【大数据Hadoop】Hadoop 3.x 新特性总览
Hadoop 3.x 新特性剖析系列1
- 1. 概述
- 2. 内容
- 2.1 JDK
- 2.2 EC技术
- 2.3 YARN的时间线V.2服务
- 2.3.1 伸缩性
- 2.3.2 可用性
- 2.3.3 架构体系
- 2.4 优化Hadoop Shell脚本
- 2.5 重构Hadoop Client Jar包
- 2.6 支持等待容器和分布式调度
- 2.7 支持多个NameNode节点
- 2.8 默认的服务端口被修改
- 2.9 支持文件系统连接器
- 2.10 DataNode内部负载均衡
1. 概述
从功能上来说,Hadoop3比Hadoop2有些功能得到了增强,具体增加了哪些,后面再讲。首先,我们来看看Hadoop3主要带来了哪些变化:
- JDK:在Hadoop2时,可以使用JDK7,但是在Hadoop3中,最低版本要求是JDK8,所以低于JDK8的版本需要对JDK进行升级,方可安装使用Hadoop3
- EC技术:Erasure Encoding 简称EC,是Hadoop3给HDFS拓展的一种新特性,用来解决存储空间文件。EC技术既可以防止数据丢失,又能解决HDFS存储空间翻倍的问题
- YARN:提供YARN的时间轴服务V.2,以便用户和开发人员可以对其进行测试,并提供反馈意见,使其成为YARN Timeline Service v.1的替代品。
- 优化Hadoop Shell脚本
- 重构Hadoop Client Jar包
- 支持随机Container
- 支持多个NameNode
- 部分默认服务端口被改变
- 支持文件系统连接器
- DataNode内部添加了负载均衡
2. 内容
2.1 JDK
在Hadoop 3中,所有的Hadoop JAR包编译的环境都是基于Java8来完成的,所有如果仍然使用的是Java 7或者更低的版本,你可能需要升级到Java 8才能正常的运行Hadoop3。如下图所示:

2.2 EC技术
首先,我们先来了解一下什么是Erasure Encoding。如下图所示:

一般来说,在存储系统中,EC技术主要用于廉价磁盘冗余阵列,即RAID。如上图,RAID通过Stripping实现EC技术,其中逻辑顺序数据(比如:文件)被划分成更小的单元(比如:位、字节或者是块),并将连续单元存储在不同的磁盘上。
然后,对原始数据单元的每个Stripe,计算并存储一定数量的奇偶校验单位。这个过程称之为编码,通过基于有效数据单元和奇偶校验单元的解码计算,可以恢复任意Stripe单元的错误。当我们想到了擦除编码的时候,我们可以先来了解一下在Hadoop2中复制的早期场景。如下图所示:

HDFS默认情况下,它的备份系数是3,一个原始数据块和其他2个副本。其中2个副本所需要的存储开销各站100%,这样使得200%的存储开销,会消耗其他资源,比如网络带宽。然而,在正常操作中很少访问具有低IO活动的冷数据集的副本,但是仍然消耗与原始数据集相同的资源量。
对于EC技术,即擦除编码存储数据和提供容错空间较小的开销相比,HDFS复制,EC技术可以代替复制,这将提供相同的容错机制,同时还减少了存储开销。如下图所示:

EC和HDFS的整合可以保持与提供存储效率相同的容错。例如,一个副本系数为3,要复制文件的6个块,需要消耗6*3=18个块的磁盘空间。但是,使用EC技术(6个数据块,3个奇偶校验块)来部署,它只需要消耗磁盘空间的9个块(6个数据块+3个奇偶校验块)。这些与原先的存储空间相比较,节省了50%的存储开销。
由于擦除编码需要在执行远程读取时,对数据重建带来额外的开销,因此他通常用于存储不太频繁访问的数据。在部署EC之前,用户应该考虑EC的所有开销,比如存储、网络、CPU等。
2.3 YARN的时间线V.2服务
Hadoop引入YARN Timeline Service v.2是为了解决两个主要问题:
- 提高时间线服务的可伸缩性和可靠性;
- 通过引入流和聚合来增强可用性
下面首先,我们来剖析一下它伸缩性。
2.3.1 伸缩性
YARN V1仅限于读写单个实例,不能很好的扩展到小集群之外。YARN V2使用了更具有伸缩性的分布式体系架构和可扩展的后端存储,它将数据的写入与数据的读取进行了分离。并使用分布式收集器,本质上是每个YARN应用的收集器。读则是独立的实例,专门通过REST API服务来查询
2.3.2 可用性
对于可用性的改进,在很多情况下,用户对流或者YARN应用的逻辑组的信息比较感兴趣。启动一组或者一系列的YARN应用程序来完成逻辑应用是很常见的。如下图所示:

