数据分析-numpy
numpy
numpy
- numpy
- 简介
- 优点
- 下载
- ndarray的属性
- 输出
- 数据类型
- routines 函数
- ndarray对象的读写操作
- ndarray的级联和切分
- 级联
- 切分
- ndarray的基本运算
- 广播机制(Broadcast)
- ndarry的聚合操作
- 数组元素的操作
- numpy 数学函数
- numpy 查找和排序
- 写在最后面

简介
numpy是一个基于python的扩展库
优点
提供了高纬数组对象ndarray,运算的速度碾压python的list,提供了各种高级数据编程工具,如矩阵计算,向量运算快速筛选,IO操作,傅里叶变换,线性代数,随机数等
下载
下载非常的简单在cmd中执行以下命令即可
pip install numpy
ndarray的属性
1.ndim:维度
# 导入模块
import numpy as np
# 生成一个ndarray对象
arr1 = np.array([1,2,3])
arr1.ndim # 1
# 生成一个ndarray对象
arr2 = np.array([[1,2,3],[4,5,6]])
arr2.ndim # 2
2.shape:形状(各维度的长度)
# 导入模块
import numpy as np
# 生成一个ndarray对象
arr1 = np.array([1,2,3])
arr1.shape # (2, 3)
# 生成一个ndarray对象
arr2 = np.array([[1,2,3],[4,5,6]])
arr2.shape # (3,)
3.size:(总长度)
# 生成一个ndarray对象
arr1 = np.array([1,2,3])
arr1.size # 3
arr2 = np.array([[1,2,3],[4,5,6]])
arr2.size # 6
4,dtype:元素类型
# 生成一个ndarray对象
arr1 = np.array([1,2,3])
arr1.dtype # dtype('int32')
arr2 = np.array([[1,2,3],[4,5,6]])
arr2.dtype # dtype('int32')
type(arr)和dtype(arr)的区别:
type是查询arr这个数据对象的类型,而dtype是查询arr数组中的内容的数据类型
输出
1.display(建议使用)
arr1 = np.array([1,2,3])
arr1.ndim
display(arr1)
2.print
arr1 = array([1, 2, 3])print(arr1)
[1 2 3]
3.output
数据类型
数据类型:numpy设计初衷是用于运算 的所以对数据类型进行 统一优化(统一是为了提高运算速度)
注意:
numpy默认是ndarray的所有元素的类型相同的
如果传进来的列表中的包含不同类型,则统一为同一类型,
优先级:str->float->int
U表示unicode的简写形成
routines 函数
1.np.ones(shape,dtype=none,order=‘c’)
生成一个都是1的高维数组
shape:形状 dtype:形状
np.ones((3,4),dtype=np.float32)

2.np.zeros(shape,dtype=none,order)
生成一个都是0的高维数组
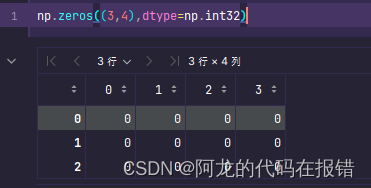
np.zeros((3,4),dtype=np.int32)
3.np.full(shape,full_value,odert=‘c’)
生成一个指定值的高维数组
full_value:指定的值
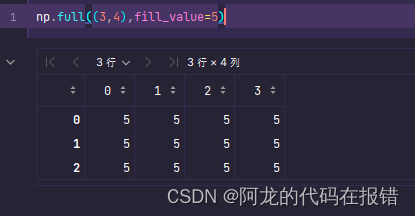
np.full((3,4),fill_value=5)
4.np.eye(n,m=None,k=0,dtype=float)
生成一个默认情况下,对角线
第一个参数:输出方阵的规模,即行数
第二个参数:输出的方阵即列数如果默认,默认为第一参数的值
第三个参数:默认情况下输出的是对角线都是1 其余的都是0的方阵如果k为正整数,则在又上方的第k条对角线全是1其余的都是0,k为负整数则在左下方第k条对角线全是1其余的都是0
第四个参数:数据类型,返回数据类型
np.eye(3,4,1,np.int32)

5.np.linespace(start,stop,num=50,endpoint=True,restep=False,dtype=None)
生成一个等差数列
start:开始的数值 stop:停止的值 num:取多少个值 endpoint=是否保留最后一个值 retstep:默认为Flase如果开启则返回的序列结果为一个元组,对应的序列在【start,end】
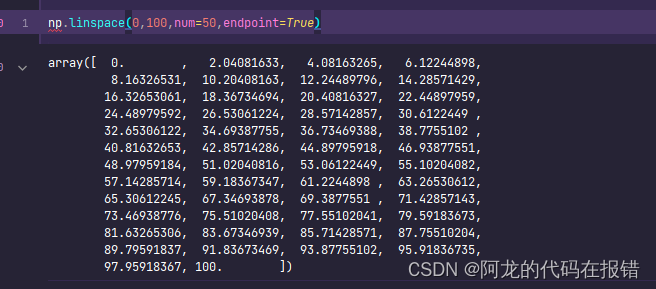
np.linspace(0,100,num=50,endpoint=True)
6.np.range(start,stop,[step],dtype=None)
生成一个等差数组
import numpy as np
np.arange(start=0,stop=100,step=2)

araneg 和linespace的区别
linespace通过指定需要多个数值组成的数组,arange:通过设置步长确定数值
7.np.random.randint(low,hight=None,size=None,dtype=None)
生成 一个随机的整数类型的数组

