GPU架构与计算入门指南
1比较CPU与GPU
首先,我们会比较CPU和GPU,这能帮助我们更好地了解GPU的发展状况,但这应该作为一个独立的主题,因为我们难以在一节中涵盖其所有的内容。因此,我们将着重介绍一些关键点。
CPU和GPU的主要区别在于它们的设计目标。CPU的设计初衷是执行顺序指令。一直以来,为提高顺序执行性能,CPU设计中引入了许多功能。其重点在于减少指令执行时延,使CPU能够尽可能快地执行一系列指令。这些功能包括指令流水线、乱序执行、预测执行和多级缓存等(此处仅列举部分)。
而GPU则专为大规模并行和高吞吐量而设计,但这种设计导致了中等至高程度的指令时延。这一设计方向受其在视频游戏、图形处理、数值计算以及现如今的深度学习中的广泛应用所影响,所有这些应用都需要以极高的速度执行大量线性代数和数值计算,因此人们倾注了大量精力以提升这些设备的吞吐量。
我们来思考一个具体的例子:由于指令时延较低,CPU在执行两个数字相加的操作时比GPU更快。在按顺序执行多个这样的计算时,CPU能够比GPU更快地完成。然而,当需要进行数百万甚至数十亿次这样的计算时,由于GPU具有强大的大规模并行能力,它将比CPU更快地完成这些计算任务。
我们可以通过具体数据来进行说明。硬件在数值计算方面的性能以每秒浮点运算次数(FLOPS)来衡量。NVIDIA的Ampere A100在32位精度下的吞吐量为19.5 TFLOPS。相比之下,Intel的24核处理器在32位精度下的吞吐量仅为0.66 TFLOPS(2021年)。同时,随时间推移,GPU与CPU在吞吐量性能上的差距逐年扩大。
CPU在芯片领域中主要用于降低指令时延的功能,例如大型缓存、较少的算术逻辑单元(ALU)和更多的控制单元。与此相比,GPU则利用大量的ALU来最大化计算能力和吞吐量,只使用极小的芯片面积用于缓存和控制单元,这些元件主要用于减少CPU时延。
时延容忍度和高吞吐量
或许你会好奇,GPU如何能够容忍高时延并同时提供高性能呢?GPU 拥有大量线程和强大的计算能力,使这一点成为可能。即使单个指令具有高延迟,GPU 也会有效地调度线程运行,以便它们在任意时间点都能利用计算能力。例如,当某些线程正在等待指令结果时,GPU 将切换到运行其他非等待线程。这可确保 GPU 上的计算单元在所有时间点都以其最大容量运行,从而提供高吞吐量。稍后当我们讨论kernel如何在 GPU 上运行时,我们将对此有更清晰的了解。
GPU架构
我们已经了解到GPU有利于实现高吞吐量,但它们是通过怎样的架构来实现这一目标的呢?本节将对此展开探讨。
GPU的计算架构
GPU由一系列流式多处理器(SM)组成,其中每个SM又由多个流式处理器、核心或线程组成。例如,NVIDIA H100 GPU具有132个SM,每个SM拥有64个核心,总计核心高达8448个。
每个SM都拥有一定数量的片上内存(on-chip memory),通常称为共享内存或临时存储器,这些共享内存被所有的核心所共享。同样,SM上的控制单元资源也被所有的核心所共享。此外,每个SM都配备了基于硬件的线程调度器,用于执行线程。
除此之外,每个SM还配备了几个功能单元或其他加速计算单元,例如张量核心(tensor core)或光线追踪单元(ray tracing unit),用于满足GPU所处理的工作负载的特定计算需求。
接下来,让我们深入剖析GPU内存并了解其中的细节。
GPU的内存架构
让我们对其进行剖析:
- 寄存器:让我们从寄存器开始。GPU中的每个SM都拥有大量寄存器。例如,NVIDIA的A100和H100模型中,每个SM拥有65536个寄存器。这些寄存器在核心之间共享,并根据线程需求动态分配。在执行过程中,每个线程都被分配了私有寄存器,其他线程无法读取或写入这些寄存器。
- 常量缓存:接下来是芯片上的常量缓存。这些缓存用于缓存SM上执行的代码中使用的常量数据。为利用这些缓存,程序员需要在代码中明确将对象声明为常量,以便GPU可以将其缓存并保存在常量缓存中。
- 共享内存:每个SM还拥有一块共享内存或临时内存,它是一种小型、快速且低时延的片上可编程SRAM内存,供运行在SM上的线程块共享使用。共享内存的设计思路是,如果多个线程需要处理相同的数据,只需要其中一个线程从全局内存(global memory)加载,而其他线程将共享这一数据。合理使用共享内存可以减少从全局内存加载重复数据的操作,并提高内核执行性能。共享内存还可以用作线程块(block)内的线程之间的同步机制。
- L1缓存:每个SM还拥有一个L1缓存,它可以缓存从L2缓存中频繁访问的数据。
