2022最新版-李宏毅机器学习深度学习课程-P34 自注意力机制类别总结
在课程的transformer视频中,李老师详细介绍了部分self-attention内容,但是self-attention其实还有各种各样的变化形式:

一、Self-attention运算存在的问题
在self-attention中,假设输入序列(query)长度是N,为了捕捉每个value或者token之间的关系,需要产生N个key与之对应,并将query与key之间做dot-product,就可以产生一个Attention Matrix(注意力矩阵),维度N*N。
这种方式最大的问题:当序列长度太长的时候,对应的Attention Matrix维度太大,计算量太大。
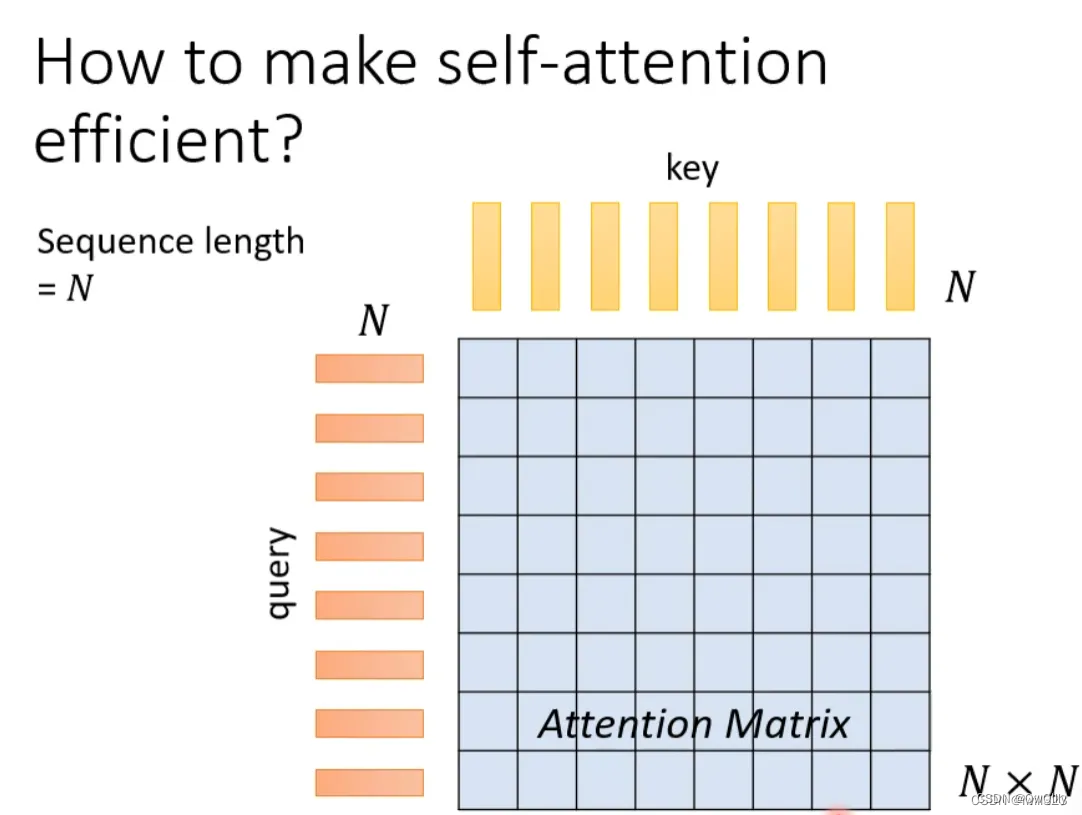
对于transformer来说,self-attention只是大的网络架构中的一个module。由上述分析我们知道,对于self-attention的运算量是跟N的平方成正比的。当N很小的时候,单纯增加self-attention的运算效率可能并不会对整个网络的计算效率有太大的影响。因此,提高self-attention的计算效率从而大幅度提高整个网络的效率的前提是N特别大的时候,比如做图像识别(影像辨识、image processing)。
比如图片像素是256*256,每个像素当成一个单位,输入长度是256*256,self-attention的运算量正比于256*256的平方。