8.正态分布
np.random,randn()
** 标准的正态分布**
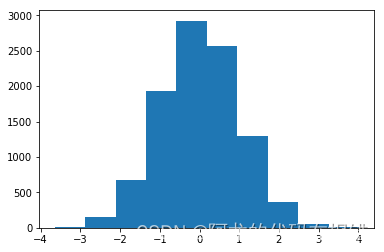
np.random.normal() 普通的正态分析
从正态(高斯)分布中抽取随机样本
参数:
loc:float 或 array_like 的浮点数
分布的均值(“中心”)。
scale:缩放浮点数或浮点数的array_like
分布的标准差(分布或“宽度”)。必须是 非负数。
size: int 或 int 的元组,可选
输出形状。如果给定的形状是,例如,,则绘制样本。如果 size 为(默认值), 如果 和 都是标量,则返回单个值。 否则,将抽取样本。(m, n, k)m * n * kNonelocscalenp.broadcast(loc, scale).size
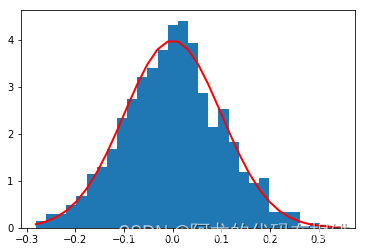
mu, sigma = 0, 0.1 # mean and standard deviation
s = np.random.normal(mu, sigma, 1000)
abs(mu - np.mean(s))
abs(sigma - np.std(s, ddof=1))
import matplotlib.pyplot as plt
count, bins, ignored = plt.hist(s, 30, density=True)
plt.plot(bins, 1/(sigma * np.sqrt(2 * np.pi)) *np.exp( - (bins - mu)**2 / (2 * sigma**2) ),linewidth=2, color='r')
plt.show()
9.np.random.random(size)
生成0-1的随机数左闭右开
参数:
size:大小
np.random.random((10,10))

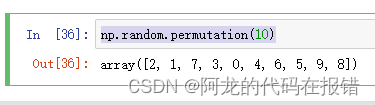
10.np.random.permutaion(10)
生成随机索引可以与列表索引进行数组的随机索引
num:生成随机索引的个数
np.random.permutation(10)
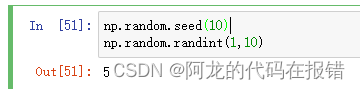
11.np.random.seed(0)
设置种子以后,可以使随机不再发生变化
num:设置种子数
在这一步只设置种子,并不产生随机数
np.random.seed(10)
np.random.randint(1,10)
ndarray对象的读写操作
索引的访问
数组对象可以使用索引的方式进行获取,高维数组访问使用【dim1_index,dim2_index,…】
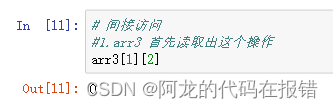
间接访问:arr[index][index]
# 间接访问
arr3 = np.random.randint(0,10,size=(2,5))
#1.arr3 首先读取出这个操作
arr3[1][2]
array提供的访问方式:arr[index1,index2]
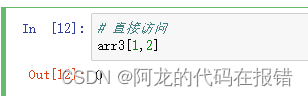
# 直接访问
arr3 = np.random.randint(0,10,size=(2,5))
#1.arr3 首先读取出这个操作
arr3[1][2]
列表访问:先将需要获取的数值的索引位置统一存放在一个列表中,然后再使用索引进行逐个获取。
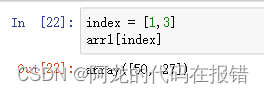
arr1 = np.random.randint(0,100,size=10)
index = [1,3]
arr1[index]
切片访问:通过切片进行数组的获取
arr2 = np.random.randint(0,100,size=(5,5))
arr2[1:4:5]
arr2[::-1]

通过布尔类型进行获取
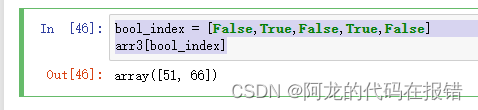
arr3 = np.random.randint(0,100,size=(5,))
bool_index = [False,True,False,True,False]
arr3[bool_index]
数组支持访问形式:int 【int】 切片 bool类型
ndarray的级联和切分
级联
级联的注意事项:
1.级联的参数是列表:一定要加中括号或者小括号
2.维度相同
# 维度不同无法级联
r1 = np.random.random(size=(3,))
r2 = np.random.random(size=(3,4))
r3 = np.concatenate((r1,r2))
r3
ValueError: all the input arrays must have same number of dimensions
3.形状相同
# 不同形状无法级联
s1 = np.random.random(size=(3,4))
s2 = np.random.random(size=(3,3))
s3 = np.concatenate((s1,s2))
#ValueError: all the input array dimensions except for the concatenation axis must match exactly
4.级联的方向是默认的是shape这个元组的第一个值所代表的方向
5.可以通过axis参数修改级联的方向
1.np.concatenate((a1,a2),axis=0)
参数:
(a1,a2) :要拼接的数组 axis:拼接的方向
axis=0 的时候数组进行纵连接 axis=1:数组进行横向拼接
a1 = np.random.randint(0,10,size=(3,4))
a2 = np.random.randint(10,20,size=(3,4))
print(a1)
print(a2)
np.concatenate((a1,a2),axis=0)
np.concatenate((a1,a2),axis=1)