- L2缓存:所有SM都共享一个L2缓存,它用于缓存全局内存中被频繁访问的数据,以降低时延。需要注意的是,L1和L2缓存对于SM来说是公开的,也就是说,SM并不知道它是从L1还是L2中获取数据。SM从全局内存中获取数据,这类似于CPU中L1/L2/L3缓存的工作方式。
- 全局内存:GPU还拥有一个片外全局内存,它是一种容量大且带宽高的动态随机存取存储器(DRAM)。例如,NVIDIA H100拥有80 GB高带宽内存(HBM),带宽达每秒3000 GB。由于与SM相距较远,全局内存的时延相当高。然而,芯片上还有几个额外的存储层以及大量的计算单元有助于掩饰这种时延。
现在我们已经了解GPU硬件的关键组成部分,接下来我们深入一步,了解执行代码时这些组件是如何发挥作用的。
了解GPU的执行模型
要理解GPU如何执行kernel,我们首先需要了解什么是kernel及其配置。
CUDA Kernel与线程块简介
CUDA是NVIDIA提供的编程接口,用于编写运行在其GPU上的程序。在CUDA中,你会以类似于C/C++函数的形式来表达想要在GPU上运行的计算,这个函数被称为kernel。kernel在并行中操作向量形式的数字,这些数字以函数参数的形式提供给它。一个简单的例子是执行向量加法的kernel,即接受两个向量作为输入,逐元素相加,并将结果写入第三个向量。
要在GPU上执行kernel,我们需要启用多个线程,这些线程总体上被称为一个网格(grid),但网格还具有更多的结构。一个网格由一个或多个线程块(有时简称为块)组成,而每个线程块又由一个或多个线程组成。
线程块和线程的数量取决于数据的大小和我们所需的并行度。例如,在向量相加的示例中,如果我们要对256维的向量进行相加运算,那么可以配置一个包含256个线程的单个线程块,这样每个线程就可以处理向量的一个元素。如果数据更大,GPU上也许没有足够的线程可用,这时我们可能需要每个线程能够处理多个数据点。
编写一个kernel需要两步。第一步是运行在CPU上的主机代码,这部分代码用于加载数据,为GPU分配内存,并使用配置的线程网格启动kernel;第二步是编写在GPU上执行的设备(GPU)代码。
由于本文的重点不在于教授CUDA,因此我们不会更深入地讨论此段代码。现在,让我们看看在GPU上执行kernel的具体步骤。
在GPU上执行Kernel的步骤
1.将数据从主机复制到设备
在调度执行kernel之前,必须将其所需的全部数据从主机(即CPU)内存复制到GPU的全局内存(即设备内存)。尽管如此,在最新的GPU硬件中,我们还可以使用统一虚拟内存直接从主机内存中读取数据(可参阅论文《EMOGI: Efficient Memory-access for Out-of-memory Graph-traversal in GPUs》)。
2. SM上线程块的调度
当GPU的内存中拥有全部所需的数据后,它会将线程块分配给SM。同一个块内的所有线程将同时由同一个SM进行处理。为此,GPU必须在开始执行线程之前在SM上为这些线程预留资源。在实际操作中,可以将多个线程块分配给同一个SM以实现并行执行。
由于SM的数量有限,而大型kernel可能包含大量线程块,因此并非所有线程块都可以立即分配执行。GPU会维护一个待分配和执行的线程块列表,当有任何一个线程块执行完成时,GPU会从该列表中选择一个线程块执行。
3. 单指令多线程 (SIMT) 和线程束(Warp)
众所周知,一个块(block)中的所有线程都会被分配到同一个SM上。但在此之后,线程还会进一步划分为大小为32的组(称为warp),并一起分配到一个称为处理块(processing block)的核心集合上进行执行。
SM通过获取并向所有线程发出相同的指令,以同时执行warp中的所有线程。然后这些线程将在数据的不同部分,同时执行该指令。在向量相加的示例中,一个warp中的所有线程可能都在执行相加指令,但它们会在向量的不同索引上进行操作。
由于多个线程同时执行相同的指令,这种warp的执行模型也称为单指令多线程 (SIMT)。这类似于CPU中的单指令多数据(SIMD)指令。
Volta及其之后的新一代GPU引入了一种替代指令调度的机制,称为独立线程调度(Independent Thread Scheduling)。它允许线程之间完全并发,不受warp的限制。独立线程调度可以更好地利用执行资源,也可以作为线程之间的同步机制。本文不会涉及独立线程调度的相关内容,但你可以在CUDA编程指南中了解更多相关信息。
4. Warp调度和时延容忍度
关于warp的运行原理,有一些值得讨论的有趣之处。
即使SM内的所有处理块(核心组)都在处理warp,但在任何给定时刻,只有其中少数块正在积极执行指令。因为SM中可用的执行单元数量是有限的。