二、各种变形:加快self-attention的求解速度
根据上述分析可以知道,影响self-attention效率最大的一个问题就是Attention Matrix的计算。如果根据一些的知识或经验,选择性的计算Attention Matrix中的某些数值或者某些数值不需要计算就可以知道数值,理论上可以减小计算量,提高计算效率。
local attention
举个例子,比如在做文本翻译的时候,有时候在翻译当前的token时不需要给出整个sequence,其实只需要知道这个token左右的邻居,把较远处attention的数值设为0,就可以翻译的很准,也就是做局部的attention(local attention)。
优点:大大提升运算效率。
缺点:只关注周围局部的值,这样做法其实跟CNN没有太大区别,结果不一定非常好。
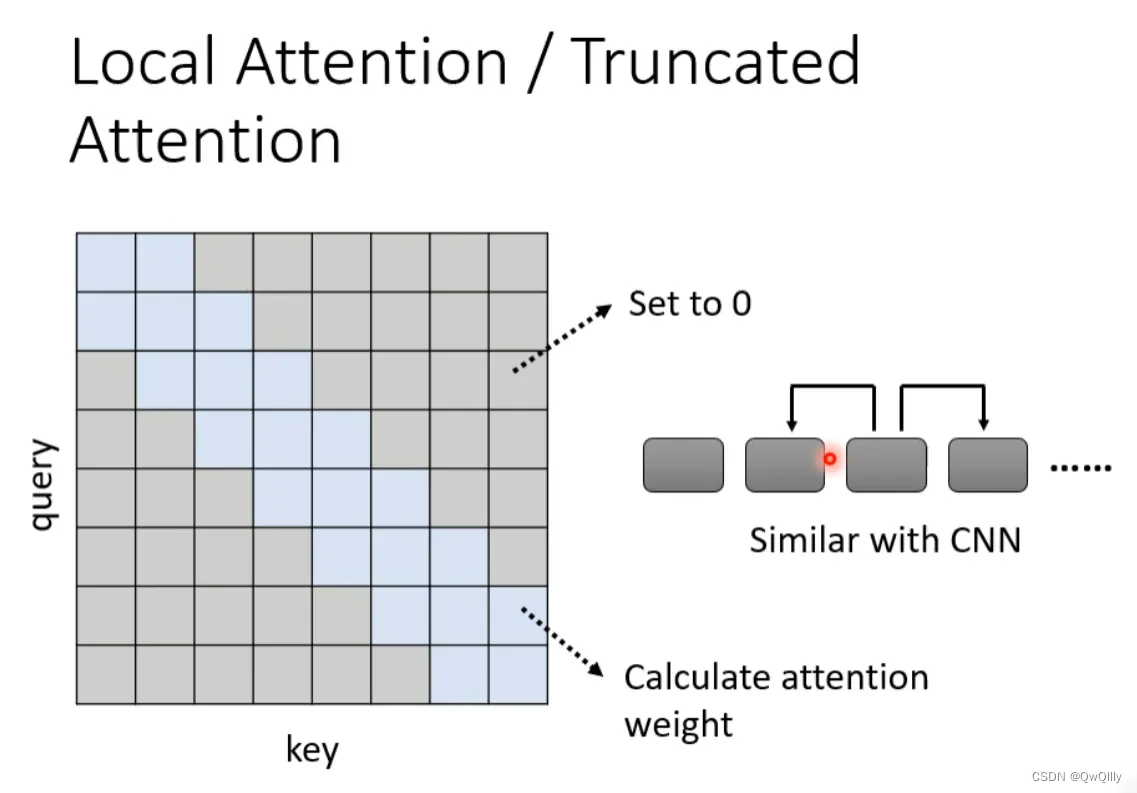
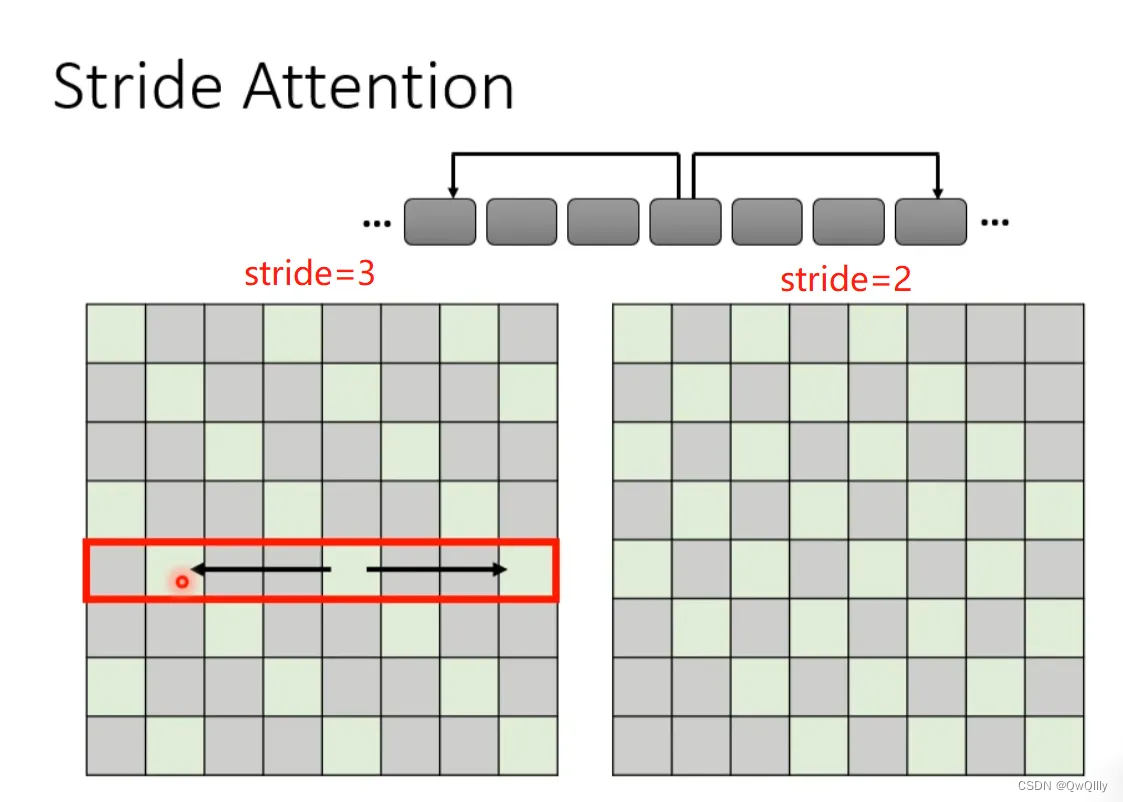
Stride Attention
如果觉得上述local attention不好,也可以换一种思路:在翻译当前token的时候,让他空一定间隔(stride)的左右邻居的信息,从而捕获当前与过去和未来的关系。stride的数值可以自己确定。
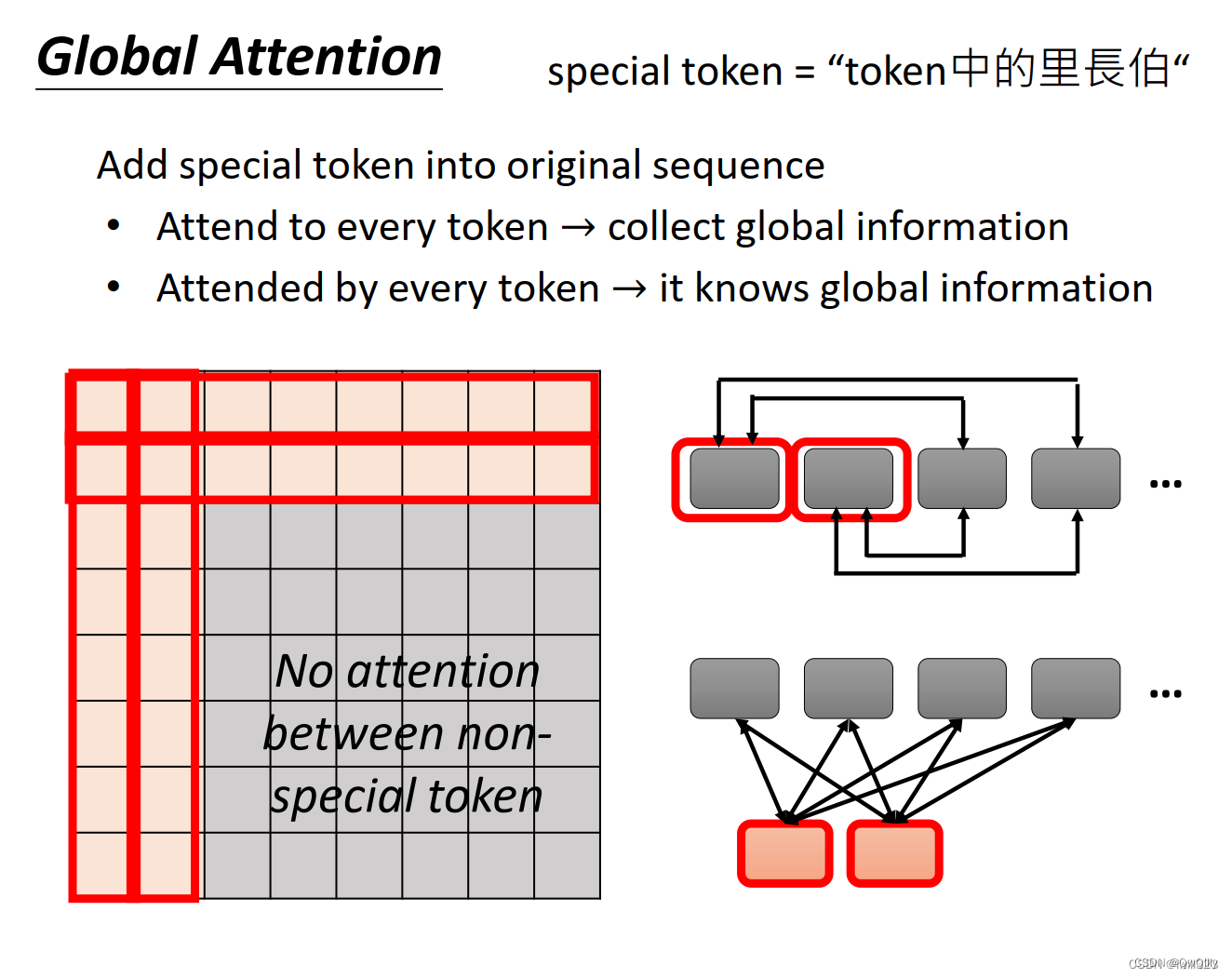
global attention
选择sequence中的某些token作为special token(比如开头的token,标点符号),或者在原始的sequence中增加special token。让special token与sequence里每一个token产生关系(Attend to every token和Attended by every token),但其他不是special token的token之间没有attention。
以在原始sequence头两个位置增加两个special token为例,只有前两行和前两列做attend计算。
Big Bird:综合运用
对于一个网络,有的head可以做local attention,有的head可以做stride attention,有的head可以做global attention。看下面几个例子:
Longformer就是组合了上面的三种attention
Big Bird就是在Longformer基础上随机选择attention赋值,进一步提高计算效率