2.np.hstack((a1,a2))
横向拼接
参数
(a1,a2): 要拼接的数组
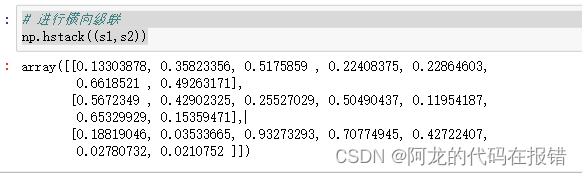
# 进行横向级联
np.hstack((a1,a2))
切分
与级联类似以下三个函数可以完成切分工作:
# 创建一个可以拆分的数组
a1,a2 = np.split(arr,indices_or_sections=2,axis=0)
display(a1,a2)
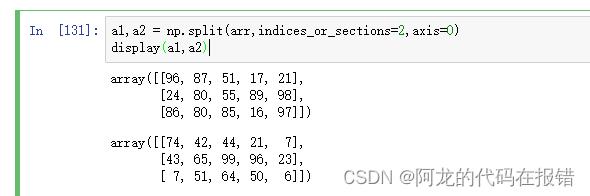
1.np.split(arr,切分规则,轴向)
如果切分规则为数组【m:n】那么数组的分割方式为0:m m:n n:最后
a1,a2 = np.hsplit(arr,2)
display(a1,a2)
2.np.hsplit()
横向切分
arr:要拆分的数组 indices_or_sections:拆分规则
a1,a2 = np.hsplit(arr,2)
display(a1,a2)

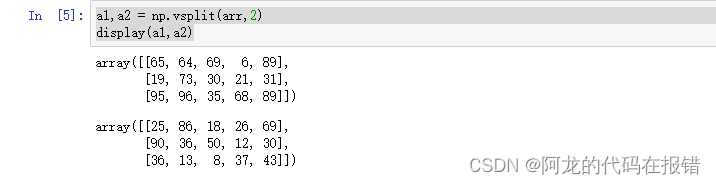
3.vsplit()
纵向切分
arr:要拆分的数组 indices_or_sections:拆分规则
a1,a2 = np.vsplit(arr,2)
display(a1,a2)
ndarray的基本运算
基本运算规则:
如果数组的形状相同的时候使用加法:相对应位置的数值进行计算
如果数组与单个数值进行计算:这个数值与数组的每个位置的数值进行计算
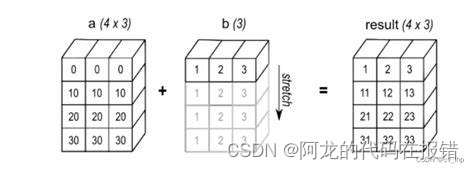
广播机制(Broadcast)
ndarray的广播机制的两条规则:
- 两个数组的后缘维度(即从末尾到开始的算起的为度)轴长度相符
- 或者其中一方长度为1
符合上面的两个规则的,则认为他们广播兼容的。广播会在缺失和(或)长度为1 的维度上进行
广播的过程:
将维度少和维度多的数组并且符合上面的规则将会把维度少的数值进行数组的扩展到相同的形状再进行相对位置的运算最后得到结果
ndarray可以和任何整数进行广播
ndarry的聚合操作
1.求和 arr.sum()
import numpy as np
data = np.random.randint(0,100,size=5)
data
data.sum()

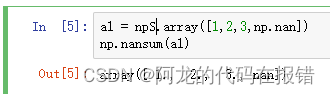
2.arr.nannum()
计算带有空值的数组
a1 = np.array([1,2,3,np.nan])
np.nansum(a1)
3.arr.max()|arr.min()
获取数组中的最大值或最小值
a1 = np.array([1,2,3,11])
# 最大值
np.max(a1)
# 最小值
np.min(a1)

4.any() | all()
np.any():
一个数组中如果数组中至少有一个返回的结果就为True
np.all(np.array([True,True,False,False]))

np.all()
一个数组中。如果数组中全部为True则返回True否则返回的结果就是Flase
5.np.nan
np.nan是一个浮点数,在python中None是None类型
np.nan与任何值相加都会得到np.nan
数组元素的操作
添加元素
numpy.append
在数组末尾添加值。追加会为分配整个数组,并且把原来的数组复制到新的数组
参数
arr:原数组 values:追加的值(可以为数组) axis :要追加的形式(追加到行还是列)
注意:如果是追加数组,需要将追加的数组设置为相同维度的数组进行追加
a1 = np.random.randint(1,100,size=(6,6))
np.append(a1,[[64, 63, 13, 89, 33, 55]],axis=0)
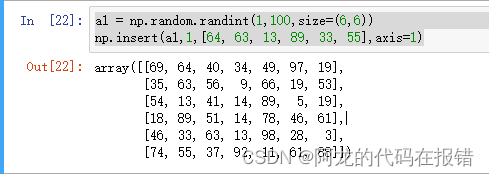
如果没有设置轴,数组将会被展开
a1 = np.random.randint(1,100,size=(6,6))
a2 = np.array([1,2,3,4,5,6])
a3 = np.append(a1,a2)
display(a1,a2,a3)