有些指令的执行时间较长,这会导致warp需要等待指令结果。在这种情况下,SM会将处于等待状态的warp休眠,并执行另一个不需要等待任何结果的warp。这使得GPU能够最大限度地利用所有可用计算资源,并提高吞吐量。
零计算开销调度:由于每个warp中的每个线程都有自己的一组寄存器,因此SM从执行一个warp切换到另一个warp时没有额外计算开销。
与CPU上进程之间的上下文切换方式(context-switching)不同。如果一个进程需要等待一个长时间运行的操作,CPU在此期间会在该核心上调度执行另一个进程。然而,在CPU中进行上下文切换的代价昂贵,这是因为CPU需要将寄存器状态保存到主内存中,并恢复另一个进程的状态。
5. 将结果数据从设备复制到主机内存
最后,当kernel的所有线程都执行完毕后,最后一步就是将结果复制回主机内存。
尽管我们涵盖了有关典型kernel执行的全部内容,但还有一点值得讨论:动态资源分区。
资源划分和占用概念
我们通过一个称为“occupancy(占用率)”的指标来衡量GPU资源的利用率,它表示分配给SM的warp数量与SM所能支持的最大warp数量之间的比值。为实现最大吞吐量,我们希望拥有100%的占用率。然而,在实践中,由于各种约束条件,这并不容易实现。
为什么我们无法始终达到100%的占用率呢?SM拥有一组固定的执行资源,包括寄存器、共享内存、线程块槽和线程槽。这些资源根据需求和GPU的限制在线程之间进行动态划分。例如,在NVIDIA H100上,每个SM可以处理32个线程块、64个warp(即2048个线程),每个线程块拥有1024个线程。如果我们启动一个包含1024个线程的网格,GPU将把2048个可用线程槽划分为2个线程块。
动态分区vs固定分区:动态分区能够更为有效地利用GPU的计算资源。相比之下,固定分区为每个线程块分配了固定数量的执行资源,这种方式并不总是最有效的。在某些情况下,固定分区可能会导致线程被分配多于其实际需求的资源,造成资源浪费和吞吐量降低。
下面我们通过一个例子说明资源分配对SM占用率的影响。假设我们使用32个线程的线程块,并需要总共2048个线程,那么我们将需要64个这样的线程块。然而,每个SM一次只能处理32个线程块。因此,即使一个SM可以运行2048个线程,但它一次也只能同时运行1024个线程,占用率仅为50%。
同样地,每个SM具有65536个寄存器。要同时执行2048个线程,每个线程最多有32个寄存器(65536/2048 =32)。如果一个kernel需要每个线程有64个寄存器,那么每个SM只能运行1024个线程,占用率同样为50%。
占用率不足的挑战在于,可能无法提供足够的时延容忍度或所需的计算吞吐量,以达到硬件的最佳性能。
高效创建GPU kernel是一项复杂任务。我们必须合理分配资源,在保持高占用率的同时尽量降低时延。例如,拥有大量寄存器可以加快代码的运行速度,但可能会降低占用率,因此谨慎优化代码至关重要。
总结
我理解众多的新术语和新概念可能令读者望而生畏,因此文章最后对要点进行了总结,以便快速回顾。
- GPU由多个SM组成,每个SM又包含多个处理核心。
- GPU上存在着一个片外全局内存,通常是高带宽内存(HBM)或动态随机存取内存(DRAM)。它与芯片上的SM相距较远,因此时延较高。
- GPU中有两个级别的缓存:片外L2缓存和片上L1缓存。L1和L2缓存的工作方式类似于CPU中的L1/L2缓存。
- 每个SM上都有一小块可配置的共享内存。这块共享内存在处理核心之间共享。通常情况下,线程块内的线程会将一段数据加载到共享内存中,并在需要时重复使用,而不是每次再从全局内存中加载。
- 每个SM都有大量寄存器,寄存器会根据线程需求进行划分。NVIDIA H100每个SM有65536个寄存器。
- 在GPU上执行kernel时,我们需要启动一个线程网格。网格由一个或多个线程块组成,而每个线程块又由一个或多个线程组成。
- 根据资源可用性,GPU会分配一个或多个线程块在SM上执行。同一个线程块中的所有线程都会被分配到同一个SM上执行。这样做的目的是为了充分利用数据的局部性(data locality),并实现线程之间的同步。
- 被分配给SM的线程进一步分为大小为32的组,称为warp。一个warp内的所有线程同时执行相同的指令,但在数据的不同部分上执行(SIMT)(尽管新一代GPU也支持独立的线程调度)。
- GPU根据每个线程的需求和SM的限制,在线程之间进行动态资源划分。程序员需要仔细优化代码,以确保在执行过程中达到最高的SM占用率。
相关文章:

GPU架构与计算入门指南
1比较CPU与GPU 首先,我们会比较CPU和GPU,这能帮助我们更好地了解GPU的发展状况,但这应该作为一个独立的主题,因为我们难以在一节中涵盖其所有的内容。因此,我们将着重介绍一些关键点。 CPU和GPU的主要区别在于它们的…...

功能测试转自动化测试好不好转型?
手工测试做了好多年,点点点成了每天必须做的事情。但是随着自动化测试趋势的日渐明显,以及受到薪资、技能的双重考验,掌握自动化测试成为了必备技能。 手工转自动化测试,不是一蹴而就的。“预先善其事,必先利其器”&a…...

微软surface laptop禁用触摸屏(win10、设备管理器)
参考链接: 在屏幕中启用和禁用触摸屏Windows 设置如下...
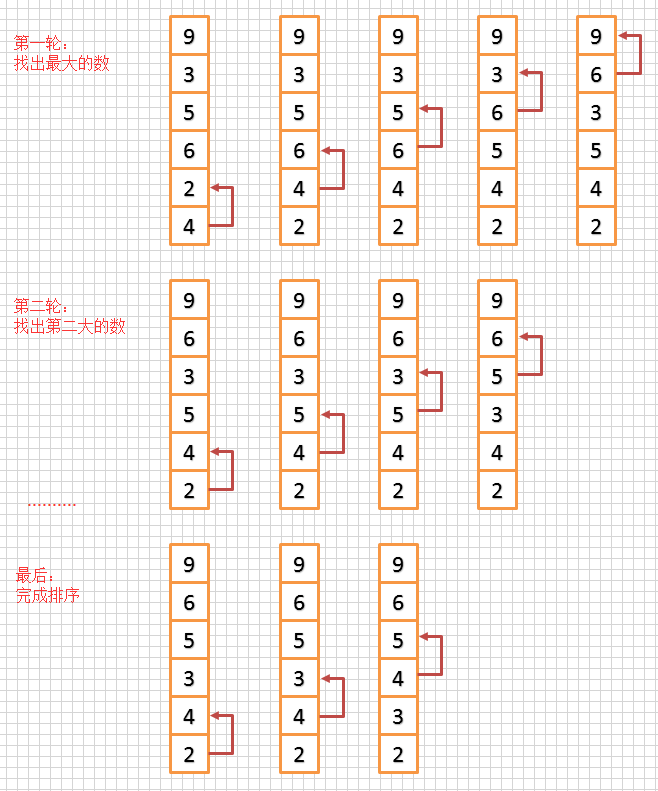
冒泡排序算法原理和代码实现,就是这么简单!
冒泡排序,是比较简单的一种排序算法。 它的命名源于它的算法原理:重复的从前往后(或者从后往前),依次比较记录中相邻的两个元素,如果他们顺序错误就把它们交换过来,直到没有再需要交换的元素&am…...