Reformer:Clustering
上面几种方法都是人为设定的哪些地方需要算attention,哪些地方不需要算attention,但是这样算是最好的方法吗?并不一定。
对于Attention Matrix来说,如果某些位置值非常小,可以直接把这些位置置0,这样对实际预测的结果也不会有太大的影响。也就是说我们只需要找出Attention Matrix中attention的值相对较大的值。但是如何找出哪些位置的值非常小/非常大呢?
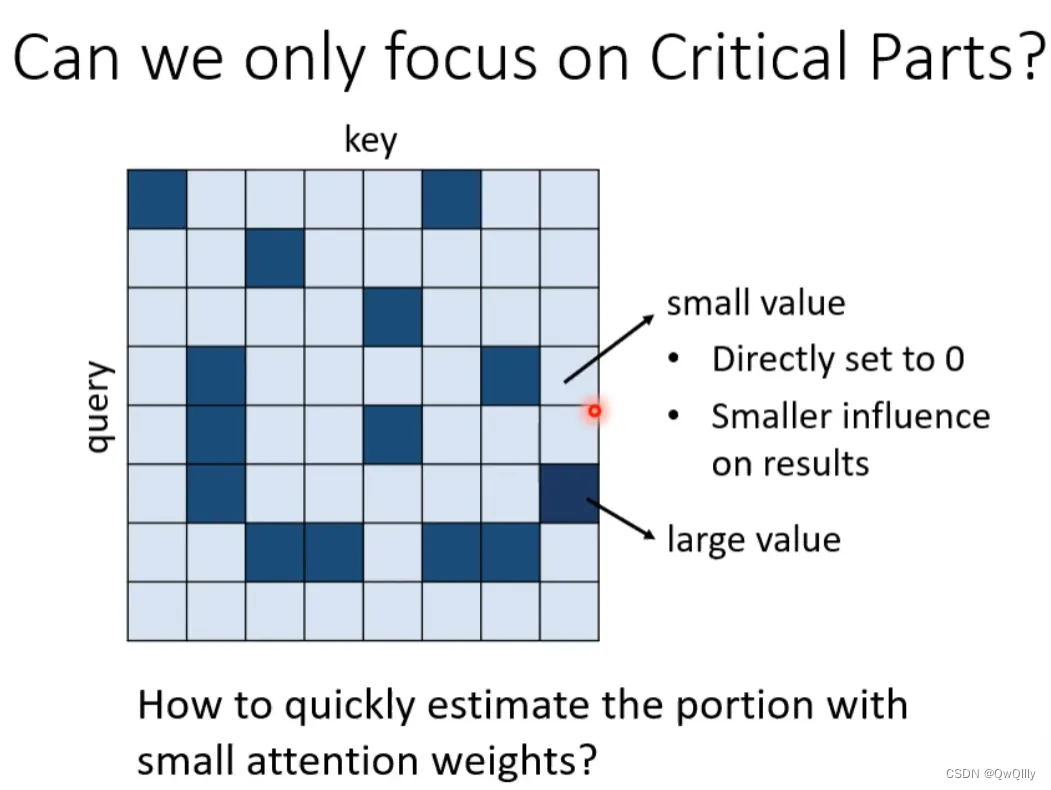
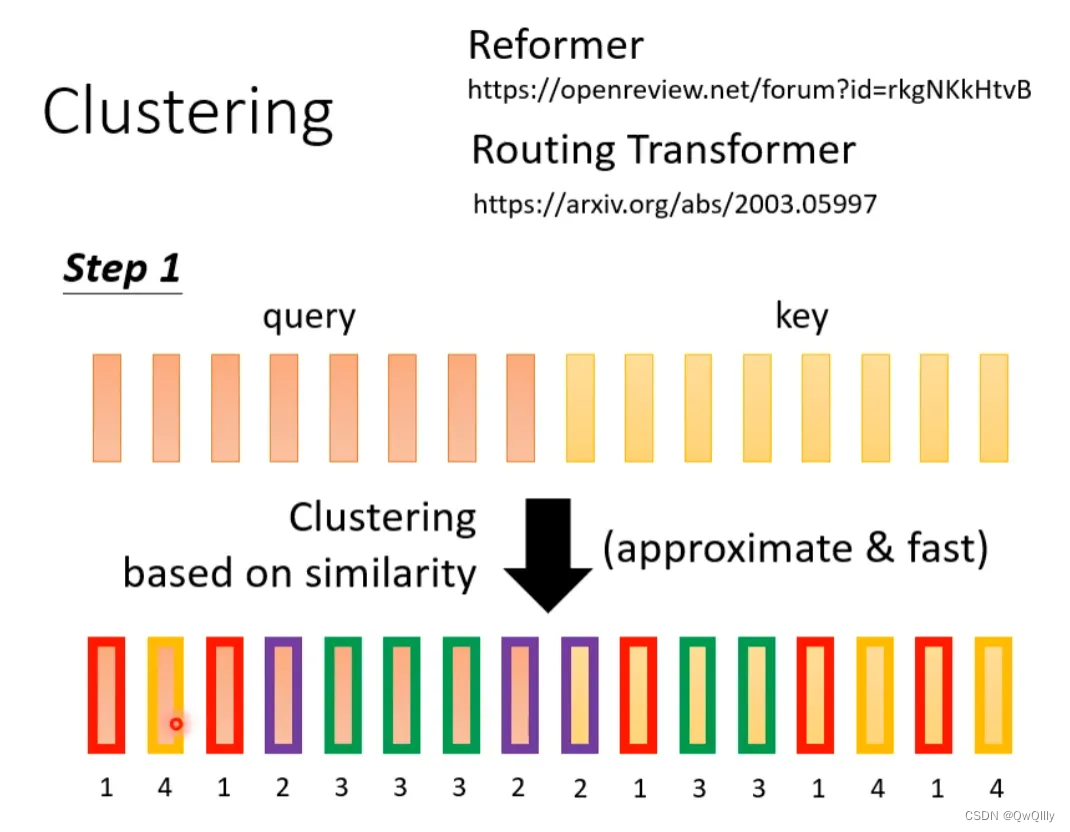
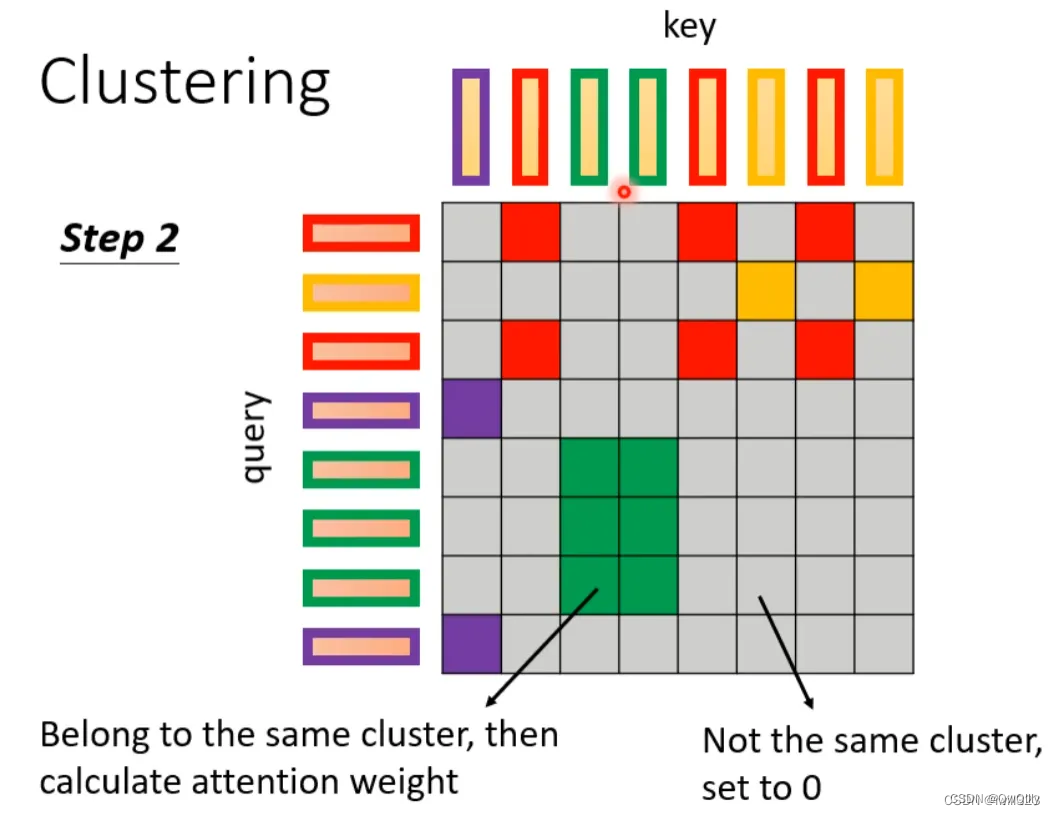
下面这两个文献中给出一种Clustering(聚类)的方案,即对query和key进行聚类,属于同一类的query和key来计算attention,不属于同一类的就不参与计算,这样就可以加快Attention Matrix的计算。比如下面这个例子中,分为4类:1(红框)、2(紫框)、3(绿框)、4(黄框)。在下面两个文献中介绍了可以快速粗略聚类的方法。
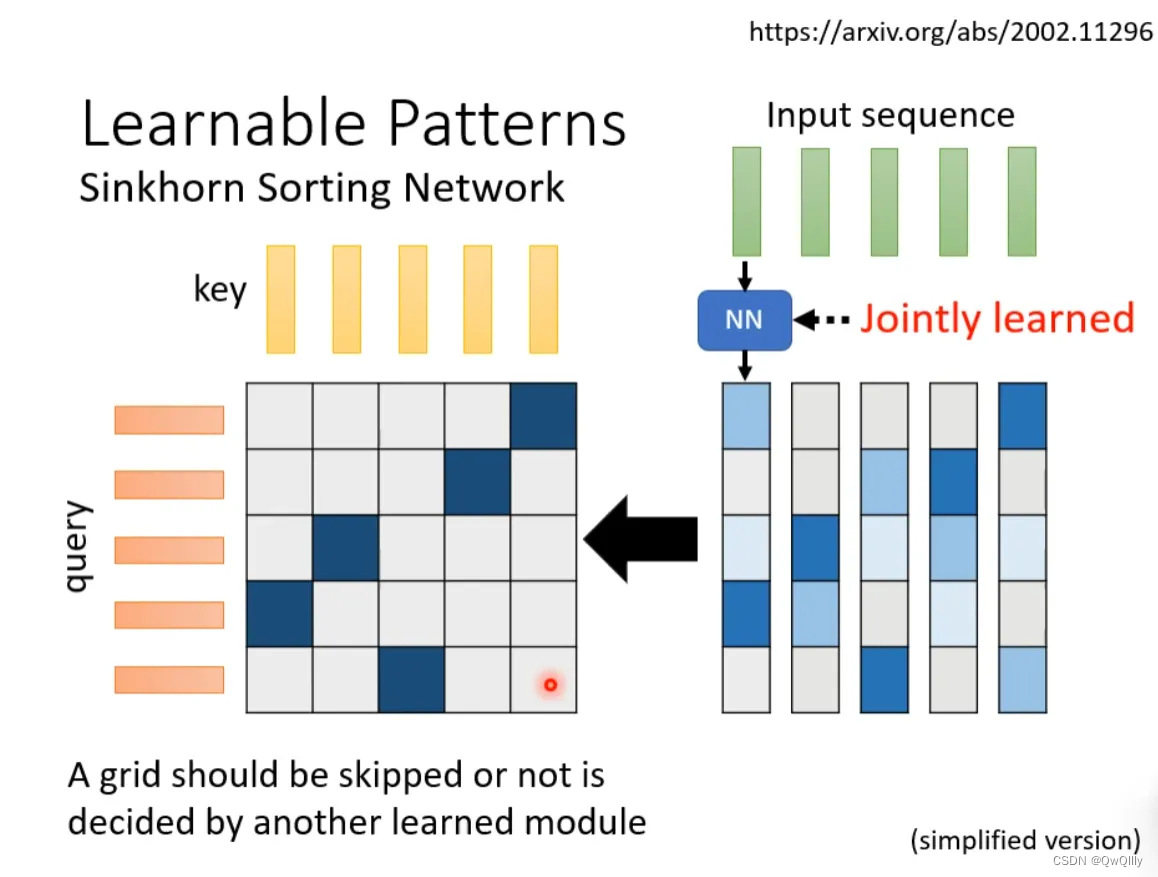
sinkhorn:Learnable Patterns
有没有一种将要不要算attention的事情用learn的方式学习出来呢?有可能的。可以再训练一个网络,输入是input sequence,输出是相同长度的weight sequence(N*N),将所有weight sequence拼接起来,再经过转换,就可以得到一个矩阵,值只有1和0,指明哪些地方需要算attention,哪些地方不需要算attention。该网络和其他网络一起被学出来。
有一个细节是:某些不同的sequence可能经过NN输出后共用同一个weight sequence,这样可以大大减小计算量。
Linformer:减少key数目
上述我们所讲的都是N*N的Matrix,但是实际来说,这样的Matrix通常来说并不是满秩的,一些列是其他列的线性组合,也就是说我们可以对原始N*N的矩阵降维,将重复的column去掉,得到一个比较小的Matrix。

