs dfs --help
注意: hdfs有相对路径,如果操作目录或者文件的时候没有以根目录/开头,就是相对路径,默认操作的是/user/root把本地文件内容追加到hdfs指定文件中: hdfs dfs -appendToFile 本地文件路径 hdfs文件绝对路径
注意: window中使用页面可以完成window本地和hdfs的上传下载,当然linux中使用命令也可以完成文件的上传和下载
linux本地上传文件到hdfs中: hdfs dfs -put linux本地要上传的目录或者文件路径 hdfs中目标位置绝对路径
hdfs中下载文件到liunx本地: hdfs dfs -get hdfs中要下载的目录或者文件的绝对路径 linux本地目标位置路径
Hive环境准备[重点]
shell脚本执行方式
方式1: sh 脚本 注意: 需要进入脚本所在目录,但脚本有没有执行权限不影响执行
方式2: ./脚本 注意: 需要进入脚本所在目录,且脚本必须有执行权限
方式3: /绝对路径/脚本 注意: 不需要进入脚本所在目录,但必须有执行权限
方式4: 脚本 注意: 需要配置环境变量(大白话就是把脚本所在路径共享,任意位置都能直接访问)
配置Hive环境变量
[root@node1 /]# vim /etc/profile在profile文件末尾添加(小技巧G+o快速定位到最后) export HIVE_HOME=/export/server/apache-hive-3.1.2-bin export PATH=$PATH:$HIVE_HOME/bin:$HIVE_HOME/sbin
[root@node1 /]# source /etc/profile最后建议关机拍摄下快照
先启动hive服务
知识点:
后台启动metastore服务: nohup hive --service metastore &
后台启动hiveserver2服务: nohup hive --service hiveserver2 &
查看metastore和hiveserver2进程是否启动: jps 注意: 服务名都叫RunJar,可以通过进程编号区分
服务启动需要一定时间可以使用lsof查看: lsof -i:10000 注意: 如果无内容继续等待,如果有内容代表启动成功
示例:
[root@node1 bin]# nohup hive --service metastore &
[1] 13490
nohup: 忽略输入并把输出追加到"nohup.out"
回车[root@node1 bin]# nohup hive --service hiveserver2 &
[2] 13632
nohup: 忽略输入并把输出追加到"nohup.out"
回车[root@node1 bin]# jps
...
13490 RunJar
13632 RunJar[root@node1 bin]#
# 注意:10000端口号一般需要等待3分钟左右才会查询到
[root@node1 bin]# lsof -i:10000
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
java 18804 root 520u IPv6 266172 0t0 TCP *:ndmp (LISTEN)
# 此处代表hive启动成功,今日内容完成再连接hive服务
知识点:
一代客户端连接命令: hive 注意: hive直接连接成功,直接可以编写sql语句
二代客户端连接命令: beeline 注意: 以后建议用二代客户端
二代客户端远程连接命令: !connect jdbc:hive2://node1:10000
注意: hive用户名是root 密码为空
一代客户端示例:
[root@node1 /]# hive
...
hive> show databases;
OK
default
Time taken: 0.5 seconds, Fetched: 1 row(s)
hive> exit;二代客户端示例:
[root@node1 /]# beeline# 先输入!connect jdbc:hive2://node1:10000连接
beeline> !connect jdbc:hive2://node1:10000# 再输入用户名root,密码不用输入直接回车即可
Enter username for jdbc:hive2://node1:10000: root
Enter password for jdbc:hive2://node1:10000:# 输入show databases;查看表
0: jdbc:hive2://node1:10000> show databases;
INFO : Concurrency mode is disabled, not creating a lock manager
+----------------+
| database_name |
+----------------+
| default |
+----------------+
1 row selected (1.2 seconds)相关文章:
【Python大数据笔记_day04_Hadoop】
分布式和集群 分布式:多台服务器协同配合完成同一个大任务(每个服务器都只完成大任务拆分出来的单独1个子任务) 集群:多台服务器联合起来独立做相同的任务(多个服务器分担客户发来的请求) 注意:集群如果客户端请求量(任务量)多,多个服务器同时处理不同请求(不同任务),如果请求量…...

Android超简单的显示网络图片方法
Android显示网络图片的方法如下: 1、首先,需要在AndroidManifest.xml文件中添加网络权限: <uses-permission android:name"android.permission.INTERNET" /> 2、在布局文件中添加ImageView控件: <ImageVie…...