[工业自动化-6]:西门子S7-15xxx编程 - PLC系统硬件组成与架构
目录 一、PLC系统组成 1.1 PLC 单机系统组成 1.2 PLC 分布式系统 二、PLC各个组件 2.1 PLC上位机 2.2 PLC主站:PLC CPU控制中心 (1)主要功能 (2)主站组成 2.3 PLC分布式从站: IO模块的拉远 (1&am…...

pinpoint监控tomcat应用,页面显示No data collected
pinpoint安装部署教程大家都可以搜到。这里就不说了。单说一下 页面没有数据的情况。 部署环境,pinpoint安装部署在A服务器上。现在是在C、D、E、F……linux机器上安装pinpoint-agnet 1. 将文件 pinpoint-agent-1.8.5.tar.gz 上传到 服务器C、D、E、F…… 2. 解压…...

【左程云算法全讲4】前缀树、非比较排序
系列综述: 💞目的:本系列是个人整理为了秋招面试的,整理期间苛求每个知识点,平衡理解简易度与深入程度。 🥰来源:材料主要源于左程云算法课程进行的,每个知识点的修正和深入主要参考…...

微头条项目实战:新增RequestHeader注解
1、RequestHeader package com.csdn.mymvc.annotation; import java.lang.annotation.*; Target(ElementType.PARAMETER) Retention(RetentionPolicy.RUNTIME) Inherited public interface RequestHeader { }2、DispatcherServlet package com.csdn.mymvc.core; import com.csd…...
E云管家个微协议框架--新版本的利器
在互联网时代,高效、可靠的互联网协议对于实现稳定、安全的数据传输至关重要。E云管家作为一项创新性的IPAD协议构建工具,基于IPAD8.0.37协议为开发者提供了强大而灵活的功能,使他们能够轻松构建高效的通信协议。本文将介绍E云管家的主要特点…...