2.3.3 架构体系
YARN时间线服务V2采用了一组收集器写数据到后端进行存储。收集器被分配并与它们专用的应用程序主机进行协作,如下图所示,属于该应用程序的所有数据都被发送到应用程序时间轴的收集器中,但是资源管理器时间轴收集器除外。

对于给定的应用程序,应用程序可以将数据写入同一时间轴收集器中。此外,为应用程序运行容器的其他节点的节点管理器,还会向运行应用程序主节点的时间轴收集器写入数据。资源管理器还维护自己的时间手机线收集器,它只发布YARN的通用生命周期事件,以保持其写入量合理。时间的读取器是单独的守护进程从收集器中分离出来的,它旨在服务于REST API查询操作。
2.4 优化Hadoop Shell脚本
Hadoop Shell脚本已经被重写,用来修复已知的BUG,解决兼容性问题和一些现有安装的更改。它还包含了一些新的特性,内容如下所示:
所有Hadoop Shell脚本子系统现在都会执行hadoop-env.sh这个脚本,它允许所有环节变量位于一个位置;
守护进程已通过*-daemon.sh选项从*-daemon.sh移动到了bin命令中,在Hadoop3中,我们可以简单的使用守护进程来启动、停止对应的Hadoop系统进程;
触发SSH连接操作现在可以在安装时使用PDSH;
${HADOOP_CONF_DIR}现在可以任意配置到任何地方;
脚本现在测试并报告守护进程启动时日志和进程ID的各种状态;
2.5 重构Hadoop Client Jar包
Hadoop2 中可用的Hadoop客户端将Hadoop的传递依赖性拉到Hadoop应用程序的类路径上。如果这些传递依赖项的版本与应用程序使用的版本发送冲突,这可能会产生问题。
因此,在Hadoop3中有新的Hadoop客户端API和Hadoop客户端运行时工件,它们将Hadoop的依赖性遮蔽到单个JAR中,Hadoop客户端API是编译范围,Hadoop客户端运行时是运行时范围,它包含从Hadoop客户端重新定位的第三方依赖关系。因此,你可以将依赖项绑定到JAR中,并测试整个JAR以解决版本冲突。这样避免了将Hadoop的依赖性泄露到应用程序的类路径上。例如,HBase可以用来与Hadoop集群进行数据交互,而不需要看到任何实现依赖。
2.6 支持等待容器和分布式调度
在Hadoop3 中引入了一种新型执行类型,即等待容器,即使在调度时集群没有可用的资源,它也可以在NodeManager中被调度执行。在这种情况下,这些容器将在NM中排队等待资源启动,等待荣容器比默认容器优先级低,因此,如果需要,可以抢占默认容器的空间,这样可以提供机器的利用率。如下图所示:

默认容器对于现有的YARN容器,它们由容量调度分配,一旦被调度到节点,就保证有可用的资源使它们执行立即开始。此外,只要没有故障发生,这些容器就可以允许完毕。
等待容器默认由中心RM分配,但还增加了支持以允许等待容器被分布式调度,该调度群被实现于AM和RM协议的拦截器。
2.7 支持多个NameNode节点
在Hadoop2中,HDFS NameNode高可用体系结构有一个Active和Standby NameNode,通过JournalNodes,该体系结构能够容忍任何一个NameNode失败。
然而,业务关键部署需要更高程度的容错性。因此,在Hadoop3中允许用户运行多个备用的NameNode。例如,通过配置三个NameNode(1个Active NameNode和2个Standby NameNode)和5个JournalNodes节点,集群可以容忍2个NameNode节点故障。如下图所示:

2.8 默认的服务端口被修改
早些时候,多个Hadoop服务的默认端口位于Linux端口范围以内。除非客户端程序明确的请求特定的端口号,否则使用的端口号是临时的,因此,在启动时,服务有时会因为与其他另一个应用程序冲突而无法绑定到端口。
因此,具有临时范围冲突端口已经被移除该范围,影响多个服务的端口号,即NameNode、Secondary NameNode、DataNode等如下所示:
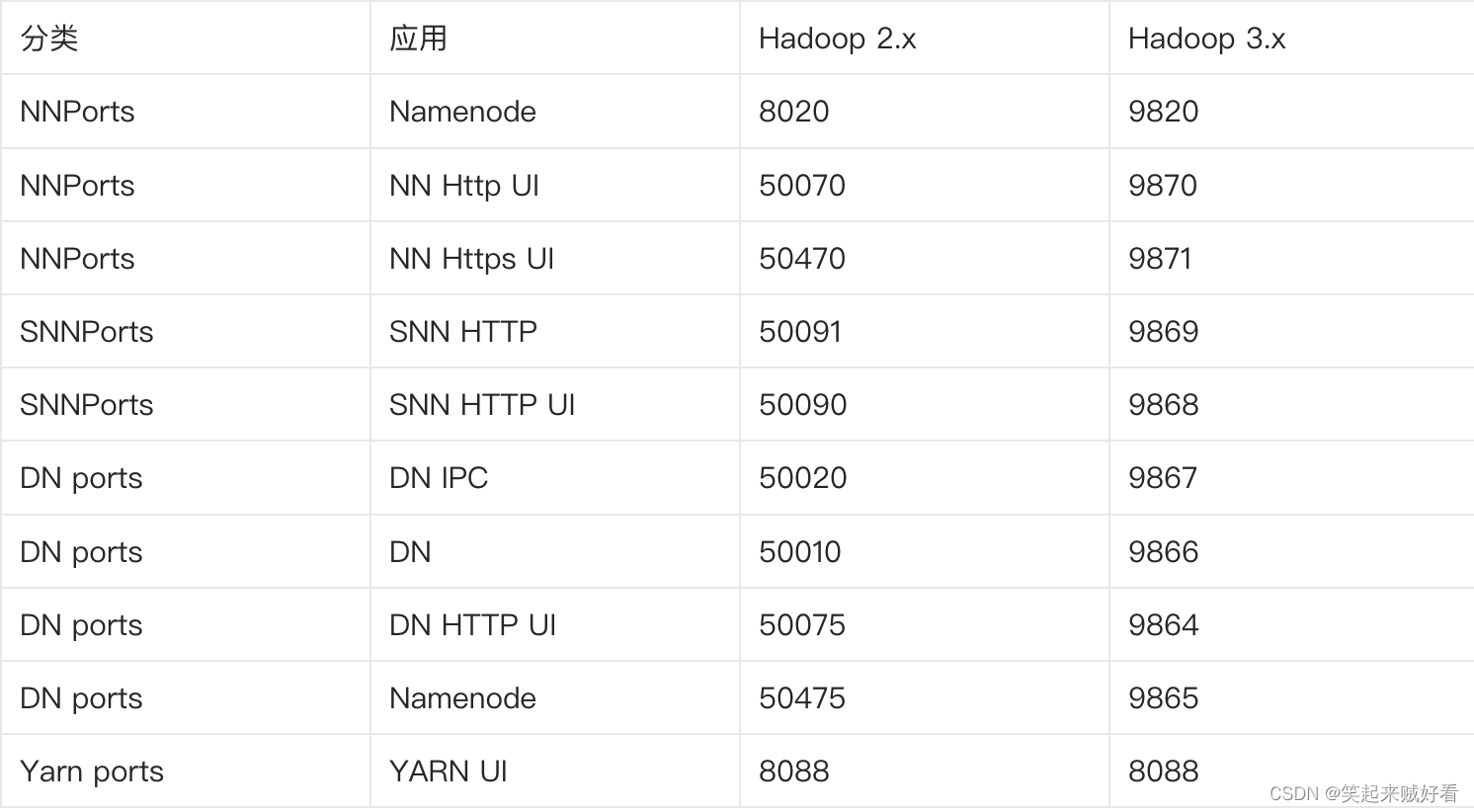
2.9 支持文件系统连接器
Hadoop现在支持与微软 Azure数据和阿里云对象存储系统的集成。它可以作为一种替代Hadoop兼容的文件系统,首先添加微软Azure数据,然后添加阿里云对象存储系统。
2.10 DataNode内部负载均衡
单个数据节点配置多个数据磁盘,在正常写入操作期间,数据被均匀的划分,因此,磁盘被均匀填充。但是,在维护磁盘时,添加或者替换磁盘会导致DataNode节点存储出现偏移,这种情况在早期的HDFS文件系统中,是没有被处理的。如图下图所示,维护前和维护后不均衡的情况:

现在Hadoop3通过新的内部DataNode平衡功能来处理这种情况,这是通过hdfs diskbalancer CLI来进行调用的。执行之后,DataNode会进行均衡处理,如下图所示:

相关文章:
【大数据Hadoop】Hadoop 3.x 新特性总览
Hadoop 3.x 新特性剖析系列11. 概述2. 内容2.1 JDK2.2 EC技术2.3 YARN的时间线V.2服务2.3.1 伸缩性2.3.2 可用性2.3.3 架构体系2.4 优化Hadoop Shell脚本2.5 重构Hadoop Client Jar包2.6 支持等待容器和分布式调度2.7 支持多个NameNode节点2.8 默认的服务端口被修改2.9 支持文件…...

Python-第三天 Python判断语句
Python-第三天 Python判断语句一、 布尔类型和比较运算符1.布尔类型2.比较运算符二、if语句的基本格式1.if 判断语句语法2.案例三、 if else 语句1.语法2.案例四 if elif else语句1.语法五、判断语句的嵌套1.语法六、实战案例一、 布尔类型和比较运算符 1.布尔类型 布尔&…...

失手删表删库,赶紧跑路?!
在数据资源日益宝贵的数字时代公司最怕什么?人还在,库没了是粮库、车库,还是小金库?实际上,这里的“库”是指的数据库Ta是公司各类信息的保险柜小到企业官网和客户信息大到金融机构的资产数据和国家秘密即便没有跟数据…...
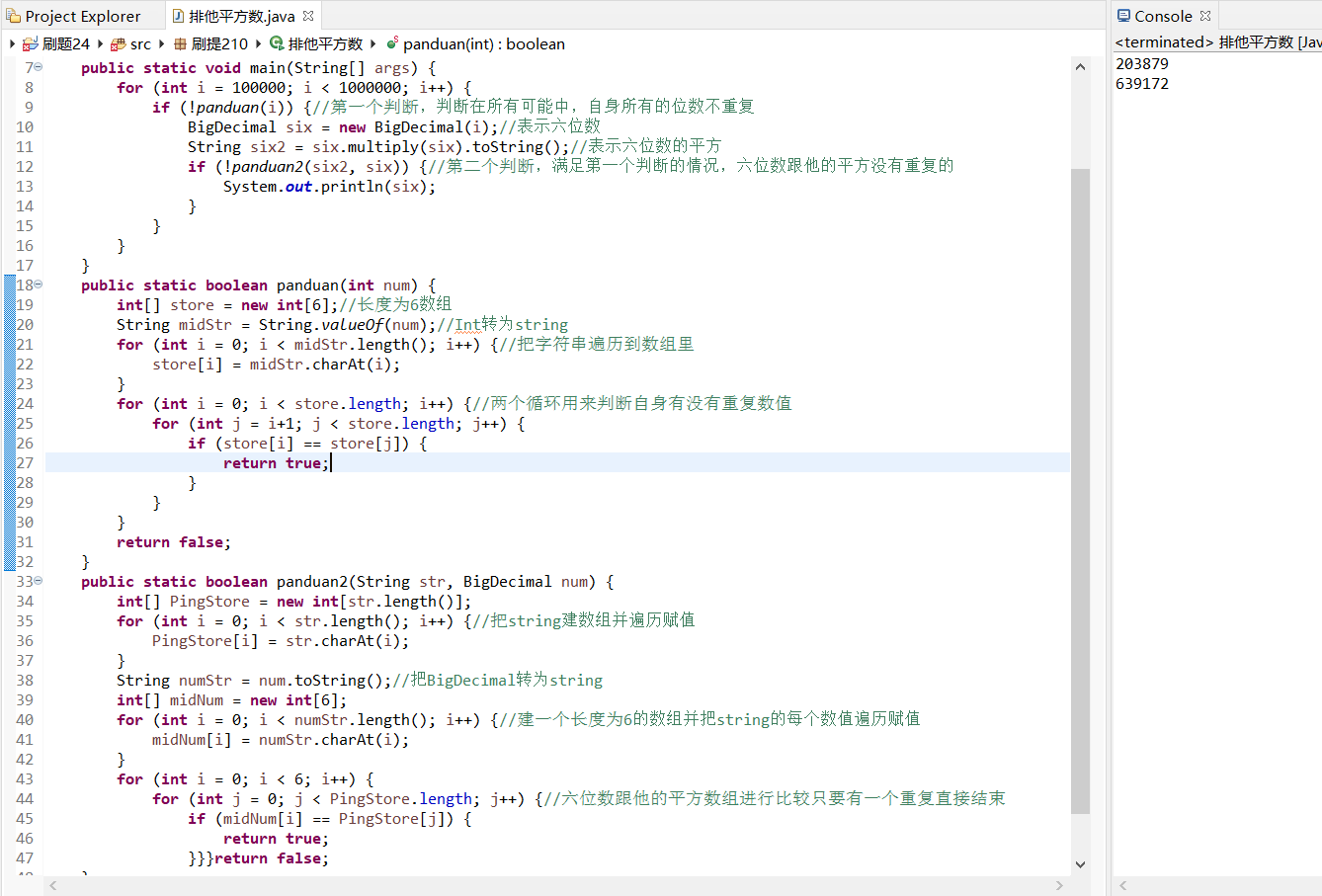
技术树基础——16排它平方数(Bigdecimal,int,string,数组的转换)
题目:03879 * 203879 41566646641这有什么神奇呢?仔细观察,203879 是个6位数,并且它的每个数位上的数字都是不同的,并且它平方后的所有数位上都不出现组成它自身的数字。具有这样特点的6位数还有一个,请你…...