基于自然语言处理的结构化数据库问答机器人系统
温馨提示:文末有 CSDN 平台官方提供的学长 Wechat / QQ 名片 :) 1. 项目简介 知识库,就是人们总结出的一些历史知识的集合,存储、索引以后,可以被方便的检索出来供后人查询/学习。QnA Maker是用于建立知识库的工具,使用…...

JVM Native内存泄露的排查分析(64M 问题)
我们有一个线上的项目,刚启动完就占用了使用 top 命令查看 RES 占用了超过 1.5G,这明显不合理,于是进行了一些分析找到了根本的原因,下面是完整的分析过程,希望对你有所帮助。 会涉及到下面这些内容 Linux 经典的 64M…...
智能网联汽车基础软件信息安全需求分析
目录 1.安全启动 2.安全升级 3.安全存储 4.安全通信 5.安全调试 6.安全诊断 7.小结 1.安全启动 对于MCU,安全启动主要是以安全岛BootROM为信任根,在MCU启动后,用户程序运行前,硬件加密模块采用逐级校验、并行校验或者混合校…...

《QT从基础到进阶·十八》QT中的各种鼠标事件QEvent
1、界面标题栏事件: NonClientAreaMouseButtonPress 标题栏点击事件 NonClientAreaMouseButtonRelease 标题栏释放事件 bool CustomPopDialog::event(QEvent* event) {switch (event->type()){case QEvent::MouseButtonRelease://Event of mouse releasing wind…...

CSDN中调整图片和文本样式
1.调整图片比例 插入图片后,觉得图片比例不协调,想改小点。只需要在文件后缀加个参数即可:?pic_center 60x。 NOTE:等号左边一定要加个空格,否则格式不生效 2.修改字体颜色 如上 NOTE:等号左边一定要…...

社区团购商品数据抓取
爬虫程序的实现需要使用到C#编程语言以及相关爬虫框架,如Scrapy、WebScraper等。以下是一个简单的示例,展示了如何使用C#爬取网站上的商品数据: using System; using System.Net; using System.IO; using HtmlAgilityPack;class Program {st…...

Nginx用做sip代理
https://www.jianshu.com/p/14d134cbf8d3?tdsourcetags_pcqq_aiomsg 看了这篇文章的方案一,我专门试了试,记录如下: 测试环境为: fs1(5080 --- nginx --- fs2(5060) 局域网同一个网段&…...