百度上线“文心一言”付费版本,AI聊天机器人市场竞争加剧
原创 | 文 BFT机器人 百度不愧是我国AI技术领域的先行者,每年致力于人工智能领域取得技术产品的突破和创新。据爆料称,百度的文心一言有突破了新境界,开创了文心大模型4.0会员版本。从线上的to C产品到试水商业化,百度都是争先走…...
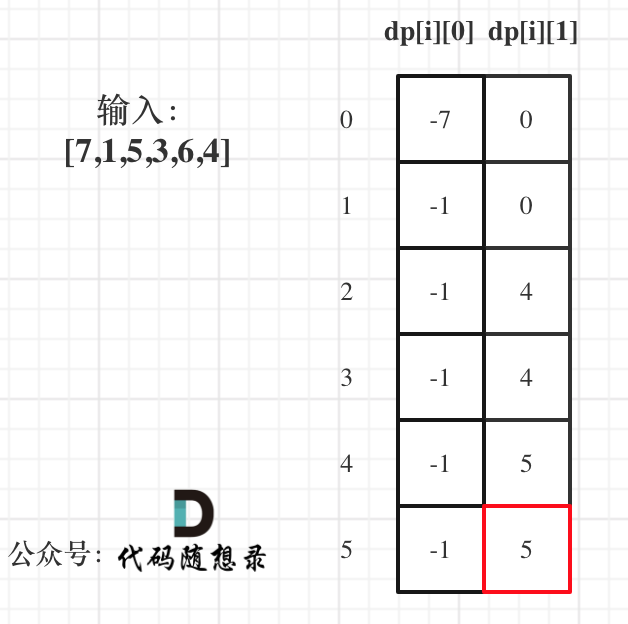
代码随想录算法训练营第四十七天丨 动态规划part10
121. 买卖股票的最佳时机 思路 动态规划 动规五部曲分析如下: 确定dp数组(dp table)以及下标的含义 dp[i][0] 表示第i天持有股票所得最多现金 ,这里可能有疑惑,本题中只能买卖一次,持有股票之后哪还有…...

微前端:quankun
零: 前言 微前端可以将大应用拆分功能独立的微应用,可独立开发部署, 每个微应用可以采用自己的技术栈,这样更好维护和拓展。微前端也会存在跨域 权限控制 数据共享 性能(页面加载时间) 安全 多团队协作(一个团队负责一个页面或模…...
CSDN每日一题学习训练——Java版(克隆图、最接近的三数之和、求公式的值)
版本说明 当前版本号[20231109]。 版本修改说明20231109初版 目录 文章目录 版本说明目录克隆图题目解题思路代码思路参考代码 最接近的三数之和题目解题思路代码思路参考代码 求公式的值题目解题思路代码思路参考代码 克隆图 题目 给你无向 连通(https://baike.baidu.com…...

XOR Construction
思路: 通过题目可以得出结论 b1^b2a1 b2^b3a2 ....... bn-1^bnan-1 所以就可以得出 (b1^b2)^(b2^b3)a1^a2 b1^b3a1^a2 有因为当确定一个数的时候就可以通过异或得到其他所有的数,且题目所求的是一个n-1的全排列 那么求出a的前缀异或和arr之后…...
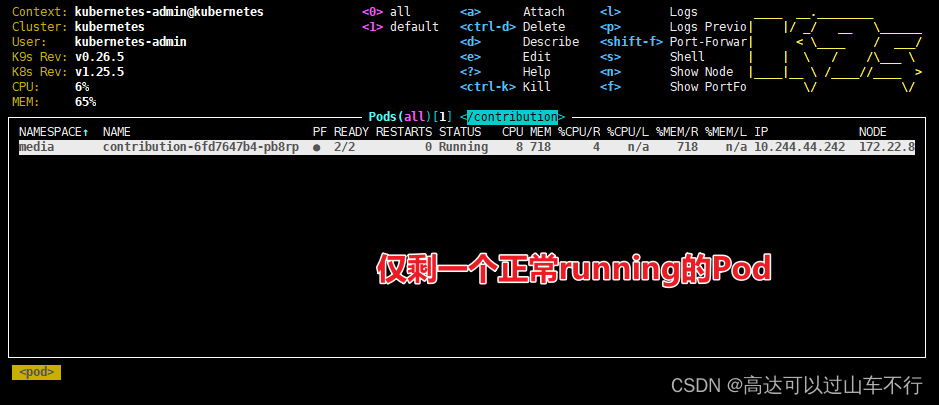
K8S容器持续Terminating无法正常关闭(sider-car容器异常,微服务容器正常)
问题 K8S上出现大量持续terminating的Pod,无法通过常规命令删除。需要编写脚本批量强制删除持续temminating的Pod:contribution-xxxxxxx。 解决 获取terminating状态的pod名称的命令: # 获取media命名空间下,名称带contributi…...