04动手实践:手把手带你实现gRPC的Hello World
这篇文章就从实践的角度出发,带大家一起体验一下gRPC的Hello World。文中的代码将全部使用Go语言实现,使用到的示例也是GitHub上提供的grpc-go,下面我们开始: Hello World官方示例 首先我们要clone GitHub上gRPC的源代码到我们本地 git clone https://github.com/grpc/g…...

区块链技术与应用1——BTC-密码学原理
文章目录比特币中的密码学原理1. 哈希函数2. 数字签名3. 比特币中的哈希函数和数字签名简单介绍:比特币与以太坊都是以区块链技术为基础的两种加密货币,因为他们应用最广泛,所以讲区块链技术一般就讲比特币和以太坊。比特币中的密码学原理 1…...

PyTorch学习笔记:data.WeightedRandomSampler——数据权重概率采样
PyTorch学习笔记:data.WeightedRandomSampler——数据权重概率采样 torch.utils.data.WeightedRandomSampler(weights, num_samples, replacementTrue, generatorNone)功能:按给定的权重(概率)[p0,p1,…,pn−1][p_0,p_1,\dots,p_{n-1}][p0,p1,…,pn…...

SpringMVC对请求参数的处理
如何获取SpringMVC中请求中的信息 ? 默认情况下,可以直接在方法的参数中填写跟请求参数一样的名称,此时会默认接受参 数 ,如果有值,直接赋值,如果没有,那么直接给空值 。Controller RequestMapp…...

12年老外贸的经验分享
回想这12年的经历,很庆幸自己的三观一直是正确的,就是买家第一不管什么原因,只要你想退货,我都可以接受退款。不能退给上级供应商,我就自己留着,就是为了避免因为这个拒收而失去买家。不管是什么质量原因&a…...
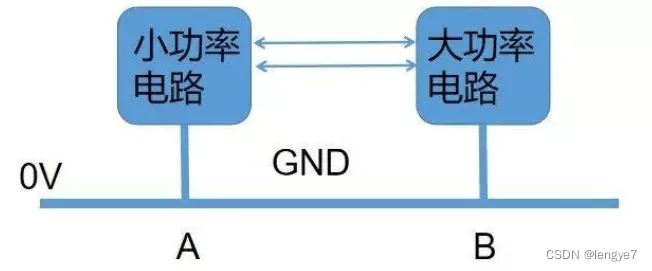
电子电路中的各种接地(接地保护与GND)
前言多年以前,雷雨天气下,建筑会遭遇雷击,从而破坏建筑以及伤害建筑内的人,为了避免雷击的伤害,人们发明了避雷针,并将避雷针接地线,从而引导雷击产生的电流经过地线流入到地下。地线࿱…...

php实现农历公历日期的相互转换
农历(Lunar calendar)和公历(Gregorian calendar)是两种不同的日历系统。公历是基于太阳和地球的运动来计算时间的,而农历是基于月亮的运动来计算时间的。农历中的月份是根据月亮的相对位置来确定的,而公历…...
基于SpringBoot的房屋租赁管理系统的设计与实现
基于SpringBoot的房屋租赁管理系统的设计与实现 1 绪论 1.1 课题来源 随着社会的不断发展以及大家生活水平的提高,越来越多的年轻人选择在大城市发展。在大城市发展就意味着要在外面有一处安身的地方。在租房的过程中,大家也面临着各种各样的问题&…...