C# set的一些使用方法
在C#应用中,使用set监控值的改变触发事件是一种非常常见的编程模式。 比如下面一些应用。 1、属性更改通知:当某个属性的值发生变化时,可以使用set监控属性的改变,并触发一个事件来通知其他部分代码。这在MVVM(Model…...
机器学习——回归
目录 一、线性回归 1、回归的概念(Regression、Prediction) 2、符号约定 3、算法流程 4、最小二乘法(LSM) 二、梯度下降 梯度下降的三种形式 1、批量梯度下降(Batch Gradient Descent,BGD)ÿ…...
JAVA代码视频转GIF(亲测有效)
1.说明 本次使用的是JAVA代码视频转GIF,maven如下: <dependency><groupId>ws.schild</groupId><artifactId>jave-nativebin-win64</artifactId><version>3.2.0</version></dependency><dependency&…...
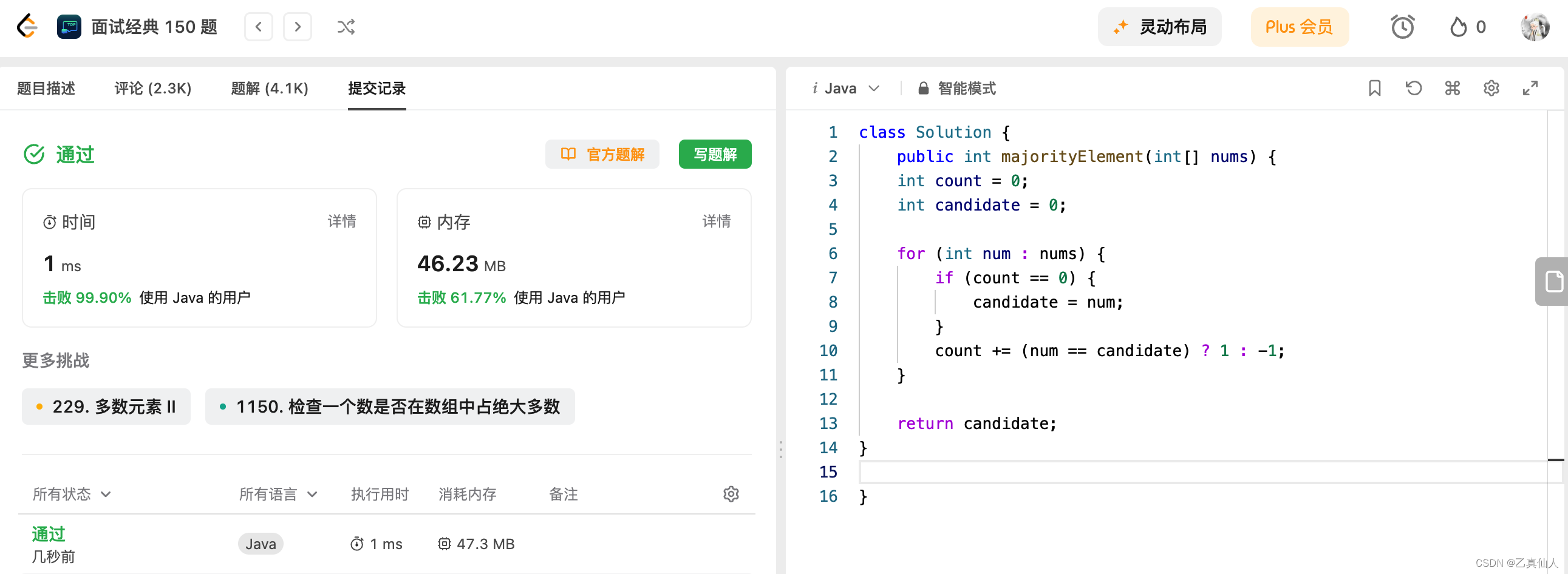
挑战100天 AI In LeetCode Day03(热题+面试经典150题)
挑战100天 AI In LeetCode Day03(热题面试经典150题) 一、LeetCode介绍二、LeetCode 热题 HOT 100-52.1 题目2.2 题解 三、面试经典 150 题-53.1 题目3.2 题解 一、LeetCode介绍 LeetCode是一个在线编程网站,提供各种算法和数据结构的题目&am…...
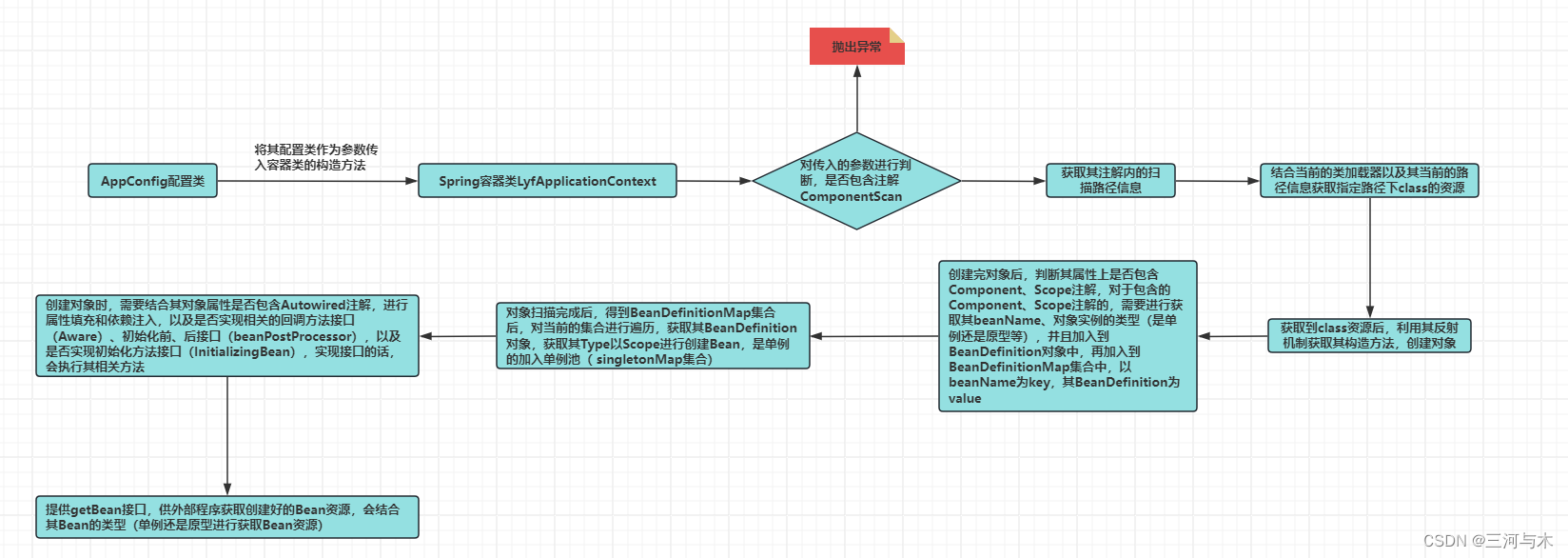
【手写模拟Spring底层原理】
文章目录 模拟Spring底层详解1、结合配置类,扫描类资源1.1、创建需要扫描的配置类AppConfig,如下:1.2、创建Spring容器对象LyfApplicationContext,如下1.3、Spring容器对象LyfApplicationContext扫描资源 2、结合上一步的扫描&…...