Spring 循环依赖
文章目录 内容总结循环依赖 内容总结 循环依赖 循环依赖只存在于 Spring 中, 是因为 Spring 创建 Bean 的流程中, 依赖注入阶段, 会先从单例池中找, 没有再从定义池中找, 针对定义池中找到的候选项会通过 getBean 创建其单例并缓存到单例池, 此机制导致了存在循环依赖的问题.…...

MySQL 8.0.13升级到8.0.35记录 .NET
1、修改表结构的字符集 utf8 修改成 utf8mb4 utf8_general_ci 修改成 utf8mb4_0900_ai_ci 注:所有地方都要替换。 否则会报错误提示:Character set utf8mb3 is not supported 下面是.NET环境升级遇到的问题 2、MySQL Connector Net 8.0.13 在程…...

flink udtaf 常年不能用
[FLINK-32807] when i use emitUpdateWithRetract of udtagg,bug error - ASF JIRA flink1.18发布的时候 他都显示未解决 但是文档上一直有udtaf...

路由汇总的四要点
1.是基于链路级的还是进程级的? RIP和eigrp都是基于接口的链路级汇总,而OSPF是基于进程的 2.汇总路由什么时候消失? 最后一条明细路由消失的时候,汇总路由消失。 3.汇总之后,汇总路由被通告,本地是否会产生一条指向NULL接口的…...
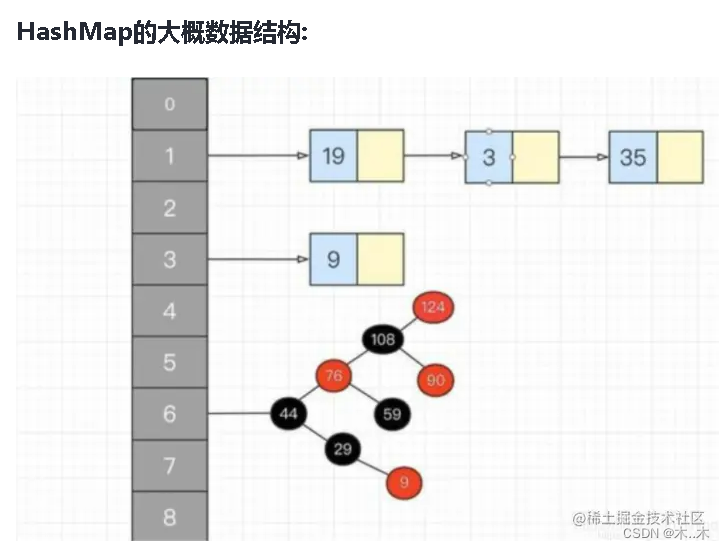
HashMap存值、取值及哈希碰撞原理分析
HashMap中的put()和get()的实现原理: map.put(k,v)实现原理 首先将k,v封装到Node对象当中(节点)。 然后它的底层会调用K的hashCode()方法得出hash值。 通过哈希表函数/哈希算法,将hash值转换成数组的下标,下标位置上…...

MATLAB里pchip插值函数怎么用?手把手教你复现并理解它的核心算法
MATLAB中pchip插值函数的深度解析与算法复现 1. 从黑盒调用到算法透明化 当我们第一次接触MATLAB的pchip函数时,通常只是简单地调用interp1(x,y,xi,pchip)就能得到平滑的插值曲线。但作为一名追求技术深度的工程师或研究者,仅仅知道如何使用是远远不够的…...