具体来说,从N个key中选出K个具有代表的key,跟query做点乘,得到Attention Matrix。从N个value vector中选出K个具有代表的value,Attention Matrix的每一行对这K个value做weighted sum,得到self-attention模型的输出。
为什么选有代表性的key不选有代表性的query呢?因为query跟output是对应的,这样output就会缩短从而损失信息。

怎么选出有代表性的key呢?这里介绍两种方法,一种是直接对key做卷积(conv),一种是对key跟一个矩阵做矩阵乘法,就是将key矩阵的列做不同的线性组合。

Linear Transformer和Performer:另一种方式计算
回顾一下注意力机制的计算过程,其中I为输入矩阵,O为输出矩阵。
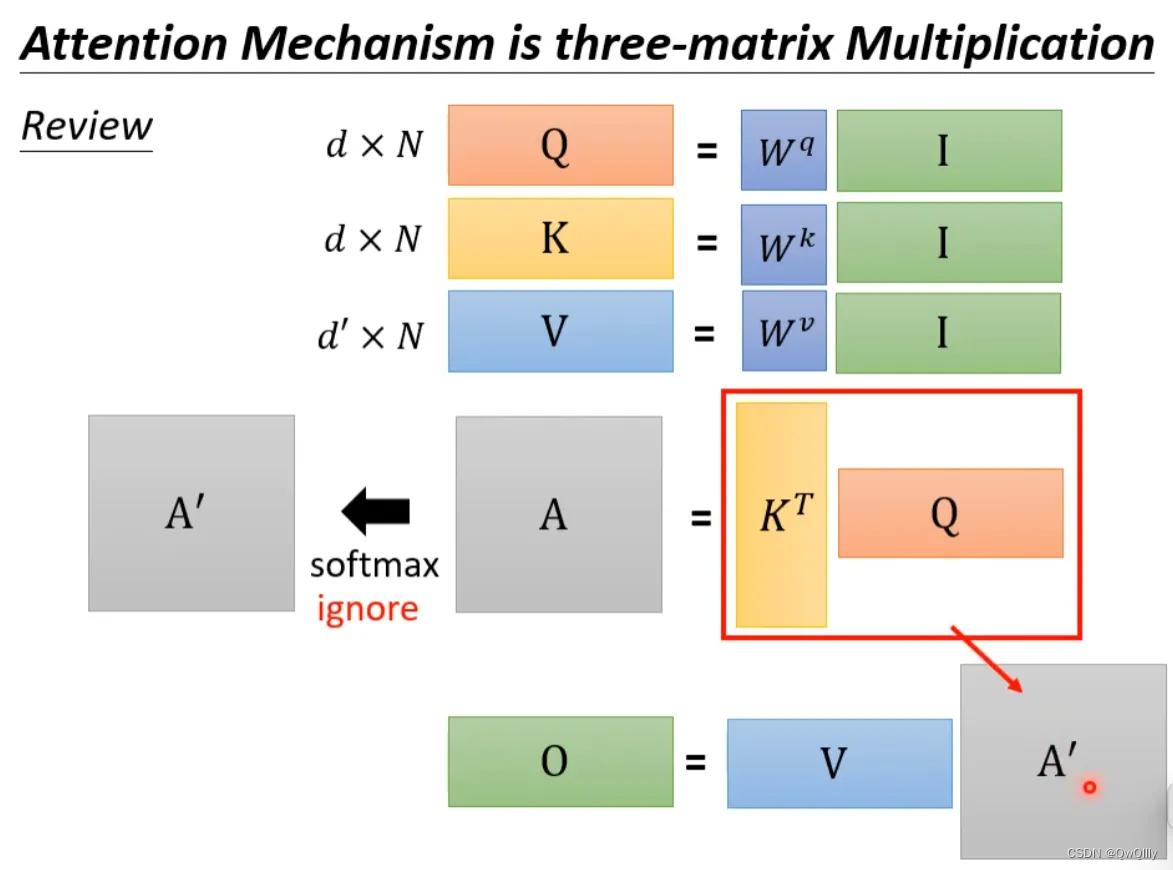
先忽略softmax,那么可以化成如下表示形式:

上述过程是可以加速的。如果先V*K^T,再乘Q的话,相比于K^T*Q,再乘V结果是相同的,但是计算量会大幅度减少。
附:线性代数关于这部分的说明

还是对上面的例子进行说明。K^T*Q会执行N*d*N次乘法,V*A会再执行d'*N*N次乘法,那么一共需要执行的计算量是(d+d')N^2。

V*K^T会执行d'*N*d次乘法,再乘以Q会执行d'*d*N次乘法,所以总共需要执行的计算量是2*d'*d*N。
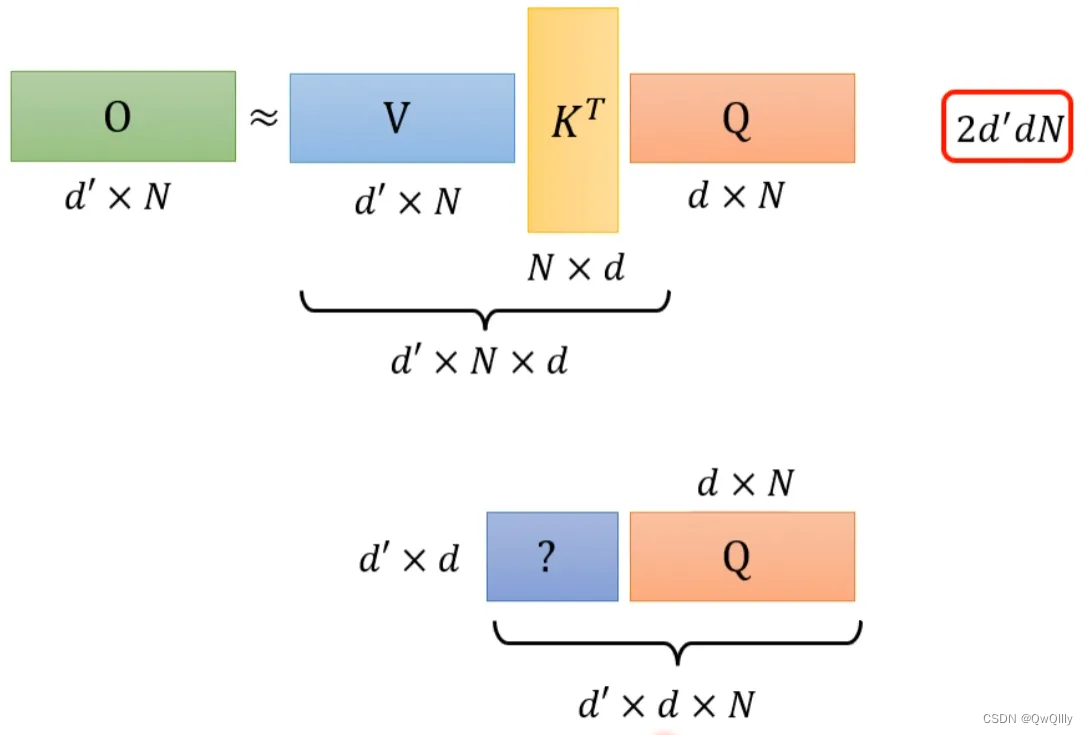
而(d+d')N^2>>2*d'*d*N,所以通过改变运算顺序就可以大幅度提升运算效率。
现在我们把softmax拿回来。原来的self-attention是这个样子,以计算b1为例:
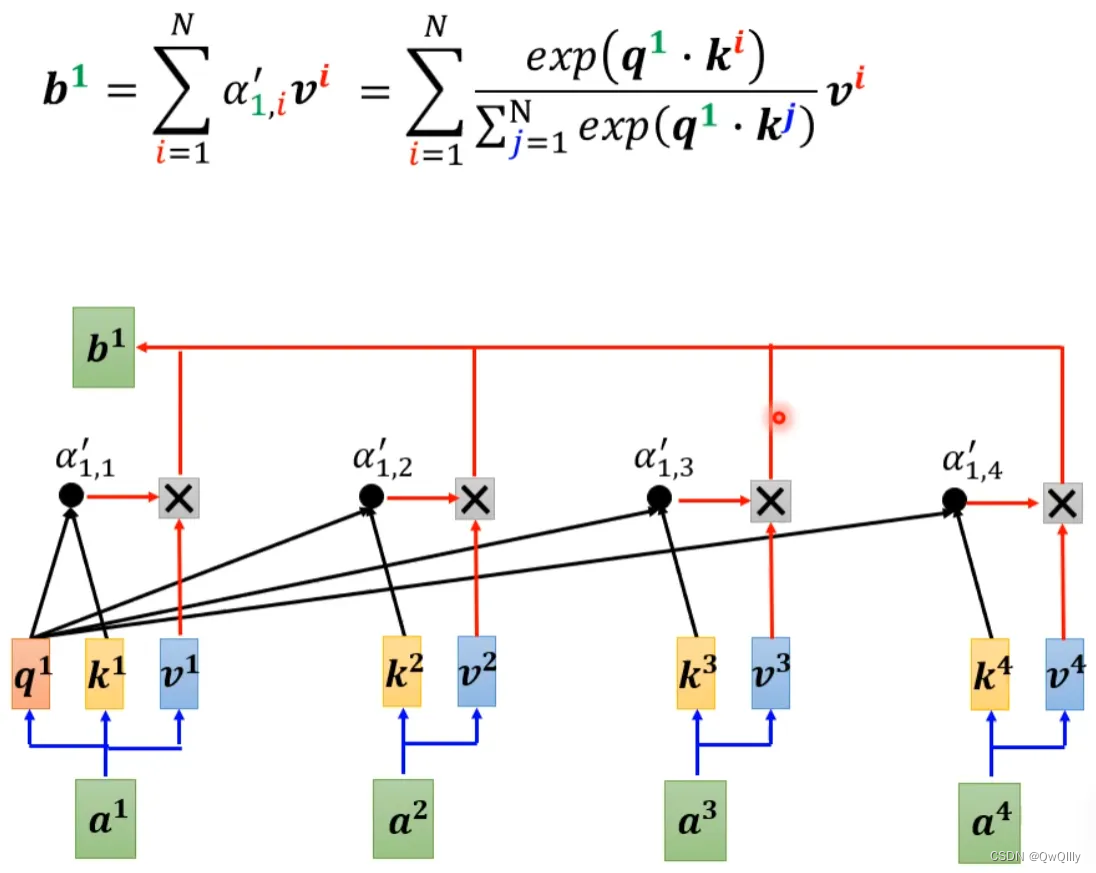
可以将exp(q*k)转换成两个映射相乘的形式,对上式进行进一步简化:
分母化简
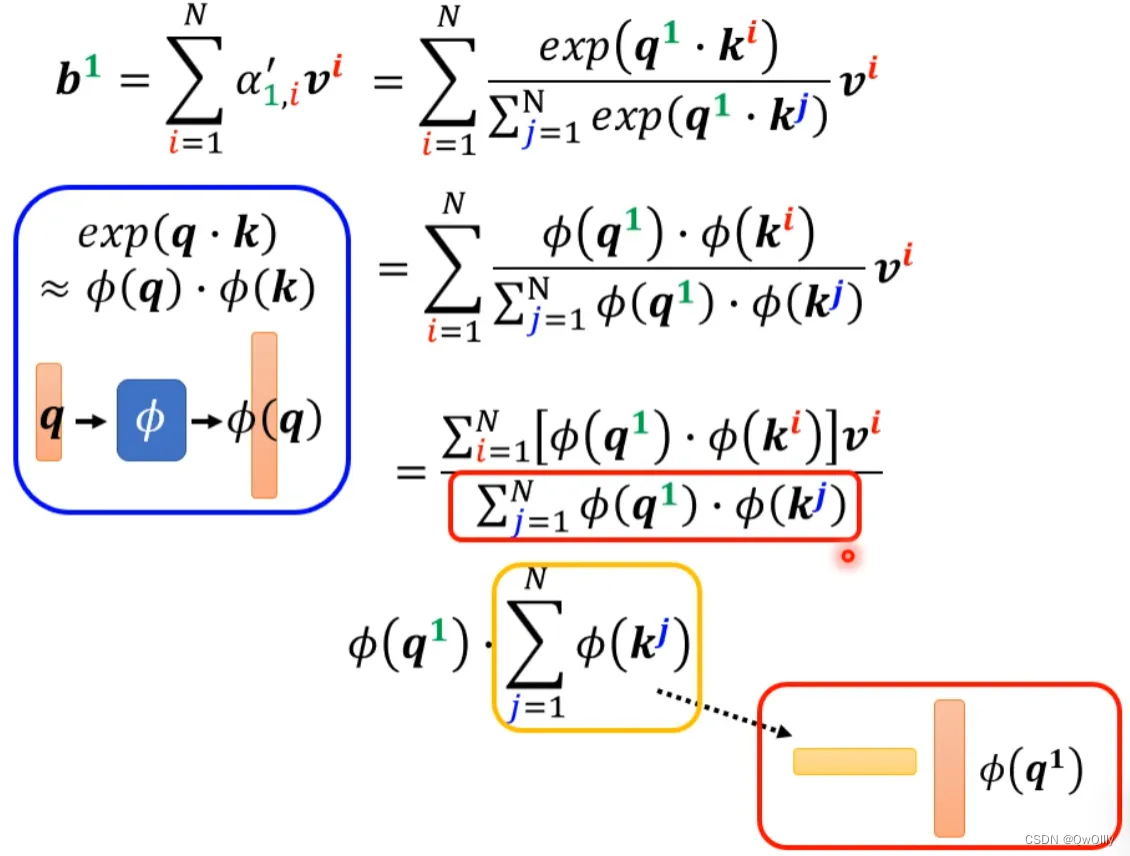
分子化简