一文带你为PySide6编译MySQL插件驱动
1.概述 最近使用PySide6开发程序,涉及与MySQL的数据交互。但是qt官方自pyqt5.12(记不太清了)以后不再提供MySQL的插件驱动,只能自己根据qt的源码编译。不过网上大部分都是qt5的MySQL驱动的编译教程。后来搜到了一个qt6的编译教程…...
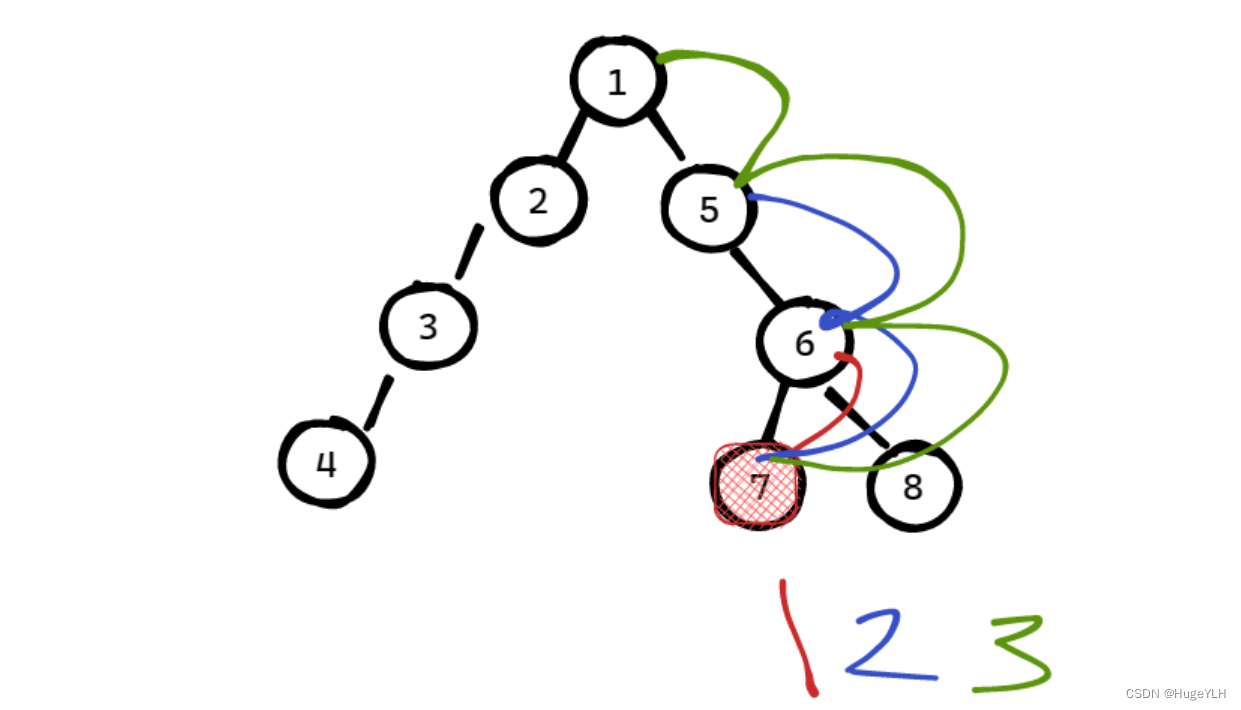
图论算法:树上倍增法解决LCA问题
文章目录树上倍增法: LCA问题树上倍增法: LCA问题 树上倍增法用于求解LCA问题是一种非常有效的方法。 倍增是什么? 简单来说,倍增就是 1 2 4 8 16 … 2^k 可以发现倍增是呈 2的指数型递增的一类数据,和二分一样&…...
 和 execute()方法有什么区别)
Java线程池中submit() 和 execute()方法有什么区别
点个关注,必回关 文章目录一. execute和submit的区别与联系1、测试代码的整体框架如下:2、首先研究Future<?> submit(Runnable task)和void execute(Runnable command),3、submit(Runnable task, T result) 方法可以使submit执行完Run…...