代码随想录训练营Day1:二分查找与移除元素
本专栏内容为:代码随想录训练营学习专栏,用于记录训练营的学习经验分享与总结。 文档讲解:代码随想录 视频讲解:二分查找与移除元素 💓博主csdn个人主页:小小unicorn ⏩专栏分类:C 🚚…...
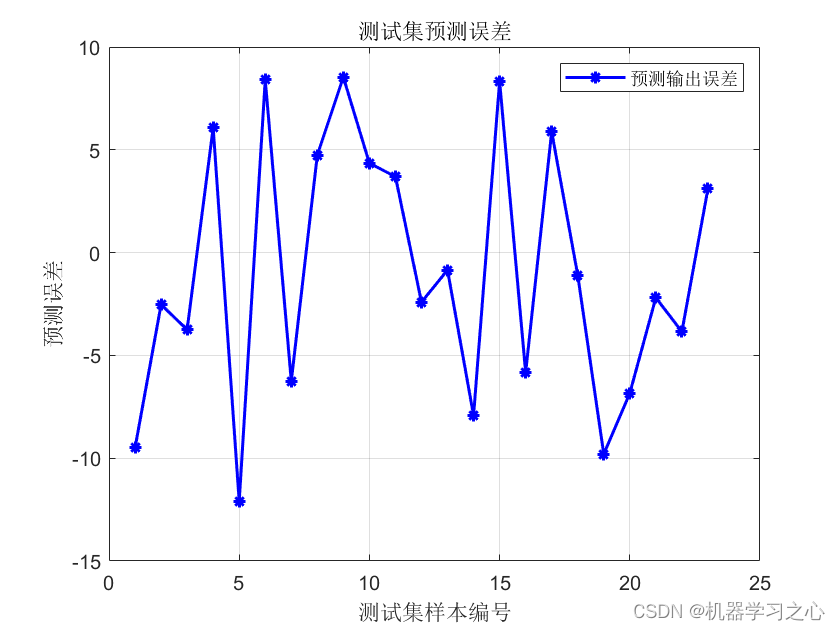
回归预测 | Matlab实现PCA-PLS主成分降维结合偏最小二乘回归预测
回归预测 | Matlab实现PCA-PLS主成分降维结合偏最小二乘回归预测 目录 回归预测 | Matlab实现PCA-PLS主成分降维结合偏最小二乘回归预测效果一览基本介绍程序设计参考资料 效果一览 基本介绍 Matlab实现PCA-PLS主成分降维结合偏小二乘回归预测(完整源码和数据) 1.输…...

高效的测试覆盖率:在更短的时间内最大化提高测试覆盖率
软件测试在敏捷开发生命周期中至关重要,而测试覆盖率又是软件测试的一个重要指标,有效的测试覆盖率对软件测试来说永远是重中之重。测试覆盖率确保所有关键功能和特性都经过彻底测试,减少最终产品中出现错误和错误的可能性(取决于…...
Qt 项目实战 | 音乐播放器
Qt 项目实战 | 音乐播放器 Qt 项目实战 | 音乐播放器播放器整体架构创建播放器主界面媒体对象状态实现播放列表实现桌面歌词添加系统托盘图标 资源下载 官方博客:https://www.yafeilinux.com/ Qt开源社区:https://www.qter.org/ 参考书:《Q…...