将括号里面的东西当做一个向量,M个向量组成M维的矩阵,在乘以φ(q1),得到分子。

用图形化表示如下:
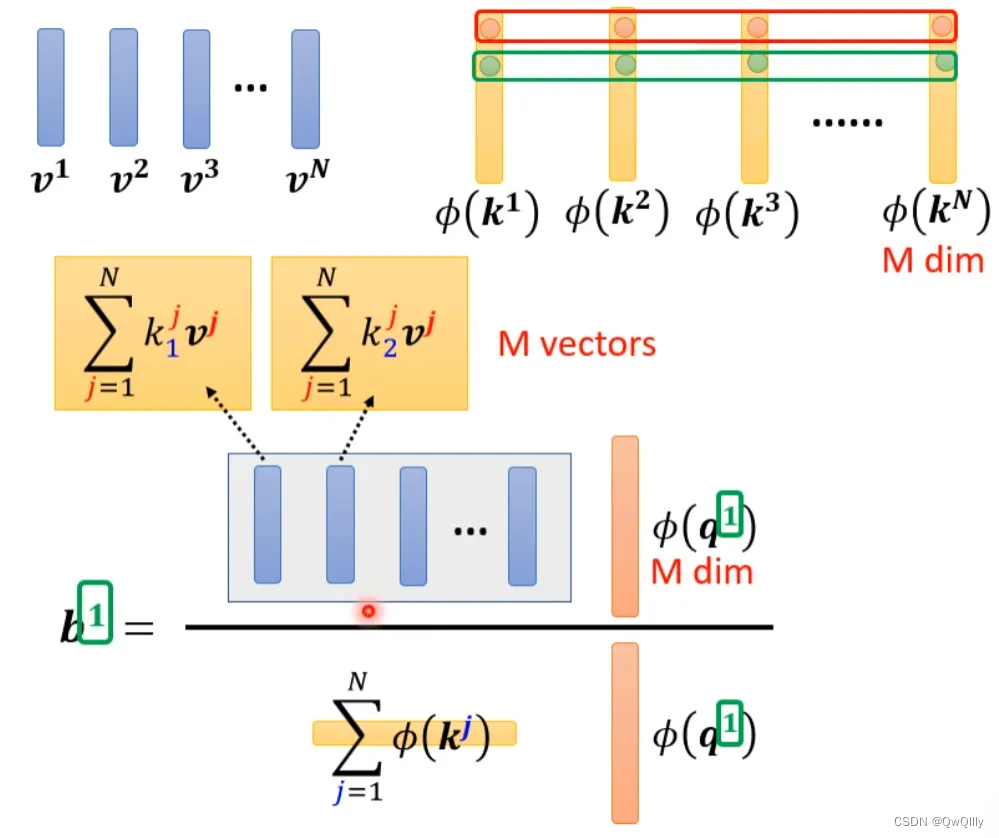
由上面可以看出蓝色的vector和黄色的vector其实跟b1中的1是没有关系的。也就是说,当我们算b2、b3...时,蓝色的vector和黄色的vector不需要再重复计算。

self-attention还可以用另一种方法来看待。这个计算的方法跟原来的self-attention计算出的结果几乎一样,但是运算量会大幅度减少。简单来说,先找到一个转换的方式φ(),对k进行转换得到M维向量φ(k),然后φ(k)跟v做weighted sum点乘得到M vectors。再对q做转换,φ(q)每个元素跟M vectors做weighted sum点乘,得到一个向量,即是b的分子。
其中M维的vector只需要计算一次。
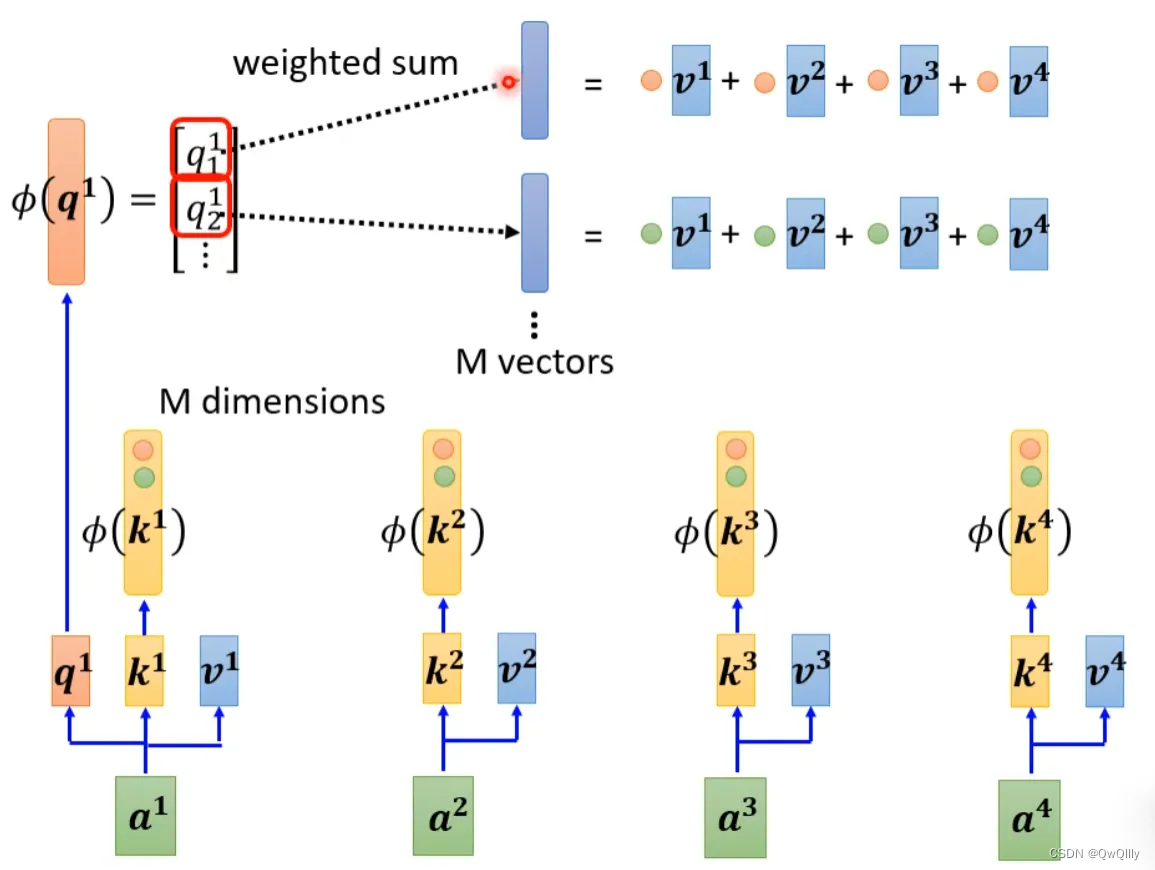
b1计算如下:

对于不同b,M vectors只需要计算一次。这种方式运算量会大幅度减少,计算结果一样的计算方法。
b2计算如下:

可以这样去理解,sequence每一个位置都产生v,对这些v做线性组合得到M个template(模板),然后通过φ(q)去寻找哪个template是最重要的(模板的线性组合),并进行矩阵的运算,得到输出b。
那么φ到底如何选择呢?不同的文献有不同的做法:

Synthesizer:attention matrix通过学习得到
在计算self-attention的时候一定需要q和k吗?不一定。
在Synthesizer文献里面,对于attention matrix不是通过q和k计算得到的,而是作为网络参数学习得到。虽然不同的input sequence对应的attention weight是一样的,但是performance不会变差太多。其实这也引发一个思考,attention的价值到底是什么?