Vue.extend和VueComponent的关系源码解析
目录 0.概念解释 前言 需求分析 Vue.extend 编程式的使用组件 源码分析 0.概念解释 Vue.extend和VueComponent是Vuejs框架中创建组件的两种不同方式。Vue.extend方法能够让你根据Vue对象(继承)来定义一个新的可重用的组件构造器。而VueComponent方…...
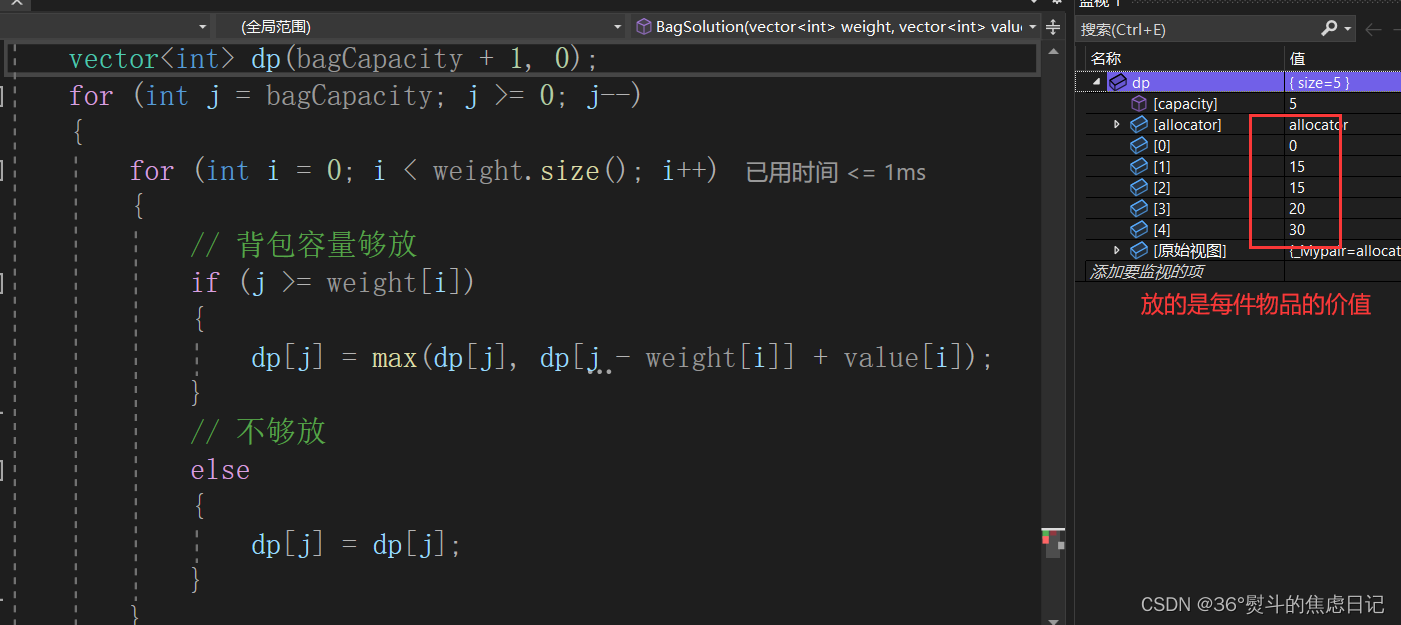
【动态规划】01背包问题(滚动数组 + 手画图解)
01背包除了可以用形象的二维动态数组表示外,还可以使用空间复杂度更低的一维滚动数组。 目录 文章目录 前言 一、滚动数组的基本理解 二、确定dp及其下标含义 三、确定递推公式 四、确定初始化 五、确定遍历顺序 1.用物品(正序)遍历背…...

javaEE 初阶 — 超时重传机制
文章目录超时重传机制1. 数据重复传输问题2. 如何解决数据重复传输问题3. 重传次数问题TCP 的工作机制:确认应答机制 超时重传机制 如果传输数据的时候丢包了该怎么办? 利用 超时重传,也就是超过了一定的时间,如果还没响应就重新…...