JavaScript使用Ajax
Ajax(Asynchronous JavaScript and XML)是使用JavaScript脚本,借助XMLHttpRequest插件,在客户端与服务器端之间实现异步通信的一种方法。2005年2月,Ajax第一次正式出现,从此以后Ajax成为JavaScript发起HTTP异步请求的代名词。2006…...
Python爬虫实战-批量爬取美女图片网下载图片
大家好,我是python222小锋老师。 近日锋哥又卷了一波Python实战课程-批量爬取美女图片网下载图片,主要是巩固下Python爬虫基础 视频版教程: Python爬虫实战-批量爬取美女图片网下载图片 视频教程_哔哩哔哩_bilibiliPython爬虫实战-批量爬取…...
)
中国药科大学赵玉成、徐健/皖西学院韩邦兴ACS Catal|元胡中痕量高效镇痛活性成分左旋紫堇达明生物合成最后缺失步骤的解析(附招聘信息)
遇见/摘要延胡索Corydalis yanhusuo W. T. Wang,又称元胡,属于罂粟科紫堇属植物,是传统常用大宗中药,也是浙江道地药材“浙八味”之一。苄基异喹啉生物碱(BIAs)是延胡索的主要活性成分,如延胡索…...

NCM文件解密终极指南:快速免费转换网易云音乐加密格式
NCM文件解密终极指南:快速免费转换网易云音乐加密格式 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 你是否曾遇到过从网易云音乐下载的歌曲只能在特定软件中播放的困扰?🤔 那些以.ncm为扩展名的…...

2025终极指南:如何用LinkSwift实现八大网盘高速下载的5大技术优势
2025终极指南:如何用LinkSwift实现八大网盘高速下载的5大技术优势 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动…...

不只是数据通道:用TMS320F28374S的CLB X-BAR和ePWM X-BAR设计灵活的保护与同步逻辑
TMS320F28374S的X-BAR系统:构建高可靠性实时控制架构的神经中枢 在工业电机驱动和数字电源系统中,毫秒级的延迟可能导致灾难性后果。当电流传感器检测到过载信号时,系统需要在微秒级别内切断PWM输出,同时触发保护逻辑链。传统的中…...

告别纯Client模式:手把手教你用CANoe的NetWork Node搭建一个实时监控Server
从被动监听转向主动响应:基于CANoe NetWork Node的车载实时监控系统实战 在传统车载网络测试中,工程师们往往将CANoe作为被动监听工具,通过Trace窗口观察总线数据流。这种"只读"模式虽然能满足基础测试需求,但当面对需要…...

5个实用技巧:用Marp打造专业级移动端演示文稿
5个实用技巧:用Marp打造专业级移动端演示文稿 【免费下载链接】marp The entrance repository of Markdown presentation ecosystem 项目地址: https://gitcode.com/gh_mirrors/mar/marp Marp是一个基于Markdown的演示文稿生态系统,让开发者能够用…...

Valorant DirectX 11崩溃稳定教程:更新后闪退进不去?
每次大版本更新后,总有一批玩家会遇到闪退进不去游戏的情况。这并非个例,通常是因为新版本的游戏客户端对系统环境提出了新的要求,或者更新包与当前驱动、反作弊模块产生了兼容性摩擦。解决更新后闪退的核心思路是:先让新文件和旧…...

Reference Extractor:如何高效提取Word文档中的Zotero和Mendeley引用?
Reference Extractor:如何高效提取Word文档中的Zotero和Mendeley引用? 【免费下载链接】ref-extractor Reference Extractor - Extract Zotero/Mendeley references from Microsoft Word files 项目地址: https://gitcode.com/gh_mirrors/re/ref-extra…...

鸿蒙PC开发的Slider组件blockSize参数的类型要求
踩坑记录06:Slider组件blockSize参数的类型要求 阅读时长:7分钟 | 难度等级:初级 | 适用版本:HarmonyOS NEXT (API 12) 关键词:Slider、blockSize、SizeOptions、原生组件 声明:本文基于真实项目开发经历编…...

不用改代码!一招搞定ABAP程序间ALV数据抓取,CL_SALV_BS_RUNTIME_INFO实战详解
零侵入式ALV数据捕获:CL_SALV_BS_RUNTIME_INFO高阶应用指南 在SAP系统运维和二次开发中,我们常常需要从标准报表或他人开发的ALV程序中提取数据,却苦于没有修改权限或不愿影响原有程序稳定性。传统方案往往需要修改源码导出数据,而…...