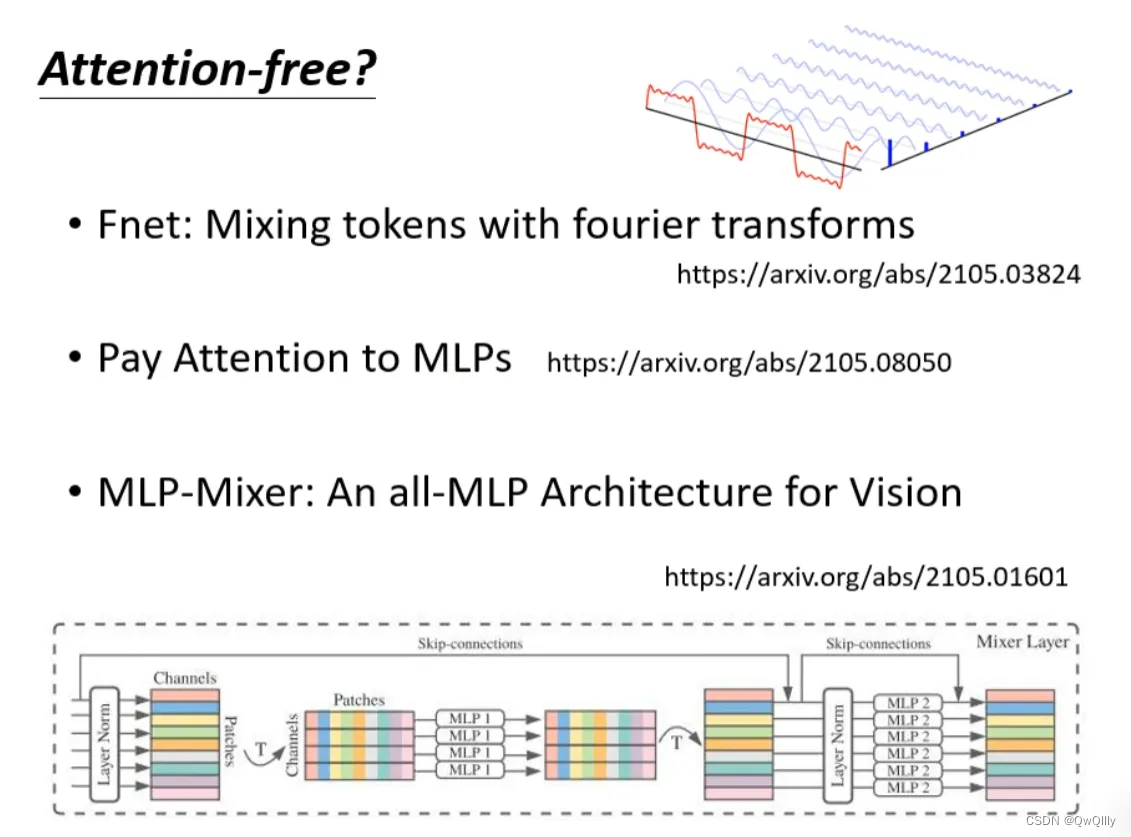
使用其他网络:不用attention
处理sequence一定要用attention吗?可不可以尝试把attention丢掉?有没有attention-free的方法?下面有几个用mlp的方法用于代替attention来处理sequence。
用mlp的方法用于代替attention来处理sequence。
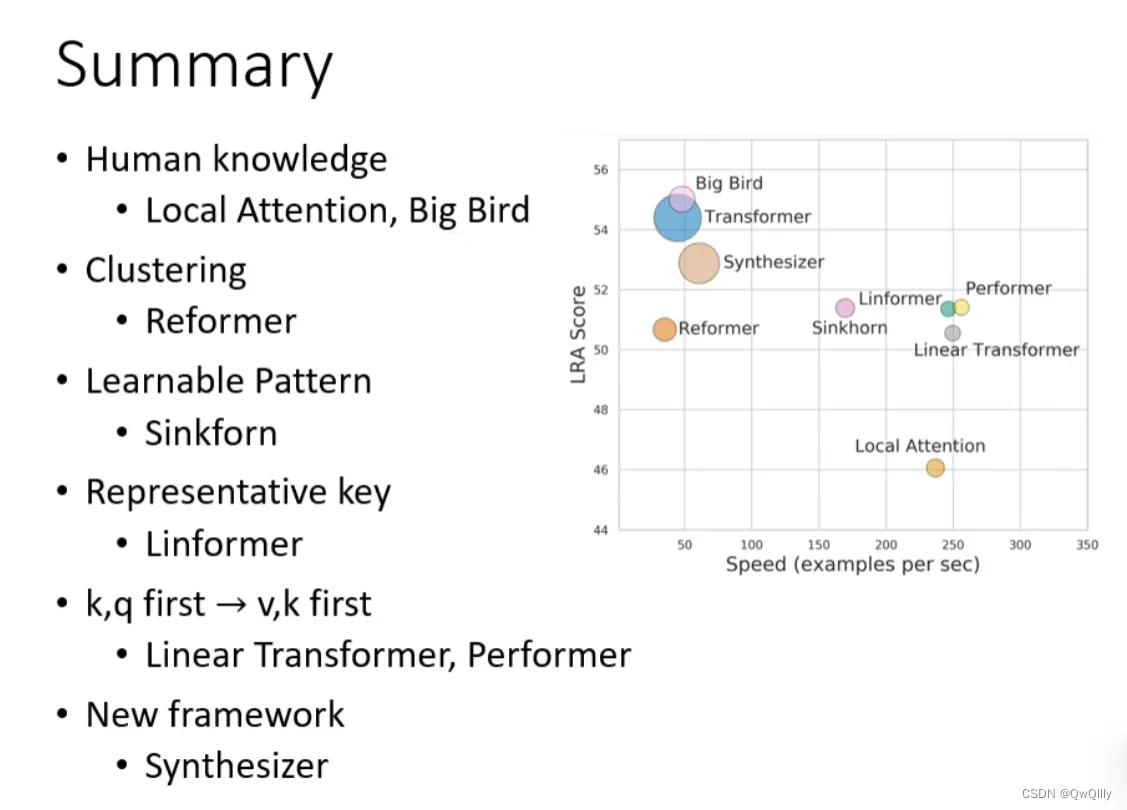
三、总结
最后这页图为今天所有讲述的方法的总结。下图中,纵轴的LRA score数值越大,网络表现越好;横轴表示每秒可以处理多少sequence,越往右速度越快;圈圈越大,代表用到的memory越多(计算量越大)。
相关文章:
2022最新版-李宏毅机器学习深度学习课程-P34 自注意力机制类别总结
在课程的transformer视频中,李老师详细介绍了部分self-attention内容,但是self-attention其实还有各种各样的变化形式: 一、Self-attention运算存在的问题 在self-attention中,假设输入序列(query)长度是N…...
css sprite 的优缺点,使用方法和示例
CSS Sprite是一种网页图片应用处理方式。 CSS Sprite的原理是将一个网页或者一个模块所用到的零碎的icon整合拼接到一张大图里,再把这张大图作为背景图放入到网页中,当访问该页面时,加载的图片就不会像以前那样一幅一幅地慢慢显示出来了。 …...
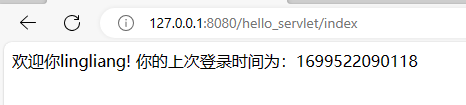
通过Cookie和Session来实现网站中登录账号的功能
文章目录 一、Cookie和Session二、基于Cookie和Session实现登录账号的功能2.1步骤一2.2步骤二2.3步骤三2.4总结通过Cookie和Session来实现登录功能2.5运行截图 一、Cookie和Session cookie是http请求header中的一个属性,是浏览器持久化存储数据的一种机制ÿ…...

QWidget 实现九宫格图案解锁
前言 最近需要实现一个九宫格图案解锁功能,查看网上的方案,基于QWidget的方案全网搜来搜去就一篇 Qt编写自定义控件:图案密码锁, 都是炒来炒去的同一篇,代码还比较复杂,运行后在PC端还是可以的,但是运行在arm机器上,就卡顿,或者容易断开手势连接线,各种不友好,于是自…...
)
设计模式-适配器模式(Adapter)
设计模式-适配器模式(Adapter) 一、适配器模式概述1.1 什么是适配器模式1.2 简单实现适配器模式1.3 使用适配器模式注意事项 二、适配器模式的用途三、实现适配器模式的方式3.1 继承适配器模式(Inheritance Adapter)3.2 组合适配器…...

react:创建项目
一: 使用create-react-app // 默认创建reactjs的webpack打包项目 npm i create-react-app -g create-react-app 项目名// 创建ts项目打包项目 sudo npx create-react-app my-app --template typescript 二: 使用vite npm create vitelatest // 创建react…...
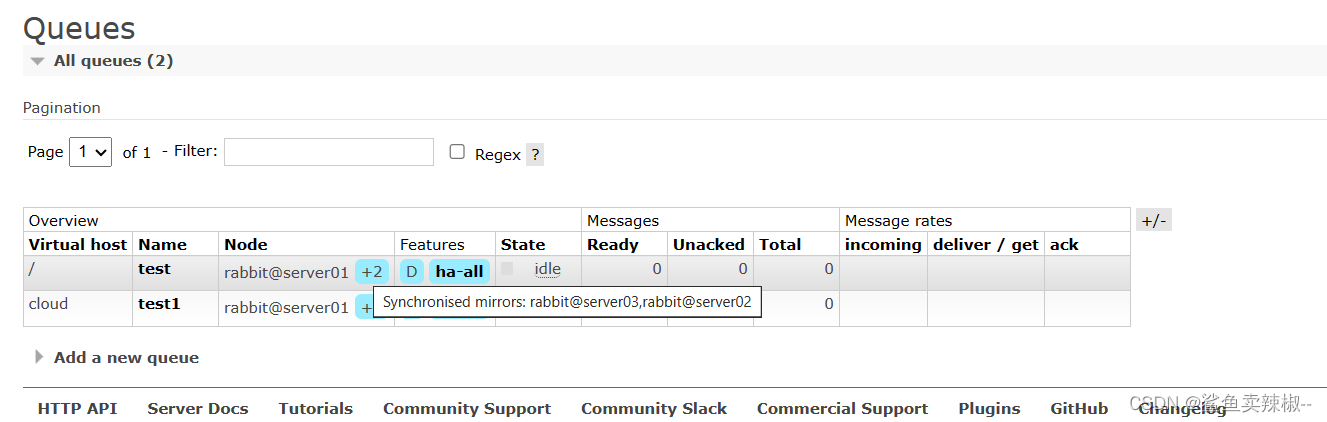
RabbitMQ集群
RabbitMQ概述 1.RabbiMQ简介 RabbiMQ是⽤Erang开发的,集群⾮常⽅便,因为Erlang天⽣就是⼀⻔分布式语⾔,但其本身并不⽀持负载均衡。支持高并发,支持可扩展。支持AJAX,持久化,用于在分布式系统中存储转发消…...

Qt QtCreator调试Qt源码配置
目录 前言1、编译debug版Qt2、QtCreator配置3、调试测试4、总结 前言 本篇主要介绍了在麒麟V10系统下,如何编译debug版qt,并通过配置QtCreator实现调试Qt源码的目的。通过调试源码,我们可以对Qt框架的运行机制进一步深入了解,同时…...