全志 D1s/F133 移植 LVGL 实战:从 T113 源码到 RISC-V 平台的驱动适配与部署
1. 从ARM到RISC-V:为什么要移植LVGL? 最近在折腾全志D1s/F133开发板的朋友可能都遇到过这个问题:网上大部分LVGL例程都是基于ARM架构的T113平台写的,但D1s搭载的是RISC-V内核。这就好比你想在MacBook上运行Windows软件,…...

Qwen3-4B-Instruct基础教程:HuggingFace tokenizer长文本分块策略
Qwen3-4B-Instruct基础教程:HuggingFace tokenizer长文本分块策略 1. 引言 Qwen3-4B-Instruct-2507是Qwen3系列的端侧/轻量旗舰模型,原生支持256K token(约50万字)上下文窗口,并可扩展至1M token。这意味着它可以轻松…...
流式输出优化:WebSocket协议适配与前端渲染技巧)
RWKV-7 (1.5B World)流式输出优化:WebSocket协议适配与前端渲染技巧
RWKV-7 (1.5B World)流式输出优化:WebSocket协议适配与前端渲染技巧 1. 项目背景与价值 RWKV-7 (1.5B World)作为轻量级大语言模型,凭借其高效的推理性能和低显存占用,成为本地化部署的热门选择。但在实际应用中,流式输出的延迟…...

Hunyuan-HY-MT1.5-1.8B实战:REST API封装详细教程
Hunyuan-HY-MT1.5-1.8B实战:REST API封装详细教程 你是不是也遇到过这样的问题:手头有个效果不错的翻译模型,但团队里前端、测试、产品同学都不会写Python,每次调用都要找你跑脚本?或者想把翻译能力集成进现有系统&am…...

Docker技术入门与实战【2.3】
第13章 编程语言本章主要介绍如何使用Docker快速部署主流编程语言的开发环境及其常用框架,包括C、C、Java、PHP、Python、Perl、Ruby、JavaScript、Ruby等。其中,笔者将重点介绍常用Web编程语言PHP的Docker使用。13.1 PHP13.1.1 PHP技术栈PHP是一种广泛使…...

Phi-3.5-Mini-Instruct效果展示:数学推导、Python调试、SQL生成三连击
Phi-3.5-Mini-Instruct效果展示:数学推导、Python调试、SQL生成三连击 1. 开篇介绍 Phi-3.5-Mini-Instruct是微软推出的轻量级大模型,专为本地推理优化设计。这个工具完美适配了Phi-3.5模型,采用官方推荐的Pipeline架构和BF16半精度推理&am…...

程序员别再死磕CRUD!拥抱大模型才是破局出路
文章目录前言一、CRUD程序员的"死亡倒计时":2026年的残酷现实1.1 被AI"团灭"的基础编码工作1.2 薪资"腰斩"与35危机的双重暴击1.3 为什么CRUD会成为"职业陷阱"?二、大模型时代的程序员:从"代码…...
)
手把手教你用Conda安装Python的dcor包,并计算距离相关系数(避坑指南)
从零开始:用Conda轻松安装dcor包并计算距离相关系数 在数据科学和统计分析中,我们经常需要衡量变量之间的相关性。传统的皮尔逊相关系数虽然广为人知,但它只能捕捉线性关系,对于非线性关系的识别就显得力不从心。这时候࿰…...

从SPSS到Python:因子分析实战全流程对比与解读
1. 为什么需要从SPSS转向Python做因子分析 十年前我刚入行数据分析时,SPSS几乎是每个分析师电脑里的标配。图形化界面点点鼠标就能出结果,对新手特别友好。但后来处理的数据量越来越大,项目需求越来越复杂,我逐渐发现了SPSS的三个…...