插入元素
np.insert
函数在给定索引之前,沿着给定的轴在输入数值中插入的值
参数:
arr:被插入的数组 obj:要插入的位置 values:要插入的值
a1 = np.random.randint(1,100,size=(6,6))
np.insert(a1,1,[64, 63, 13, 89, 33, 55],axis=1)
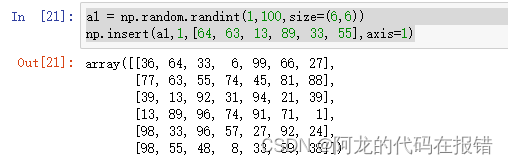
如果没有提供轴,数据将会被展开
a1 = np.random.randint(1,100,size=(6,6))
np.insert(a1,1,10)
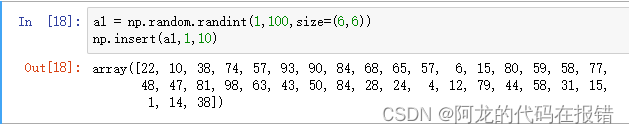
删除元素
np.delete
函数返回输入数值中删除指定数组的新数组
a1 = np.random.randint(1,100,size=(6,6))
np.delete(a1,[32, 10, 86, 3, 34, 46],axis=0)

如果没有提供轴,数据将会被展开
a1 = np.random.randint(1,100,size=(6,6))
np.delete(a1,[32, 10, 86, 3, 34, 46])

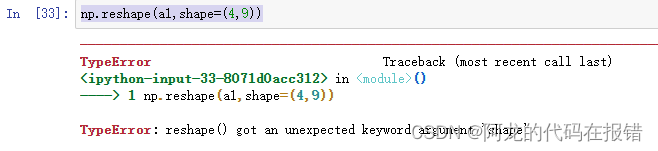
数组变形(reshape)
np.reshape:函数可以在不改变数据条件下修改形状
参数:
arr:要改变形状的数组 new_shape:想要修改成的形状,整数或者整数数组,新的形状应该兼容之前的形状
order:‘c’ — 按行 ‘F’ — 按列 ‘A’- -----按照原来的顺序 ‘K’-----元素在内存中出现的顺序
a1 = np.random.randint(1,100,size=(6,6))
np.reshape(a1,(4,9))
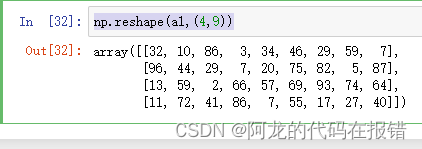
注意:不能显示的使用shape参数,否则会报错
np.reshape(a1,shape=(4,9))
数组的迭代器
ndarray.flat
两段代码的最后实现的效果是一样的
for i in a1.flat for i in a1:========> for i1 in i: print(i1)print(i)
数组的扁平化处理
ndarray.flatten():返回一份展开数组的拷贝,对拷贝的数组进行修改,对原来的数组不会影响到原来的数组
ndarray.ravel():展开数组,返回一个展开的数组引用,修改会影响原始数组。
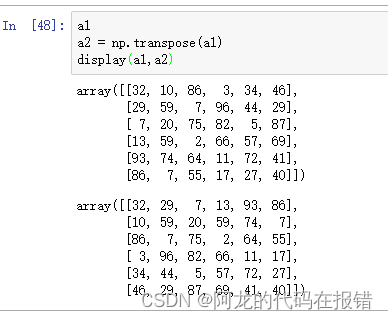
数组翻转
np.transpose:翻转数组的维度
这个函数只有两个参数
a:需要翻转的数组 ,axes=选择的列或行
a1
a2 = np.transpose(a1)
display(a1,a2)
numpy 数学函数
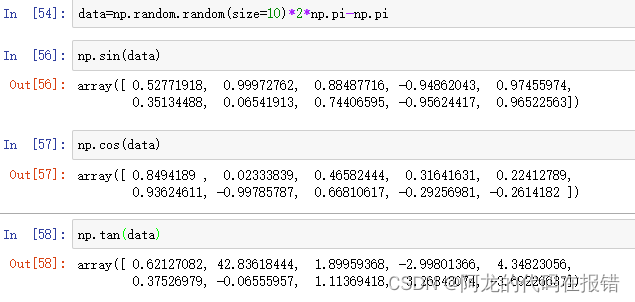
三角函数(这里需要注意:三角函数接受的参数是弧度不是角度):
np.sin() np.cos np.tan()
data=np.random.random(size=10)*2*np.pi-np.pi
np.sin(data)
np.cos(data)
np.tan(data)
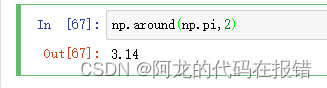
舍入函数
np.around()
参数:
a:数组 decimals:舍入的小数位。默认值为0,如果为负,整数将四舍五入到小数点最左侧的位置
np.around(np.pi,2)
算数函数
加减乘除:add(),subtract(),multipy(),divide()
np.add()
import numpy as np
# 1+1
np.add(1,1)
# 7-1
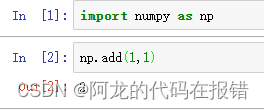
np.subtract(7,1)