JavaScript如何实现钟表效果,时分秒针指向当前时间,并显示当前年月日,及2024春节倒计时,源码奉上
本篇有运用jQuery,记得引入jQuery库,否则不会执行的喔~ <!DOCTYPE html> <html> <head> <meta charset"utf-8"> <title></title> <meta name"chenc" content"Runoob"> <met…...
重生奇迹MU套装大全中的极品属性
在重生奇迹MU之中,你不能如其他游戏一般只看攻击与防御,你更要看属性,这才是重生奇迹中的王道!属性好,才是极品,属性不佳,即便攻击、防御再出色,也只能沦落成为一件替用品࿰…...

用Python解决猴子分桃问题
1 问题 海滩上有一堆桃子,五只猴子来分。第一只猴子把这堆桃子平均分为五份,多了一个,这只猴子把多的一个扔入海中,拿走了一份。第二只猴子把剩下的桃子又平均分成五份,又多了一个,它同样把多的一个扔入海中…...

YOLOv8-Seg改进:分割注意力系列篇 | 新型的多尺度卷积注意力(MSCA)模块
🚀🚀🚀本文改进: 新型的多尺度卷积注意力(MSCA)模块,实现创新,MSCA包含三个部分:深度卷积聚合局部信息,多分支深度条卷积捕获多尺度上下文,以及11卷积建模不同通道之间的关系。 🚀🚀🚀MSCA多尺度特性在小目标分割检测领域表现优异 🚀🚀🚀YOLOv8-seg…...

基于springboot实现致远汽车租赁平台管理系统项目【项目源码+论文说明】计算机毕业设计
基于springboot实现致远汽车租赁平台管理系统演示 摘要 首先,论文一开始便是清楚的论述了系统的研究内容。其次,剖析系统需求分析,弄明白“做什么”,分析包括业务分析和业务流程的分析以及用例分析,更进一步明确系统的需求。然后在明白了系统的需求基础上需要进一步地设计系统…...
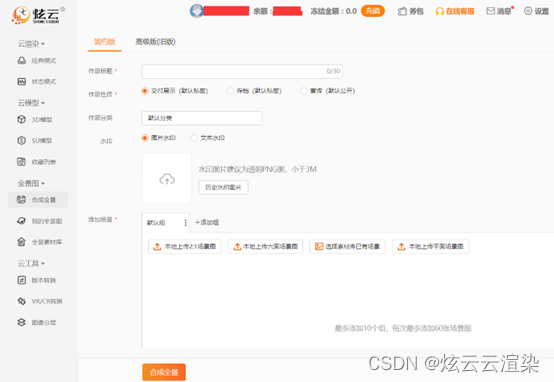
真的设计师做图只需要一个炫云客户端就够了
真的设计师做图只需要一个炫云客户端就够了,为什么这么说呢?因为炫云的这个客户端功能真的太全了,设计师想要的功能在炫云客户端上都有,而且还很多功能是免费的,非常的实用,具体有哪些功能我们一起来看看吧…...

简述 HTTP 请求的过程是什么?
HTTP(Hypertext Transfer Protocol)请求的过程可以简单地描述为客户端与服务器之间的通信交互。下面是一般的 HTTP 请求过程: 解析 URL:客户端解析目标 URL,提取出服务器的主机名(域名)和端口号…...

免root修改手机imei的技术原理是什么?如何实现的?hook吗
在过去,修改手机IMEI(International Mobile Equipment Identity)通常需要Root权限,这给用户带来了一些不便,也存在一定的安全风险。然而,近年来,一些技术爱好者提出了一种免Root修改手机IMEI的方…...

【Redis】整合使用,进行注解式开发及应用场景和击穿、穿透、雪崩的讲解
目录 一、整合 1. 为什么 2. 整合应用 ( 1 ) pom配置 ( 2 ) 所需配置 3. 注解式开发及应用场景 1. Cacheable 2. CachePut 3. CacheEvict 4. 击穿、穿透、雪崩 一、整合 1. 为什么 Redis可以与SSM项目整合,主要是为了提高项目的性能和效率。以下是整合Re…...
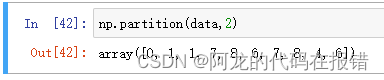
数据分析-numpy
numpy numpy numpy简介优点下载ndarray的属性输出数据类型routines 函数ndarray对象的读写操作ndarray的级联和切分级联切分 ndarray的基本运算广播机制(Broadcast)ndarry的聚合操作数组元素的操作numpy 数学函数numpy 查找和排序 写在最后面 简介 nump…...
【Java】云HIS云端数字医院信息平台源码
一、云HIS系统特色 • 使用简易化 即开即用,快速复制,按需开通功能模块,多机构共享机房、软件、服务器、存储设备等资源,资源利用最大化。 • 连锁集团化 可支持连锁集团化管理,1N模式,支撑运营&#x…...

Jupyter Notebook 内核似乎挂掉了,它很快将自动重启
报错原因: OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized. OMP: Hint This means that multiple copies of the OpenMP runtime have been linked into the program. That is dangerous, since it can degrade perfo…...

哈氏训练助力孩子克服作业拖延症与情绪表达困难
哈氏训练在克服作业拖延症中的应用与效果分析 哈氏训练是一种有效的方式,旨在帮助孩子面对作业拖延症。这种训练方法通过结构化的任务管理技巧,帮助孩子建立良好的学习习惯。在训练过程中,孩子学会将大任务分解为小步骤,从而减轻心…...

BililiveRecorder录播引擎深度解析:3大核心架构与5项企业级部署策略
BililiveRecorder录播引擎深度解析:3大核心架构与5项企业级部署策略 【免费下载链接】BililiveRecorder 录播姬 | mikufans 生放送录制 项目地址: https://gitcode.com/gh_mirrors/bi/BililiveRecorder BililiveRecorder作为一款专注于B站直播录制的开源工具…...

BililiveRecorder终极指南:快速掌握B站直播录制完整方案
BililiveRecorder终极指南:快速掌握B站直播录制完整方案 【免费下载链接】BililiveRecorder 录播姬 | mikufans 生放送录制 项目地址: https://gitcode.com/gh_mirrors/bi/BililiveRecorder BililiveRecorder是一款专门为B站直播设计的开源录播工具ÿ…...

萤石2026新品发布会:AI驱动创新,以安全科技共创美好生活
萤石举办2026品牌新品发布会,展现AI创新成果4月21日,全球领先的安全智能生活品牌萤石在杭州正式举办2026品牌新品发布会。这场以“驭智向前”(Ahead with Intelligence)为主题的盛会,全景式展现了AI驱动下的创新成果&a…...

番茄小说下载器:轻松保存您喜爱的网络小说
番茄小说下载器:轻松保存您喜爱的网络小说 【免费下载链接】fanqienovel-downloader 下载番茄小说 项目地址: https://gitcode.com/gh_mirrors/fa/fanqienovel-downloader 想要永久收藏番茄小说平台上的精彩故事吗?这款免费开源的番茄小说下载器正…...

如何实现网盘直链解析工具的高速下载:5个实用技巧
如何实现网盘直链解析工具的高速下载:5个实用技巧 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云盘…...

网盘下载限速终结者:8大平台直链一键获取,解放你的生产力!
网盘下载限速终结者:8大平台直链一键获取,解放你的生产力! 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里…...

Windows BAT脚本提权实战:从‘拒绝访问’到完美运行,我的踩坑记录与两种VBS方案详解
Windows BAT脚本提权实战:从权限不足到完美执行的深度解析 1. 当脚本遇到"拒绝访问":一个真实的权限困境 上周三凌晨2点,我正试图通过批处理脚本自动化部署一套本地测试环境。当脚本尝试修改C:\Windows\System32\drivers\etc\hosts…...

Ubuntu 18.04 + CUDA 9.0 环境下,保姆级避坑指南:从源码编译GCC 4.9.2到成功运行DensePose
Ubuntu 18.04 CUDA 9.0 环境下GCC 4.9.2源码编译全攻略:破解DensePose安装的核心难题 在计算机视觉领域,DensePose作为将2D图像中的人体像素映射到3D表面模型的重要工具,其安装过程却常常让开发者望而生畏。特别是在Ubuntu 18.04和CUDA 9.0环…...

深蓝词库转换:3分钟搞定30+输入法词库迁移的完整指南
深蓝词库转换:3分钟搞定30输入法词库迁移的完整指南 【免费下载链接】imewlconverter ”深蓝词库转换“ 一款开源免费的输入法词库转换程序 项目地址: https://gitcode.com/gh_mirrors/im/imewlconverter 你是否曾因更换输入法而面临词库无法迁移的困扰&…...