小米5x wlan无法打开解决
诱因:想要利用空置设备做节点服务器或者边缘计算,因此解锁并刷了magisk,印象中在刷之前wlan已经无法打开无法进行wifi联网 表现: 1 WLAN开关无法打开,或者虚假打开,无法扫描wifi 2 设置->我的设备->全…...

负载均衡之最小活跃数算法
文章目录[toc]一、概念二、场景与设计思路三、实现四、代码下载一、概念 活跃数 集群中各实例未处理的请求数。 最小活跃数 集群中各个实例,哪个实例未处理的请求数据最小,就称之为最小活跃数。 二、场景与设计思路 场景 以获取微服务地址为场景。 设计…...

Cesium使用
Cesium官网:https://cesiumjs.org 官方API文档:https://cesium.com/learn/ion-sdk/ref-doc 中文API文档:https://cesium.xin/cesium/cn/Documentation1.95 https://cesium.xin Cesium中文社区:http://cesiumcn.org …...

终极DBeaver多线程查询优先级控制:基于查询类型的动态调整指南
终极DBeaver多线程查询优先级控制:基于查询类型的动态调整指南 【免费下载链接】dbeaver DBeaver 是一个通用的数据库管理工具,支持跨平台使用。* 支持多种数据库类型,如 MySQL、PostgreSQL、MongoDB 等;提供 SQL 编辑、查询、调试…...

【Java】UTF-8变长编码及其3字节存储奥秘
UTF-8 是一种变长编码,一个字符可能由 1 到 4 个字节组成。 解码时(将字节数组转回 String),计算机并不需要“猜”或者去查表,因为长度信息本身就包含在字节的“头部”里。这就是 UTF-8 设计的精妙之处:它是…...

重庆灌浆料销售厂家怎么联系
在重庆的建筑工程领域,灌浆料的应用十分广泛。然而,众多重庆灌浆料厂家的市场状况究竟如何?又存在哪些痛点呢?市场现状:鱼龙混杂目前,重庆灌浆料市场厂家众多,但质量参差不齐。行业权威报告显示…...

保姆级教程:用Docker Compose一键部署Calibre-Web,再也不用担心电子书管理了
零基础打造个人电子书库:Docker Compose全栈部署Calibre-Web实战指南 在数字阅读时代,如何高效管理日益增长的电子书资源成为许多读者的痛点。传统文件管理方式难以满足多设备同步、元数据整理和阅读进度跟踪等需求,而Calibre-Web正是为解决这…...

教你 .NET Core API 怎么和数据库表一一对应
不用复杂理论,直接照做就能成功! 一、核心规则(记住这 4 句) 类 = 表 类名 = 表名 属性 = 字段 属性名 = 字段名 二、一步一步教你对应(超级简单) 1)数据库有一张表 → 你就写一个类 例如你数据库里有表: sql Users (Id int primary key identity,Name nvarchar(5…...

OpenClaw自动化测试:Qwen3-32B批量执行LeetCode题目
OpenClaw自动化测试:Qwen3-32B批量执行LeetCode题目 1. 为什么需要自动化编程能力测试 作为一名长期关注AI编程辅助工具的技术博主,我一直在寻找能够客观评估大模型编程能力的方法。传统的单次对话测试往往带有偶然性,无法系统性地反映模型…...

玩转AI!用FastAPI+RAG轻松构建智能文档问答系统,代码、文档全公开!
在企业数字化转型的浪潮中,我们常遇到这样一个痛点:海量的业务文档、研究报告、技术手册堆积如山,当需要从中寻找某个特定答案时,员工往往要花费数小时甚至数天进行翻阅。这不仅是效率的浪费,更是知识资产沉睡的体现**…...

C++ 内联函数的性能影响
C内联函数的性能影响探析 在追求高效代码的C开发中,内联函数因其消除函数调用开销的特性而备受关注。通过将函数体直接嵌入调用点,内联函数能显著提升程序性能,尤其在频繁调用的场景下。过度或不恰当的内联也可能导致代码膨胀或缓存命中率下…...

避坑指南:用ESP32驱动LD2420毫米波雷达时,串口数据丢失和自动开机卡死的那些事儿
ESP32与LD2420毫米波雷达深度避坑实战:从数据丢失到系统卡死的全链路解决方案 当你在凌晨三点盯着逻辑分析仪上那些残缺的串口波形时,就会明白为什么LD2420毫米波雷达被称为"最熟悉的陌生人"。这个能穿透墙壁感知呼吸的24GHz传感器,…...