乘
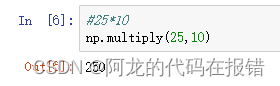
除
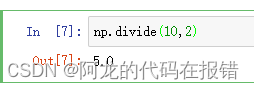
幂运算(可以做开放运算):
np.power(16,2)
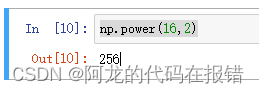
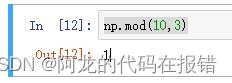
求余运算:
np.mod(10,3)
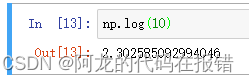
自然底数的对数:
np.log(),np.log^2 ()
,np.log^10()
np.log(10)
numpy 查找和排序
查找索引:
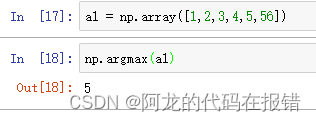
argmax:返回最大的值的索引位置
a1 = np.array([1,2,3,4,5,56])
np.argmax(a1)
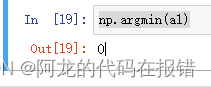
argmin:返回最小的值的索引位置
a1 = np.array([1,2,3,4,5,56])
np.argmin(a1)
条件查询
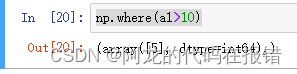
np.where:函数返回输如数组中给定条件的元素索引
参数:
condition:条件表达式
a1 = np.array([1,2,3,4,5,56])
np.where(a1>10)
快速索引
np.start()与ndarray.stort()都可以进行排序但是有区别
np.start()不改变输出方式 ndarray.sort() 本地处理,不占用空间,但是改变输出的方式
data = np.random.randint(1,100,10)
np.sort(data)
data.sort()

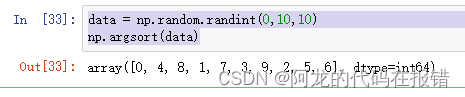
索引排序
np.argsort():函数返回的是数组从小到大的索引值
data = np.random.randint(0,10,10)
np.argsort(data)
部分索引
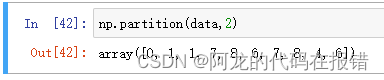
np.partition(a,k):当k为正数的时候得到最小的k个数,当k为负数的时候,得到最大的k个数
他只是给k个数进行排序不是显示k个数
data = np.random.randint(0,10,10)
np.partition(data,2)
写在最后面
个人笔记,如果有错误的地方希望各位大佬帮忙指正纠正。
相关文章:
数据分析-numpy
numpy numpy numpy简介优点下载ndarray的属性输出数据类型routines 函数ndarray对象的读写操作ndarray的级联和切分级联切分 ndarray的基本运算广播机制(Broadcast)ndarry的聚合操作数组元素的操作numpy 数学函数numpy 查找和排序 写在最后面 简介 nump…...
【Java】云HIS云端数字医院信息平台源码
一、云HIS系统特色 • 使用简易化 即开即用,快速复制,按需开通功能模块,多机构共享机房、软件、服务器、存储设备等资源,资源利用最大化。 • 连锁集团化 可支持连锁集团化管理,1N模式,支撑运营&#x…...

Jupyter Notebook 内核似乎挂掉了,它很快将自动重启
报错原因: OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized. OMP: Hint This means that multiple copies of the OpenMP runtime have been linked into the program. That is dangerous, since it can degrade perfo…...
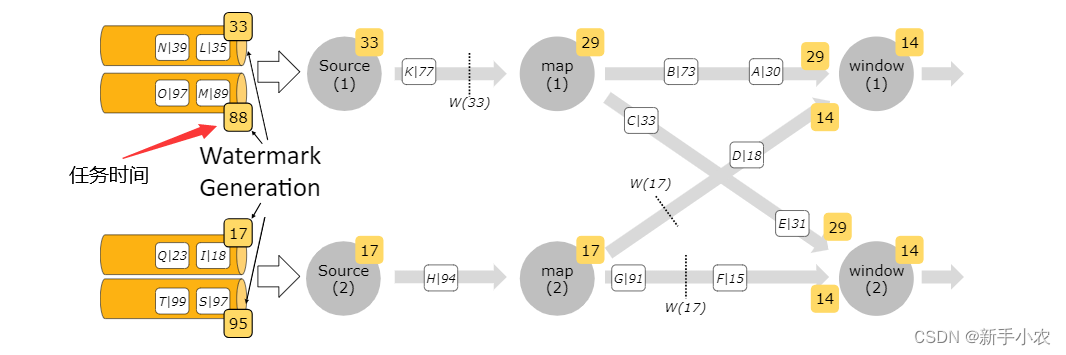
Flink -- 事件时间 Watermark
1、事件时间: 指的是数据产生的时间或是说是数据发生的时间。 在Flink中有三种时间分别是: Event Time:事件时间,数据产生的时间,可以反应数据真实发生的时间 Infestion Time:事件接收时间 Processing Tim…...

Django框架简介
文章目录 Django框架介绍MVC与MVT模型MVCMTV 版本问题运行django注意事项 Django的下载与基本命令下载Django方式一:在命令界面使用pip安装方式二:使用pycharm安装 Django的基础命令命令行操作pycharm操作 Django项目命令行操作与Pycharm操作的区别应用D…...
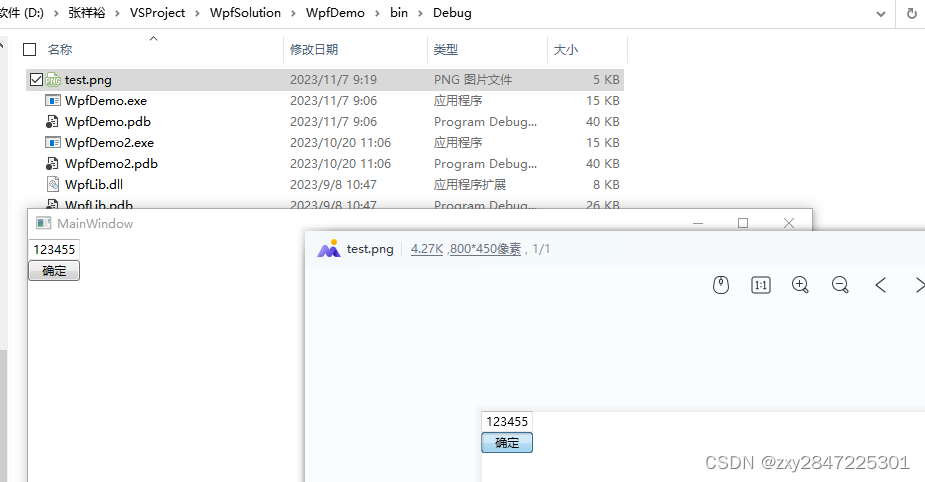
把wpf的窗体保存为png图片
昨晚在stack overflow刷问题时看到有这个问题,今天早上刚好来尝试学习一下 stack overflow的链接如下: c# - How to render a WPF UserControl to a bitmap without creating a window - Stack Overflow 测试步骤如下: 1 新建.net frame…...

2023NOIP A层联测28-大眼鸹猫
给你两个长度为 n n n 的序列 a , b a,b a,b,这两个序列都是单调不降的。 你可以对 a a a 进行不超过 m m m 次操作,每次操作你可以选择一个 i i i 满足 1 ≤ i ≤ n 1\le i\le n 1≤i≤n,然后选择一个整数(可以是负数&…...
电机应用-直流有刷电机
目录 直流有刷电机 工作原理 直流有刷减速电机的重要参数 电路原理与分析 驱动芯片分析 L298N驱动芯片 直流有刷减速电机控制实现 控制速度原理 硬件设计 L298N 野火直流有刷电机驱动板-MOS管搭建板 软件设计1:两个直流有刷减速电机按键控制 开发设计 …...

BIM、建筑机器人、隧道工程施工关键技术
一、BIM简介 (一)BIM概念 BIM(Building Information Modeling),建筑信息模型。该技术通过数字化手段,在计算机中建立虚拟建筑,该虚拟建筑提供从单一到完整、包含逻辑关系的建筑信息库。信息库…...
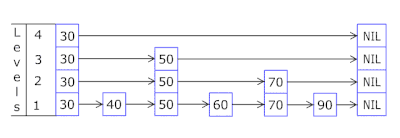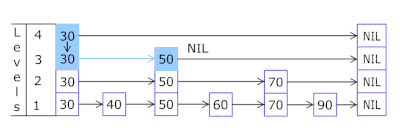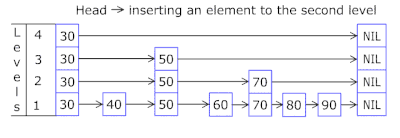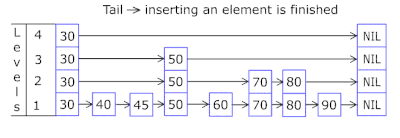
快速了解什么是跳跃表(skip list)
什么是跳跃表(skip list) 跳跃表(Skip List)是一种概率性的数据结构,它通过在多层链表的基础上添加“快速通道”来提高搜索效率。跳跃表的效率可以与平衡树相媲美,即在平均和最坏的情况下,查找…...

【Node.js入门】1.1Node.js 简介
Node.js入门之—1.1Node.js 简介 文章目录 Node.js入门之—1.1Node.js 简介什么是 Node.js错误说法 Node.js 的特点跨平台三方类库自带http服务器非阻塞I/O事件驱动单线程 Node.js 的应用场合适合用Node.js的场合不适合用Node.js的场合弥补Node.js不足的解决方案 什么是 Node.j…...
数据库 高阶语句
目录 数据库 高阶语句 使用select 语句,用order by来对进行排序 区间判断查询和去重查询 如何对结果进行分组查询group by语句 limit 限制输出的结果记录,查看表中的指定行 通配符 设置别名:alias 简写就是 as 使用select 语句&#x…...
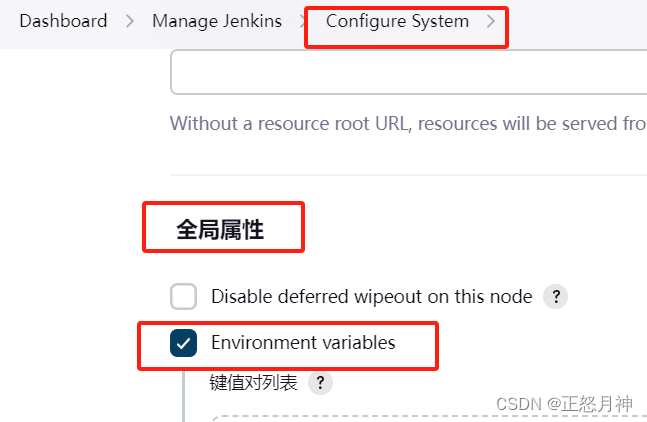
jenkins Java heap space
jenkins Java heap space,是内存不够。 两个解决方案: 一,修改配置文件 windows系统中,找到Jenkins的安装路径, 修改jenkins.xml 将 -Xmx256m 改为 -Xmx1024m 或者更大 重启jenkins服务。 二,jenkins增…...

OpenCV校准棋盘集合
棋盘格可以与相机校准工具一起使用,例如ROS的camera_calibration包。您可以通过单击下面的任何链接免费下载 PDF 格式的各种棋盘,没有水印或广告。此外,还添加了基于 JavaScript 的棋盘生成器,允许您生成自定义尺寸。 提示&#…...

使用git将本地项目推送到远程仓库github
总结:本地项目通过git上传到github 1)、在本地创建一个版本库(即文件夹),通过 git init 把它变成Git仓库; 2)、把项目复制到这个文件夹里面,再通过 git add . 把项目添加到仓库; 3)、再通过 gi…...
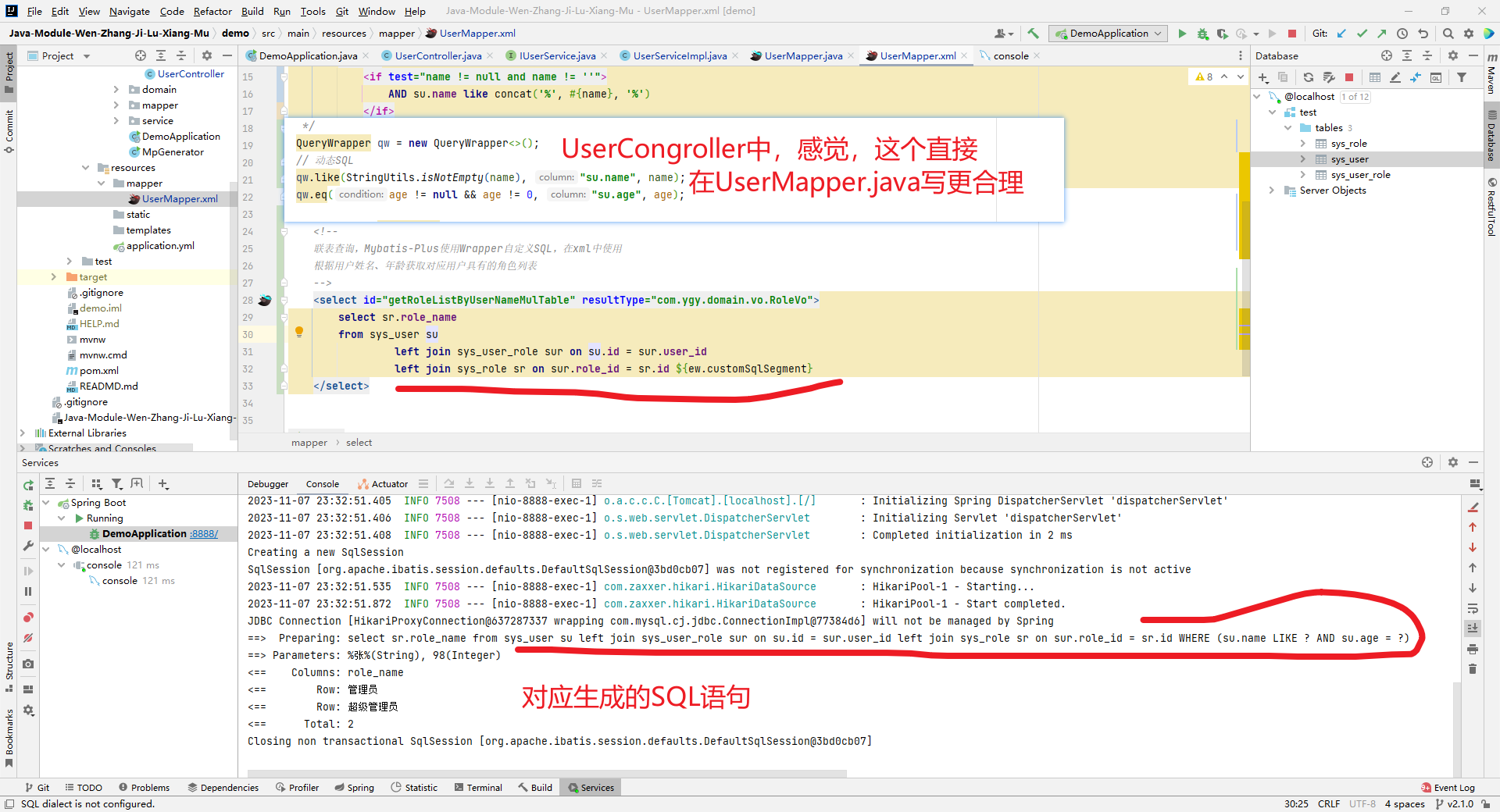
Mybatis-Plus使用Wrapper自定义SQL
文章目录 准备工作Mybatis-Plus使用Wrapper自定义SQL注意事项目录结构如下所示domain层Controller层Service层ServiceImplMapper层UserMapper.xml 结果如下所示:单表查询条件构造器单表查询,Mybatis-Plus使用Wrapper自定义SQL联表查询不用,My…...
仿mudou库one thread one loop式并发服务器
目录 1.实现目标 2.HTTP服务器 实现高性能服务器-Reactor模型 模块划分 SERVER模块: HTTP协议模块: 3.项目中的子功能 秒级定时任务实现 时间轮实现 正则库的简单使用 通⽤类型any类型的实现 4.SERVER服务器实现 日志宏的封装 缓冲区Buffer…...

二十三种设计模式全面解析-组合模式与装饰器模式的结合:实现动态功能扩展
在前文中,我们介绍了组合模式的基本原理和应用,以及它在构建对象结构中的价值和潜力。然而,组合模式的魅力远不止于此。在本文中,我们将继续探索组合模式的进阶应用,并展示它与其他设计模式的结合使用,以构…...
智慧城市建设解决方案分享【完整】
文章目录 第1章 前言第2章 智慧城市建设的背景2.1 智慧城市的发展现状2.2 智慧城市的发展趋势 第3章 智慧城市“十二五”规划要点3.1 国民经济和社会发展“十二五”规划要点3.2 “十二五”信息化发展规划要点 第4章 大数据:智慧城市的智慧引擎4.1 大数据技术—智慧城…...

unity - Blend Shape - 变形器 - 实践
文章目录 目的Blend Shape 逐顶点 多个混合思路Blender3Ds maxUnity 中使用Project 目的 拾遗,备份 Blend Shape 逐顶点 多个混合思路 blend shape 基于: vertex number, vertex sn 相同,才能正常混合、播放 也就是 vertex buffer 的顶点数…...

从零构建人脸识别系统:OpenCV与dlib实战
1. 项目概述人脸识别系统是计算机视觉领域最具实用价值的技术之一。从手机解锁到机场安检,这项技术已经深入到我们生活的方方面面。但大多数人只把它当作黑箱使用,很少了解背后的实现原理。今天我想分享如何从零开始构建一个基础但完整的人脸识别系统&am…...

Stable Diffusion【ControlNet】进阶:IP-Adapter预处理器实战指南与场景化应用
1. IP-Adapter预处理器核心原理揭秘 第一次接触IP-Adapter时,我也被它那些拗口的专业术语搞得头晕。但实际用下来才发现,这个看似复杂的技术,本质上就是个"图片翻译官"。想象一下:你拿着外国菜单点菜时,服务…...

告别编译噩梦:用Docker容器5分钟快速部署Neper多晶建模环境
告别编译噩梦:用Docker容器5分钟快速部署Neper多晶建模环境 第一次接触Neper时,我被它强大的多晶建模能力吸引,但随即陷入长达两天的依赖安装地狱。GSL、NLOPT、OpenMP、Gmsh...每个组件都需要特定版本,编译错误像打地鼠一样此起彼…...
你还能聊什么?从应用场景到代码优化)
面试官问堆排序,除了O(nlogn)你还能聊什么?从应用场景到代码优化
面试官问堆排序,除了O(nlogn)你还能聊什么?从应用场景到代码优化 当面试官抛出堆排序的问题时,大多数候选人会条件反射般回答"时间复杂度O(nlogn)"——这当然没错,但如果你止步于此,就错过了一次展示技术深度…...

别再死记贝叶斯公式了!用sklearn的CategoricalNB实战Ionosphere数据集,手把手教你搞定分类
别再死记贝叶斯公式了!用sklearn的CategoricalNB实战Ionosphere数据集,手把手教你搞定分类 当你第一次接触机器学习分类任务时,可能会被各种数学公式吓退。但今天我要告诉你一个秘密:实际应用中,你完全不需要死记硬背贝…...

R语言空间分析、模拟预测与可视化高级应用
随着地理信息系统(GIS)和大尺度研究的发展,空间数据的管理、统计与制图变得越来越重要。R语言在数据分析、挖掘和可视化中发挥着重要的作用,其中在空间分析方面扮演着重要角色,与空间相关的包的数量也达到130多个。在本…...

3个颠覆性技巧让AI到PSD转换效率提升300%
3个颠覆性技巧让AI到PSD转换效率提升300% 【免费下载链接】ai-to-psd A script for prepare export of vector objects from Adobe Illustrator to Photoshop 项目地址: https://gitcode.com/gh_mirrors/ai/ai-to-psd 你是否曾为Illustrator到Photoshop的转换而头疼&…...

思源宋体TTF:为什么这款免费字体能彻底改变你的中文排版体验
思源宋体TTF:为什么这款免费字体能彻底改变你的中文排版体验 【免费下载链接】source-han-serif-ttf Source Han Serif TTF 项目地址: https://gitcode.com/gh_mirrors/so/source-han-serif-ttf 还记得那些年为中文字体版权发愁的日子吗?当我第一…...
)
MacOS上VScode装PlatformIO卡死?试试这个官方脚本安装法(附详细日志)
MacOS开发者必备:PlatformIO官方脚本安装全指南与疑难解析 当你在VScode插件市场点击"Install"按钮后,进度条却像被冻住一样纹丝不动——这可能是许多MacOS开发者初次接触PlatformIO时共同的噩梦。不同于Windows系统的一键安装体验,…...

如何高效使用免费AMD Ryzen调试工具:SMUDebugTool专业操作指南
如何高效使用免费AMD Ryzen调试工具:SMUDebugTool专业操作指南 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: ht…...